Oddíl a ukázková komponenta
Tento článek popisuje komponentu v návrháři služby Azure Machine Learning.
Komponenty Oddíl a Sample použijte k vzorkování datové sady nebo k vytvoření oddílů z datové sady.
Vzorkování je ve strojovém učení důležitým nástrojem, protože umožňuje zmenšit velikost datové sady při zachování stejného poměru hodnot. Tato komponenta podporuje několik souvisejících úloh, které jsou důležité ve strojovém učení:
Rozdělení dat do několika pododdílů stejné velikosti
Oddíly můžete použít k křížovému ověření nebo k přiřazení případů k náhodným skupinám.
Oddělení dat do skupin a následná práce s daty z konkrétní skupiny
Poté, co náhodně přiřadíte případy různým skupinám, možná budete muset upravit funkce, které jsou přidružené pouze k jedné skupině.
Odběru vzorků.
Můžete extrahovat procento dat, použít náhodné vzorkování nebo zvolit sloupec, který se má použít pro vyrovnávání datové sady a provádět stratifikované vzorkování jejích hodnot.
Vytvoření menší datové sady pro testování
Pokud máte hodně dat, můžete při nastavování kanálu použít pouze prvních n řádků a při sestavování modelu pak přepnout na použití úplné datové sady. Vzorkování můžete také použít k vytvoření menší datové sady pro použití při vývoji.
Konfigurace komponenty
Tato komponenta podporuje následující metody pro rozdělení dat do oddílů nebo pro vzorkování. Nejprve zvolte metodu a pak nastavte další možnosti, které metoda vyžaduje.
- Head
- Vzorkování
- Přiřadit k záhybům
- Vybrat přeložení
Získání prvních N řádků z datové sady
Pomocí tohoto režimu můžete získat pouze prvních n řádků. Tato možnost je užitečná, pokud chcete testovat kanál na malém počtu řádků a nepotřebujete, aby se data žádným způsobem vyvažovala nebo vzorkovala.
Přidejte do kanálu v rozhraní komponentu Partition a Sample a připojte datovou sadu.
Oddílový nebo ukázkový režim: Nastavte tuto možnost na Head (Hlava).
Počet řádků, které se mají vybrat: Zadejte počet řádků, které se mají vrátit.
Počet řádků musí být nezáporné celé číslo. Pokud je počet vybraných řádků větší než počet řádků v datové sadě, vrátí se celá datová sada.
Odešlete kanál.
Komponenta vypíše jednu datovou sadu, která obsahuje pouze zadaný počet řádků. Řádky se vždy načítají z horní části datové sady.
Vytvoření ukázky dat
Tato možnost podporuje jednoduchý náhodný vzorkování nebo stratifikovaný náhodný vzorkování. Je to užitečné, pokud chcete vytvořit menší reprezentativní ukázkovou datovou sadu pro testování.
Přidejte do kanálu komponenty Partition (Oddíl) a Sample (Ukázka ) a připojte datovou sadu.
Režim dělení nebo vzorkování: Tuto možnost nastavte na Vzorkování.
Rychlost vzorkování: Zadejte hodnotu mezi 0 a 1. tato hodnota určuje procento řádků ze zdrojové datové sady, které by měly být zahrnuty do výstupní datové sady.
Pokud například chcete jenom polovinu původní datové sady, zadejte
0.5, abyste označili, že vzorkovací frekvence by měla být 50 procent.Řádky vstupní datové sady se promíchají a selektivně umístí do výstupní datové sady podle zadaného poměru.
Náhodné počáteční hodnoty pro vzorkování: Volitelně zadejte celé číslo, které se použije jako počáteční hodnota.
Tato možnost je důležitá, pokud chcete, aby se řádky pokaždé dělily stejným způsobem. Výchozí hodnota je 0, což znamená, že počáteční počáteční hodnota se generuje na základě systémových hodin. Tato hodnota může vést k mírně odlišným výsledkům při každém spuštění kanálu.
Stratifikované rozdělení pro vzorkování: Tuto možnost vyberte, pokud je důležité, aby řádky v datové sadě byly před vzorkováním rovnoměrně rozděleny určitým klíčovým sloupcem.
V části Sloupec s klíčem stratifikace pro vzorkování vyberte jeden sloupec vrstvy , který se má použít při dělení datové sady. Řádky v datové sadě se pak rozdělí takto:
Všechny vstupní řádky jsou seskupeny (rozvrstveny) podle hodnot v zadaném sloupci strata.
Řádky se v každé skupině prohazují.
Každá skupina se selektivně přidá do výstupní datové sady tak, aby splňovala zadaný poměr.
Odešlete kanál.
Při použití této možnosti komponenta vypíše jednu datovou sadu, která obsahuje reprezentativní vzorkování dat. Zbývající část datové sady bez přivzorkování není výstupem.
Rozdělení dat do oddílů
Tuto možnost použijte, pokud chcete datovou sadu rozdělit na podmnožinu dat. Tato možnost je užitečná také v případě, že chcete vytvořit vlastní počet přeložení pro křížové ověření nebo rozdělit řádky do několika skupin.
Přidejte do kanálu komponenty Partition (Oddíl) a Sample (Ukázka ) a připojte datovou sadu.
V části Režim oddílu nebo ukázky vyberte Přiřadit k přeložení.
Použít nahrazení v dělení: Tuto možnost vyberte, pokud chcete vzorkovaný řádek vložit zpět do fondu řádků pro potenciální opakované použití. V důsledku toho může být stejný řádek přiřazen k několika záhybům.
Pokud nepoužijete nahrazení (výchozí možnost), nevloží se vzorkovaný řádek zpět do fondu řádků pro potenciální opakované použití. V důsledku toho může být každý řádek přiřazen pouze k jednomu přeložení.
Náhodné rozdělení: Tuto možnost vyberte, pokud chcete, aby řádky byly náhodně přiřazeny k záhybům.
Pokud tuto možnost nevyberete, řádky se přiřazují k přeložení pomocí metody kruhového dotazování.
Náhodné počáteční hodnoty: Volitelně zadejte celé číslo, které se použije jako počáteční hodnota. Tato možnost je důležitá, pokud chcete, aby se řádky pokaždé dělily stejným způsobem. Jinak výchozí hodnota 0 znamená, že se použije náhodné počáteční počáteční seed.
Zadejte metodu dělicí metody: Pomocí těchto možností určete, jak se mají data přidělovat jednotlivým oddílům:
Rovnoměrné dělení: Tuto možnost použijte, pokud chcete do každého oddílu umístit stejný počet řádků. Pokud chcete zadat počet výstupních oddílů, zadejte celé číslo do pole Zadejte počet přeháně, které chcete rovnoměrně rozdělit .
Oddíl s přizpůsobenými poměry: Pomocí této možnosti můžete určit velikost jednotlivých oddílů jako seznam oddělený čárkami.
Předpokládejme například, že chcete vytvořit tři oddíly. První oddíl bude obsahovat 50 procent dat. Zbývající dva oddíly budou každý obsahovat 25 procent dat. Do pole Seznam podílů oddělených čárkami zadejte tato čísla: 0,5, 0,25, 0,25.
Součet všech velikostí oddílů musí být součet přesně 1.
Pokud zadáte čísla, která sčítají méně než 1, vytvoří se další oddíl, který bude obsahovat zbývající řádky. Pokud například zadáte hodnoty 0.2 a .3, vytvoří se třetí oddíl, který bude obsahovat zbývajících 50 % všech řádků.
Pokud zadáte čísla, která sčítají více než 1, při spuštění kanálu dojde k chybě.
Stratifikované rozdělení: Tuto možnost vyberte, pokud chcete, aby se řádky při rozdělení stratifikují, a pak zvolte sloupec strata.
Odešlete kanál.
Při použití této možnosti komponenta vypíše více datových sad. Datové sady jsou rozdělené podle pravidel, která jste zadali.
Použití dat z předdefinovaného oddílu
Tuto možnost použijte, pokud jste datovou sadu rozdělili do několika oddílů a teď chcete jednotlivé oddíly načíst pro další analýzu nebo zpracování.
Přidejte do kanálu komponenty Partition (Oddíl) a Sample (Ukázka ).
Připojte komponentu k výstupu předchozí instance partition a sample. Tato instance musela použít možnost Přiřadit k přeložení , aby vygenerovala určitý počet oddílů.
Režim oddílu nebo ukázky: Vyberte Vybrat skládání.
Zadejte, ze kterého objektu se má vzorkovat: Zadáním jeho indexu vyberte oddíl, který chcete použít. Indexy oddílů jsou založené na 1. Pokud byste například datovou sadu rozdělili na tři části, oddíly by měly indexy 1, 2 a 3.
Pokud zadáte neplatnou hodnotu indexu, vyvolá se chyba při návrhu: Chyba 0018: Datová sada obsahuje neplatná data.
Kromě seskupení datové sady podle záhybů můžete datovou sadu rozdělit do dvou skupin: cílového přeložení a všech ostatních. Chcete-li to provést, zadejte index jednoduchého přeložení a poté vyberte možnost Vybrat doplněk vybraného přeložení , abyste získali vše kromě dat v zadaném přehybu.
Pokud pracujete s více oddíly, musíte přidat další instance komponenty Partition a Sample pro zpracování jednotlivých oddílů.
Například komponenta Oddíl a Ukázka v druhém řádku je nastavená na Přiřadit k přeložení a komponenta ve třetím řádku je nastavená na Vybrat přeložení.
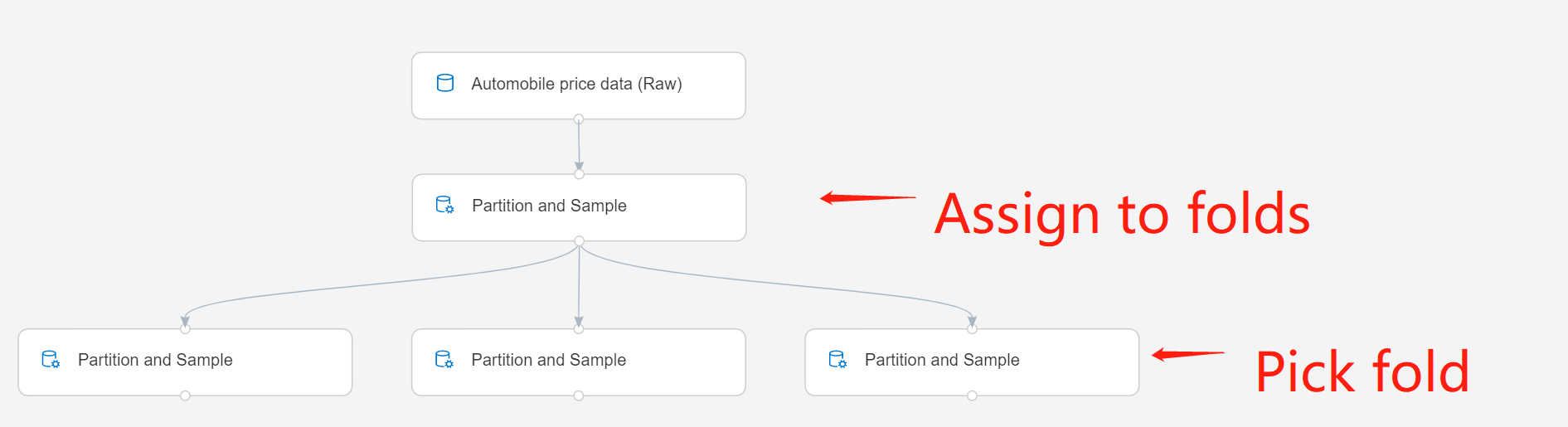
Odešlete kanál.
Při této možnosti komponenta vypíše jednu datovou sadu, která obsahuje pouze řádky přiřazené k tomuto přeložení.
Poznámka
Označení přeložení není možné zobrazit přímo. Jsou přítomny pouze v metadatech.
Další kroky
Podívejte se na sadu komponent dostupných pro Azure Machine Learning.