Předzpracování textu
Tento článek popisuje komponentu v návrháři služby Azure Machine Learning.
K vyčištění a zjednodušení textu použijte komponentu Preprocess Text . Podporuje tyto běžné operace zpracování textu:
- Odebrání stop-words
- Použití regulárních výrazů k vyhledání a nahrazení konkrétních cílových řetězců
- Lemmatizace, která převádí více souvisejících slov na jeden kanonický formulář
- Normalizace velkých a malých písmen
- Odebrání určitých tříd znaků, jako jsou čísla, speciální znaky a posloupnosti opakovaných znaků, například "aaaa".
- Identifikace a odebrání e-mailů a adres URL
Součást Preprocess Text v současné době podporuje pouze angličtinu.
Konfigurace předběžného zpracování textu
Přidejte komponentu Preprocess Text do kanálu ve službě Azure Machine Learning. Tuto komponentu najdete v části Analýza textu.
Připojte datovou sadu, která obsahuje aspoň jeden sloupec obsahující text.
V rozevíracím seznamu Jazyk vyberte jazyk.
Textový sloupec, který chcete vyčistit: Vyberte sloupec, který chcete předzpracovat.
Odebrat slova stop: Tuto možnost vyberte, pokud chcete u textového sloupce použít předdefinovaný seznam stopword.
Seznamy stopword jsou závislé na jazyce a přizpůsobitelné.
Lemmatizace: Tuto možnost vyberte, pokud chcete, aby slova byla reprezentována v jejich kanonické podobě. Tato možnost je užitečná pro snížení počtu jedinečných výskytů jinak podobných textových tokenů.
Proces lemmatizace je vysoce závislý na jazyce..
Rozpoznat věty: Tuto možnost vyberte, pokud chcete, aby komponenta při provádění analýzy vložil značku hranice věty.
Tato komponenta používá řadu tří znaků svislé znaky
|||, které představují ukončovací znak věty.Pomocí regulárních výrazů proveďte volitelné operace hledání a nahrazení. Regulární výraz se nejprve zpracuje před všemi ostatními integrovanými možnostmi.
- Vlastní regulární výraz: Definujte hledaný text.
- Vlastní řetězec nahrazení: Definujte jednu hodnotu nahrazení.
Normalizovat malá písmena na malá písmena: Tuto možnost vyberte, pokud chcete převést velká písmena ASCII na jejich malé formuláře.
Pokud nejsou znaky normalizovány, považuje se stejné slovo velkými a malými písmeny za dvě různá slova.
Z zpracovaného výstupního textu můžete také odebrat následující typy znaků nebo sekvence znaků:
Odebrat čísla: Tuto možnost vyberte, pokud chcete odebrat všechny číselné znaky pro zadaný jazyk. Identifikační čísla jsou závislá na doméně a závislé na jazyce. Pokud jsou číselné znaky nedílnou součástí známého slova, nemusí být číslo odebráno. Další informace najdete v technických poznámkách.
Odebrat speciální znaky: Pomocí této možnosti odeberete všechny jiné než alfanumerické speciální znaky.
Odebrat duplicitní znaky: Tuto možnost vyberte, pokud chcete odebrat nadbytečné znaky ve všech sekvencích, které se opakují více než dvakrát. Například sekvence jako "aaaaa" by se snížila na "aa".
Odebrat e-mailové adresy: Tuto možnost vyberte, pokud chcete odebrat libovolnou posloupnost formátu
<string>@<string>.Odebrat adresy URL: Tuto možnost vyberte, pokud chcete odebrat jakoukoli sekvenci, která obsahuje následující předpony adres URL:
http,https,ftpwww
Rozbalit slovesné kontrakty: Tato možnost se vztahuje pouze na jazyky, které používají slovesné kontrakty; v současné době pouze v angličtině.
Když vyberete tuto možnost, můžete například nahradit frázi "nezůstanu tam" slovem "nezůstanu tam".
Normalizovat zpětná lomítka na lomítka: Tuto možnost vyberte, pokud chcete namapovat všechny instance
\\na/.Rozdělte tokeny na speciální znaky: Tuto možnost vyberte, pokud chcete rozdělit slova na znaky, například
&,-a tak dále. Tato možnost může také snížit speciální znaky, když se opakuje více než dvakrát.Například řetězec
MS---WORDby byl rozdělen do tří tokenů,MS-, aWORD.Odešlete kanál.
Technické poznámky
Komponenta preprocess-text v sadě Studio (classic) a návrhář používá různé jazykové modely. Návrhář používá model CNN s více úlohami trénovaný z spaCy. Různé modely poskytují různé tokenizátory a part-of-speech tagger, což vede k různým výsledkům.
Tady je několik příkladů:
| Konfigurace | Výsledek výstupu |
|---|---|
| U všech vybraných možností Vysvětlení: V případech, jako je "3test" v "WC-3 3test 4test", návrhář odebere celé slovo "3test", protože v tomto kontextu část-of-speech tagger určuje tento token "3test" jako číslice a podle části řeči ji komponenta odebere. |
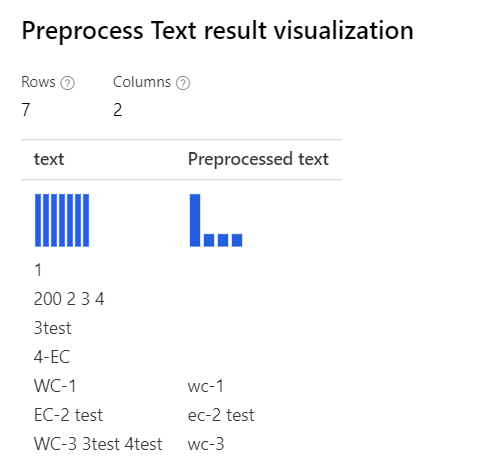
|
Removing number Pouze s vybraným vysvětlením: Pro případy jako "3test", "4-EC", dávka tokenizátoru návrháře tyto případy nerozdělí a považuje je za celé tokeny. Proto se čísla v těchto slovech neodeberou. |

|
K výstupu přizpůsobených výsledků můžete použít také regulární výraz:
| Konfigurace | Výsledek výstupu |
|---|---|
| Při výběru všech možností Vlastní regulární výraz: (\s+)*(-|\d+)(\s+)* Vlastní náhradní řetězec: \1 \2 \3 |

|
Removing number Pouze s vybraným vlastním regulárním výrazem: (\s+)*(-|\d+)(\s+)* Vlastní náhradní řetězec: \1 \2 \3 |
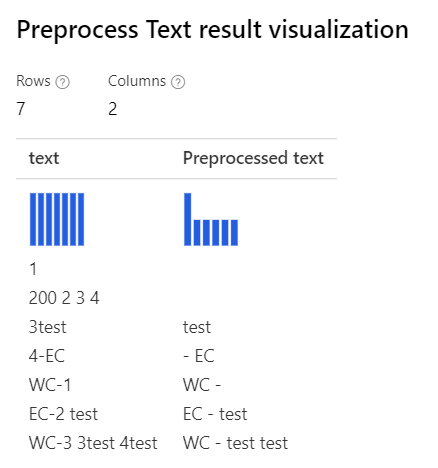
|
Další kroky
Podívejte se na sadu komponent dostupných pro Azure Machine Learning.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro