Nastavení AutoML pro trénování modelu prognózování časových řad pomocí Pythonu (SDKv1)
PLATÍ PRO: Python SDK azureml v1
Python SDK azureml v1
V tomto článku se dozvíte, jak nastavit trénování AutoML pro modely prognózování časových řad pomocí služby Azure Machine Učení automatizovaného strojového učení v sadě Azure Machine Učení Python SDK.
Uděláte to takto:
- Příprava dat pro modelování časových řad
- Nakonfigurujte konkrétní parametry časové řady v objektu
AutoMLConfig. - Spouštění předpovědí s daty časových řad
Informace o nízkém prostředí kódu najdete v kurzu: Prognóza poptávky pomocí automatizovaného strojového učení pro příklad prognózování časových řad pomocí automatizovaného strojového učení v studio Azure Machine Learning.
Na rozdíl od klasických metod časových řad jsou v automatizovaném strojovém učení hodnoty časových řad "pivoted", aby se staly dalšími dimenzemi regresoru spolu s dalšími prediktory. Tento přístup zahrnuje několik kontextových proměnných a jejich vztah k sobě během trénování. Vzhledem k tomu, že prognózu může ovlivnit více faktorů, tato metoda se dobře zarovná se scénáři prognózování z reálného světa. Například při prognózování prodeje, interakce historických trendů, směnného kurzu a ceny společně řídí výsledek prodeje.
Požadavky
Pro tento článek potřebujete:
Pracovní prostor služby Azure Machine Learning. Pokud chcete vytvořit pracovní prostor, přečtěte si téma Vytvoření prostředků pracovního prostoru.
Tento článek předpokládá určitou znalost nastavení experimentu automatizovaného strojového učení. Postupujte podle návodu a podívejte se na hlavní vzory návrhu experimentů automatizovaného strojového učení.
Důležité
Příkazy Pythonu v tomto článku vyžadují nejnovější
azureml-train-automlverzi balíčku.- Nainstalujte nejnovější
azureml-train-automlbalíček do místního prostředí. - Podrobnosti o nejnovějším
azureml-train-automlbalíčku najdete v poznámkách k verzi.
- Nainstalujte nejnovější
Trénovací a ověřovací data
Nejdůležitější rozdíl mezi typem úlohy prognózování regrese a typem regresní úlohy v rámci automatizovaného strojového učení je zahrnutí funkce do trénovacích dat, která představuje platnou časovou řadu. Běžná časová řada má dobře definovanou a konzistentní frekvenci a má hodnotu v každém vzorovém bodu v souvislém časovém rozsahu.
Důležité
Při trénování modelu pro prognózování budoucích hodnot se ujistěte, že se všechny funkce použité v trénování dají použít při spouštění předpovědí pro zamýšlený horizont. Například při vytváření prognózy poptávky, včetně funkce pro aktuální cenu akcií, může masivně zvýšit přesnost trénování. Pokud ale máte v úmyslu předpovídat s dlouhým horizontem, možná nebudete moct přesně předpovědět budoucí hodnoty akcií odpovídající budoucím bodům časové řady a přesnost modelu by mohla trpět.
Můžete zadat samostatná trénovací data a ověřovací data přímo v objektu AutoMLConfig . Přečtěte si další informace o autoMLConfigu.
Pro prognózování časových řad se pro ověřování ve výchozím nastavení používá pouze ověřování roCV (Rolling Origin Cross Validation). ROCV rozdělí řadu na trénovací a ověřovací data pomocí počátečního časového bodu. Posunutím počátku v čase se vygenerují křížové záhyby křížového ověření. Tato strategie zachovává integritu dat časové řady a eliminuje riziko úniku dat.
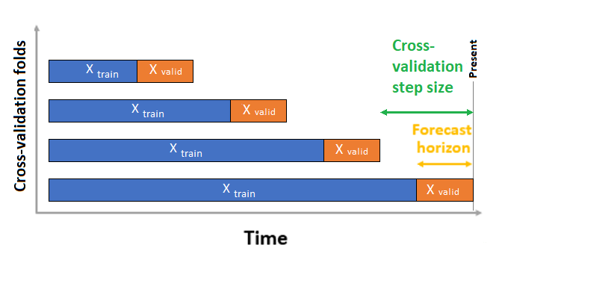
Předejte trénovací a ověřovací data jako jednu datovou sadu parametru training_data. Nastavte počet záhybů křížového ověřování s parametrem n_cross_validations a nastavte počet období mezi dvěma po sobě jdoucími křížovými ověřeními cv_step_sizes . Můžete také nechat oba parametry prázdné a AutoML je nastaví automaticky.
PLATÍ PRO:Python SDK azureml v1
automl_config = AutoMLConfig(task='forecasting',
training_data= training_data,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
...
**time_series_settings)
Můžete také použít vlastní ověřovací data, další informace najdete v tématu Konfigurace rozdělení dat a křížového ověřování v AutoML.
Přečtěte si další informace o tom, jak AutoML používá křížové ověřování, aby se zabránilo přetěžování modelů.
Konfigurace experimentu
Objekt AutoMLConfig definuje nastavení a data potřebná pro automatizovanou úlohu strojového učení. Konfigurace modelu prognózování se podobá nastavení standardního regresního modelu, ale některé modely, možnosti konfigurace a kroky featurizace existují speciálně pro data časových řad.
Podporované modely
Automatizované strojové učení automaticky zkouší různé modely a algoritmy v rámci procesu vytváření a ladění modelu. Jako uživatel nemusíte zadávat algoritmus. Pro prognózování experimentů jsou součástí systému doporučení nativní časové řady i modely hlubokého učení.
Tip
Tradiční regresní modely se také testují jako součást systému doporučení pro prognózování experimentů. Úplný seznam podporovaných modelů najdete v referenční dokumentaci k sadě SDK.
Nastavení konfigurace
Podobně jako u problému s regresí definujete standardní trénovací parametry, jako je typ úkolu, počet iterací, trénovací data a počet křížových ověření. Úlohy prognózování vyžadují time_column_name , aby experiment konfigurovali pomocí forecast_horizon parametrů. Pokud data obsahují více časových řad, například prodejní data pro více úložišť nebo energetické údaje v různých státech, automatizované strojové učení to automaticky zjistí a nastaví time_series_id_column_names parametr (Preview). Můžete také zahrnout další parametry pro lepší konfiguraci spuštění. Další podrobnosti o tom, co je možné zahrnout, najdete v části Volitelné konfigurace .
Důležité
Automatická identifikace časových řad je aktuálně ve verzi Public Preview. Tato verze Preview je poskytována bez smlouvy o úrovni služeb. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti. Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
| Název parametru | Popis |
|---|---|
time_column_name |
Slouží k určení sloupce datetime ve vstupních datech použitých k sestavení časové řady a odvození jeho frekvence. |
forecast_horizon |
Definuje, kolik období chcete předpovědět. Horizont je v jednotkách frekvence časových řad. Jednotky jsou založené na časovém intervalu trénovacích dat, například každý měsíc, kdy má prognóza předpovědět. |
Následující kód:
ForecastingParametersPomocí třídy definuje parametry prognózy pro trénování experimentu.time_column_nameNastaví poleday_datetimev sadě dat.forecast_horizonNastaví hodnotu 50, aby bylo možné předpovědět pro celou testovací sadu.
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecasting_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
freq='W')
Ty forecasting_parameters se pak předávají do standardního AutoMLConfig objektu spolu s typem forecasting úkolu, primární metrikou, kritérii ukončení a trénovacími daty.
from azureml.core.workspace import Workspace
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
import logging
automl_config = AutoMLConfig(task='forecasting',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=15,
enable_early_stopping=True,
training_data=train_data,
label_column_name=label,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
enable_ensembling=False,
verbosity=logging.INFO,
forecasting_parameters=forecasting_parameters)
Množství dat potřebných k úspěšnému trénování modelu prognózování pomocí automatizovaného strojového učení je ovlivněno forecast_horizonhodnotou , n_cross_validationsa target_lags nebo target_rolling_window_size hodnotami zadanými při konfiguraci AutoMLConfig.
Následující vzorec vypočítá množství historických dat, která by byla potřeba k vytvoření funkcí časových řad.
Minimální požadovaná historická data: (2x forecast_horizon) + # +n_cross_validations max(max(target_lags), target_rolling_window_size)
Je Error exception vyvolána pro všechny řady v datové sadě, které nevyhovují požadovanému množství historických dat pro zadaná příslušná nastavení.
Kroky pro featurizaci
V každém experimentu automatizovaného strojového učení se ve výchozím nastavení na vaše data použijí techniky automatického škálování a normalizace. Tyto techniky jsou typy featurizace , které pomáhají určitým algoritmům citlivým na funkce v různých škálách. Další informace o výchozích krocích featurizace v AutoML
Následující kroky se však provádějí pouze pro forecasting typy úloh:
- Zjistěte frekvenci vzorkování časových řad (například každou hodinu, denně, týdně) a vytvořte nové záznamy pro chybějící časové body, aby byla řada souvislá.
- Imputování chybějících hodnot v cíli (prostřednictvím doplňování dopředu) a sloupců funkcí (pomocí mediánu hodnot sloupců)
- Vytváření funkcí založených na identifikátorech časových řad, které umožňují pevné efekty napříč různými řadami
- Vytváření funkcí založených na čase, které pomáhají učit se sezónní vzory
- Kódování kategorických proměnných na číselné množství
- Detekujte nonstationární časovou řadu a automaticky se liší, aby se zmírnit dopad kořenových jednotek.
Úplný seznam možných vytvořených funkcí vygenerovaných z dat časových řad naleznete v části TimeIndexFeaturizer – třída.
Poznámka:
Kroky automatického featurizace strojového učení (normalizace funkcí, zpracování chybějících dat, převod textu na číselný atd.) se stanou součástí základního modelu. Při použití modelu pro předpovědi se na vstupní data automaticky použijí stejné kroky featurizace použité během trénování.
Přizpůsobení featurizace
Máte také možnost přizpůsobit nastavení featurizace, abyste zajistili, že data a funkce používané k trénování modelu ML vedou k relevantním předpovědím.
Mezi podporovaná přizpůsobení pro forecasting úlohy patří:
| Vlastní nastavení | definice |
|---|---|
| Aktualizace účelu sloupce | Přepište typ funkce automatického rozpoznávání pro zadaný sloupec. |
| Aktualizace parametrů Transformátoru | Aktualizujte parametry pro zadaný transformátor. V současné době podporuje Imputer (fill_value a medián). |
| Přetažení sloupců | Určuje sloupce, které mají být vyřazeny z featurizace. |
Pokud chcete přizpůsobit featurizace pomocí sady SDK, zadejte "featurization": FeaturizationConfig v objektu AutoMLConfig . Přečtěte si další informace o vlastních featurizacích.
Poznámka:
Funkce vyřazených sloupců je vyřazená ze sady SDK verze 1.19. Vypusťte sloupce z datové sady jako součást čištění dat před tím, než je začnete využívat v experimentu automatizovaného strojového učení.
featurization_config = FeaturizationConfig()
# `logQuantity` is a leaky feature, so we remove it.
featurization_config.drop_columns = ['logQuantitity']
# Force the CPWVOL5 feature to be of numeric type.
featurization_config.add_column_purpose('CPWVOL5', 'Numeric')
# Fill missing values in the target column, Quantity, with zeroes.
featurization_config.add_transformer_params('Imputer', ['Quantity'], {"strategy": "constant", "fill_value": 0})
# Fill mising values in the `INCOME` column with median value.
featurization_config.add_transformer_params('Imputer', ['INCOME'], {"strategy": "median"})
Pokud používáte studio Azure Machine Learning pro experiment, podívejte se, jak přizpůsobit featurizaci v sadě Studio.
Volitelné konfigurace
Další volitelné konfigurace jsou k dispozici pro prognózování úloh, jako je povolení hlubokého učení a určení cílové agregace posuvných oken. Úplný seznam dalších parametrů je k dispozici v referenční dokumentaci sady ForecastingParameters SDK.
Agregace četnosti a cíle dat
Použijte frekvenci , freqparametr, který pomáhá vyhnout se selháním způsobeným nepravidelnými daty. Nepravidelná data zahrnují data, která nedodržují nastavené tempo, jako jsou hodinová nebo denní data.
U vysoce nepravidelných dat nebo pro různé obchodní potřeby mohou uživatelé volitelně nastavit požadovanou frekvenci freqprognózy a zadat target_aggregation_function agregovaný cílový sloupec časové řady. Tato dvě nastavení v objektu AutoMLConfig vám můžou pomoct ušetřit čas při přípravě dat.
Mezi podporované agregační operace pro hodnoty cílového sloupce patří:
| Function | Popis |
|---|---|
sum |
Součet cílových hodnot |
mean |
Střední nebo průměr cílových hodnot |
min |
Minimální hodnota cíle |
max |
Maximální hodnota cíle |
Povolení hlubokého učení
Poznámka:
Podpora sítě DNN pro prognózování v automatizovaném počítači Učení je ve verzi Preview a nepodporuje se pro místní spuštění nebo spuštění zahájená v Databricks.
Hloubkové učení můžete také použít s hlubokými neurálními sítěmi, sítěmi DNN a zlepšit skóre modelu. Hloubkové učení automatizovaného strojového učení umožňuje předpovídat jednovariátová a multivariátní data časových řad.
Modely hlubokého učení mají tři vnitřní funkce:
- Mohou se učit z libovolných mapování ze vstupů na výstupy.
- Podporují více vstupů a výstupů.
- Můžou automaticky extrahovat vzory ve vstupních datech, která přesahují dlouhé sekvence.
Pokud chcete povolit hluboké učení, nastavte enable_dnn=True objekt v objektu AutoMLConfig .
automl_config = AutoMLConfig(task='forecasting',
enable_dnn=True,
...
forecasting_parameters=forecasting_parameters)
Upozorňující
Když povolíte síť DNN pro experimenty vytvořené pomocí sady SDK, nejlepší vysvětlení modelů se zakáže.
Pokud chcete povolit síť DNN pro experiment AutoML vytvořený v studio Azure Machine Learning, podívejte se na nastavení typu úlohy v návodu k uživatelskému rozhraní studia.
Cílová agregace posuvné okno
Nejlepší informace pro prognózovací službu jsou často poslední hodnotou cíle. Cílové agregace posuvného okna umožňují přidat průběžnou agregaci hodnot dat jako funkce. Generování a používání těchto funkcí jako dodatečných kontextových dat pomáhá s přesností modelu trénování.
Řekněme například, že chcete předpovědět poptávku po energii. Možná budete chtít přidat funkci posuvného okna se třemi dny, aby se zohlednily tepelné změny vytápěných prostorů. V tomto příkladu vytvořte toto okno nastavením target_rolling_window_size= 3 v konstruktoru AutoMLConfig .
Tabulka ukazuje výslednou přípravu funkcí, ke které dochází při použití agregace okna. Sloupce pro minimální, maximální a součet se generují na posuvné okno se třemi na základě definovaných nastavení. Každý řádek má novou počítanou funkci v případě časového razítka pro 8. září 2017 4:00 a maximální, minimální a součet hodnoty se počítají pomocí hodnot poptávky pro 8. září 2017 1:00–3:00. Toto okno se třemi směnami se naplní daty pro zbývající řádky.

Podívejte se na příklad kódu Pythonu s použitím agregační funkce cílového souhrnného okna.
Zpracování krátkých řad
Automatizované strojové učení považuje časovou řadu za krátkou řadu , pokud není dostatek datových bodů k provedení fází trénování a ověřování vývoje modelu. Počet datových bodů se u každého experimentu liší a závisí na max_horizon, počtu rozděleních křížového ověřování a délce zpětného vyhledávání modelu, tj. maximální počet historie potřebných k vytvoření funkcí časových řad.
Automatizované strojové učení ve výchozím nastavení nabízí zpracování krátkých řad s parametrem short_series_handling_configuration v objektu ForecastingParameters .
Pokud chcete povolit zpracování krátkých řad, freq musí být také definován parametr. Abychom definovali hodinovou frekvenci, nastavíme freq='H'. Zobrazte možnosti řetězce četnosti v části Objekty DataOffset stránky pandas Time series. Chcete-li změnit výchozí chování, short_series_handling_configuration = 'auto'aktualizujte short_series_handling_configurationForecastingParameter parametr v objektu.
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecast_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
short_series_handling_configuration='auto',
freq = 'H',
target_lags='auto')
Následující tabulka shrnuje dostupná nastavení pro short_series_handling_config.
| Nastavení | Popis |
|---|---|
auto |
Výchozí hodnota pro zpracování krátkých řad. - Pokud jsou všechny řady krátké, vložte data. - Pokud ne všechny řady jsou krátké, zahoďte krátkou řadu. |
pad |
Pokud short_series_handling_config = padpak automatizované strojové učení přidá náhodné hodnoty do každé krátké nalezené řady. Následující seznam uvádí typy sloupců a jejich vkládání: – Objektové sloupce s názvy NaN - Číselné sloupce s 0 – logické sloupce nebo sloupce logiky s hodnotou False - Cílový sloupec je vycpaný náhodnými hodnotami se střední hodnotou nuly a směrodatnou odchylkou 1. |
drop |
Pokud short_series_handling_config = droppak automatizované strojové učení krátké řady poklesne a nepoužije se pro trénování nebo predikci. Předpovědi pro tyto řady vrací hodnoty NaN. |
None |
Žádná řada není vycpaná nebo zahozená |
Upozorňující
Odsazení může mít vliv na přesnost výsledného modelu, protože zavádíme umělá data, abychom získali předchozí trénování bez selhání. Pokud je řada řad krátká, může se také zobrazit nějaký dopad na výsledky vysvětlovatelnosti.
Detekce a zpracování nonstationárních časových řad
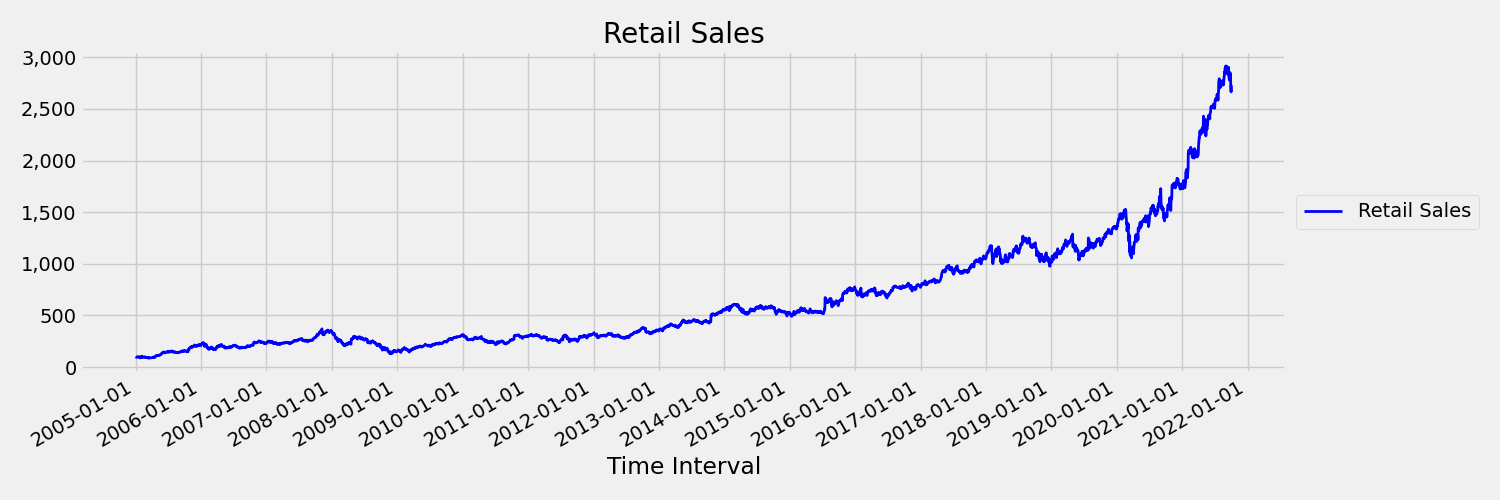
Časová řada, jejíž momenty (střední a rozptyl) se v průběhu času mění, se nazývá nehybná. Časové řady, které vykazují stochastické trendy, jsou například neschytné přírodou. Abychom to mohli vizualizovat, následující obrázek vykreslí řadu, která obecně roste směrem nahoru. Teď vypočítá a porovná střední (průměr) hodnoty pro první a druhou polovinu řady. Jsou stejné? Tady je průměr řady v první polovině grafu menší než v druhé polovině. Skutečnost, že průměr řady závisí na časovém intervalu, na který se díváte, je příkladem časových momentů, které se liší. Tady je první okamžik průměr série.
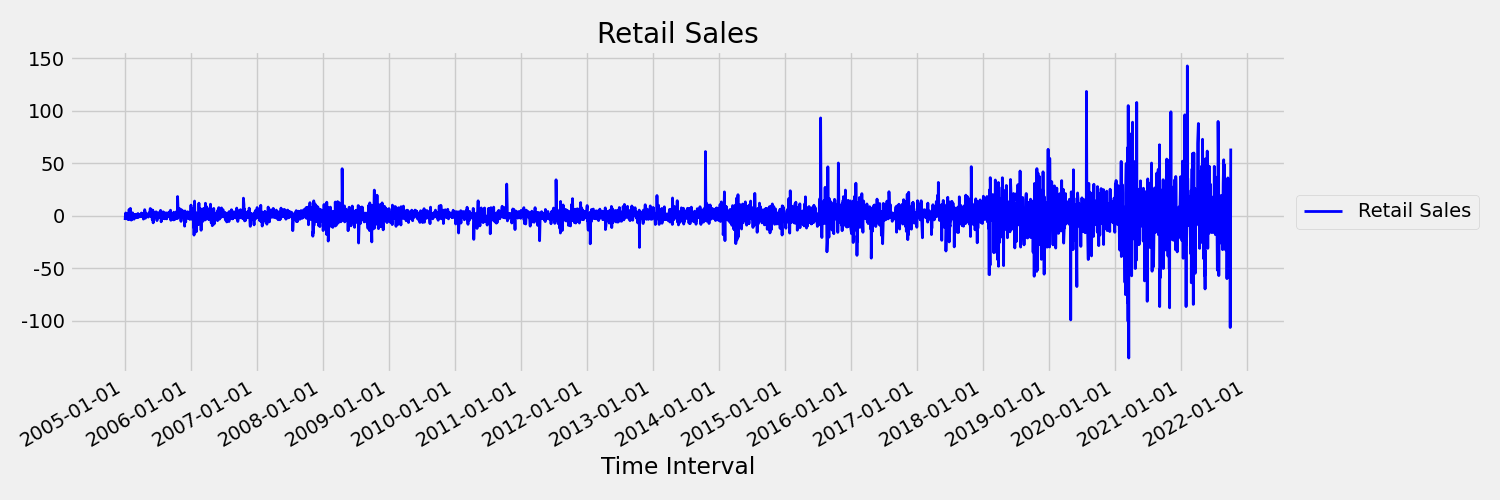
Teď se podíváme na obrázek, který vykreslí původní řadu v prvních rozdílech, $x_t = y_t - y_{t-1}$, kde $x_t$ je změna maloobchodního prodeje a $y_t$ a $y_{t-1}$ představují původní řadu a její první prodlevu. Průměr řady je zhruba konstantní bez ohledu na časový rámec, na který se dívá. Toto je příklad první objednávky řady statických časů. Důvodem, proč jsme přidali první termín pořadí, je to, že první moment (střední hodnota) se s časovým intervalem nezmění, totéž se nedá říci o rozptylu, což je druhý okamžik.
Modely strojového učení AutoML nemohou ze své podstaty řešit stochastické trendy ani jiné dobře známé problémy spojené s nestánínou časovou řadou. V důsledku toho je jejich přesnost předpovědí z vzorku "špatná", pokud jsou takové trendy přítomny.
AutoML automaticky analyzuje datovou sadu časových řad a kontroluje, jestli je staticky nebo ne. Když se zjistí nestáníná časová řada, AutoML automaticky použije rozdílovou transformaci, která zmírní vliv nestáníných časových řad.
Spusťte experiment.
Až budete mít AutoMLConfig objekt připravený, můžete experiment odeslat. Po dokončení modelu načtěte nejlepší iteraci spuštění.
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-forecasting")
local_run = experiment.submit(automl_config, show_output=True)
best_run, fitted_model = local_run.get_output()
Prognózování s nejlepším modelem
Nejlepší iterace modelu použijte k prognózování hodnot pro data, která nebyla použita k trénování modelu.
Vyhodnocení přesnosti modelu se klouzavým prognózou
Před uvedením modelu do produkčního prostředí byste měli vyhodnotit jeho přesnost na testovací sadě uchovávané z trénovacích dat. Osvědčeným postupem je tzv. postupné vyhodnocení, které v průběhu testovací sady postupně převrací vytrénovaný prognózovací nástroj a průměruje metriky chyb v několika časových oknech předpovědí, aby se získaly statisticky robustní odhady pro určitou sadu zvolených metrik. V ideálním případě je testovací sada pro vyhodnocení dlouhá vzhledem k horizontu prognózy modelu. Odhady prognózovací chyby mohou být jinak hlučné, a proto méně spolehlivé.
Předpokládejme například, že model natrénujete na denní prodej, abyste předpověděli poptávku až dva týdny (14 dní) do budoucnosti. Pokud je k dispozici dostatek historických dat, můžete si poslední několik měsíců rezervovat i rok dat pro testovací sadu. Postupné vyhodnocení začíná generováním 14denní prognózy pro první dva týdny testovací sady. Pak je prognóza rozšířena o několik dní do testovací sady a vygenerujete další 14denní prognózu z nové pozice. Proces pokračuje, dokud se nedostanete na konec testovací sady.
Chcete-li provést průběžné vyhodnocení, zavoláte rolling_forecast metodu fitted_modela pak vypočítáte požadované metriky ve výsledku. Předpokládejme například, že máte funkce testovací sady v datovém rámci pandas a test_features_df testovací sada skutečných hodnot cíle v poli numpy s názvem test_target. Postupné vyhodnocení pomocí střední kvadratická chyba je znázorněno v následující ukázce kódu:
from sklearn.metrics import mean_squared_error
rolling_forecast_df = fitted_model.rolling_forecast(
test_features_df, test_target, step=1)
mse = mean_squared_error(
rolling_forecast_df[fitted_model.actual_column_name], rolling_forecast_df[fitted_model.forecast_column_name])
V této ukázce je velikost kroku pro průběžnou prognózu nastavená na jednu, což znamená, že prognóza je pokročilá o jedno období nebo jeden den v našem příkladu předpovědi poptávky v každé iteraci. Celkový počet prognóz vrácených rolling_forecast tímto způsobem závisí na délce testovací sady a velikosti tohoto kroku. Další podrobnosti a příklady najdete v dokumentaci k rolling_forecast() a v poznámkovém bloku pro prognózování dat.
Předpověď do budoucnosti
Funkce forecast_quantiles() umožňuje, kdy se mají začít predikce, na rozdíl od predict() metody, která se obvykle používá pro úlohy klasifikace a regrese. Metoda forecast_quantiles() ve výchozím nastavení vygeneruje předpověď bodu nebo střední/medián prognózy, která nemá kolem sebe kužele nejistoty. Další informace najdete v poznámkovém bloku s trénovacími daty v prognózách.
V následujícím příkladu nejprve nahradíte všechny hodnoty v y_predNaN. Původ prognózy je na konci trénovacích dat v tomto případě. Pokud byste však nahradili pouze druhou polovinu y_predNaN, funkce ponechá číselné hodnoty v první polovině nezměněné, ale předpovídají NaN hodnoty v druhé polovině. Funkce vrátí prognózované hodnoty i zarovnané funkce.
Parametr ve forecast_quantiles() funkci můžete také použít forecast_destination k prognózování hodnot do zadaného data.
label_query = test_labels.copy().astype(np.float)
label_query.fill(np.nan)
label_fcst, data_trans = fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
Zákazníci často chtějí porozumět předpovědím v konkrétním quantile distribuce. Například když se prognóza používá k řízení inventáře, jako jsou potraviny nebo virtuální počítače pro cloudovou službu. V takových případech je řídicí bod obvykle něco jako "chceme, aby položka byla na skladě a nevyčerchá se 99 % času". Následující příklad ukazuje, jak určit, které quantily chcete zobrazit pro předpovědi, například 50. nebo 95. percentil. Pokud nezadáte quantile, například v výše uvedeném příkladu kódu, vygenerují se pouze 50. předpovědi percentilu.
# specify which quantiles you would like
fitted_model.quantiles = [0.05,0.5, 0.9]
fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
Můžete vypočítat metriky modelu, jako je odmocnina střední kvadratická chyba (RMSE) nebo absolutní procentuální chyba (MAPE), které vám pomůžou odhadnout výkon modelů. Příklad najdete v části Vyhodnocení poznámkového bloku pro sdílení kol.
Po zjištění celkové přesnosti modelu je nejrealističtějším dalším krokem použití modelu k prognózování neznámých budoucích hodnot.
Zadejte datovou sadu ve stejném formátu jako testovací sadu test_dataset , ale s budoucími hodnotami datetime a výsledná sada předpovědí je předpovídané hodnoty pro každý krok časové řady. Předpokládejme, že poslední záznamy časové řady v sadě dat byly 12. 31. 2018. Pokud chcete předpovědět poptávku po následující den (nebo tolik období, kolik potřebujete předpovědět, <= forecast_horizon), vytvořte pro každé úložiště jeden záznam časové řady pro 1. 1. 2019.
day_datetime,store,week_of_year
01/01/2019,A,1
01/01/2019,A,1
Opakujte nezbytné kroky pro načtení těchto budoucích dat do datového rámce a pak spusťte best_run.forecast_quantiles(test_dataset) predikci budoucích hodnot.
Poznámka:
Předpovědi v ukázce nejsou podporovány pro prognózování pomocí automatizovaného strojového učení, pokud target_lags a/nebo target_rolling_window_size jsou povolené.
Prognózování ve velkém měřítku
Existují scénáře, kdy jeden model strojového učení není dostatečný a vyžaduje se několik modelů strojového učení. Například predikce prodeje pro každou jednotlivou prodejnu pro značku nebo přizpůsobení prostředí jednotlivým uživatelům. Vytvoření modelu pro každou instanci může vést k lepším výsledkům mnoha problémů se strojovým učením.
Seskupení je koncept prognózování časových řad, který umožňuje kombinování časových řad pro trénování jednotlivých modelů na skupinu. Tento přístup může být užitečný zejména v případě, že máte časové řady, které vyžadují vyhlazování, vyplňování nebo entity ve skupině, které můžou těžit z historie nebo trendů z jiných entit. Mnoho modelů a hierarchické prognózování časových řad jsou řešení založená na automatizovaném strojovém učení pro tyto rozsáhlé scénáře prognózování.
Mnoho modelů
Azure Machine Učení řešení mnoha modelů pomocí automatizovaného strojového učení umožňuje uživatelům trénovat a spravovat miliony modelů paralelně. Řada modelů Akcelerátor řešení používá k trénování modelu kanály Azure Machine Učení. Konkrétně se používá objekt kanálu a ParalleRunStep a vyžadují specifické konfigurační parametry nastavené prostřednictvím ParallelRunConfig.
Následující diagram znázorňuje pracovní postup pro řešení mnoha modelů.

Následující kód ukazuje klíčové parametry, které uživatelé potřebují k nastavení mnoha modelů. Příklad prognózování mnoha modelů najdete v poznámkovém bloku Automatizované strojové učení.
from azureml.train.automl.runtime._many_models.many_models_parameters import ManyModelsTrainParameters
partition_column_names = ['Store', 'Brand']
automl_settings = {"task" : 'forecasting',
"primary_metric" : 'normalized_root_mean_squared_error',
"iteration_timeout_minutes" : 10, #This needs to be changed based on the dataset. Explore how long training is taking before setting this value
"iterations" : 15,
"experiment_timeout_hours" : 1,
"label_column_name" : 'Quantity',
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
"time_column_name": 'WeekStarting',
"max_horizon" : 6,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,}
mm_paramters = ManyModelsTrainParameters(automl_settings=automl_settings, partition_column_names=partition_column_names)
Hierarchické prognózování časových řad
Ve většině aplikací mají zákazníci potřebu porozumět jejich prognózám na makrech a mikroúrovňové úrovni firmy. Forcasts může predikovat prodej produktů v různých geografických lokalitách nebo porozumět očekávané poptávce pracovních sil pro různé organizace ve společnosti. Schopnost vytrénovat model strojového učení tak, aby inteligentně předpovídá data hierarchie, je nezbytná.
Hierarchická časová řada je struktura, ve které je každá z jedinečných řad uspořádána do hierarchie na základě dimenzí, jako je geografie nebo typ produktu. Následující příklad ukazuje data s jedinečnými atributy, které tvoří hierarchii. Naše hierarchie je definována: typ produktu, jako jsou sluchátka nebo tablety, kategorie produktu, která rozděluje typy produktů na příslušenství a zařízení a oblast, ve které se produkty prodávají.

Pro další vizualizaci obsahuje úrovně listu hierarchie všechny časové řady s jedinečnými kombinacemi hodnot atributů. Každá vyšší úroveň v hierarchii považuje jednu menší dimenzi pro definování časových řad a agreguje každou sadu podřízených uzlů z nižší úrovně do nadřazeného uzlu.

Hierarchické řešení časových řad je postavené na řešení mnoha modelů a sdílí podobné nastavení konfigurace.
Následující kód ukazuje klíčové parametry pro nastavení hierarchických běhů časových řad. Kompletní příklad najdete v poznámkovém bloku Hierarchické časové řady – Automatizované strojové učení.
from azureml.train.automl.runtime._hts.hts_parameters import HTSTrainParameters
model_explainability = True
engineered_explanations = False # Define your hierarchy. Adjust the settings below based on your dataset.
hierarchy = ["state", "store_id", "product_category", "SKU"]
training_level = "SKU"# Set your forecast parameters. Adjust the settings below based on your dataset.
time_column_name = "date"
label_column_name = "quantity"
forecast_horizon = 7
automl_settings = {"task" : "forecasting",
"primary_metric" : "normalized_root_mean_squared_error",
"label_column_name": label_column_name,
"time_column_name": time_column_name,
"forecast_horizon": forecast_horizon,
"hierarchy_column_names": hierarchy,
"hierarchy_training_level": training_level,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,
"model_explainability": model_explainability,# The following settings are specific to this sample and should be adjusted according to your own needs.
"iteration_timeout_minutes" : 10,
"iterations" : 10,
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
}
hts_parameters = HTSTrainParameters(
automl_settings=automl_settings,
hierarchy_column_names=hierarchy,
training_level=training_level,
enable_engineered_explanations=engineered_explanations
)
Příklady poznámkových bloků
V ukázkových poznámkových blocích pro prognózování najdete podrobné příklady kódu rozšířené konfigurace prognózování, mezi které patří:
- Detekce svátků a extrakce příznaků
- Postupné křížové ověřování původu
- Konfigurovatelné prodlevy
- Agregační funkce posuvného okna
Další kroky
- Přečtěte si další informace o tom, jak nasadit model AutoML do online koncového bodu.
- Další informace o interpretovatelnosti: vysvětlení modelů v automatizovaném strojovém učení (Preview)
- Přečtěte si, jak AutoML vytváří modely prognózování.