Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento článek popisuje, jak pomocí komponenty Execute R Script spustit kód jazyka R v kanálu návrháře služby Azure Machine Learning.
S jazykem R můžete provádět úlohy, které stávající komponenty nepodporují, například:
- Vytváření vlastních transformací dat
- Vyhodnocení předpovědí pomocí vlastních metrik
- Vytváření modelů pomocí algoritmů, které nejsou implementovány jako samostatné komponenty v návrháři
Podpora verzí jazyka R
Návrhář Azure Machine Learning používá distribuci CRAN (Comprehensive R Archive Network) jazyka R. Aktuálně použitá verze je CRAN 3.5.1.
Podporované balíčky R
Prostředí R je předinstalované s více než 100 balíčky. Úplný seznam najdete v části Předinstalované balíčky jazyka R.
Můžete také přidat následující kód do libovolné součásti Execute R Script, abyste viděli nainstalované balíčky.
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
dataframe1 <- data.frame(installed.packages())
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Poznámka:
Pokud váš kanál obsahuje více komponent skriptu Execute R, které potřebují balíčky, které nejsou v předinstalovaném seznamu, nainstalujte balíčky v každé komponentě.
Instalace balíčků R
K instalaci dalších balíčků R použijte metodu install.packages() . Balíčky jsou nainstalovány pro každou komponentu Execute R Script. Nesdílí se mezi ostatními komponentami execute R Script.
Poznámka:
Nedoporučuje se instalovat balíček R ze sady skriptů. Doporučujeme nainstalovat balíčky přímo v editoru skriptů.
Při instalaci balíčků zadejte úložiště CRAN, například install.packages("zoo",repos = "https://cloud.r-project.org").
Upozorňující
Komponenta skriptu excute R nepodporuje instalaci balíčků, které vyžadují nativní kompilaci, jako qdap je balíček, který vyžaduje JAZYK JAVA a drc balíček, který vyžaduje C++. Důvodem je to, že se tato komponenta spouští v předinstalovaném prostředí s oprávněním bez oprávnění správce.
Neinstalujte balíčky, které jsou předdefinované nebo pro Windows, protože komponenty návrháře běží na Ubuntu. Pokud chcete zkontrolovat, jestli je balíček předdefinovaný ve Windows, můžete přejít na CRAN a prohledat balíček, stáhnout si jeden binární soubor podle operačního systému a zkontrolovat, že je součástí souboru DESCRIPTION. Následuje příklad: 
Tato ukázka ukazuje, jak nainstalovat Zoo:
# R version: 3.5.1
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Note that functions dependent on the X11 library,
# such as "View," are not supported because the X11 library
# is not preinstalled.
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be null.
# Param<dataframe1>: a R DataFrame
# Param<dataframe2>: a R DataFrame
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
if(!require(zoo)) install.packages("zoo",repos = "https://cloud.r-project.org")
library(zoo)
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Poznámka:
Před instalací balíčku zkontrolujte, jestli už existuje, abyste instalaci neopakovali. Opakované instalace můžou způsobit vypršení časového limitu požadavků webové služby.
Přístup k registrované datové sadě
Pokud chcete získat přístup k registrovaným datovým sadám ve vašem pracovním prostoru, podívejte se na následující ukázkový kód:
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
run = get_current_run()
ws = run$experiment$workspace
dataset = azureml$core$dataset$Dataset$get_by_name(ws, "YOUR DATASET NAME")
dataframe2 <- dataset$to_pandas_dataframe()
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Postup konfigurace spuštění skriptu R
Komponenta Execute R Script obsahuje ukázkový kód jako výchozí bod.
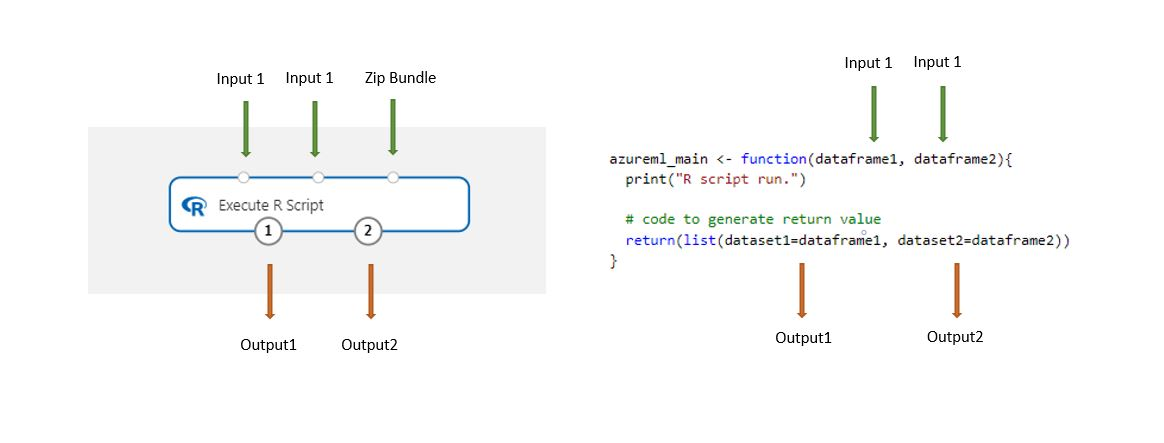
Datové sady uložené v návrháři se při načtení této komponenty automaticky převedou na datový rámec R.
Přidejte do kanálu komponentu Spustit skript jazyka R.
Připojte všechny vstupy, které skript potřebuje. Vstupy jsou volitelné a můžou obsahovat data a další kód R.
Datová sada1: Odkaz na první vstup jako
dataframe1. Vstupní datová sada musí být naformátovaná jako soubor CSV, TSV nebo ARFF. Nebo můžete připojit datovou sadu Azure Machine Learning.Datová sada2: Odkaz na druhý vstup jako
dataframe2. Tato datová sada musí být také naformátovaná jako soubor CSV, TSV nebo ARFF nebo jako datová sada Azure Machine Learning.Sada skriptů: Třetí vstup přijímá .zip soubory. Komprimovaný soubor může obsahovat více souborů a více typů souborů.
Do textového pole skriptu jazyka R zadejte nebo vložte platný skript jazyka R.
Poznámka:
Při psaní skriptu buďte opatrní. Ujistěte se, že neexistují žádné chyby syntaxe, jako je použití nedelarovaných proměnných nebo neimportovaných součástí nebo funkcí. Věnujte zvláštní pozornost předinstalovaným seznamu balíčků na konci tohoto článku. Pokud chcete použít balíčky, které tu nejsou, nainstalujte je do skriptu. Příklad:
install.packages("zoo",repos = "https://cloud.r-project.org").Abyste mohli začít, je textové pole Skript jazyka R předem vyplněné vzorovým kódem, který můžete upravit nebo nahradit.
# R version: 3.5.1 # The script MUST contain a function named azureml_main, # which is the entry point for this component. # Note that functions dependent on the X11 library, # such as "View," are not supported because the X11 library # is not preinstalled. # The entry point function MUST have two input arguments. # If the input port is not connected, the corresponding # dataframe argument will be null. # Param<dataframe1>: a R DataFrame # Param<dataframe2>: a R DataFrame azureml_main <- function(dataframe1, dataframe2){ print("R script run.") # If a .zip file is connected to the third input port, it's # unzipped under "./Script Bundle". This directory is added # to sys.path. # Return datasets as a Named List return(list(dataset1=dataframe1, dataset2=dataframe2)) }Funkce vstupního bodu musí mít vstupní argumenty
Param<dataframe1>, aParam<dataframe2>to i v případě, že se tyto argumenty ve funkci nepoužívají.Poznámka:
Data předaná komponentě Execute R Script jsou odkazována jako
dataframe1adataframe2, která se liší od návrháře služby Azure Machine Learning (odkaz návrháře jakodataset1,dataset2). Ujistěte se, že se ve skriptu správně odkazují vstupní data.Poznámka:
Existující kód jazyka R může vyžadovat menší změny ke spuštění v kanálu návrháře. Například vstupní data, která zadáte ve formátu CSV, by se před použitím v kódu měla explicitně převést na datovou sadu. Typy dat a sloupců používané v jazyce R se liší také některými způsoby od dat a typů sloupců používaných v návrháři.
Pokud je váš skript větší než 16 kB, použijte port Sada skriptů, abyste se vyhnuli chybám, jako je příkazový řádek, překročil limit 16597 znaků.
- Seskupte skript a další vlastní prostředky do souboru ZIP.
- Nahrajte soubor ZIP jako datovou sadu souborů do studia.
- Přetáhněte komponentu datové sady ze seznamu Datových sad v levém podokně komponent na stránce pro vytváření návrháře.
- Připojte komponentu datové sady k portu Sada skriptů komponenty Execute R Script .
Následuje ukázkový kód pro využívání skriptu v sadě skriptů:
azureml_main <- function(dataframe1, dataframe2){ # Source the custom R script: my_script.R source("./Script Bundle/my_script.R") # Use the function that defined in my_script.R dataframe1 <- my_func(dataframe1) sample <- readLines("./Script Bundle/my_sample.txt") return (list(dataset1=dataframe1, dataset2=data.frame("Sample"=sample))) }Do pole Random Seed zadejte hodnotu, která se má použít v prostředí R jako náhodná počáteční hodnota. Tento parametr je ekvivalentní volání
set.seed(value)v kódu jazyka R.Odešlete kanál.
Výsledky
Spouštění komponent skriptu R může vracet více výstupů, ale musí být poskytovány jako datové rámce R. Návrhář automaticky převede datové rámce na datové sady kvůli kompatibilitě s jinými komponentami.
Standardní zprávy a chyby z R se vrátí do protokolu komponenty.
Pokud potřebujete vytisknout výsledky ve skriptu jazyka R, můžete vytištěné výsledky najít v 70_driver_log na kartě Výstupy a protokoly v pravém panelu komponenty.
Ukázkové skripty
Kanál můžete rozšířit mnoha způsoby pomocí vlastních skriptů jazyka R. Tato část obsahuje ukázkový kód pro běžné úlohy.
Přidání skriptu R jako vstupu
Komponenta Execute R Script podporuje libovolné soubory skriptů jazyka R jako vstupy. Pokud je chcete použít, musíte je nahrát do pracovního prostoru jako součást souboru .zip.
Pokud chcete nahrát .zip soubor, který obsahuje kód R do pracovního prostoru, přejděte na stránku assetu Datové sady. Vyberte Vytvořit datovou sadu a pak vyberte Z místního souboru a možnost Typ datové sady.
Ověřte, že se komprimovaný soubor zobrazí v části Datové sady v kategorii Datové sady ve stromu levé komponenty.
Připojte datovou sadu ke vstupnímu portu sady skriptů.
Všechny soubory v souboru .zip jsou k dispozici během běhu kanálu.
Pokud soubor sady skriptů obsahoval adresářovou strukturu, struktura se zachová. Musíte ale změnit kód tak, aby se předzálohoval adresář ./Script Bundle na cestu.
Zpracování dat
Následující ukázka ukazuje, jak škálovat a normalizovat vstupní data:
# R version: 3.5.1
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Note that functions dependent on the X11 library,
# such as "View," are not supported because the X11 library
# is not preinstalled.
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be null.
# Param<dataframe1>: a R DataFrame
# Param<dataframe2>: a R DataFrame
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
# If a .zip file is connected to the third input port, it's
# unzipped under "./Script Bundle". This directory is added
# to sys.path.
series <- dataframe1$width
# Find the maximum and minimum values of the width column in dataframe1
max_v <- max(series)
min_v <- min(series)
# Calculate the scale and bias
scale <- max_v - min_v
bias <- min_v / dis
# Apply min-max normalizing
dataframe1$width <- dataframe1$width / scale - bias
dataframe2$width <- dataframe2$width / scale - bias
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Čtení souboru .zip jako vstupu
Tato ukázka ukazuje, jak použít datovou sadu v souboru .zip jako vstup komponenty Execute R Script.
- Vytvořte datový soubor ve formátu CSV a pojmenujte ho mydatafile.csv.
- Vytvořte soubor .zip a přidejte ho do archivu.
- Nahrajte komprimovaný soubor do pracovního prostoru Služby Azure Machine Learning.
- Připojte výslednou datovou sadu ke vstupu ScriptBundle komponenty Execute R Script .
- Ke čtení dat CSV ze souboru ZIP použijte následující kód.
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
mydataset<-read.csv("./Script Bundle/mydatafile.csv",encoding="UTF-8");
# Return datasets as a Named List
return(list(dataset1=mydataset, dataset2=dataframe2))
}
Replikace řádků
Tato ukázka ukazuje, jak replikovat kladné záznamy v datové sadě za účelem vyvážení ukázky:
azureml_main <- function(dataframe1, dataframe2){
data.set <- dataframe1[dataframe1[,1]==-1,]
# positions of the positive samples
pos <- dataframe1[dataframe1[,1]==1,]
# replicate the positive samples to balance the sample
for (i in 1:20) data.set <- rbind(data.set,pos)
row.names(data.set) <- NULL
# Return datasets as a Named List
return(list(dataset1=data.set, dataset2=dataframe2))
}
Předání objektů R mezi komponentami execute R Script
Objekty jazyka R můžete předat mezi instancemi komponenty Execute R Script pomocí interního mechanismu serializace. Tento příklad předpokládá, že chcete přesunout objekt R pojmenovaný A mezi dvěma komponentami Execute R Script.
Přidejte do kanálu první komponentu Spustit skript jazyka R. Do textového pole Skript jazyka R zadejte následující kód, který vytvoří serializovaný objekt
Ajako sloupec ve výstupní tabulce dat komponenty:azureml_main <- function(dataframe1, dataframe2){ print("R script run.") # some codes generated A serialized <- as.integer(serialize(A,NULL)) data.set <- data.frame(serialized,stringsAsFactors=FALSE) return(list(dataset1=data.set, dataset2=dataframe2)) }Explicitní převod na celočíselnou typ se provádí, protože funkce serializace vypíše data ve formátu R
Raw, který návrhář nepodporuje.Přidejte druhou instanci komponenty Execute R Script a připojte ji k výstupnímu portu předchozí komponenty.
Do textového pole Skript jazyka R zadejte následující kód, který extrahuje objekt
Aze vstupní tabulky dat.azureml_main <- function(dataframe1, dataframe2){ print("R script run.") A <- unserialize(as.raw(dataframe1$serialized)) # Return datasets as a Named List return(list(dataset1=dataframe1, dataset2=dataframe2)) }
Předinstalované balíčky R
Aktuálně jsou k dispozici následující předinstalované balíčky R:
| Balíček | Verze |
|---|---|
| žádost o heslo | 1,1 |
| ověřit, že | 0.2.1 |
| backporty | 1.1.4 |
| základna | 3.5.1 |
| base64enc | 0,1-3 |
| Bosna a Hercegovina | 1.69.0-1 |
| bindr | 0.1.1 |
| bindrcpp | 0.2.2 |
| bitops | 1.0-6 |
| startování | 1.3-22 |
| koště | 0.5.2 |
| volající | 3.2.0 |
| vynechávka | 6.0-84 |
| caTools | 1.17.1.2 |
| cellranger | 1.1.0 |
| třída | 7.3-15 |
| Rozhraní příkazového řádku | 1.1.0 |
| Clipr | 0.6.0 |
| klastr | 2.0.7-1 |
| codetools | 0.2-16 |
| barevný prostor | 1.4-1 |
| – kompilátor | 3.5.1 |
| pastelka | 1.3.4 |
| kudrna | 3.3 |
| datová tabulka | 1.12.2 |
| Power BI | 3.5.1 |
| DBI | 1.0.0 |
| dbplyr | 1.4.1 |
| trávit | 0.6.19 |
| dplyr | 0.7.6 |
| e1071 | 1.7-2 |
| hodnotit | 0,14 |
| fanynky | 0.4.0 |
| pro kočky | 0.3.0 |
| foreach | 1.4.4 |
| zahraniční | 0.8-71 |
| Fs | 1.3.1 |
| gdata | 2.18.0 |
| Generik | 0.0.2 |
| ggplot2 | 3.2.0 |
| glmnet | 2.0-18 |
| lepidlo | 1.3.1 |
| Gower | 0.2.1 |
| gplots | 3.0.1.1 |
| Grafika | 3.5.1 |
| grDevices | 3.5.1 |
| mřížka | 3.5.1 |
| gtable | 0.3.0 |
| gtools | 3.8.1 |
| útočiště | 2.1.0 |
| vyšší | 0,8 |
| Hms | 0.4.2 |
| htmlové nástroje | 0.3.6 |
| httr | 1.4.0 |
| ipred | 0.9-9 |
| Iterátory | 1.0.10 |
| jsonlite | 1.6 |
| KernSmooth | 2.23-15 |
| pletení | 1.23 |
| značení | 0,3 |
| mříž | 0.20-38 |
| láva | 1.6.5 |
| lazyeval | 0.2.2 |
| lubridate | 1.7.4 |
| magrittr | 1.5 |
| sleva | 0 |
| MŠE | 7.3-51.4 |
| Matice | 1.2-17 |
| metody | 3.5.1 |
| mgcv | 1.8-28 |
| mim | 0,7 |
| ModelMetrics | 1.2.2 |
| modelář | 0.1.4 |
| munsell | 0.5.0 |
| nlme | 3.1-140 |
| nnet (neuronová síť) | 7.3-12 |
| numDeriv (Numerická derivace) | 2016.8 - 1.1 |
| OpenSSL | 1.4 |
| rovnoběžný | 3.5.1 |
| pilíř | 1.4.1 |
| pkgconfig | 2.0.2 |
| plogr | 0.2.0 |
| plyr | 1.8.4 |
| prettyunits | 1.0.2 |
| processx | 3.3.1 |
| prodlim | 2018.04.18 |
| Průběh | 1.2.2 |
| PS | 1.3.0 |
| purrr | 0.3.2 |
| čtyřúhelník | 1.5-7 |
| quantmod | 0.4-15 |
| R6 | 2.4.0 |
| "randomForest" | 4.6-14 |
| RColorBrewer | 1.1-2 |
| Rcpp | 1.0.1 |
| RcppRoll | 0.3.0 |
| čtenář | 1.3.1 |
| readxl | 1.3.1 |
| recepty | 0.1.5 |
| odvetný zápas | 1.0.1 |
| reprodukovatelný příklad | 0.3.0 |
| reshape2 | 1.4.3 |
| rozvést elektřinu | 1.12 |
| rlang | 0.4.0 |
| rmarkdown | 1.13 |
| ROCR | 1.0-7 |
| rpart | 4.1-15 |
| rstudioapi | 0,1 |
| rvest | 0.3.4 |
| váhy | 1.0.0 |
| selektor | 0.4-1 |
| prostorový | 7.3-11 |
| spline křivky | 3.5.1 |
| ČTVEREC | 2017.10-1 |
| statistické údaje | 3.5.1 |
| Statistiky 4 | 3.5.1 |
| řetězce | 1.4.3 |
| stringr | 1.3.1 |
| přežití | 2.44-1.1 |
| systém | 3.2 |
| tcltk | 3.5.1 |
| tibble | 2.1.3 |
| tidyr | 0.8.3 |
| tidyselect | 0.2.5 |
| tidyverse | 1.2.1 |
| datum a čas | 3043.102 |
| tinytex | 0,13 |
| nářadí | 3.5.1 |
| tseries | 0.10-47 |
| TTR | 0.23-4 |
| utf8 | 1.1.4 |
| nástroje | 3.5.1 |
| vctrs | 0.1.0 |
| viridisLite | 0.3.0 |
| vous | 0,3–2 |
| (v případě, že je možné poskytnout smysl slova "withr", by bylo možné ho přeložit) | 2.1.2 |
| xfun | 0,8 |
| xml2 | 1.2.0 |
| xts | 0.11-2 |
| yaml | 2.2.0 |
| zeallot | 0.1.0 |
| zoologická zahrada | 1.8-6 |
Další kroky
Podívejte se na sadu komponent dostupných pro Azure Machine Learning.