Vysoká dostupnost služby IoT Hub a zotavení po havárii
Jako první krok k implementaci odolného řešení IoT musí architekti, vývojáři a vlastníci firmy definovat cíle dostupnosti pro řešení, která vytvářejí. Tyto cíle je možné definovat primárně na základě konkrétních obchodních cílů pro každý scénář. V tomto kontextu článek Technické pokyny k provozní kontinuitě Azure popisuje obecnou architekturu, která vám pomůže přemýšlet o kontinuitě podnikových procesů a zotavení po havárii. Dokument o zotavení po havárii a vysoké dostupnosti pro aplikace Azure poskytuje pokyny k architektuře strategií pro aplikace Azure pro dosažení vysoké dostupnosti (HA) a zotavení po havárii (DR).
Tento článek popisuje funkce vysoké dostupnosti a zotavení po havárii nabízené speciálně službou IoT Hub. Mezi obecné oblasti, které jsou popsány v tomto článku, patří:
- Vysoká dostupnost v rámci oblasti
- Zotavení po havárii napříč oblastmi
- Dosažení vysoké dostupnosti napříč oblastmi
V závislosti na cílech dostupnosti, které definujete pro vaše řešení IoT, byste měli určit, které z možností uvedených v tomto článku nejlépe vyhovují vašim obchodním cílům. Začlenění některé z těchto alternativ ha/DR do vašeho řešení IoT vyžaduje pečlivé vyhodnocení kompromisů mezi těmito:
- Úroveň odolnosti, kterou potřebujete
- Složitost implementace a údržby
- Dopad COGS
Vysoká dostupnost v rámci oblasti
Služba IoT Hub poskytuje vysokou dostupnost v rámci oblasti implementací redundance téměř ve všech vrstvách služby. Smlouva SLA publikovaná službou IoT Hub se dosahuje využitím těchto redundancí. Vývojáři řešení IoT nevyžadují žádnou další práci, aby mohli využívat tyto funkce vysoké dostupnosti. I když IoT Hub nabízí rozumně vysokou záruku doby provozu, přechodné chyby se stále dají očekávat stejně jako u jakékoli distribuované výpočetní platformy. Pokud teprve začínáte s migrací řešení do cloudu z místního řešení, je potřeba zaměřit se na optimalizaci "střední doby mezi selháními" na "střední dobu obnovení". Jinými slovy, přechodná selhání se při provozu s cloudem ve mixu považují za normální. Aby bylo možné řešit přechodné selhání, musí být pro komponenty pracující s cloudovou aplikací integrované vhodné vzory opakování.
Zóny dostupnosti
IoT Hub podporuje zóny dostupnosti Azure. Zóna dostupnosti je nabídka s vysokou dostupností, která chrání vaše aplikace a data před selháními datacentra. Oblast s podporou zóny dostupnosti zahrnuje tři zóny podporující danou oblast. Každá zóna poskytuje jedno nebo více datacenter, každé v jedinečném fyzickém umístění s nezávislým napájením, chlazením a sítěmi. Tato konfigurace poskytuje replikaci a redundanci v rámci oblasti.
Zóny dostupnosti poskytují dvě výhody: odolnost dat a plynulejší nasazení.
Odolnost dat pochází z nahrazení základních služeb úložiště úložiště podporovanými zónami dostupnosti. Odolnost dat je důležitá pro řešení IoT, protože tato řešení často pracují ve složitých, dynamických a nejistých prostředích, kde selhání nebo přerušení mohou mít významné důsledky. Bez ohledu na to, jestli řešení IoT podporuje výrobní prostředí, maloobchodní prostředí nebo prostředí restaurací, zdravotnické systémy nebo infrastrukturu, je dostupnost a kvalita dat nezbytná k zotavení od selhání a k poskytování spolehlivých a konzistentních služeb.
Plynulejší nasazení pocházejí z nahrazení základního hardwaru datového centra novějším hardwarem, který podporuje zóny dostupnosti. Tato vylepšení hardwaru minimalizují dopad zákazníků na odpojení zařízení a opětovné připojení a také další výpadky související s nasazením. Technický tým IoT Hubu nasadí do každého centra IoT každý měsíc několik aktualizací, a to z bezpečnostních důvodů i z důvodu vylepšení funkcí. Hardware podporovaný zónami dostupnosti je rozdělený na 15 aktualizačních domén, takže každá aktualizace bude plynulejší a bude mít minimální dopad na vaše pracovní postupy. Další informace o aktualizačních doménách najdete v tématu Skupiny dostupnosti.
Podpora zón dostupnosti pro IoT Hub je povolená automaticky pro nové prostředky IoT Hubu vytvořené v následujících oblastech Azure:
| Oblast | Odolnost dat | Plynulejší nasazení |
|---|---|---|
| Austrálie – východ | ||
| Brazílie – jih | ||
| Střední Kanada | ||
| Indie – střed | ||
| USA – střed | ||
| East US | ||
| Francie – střed | ||
| Německo – středozápad | ||
| Japonsko – východ | ||
| Jižní Korea – střed | ||
| Severní Evropa | ||
| Norsko – východ | ||
| Střední Katar | ||
| USA – středojižní | ||
| Southeast Asia | ||
| Velká Británie – jih | ||
| Západní Evropa | ||
| Západní USA 2 | ||
| USA – západ 3 |
Zotavení po havárii napříč oblastmi
Může se stát, že dojde k několika výjimečným situacím, kdy dojde k rozšířenému výpadku datacentra kvůli selháním napájení nebo jiným selháním souvisejícím s fyzickými prostředky. Takové události jsou vzácné, během kterých funkce vysoké dostupnosti v rámci oblasti popsaná dříve nemusí vždy pomoct. IoT Hub poskytuje několik řešení pro zotavení z takových rozšířených výpadků.
Možnosti obnovení dostupné zákazníkům v takové situaci jsou převzetí služeb při selhání iniciované Microsoftem a ruční převzetí služeb při selhání. Základním rozdílem mezi těmito dvěma je to, že Společnost Microsoft iniciuje první a uživatel iniciuje druhou. Ruční převzetí služeb při selhání také poskytuje nižší cíl doby obnovení (RTO) v porovnání s možností převzetí služeb při selhání iniciované Microsoftem. Konkrétní RTO nabízené s každou možností jsou popsány v následujících částech. Když se provede převzetí služeb při selhání centra IoT z primární oblasti, stane se centrum plně funkční v odpovídající geografické spárované oblasti Azure.
Obě tyto možnosti převzetí služeb při selhání nabízejí následující cíle bodů obnovení (RPO):
| Datový typ | Cíle bodu obnovení (RPO) |
|---|---|
| Registr identit | 0–5 minut ztráty dat |
| Data dvojčete zařízení | 0–5 minut ztráty dat |
| Zprávyz cloudu na zařízení 1 | 0–5 minut ztráty dat |
| Nadřazené1 úlohy a úlohy zařízení | 0–5 minut ztráty dat |
| Zprávy typu zařízení-cloud | Všechny nepřečtené zprávy se ztratí. |
| Zprávy zpětné vazby z cloudu na zařízení | Všechny nepřečtené zprávy se ztratí. |
1Zprávy typu cloud-zařízení a nadřazené úlohy se v rámci ručního převzetí služeb při selhání neobnoví.
Po dokončení operace převzetí služeb při selhání centra IoT se očekává, že všechny operace ze zařízení a back-endových aplikací budou fungovat i bez nutnosti ručního zásahu. To znamená, že zprávy typu zařízení-cloud by měly dál fungovat a celý registr zařízení je nedotčený. Události generované přes Event Grid je možné využívat prostřednictvím stejných předplatných nakonfigurovaných dříve, dokud budou tato předplatná Event Gridu nadále dostupná. Pro vlastní koncové body se nevyžaduje žádné další zpracování.
Upozornění
- Název a koncový bod integrovaného koncového bodu událostí služby IoT Hub kompatibilní se službou Event Hub po převzetí služeb při selhání. Při příjmu telemetrických zpráv z integrovaného koncového bodu pomocí klienta služby Event Hubs nebo hostitele procesoru událostí byste měli k navázání připojení použít službu IoT Hub připojovací řetězec. Tím zajistíte, že back-endové aplikace budou dál fungovat bez nutnosti ručního zásahu po převzetí služeb při selhání. Pokud ve své aplikaci použijete přímo název a koncový bod kompatibilní s centrem událostí, budete muset po převzetí služeb při selhání pokračovat v operacích načtení nového koncového bodu kompatibilního s centrem událostí. Další informace najdete v tématu Ruční převzetí služeb při selhání a Centrum událostí.
- Pokud k připojení integrovaného koncového bodu událostí používáte Azure Functions nebo Azure Stream Analytics, možná budete muset provést restartování. Důvodem je to, že během předchozích posunů převzetí služeb při selhání už nejsou platné.
- Při směrování do úložiště doporučujeme vypisovat objekty blob nebo soubory a pak je iterovat, abyste zajistili, že se všechny objekty blob nebo soubory čtou, aniž byste museli provádět předpoklady oddílu. Rozsah oddílů se může potenciálně změnit během převzetí služeb při selhání iniciovaného Microsoftem nebo ručním převzetím služeb při selhání. K zobrazení výčtu seznamu objektů blob můžete použít rozhraní API pro výpis objektů blob nebo seznam rozhraní API ADLS Gen2 pro seznam souborů. Další informace najdete v tématu Azure Storage jako koncový bod směrování.
Převzetí služeb při selhání iniciované Microsoftem
Převzetí služeb při selhání iniciované Microsoftem provádí Microsoft ve výjimečných situacích, aby převzal služby při selhání všech center IoT z ovlivněné oblasti do odpovídající geograficky spárované oblasti. Tento proces je výchozí možností a nevyžaduje zásah uživatele. Společnost Microsoft si vyhrazuje právo rozhodnout, kdy bude tato možnost uplatněna. Tento mechanismus nezahrnuje souhlas uživatele před převzetím služeb při selhání centra uživatele. Převzetí služeb při selhání iniciované Microsoftem má plánovanou dobu obnovení (RTO) 2–26 hodin.
Velká plánovaná doba obnovení je způsobená tím, že Společnost Microsoft musí provést operaci převzetí služeb při selhání jménem všech ovlivněných zákazníků v této oblasti. Pokud provozujete méně důležité řešení IoT, které může trvat zhruba den výpadků, je v pořádku, abyste na této možnosti mohli spoléhat, abyste splnili celkové cíle zotavení po havárii pro vaše řešení IoT. Celková doba, po které se tento proces aktivuje, se plně zprovozní, je popsána v části Doba obnovení.
Tuto funkci můžou vyjádřit pouze uživatelé, kteří nasazují centra IoT do oblastí Brazílie – jih a jihovýchodní Asie (Singapur). Další informace najdete v tématu Zakázání zotavení po havárii.
Poznámka:
Azure IoT Hub neukládá ani nezpracovává data zákazníků mimo geografickou oblast, ve které je instance služby nasazená. Další informace najdete v tématu Replikace mezi oblastmi v Azure.
Ruční převzetí služeb při selhání
Pokud vaše cíle dostupnosti vaší firmy nevyhovují rto, které poskytuje převzetí služeb při selhání iniciované Microsoftem, zvažte použití ručního převzetí služeb při selhání k aktivaci procesu převzetí služeb při selhání sami. Plánovaná doba obnovení pomocí této možnosti může být 10 minut až několik hodin. RTO je v současné době funkcí počtu zařízení registrovaných pro instanci služby IoT Hub, u které došlo k převzetí služeb při selhání. Můžete očekávat, že RTO pro centrum hostující přibližně 100 000 zařízení bude v ballparku 15 minut. Celková doba, po které se tento proces aktivuje, se plně zprovozní, je popsána v části Doba obnovení.
Možnost ručního převzetí služeb při selhání je vždy dostupná bez ohledu na to, jestli dochází k výpadku primární oblasti nebo ne. Tato možnost by se proto mohla použít k provádění plánovaných převzetí služeb při selhání. Jedním z příkladů použití plánovaných převzetí služeb při selhání je provádět pravidelné postupy převzetí služeb při selhání. Upozornění však spočívá v tom, že plánovaná operace převzetí služeb při selhání vede k výpadku centra pro období definovaného rto pro tuto možnost a také vede ke ztrátě dat, jak je definováno v tabulce bodu obnovení výše. Můžete zvážit nastavení testovací instance ioT Hubu pro pravidelné cvičení plánovaného převzetí služeb při selhání, abyste získali jistotu, že vaše ucelená řešení zprovozní a zprovozní, když dojde k reálné havárii.
Ruční převzetí služeb při selhání je k dispozici bez dalších poplatků za službu IoT Hubs vytvořená po 18. květnu 2017
Podrobné pokyny najdete v tématu Kurz: Ruční převzetí služeb při selhání centra IoT
Ruční převzetí služeb při selhání a Event Hubs
Název a koncový bod integrovaného koncového bodu událostí služby IoT Hub kompatibilní se službou Event Hub po ručním převzetí služeb při selhání. Důvodem je to, že klient služby Event Hubs nemá přehled o událostech služby IoT Hub. Totéž platí i pro ostatní cloudové klienty, jako jsou Functions a Azure Stream Analytics. Pokud chcete načíst koncový bod a název, můžete použít Azure Portal nebo sadu .NET SDK.
Použití portálu
Další informace o použití portálu k načtení koncového bodu kompatibilního s centrem událostí a názvu kompatibilního s centrem událostí najdete v tématu Připojení k integrovanému koncovému bodu.
Použití sady .NET SDK
Pokud chcete použít ioT Hub připojovací řetězec k rekapitulace koncového bodu kompatibilního se službou Event Hubs, použijte ukázku umístěnou na https://github.com/Azure/azure-sdk-for-net/tree/main/samples/iothub-connect-to-eventhubsadrese . Příklad kódu používá připojovací řetězec k získání nového koncového bodu služby Event Hubs a opětovnému navázání připojení. Musíte mít nainstalovanou sadu Visual Studio.
Spuštění testovacích podrobností
V centrech IoT, které se používají v produkčních prostředích, by se neměly provádět testovací postupy.
Nepoužívejte ruční převzetí služeb při selhání k migraci ioT Hubu do jiné oblasti.
Ruční převzetí služeb při selhání by se nemělo používat jako mechanismus pro trvalou migraci centra mezi geograficky spárovanými oblastmi Azure. Za předpokladu, že se zařízení nacházejí nejblíže primární oblasti centra, zvýší se latence operací prováděných s centrem IoT, když centrum převezme služby při selhání do sekundární oblasti.
Navrácení služeb po obnovení
Druhou aktivací akce převzetí služeb při selhání můžete provést navrácení služeb po obnovení do původní primární oblasti. Pokud byla původní operace převzetí služeb při selhání provedena kvůli zotavení z rozšířeného výpadku v původní primární oblasti, doporučujeme, aby se centrum po obnovení z situace výpadku vrátilo zpět do původního umístění.
Důležité
- Uživatelé mohou provádět pouze 2 úspěšné převzetí služeb při selhání a 2 úspěšné operace navrácení služeb po obnovení za den.
- Operace navrácení služeb při selhání nebo navrácení služeb po obnovení nejsou povolené. Mezi těmito operacemi je potřeba 1 hodinu počkat.
Doba potřebná k obnovení
I když plně kvalifikovaný název domény (a proto připojovací řetězec) instance ioT Hubu zůstává po převzetí služeb při selhání stejný, základní IP adresa se změní. Čas provádění operací za běhu s vaší instancí služby IoT Hub, aby se po dokončení procesu převzetí služeb při selhání mohl vyjádřit pomocí následující funkce:
Doba obnovení = RTO [10 min - 2 hodiny pro ruční převzetí služeb při selhání | 2 – 26 hodin pro převzetí služeb při selhání iniciované Microsoftem] + zpoždění šíření DNS + doba potřebná klientskou aplikací k aktualizaci jakékoli IP adresy ioT Hubu uložené v mezipaměti.
Důležité
Sady Sdk IoT neukly IP adresu centra IoT do mezipaměti. Doporučujeme, aby uživatelský kód propojený se sadami SDK neukládaly IP adresu centra IoT do mezipaměti.
Zákaz zotavení po havárii
IoT Hub poskytuje převzetí služeb při selhání iniciované Microsoftem a ruční převzetí služeb při selhání tím, že replikuje data do spárované oblasti pro každé centrum IoT. V některých oblastech se můžete vyhnout replikaci dat mimo oblast zakázáním zotavení po havárii při vytváření centra IoT. Tuto funkci podporují následující oblasti:
- Brazílie – jih; spárovaná oblast, USA – středojiž.
- Jihovýchodní Asie (Singapur); spárovaná oblast, Východní Asie (Hongkong – zvláštní správní oblast).
Pokud chcete zakázat zotavení po havárii v podporovaných oblastech, ujistěte se, že při vytváření centra IoT není zaškrtnutá možnost zotavení po havárii:
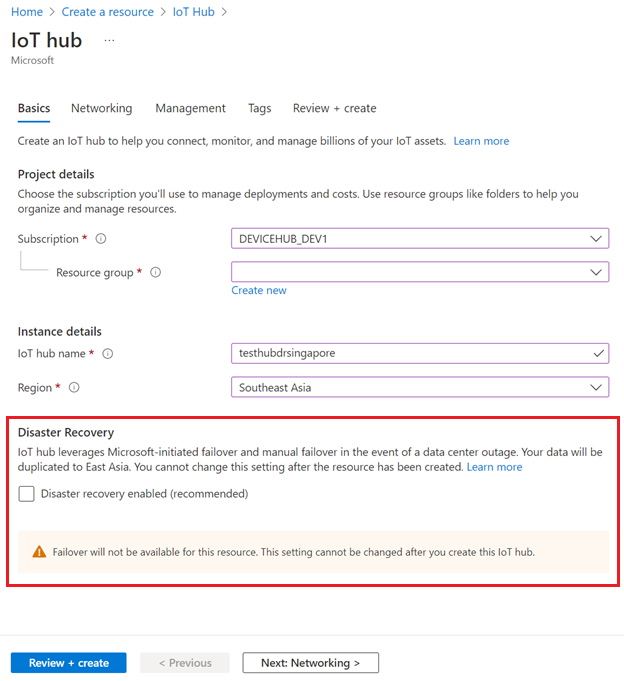
Zotavení po havárii můžete také zakázat při vytváření centra IoT pomocí šablony ARM.
Funkce převzetí služeb při selhání nebude dostupná, pokud zakážete zotavení po havárii pro centrum IoT.
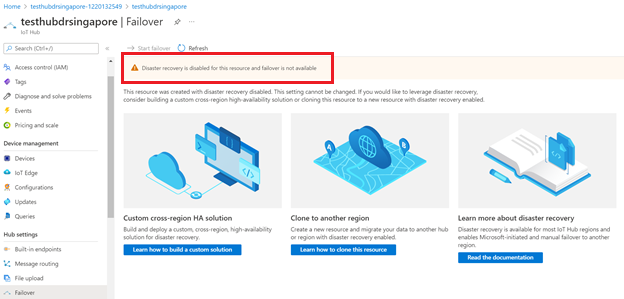
Zotavení po havárii můžete zakázat, abyste se vyhnuli replikaci dat mimo spárovanou oblast v Brazílii – jih nebo jihovýchodní Asii při vytváření centra IoT. Pokud chcete nakonfigurovat stávající centrum IoT tak, aby zakázalo zotavení po havárii, musíte vytvořit nové centrum IoT se zakázaným zotavením po havárii a ručně migrovat stávající centrum IoT. Pokyny najdete v tématu Postup migrace ioT Hubu.
Dosažení vysoké dostupnosti napříč oblastmi
Pokud rtO vaší firmy nespokojí cíle dostupnosti, které nabízí převzetí služeb při selhání iniciované Microsoftem nebo možnosti ručního převzetí služeb při selhání, měli byste zvážit implementaci mechanismu automatického převzetí služeb při selhání mezi zařízeními. Kompletní ošetření topologií nasazení v řešeních IoT je mimo rozsah tohoto článku. Tento článek popisuje místní model nasazení převzetí služeb při selhání pro zajištění vysoké dostupnosti a zotavení po havárii.
V modelu regionálního převzetí služeb při selhání běží back-end řešení primárně v jednom umístění datacentra. Sekundární centrum IoT a back-end se nasadí do jiného umístění datacentra. Pokud dojde k výpadku centra IoT v primární oblasti nebo dojde k přerušení síťového připojení ze zařízení k primární oblasti, zařízení používají sekundární koncový bod služby. Dostupnost řešení můžete vylepšit implementací modelu převzetí služeb při selhání napříč oblastmi, a ne v jedné oblasti.
Pokud chcete implementovat místní model převzetí služeb při selhání se službou IoT Hub, musíte provést následující kroky:
Sekundární logika směrování ioT Hubu a zařízení: Pokud dojde k narušení služby v primární oblasti, musí se zařízení začít připojovat k vaší sekundární oblasti. Vzhledem k povaze většiny zahrnutých služeb je běžné, že správci řešení aktivují proces převzetí služeb při selhání mezi oblastmi. Nejlepší způsob, jak komunikovat nový koncový bod se zařízeními při zachování kontroly procesu, je pravidelně kontrolovat službu concierge pro aktuální aktivní koncový bod. Služba Concierge může být webová aplikace, která se replikuje a udržuje dosažitelnou pomocí technik přesměrování DNS (například pomocí Azure Traffic Manageru).
Poznámka:
Služba IoT Hub není podporovaným typem koncového bodu v Azure Traffic Manageru. Doporučujeme integrovat navrženou službu Concierge s Azure Traffic Managerem tím, že implementuje rozhraní API sondy stavu koncového bodu.
Replikace registru identit: Aby bylo možné použít, musí sekundární centrum IoT obsahovat všechny identity zařízení, které se můžou připojit k řešení. Řešení by mělo uchovávat geograficky replikované zálohy identit zařízení a před přepnutím aktivního koncového bodu pro zařízení je nahrát do sekundárního centra IoT. Funkce exportu identity zařízení ve službě IoT Hub je v tomto kontextu užitečná. Další informace najdete v příručce pro vývojáře služby IoT Hub – registr identit.
Logika sloučení: Jakmile bude primární oblast opět dostupná, musí se všechny stavy a data vytvořená v sekundární lokalitě migrovat zpět do primární oblasti. Tento stav a data většinou souvisejí s identitami zařízení a metadaty aplikací, které se musí sloučit s primárním centrem IoT a všemi dalšími úložišti specifickými pro aplikace v primární oblasti.
Pro zjednodušení tohoto kroku byste měli použít idempotentní operace. Idempotentní operace minimalizují vedlejší účinky z konečného konzistentního rozdělení událostí a z duplicit nebo doručení událostí mimo objednávku. Logika aplikace by navíc měla být navržena tak, aby tolerovala potenciální nekonzistence nebo mírně zastaralý stav. K této situaci může dojít kvůli delší době, která systém potřebuje k nápravě na základě cílů bodu obnovení (RPO).
Volba správné možnosti vysoké dostupnosti nebo zotavení po havárii
Tady je souhrn možností vysoké dostupnosti a zotavení po havárii uvedených v tomto článku, které můžete použít jako rámec odkazu a zvolit správnou možnost, která funguje pro vaše řešení.
| Možnost vysoké dostupnosti a zotavení po havárii | RTO | RPO | Vyžaduje ruční zásah? | Složitost implementace | Dopad na náklady |
|---|---|---|---|---|---|
| Převzetí služeb při selhání iniciované Microsoftem | 2 – 26 hodin | Projděte si výše uvedenou tabulku cíle bodu obnovení. | No | Nic | Nic |
| Ruční převzetí služeb při selhání | 10 minut – 2 hodiny | Projděte si výše uvedenou tabulku cíle bodu obnovení. | Ano | Velmi nízká. Tuto operaci musíte aktivovat jenom z portálu. | Nic |
| Vysoká dostupnost napříč oblastmi | < 1 min. | Závisí na frekvenci replikace vlastního řešení vysoké dostupnosti. | No | Vysoká | > 1x náklady na 1 IoT Hub |
Další kroky
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro