Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
V tomto rychlém startu použijete šablonu Azure Resource Manageru (šablonu ARM) k vytvoření clusteru Apache Spark ve službě Azure HDInsight. Pak vytvoříte soubor Jupyter Notebook a použijete ho ke spouštění dotazů Spark SQL na tabulky Apache Hive. Azure HDInsight je spravovaná opensourcová analytická služba určená pro podniky. Architektura Apache Spark pro HDInsight umožňuje rychlou analýzu dat a cluster computing pomocí zpracování v paměti. Jupyter Notebook umožňuje pracovat s daty, kombinovat kód s textem markdownu a provádět jednoduché vizualizace.
Pokud používáte více clusterů společně, budete chtít vytvořit virtuální síť a pokud používáte cluster Spark, budete také chtít použít konektor Hive Warehouse Connector. Další informace najdete v tématu Plánování virtuální sítě pro Azure HDInsight a integrace Apache Sparku a Apache Hivu s konektorem Hive Warehouse.
Šablona Azure Resource Manageru je soubor JSON (JavaScript Object Notation), který definuje infrastrukturu a konfiguraci projektu. Tato šablona používá deklarativní syntaxi. Popíšete zamýšlené nasazení, aniž byste museli psát posloupnost programovacích příkazů pro vytvoření nasazení.
Pokud vaše prostředí splňuje požadavky a jste obeznámeni s používáním šablon ARM, vyberte tlačítko Nasazení do Azure. Šablona se otevře v prostředí Azure Portal.

Požadavky
Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet.
Kontrola šablony
Šablona použitá v tomto rychlém startu je jednou z šablon pro rychlý start Azure.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"metadata": {
"_generator": {
"name": "bicep",
"version": "0.5.6.12127",
"templateHash": "4742950082151195489"
}
},
"parameters": {
"clusterName": {
"type": "string",
"metadata": {
"description": "The name of the HDInsight cluster to create."
}
},
"clusterLoginUserName": {
"type": "string",
"maxLength": 20,
"minLength": 2,
"metadata": {
"description": "These credentials can be used to submit jobs to the cluster and to log into cluster dashboards. The username must consist of digits, upper or lowercase letters, and/or the following special characters: (!#$%&'()-^_`{}~)."
}
},
"clusterLoginPassword": {
"type": "secureString",
"minLength": 10,
"metadata": {
"description": "The password must be at least 10 characters in length and must contain at least one digit, one upper case letter, one lower case letter, and one non-alphanumeric character except (single-quote, double-quote, backslash, right-bracket, full-stop). Also, the password must not contain 3 consecutive characters from the cluster username or SSH username."
}
},
"sshUserName": {
"type": "string",
"minLength": 2,
"metadata": {
"description": "These credentials can be used to remotely access the cluster. The sshUserName can only consit of digits, upper or lowercase letters, and/or the following special characters (%&'^_`{}~). Also, it cannot be the same as the cluster login username or a reserved word"
}
},
"sshPassword": {
"type": "secureString",
"maxLength": 72,
"minLength": 6,
"metadata": {
"description": "SSH password must be 6-72 characters long and must contain at least one digit, one upper case letter, and one lower case letter. It must not contain any 3 consecutive characters from the cluster login name"
}
},
"location": {
"type": "string",
"defaultValue": "[resourceGroup().location]",
"metadata": {
"description": "Location for all resources."
}
},
"headNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E8_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the headnode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
},
"workerNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E8_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the workernode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
}
},
"resources": [
{
"type": "Microsoft.Storage/storageAccounts",
"apiVersion": "2021-08-01",
"name": "[format('storage{0}', uniqueString(resourceGroup().id))]",
"location": "[parameters('location')]",
"sku": {
"name": "Standard_LRS"
},
"kind": "StorageV2"
},
{
"type": "Microsoft.HDInsight/clusters",
"apiVersion": "2021-06-01",
"name": "[parameters('clusterName')]",
"location": "[parameters('location')]",
"properties": {
"clusterVersion": "4.0",
"osType": "Linux",
"tier": "Standard",
"clusterDefinition": {
"kind": "spark",
"configurations": {
"gateway": {
"restAuthCredential.isEnabled": true,
"restAuthCredential.username": "[parameters('clusterLoginUserName')]",
"restAuthCredential.password": "[parameters('clusterLoginPassword')]"
}
}
},
"storageProfile": {
"storageaccounts": [
{
"name": "[replace(replace(reference(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id)))).primaryEndpoints.blob, 'https://', ''), '/', '')]",
"isDefault": true,
"container": "[parameters('clusterName')]",
"key": "[listKeys(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id))), '2021-08-01').keys[0].value]"
}
]
},
"computeProfile": {
"roles": [
{
"name": "headnode",
"targetInstanceCount": 2,
"hardwareProfile": {
"vmSize": "[parameters('headNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
},
{
"name": "workernode",
"targetInstanceCount": 2,
"hardwareProfile": {
"vmSize": "[parameters('workerNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
}
]
}
},
"dependsOn": [
"[resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id)))]"
]
}
],
"outputs": {
"storage": {
"type": "object",
"value": "[reference(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id))))]"
},
"cluster": {
"type": "object",
"value": "[reference(resourceId('Microsoft.HDInsight/clusters', parameters('clusterName')))]"
}
}
}
V šabloně jsou definované dva prostředky Azure:
- Microsoft.Storage/storageAccounts: Vytvořte účet úložiště Azure.
- Microsoft.HDInsight/cluster: Vytvořte cluster HDInsight.
Nasazení šablony
Klikněte na tlačítko Nasadit do Azure, přihlaste se k Azure a otevřete šablonu ARM.
Zadejte nebo vyberte tyto hodnoty:
Vlastnost Popis Předplatné V rozevíracím seznamu vyberte předplatné Azure, které se používá pro cluster. Skupina prostředků V rozevíracím seznamu vyberte existující skupinu prostředků nebo vyberte možnost Vytvořit novou. Umístění Tato hodnota se automaticky vyplní podle polohy skupiny prostředků. Název clusteru Zadejte globálně jedinečný název. Pro tuto šablonu používejte jenom malá písmena a číslice. Uživatelské jméno pro přihlášení do clusteru Zadejte uživatelské jméno, výchozí hodnota je admin.Heslo přihlášení clusteru Zadejte heslo. Heslo musí mít délku nejméně 10 znaků a musí obsahovat alespoň jednu číslici, jedno velké písmeno a jedno malé písmeno, jeden nealnumerický znak (s výjimkou znaků ' ` ").Uživatelské jméno SSH Zadejte uživatelské jméno, výchozí hodnota je sshuser.Heslo SSH Zadejte heslo. 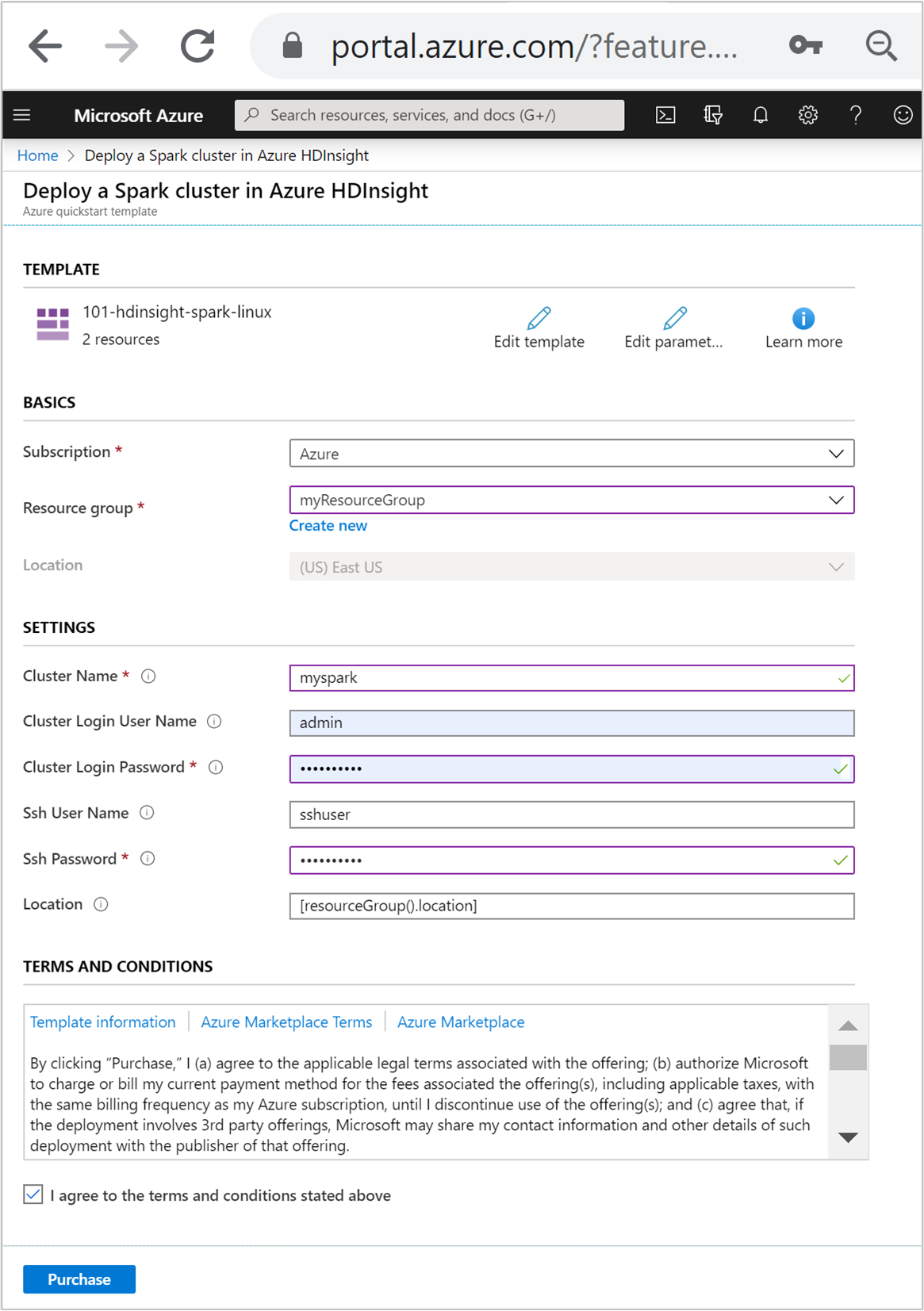
Přečtěte si podmínky a ujednání. Pak vyberte Souhlasím s podmínkami a ujednáními uvedenými výše a pak nákupem. Zobrazí se oznámení o probíhajícím nasazení. Vytvoření clusteru trvá přibližně 20 minut.
Pokud narazíte na problém s vytvářením clusterů HDInsight, může to být, že nemáte správná oprávnění k tomu. Další informace najdete v tématu popisujícím požadavky na řízení přístupu.
Kontrola nasazených prostředků
Po vytvoření clusteru obdržíte oznámení o úspěšném nasazení s odkazem Přejít k prostředku . Stránka skupiny prostředků zobrazí seznam nového clusteru HDInsight a výchozího úložiště přidruženého ke clusteru. Každý cluster má službu Azure Storage nebo závislost Azure Data Lake Storage Gen2 . Označuje se jako výchozí účet úložiště. Cluster HDInsight a jeho výchozí účet úložiště musí být umístěny ve stejné oblasti Azure. Odstranění clusterů neodstraní závislost účtu úložiště. Označuje se jako výchozí účet úložiště. Cluster HDInsight a jeho výchozí úložný účet musí být umístěny ve stejné oblasti Azure. Odstraněním clusterů se účet úložiště neodstraní.
Vytvoření souboru Jupyter Notebook
Jupyter Notebook je interaktivní prostředí poznámkového bloku, které podporuje různé programovací jazyky. Soubor Jupyter Notebook můžete použít k interakci s daty, kombinování kódu s textem markdownu a provádění jednoduchých vizualizací.
Otevřete Azure Portal.
Vyberte cluster HDInsight a poté vyberte cluster, který jste vytvořili.
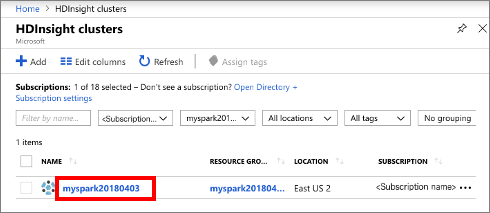
Na portálu v sekci Řídicí panely clusteru vyberte Jupyter Notebook. Po zobrazení výzvy zadejte přihlašovací údaje clusteru.
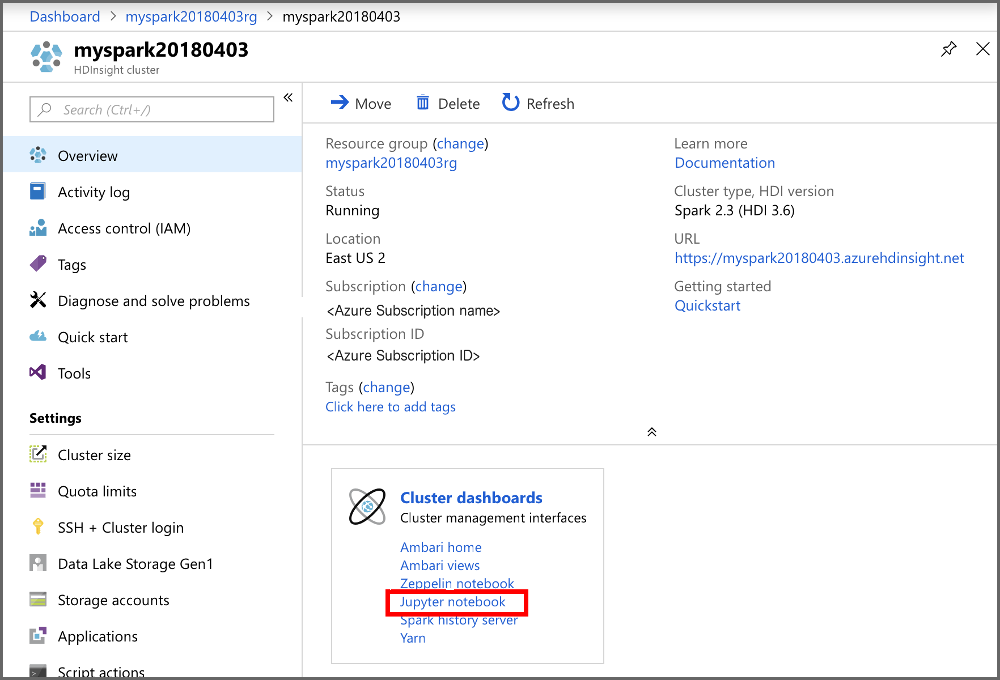
Vyberte Nový>PySpark a vytvořte poznámkový blok.
Nový poznámkový blok se vytvoří a otevře s názvem Bez názvu (Bez názvu.pynb).
Spouštění příkazů Apache Spark SQL
Jazyk SQL (Structured Query Language) je nejběžnějším a široce používaným jazykem pro dotazování a transformaci dat. Spark SQL funguje jako rozšíření Apache Spark pro zpracování strukturovaných dat a používá známou syntaxi jazyka SQL.
Ověřte, že je jádro připravené. Jádro bude připravené, až se vedle názvu jádra v poznámkovém bloku zobrazí prázdný kroužek. Plný kruh označuje, že je jádro zaneprázdněno.
 alt-text="Stav jádra" border="true":::
alt-text="Stav jádra" border="true":::Při prvním spuštění poznámkového bloku jádro provede některé úlohy na pozadí. Počkejte, až bude jádro připravené.
Do prázdné buňky vložte následující kód a stisknutím SHIFT + ENTER kód spusťte. Příkaz vypíše tabulky Hive v clusteru:
%%sql SHOW TABLESPři použití souboru Jupyter Notebook s clusterem HDInsight získáte přednastavenou
sparkrelaci, kterou můžete použít ke spouštění dotazů Hive pomocí Spark SQL.%%sqlinstruuje poznámkový blok Jupyter, aby použil přednastavenou relacisparkke spuštění dotazu Hive. Dotaz načte prvních 10 řádků z tabulky Hive (hivesampletable), která je ve výchozím nastavení k dispozici na všech clusterech HDInsight. Při prvním odeslání dotazu vytvoří Jupyter aplikaci Spark pro poznámkový blok. Dokončení trvá přibližně 30 sekund. Jakmile je aplikace Spark připravená, dotaz se spustí přibližně za sekundu a vytvoří výsledky. Výstup vypadá takto: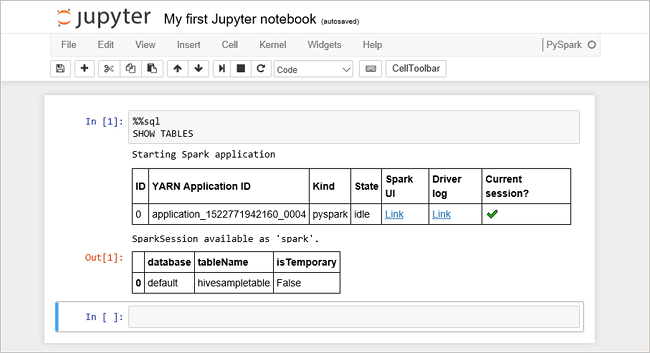 y v HDInsight" border="true":::
y v HDInsight" border="true":::Při každém spuštění dotazu v Jupyter se v názvu okna webového prohlížeče zobrazí stav (Busy) (Zaneprázdněn) společně s názvem poznámkového bloku. Zobrazí se také plný kroužek vedle textu PySpark v pravém horním rohu.
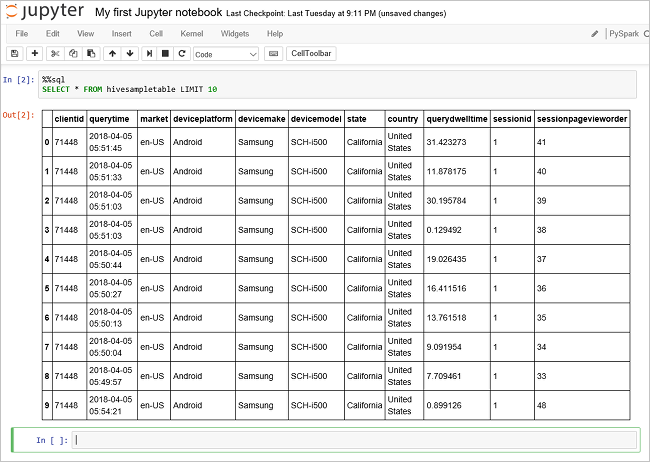
Spuštěním dalšího dotazu zobrazíte data v tabulce
hivesampletable.%%sql SELECT * FROM hivesampletable LIMIT 10Obrazovka by se měla aktualizovat a zobrazit výstup dotazu.
 Insight" border="true":::
Insight" border="true":::V nabídce Soubor poznámkového bloku vyberte Zavřít a zastavit. Vypnutí poznámkového bloku uvolní prostředky clusteru, včetně aplikace Spark.
Vyčisti prostředky
Po dokončení rychlého startu možná budete chtít cluster odstranit. S HDInsight jsou vaše data uložená ve službě Azure Storage, takže můžete cluster bezpečně odstranit, když se nepoužívá. Za cluster HDInsight se vám také účtují poplatky, i když se nepoužívá. Vzhledem k tomu, že poplatky za cluster jsou mnohokrát vyšší než poplatky za úložiště, dává smysl odstranit clustery, když se nepoužívají.
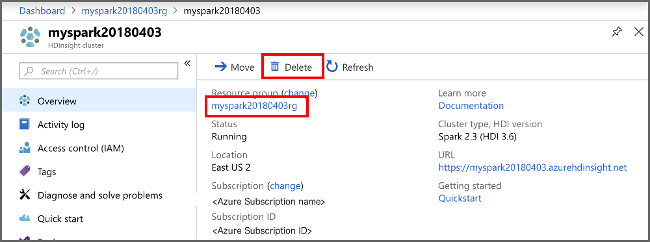
Na webu Azure Portal přejděte do clusteru a vyberte Odstranit.
 sight cluster" border="true":::
sight cluster" border="true":::
Můžete také výběrem názvu skupiny prostředků otevřít stránku skupiny prostředků a pak vybrat Odstranit skupinu prostředků. Odstraněním skupiny prostředků odstraníte cluster HDInsight i výchozí účet úložiště.
Další kroky
V tomto rychlém startu jste zjistili, jak vytvořit cluster Apache Spark ve službě HDInsight a spustit základní dotaz Spark SQL. V dalším kurzu se dozvíte, jak pomocí clusteru HDInsight spouštět interaktivní dotazy na ukázková data.