Apache Phoenix ve službě Azure HDInsight
Apache Phoenix je opensourcová, masivně paralelní relační databázová vrstva založená na Apache HBase. Phoenix umožňuje používat dotazy podobné JAZYKu SQL přes HBase. Phoenix používá ovladače JDBC, které uživatelům umožňují vytvářet, odstraňovat, měnit tabulky SQL, indexy, zobrazení a sekvence a upsertovat řádky jednotlivě a hromadně. Phoenix používá nativní kompilaci noSQL místo použití MapReduce ke kompilaci dotazů, což umožňuje vytvářet aplikace s nízkou latencí nad HBase. Phoenix přidává koprocesory pro podporu spouštění kódu dodaného klientem v adresních prostorech serveru a spouští kód společně s daty. Tento přístup minimalizuje přenos dat klienta nebo serveru.
Apache Phoenix otevírá dotazy na velké objemy dat pro jiné vývojáře, kteří můžou místo programování používat syntaxi podobné JAZYKu SQL. Phoenix je vysoce optimalizovaný pro HBase, na rozdíl od jiných nástrojů, jako je Apache Hive a Apache Spark SQL. Výhodou pro vývojáře je psaní vysoce výkonných dotazů s mnohem méně kódem.
Když odešlete dotaz SQL, Phoenix dotaz zkompiluje do nativních volání HBase a spustí kontrolu (nebo plán) paralelně pro optimalizaci. Tato vrstva abstrakce uvolní vývojáře v psaní úloh MapReduce, aby se místo toho zaměřil na obchodní logiku a pracovní postup aplikace v oblasti úložiště Phoenix pro velké objemy dat.
Optimalizace výkonu dotazů a další funkce
Apache Phoenix přidává do dotazů HBase několik vylepšení výkonu a funkcí.
Sekundární indexy
HBase má jeden index, který je lexicicky seřazený na primárním klíči řádku. K těmto záznamům lze přistupovat pouze prostřednictvím klíče řádku. Přístup k záznamům přes jakýkoli jiný sloupec než klíč řádku vyžaduje kontrolu všech dat při použití požadovaného filtru. V sekundárním indexu sloupce nebo výrazy, které jsou indexovány, tvoří alternativní klíč řádku, což umožňuje vyhledávání a prohledání rozsahu na daném indexu.
Pomocí příkazu vytvořte sekundární index CREATE INDEX :
CREATE INDEX ix_purchasetype on SALTEDWEBLOGS (purchasetype, transactiondate) INCLUDE (bookname, quantity);
Tento přístup může přinést výrazné zvýšení výkonu při provádění dotazů s jedním indexováním. Tento typ sekundárního indexu je krytý index, který obsahuje všechny sloupce zahrnuté v dotazu. Proto není vyhledávání tabulky povinné a index splňuje celý dotaz.
Zobrazení
Phoenix views představují způsob, jak překonat omezení HBase, kdy se při vytváření více než 100 fyzických tabulek začne snižovat výkon. Phoenix views enable multiple virtual tables to share one underlying physical HBase table.
Vytvoření phoenixového zobrazení se podobá použití standardní syntaxe zobrazení SQL. Jedním z rozdílů je, že kromě sloupců zděděných ze základní tabulky můžete definovat sloupce pro zobrazení. Můžete také přidat nové KeyValue sloupce.
Tady je například fyzická tabulka s názvem product_metrics s následující definicí:
CREATE TABLE product_metrics (
metric_type CHAR(1) NOT NULL,
created_by VARCHAR,
created_date DATE NOT NULL,
metric_id INTEGER NOT NULL
CONSTRAINT pk PRIMARY KEY (metric_type, created_by, created_date, metric_id));
Definujte zobrazení nad touto tabulkou s dalšími sloupci:
CREATE VIEW mobile_product_metrics (carrier VARCHAR, dropped_calls BIGINT) AS
SELECT * FROM product_metrics
WHERE metric_type = 'm';
Pokud chcete později přidat další sloupce, použijte příkaz ALTER VIEW .
Přeskočit kontrolu
Přeskočení prohledávání používá k vyhledání jedinečných hodnot jeden nebo více sloupců složeného indexu. Na rozdíl od prohledávání rozsahu přeskočení skenování implementuje prohledávání uvnitř řádků a přináší vyšší výkon. Při prohledávání se první shodná hodnota přeskočí spolu s indexem, dokud se nenajde další hodnota.
Při prohledávání přeskočení se SEEK_NEXT_USING_HINT používá výčet filtru HBase. Pomocí SEEK_NEXT_USING_HINTfunkce přeskočit prohledávání sleduje, kterou sadu klíčů nebo rozsahy klíčů se prohledávají v jednotlivých sloupcích. Kontrola přeskočení pak vezme klíč, který se mu předal během vyhodnocení filtru, a určí, jestli se jedná o jednu z kombinací. Pokud ne, kontrola přeskočení vyhodnotí další nejvyšší klíč, na který přejdete.
Transakce
I když HBase poskytuje transakce na úrovni řádků, Phoenix se integruje s Tephra a přidává podporu transakcí napříč řádky a křížové tabulky s plnou sémantikou ACID .
Stejně jako u tradičních transakcí SQL umožňují transakce poskytované správcem transakcí Phoenix zajistit, aby atomická jednotka dat byla úspěšně upsertována, vrácení transakce zpět v případě, že operace upsert selže u jakékoli tabulky s podporou transakcí.
Pokud chcete povolit transakce Phoenix, přečtěte si dokumentaci k transakcím Apache Phoenix.
Pokud chcete vytvořit novou tabulku s povolenými transakcemi, nastavte TRANSACTIONAL vlastnost na true příkaz CREATE :
CREATE TABLE my_table (k BIGINT PRIMARY KEY, v VARCHAR) TRANSACTIONAL=true;
Chcete-li změnit existující tabulku na transakční, použijte stejnou vlastnost v ALTER příkazu:
ALTER TABLE my_other_table SET TRANSACTIONAL=true;
Poznámka:
Transakční tabulku nelze přepnout zpět na neaktuální.
Slané stoly
K hotspotování serveru oblasti může dojít při zápisu záznamů sekvenčními klíči do HBase. I když máte v clusteru možná více serverů oblastí, všechny zápisy probíhají jenom na jednom. Tato koncentrace vytváří problém s hotspotováním, kdy se místo úlohy zápisu distribuuje napříč všemi dostupnými servery oblastí jen jeden z nich zpracovává zatížení. Vzhledem k tomu, že každá oblast má předdefinovanou maximální velikost, když oblast dosáhne limitu velikosti, rozdělí se do dvou malých oblastí. V takovém případě jedna z těchto nových oblastí přebírá všechny nové záznamy a stává se novým hotspotem.
Pokud chcete tento problém zmírnit a dosáhnout lepšího výkonu, předem rozdělené tabulky tak, aby se všechny servery oblastí používaly stejně. Phoenix poskytuje slané tabulky, transparentně přidává slané bajty do klíče řádku pro určitou tabulku. Tabulka je předem rozdělená na hranice solných bajtů, aby se zajistilo rovnoměrné rozdělení zatížení mezi servery oblastí během počáteční fáze tabulky. Tento přístup distribuuje úlohu zápisu mezi všechny dostupné servery oblastí, což zlepšuje výkon zápisu a čtení. Chcete-li tabulku osolit, zadejte SALT_BUCKETS vlastnost tabulky při vytvoření tabulky:
CREATE TABLE Saltedweblogs (
transactionid varchar(500) Primary Key,
transactiondate Date NULL,
customerid varchar(50) NULL,
bookid varchar(50) NULL,
purchasetype varchar(50) NULL,
orderid varchar(50) NULL,
bookname varchar(50) NULL,
categoryname varchar(50) NULL,
invoicenumber varchar(50) NULL,
invoicestatus varchar(50) NULL,
city varchar(50) NULL,
state varchar(50) NULL,
paymentamount DOUBLE NULL,
quantity INTEGER NULL,
shippingamount DOUBLE NULL) SALT_BUCKETS=4;
Povolení a ladění Phoenixu pomocí Apache Ambari
Cluster HDInsight HBase obsahuje uživatelské rozhraní Ambari pro provádění změn konfigurace.
Pokud chcete povolit nebo zakázat Phoenix a řídit nastavení časového limitu dotazu Phoenixu, přihlaste se k webovému uživatelskému rozhraní Ambari (
https://YOUR_CLUSTER_NAME.azurehdinsight.net) pomocí přihlašovacích údajů uživatele Hadoop.V seznamu služeb v nabídce vlevo vyberte HBase a pak vyberte kartu Konfigurace .
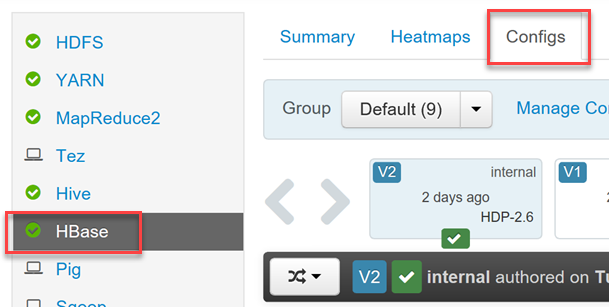
Vyhledejte oddíl konfigurace Phoenix SQL, který povolí nebo zakáže phoenix, a nastavte časový limit dotazu.