Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
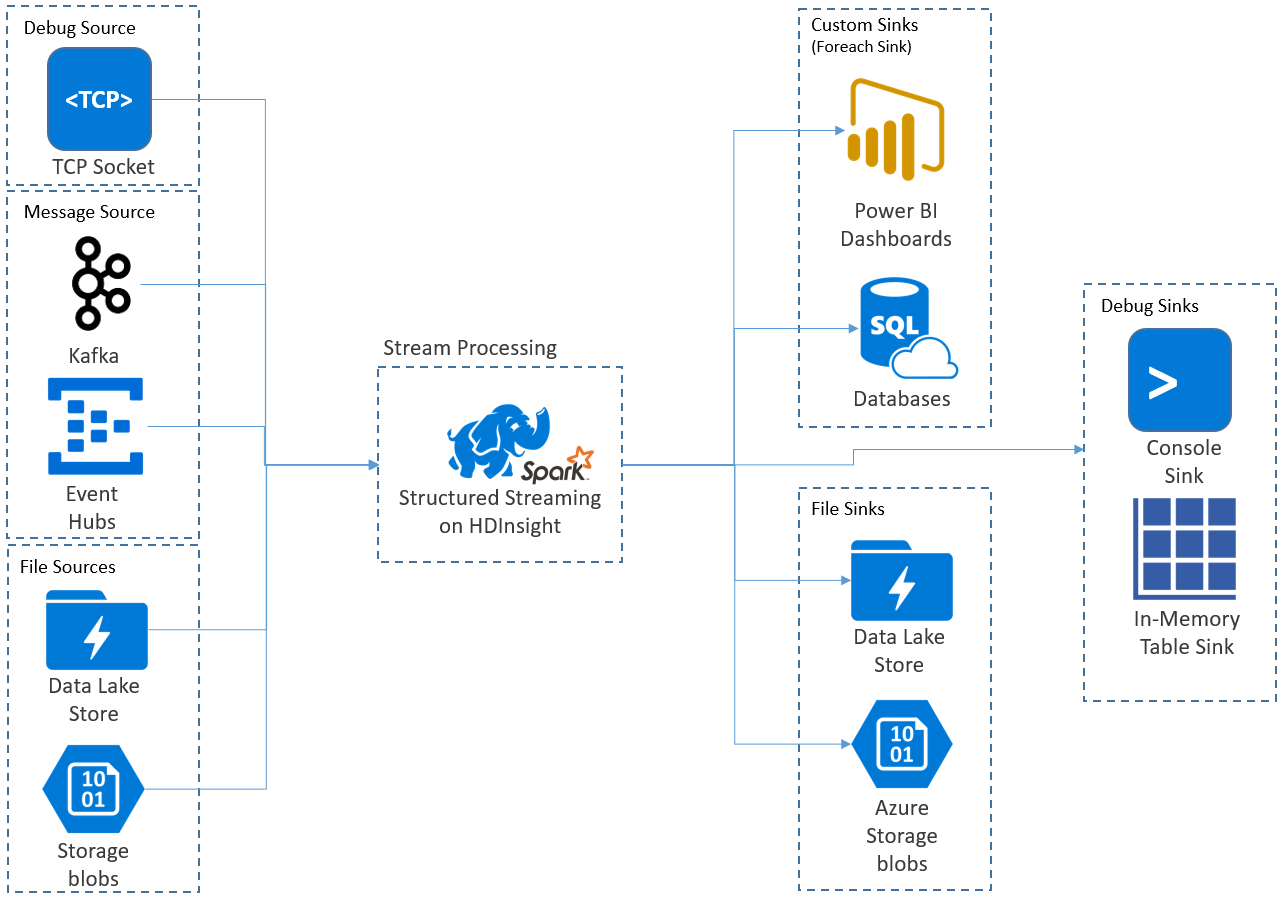
Strukturované streamování Apache Spark umožňuje implementovat škálovatelné aplikace odolné proti chybám pro zpracování datových proudů. Strukturované streamování je postavené na modulu Spark SQL a vylepšuje konstrukce z datových rámců a datových sad Spark SQL, takže streamované dotazy můžete psát stejným způsobem jako dávkové dotazy.
Aplikace strukturovaného streamování běží v clusterech HDInsight Spark a připojují se ke streamování dat z Apache Kafka, soketu TCP (pro účely ladění), Azure Storage nebo Azure Data Lake Storage. Druhé dvě možnosti, které spoléhají na externí služby úložiště, umožňují sledovat nové soubory přidané do úložiště a zpracovávat jejich obsah, jako by byly streamovány.
Strukturované streamování vytvoří dlouhotrvající dotaz, během kterého můžete na vstupní data použít operace, jako jsou výběr, projekce, agregace, použití oken a spojení streamovaného datového rámce s referenčními datovými rámci. Dále vypíšete výsledky do úložiště souborů (objekty blob služby Azure Storage nebo Data Lake Storage) nebo do jakéhokoli úložiště dat pomocí vlastního kódu (například SQL Database nebo Power BI). Strukturované streamování také poskytuje výstup do konzoly pro místní ladění a do tabulky v paměti, abyste viděli data vygenerovaná pro ladění ve službě HDInsight.
Poznámka:
Strukturované streamování Sparku nahrazuje streamování Sparku (DStreams). V budoucnu bude strukturované streamování dostávat vylepšení a údržbu, zatímco DStreams bude pouze v režimu údržby. Strukturované streamování v současné době není tak funkčně kompletní jako DStreams pro zdroje a jímky, které podporuje přímo, proto zvažte své požadavky, abyste vybrali vhodnou možnost zpracování streamů v nástroji Spark.
Streamy jako tabulky
Strukturované streamování Sparku představuje datový proud jako tabulku, která je neomezená, tedy znamená, že tabulka stále roste, jakmile dorazí nová data. Tato vstupní tabulka se průběžně zpracovává dlouhotrvajícím dotazem a výsledky odeslané do výstupní tabulky:

Ve strukturovaném streamování data přicházejí do systému a okamžitě se ingestují do vstupní tabulky. Zapisujete dotazy (pomocí rozhraní API datového rámce a datové sady), které provádějí operace s touto vstupní tabulkou. Výstup dotazu vrátí jinou tabulku, tabulku výsledků. Tabulka výsledků obsahuje výsledky dotazu, ze kterých nakreslíte data pro externí úložiště dat, jako je relační databáze. Načasování zpracování dat ze vstupní tabulky je řízeno intervalem aktivační události. Ve výchozím nastavení je interval triggeru nulový, takže strukturované streamování se pokusí zpracovat data, jakmile dorazí. V praxi to znamená, že jakmile Strukturované streamování dokončí zpracování běhu předchozího dotazu, zahájí další zpracování s nově přijatými daty. Můžete nakonfigurovat spouštěč tak, aby se spouštěl v intervalech, takže streamovaná data budou zpracovávána v časově založených dávkách.
Data v tabulkách výsledků můžou obsahovat pouze data, která jsou nová od posledního zpracování dotazu (režim připojení) nebo se tabulka může aktualizovat pokaždé, když jsou nová data, aby tabulka obsahovala všechna výstupní data od začátku streamovacího dotazu (úplný režim).
Režim přidání
V režimu připojení se do tabulky výsledků zapisují pouze řádky přidané do tabulky výsledků od posledního spuštění dotazu a zapisují se do externího úložiště. Například nejjednodušší dotaz pouze zkopíruje všechna data ze vstupní tabulky do tabulky výsledků beze změny. Při každém uplynutí intervalu aktivační události se nová data zpracovávají a řádky představující nová data se zobrazí v tabulce výsledků.
Představte si scénář, ve kterém zpracováváte telemetrii ze snímačů teploty, jako je termostat. Předpokládejme, že první trigger zpracovával jednu událost v okamžiku 00:01 pro zařízení 1 se čtením teploty 95 stupňů. V prvním triggeru dotazu se v tabulce výsledků zobrazí pouze řádek s časem 00:01. V okamžiku 00:02, kdy přijde jiná událost, je jediným novým řádkem řádek s časem 00:02, takže tabulka výsledků by obsahovala pouze tento jeden řádek.
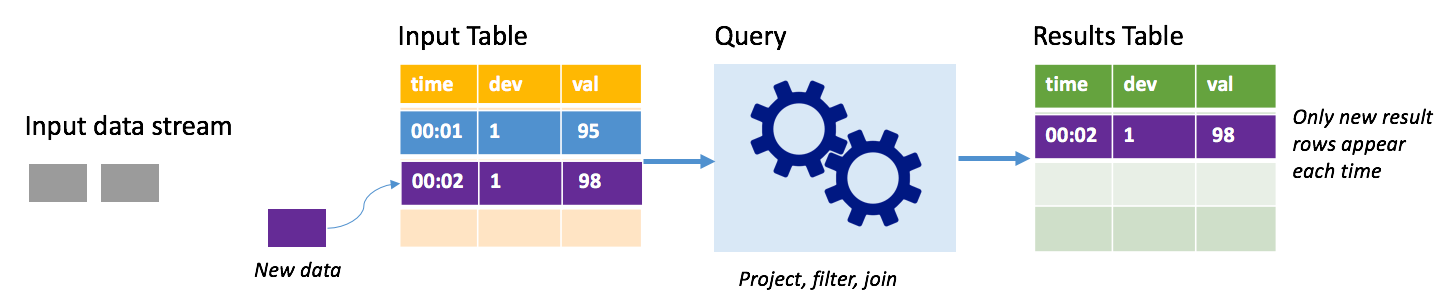
Při použití režimu přidání by dotaz použil projekce (výběr sloupců, o které se stará), filtrování (výběr pouze řádků, které splňují určité podmínky) nebo spojení (rozšíření dat o data ze statické vyhledávací tabulky). Režim přidávání usnadňuje odeslání jenom relevantních nových datových bodů do externího úložiště.
Režim dokončení
Představte si stejný scénář, tentokrát pomocí režimu dokončení. V úplném režimu se celá výstupní tabulka aktualizuje na každém triggeru, takže tabulka obsahuje data nejen z posledního spuštění triggeru, ale ze všech spuštění. Úplný režim můžete použít ke zkopírování dat nezměněných ze vstupní tabulky do tabulky výsledků. Při každém aktivovaném spuštění se nové řádky výsledků zobrazí společně se všemi předchozími řádky. Tabulka výsledků výstupu nakonec uloží všechna data shromážděná od začátku dotazu a nakonec dojde k nedostatku paměti. Úplný režim je určený pro agregační dotazy, které nějakým způsobem shrnují příchozí data, takže při každé aktivaci se tabulka výsledků aktualizuje novým souhrnem.
Předpokládejme, že zatím jsou data za pět sekund již zpracována a je čas zpracovat data za šestou sekundu. Vstupní tabulka obsahuje události pro čas 00:01 a čas 00:03. Cílem tohoto ukázkového dotazu je poskytnout průměrnou teplotu zařízení každých pět sekund. Implementace tohoto dotazu použije agregaci, která vezme všechny hodnoty, které spadají do každého 5sekundového okna, zprůměruje teplotu a vytvoří řádek pro průměrnou teplotu v daném intervalu. Na konci prvního 5sekundového intervalu jsou dvě n-tice: (00:01, 1, 95) a (00:03, 1, 98). Takže pro okno 00:00-00:05 agregace vytvoří řazenou kolekci členů s průměrnou teplotou 96,5 stupňů. V dalším 5sekundovém okně je v čase 00:06 pouze jeden datový bod, takže výsledná průměrná teplota je 98 stupňů. V čase 00:10 má tabulka výsledků řádky pro obě okna 00:00-00:05 a 00:05-00:10, protože dotaz zahrnuje všechny agregované řádky, nejen nové. Proto se tabulka výsledků bude i nadále zvětšovat při přidání nových oken.
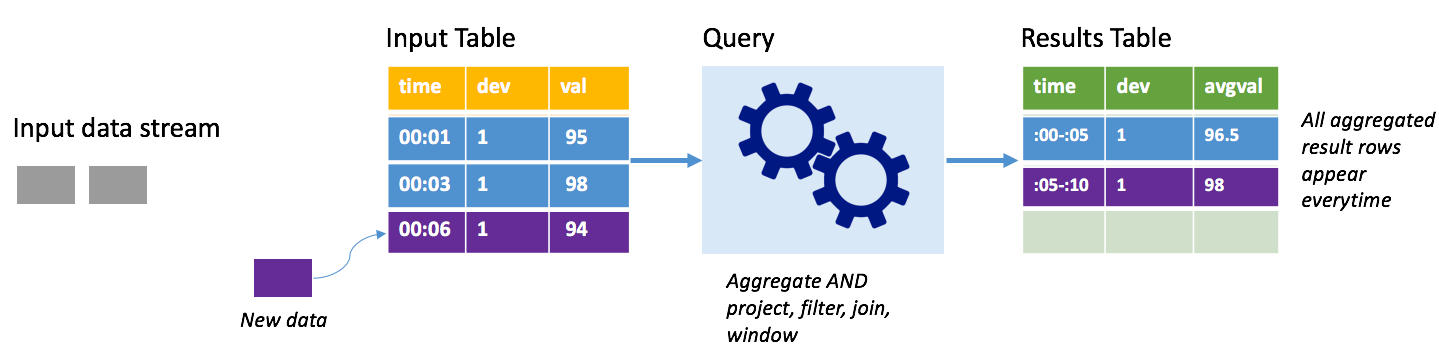
Ne všechny dotazy používající úplný režim způsobí, že se tabulka zvětší bez hranic. V předchozím příkladu zvažte, že místo průměrování teploty podle časového intervalu se průměruje podle ID zařízení. Výsledná tabulka obsahuje pevný počet řádků (jeden na zařízení) s průměrnou teplotou zařízení ve všech datových bodech přijatých z tohoto zařízení. Při přijetí nových teplot se tabulka výsledků aktualizuje tak, aby průměry v tabulce byly vždy aktuální.
Komponenty aplikace strukturovaného streamování Sparku
Jednoduchý ukázkový dotaz může shrnout hodnoty teploty podle hodinových oken. V tomto případě se data ukládají v souborech JSON ve službě Azure Storage (připojené jako výchozí úložiště pro cluster HDInsight):
{"time":1469501107,"temp":"95"}
{"time":1469501147,"temp":"95"}
{"time":1469501202,"temp":"95"}
{"time":1469501219,"temp":"95"}
{"time":1469501225,"temp":"95"}
Tyto soubory JSON jsou uložené v temps podsložce pod kontejnerem clusteru HDInsight.
Definování vstupního zdroje
Nejprve nakonfigurujte datový rámec, který popisuje zdroj dat a všechna nastavení vyžadovaná tímto zdrojem. Tento příklad načítá ze souborů JSON ve službě Azure Storage a použije na ně schéma v době čtení.
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
//Cluster-local path to the folder containing the JSON files
val inputPath = "/temps/"
//Define the schema of the JSON files as having the "time" of type TimeStamp and the "temp" field of type String
val jsonSchema = new StructType().add("time", TimestampType).add("temp", StringType)
//Create a Streaming DataFrame by calling readStream and configuring it with the schema and path
val streamingInputDF = spark.readStream.schema(jsonSchema).json(inputPath)
Použít dotaz
Dále použijte dotaz, který obsahuje požadované operace s datovým rámcem pro streamování. V tomto případě agregace seskupí všechny řádky do 1hodinových oken a pak vypočítá minimální, průměrnou a maximální teplotu v tomto 1hodinovém intervalu.
val streamingAggDF = streamingInputDF.groupBy(window($"time", "1 hour")).agg(min($"temp"), avg($"temp"), max($"temp"))
Definování výstupní jímky
Dále definujte cíl řádků, které jsou přidány do tabulky výsledků v rámci každého intervalu triggeru. Tento příklad pouze vypíše všechny řádky do tabulky temps v paměti, kterou můžete později dotazovat pomocí SparkSQL. Úplný výstupní režim zajišťuje, že všechny řádky pro všechna okna jsou vždy vyvedeny.
val streamingOutDF = streamingAggDF.writeStream.format("memory").queryName("temps").outputMode("complete")
Spuštění dotazu
Spusťte streamovací dotaz a spusťte ho, dokud se neobdrží signál ukončení.
val query = streamingOutDF.start()
Zobrazení výsledků
Když je dotaz spuštěný, ve stejné SparkSession můžete spustit dotaz SparkSQL na temps tabulku, ve které jsou uloženy výsledky dotazu.
select * from temps
Tento dotaz poskytuje výsledky podobné následujícímu:
| okno | min(temp) | průměr(teplota) | max(temp) |
|---|---|---|---|
| {u'start': u'2016-07-26T02:00:00.000Z', u'end'... | 95 | 95.231579 | 99 |
| {u'start': u'2016-07-26T03:00:00.000Z', u'end'... | 95 | 96.023048 | 99 |
| {u'start': u'2016-07-26T04:00:00.000Z', u'end'... | 95 | 96.797133 | 99 |
| {u'start': u'2016-07-26T05:00:00.000Z', u'end'... | 95 | 96.984639 | 99 |
| {u'start': u'2016-07-26T06:00:00.000Z', u'end'... | 95 | 97.014749 | 99 |
| {u'start': u'2016-07-26T07:00:00.000Z', u'end'... | 95 | 96.980971 | 99 |
| {u'start': u'2016-07-26T08:00:00.000Z', u'end'... | 95 | 96.965997 | 99 |
Podrobnosti o rozhraní API strukturovaného streamu Sparku spolu se vstupními zdroji dat, operacemi a výstupními jímky, které podporuje, najdete v průvodci programováním strukturovaného streamování Apache Sparku.
Kontrolní body a protokoly o zápisu předem
Aby bylo možné zajistit odolnost a odolnost proti chybám, strukturované streamování spoléhá na vytváření kontrolních bodů , aby bylo zajištěno, že zpracování datových proudů může pokračovat bez přerušení, a to i při selhání uzlů. Ve službě HDInsight Spark vytváří kontrolní body pro trvalé úložiště, a to buď Azure Storage, nebo Data Lake Storage. Tyto kontrolní body ukládají informace o průběhu dotazu streamování. Strukturované streamování navíc používá protokol WAL (write-ahead). Wal zaznamenává přijatá data, která byla přijata, ale ještě nebyla zpracována dotazem. Pokud dojde k selhání a zpracování se restartuje z WAL, neztratí se všechny události přijaté ze zdroje.
Nasazení aplikací Spark Streaming
Aplikaci Spark Streaming obvykle sestavíte místně do souboru JAR a pak ji nasadíte do Sparku ve službě HDInsight zkopírováním souboru JAR do výchozího úložiště připojeného ke clusteru HDInsight. Aplikaci můžete spustit pomocí rozhraní Apache Livy REST API dostupných z vašeho clusteru pomocí operace POST. Tělo POST obsahuje dokument JSON, který poskytuje cestu k vašemu SOUBORU JAR, název třídy, jejíž hlavní metoda definuje a spouští streamovací aplikaci, a volitelně požadavky na prostředky úlohy (například počet exekutorů, paměť a jádra) a všechna nastavení konfigurace, která vyžaduje kód aplikace.
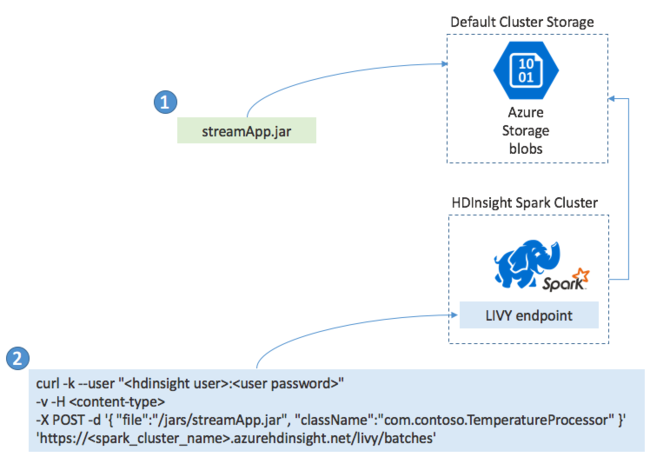
Stav všech aplikací lze také zkontrolovat pomocí požadavku GET na koncový bod LIVY. Nakonec můžete spuštěnou aplikaci ukončit tak, že vydáte požadavek DELETE na koncový bod LIVY. Podrobnosti o rozhraní LIVY API najdete v tématu Vzdálené úlohy s Apache LIVY.