Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
V tomto kurzu se dozvíte, jak vytvořit cluster Apache HBase v Azure HDInsight, vytvořit tabulky HBase a dotazovat se na tabulky pomocí Apache Hivu. Obecné informace o HBase najdete v tématu Přehled HBase ve službě HDInsight.
V tomto kurzu se naučíte:
- Vytvoření clusteru Apache HBase
- Vytvoření tabulek HBase a vložení dat
- Použití Apache Hivu k dotazování Apache HBase
- Použití rozhraní REST API HBase pomocí Curl
- Kontrola stavu clusteru
Požadavky
Klient SSH. Další informace najdete v tématu Připojení ke službě HDInsight (Apache Hadoop) pomocí SSH.
Večírek. Příklady v tomto článku používají prostředí Bash ve Windows 10 pro příkazy curl. Postup instalace najdete v průvodci instalací Subsystém Windows pro Linux pro Windows 10. Ostatní Unix shelly fungují také. Příklady curl, s některými drobnými úpravami, mohou pracovat na příkazovém řádku Windows. Nebo můžete použít rutinu Windows PowerShellu Invoke-RestMethod.
Vytvoření clusteru Apache HBase
Následující postup používá šablonu Azure Resource Manageru k vytvoření clusteru HBase. Šablona také vytvoří závislý výchozí účet služby Azure Storage. Pro lepší pochopení parametrů použitých v postupu a dalších metod vytvoření clusteru si projděte téma Vytvoření Hadoop clusterů se systémem Linux v HDInsight.
Výběrem následujícího obrázku otevřete šablonu na webu Azure Portal. Šablona se nachází v šablonách rychlého startu Azure.

V dialogovém okně Vlastní nasazení zadejte následující hodnoty:
Vlastnost Popis Předplatné Vyberte své předplatné Azure, které se používá k vytvoření clusteru. Skupina prostředků Vytvořte skupinu pro správu prostředků Azure nebo použijte existující skupinu. Umístění Zadejte umístění skupiny prostředků. Název clusteru Zadejte název clusteru HBase. Přihlašovací jméno a heslo clusteru Výchozí přihlašovací jméno je admin.Uživatelské jméno a heslo SSH Výchozí uživatelské jméno je sshuser.Ostatní parametry jsou volitelné.
Každý cluster obsahuje závislost účtu Azure Storage. Po odstranění clusteru zůstanou data v účtu úložiště. Výchozí název účtu úložiště clusteru je název clusteru s připojenou příponou „úložiště“. Je fixně kódován v části proměnných šablony.
Vyberte Souhlasím s podmínkami a ujednáními uvedenými výše a pak vyberte Koupit. Vytvoření clusteru trvá přibližně 20 minut.
Po odstranění clusteru HBase můžete vytvořit jiný cluster HBase pomocí stejného výchozího kontejneru objektů blob. Nový cluster převezme tabulky HBase, které jste vytvořili v původním clusteru. Aby se zabránilo nekonzistencím, doporučujeme zakázat tabulky HBase před odstraněním clusteru.
Vytváření tabulek a vkládání dat
SSH můžete použít pro připojení ke clusterům HBase a následné použití Prostředí Apache HBase k vytváření tabulek HBase , vkládání dat a dotazování dat.
Pro většinu osob se data zobrazí v tabulkovém formátu:

V HBase (implementace Cloud BigTable) vypadají stejná data takto:

Použití prostředí HBase
Pomocí
sshpříkazu se připojte ke clusteru HBase. Upravte následující příkaz nahrazenímCLUSTERNAMEnázvu clusteru a zadáním příkazu:ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netPomocí
hbase shellpříkazu spusťte interaktivní prostředí HBase. Do připojení SSH zadejte následující příkaz:hbase shellPomocí
createpříkazu vytvořte tabulku HBase se dvěma sloupci. V názvech tabulek a sloupců se rozlišují malá a velká písmena. Zadejte tento příkaz:create 'Contacts', 'Personal', 'Office'Pomocí
listpříkazu zobrazíte seznam všech tabulek v HBase. Zadejte tento příkaz:listPříkaz slouží
putk vložení hodnot do zadaného sloupce v zadaném řádku v konkrétní tabulce. Zadejte následující příkazy:put 'Contacts', '1000', 'Personal:Name', 'John Dole' put 'Contacts', '1000', 'Personal:Phone', '1-425-000-0001' put 'Contacts', '1000', 'Office:Phone', '1-425-000-0002' put 'Contacts', '1000', 'Office:Address', '1111 San Gabriel Dr.'Pomocí
scanpříkazu můžete prohledávat a vracetContactsdata tabulky. Zadejte tento příkaz:scan 'Contacts'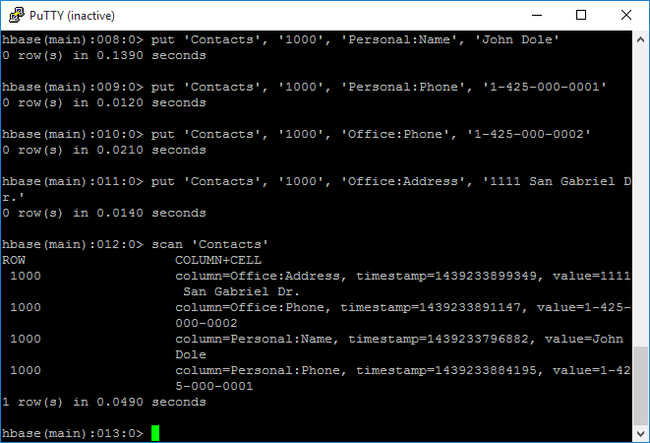
K načtení obsahu řádku použijte
getpříkaz. Zadejte tento příkaz:get 'Contacts', '1000'Uvidíte podobné výsledky jako při použití příkazu
scan, protože je zde jen jeden řádek.Další informace o schématu tabulky HBase naleznete v tématu Úvod do návrhu schématu Apache HBase. Další příkazy HBase najdete v tématu Referenční příručka Apache HBase.
Pomocí
exitpříkazu zastavte interaktivní prostředí HBase. Zadejte tento příkaz:exit
Hromadné načítání dat do tabulky kontaktů HBase
HBase obsahuje několik metod načítání dat do tabulek. Další informace naleznete v části Hromadné načítání.
Ukázkový datový soubor najdete ve veřejném kontejneru objektů blob: wasb://hbasecontacts@hditutorialdata.blob.core.windows.net/contacts.txt. Obsah datového souboru je:
8396 Calvin Raji 230-555-0191 230-555-0191 5415 San Gabriel Dr.
16600 Karen Wu 646-555-0113 230-555-0192 9265 La Paz
4324 Karl Xie 508-555-0163 230-555-0193 4912 La Vuelta
16891 Jonn Jackson 674-555-0110 230-555-0194 40 Ellis St.
3273 Miguel Miller 397-555-0155 230-555-0195 6696 Anchor Drive
3588 Osa Agbonile 592-555-0152 230-555-0196 1873 Lion Circle
10272 Julia Lee 870-555-0110 230-555-0197 3148 Rose Street
4868 Jose Hayes 599-555-0171 230-555-0198 793 Crawford Street
4761 Caleb Alexander 670-555-0141 230-555-0199 4775 Kentucky Dr.
16443 Terry Chander 998-555-0171 230-555-0200 771 Northridge Drive
Volitelně můžete vytvořit textový soubor a nahrát ho do vlastního účtu úložiště. Pokyny najdete v tématu Nahrání dat pro úlohy Apache Hadoop ve službě HDInsight.
Tento postup používá Contacts tabulku HBase, kterou jste vytvořili v posledním postupu.
Spuštěním následujícího příkazu z otevřeného připojení ssh transformujte datový soubor na StoreFiles a uložte ho do relativní cesty určené
Dimporttsv.bulk.output.hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns="HBASE_ROW_KEY,Personal:Name,Personal:Phone,Office:Phone,Office:Address" -Dimporttsv.bulk.output="/example/data/storeDataFileOutput" Contacts wasb://hbasecontacts@hditutorialdata.blob.core.windows.net/contacts.txtSpuštěním následujícího příkazu nahrajte data z
/example/data/storeDataFileOutputtabulky HBase:hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /example/data/storeDataFileOutput ContactsMůžete otevřít prostředí HBase a pomocí
scanpříkazu vypsat obsah tabulky.
Použití Apache Hivu k dotazování Apache HBase
Data v tabulkách HBase můžete dotazovat pomocí Apache Hivu. V této části vytvoříte tabulku Hive, která se namapuje na tabulku HBase, a použijete ji k dotazování dat v tabulce HBase.
Z otevřeného připojení ssh spusťte Beeline pomocí následujícího příkazu:
beeline -u 'jdbc:hive2://localhost:10001/;transportMode=http' -n adminDalší informace o Beeline najdete v tématu Použití Hivu s Hadoopem ve službě HDInsight s Beeline.
Spuštěním následujícího skriptu HiveQL vytvořte tabulku Hive, která se mapuje na tabulku HBase. Před spuštěním tohoto příkazu se ujistěte, že jste vytvořili ukázkovou tabulku odkazovanou dříve v tomto článku pomocí prostředí HBase.
CREATE EXTERNAL TABLE hbasecontacts(rowkey STRING, name STRING, homephone STRING, officephone STRING, officeaddress STRING) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ('hbase.columns.mapping' = ':key,Personal:Name,Personal:Phone,Office:Phone,Office:Address') TBLPROPERTIES ('hbase.table.name' = 'Contacts');Spusťte následující skript HiveQL pro dotaz na data v tabulce HBase:
SELECT count(rowkey) AS rk_count FROM hbasecontacts;Chcete-li ukončit Beeline, použijte
!exit.Chcete-li ukončit připojení ssh, použijte
exit.
Oddělení clusterů Hive a HBase
Dotaz Hive pro přístup k datům HBase se nemusí spouštět z clusteru HBase. K dotazování dat HBase je možné použít jakýkoli cluster, který je součástí Hivu (včetně Sparku, Hadoopu, HBase nebo Interactive Query), a to za předpokladu, že jsou dokončeny následující kroky:
- Oba clustery musí být připojené ke stejné virtuální síti a podsíti.
- Zkopírujte
/usr/hdp/$(hdp-select --version)/hbase/conf/hbase-site.xmlz hlavních uzlů clusteru HBase do hlavních uzlů clusteru Hive a pracovních uzlů.
Zabezpečené clustery
Data HBase se také dají dotazovat z Hivu pomocí HBase s podporou ESP:
- Při sledování vzoru pro více clustery musí být oba clustery s aktivovaným ESP.
- Pokud chcete, aby Hive mohl dotazovat data HBase, ujistěte se, že
hivemá uživatel udělená oprávnění pro přístup k datům HBase prostřednictvím modulu plug-in HBase Apache Ranger. - Pokud používáte samostatné clustery s podporou ESP, musí se obsah
/etc/hostshlavních uzlů clusteru HBase připojit k/etc/hostshlavním uzlům clusteru Hive a pracovním uzlům.
Poznámka:
Po škálování jednoho z clusterů je nutné znovu připojit /etc/hosts
Používání rozhraní HBase REST API prostřednictvím cURL
Rozhraní REST API HBase je zabezpečené prostřednictvím základního ověřování. Požadavky byste vždy měli provádět pomocí protokolu HTTPS (Secure HTTP), čímž pomůžete zajistit, že se přihlašovací údaje budou na server odesílat bezpečně.
Pokud chcete povolit rozhraní HBase REST API v clusteru HDInsight, přidejte do části Akce skriptu následující vlastní spouštěcí skript. Spouštěcí skript můžete přidat při vytváření clusteru nebo po vytvoření clusteru. Jako typ uzlu vyberte Servery oblastí , aby se zajistilo, že se skript spustí pouze na serverech oblastí HBase. Skript spustí proxy server HBase REST na portu 8090 na serverech oblastí.
#! /bin/bash THIS_MACHINE=`hostname` if [[ $THIS_MACHINE != wn* ]] then printf 'Script to be executed only on worker nodes' exit 0 fi RESULT=`pgrep -f RESTServer` if [[ -z $RESULT ]] then echo "Applying mitigation; starting REST Server" sudo python /usr/lib/python2.7/dist-packages/hdinsight_hbrest/HbaseRestAgent.py else echo "REST server already running" exit 0 fiNastavte proměnnou prostředí pro snadné použití. Upravte následující příkazy nahrazením
MYPASSWORDpřihlašovacího hesla clusteru. NahraďteMYCLUSTERNAMEnázvem vašeho clusteru HBase. Pak zadejte příkazy.export PASSWORD='MYPASSWORD' export CLUSTER_NAME=MYCLUSTERNAMEPomocí následujícího příkazu můžete zobrazit seznam existujících tabulek HBase:
curl -u admin:$PASSWORD \ -G https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Pokud chcete vytvořit novou tabulku HBase se dvěma skupinami sloupců, použijte následující příkaz:
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/schema" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"@name\":\"Contact1\",\"ColumnSchema\":[{\"name\":\"Personal\"},{\"name\":\"Office\"}]}" \ -vSchéma je k dispozici ve formátu JSON.
Chcete-li vložit nějaká data použijte následující příkaz:
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/false-row-key" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"Row\":[{\"key\":\"MTAwMA==\",\"Cell\": [{\"column\":\"UGVyc29uYWw6TmFtZQ==\", \"$\":\"Sm9obiBEb2xl\"}]}]}" \ -vBase64 kóduje hodnoty zadané v přepínači
-d. V tomto příkladu:MTAwMA==: 1000
UGVyc29uYWw6TmFtZQ==: Osobní: Jméno
Sm9obiBEb2xl: John Dole
false-row-key umožňuje vložit více (dávkových) hodnot.
Pro získání řádku použijte následující příkaz:
curl -u admin:$PASSWORD \ GET "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/1000" \ -H "Accept: application/json" \ -v
Poznámka:
Kontrola prostřednictvím koncového bodu clusteru se zatím nepodporuje.
Další informace o HBase Rest naleznete v tématu Referenční příručka Apache HBase.
Poznámka:
Thrift není podporován v HBase na HDInsight.
Pokud používáte Curl nebo jakoukoli jinou komunikaci REST s WebHCat, musíte požadavky ověřit zadáním uživatelského jména a hesla pro správce clusteru HDInsight. Název clusteru také musíte použít jako součást identifikátoru URI (Uniform Resource Identifier) sloužícího k odesílání požadavků na server:
curl -u <UserName>:<Password> \
-G https://<ClusterName>.azurehdinsight.net/templeton/v1/status
Měla by se zobrazit odpověď podobná následující odpovědi:
{"status":"ok","version":"v1"}
Kontrola stavu clusteru
HBase v HDInsight se dodává s webovým uživatelským rozhraním pro sledování clusterů. Pomocí webového uživatelského rozhraní, můžete žádat o statistické údaje nebo informace o oblastech.
Přístup k hlavnímu uživatelskému rozhraní HBase
Přihlaste se k webovému uživatelskému rozhraní Ambari, kde
https://CLUSTERNAME.azurehdinsight.netCLUSTERNAMEje název vašeho clusteru HBase.V nabídce vlevo vyberte HBase .
Vyberte rychlé odkazy v horní části stránky, přejděte na aktivní odkaz uzlu Zookeeper a pak vyberte hlavní uživatelské rozhraní HBase. Uživatelské rozhraní se otevře na nové kartě prohlížeče:
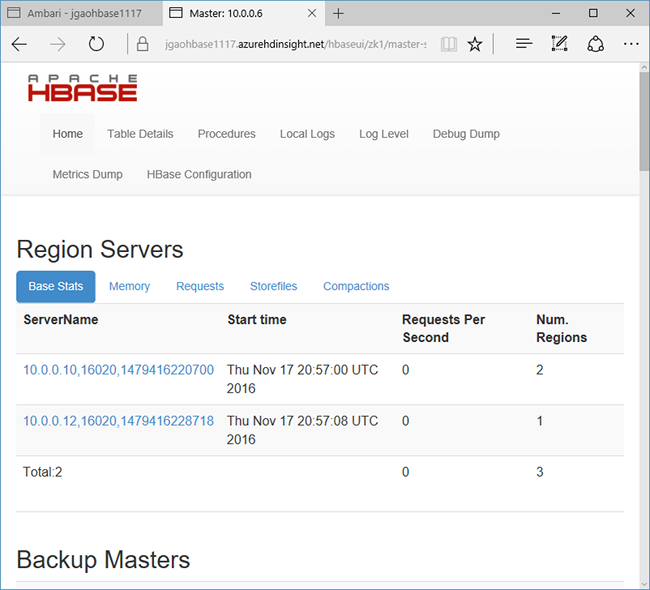
Hlavní uživatelské rozhraní HBase obsahuje tyto části:
- oblastní servery
- zálohování hlavních serverů
- V tabulkách
- úlohy
- atributy softwaru
Rekonstrukce clusteru
Po odstranění clusteru HBase můžete vytvořit jiný cluster HBase pomocí stejného výchozího kontejneru objektů blob. Nový cluster převezme tabulky HBase, které jste vytvořili v původním clusteru. Abyste se však vyhnuli nekonzistenci, doporučujeme před odstraněním clusteru zakázat tabulky HBase.
Můžete použít příkaz disable 'Contacts'HBase .
Uvolnění prostředků
Pokud nebudete tuto aplikaci dál používat, odstraňte cluster HBase, který jste vytvořili, pomocí následujícího postupu:
- Přihlaste se k portálu Azure.
- Do vyhledávacího pole v horní části zadejte HDInsight.
- V části Služby vyberte clustery HDInsight.
- V seznamu clusterů HDInsight, které se zobrazí, klikněte na ... vedle clusteru, který jste vytvořili pro tento kurz.
- Klepněte na tlačítko Odstranit. Klepněte na tlačítko Ano.
Další kroky
V tomto kurzu jste zjistili, jak vytvořit cluster Apache HBase. A jak vytvořit tabulky a zobrazit data v těchto tabulkách z prostředí HBase. Dozvěděli jste se také, jak používat dotaz Hive na data v tabulkách HBase. A jak použít rozhraní REST API jazyka C# HBase k vytvoření tabulky HBase a načtení dat z tabulky. Další informace najdete v následujících tématech: