Zprovoznění kanálu datových analýz
Datové kanály podceně mnoho řešení pro analýzu dat. Jak název napovídá, datový kanál převezme nezpracovaná data, podle potřeby je vyčistí a přetřísí a pak obvykle provádí výpočty nebo agregace před uložením zpracovaných dat. Zpracovávaná data využívají klienti, sestavy nebo rozhraní API. Datový kanál musí poskytovat opakovatelné výsledky, ať už podle plánu nebo při aktivaci novými daty.
Tento článek popisuje, jak zprovoznit datové kanály pro opakovatelnost pomocí Oozie spuštěných v clusterech HDInsight Hadoop. Ukázkový scénář vás provede datovým kanálem, který připraví a zpracuje data letových časových řad leteckých společností.
V následujícím scénáři jsou vstupní data plochým souborem obsahujícím dávku letových dat po dobu jednoho měsíce. Tato data o letu zahrnují informace, jako je počáteční a cílové letiště, letové míle, čas odletu a příletu atd. Cílem tohoto kanálu je sumarizovat denní výkon leteckých společností, kde každá letecká společnost má pro každý den jeden řádek s průměrným zpožděním odletu a příletu v minutách a celkový počet mílí letadel v daném dni.
| YEAR | MONTH | DAY_OF_MONTH | DOPRAVCE | AVG_DEP_DELAY | AVG_ARR_DELAY | TOTAL_DISTANCE |
|---|---|---|---|---|---|---|
| 2017 | 1 | 3 | AA | 10.142229 | 7.862926 | 2644539 |
| 2017 | 1 | 3 | AS | 9.435449 | 5.482143 | 572289 |
| 2017 | 1 | 3 | DL | 6.935409 | -2.1893024 | 1909696 |
Ukázkový kanál počká, až dorazí data testovacího období nového časového období, a pak uloží podrobné informace o letu do datového skladu Apache Hive pro dlouhodobé analýzy. Kanál také vytvoří mnohem menší datovou sadu, která shrnuje pouze data o denních letech. Tato denní souhrnná data letů se odesílají do služby SQL Database, aby poskytovala sestavy, například pro web.
Následující diagram znázorňuje ukázkový kanál.
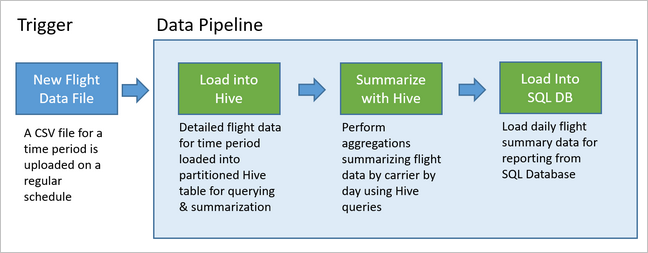
Přehled řešení Apache Oozie
Tento kanál používá Apache Oozie spuštěný v clusteru HDInsight Hadoop.
Oozie popisuje své kanály z hlediska akcí, pracovních postupů a koordinátorů. Akce určují skutečnou práci, která se má provést, například spuštění dotazu Hive. Pracovní postupy definují posloupnost akcí. Koordinátoři definují plán spuštění pracovního postupu. Koordinátoři mohou také počkat na dostupnost nových dat před spuštěním instance pracovního postupu.
Následující diagram znázorňuje základní návrh tohoto ukázkového kanálu Oozie.
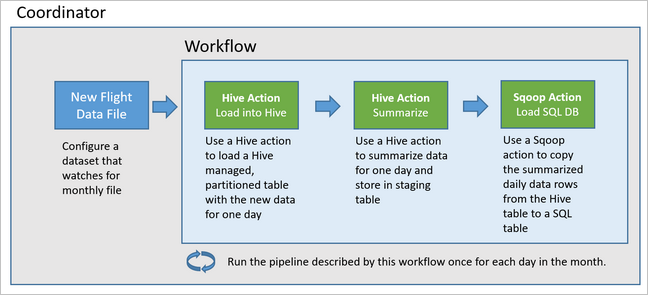
Zřízení prostředků Azure
Tento kanál vyžaduje službu Azure SQL Database a cluster HDInsight Hadoop ve stejném umístění. Azure SQL Database ukládá souhrnná data vytvořená kanálem i úložištěm metadat Oozie.
Zřízení služby Azure SQL Database
Vytvořte azure SQL Database. Viz Vytvoření služby Azure SQL Database na webu Azure Portal.
Abyste měli jistotu, že váš cluster HDInsight má přístup k připojené službě Azure SQL Database, nakonfigurujte pravidla brány firewall služby Azure SQL Database tak, aby umožňovala službám a prostředkům Azure přístup k serveru. Tuto možnost můžete povolit na webu Azure Portal výběrem možnosti Nastavit bránu firewall serveru a výběrem možnosti Zapnuto v části Povolit službám a prostředkům Azure přístup k tomuto serveru pro Azure SQL Database. Další informace najdete v části Vytváření a správa pravidel firewallu protokolu IP.
Pomocí editoru dotazů spusťte následující příkazy SQL a vytvořte
dailyflightstabulku, která bude ukládat souhrnná data z každého spuštění kanálu.CREATE TABLE dailyflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER CHAR(2), AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) GO CREATE CLUSTERED INDEX dailyflights_clustered_index on dailyflights(YEAR,MONTH,DAY_OF_MONTH,CARRIER) GO
Vaše služba Azure SQL Database je teď připravená.
Zřízení clusteru Apache Hadoop
Vytvořte cluster Apache Hadoop s vlastním metastorem. Během vytváření clusteru z portálu na kartě Úložiště se ujistěte, že jste v nastavení metastoru vybrali službu SQL Database. Další informace o výběru metastoru najdete v tématu Výběr vlastního metastoru během vytváření clusteru. Další informace o vytváření clusteru najdete v tématu Začínáme se službou HDInsight v Linuxu.
Ověření nastavení tunelového propojení SSH
Pokud chcete použít webovou konzolu Oozie k zobrazení stavu vašich instancí koordinátoru a pracovních postupů, nastavte tunel SSH do clusteru HDInsight. Další informace najdete v tématu Tunel SSH.
Poznámka:
Chrome s rozšířením Foxy Proxy můžete také použít k procházení webových prostředků clusteru přes tunel SSH. Nakonfigurujte ho pro proxy všechny požadavky prostřednictvím hostitele localhost na portu tunelu 9876. Tento přístup je kompatibilní s Subsystém Windows pro Linux, označovaným také jako Bash ve Windows 10.
Spuštěním následujícího příkazu otevřete tunel SSH do clusteru, kde
CLUSTERNAMEje název clusteru:ssh -C2qTnNf -D 9876 sshuser@CLUSTERNAME-ssh.azurehdinsight.netZkontrolujte, že tunel funguje, a to tak, že přejdete na Ambari na hlavním uzlu tak, že přejdete na:
http://headnodehost:8080Pokud chcete získat přístup k webové konzole Oozie z Ambari, přejděte na rychlé odkazy> Oozie>[Active server] >Oozie Webové uživatelské rozhraní.
Konfigurace Hivu
Nahrání dat
Stáhněte si ukázkový soubor CSV, který obsahuje letová data po dobu jednoho měsíce. Stáhněte si soubor
2017-01-FlightData.zipZIP z úložiště HDInsight GitHub a rozbalte ho do souboru2017-01-FlightData.csvCSV .Zkopírujte tento soubor CSV do účtu azure Storage připojeného ke clusteru HDInsight a umístěte ho do
/example/data/flightssložky.Pomocí SCP zkopírujte soubory z místního počítače do místního úložiště hlavního uzlu clusteru HDInsight.
scp ./2017-01-FlightData.csv sshuser@CLUSTERNAME-ssh.azurehdinsight.net:2017-01-FlightData.csvPomocí příkazu ssh se připojte ke clusteru. Upravte následující příkaz nahrazením
CLUSTERNAMEnázvu clusteru a zadáním příkazu:ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netZ relace SSH zkopírujte soubor z místního úložiště hlavního uzlu do Azure Storage pomocí příkazu HDFS.
hadoop fs -mkdir /example/data/flights hdfs dfs -put ./2017-01-FlightData.csv /example/data/flights/2017-01-FlightData.csv
Vytváření tabulek
Ukázková data jsou teď k dispozici. Kanál ale vyžaduje ke zpracování dvě tabulky Hive, jednu pro příchozí data (rawFlights) a druhou pro souhrnná data (flights). Tyto tabulky vytvořte v Ambari následujícím způsobem.
Přihlaste se k Ambari tak, že přejdete na
http://headnodehost:8080.V seznamu služeb vyberte Hive.
Vyberte Přejít k zobrazení vedle popisku Zobrazení Hive 2.0.

Do textové oblasti dotazu vložte následující příkazy, které vytvoří
rawFlightstabulku. TabulkarawFlightsposkytuje schéma při čtení souborů CSV ve/example/data/flightssložce ve službě Azure Storage.CREATE EXTERNAL TABLE IF NOT EXISTS rawflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" ) LOCATION '/example/data/flights'Výběrem možnosti Execute (Spustit ) vytvořte tabulku.
Pokud chcete vytvořit
flightstabulku, nahraďte text v textové oblasti dotazu následujícími příkazy. Tabulkaflightsje tabulka spravovaná Hivem, která rozděluje data načtená do ní podle roku, měsíce a dne v měsíci. Tato tabulka bude obsahovat všechna historická data letu s nejnižší členitostí v zdrojových datech jednoho řádku na let.SET hive.exec.dynamic.partition.mode=nonstrict; CREATE TABLE flights ( FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT ) PARTITIONED BY (YEAR INT, MONTH INT, DAY_OF_MONTH INT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" );Výběrem možnosti Execute (Spustit ) vytvořte tabulku.
Vytvoření pracovního postupu Oozie
Kanály obvykle zpracovávají data v dávkách podle daného časového intervalu. V tomto případě kanál zpracovává data letu každý den. Tento přístup umožňuje vstupním souborům CSV dorazit každý den, týdně, měsíčně nebo ročně.
Ukázkový pracovní postup zpracovává data letů každý den ve třech hlavních krocích:
- Spuštěním dotazu Hive extrahujte data pro rozsah kalendářních dat daného dne ze zdrojového souboru CSV reprezentované
rawFlightstabulkou a vložte data doflightstabulky. - Spuštěním dotazu Hive můžete dynamicky vytvořit pracovní tabulku v Hivu pro tento den, která obsahuje kopii letových dat shrnutých podle dne a dopravce.
- Pomocí Apache Sqoopu zkopírujte všechna data z denní pracovní tabulky v Hive do cílové
dailyflightstabulky ve službě Azure SQL Database. Sqoop přečte zdrojové řádky z dat za tabulkou Hive umístěnou ve službě Azure Storage a načte je do služby SQL Database pomocí připojení JDBC.
Tyto tři kroky koordinuje pracovní postup Oozie.
Z místní pracovní stanice vytvořte soubor s názvem
job.properties. Jako počáteční obsah souboru použijte následující text. Pak aktualizujte hodnoty pro vaše konkrétní prostředí. Tabulka pod textem shrnuje jednotlivé vlastnosti a označuje, kde můžete najít hodnoty pro vlastní prostředí.nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net jobTracker=[ACTIVERESOURCEMANAGER]:8050 queueName=default oozie.use.system.libpath=true appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie oozie.wf.application.path=${appBase}/load_flights_by_day hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql hiveDailyTableName=dailyflights${year}${month}${day} hiveDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/${year}/${month}/${day} sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]" sqlDatabaseTableName=dailyflights year=2017 month=01 day=03Vlastnost Zdroj hodnoty nameNode Úplná cesta ke kontejneru Azure Storage připojenému k vašemu clusteru HDInsight. jobTracker Interní název hostitele hlavního uzlu YARN vašeho aktivního clusteru. Na domovské stránce Ambari vyberte ze seznamu služeb YARN a pak zvolte Active Resource Manager. Identifikátor URI názvu hostitele se zobrazí v horní části stránky. Připojte port 8050. queueName Název fronty YARN, který se používá při plánování akcí Hive. Ponechte jako výchozí. oozie.use.system.libpath Ponechejte hodnotu true. appBase Cesta k podsložce ve službě Azure Storage, kam nasadíte pracovní postup Oozie a podpůrné soubory. oozie.wf.application.path Umístění pracovního postupu workflow.xmlOozie, který se má spustit.hiveScriptLoadPartition Cesta ve službě Azure Storage k souboru hive-load-flights-partition.hqldotazu Hive .hiveScriptCreateDailyTable Cesta ve službě Azure Storage k souboru hive-create-daily-summary-table.hqldotazu Hive .hiveDailyTableName Dynamicky vygenerovaný název, který se má použít pro pracovní tabulku. hiveDataFolder Cesta ve službě Azure Storage k datům obsaženým v pracovní tabulce. sqlDatabase Připojení ionString Syntaxe JDBC připojovací řetězec do služby Azure SQL Database. sqlDatabaseTableName Název tabulky ve službě Azure SQL Database, do které se vloží souhrnné řádky. Ponechte jako dailyflights.za rok Část roku dne, pro kterou se počítají souhrny letů. Nechte ho beze změny. měs Měsíční komponenta dne, pro který se počítají souhrny letů. Nechte ho beze změny. den Část dne v měsíci, pro kterou se počítají souhrny letů. Nechte ho beze změny. Z místní pracovní stanice vytvořte soubor s názvem
hive-load-flights-partition.hql. Jako obsah souboru použijte následující kód.SET hive.exec.dynamic.partition.mode=nonstrict; INSERT OVERWRITE TABLE flights PARTITION (YEAR, MONTH, DAY_OF_MONTH) SELECT FL_DATE, CARRIER, FL_NUM, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, ACTUAL_ELAPSED_TIME, DISTANCE, YEAR, MONTH, DAY_OF_MONTH FROM rawflights WHERE year = ${year} AND month = ${month} AND day_of_month = ${day};Proměnné Oozie používají syntaxi
${variableName}. Tyto proměnné jsou v souboru nastavenéjob.properties. Oozie nahradí skutečné hodnoty za běhu.Z místní pracovní stanice vytvořte soubor s názvem
hive-create-daily-summary-table.hql. Jako obsah souboru použijte následující kód.DROP TABLE ${hiveTableName}; CREATE EXTERNAL TABLE ${hiveTableName} ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER STRING, AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${hiveDataFolder}'; INSERT OVERWRITE TABLE ${hiveTableName} SELECT year, month, day_of_month, carrier, avg(dep_delay) avg_dep_delay, avg(arr_delay) avg_arr_delay, sum(distance) total_distance FROM flights GROUP BY year, month, day_of_month, carrier HAVING year = ${year} AND month = ${month} AND day_of_month = ${day};Tento dotaz vytvoří pracovní tabulku, která bude uchovávat pouze souhrnná data za jeden den, poznamenejte si příkaz SELECT, který vypočítá průměrné zpoždění a celkový objem vzdálenosti leten operátorem po dnech. Data vložená do této tabulky uložená ve známém umístění (cesta označená proměnnou hiveDataFolder), aby je bylo možné použít jako zdroj pro Sqoop v dalším kroku.
Z místní pracovní stanice vytvořte soubor s názvem
workflow.xml. Jako obsah souboru použijte následující kód. Výše uvedené kroky jsou vyjádřeny jako samostatné akce v souboru pracovního postupu Oozie.<workflow-app name="loadflightstable" xmlns="uri:oozie:workflow:0.5"> <start to = "RunHiveLoadFlightsScript"/> <action name="RunHiveLoadFlightsScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptLoadPartition}</script> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> </hive> <ok to="RunHiveCreateDailyFlightTableScript"/> <error to="fail"/> </action> <action name="RunHiveCreateDailyFlightTableScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptCreateDailyTable}</script> <param>hiveTableName=${hiveDailyTableName}</param> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> <param>hiveDataFolder=${hiveDataFolder}/${year}/${month}/${day}</param> </hive> <ok to="RunSqoopExport"/> <error to="fail"/> </action> <action name="RunSqoopExport"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <arg>export</arg> <arg>--connect</arg> <arg>${sqlDatabaseConnectionString}</arg> <arg>--table</arg> <arg>${sqlDatabaseTableName}</arg> <arg>--export-dir</arg> <arg>${hiveDataFolder}/${year}/${month}/${day}</arg> <arg>-m</arg> <arg>1</arg> <arg>--input-fields-terminated-by</arg> <arg>"\t"</arg> <archive>mssql-jdbc-7.0.0.jre8.jar</archive> </sqoop> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Job failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message> </kill> <end name="end"/> </workflow-app>
Ke dvěma dotazům Hive se přistupuje cestou ve službě Azure Storage a zbývající hodnoty proměnných jsou poskytovány souborem job.properties . Tento soubor nakonfiguruje pracovní postup tak, aby běžel pro datum 3. ledna 2017.
Nasazení a spuštění pracovního postupu Oozie
Pomocí SCP z relace Bash nasaďte pracovní postup Oozie (workflow.xml), dotazy Hive (hive-load-flights-partition.hql a hive-create-daily-summary-table.hql) a konfiguraci úlohy (job.properties). V Oozie může existovat pouze job.properties soubor v místním úložišti hlavního uzlu. Všechny ostatní soubory musí být uložené v HDFS, v tomto případě Azure Storage. Akce Sqoop, kterou pracovní postup používá, závisí na ovladači JDBC pro komunikaci se službou SQL Database, která se musí zkopírovat z hlavního uzlu do HDFS.
load_flights_by_dayVytvořte podsložku pod cestou uživatele v místním úložišti hlavního uzlu. V otevřené relaci ssh spusťte následující příkaz:mkdir load_flights_by_dayZkopírujte všechny soubory v aktuálním adresáři (soubory
workflow.xmljob.properties) až doload_flights_by_daypodsložky. Z místní pracovní stanice spusťte následující příkaz:scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:load_flights_by_dayZkopírujte soubory pracovního postupu do HDFS. V otevřené relaci ssh spusťte následující příkazy:
cd load_flights_by_day hadoop fs -mkdir -p /oozie/load_flights_by_day hdfs dfs -put ./* /oozie/load_flights_by_dayZkopírujte
mssql-jdbc-7.0.0.jre8.jarz místního hlavního uzlu do složky pracovního postupu v HDFS. Revidujte příkaz podle potřeby, pokud váš cluster obsahuje jiný soubor JAR. Podle potřeby upravteworkflow.xml, aby odrážel jiný soubor JAR. V otevřené relaci ssh spusťte následující příkaz:hdfs dfs -put /usr/share/java/sqljdbc_7.0/enu/mssql-jdbc*.jar /oozie/load_flights_by_daySpuštění pracovního postupu. V otevřené relaci ssh spusťte následující příkaz:
oozie job -config job.properties -runSledujte stav webové konzoly Oozie. V Ambari vyberte Oozie, Rychlé odkazy a pak Oozie Web Console. Na kartě Úlohy pracovního postupu vyberte Všechny úlohy.
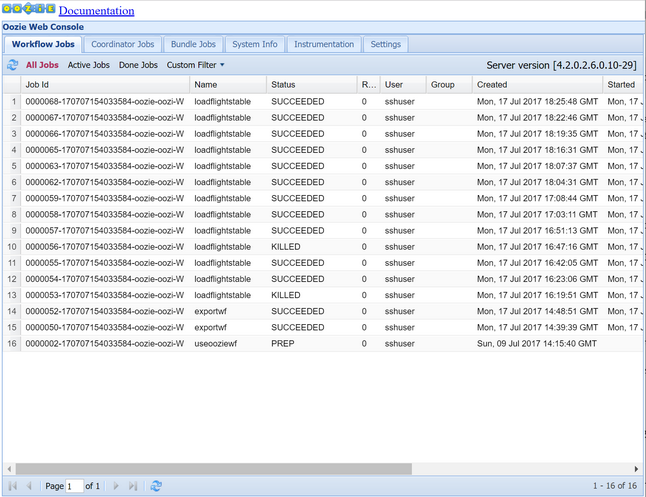
Pokud je stav ÚSPĚŠNÝ, odešlete dotaz na tabulku SLUŽBY SQL Database, aby se zobrazily vložené řádky. Pomocí webu Azure Portal přejděte do podokna pro službu SQL Database, vyberte Nástroje a otevřete Editor Power Query.
SELECT * FROM dailyflights
Teď, když je pracovní postup spuštěný pro jeden testovací den, můžete tento pracovní postup zabalit s koordinátorem, který pracovní postup naplánuje tak, aby běžel každý den.
Spuštění pracovního postupu s koordinátorem
Chcete-li naplánovat tento pracovní postup tak, aby běžel každý den (nebo všechny dny v rozsahu kalendářních dat), můžete použít koordinátora. Koordinátor je definován souborem XML, například coordinator.xml:
<coordinator-app name="daily_export" start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" timezone="UTC" xmlns="uri:oozie:coordinator:0.4">
<datasets>
<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC">
<uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template>
<done-flag></done-flag>
</dataset>
</datasets>
<input-events>
<data-in name="event_input1" dataset="ds_input1">
<instance>${coord:current(0)}</instance>
</data-in>
</input-events>
<action>
<workflow>
<app-path>${appBase}/load_flights_by_day</app-path>
<configuration>
<property>
<name>year</name>
<value>${coord:formatTime(coord:nominalTime(), 'yyyy')}</value>
</property>
<property>
<name>month</name>
<value>${coord:formatTime(coord:nominalTime(), 'MM')}</value>
</property>
<property>
<name>day</name>
<value>${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveScriptLoadPartition</name>
<value>${hiveScriptLoadPartition}</value>
</property>
<property>
<name>hiveScriptCreateDailyTable</name>
<value>${hiveScriptCreateDailyTable}</value>
</property>
<property>
<name>hiveDailyTableNamePrefix</name>
<value>${hiveDailyTableNamePrefix}</value>
</property>
<property>
<name>hiveDailyTableName</name>
<value>${hiveDailyTableNamePrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}${coord:formatTime(coord:nominalTime(), 'MM')}${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveDataFolderPrefix</name>
<value>${hiveDataFolderPrefix}</value>
</property>
<property>
<name>hiveDataFolder</name>
<value>${hiveDataFolderPrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}/${coord:formatTime(coord:nominalTime(), 'MM')}/${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>sqlDatabaseConnectionString</name>
<value>${sqlDatabaseConnectionString}</value>
</property>
<property>
<name>sqlDatabaseTableName</name>
<value>${sqlDatabaseTableName}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>
Jak vidíte, většina koordinátoru pouze předává informace o konfiguraci instanci pracovního postupu. Existuje však několik důležitých položek, které je potřeba zdůraznit.
Bod 1: Atributy
startendsamotnéhocoordinator-appprvku řídí časový interval, ve kterém se spouští koordinátor.<coordinator-app ... start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" ...>Koordinátor zodpovídá za plánování akcí v rozsahu
startdat aendpodle intervalu určeného atributemfrequency. Každá naplánovaná akce zase spustí pracovní postup podle konfigurace. V definici koordinátoru výše je koordinátor nakonfigurovaný tak, aby spouštět akce od 1. ledna 2017 do 5. ledna 2017. Frekvence je nastavena na jeden den výrazem Oozie Expression Language frequency výrazu${coord:days(1)}. Výsledkem je naplánování akce (a proto pracovního postupu) koordinátora jednou za den. U rozsahů kalendářních dat, které jsou v minulosti, jako v tomto příkladu, bude akce naplánována tak, aby běžela bez zpoždění. Začátek data, od kterého je naplánováno spuštění akce, se nazývá nominální čas. Například pro zpracování dat pro leden 1, 2017 koordinátor naplánuje akci s nominálním časem 2017-01-01T00:00:00 GMT.Bod 2: V rámci rozsahu kalendářních dat pracovního postupu určuje prvek, kam se má v HDFS hledat data pro konkrétní rozsah kalendářních dat, a konfiguruje, jak Oozie určuje,
datasetjestli jsou data ještě k dispozici ke zpracování.<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC"> <uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template> <done-flag></done-flag> </dataset>Cesta k datům v HDFS se dynamicky sestavuje podle výrazu zadaného
uri-templatev prvku. V tomto koordinátoru se s datovou sadou používá frekvence jednoho dne. Zatímco počáteční a koncové datum v ovládacím prvku koordinátoru, kdy jsou akce naplánovány (a definuje jejich nominální časy),initial-instanceafrequencyv datové sadě řídí výpočet data, které se používá při vytvářeníuri-template. V takovém případě nastavte počáteční instanci na jeden den před začátkem koordinátoru, abyste zajistili, že převezme data prvního dne (1. ledna 2017). Výpočet data datové sady se převrací od hodnotyinitial-instance(12.31.2016) v přírůstcích četnosti datových sad (jeden den), dokud nenajde nejnovější datum, které neprojde nominálním časem nastaveným koordinátorem (2017-01-01T00:00:00 GMT pro první akci).Prázdný
done-flagprvek označuje, že když Oozie kontroluje přítomnost vstupních dat v určeném čase, Oozie určuje data, zda je k dispozici přítomnost adresáře nebo souboru. V tomto případě se jedná o přítomnost souboru CSV. Pokud existuje soubor CSV, Oozie předpokládá, že jsou data připravená a spustí instanci pracovního postupu pro zpracování souboru. Pokud neexistuje žádný soubor CSV, Oozie předpokládá, že data ještě nejsou připravená a spuštění pracovního postupu přejde do čekajícího stavu.Bod 3: Prvek
data-inurčuje konkrétní časové razítko, které se má použít jako nominální čas při nahrazení hodnot prouri-templatepřidruženou datovou sadu.<data-in name="event_input1" dataset="ds_input1"> <instance>${coord:current(0)}</instance> </data-in>V tomto případě nastavte instanci na výraz
${coord:current(0)}, který se překládá na použití nominálního času akce původně naplánovaného koordinátorem. Jinými slovy, když koordinátor naplánuje akci tak, aby běžela s nominálním časem 01/01/2017, pak 01/01/2017 se použije k nahrazení proměnných YEAR (2017) a MONTH (01) v šabloně identifikátoru URI. Jakmile se šablona identifikátoru URI vypočítá pro tuto instanci, Oozie zkontroluje, jestli je k dispozici očekávaný adresář nebo soubor, a podle toho naplánuje další spuštění pracovního postupu.
Tři předchozí body kombinují situaci, kdy koordinátor plánuje zpracování zdrojových dat denním způsobem.
Bod 1: Koordinátor začíná nominálním datem 2017-01-01.01.
Bod 2: Oozie hledá data dostupná v
sourceDataFolder/2017-01-FlightData.csv.Bod 3: Když Oozie najde tento soubor, naplánuje instanci pracovního postupu, který bude zpracovávat data za 1. ledna 2017. Oozie pak pokračuje ve zpracování za 1. 1. 2017. Toto vyhodnocení se opakuje až do 5. 1. 2017.
Stejně jako u pracovních postupů se konfigurace koordinátoru definuje v job.properties souboru, který má nadmnožinu nastavení používaných pracovním postupem.
nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net
jobTracker=[ACTIVERESOURCEMANAGER]:8050
queueName=default
oozie.use.system.libpath=true
appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie
oozie.coord.application.path=${appBase}
sourceDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/
hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql
hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql
hiveDailyTableNamePrefix=dailyflights
hiveDataFolderPrefix=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/
sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]"
sqlDatabaseTableName=dailyflights
Jedinými novými vlastnostmi zavedených v tomto job.properties souboru jsou:
| Vlastnost | Zdroj hodnoty |
|---|---|
| oozie.coord.application.path | Určuje umístění souboru obsahujícího coordinator.xml koordinátorA Oozie, který se má spustit. |
| hiveDailyTableNamePrefix | Předpona použitá při dynamickém vytváření názvu tabulky pracovní tabulky. |
| hiveDataFolderPrefix | Předpona cesty, kde budou uloženy všechny pracovní tabulky. |
Nasazení a spuštění koordinátoru Oozie
Pokud chcete spustit kanál s koordinátorem, pokračujte podobným způsobem jako u pracovního postupu, s výjimkou toho, že pracujete ze složky o jednu úroveň nad složkou, která obsahuje váš pracovní postup. Tato konvence složek odděluje koordinátory od pracovních postupů na disku, takže můžete přidružit jednoho koordinátora k různým podřízeným pracovním postupům.
Pomocí SCP z místního počítače zkopírujte koordinační soubory do místního úložiště hlavního uzlu clusteru.
scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:~Připojte se k hlavnímu uzlu SSH.
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netZkopírujte koordinační soubory do HDFS.
hdfs dfs -put ./* /oozie/Spusťte koordinátora.
oozie job -config job.properties -runPomocí webové konzoly Oozie ověřte stav, tentokrát vyberte kartu Úlohy koordinátoru a pak všechny úlohy.
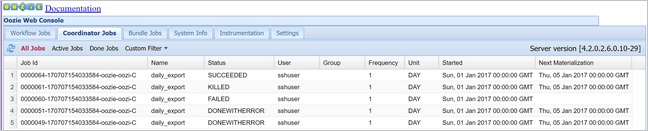
Výběrem instance koordinátoru zobrazte seznam plánovaných akcí. V tomto případě byste měli vidět čtyři akce s nominálními časy v rozsahu od 1. ledna 2017 do 4. ledna 2017.
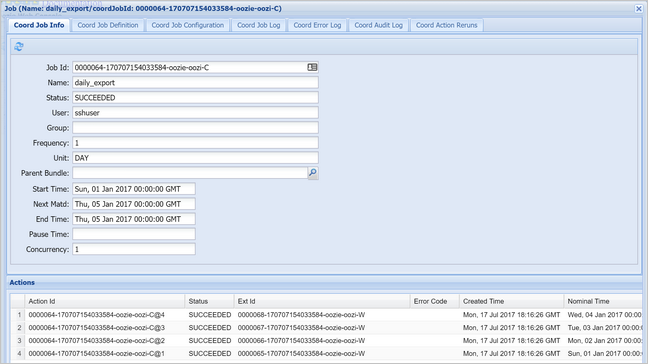
Každá akce v tomto seznamu odpovídá instanci pracovního postupu, která zpracovává data za jeden den, kdy je začátek tohoto dne označený nominálním časem.