Nastavení projektu popisování obrázků
Naučte se vytvářet a spouštět projekty popisování dat pro označování obrázků ve službě Azure Machine Learning. Pomocí popisování dat s asistencí strojového učení nebo popisování smyčky člověka v rámci smyčky vám pomůže s úlohou.
Nastavte popisky pro klasifikaci, detekci objektů (ohraničující rámeček), segmentaci instance (mnohoúhelník) nebo sémantickou segmentaci (Preview).
Pomocí nástroje pro popisování dat ve službě Azure Machine Learning můžete také vytvořit projekt popisků textu.
Důležité
Položky označené (Preview) v tomto článku jsou aktuálně ve verzi Public Preview. Verze Preview je poskytována bez smlouvy o úrovni služeb a nedoporučuje se pro produkční úlohy. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti. Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
Možnosti označování obrázků
Popisování dat ve službě Azure Machine Learning je nástroj, který můžete použít k vytváření, správě a monitorování projektů popisování dat. Použijte ji k následujícím akcím:
- Koordinujte data, popisky a členy týmu a efektivně spravujte úkoly označování.
- Sledujte průběh a udržujte frontu nedokončených úkolů popisování.
- Spusťte a zastavte projekt a určete průběh popisování.
- Zkontrolujte a exportujte označená data jako datovou sadu Azure Machine Learning.
Důležité
Obrázky dat, se kterými pracujete v nástroji pro popisování dat ve službě Azure Machine Learning, musí být dostupné v úložišti dat Azure Blob Storage. Pokud nemáte existující úložiště dat, můžete datové soubory nahrát do nového úložiště dat při vytváření projektu.
Data obrázku mohou být jakýkoli soubor, který má jednu z těchto přípon souborů:
.jpg.jpeg.png.jpe.jfif.bmp.tif.tiff.dcm.dicom
Každý soubor je položka, která má být označena.
Datový asset můžete použít MLTable také jako vstup do projektu popisování obrázků, pokud jsou obrázky v tabulce jedním z výše uvedených formátů. Další informace naleznete v tématu Použití MLTable datových prostředků.
Požadavky
Tyto položky slouží k nastavení popisků obrázků ve službě Azure Machine Learning:
- Data, která chcete označit, buď v místních souborech, nebo ve službě Azure Blob Storage.
- Sada popisků, které chcete použít.
- Pokyny pro označování.
- Předplatné Azure. Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet.
- Pracovní prostor služby Azure Machine Learning. Viz Vytvoření pracovního prostoru Azure Machine Learning.
Vytvoření projektu pro označování obrázků
Projekty popisování se spravují ve službě Azure Machine Learning. Ke správě projektů použijte stránku Popisování dat ve službě Machine Learning.
Pokud už jsou vaše data ve službě Azure Blob Storage, před vytvořením projektu popisků se ujistěte, že jsou k dispozici jako úložiště dat.
Pokud chcete vytvořit projekt, vyberte Přidat projekt.
Jako název projektu zadejte název projektu.
Název projektu nemůžete znovu použít, i když projekt odstraníte.
Pokud chcete vytvořit projekt popisků obrázků, jako typ média vyberte Obrázek.
U typu úlohy Popisování vyberte možnost pro váš scénář:
- Pokud chcete na obrázek ze sady popisků použít jenom jeden popisek , vyberte více tříd klasifikace obrázků.
- Pokud chcete u obrázku ze sady popisků použít jeden nebo více popisků, vyberte více popisek klasifikace obrázků. Například fotka psa může být označena psem i denním časem.
- Pokud chcete každému objektu v obrázku přiřadit popisek a přidat ohraničující rámečky, vyberte identifikaci objektu (ohraničující pole).
- Pokud chcete přiřadit popisek každému objektu v obrázku a nakreslit mnohoúhelník kolem každého objektu, vyberte Mnohoúhelník (Segmentace instance).
- Pokud chcete na obrázku nakreslit masky a přiřadit třídu popisku na úrovni pixelů, vyberte Sémantic Segmentation (Preview).
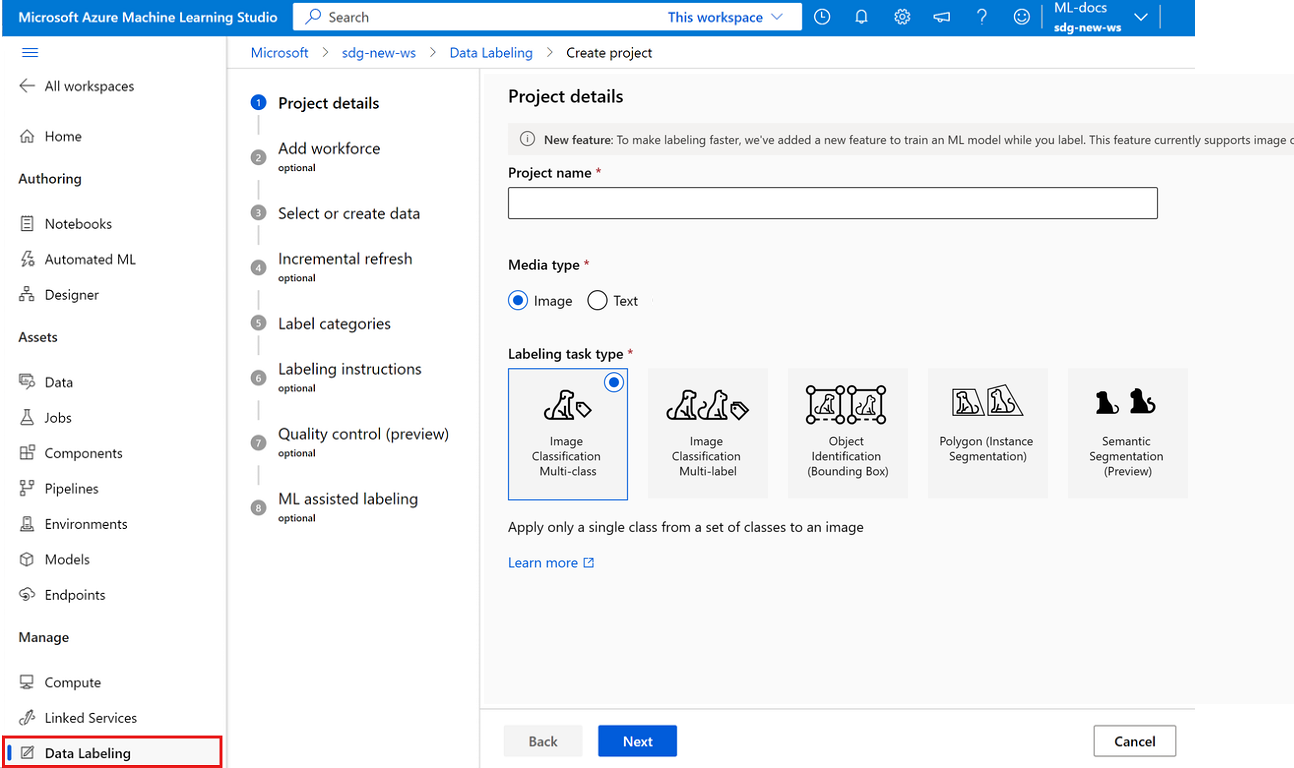
Pokračujte výběrem tlačítka Další.
Přidání pracovníků (volitelné)
Vyberte Použít společnost popisující dodavatele z Azure Marketplace jenom v případě, že jste zapsali společnost popisující data z Azure Marketplace. Pak vyberte dodavatele. Pokud se váš dodavatel v seznamu nezobrazí, zrušte zaškrtnutí této možnosti.
Ujistěte se, že jste nejprve kontaktovali dodavatele a podepsali smlouvu. Další informace najdete v tématu Práce s dodavatelem popisků dat (Preview).
Pokračujte výběrem tlačítka Další.
Zadání dat, která se mají označit
Pokud jste už vytvořili datovou sadu, která obsahuje vaše data, vyberte datovou sadu v rozevíracím seznamu Vybrat existující datovou sadu .
Můžete také vybrat možnost Vytvořit datovou sadu pro použití existujícího úložiště dat Azure nebo nahrát místní soubory.
Poznámka:
Projekt nemůže obsahovat více než 500 000 souborů. Pokud vaše datová sada překročí tento počet souborů, načtou se jenom prvních 500 000 souborů.
Mapování datových sloupců (Preview)
Pokud vyberete datový asset TABULKY MLTable, zobrazí se jiný krok mapování sloupců dat, ve kterém můžete zadat sloupec, který obsahuje adresy URL obrázků.
Je nutné zadat sloupec, který se mapuje na pole Obrázek . Volitelně můžete také mapovat další sloupce, které jsou v datech. Pokud například data obsahují sloupec Popisek , můžete je namapovat na pole Kategorie . Pokud vaše data obsahují sloupec spolehlivosti, můžete je namapovat na pole Spolehlivosti.
Pokud importujete popisky z předchozího projektu, musí být popisky ve stejném formátu jako popisky, které vytváříte. Pokud například vytváříte ohraničující popisky rámečku, musí být popisky, které importujete, také ohraničující popisky rámečku.
Možnosti importu (Preview)
Pokud do kroku Mapování datových sloupců zahrnete sloupec Kategorie, pomocí možností importu určete, jak s označenými daty zacházet.
Je nutné zadat sloupec, který se mapuje na pole Obrázek . Volitelně můžete také mapovat další sloupce, které jsou v datech. Pokud například data obsahují sloupec Popisek , můžete je namapovat na pole Kategorie . Pokud vaše data obsahují sloupec spolehlivosti, můžete je namapovat na pole Spolehlivosti.
Pokud importujete popisky z předchozího projektu, musí být popisky ve stejném formátu jako popisky, které vytváříte. Pokud například vytváříte ohraničující popisky rámečku, musí být popisky, které importujete, také ohraničující popisky rámečku.
Vytvoření datové sady z úložiště dat Azure
V mnoha případech můžete nahrát místní soubory. Průzkumník služby Azure Storage ale poskytuje rychlejší a robustnější způsob přenosu velkého množství dat. Jako výchozí způsob přesouvání souborů doporučujeme Průzkumník služby Storage.
Vytvoření datové sady z dat, která jsou už uložená ve službě Blob Storage:
- Vyberte Vytvořit.
- Jako název zadejte název datové sady. Volitelně můžete zadat popis.
- Ujistěte se, že je typ datové sady nastavený na Soubor. Obrázky podporují jenom typy datových sad souborů.
- Vyberte Další.
- Vyberte Z úložiště Azure a pak vyberte Další.
- Vyberte úložiště dat a pak vyberte Další.
- Pokud jsou vaše data v podsložce ve službě Blob Storage, zvolte Procházet a vyberte cestu.
- Pokud chcete zahrnout všechny soubory do podsložek vybrané cesty, připojte
/**se k cestě. - Pokud chcete zahrnout všechna data v aktuálním kontejneru a jejích podsložkách, připojte
**/*.*se k cestě.
- Pokud chcete zahrnout všechny soubory do podsložek vybrané cesty, připojte
- Vyberte Vytvořit.
- Vyberte datový asset, který jste vytvořili.
Vytvoření datové sady z nahraných dat
Přímé nahrání dat:
- Vyberte Vytvořit.
- Jako název zadejte název datové sady. Volitelně můžete zadat popis.
- Ujistěte se, že je typ datové sady nastavený na Soubor. Obrázky podporují jenom typy datových sad souborů.
- Vyberte Další.
- Vyberte Z místních souborů a pak vyberte Další.
- (Volitelné) Vyberte úložiště dat. Můžete také ponechat výchozí možnost pro nahrání do výchozího úložiště objektů blob (workspaceblobstore) pro váš pracovní prostor Machine Learning.
- Vyberte Další.
- Vyberte Nahrát>soubory nebo Nahrát složku pro nahrání>a vyberte místní soubory nebo složky, které chcete nahrát.
- V okně prohlížeče vyhledejte soubory nebo složky a pak vyberte Otevřít.
- Pokračujte výběrem možnosti Nahrát , dokud nezadáte všechny soubory a složky.
- Volitelně můžete zaškrtnout políčko Přepsat, pokud už existuje . Ověřte seznam souborů a složek.
- Vyberte Další.
- Potvrďte podrobnosti. Výběrem možnosti Zpět upravte nastavení nebo výběrem možnosti Vytvořit vytvořte datovou sadu.
- Nakonec vyberte datový asset, který jste vytvořili.
Konfigurace přírůstkové aktualizace
Pokud plánujete do datové sady přidat nové datové soubory, přidejte je do projektu pomocí přírůstkové aktualizace.
Pokud je v pravidelných intervalech nastavená možnost Povolit přírůstkovou aktualizaci, datová sada se pravidelně kontroluje, aby se nové soubory přidávaly do projektu na základě míry dokončování popisků. Kontrola nových dat se zastaví, když projekt obsahuje maximálně 500 000 souborů.
Pokud chcete, aby projekt průběžně monitorovávat nová data v úložišti dat, vyberte Povolit přírůstkovou aktualizaci v pravidelných intervalech .
Zrušte výběr, pokud nechcete, aby se do projektu automaticky přidaly nové soubory v úložišti dat.
Důležité
Pokud je povolená přírůstková aktualizace, nevytvávejte pro datovou sadu, kterou chcete aktualizovat, novou verzi. Pokud ano, aktualizace se nezobrazí, protože projekt popisování dat je připnutý k počáteční verzi. Místo toho použijte Průzkumník služby Azure Storage k úpravě dat v příslušné složce ve službě Blob Storage.
Také neodebíjejte data. Odebrání dat z datové sady, která projekt používá, způsobí chybu v projektu.
Po vytvoření projektu můžete pomocí karty Podrobnosti změnit přírůstkovou aktualizaci, zobrazit časové razítko poslední aktualizace a požádat o okamžitou aktualizaci dat.
Určení tříd popisků
Na stránce Kategorie popisků zadejte sadu tříd pro kategorizaci dat.
Přesnost a rychlost popisovačů jsou ovlivněny jejich schopností vybírat mezi třídami. Například místo úplného rodu a druhů pro rostliny nebo zvířata použijte kód pole nebo zkracujte rod.
Můžete použít buď plochý seznam, nebo vytvořit skupiny popisků.
Pokud chcete vytvořit plochý seznam, vyberte Přidat kategorii popisků a vytvořte každý popisek.
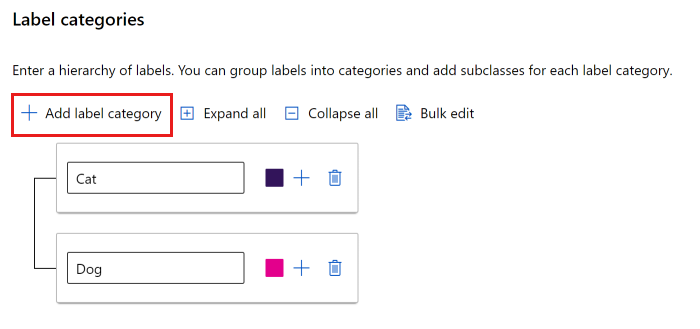
Pokud chcete vytvořit popisky v různých skupinách, vyberte Přidat kategorii popisků a vytvořte popisky nejvyšší úrovně. Pak vyberte znaménko plus (+) pod každou nejvyšší úrovní a vytvořte další úroveň popisků pro danou kategorii. Pro libovolné seskupení můžete vytvořit až šest úrovní.
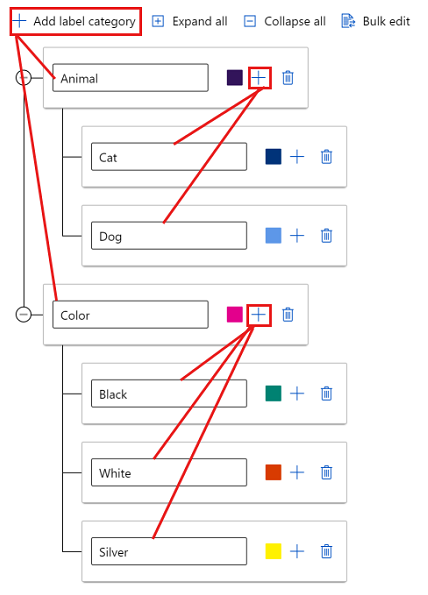
Během procesu označování můžete vybrat popisky na libovolné úrovni. Například popisky Animal, , Animal/Cat, Animal/DogColor/BlackColor, Color/Whitea Color/Silver jsou všechny dostupné volby pro popisek. V projektu s více popisky není nutné vybrat jednu z každé kategorie. Pokud se jedná o váš záměr, nezapomeňte tyto informace zahrnout do pokynů.
Popis úlohy popisování obrázku
Je důležité jasně vysvětlit úlohu popisování. Na stránce s pokyny popisků můžete přidat odkaz na externí web s pokyny pro popisky nebo můžete zadat pokyny v poli pro úpravy na stránce. Udržujte pokyny orientované na úkoly a vhodné pro cílovou skupinu. Zvažte tyto otázky:
- Jaké popisky popisky uvidí a jak si mezi nimi vyberou? Existuje odkaz na text odkazu?
- Co by měli dělat, pokud se zdá, že žádný popisek není vhodný?
- Co by měly dělat, když se zdá, že je více popisků vhodné?
- Jaká prahová hodnota spolehlivosti by se měla použít u popisku? Chcete, aby popisovač byl nejlepší odhadnout, jestli si nejsou jistí?
- Co mají dělat s částečně odlehlé nebo překrývajícími se objekty zájmu?
- Co by měly dělat, když je objekt zájmu oříznut okrajem obrázku?
- Co by měli dělat, když si myslí, že udělali chybu po odeslání štítku?
- Co by měli dělat, když zjistí problémy s kvalitou obrazu, včetně špatných světelných podmínek, odrazů, ztráty fokusu, nezahrnutého pozadí, abnormálních úhlů kamery atd.?
- Co by měli dělat, pokud má více revidujících různé názory na použití popisku?
Mezi důležité otázky týkající se ohraničujících polí patří:
- Jak je pro tento úkol definován ohraničující rámeček? Měl by zůstat zcela na interiéru objektu, nebo by měl být na vnější straně? Měla by se oříznout co nejblíže, nebo je nějaká clearance přijatelná?
- Jakou úroveň péče a konzistence očekáváte, že popisovače budou platit při definování ohraničujících polí?
- Jaká je vizuální definice každé třídy popisků? Můžete zadat seznam normálních případů, okrajů a čítačů pro každou třídu?
- Co mají popisovače dělat, když je objekt malý? Měl by být označený jako objekt nebo by měl tento objekt ignorovat jako pozadí?
- Jak by popisky měly zpracovávat objekt, který se na obrázku zobrazuje jenom částečně?
- Jak by popisovače měly zpracovávat objekt, který je částečně pokryt jiným objektem?
- Jak by popisovače měly zpracovávat objekt, který nemá žádnou jasnou hranici?
- Jak by popisky měly zpracovávat objekt, který není třídou zájmu objektu, ale má vizuální podobnost s příslušným typem objektu?
Poznámka:
Popisky můžou vybrat prvních devět popisků pomocí číselových kláves 1 až 9. Tyto informace můžete chtít zahrnout do pokynů.
Řízení kvality (Preview)
Chcete-li získat přesnější popisky, použijte stránku řízení kvality k odeslání každé položky více popisků.
Důležité
Popisování konsensu je v současné době ve verzi Public Preview.
Verze Preview je poskytována bez smlouvy o úrovni služeb a nedoporučuje se pro produkční úlohy. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti.
Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
Pokud chcete, aby se každá položka odesílala více popiskům, vyberte Povolit popisování konsensu (Preview). Potom nastavte hodnoty pro minimální popisovače a maximální popisky , abyste určili, kolik popisků se má použít. Ujistěte se, že máte k dispozici tolik popisků jako maximální počet. Po spuštění projektu nemůžete tato nastavení změnit.
Pokud je dosaženo konsensus z minimálního počtu popisovačů, položka se označí. Pokud se nenajde shoda, položka se odešle více popiskům. Pokud po tom, co položka přejde na maximální počet popisovačů, neexistuje žádná shoda, jeho stav je Potřeba zkontrolovat a vlastník projektu zodpovídá za označení položky.
Poznámka:
Projekty segmentace instancí nemůžou používat popisování konsensu.
Použití popisků dat s asistencí ML
Pokud chcete urychlit úlohy popisování, můžete na stránce popisování s asistencí ML aktivovat automatické modely strojového učení. Lékařské obrázky (soubory s příponou .dcm ) nejsou součástí asistovaného označování. Pokud je typ projektu Sémantic Segmentation (Preview), popisování s asistencí ML není k dispozici.
Na začátku projektu označování se položky zamíchají do náhodného pořadí, aby se snížil potenciální předsudky. Vytrénovaný model ale odráží všechny předsudky, které jsou přítomné v datové sadě. Pokud je například 80 procent položek jedné třídy, pak přibližně 80 procent dat použitých k trénování modelu v dané třídě.
Pokud chcete povolit asistované popisování, vyberte Povolit popisování s asistencí ML a zadejte GPU. Pokud nemáte v pracovním prostoru GPU, vytvoří se cluster GPU (název prostředku: DefLabelNC6v3, vmsize: Standard_NC6s_v3) a přidá se do pracovního prostoru. Cluster se vytvoří s minimálním počtem nulových uzlů, což znamená, že když se nepoužívá, nic stojí.
Popisování asistovaného strojového učení se skládá ze dvou fází:
- Clustering
- Předběžné označování
Počet označených datových položek, který je potřeba k zahájení asistovaného popisování, není pevné číslo. Toto číslo se může výrazně lišit od jednoho projektu popisování po jiný. U některých projektů je někdy možné zobrazit předběžné nebo clusterové úlohy po ručním označení 300 položek. Popisování s asistencí ML používá techniku označovanou jako transferové učení. Převod učení využívá předem natrénovaný model k zahájení procesu trénování. Pokud se třídy vaší datové sady podobají třídám v předtrénovaném modelu, můžou být po několika stovkách ručně označených položek k dispozici přednabídky. Pokud se vaše datová sada výrazně liší od dat použitých k předtrénování modelu, může proces trvat déle.
Pokud používáte popisování konsensu, použije se popisek konsensu pro trénování.
Vzhledem k tomu, že konečné popisky stále spoléhají na vstup z popisovače, tato technologie se někdy označuje jako popisování human-in-the-loop .
Poznámka:
Popisování dat s asistencí ML nepodporuje výchozí účty úložiště, které jsou zabezpečené za virtuální sítí. Pro popisování dat s asistencí ML musíte použít jiný než výchozí účet úložiště. Za virtuální sítí je možné zabezpečit jiný než výchozí účet úložiště.
Clustering
Po odeslání některých popisků začne klasifikační model seskupovat podobné položky. Tyto podobné obrázky se zobrazují popiskům na stejné stránce, aby byly ruční označování efektivnější. Clustering je užitečný zejména v případě, že popisovač zobrazí mřížku čtyř, šesti nebo devíti obrázků.
Po vytrénování modelu strojového učení na ručně označených datech se model zkrátí na poslední plně propojenou vrstvu. Neoznačené obrázky se pak předávají zkráceným modelem v procesu označovaného jako vkládání nebo featurizace. Tento proces vloží každý obrázek do vysoce dimenzionálního prostoru, který definuje vrstva modelu. Další image v prostoru, které jsou nejblíže k imagi, se používají pro úlohy clusteringu.
Fáze clusteringu se nezobrazuje pro modely detekce objektů ani klasifikaci textu.
Předběžné označování
Po odeslání dostatečného množství popisků pro trénování buď klasifikační model predikuje značky, nebo model detekce objektů předpovídá ohraničující rámečky. Popisovač teď uvidí stránky, které obsahují předpovězené popisky, které už jsou na každé položce. Pro detekci objektů se zobrazují také předpovězená pole. Úloha zahrnuje kontrolu těchto předpovědí a opravu všech nesprávně označených obrázků před odesláním stránky.
Po vytrénování modelu strojového učení na ručně označených datech se model vyhodnotí na testovací sadě ručně označených položek. Vyhodnocení pomáhá určit přesnost modelu při různých prahových hodnotách spolehlivosti. Proces vyhodnocení nastaví prahovou hodnotu spolehlivosti, nad kterou je model dostatečně přesný, aby zobrazoval předznačky. Model se pak vyhodnotí proti neoznačenému datu. Položky s predikcemi, které jsou s větší jistotou než prahová hodnota, se používají k předběžnému označování.
Inicializace projektu popisků obrázků
Po inicializaci projektu popisků jsou některé aspekty projektu neměnné. Typ úkolu ani datovou sadu nemůžete změnit. Popisky a adresu URL popisu úkolu můžete upravit. Před vytvořením projektu pečlivě zkontrolujte nastavení. Po odeslání projektu se vrátíte na stránku přehledu popisků dat, která zobrazuje projekt jako Inicializace.
Poznámka:
Stránka přehledu se nemusí automaticky aktualizovat. Po pozastavení ručně aktualizujte stránku, aby se zobrazil stav projektu jako Vytvořený.
Řešení problému
Problémy s vytvořením projektu nebo přístupem k datům najdete v tématu Řešení potíží s popisky dat.