Nastavení AutoML pro trénování modelů počítačového zpracování obrazu pomocí Pythonu (v1)
PLATÍ PRO: Python SDK azureml v1
Python SDK azureml v1
Důležité
Některé příkazy Azure CLI v tomto článku používají azure-cli-mlrozšíření Azure Machine Učení ( nebo v1). Podpora rozšíření v1 skončí 30. září 2025. Do tohoto data budete moct nainstalovat a používat rozšíření v1.
Doporučujeme přejít na mlrozšíření (nebo v2) před 30. zářím 2025. Další informace o rozšíření v2 najdete v tématu Rozšíření Azure ML CLI a Python SDK v2.
Důležité
Tato funkce je v současné době ve verzi Public Preview. Tato verze Preview je poskytována bez smlouvy o úrovni služeb. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti. Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
V tomto článku se dozvíte, jak trénovat modely počítačového zpracování obrazu na datech obrázků pomocí automatizovaného strojového učení v sadě Azure Machine Učení Python SDK.
Automatizované strojové učení podporuje trénování modelů pro úlohy počítačového zpracování obrazu, jako jsou klasifikace obrázků, rozpoznávání objektů nebo segmentace instancí. Vytváření modelů automatizovaného strojového učení pro úlohy počítačového zpracování obrazu se v současné době podporuje prostřednictvím sady Python SDK služby Azure Machine Learning. Výsledné experimentování běží, modely a výstupy jsou přístupné z uživatelského rozhraní studio Azure Machine Learning. Přečtěte si další informace o automatizovaném ml pro úlohy počítačového zpracování obrazu na datech obrázků.
Poznámka:
Automatizované strojové učení pro úlohy počítačového zpracování obrazu je dostupné pouze prostřednictvím sady Azure Machine Učení Python SDK.
Požadavky
Pracovní prostor služby Azure Machine Learning. Pokud chcete vytvořit pracovní prostor, přečtěte si téma Vytvoření prostředků pracovního prostoru.
Nainstalovaná sada Azure Machine Učení Python SDK. Pokud chcete nainstalovat sadu SDK, kterou můžete provést,
Vytvořte výpočetní instanci, která automaticky nainstaluje sadu SDK a je předem nakonfigurovaná pro pracovní postupy ML. Další informace najdete v tématu Vytvoření a správa výpočetní instance služby Azure Machine Učení.
automlNainstalujte balíček sami, který zahrnuje výchozí instalaci sady SDK.
Poznámka:
Pouze Python 3.7 a 3.8 jsou kompatibilní s automatizovanou podporou strojového učení pro úlohy počítačového zpracování obrazu.
Vyberte typ úkolu.
Automatizované strojové učení pro image podporuje následující typy úloh:
| Typ úkolu | Syntaxe konfigurace AutoMLImage |
|---|---|
| klasifikace obrázků | ImageTask.IMAGE_CLASSIFICATION |
| klasifikace obrázků s více popisky | ImageTask.IMAGE_CLASSIFICATION_MULTILABEL |
| Rozpoznávání objektů obrázku | ImageTask.IMAGE_OBJECT_DETECTION |
| Segmentace instance image | ImageTask.IMAGE_INSTANCE_SEGMENTATION |
Tento typ úkolu je povinný parametr a je předán pomocí task parametru v souboru AutoMLImageConfig.
Příklad:
from azureml.train.automl import AutoMLImageConfig
from azureml.automl.core.shared.constants import ImageTask
automl_image_config = AutoMLImageConfig(task=ImageTask.IMAGE_OBJECT_DETECTION)
Trénovací a ověřovací data
Abyste mohli generovat modely počítačového zpracování obrazu, musíte jako vstup pro trénování modelu použít označení data obrázků ve formě objektu Azure Machine Učení TabularDataset. Můžete použít TabularDatasetbuď exportovaný z projektu popisování dat, nebo můžete vytvořit nový TabularDataset s označenými trénovacími daty.
Pokud jsou trénovací data v jiném formátu (například pascal VOC nebo COCO), můžete použít pomocné skripty, které jsou součástí ukázkových poznámkových bloků, a převést data na JSONL. Přečtěte si další informace o tom , jak připravit data pro úlohy počítačového zpracování obrazu pomocí automatizovaného strojového učení.
Upozorňující
Vytváření tabulkových datových sad z dat ve formátu JSONL je podporováno pouze pomocí sady SDK pro tuto funkci. Vytvoření datové sady prostřednictvím uživatelského rozhraní se v tuto chvíli nepodporuje. Odteď uživatelské rozhraní nerozpozná datový typ StreamInfo, což je datový typ používaný pro adresy URL obrázků ve formátu JSONL.
Poznámka:
Aby bylo možné odeslat spuštění AutoML, musí mít trénovací datová sada alespoň 10 obrázků.
Ukázky schématu JSONL
Struktura TabularDataset závisí na úkolu, který je v ruce. U typů úloh počítačového zpracování obrazu se skládá z následujících polí:
| Pole | Popis |
|---|---|
image_url |
Obsahuje cestu k souboru jako objekt StreamInfo. |
image_details |
Informace o metadatech obrázků se skládají z výšky, šířky a formátu. Toto pole je volitelné, a proto může nebo nemusí existovat. |
label |
Reprezentace popisku obrázku ve formátu JSON na základě typu úlohy. |
Následuje ukázkový soubor JSONL pro klasifikaci obrázků:
{
"image_url": "AmlDatastore://image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "AmlDatastore://image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
Následující kód je ukázkový soubor JSONL pro detekci objektů:
{
"image_url": "AmlDatastore://image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "AmlDatastore://image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
Využívání dat
Jakmile jsou data ve formátu JSONL, můžete vytvořit TabularDataset s následujícím kódem:
ws = Workspace.from_config()
ds = ws.get_default_datastore()
from azureml.core import Dataset
training_dataset = Dataset.Tabular.from_json_lines_files(
path=ds.path('odFridgeObjects/odFridgeObjects.jsonl'),
set_column_types={'image_url': DataType.to_stream(ds.workspace)})
training_dataset = training_dataset.register(workspace=ws, name=training_dataset_name)
Automatizované strojové učení neukládá žádné omezení velikosti trénovacích nebo ověřovacích dat pro úlohy počítačového zpracování obrazu. Maximální velikost datové sady je omezená pouze vrstvou úložiště za datovou sadou (tj. úložištěm objektů blob). Neexistuje minimální počet obrázků nebo popisků. Doporučujeme ale začít s minimálně 10 až 15 vzorky na popisek, aby byl výstupní model dostatečně natrénovaný. Čím vyšší je celkový počet popisků/tříd, tím více vzorků na popisek potřebujete.
Trénovací data jsou povinná a předávají se pomocí parametru training_data . Volitelně můžete jako ověřovací datovou sadu zadat jinou tabulkovou datovou sadu, která se použije pro váš model s parametrem validation_data AutoMLImageConfig. Pokud nezadáte žádnou ověřovací datovou sadu, použije se pro ověření ve výchozím nastavení 20 % trénovacích dat, pokud nepředáte validation_size argument s jinou hodnotou.
Příklad:
from azureml.train.automl import AutoMLImageConfig
automl_image_config = AutoMLImageConfig(training_data=training_dataset)
Výpočetní prostředí pro spuštění experimentu
Poskytnutí cílového výpočetního objektu pro automatizované strojové učení pro trénování modelu Modely automatizovaného strojového učení pro úlohy počítačového zpracování obrazu vyžadují skladové položky GPU a podporují rodiny nc a ND. Pro rychlejší trénování doporučujeme řady NCsv3 (s grafickými procesory v100). Cílový výpočetní objekt s skladovou jednotkou virtuálního počítače s více GPU využívá k urychlení trénování několik GPU. Navíc při nastavování cílového výpočetního objektu s více uzly můžete provádět rychlejší trénování modelu prostřednictvím paralelismu při ladění hyperparametrů pro váš model.
Poznámka:
Pokud jako cílový výpočetní objekt používáte výpočetní instanci , ujistěte se, že není spuštěno více úloh AutoML najednou. Ujistěte se také, že max_concurrent_iterations je v prostředcích experimentu nastavená hodnota 1.
Výpočetní cíl je povinný parametr a předává se pomocí compute_target parametru AutoMLImageConfig. Příklad:
from azureml.train.automl import AutoMLImageConfig
automl_image_config = AutoMLImageConfig(compute_target=compute_target)
Konfigurace algoritmů modelu a hyperparametrů
S podporou úloh počítačového zpracování obrazu můžete řídit algoritmus modelu a uklidit hyperparametry. Tyto algoritmy modelu a hyperparametry se předávají jako prostor parametrů pro úklid.
Algoritmus modelu se vyžaduje a předává se prostřednictvím model_name parametru. Můžete zadat jeden model_name nebo vybrat mezi více.
Podporované algoritmy modelů
Následující tabulka shrnuje podporované modely pro jednotlivé úlohy počítačového zpracování obrazu.
| Úloha | Algoritmy modelů | Syntaxe řetězcového literáludefault_model* označeno * |
|---|---|---|
| Klasifikace obrázku (více tříd a více popisků) |
MobileNet: Lehké modely pro mobilní aplikace ResNet: Zbytkové sítě ResNeSt: Rozdělení sítí pozornosti SE-ResNeXt50: Sítě stisknuté a vzrušující ViT: Sítě transformátoru obrazu |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224 (malý) vitb16r224* (základna) vitl16r224 (velký) |
| Detekce objektů | YOLOv5: Model detekce objektů v jedné fázi Rychlejší analýza RCNN ResNet FPN: Modely detekce objektů ve dvou fázích Sítnice ResNet FPN: adresní nerovnováha třídy s kontaktní ztrátou Poznámka: Informace o model_size hyperparametrech pro velikosti modelů YOLOv5 |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| Segmentace instancí | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn maskrcnn_resnet50_fpn |
Kromě řízení algoritmu modelu můžete také ladit hyperparametry používané pro trénování modelu. Zatímco mnohé z vystavených hyperparametrů jsou nezávislé na modelu, existují instance, ve kterých jsou hyperparametry specifické pro úlohu nebo pro konkrétní model. Přečtěte si další informace o dostupných hyperparametrech pro tyto instance.
Rozšíření dat
Obecně platí, že výkon modelu hlubokého učení se může často zlepšit s více daty. Rozšíření dat je praktická technika pro zvětšení velikosti dat a variability datové sady, která pomáhá zabránit přeurčení a zlepšit schopnost zobecnění modelu u nezobrazených dat. Automatizované strojové učení používá různé techniky rozšiřování dat na základě úlohy počítačového zpracování obrazu před podáváním vstupních obrázků do modelu. V současné době není k dispozici žádný zpřístupněný hyperparametr pro řízení rozšíření dat.
| Úloha | Ovlivněná datová sada | Použité techniky rozšiřování dat |
|---|---|---|
| Klasifikace obrázků (více tříd a více popisků) | Školení Ověřování a testování |
Náhodná změna velikosti a oříznutí, vodorovné překlopení, změna barvy (jas, kontrast, sytost a odstín), normalizace pomocí střední hodnoty a směrodatné odchylky imagenetu Změna velikosti, středového oříznutí, normalizace |
| Rozpoznávání objektů, segmentace instancí | Školení Ověřování a testování |
Náhodné oříznutí kolem ohraničujících polí, rozbalení, vodorovné překlopení, normalizace, změna velikosti Normalizace, změna velikosti |
| Rozpoznávání objektů pomocí yolov5 | Školení Ověřování a testování |
Mozaika, náhodný affine (otočení, překlad, měřítko, stříšku), vodorovné překlopení Změna velikosti poštovní schránky |
Konfigurace nastavení experimentu
Před velkým úklidem pro hledání optimálních modelů a hyperparametrů doporučujeme vyzkoušet výchozí hodnoty, abyste získali první směrný plán. V dalším kroku můžete prozkoumat více hyperparametrů pro stejný model před přemístit více modelů a jejich parametry. Tímto způsobem můžete použít iterativní přístup, protože s více modely a více hyperparametry pro každý z nich roste prostor vyhledávání exponenciálně a k nalezení optimálních konfigurací potřebujete více iterací.
Pokud chcete použít výchozí hodnoty hyperparametrů pro daný algoritmus (například yolov5), můžete zadat konfiguraci pro spuštění image AutoML následujícím způsobem:
from azureml.train.automl import AutoMLImageConfig
from azureml.train.hyperdrive import GridParameterSampling, choice
from azureml.automl.core.shared.constants import ImageTask
automl_image_config_yolov5 = AutoMLImageConfig(task=ImageTask.IMAGE_OBJECT_DETECTION,
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
hyperparameter_sampling=GridParameterSampling({'model_name': choice('yolov5')}),
iterations=1)
Jakmile vytvoříte základní model, můžete chtít optimalizovat výkon modelu, abyste mohli přemístit algoritmus modelu a prostor hyperparametrů. Následující ukázkovou konfiguraci můžete použít k úklidu hyperparametrů pro každý algoritmus, výběru z rozsahu hodnot pro learning_rate, optimalizátoru, lr_scheduler atd., a vygenerovat model s optimální primární metrikou. Pokud nejsou zadány hodnoty hyperparametrů, použijí se výchozí hodnoty pro zadaný algoritmus.
Primární metrika
Primární metrika použitá pro optimalizaci modelu a ladění hyperparametrů závisí na typu úlohy. Použití jiných primárních hodnot metrik se v současné době nepodporuje.
accuracypro IMAGE_CLASSIFICATIONioupro IMAGE_CLASSIFICATION_MULTILABELmean_average_precisionpro IMAGE_OBJECT_DETECTIONmean_average_precisionpro IMAGE_INSTANCE_SEGMENTATION
Rozpočet experimentu
Volitelně můžete zadat maximální časový rozpočet experimentu AutoML Vision pomocí experiment_timeout_hours – dobu v hodinách před ukončením experimentu. Pokud není zadaný žádný, výchozí časový limit experimentu je sedm dnů (maximálně 60 dnů).
Uklidení hyperparametrů pro váš model
Při trénování modelů počítačového zpracování obrazu závisí výkon modelu silně na vybraných hodnotách hyperparametrů. Často můžete chtít hyperparametry ladit, abyste získali optimální výkon. Díky podpoře úloh počítačového zpracování obrazu v automatizovaném strojovém učení můžete hyperparametry uklidit a najít optimální nastavení pro váš model. Tato funkce používá možnosti ladění hyperparametrů ve službě Azure Machine Učení. Naučte se ladit hyperparametry.
Definování prostoru pro hledání parametrů
Můžete definovat algoritmy modelu a hyperparametry, které se mají v prostoru parametrů uklidit.
- Seznam podporovaných algoritmů modelu pro jednotlivé typy úloh najdete v tématu Konfigurace algoritmů modelů a hyperparametrů .
- Viz Hyperparametry pro úlohy počítačového zpracování obrazu hyperparametry pro každý typ úlohy počítačového zpracování obrazu.
- Podrobnosti o podporovaných distribucích najdete v samostatných a průběžných hyperparametrech.
Metody vzorkování pro úklid
Při úklidu hyperparametrů je potřeba zadat metodu vzorkování, která se má použít k úklidu nad definovaným prostorem parametrů. V současné době jsou s parametrem hyperparameter_sampling podporovány následující metody vzorkování:
Poznámka:
V současné době podporují podmíněné hyperparametry pouze náhodné vzorkování a vzorkování mřížky.
Zásady předčasného ukončení
Můžete automaticky ukončit špatně výkonné spuštění pomocí zásad předčasného ukončení. Předčasné ukončení zlepšuje výpočetní efektivitu a šetří výpočetní prostředky, které by jinak byly vynaloženy na méně slibné konfigurace. Automatizované strojové učení pro image podporuje následující zásady předčasného ukončení s využitím tohoto parametru early_termination_policy . Pokud není zadána žádná zásada ukončení, všechny konfigurace se spustí až do dokončení.
Přečtěte si další informace o tom, jak nakonfigurovat zásady předčasného ukončení pro úklid hyperparametrů.
Zdroje pro úklid
Prostředky vynaložené na úklid hyperparametrů můžete řídit tak, že zadáte a iterations zametáte max_concurrent_iterations .
| Parametr | Detail |
|---|---|
iterations |
Povinný parametr pro maximální počet konfigurací, které se mají uklidit. Musí být celé číslo od 1 do 1000. Při zkoumání pouze výchozích hyperparametrů pro daný algoritmus modelu nastavte tento parametr na hodnotu 1. |
max_concurrent_iterations |
Maximální počet spuštění, která se dají spustit souběžně. Pokud není zadáno, spustí se všechna spuštění paralelně. Pokud je zadáno, musí být celé číslo od 1 do 100. POZNÁMKA: Počet souběžných spuštění se hradí u prostředků dostupných v zadaném cílovém výpočetním objektu. Ujistěte se, že cílový výpočetní objekt má dostupné prostředky pro požadovanou souběžnost. |
Poznámka:
Kompletní ukázku konfigurace úklidu najdete v tomto kurzu.
Argumenty
Jako argumenty můžete předat pevná nastavení nebo parametry, které se během úklidu prostoru parametrů nemění. Argumenty se předávají ve dvojicích name-value a název musí mít předponu dvojitou pomlčkou.
from azureml.train.automl import AutoMLImageConfig
arguments = ["--early_stopping", 1, "--evaluation_frequency", 2]
automl_image_config = AutoMLImageConfig(arguments=arguments)
Přírůstkové trénování (volitelné)
Po dokončení trénování máte možnost model dále trénovat načtením kontrolního bodu natrénovaného modelu. Pro přírůstkové trénování můžete použít stejnou datovou sadu nebo jinou datovou sadu.
Pro přírůstkové trénování jsou k dispozici dvě možnosti. Můžete provádět následující akce:
- Předejte ID spuštění, ze kterého chcete kontrolní bod načíst.
- Předávat kontrolní body přes FileDataset.
Předání kontrolního bodu přes ID spuštění
K vyhledání ID spuštění z požadovaného modelu můžete použít následující kód.
# find a run id to get a model checkpoint from
target_checkpoint_run = automl_image_run.get_best_child()
Pokud chcete kontrolní bod předat prostřednictvím ID spuštění, musíte použít checkpoint_run_id parametr.
automl_image_config = AutoMLImageConfig(task='image-object-detection',
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
checkpoint_run_id= target_checkpoint_run.id,
primary_metric='mean_average_precision',
**tuning_settings)
automl_image_run = experiment.submit(automl_image_config)
automl_image_run.wait_for_completion(wait_post_processing=True)
Předání kontrolního bodu přes FileDataset
Pokud chcete předat kontrolní bod přes FileDataset, musíte použít checkpoint_dataset_id parametry a checkpoint_filename parametry.
# download the checkpoint from the previous run
model_name = "outputs/model.pt"
model_local = "checkpoints/model_yolo.pt"
target_checkpoint_run.download_file(name=model_name, output_file_path=model_local)
# upload the checkpoint to the blob store
ds.upload(src_dir="checkpoints", target_path='checkpoints')
# create a FileDatset for the checkpoint and register it with your workspace
ds_path = ds.path('checkpoints/model_yolo.pt')
checkpoint_yolo = Dataset.File.from_files(path=ds_path)
checkpoint_yolo = checkpoint_yolo.register(workspace=ws, name='yolo_checkpoint')
automl_image_config = AutoMLImageConfig(task='image-object-detection',
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
checkpoint_dataset_id= checkpoint_yolo.id,
checkpoint_filename='model_yolo.pt',
primary_metric='mean_average_precision',
**tuning_settings)
automl_image_run = experiment.submit(automl_image_config)
automl_image_run.wait_for_completion(wait_post_processing=True)
Odeslání spuštění
Až budete mít AutoMLImageConfig objekt připravený, můžete experiment odeslat.
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-image-object-detection")
automl_image_run = experiment.submit(automl_image_config)
Výstupy a metriky vyhodnocení
Spuštění automatizovaného trénování ML generuje výstupní soubory modelu, vyhodnocovací metriky, protokoly a artefakty nasazení, jako je soubor bodování a soubor prostředí, které je možné zobrazit z výstupů a protokolů a metrik podřízeného spuštění.
Tip
V části Zobrazit výsledky spuštění zkontrolujte, jak přejít na výsledky úlohy.
Definice a příklady výkonnostních grafů a metrik poskytovaných pro každé spuštění najdete v tématu Vyhodnocení výsledků experimentů automatizovaného strojového učení.
Registrace a nasazení modelu
Po dokončení spuštění můžete zaregistrovat model vytvořený z nejlepšího spuštění (konfigurace, která způsobila nejlepší primární metriku).
best_child_run = automl_image_run.get_best_child()
model_name = best_child_run.properties['model_name']
model = best_child_run.register_model(model_name = model_name, model_path='outputs/model.pt')
Jakmile zaregistrujete model, který chcete použít, můžete ho nasadit jako webovou službu ve službě Azure Container Instances (ACI) nebo Azure Kubernetes Service (AKS). ACI je ideální možností pro testování nasazení, zatímco AKS je vhodnější pro vysoce škálovatelné produkční využití.
Tento příklad nasadí model jako webovou službu v AKS. Pokud chcete nasadit v AKS, nejprve vytvořte výpočetní cluster AKS nebo použijte existující cluster AKS. Pro cluster nasazení můžete použít skladové položky virtuálních počítačů s gpu nebo procesorem.
from azureml.core.compute import ComputeTarget, AksCompute
from azureml.exceptions import ComputeTargetException
# Choose a name for your cluster
aks_name = "cluster-aks-gpu"
# Check to see if the cluster already exists
try:
aks_target = ComputeTarget(workspace=ws, name=aks_name)
print('Found existing compute target')
except ComputeTargetException:
print('Creating a new compute target...')
# Provision AKS cluster with GPU machine
prov_config = AksCompute.provisioning_configuration(vm_size="STANDARD_NC6",
location="eastus2")
# Create the cluster
aks_target = ComputeTarget.create(workspace=ws,
name=aks_name,
provisioning_configuration=prov_config)
aks_target.wait_for_completion(show_output=True)
Dále můžete definovat konfiguraci odvozování, která popisuje, jak nastavit webovou službu obsahující váš model. Skript bodování a prostředí můžete použít z trénovacího spuštění v konfiguraci odvozování.
from azureml.core.model import InferenceConfig
best_child_run.download_file('outputs/scoring_file_v_1_0_0.py', output_file_path='score.py')
environment = best_child_run.get_environment()
inference_config = InferenceConfig(entry_script='score.py', environment=environment)
Model pak můžete nasadit jako webovou službu AKS.
# Deploy the model from the best run as an AKS web service
from azureml.core.webservice import AksWebservice
from azureml.core.webservice import Webservice
from azureml.core.model import Model
from azureml.core.environment import Environment
aks_config = AksWebservice.deploy_configuration(autoscale_enabled=True,
cpu_cores=1,
memory_gb=50,
enable_app_insights=True)
aks_service = Model.deploy(ws,
models=[model],
inference_config=inference_config,
deployment_config=aks_config,
deployment_target=aks_target,
name='automl-image-test',
overwrite=True)
aks_service.wait_for_deployment(show_output=True)
print(aks_service.state)
Případně můžete model nasadit z uživatelského rozhraní studio Azure Machine Learning. Přejděte na model, který chcete nasadit, na kartě Modely spuštění automatizovaného strojového učení a vyberte Nasadit.
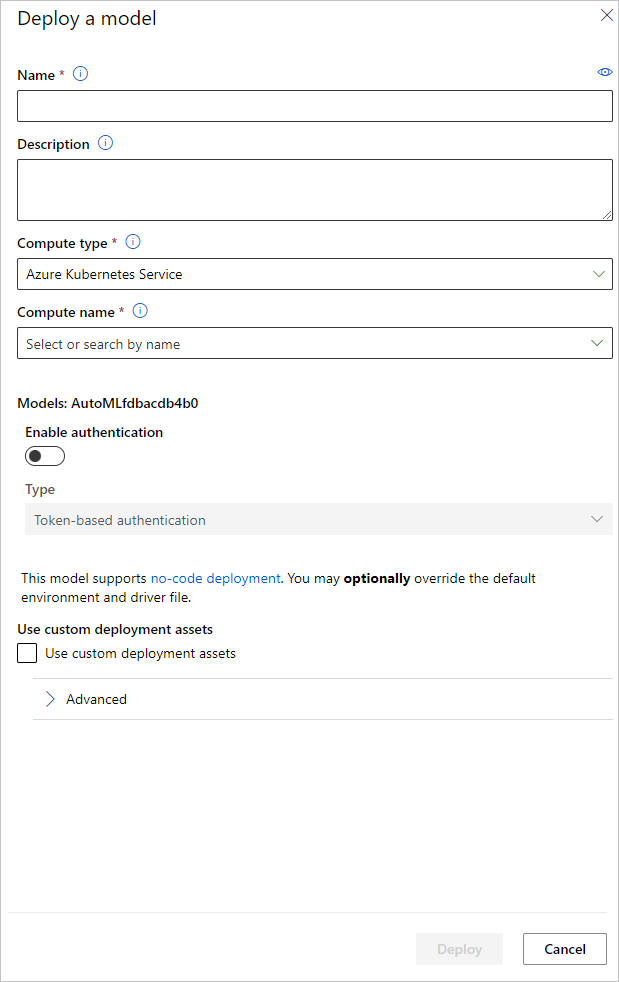
Název koncového bodu nasazení modelu a cluster odvozování můžete nakonfigurovat tak, aby se používal pro nasazení modelu v podokně Nasazení modelu .
Aktualizace konfigurace odvozování
V předchozím kroku jsme stáhli soubor outputs/scoring_file_v_1_0_0.py bodování z nejlepšího modelu do místního score.py souboru a použili jsme ho k vytvoření objektu InferenceConfig . Tento skript lze upravit tak, aby v případě potřeby po stažení a před vytvořením InferenceConfigsouboru změnil nastavení odvozování specifické pro model . Toto je například část kódu, která inicializuje model v souboru bodování:
...
def init():
...
try:
logger.info("Loading model from path: {}.".format(model_path))
model_settings = {...}
model = load_model(TASK_TYPE, model_path, **model_settings)
logger.info("Loading successful.")
except Exception as e:
logging_utilities.log_traceback(e, logger)
raise
...
Každý z úkolů (a některé modely) má ve slovníku model_settings sadu parametrů. Ve výchozím nastavení používáme stejné hodnoty pro parametry, které byly použity během trénování a ověřování. V závislosti na chování, které potřebujeme při použití modelu pro odvozování, můžeme tyto parametry změnit. Níže najdete seznam parametrů pro každý typ úlohy a model.
| Úloha | Název parametru | Výchozí |
|---|---|---|
| Klasifikace obrázků (více tříd a více popisků) | valid_resize_sizevalid_crop_size |
256 224 |
| Detekce objektů | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0.3 0.5 100 |
Rozpoznávání objektů pomocí yolov5 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 střední 0,1 0.5 |
| Segmentace instancí | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0.3 0.5 100 0.5 100 False JPG |
Podrobný popis hyperparametrů specifických pro úlohu najdete v hyperparametrech pro úlohy počítačového zpracování obrazu v automatizovaném strojovém učení.
Pokud chcete použít provázání a chcete řídit chování provazování, jsou k dispozici následující parametry: tile_grid_sizetile_overlap_ratio a tile_predictions_nms_thresh. Další podrobnosti o těchtoparametrch
Příklady poznámkových bloků
Podrobné příklady kódu a případy použití najdete v ukázkách automatizovaného strojového učení v úložišti poznámkových bloků na GitHubu. Projděte si ukázky specifické pro vytváření modelů počítačového zpracování obrazu ve složkách s předponou image.