Přístup k datům v úloze
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
V tomto článku se dozvíte:
- Čtení dat z úložiště Azure v úloze Azure Machine Learning
- Jak zapisovat data z úlohy Azure Machine Learning do Služby Azure Storage
- Rozdíl mezi režimy připojení a stahování .
- Jak používat identitu uživatele a spravovanou identitu pro přístup k datům.
- Nastavení připojení dostupná v úloze
- Optimální nastavení montáže pro běžné scénáře.
- Přístup k datovým prostředkům V1
Požadavky
Předplatné Azure. Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet. Vyzkoušejte bezplatnou nebo placenou verzi služby Azure Machine Learning.
Pracovní prostor Azure Machine Learning
Rychlé zprovoznění
Než prozkoumáte podrobné možnosti, které máte k dispozici při přístupu k datům, nejprve popíšeme relevantní fragmenty kódu pro přístup k datům.
Čtení dat z úložiště Azure v úloze Azure Machine Learning
V tomto příkladu odešlete úlohu Služby Azure Machine Learning, která přistupuje k datům z veřejného účtu úložiště objektů blob. Fragment kódu ale můžete přizpůsobit tak, aby přistupoval k vlastním datům v privátním účtu azure Storage. Aktualizujte cestu, jak je popsáno zde. Azure Machine Learning bezproblémově zpracovává ověřování v cloudovém úložišti s předáváním Microsoft Entra. Když odešlete úlohu, můžete zvolit:
- Identita uživatele: Předání identity Microsoft Entra pro přístup k datům
- Spravovaná identita: Použití spravované identity cílového výpočetního objektu pro přístup k datům
- Žádné: Nezadávejte identitu pro přístup k datům. Použití žádné při použití úložišť dat založených na přihlašovacích údajích (klíč/token SAS) nebo při přístupu k veřejným datům
Tip
Pokud k ověření používáte klíče nebo tokeny SAS, doporučujeme vytvořit úložiště dat služby Azure Machine Learning, protože modul runtime se automaticky připojí k úložišti bez vystavení klíče nebo tokenu.
from azure.ai.ml import command, Input, MLClient, UserIdentityConfiguration, ManagedIdentityConfiguration
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data.
# Supported `path` formats for input include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# Supported `path` format for output is:
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# We set the input path to a file on a public blob container
# ==============================================================
path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
# ==============================================================
# What type of data does the path point to? Options include:
# data_type = AssetTypes.URI_FILE # a specific file
# data_type = AssetTypes.URI_FOLDER # a folder
# data_type = AssetTypes.MLTABLE # an mltable
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the mode. The popular modes include:
# mode = InputOutputModes.RO_MOUNT # Read-only mount on the compute target
# mode = InputOutputModes.DOWNLOAD # Download the data to the compute target
# ==============================================================
mode = InputOutputModes.RO_MOUNT
# ==============================================================
# You can set the identity you want to use in a job to access the data. Options include:
# identity = UserIdentityConfiguration() # Use the user's identity
# identity = ManagedIdentityConfiguration() # Use the compute target managed identity
# ==============================================================
# This example accesses public data, so we don't need an identity.
# You also set identity to None if you use a credential-based datastore
identity = None
# Set the input for the job:
inputs = {
"input_data": Input(type=data_type, path=path, mode=mode)
}
# This command job uses the head Linux command to print the first 10 lines of the file
job = command(
command="head ${{inputs.input_data}}",
inputs=inputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
identity=identity,
)
# Submit the command
ml_client.jobs.create_or_update(job)
Zápis dat z úlohy Azure Machine Learning do Azure Storage
V tomto příkladu odešlete úlohu Služby Azure Machine Learning, která zapisuje data do výchozího úložiště dat služby Azure Machine Learning. Volitelně můžete nastavit name hodnotu datového assetu pro vytvoření datového assetu ve výstupu.
from azure.ai.ml import command, Input, Output, MLClient
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data.
# Supported `path` formats for input include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# Supported `path` format for output is:
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# As an example, we set the input path to a file on a public blob container
# As an example, we set the output path to a folder in the default datastore
# ==============================================================
input_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
output_path = "azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv"
# ==============================================================
# What type of data are you pointing to?
# AssetTypes.URI_FILE (a specific file)
# AssetTypes.URI_FOLDER (a folder)
# AssetTypes.MLTABLE (a table)
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the input mode. The most commonly-used modes:
# InputOutputModes.RO_MOUNT
# InputOutputModes.DOWNLOAD
# Set the mode to Read Only (RO) to mount the data
# ==============================================================
input_mode = InputOutputModes.RO_MOUNT
# ==============================================================
# Set the output mode. The most commonly-used modes:
# InputOutputModes.RW_MOUNT
# InputOutputModes.UPLOAD
# Set the mode to Read Write (RW) to mount the data
# ==============================================================
output_mode = InputOutputModes.RW_MOUNT
# Set the input and output for the job:
inputs = {
"input_data": Input(type=data_type, path=input_path, mode=input_mode)
}
outputs = {
"output_data": Output(type=data_type,
path=output_path,
mode=output_mode,
# optional: if you want to create a data asset from the output,
# then uncomment `name` (`name` can be set without setting `version`, and in this way, we will set `version` automatically for you)
# name = "<name_of_data_asset>", # use `name` and `version` to create a data asset from the output
# version = "<version>",
)
}
# This command job copies the data to your default Datastore
job = command(
command="cp ${{inputs.input_data}} ${{outputs.output_data}}",
inputs=inputs,
outputs=outputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
)
# Submit the command
ml_client.jobs.create_or_update(job)
Modul runtime dat služby Azure Machine Learning
Když odešlete úlohu, modul runtime dat Azure Machine Learning řídí načítání dat z umístění úložiště do cílového výpočetního objektu. Modul runtime dat Služby Azure Machine Learning je optimalizovaný pro rychlost a efektivitu úloh strojového učení. Mezi klíčové výhody patří:
- Načítání dat zapsaná v jazyce Rust, jazyk známý pro vysokou rychlost a vysokou efektivitu paměti. U souběžných stahování dat se Rust vyhne problémům s globálním zámkem interpreta Pythonu (GIL).
- Lehká hmotnost; Rust nemá žádné závislosti na jiných technologiích – například JVM. V důsledku toho se modul runtime rychle nainstaluje a nevyprázdní další prostředky (procesor, paměť) do cílového výpočetního objektu.
- Načítání dat s více procesy (paralelně)
- Předem načte data jako úlohu na pozadí na procesorech, aby se při hlubokém učení umožnilo lepší využití GPU.
- Bezproblémové zpracování ověřování do cloudového úložiště
- Poskytuje možnosti připojení dat (streamu) nebo stažení všech dat. Další informace najdete v částech Připojit (streamování) a Stáhnout .
- Bezproblémová integrace s fsspec – jednotné pythonické rozhraní pro místní, vzdálené a vložené systémy souborů a bajtové úložiště.
Tip
Doporučujeme využít modul runtime dat služby Azure Machine Learning místo vytvoření vlastní funkce připojení a stahování v kódu trénování (klienta). Zjistili jsme omezení propustnosti úložiště, když klientský kód používá Python ke stahování dat z úložiště kvůli problémům s globálním zámkem interpreta (GIL).
Cesty
Při zadávání vstupu a výstupu dat do úlohy je nutné zadat path parametr, který odkazuje na umístění dat. Tato tabulka ukazuje různá umístění dat, která Azure Machine Learning podporuje, a také ukazuje path příklady parametrů:
| Umístění | Příklady | Vstup | Výstup |
|---|---|---|---|
| Cesta na místním počítači | ./home/username/data/my_data |
Y | N |
| Cesta na veřejném serveru HTTP | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
Y | N |
| Cesta ve službě Azure Storage | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
Y, pouze pro ověřování na základě identity. | N |
| Cesta k úložišti dat služby Azure Machine Learning | azureml://datastores/<data_store_name>/paths/<path> |
Y | Y |
| Cesta k datovému assetu | azureml:<my_data>:<version> |
Y | N, ale můžete použít name a version vytvořit datový asset z výstupu. |
Režimy
Když spustíte úlohu s datovými vstupy a výstupy, můžete si vybrat z těchto možností režimu :
ro_mount: Připojte umístění úložiště jako jen pro čtení na cílové výpočetní objekty místního disku (SSD).rw_mount: Připojte umístění úložiště jako čtení a zápis na cílový výpočetní objekt místního disku (SSD).download: Stáhněte data z umístění úložiště do cílového výpočetního objektu místního disku (SSD).upload: Nahrajte data z cílového výpočetního objektu do umístění úložiště.eval_mount/eval_download: Tyto režimy jsou jedinečné pro MLTable. V některých scénářích může tabulka MLTable přinést soubory, které se mohou nacházet v účtu úložiště, který se liší od účtu úložiště, který je hostitelem souboru MLTable. Nebo tabulka MLTable může podmnožinu nebo prohazování dat umístěných v prostředku úložiště. Toto zobrazení podmnožina/náhodného prohazování se zobrazí jenom v případě, že modul runtime dat Azure Machine Learning skutečně vyhodnocuje soubor MLTable. Tento diagram například ukazuje, jak se tabulka MLTable používáeval_mountse dvěma různými kontejnery úložiště neboeval_downloadmůže pořizovat obrázky ze dvou různých kontejnerů úložiště a soubor poznámek umístěný v jiném účtu úložiště a pak připojit nebo stáhnout do systému souborů vzdáleného cílového výpočetního objektu.
Složka
camera1,camera2složka aannotations.csvsoubor jsou pak přístupné v systému souborů cílového výpočetního objektu ve struktuře složek:/INPUT_DATA ├── account-a │ ├── container1 │ │ └── camera1 │ │ ├── image1.jpg │ │ └── image2.jpg │ └── container2 │ └── camera2 │ ├── image1.jpg │ └── image2.jpg └── account-b └── container1 └── annotations.csvdirect: Můžete chtít číst data přímo z identifikátoru URI prostřednictvím jiných rozhraní API, a ne procházet modulem runtime dat služby Azure Machine Learning. Například můžete chtít přistupovat k datům v kontejneru s3 (s adresou URL stylu nebo stylu cestyhttps) pomocí klienta boto s3. Identifikátor URI vstupu můžete získat jako řetězec s režimemdirect. V úlohách Sparku vidíte použití přímého režimu, protožespark.read_*()metody vědí, jak zpracovat identifikátory URI. Pro úlohy mimo Spark je vaší zodpovědností spravovat přístupové přihlašovací údaje. Musíte například explicitně použít výpočetní MSI nebo jiný přístup zprostředkovatele.

Tato tabulka ukazuje možné režimy pro různé kombinace typu, režimu, vstupu a výstupu:
| Typ | Vstup a výstup | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|---|
uri_folder |
Vstup | ✓ | ✓ | ✓ | ||||
uri_file |
Vstup | ✓ | ✓ | ✓ | ||||
mltable |
Vstup | ✓ | ✓ | ✓ | ✓ | ✓ | ||
uri_folder |
Výstup | ✓ | ✓ | |||||
uri_file |
Výstup | ✓ | ✓ | |||||
mltable |
Výstup | ✓ | ✓ | ✓ |
Stáhnout
V režimu stahování se všechna vstupní data zkopírují na místní disk (SSD) cílového výpočetního objektu. Modul runtime dat služby Azure Machine Learning spustí trénovací skript uživatele, jakmile se zkopírují všechna data. Když se spustí uživatelský skript, načte data z místního disku stejně jako ostatní soubory. Po dokončení úlohy se data odeberou z disku cílového výpočetního objektu.
| Výhody | Nevýhody |
|---|---|
| Při spuštění trénování jsou všechna data k dispozici na místním disku (SSD) cílového výpočetního objektu pro trénovací skript. Nevyžaduje se žádná interakce se službou Azure Storage nebo sítí. | Datová sada se musí zcela vejít na cílový výpočetní disk. |
| Po spuštění uživatelského skriptu neexistují žádné závislosti na spolehlivosti úložiště nebo sítě. | Stáhnou se celá datová sada (pokud trénování potřebuje náhodně vybrat jenom malou část dat, velká část stahování se pak promarní). |
| Modul runtime dat Služby Azure Machine Learning může paralelně paralelizovat stahování (významný rozdíl v mnoha malých souborech) a maximální propustnost sítě a úložiště. | Úloha čeká na stažení všech dat na místní disk cílového výpočetního objektu. V případě odeslané úlohy hlubokého učení jsou GPU nečinné, dokud nebudou data připravená. |
| Vrstva FUSE nepřidá žádnou neuložené režijní náklady (zaokrouhlování: volání uživatelského prostoru v uživatelském skriptu → jádru → uživatelském prostoru fuse démon → jádra → odpověď na uživatelský skript v uživatelském prostoru). | Změny úložiště se po dokončení stahování neprojeví na datech. |
Kdy použít stahování
- Data jsou dostatečně malá, aby se vešla na disk cílového výpočetního objektu bez zásahu do jiného trénování.
- Trénování používá většinu nebo všechny datové sady.
- Trénování čte soubory z datové sady více než jednou.
- Trénování musí přeskakovat na náhodné pozice velkého souboru.
- Před zahájením trénování je v pořádku počkat na stažení všech dat.
Dostupná nastavení stahování
Nastavení stahování můžete vyladit pomocí těchto proměnných prostředí ve své úloze:
| Název proměnné prostředí | Type | Výchozí hodnota | Popis |
|---|---|---|---|
RSLEX_DOWNLOADER_THREADS |
u64 | NUMBER_OF_CPU_CORES * 4 |
Počet souběžných vláken ke stažení |
AZUREML_DATASET_HTTP_RETRY_COUNT |
u64 | 7 | Počet opakovaných pokusů o obnovení z přechodných chyb v jednotlivých úložištích nebo http požadavku |
Ve své úloze můžete výše uvedené výchozí hodnoty změnit nastavením proměnných prostředí , například:
Pro stručnost ukazujeme, jak definovat proměnné prostředí v úloze.
from azure.ai.ml import command
env_var = {
"RSLEX_DOWNLOADER_THREADS": 64,
"AZUREML_DATASET_HTTP_RETRY_COUNT": 10
}
job = command(
environment_variables=env_var
)
Stažení metrik výkonu
Velikost virtuálního počítače cílového výpočetního objektu má vliv na dobu stahování dat. Konkrétně:
- Počet jader. Čím více jader je k dispozici, tím více souběžnosti a tím rychlejší stahování.
- Očekávaná šířka pásma sítě. Každý virtuální počítač v Azure má maximální propustnost z síťové karty (NIC).
Poznámka:
U virtuálních počítačů S GPU A100 může modul runtime dat Služby Azure Machine Learning nasytit síťový adaptér (síťová karta) při stahování dat do cílového výpočetního objektu (~24 Gbit/s): Teoretická maximální možná propustnost.
Tato tabulka ukazuje výkon stahování, který může modul runtime dat služby Azure Machine Learning zpracovat pro 100GB soubor na virtuálním Standard_D15_v2 počítači (20 jader, propustnost sítě 25 Gbit/s):
| Struktura dat | Pouze stahování (sekundy) | Stažení a výpočet MD5 (s) | Dosažená propustnost (Gbit/s) |
|---|---|---|---|
| Soubory 10 x 10 GB | 55.74 | 260.97 | 14.35 Gbit/s |
| Soubory 100 x 1 GB | 58.09 | 259.47 | 13,77 Gbit/s |
| Soubor 1 x 100 GB | 96.13 | 300.61 | 8,32 Gbit/s |
Vidíme, že větší soubor, rozdělený na menší soubory, může zlepšit výkon stahování z důvodu paralelismu. Doporučujeme, abyste se vyhnuli příliš malým souborům (méně než 4 MB), protože doba potřebná k odeslání požadavků na úložiště se zvyšuje vzhledem k času strávenému stažením datové části. Další informace naleznete v tématu Mnoho malých souborů problém.
Připojení (streamování)
V režimu připojení využívá funkce FUSE (systém souborů v uživatelském prostoru) Linux funkce Azure Machine Learning k vytvoření emulovaného systému souborů. Místo stažení všech dat na místní disk (SSD) cílového výpočetního objektu může modul runtime reagovat na akce skriptu uživatele v reálném čase. Například "open file", "read 2-KB chunk from position X", "list directory content".
| Výhody | Nevýhody |
|---|---|
| Data, která překračují kapacitu místního disku cílového výpočetního objektu, je možné použít (ne omezený výpočetním hardwarem). | Přidali jsme režii modulu FUSE pro Linux. |
| Žádné zpoždění na začátku trénování (na rozdíl od režimu stahování). | Závislost na chování kódu uživatele (pokud trénovací kód, který postupně čte malé soubory v jednom připojení vlákna, také vyžaduje data z úložiště, nemusí maximalizovat propustnost sítě nebo úložiště). |
| Další dostupná nastavení pro vyladění scénáře použití | Žádná podpora windows. |
| Z úložiště se čtou jenom data potřebná pro trénování. |
Kdy použít připojení
- Data jsou velká a nevejdou se na cílový výpočetní místní disk.
- Každý jednotlivý výpočetní uzel v clusteru nemusí číst celou datovou sadu (náhodný soubor nebo řádky ve výběru souboru CSV atd.).
- Zpoždění čekání na stažení všech dat před zahájením trénování se může stát problémem (nečinný čas GPU).
Dostupná nastavení připojení
Nastavení připojení můžete v úloze vyladit pomocí těchto proměnných prostředí:
| Název proměnné env | Type | Default value | Popis |
|---|---|---|---|
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL |
u64 | Nenastaví se (nikdy nevyprší platnost mezipaměti) | Čas, v milisekundách, potřeba zachovat getattr výsledky volání v mezipaměti a vyhnout se následným požadavkům těchto informací z úložiště. |
DATASET_RESERVED_FREE_DISK_SPACE |
u64 | 150 MB | Účelem konfigurace systému je zajistit, aby byl výpočetní výkon v pořádku. Bez ohledu na hodnoty ostatních nastavení nepoužívá modul runtime dat služby Azure Machine Learning poslední RESERVED_FREE_DISK_SPACE bajty místa na disku. |
DATASET_MOUNT_CACHE_SIZE |
usize | Bez omezení | Určuje, kolik místa na disku může připojení použít. Kladná hodnota nastaví absolutní hodnotu v bajtech. Záporná hodnota nastaví, kolik místa na disku necháte volné. Tato tabulka poskytuje další možnosti mezipaměti disku. MB Podporuje KBa GB modifikátory pro usnadnění. |
DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD |
f64 | 1.0 | Připojení svazku spustí vyprázdnění mezipaměti při naplnění mezipaměti až do AVAILABLE_CACHE_SIZE * DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD. Měla by být mezi 0 a 1. < Nastavení 1 aktivuje vyřazení mezipaměti na pozadí dříve. AVAILABLE_CACHE_SIZE není proměnná prostředí, kterou můžete upravovat ani zobrazovat přímo. V tomto kontextu odkazuje na "počet bajtů, které systém vypočítá jako dostupný pro ukládání do mezipaměti". Tato hodnota závisí na faktorech, jako je velikost disku, velikost místa na disku vyžadované pro stav systému a konfigurace nastavené v proměnných prostředí (například DATASET_RESERVED_FREE_DISK_SPACE a DATASET_MOUNT_CACHE_SIZE). |
DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET |
f64 | 0,7 | Vyřazení mezipaměti se pokusí uvolnit alespoň (1-DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET) místo v mezipaměti. |
DATASET_MOUNT_READ_BLOCK_SIZE |
usize | 2 MB | Velikost bloku čtení streamování Pokud je soubor dostatečně velký, požádejte alespoň DATASET_MOUNT_READ_BLOCK_SIZE o data z úložiště a mezipaměť i v případě, že operace fuse požadovaného čtení byla méně. |
DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT |
usize | 32 | Počet bloků, které se mají předem načíst (čtení bloku k triggerů před načtením pozadí bloků k+1, ..., k.+DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT) |
DATASET_MOUNT_READ_THREADS |
usize | NUMBER_OF_CORES * 4 |
Počet vláken předběžného načítání na pozadí |
DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED |
bool | false (nepravda) | Povolte ukládání do mezipaměti založené na blokech. |
DATASET_MOUNT_MEMORY_CACHE_SIZE |
usize | 128 MB | Platí jenom pro ukládání do mezipaměti založené na blokech. Velikost mezipaměti založené na blokech RAM může být používána. Hodnota 0 zakáže ukládání do mezipaměti zcela. |
DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED |
bool | true | Platí jenom pro ukládání do mezipaměti založené na blokech. Pokud je nastavená hodnota true, ukládání do mezipaměti používá místní pevný disk k blokům mezipaměti. |
DATASET_MOUNT_BLOCK_FILE_CACHE_MAX_QUEUE_SIZE |
usize | 512 MB | Platí jenom pro ukládání do mezipaměti založené na blokech. Blokové ukládání do mezipaměti zapisuje blok uložený v mezipaměti na místní disk na pozadí. Toto nastavení určuje, kolik paměti může připojení paměti použít k ukládání bloků čekajících na vyprázdnění do místní mezipaměti disku. |
DATASET_MOUNT_BLOCK_FILE_CACHE_WRITE_THREADS |
usize | NUMBER_OF_CORES * 2 |
Platí jenom pro ukládání do mezipaměti založené na blokech. Počet vláken na pozadí, které blokové ukládání do mezipaměti používá k zápisu stažených bloků na místní disk cílového výpočetního objektu. |
DATASET_UNMOUNT_TIMEOUT_SECONDS |
u64 | 30 | Doba v sekundách( unmount než (řádně) dokončí všechny čekající operace (například volání vyprázdnění) před vynucenou ukončením smyčky připojené zprávy. |
Ve své úloze můžete výše uvedené výchozí hodnoty změnit nastavením proměnných prostředí, například:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": True
}
job = command(
environment_variables=env_var
)
Režim otevření na základě bloků
Režim otevření na základě bloků rozdělí jednotlivé soubory na bloky předdefinované velikosti (s výjimkou posledního bloku). Žádost o čtení ze zadané pozice vyžaduje odpovídající blok z úložiště a okamžitě vrátí požadovaná data. Čtení také aktivuje předběžné načtení pozadí dalších bloků N pomocí více vláken (optimalizovaných pro sekvenční čtení). Stažené bloky se ukládají do mezipaměti ve dvou vrstvách (RAM a místní disk).
| Výhody | Nevýhody |
|---|---|
| Rychlé doručování dat do trénovacího skriptu (méně blokující bloky dat, které ještě nebyly požadovány). | Náhodné čtení může ztratit předem načtené bloky. |
| Více práce se přesměruje na vlákna na pozadí (předběžné načítání nebo ukládání do mezipaměti). Trénování pak může pokračovat. | Přidání režie pro navigaci mezi mezipamětí ve srovnání s přímým čtením ze souboru v místní mezipaměti disku (například v režimu mezipaměti celého souboru). |
| Z úložiště se čtou jenom požadovaná data (plus předběžné načtení). | |
| Pro malá data se používá rychlá mezipaměť založená na paměti RAM. |
Kdy použít režim otevření založeného na blokech
Doporučuje se pro většinu scénářů s výjimkou případů, kdy potřebujete rychlé čtení z náhodných umístění souborů. V takových případech použijte režim otevření celé mezipaměti souborů.
Režim otevření celé mezipaměti souborů
Při otevření souboru ve složce připojení (například f = open(path, args)) v celém režimu souboru se volání zablokuje, dokud se celý soubor nestáhnou do složky cílové mezipaměti výpočetních prostředků na disku. Všechna následná volání čtení se přesměrovávají do souboru uloženého v mezipaměti, takže není potřeba žádná interakce s úložištěm. Pokud mezipaměť nemá dostatek volného místa pro přizpůsobení aktuálního souboru, připojení se pokusí vyřadit odstraněním naposledy použitého souboru z mezipaměti. V případech, kdy soubor nejde umístit na disk (s ohledem na nastavení mezipaměti), modul runtime dat se vrátí do režimu streamování.
| Výhody | Nevýhody |
|---|---|
| Po otevření souboru nejsou žádné závislosti na spolehlivosti úložiště a propustnosti. | Otevřené volání se zablokuje, dokud se nestáhnou celý soubor. |
| Rychlé náhodné čtení (čtení bloků dat z náhodných míst souboru) | Celý soubor se načte z úložiště, i když některé části souboru nemusí být potřeba. |
Kdy ji použít
Pokud jsou potřeba náhodné čtení pro relativně velké soubory, které překračují 128 MB.
Využití
Nastavte proměnnou DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED prostředí na false vaši úlohu:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False
}
job = command(
environment_variables=env_var
)
Připojení: Výpis souborů
Při práci s miliony souborů se vyhněte rekurzivnímu výpisu , například ls -R /mnt/dataset/folder/. Rekurzivní výpis aktivuje mnoho volání pro výpis obsahu adresáře nadřazeného adresáře. Pak vyžaduje samostatné rekurzivní volání pro každý adresář uvnitř všech podřízených úrovní. Azure Storage obvykle umožňuje vrácení pouze 5 000 prvků na jeden požadavek na seznam. V důsledku toho rekurzivní výpis 1M složek obsahujících 10 souborů vyžaduje 1,000,000 / 5000 + 1,000,000 = 1,000,200 požadavky na úložiště. Ve srovnání s 1 000 složkami s 10 000 soubory by pro rekurzivní výpis potřebovalo 1001 požadavků.
Připojení služby Azure Machine Learning zpracovává výpis opožděným způsobem. Pokud tedy chcete vypsat mnoho malých souborů, je lepší použít volání iterativní klientské knihovny (například os.scandir() v Pythonu) místo volání klientské knihovny, které vrací úplný seznam (například os.listdir() v Pythonu). Iterativní volání klientské knihovny vrátí generátor, což znamená, že nemusí čekat na načtení celého seznamu. Pak může pokračovat rychleji.
Tato tabulka porovnává čas potřebný k os.scandir() os.listdir() zobrazení seznamu složek, které obsahují soubory ~4M v ploché struktuře:
| Metrika | os.scandir() |
os.listdir() |
|---|---|---|
| Čas na získání první položky (sekundy) | 0.67 | 553.79 |
| Čas získat prvních 50 tisíc položek (sekundy) | 9.56 | 562.73 |
| Čas získat všechny položky (s) | 558.35 | 582.14 |
Optimální nastavení montáže pro běžné scénáře
V některých běžných scénářích zobrazujeme optimální nastavení připojení, která je potřeba nastavit v úloze Služby Azure Machine Learning.
Čtení velkého souboru postupně jednou (zpracování řádků v souboru CSV)
Do části úlohy Azure Machine Learning zahrňte tato nastavení environment_variables připojení:
Poznámka:
Pokud chcete používat bezserverové výpočetní prostředky, odstraňte compute="cpu-cluster", ho v tomto kódu.
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
# Increase the number of blocks used for prefetch. This leads to use of more RAM (2 MB * #value set).
# Can adjust up and down for fine-tuning, depending on the actual data processing pattern.
# An optimal setting based on our test ~= the number of prefetching threads (#CPU_CORES * 4 by default)
"DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT": 80,
}
job = command(
environment_variables=env_var
)
Čtení velkého souboru jednou z více vláken (zpracování dělených souborů CSV ve více vláknech)
Do části úlohy Azure Machine Learning zahrňte tato nastavení environment_variables připojení:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
Čtení milionů malých souborů (obrázků) z více vláken jednou (jedno epochové trénování obrázků)
Do části úlohy Azure Machine Learning zahrňte tato nastavení environment_variables připojení:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
Čtení milionů malých souborů (obrázků) z více vláken vícekrát (více epoch trénování obrázků)
Do části úlohy Azure Machine Learning zahrňte tato nastavení environment_variables připojení:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
}
job = command(
environment_variables=env_var
)
Čtení velkého souboru s náhodným hledáním (například obsluha souborové databáze z připojené složky)
Do části úlohy Azure Machine Learning zahrňte tato nastavení environment_variables připojení:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False, # Disable block-based caching
}
job = command(
environment_variables=env_var
)
Diagnostika a řešení kritických bodů načítání dat
Při spuštění úlohy Azure Machine Learning s daty mode určuje vstup, jak se bajty čtou z úložiště a ukládají se do mezipaměti na cílovém místním disku SSD výpočetního objektu. V režimu stahování se před spuštěním uživatelského kódu ukládají všechna data do mezipaměti na disku. Faktory, jako jsou například
- počet paralelních vláken
- počet souborů
- velikost souboru
mají vliv na maximální rychlost stahování. Pro připojení musí uživatelský kód začít otevírat soubory před tím, než se data začnou ukládat do mezipaměti. Různá nastavení připojení vedou k různým chováním při čtení a ukládání do mezipaměti. Různé faktory mají vliv na rychlost načítání dat z úložiště:
- Umístění dat pro výpočty: Úložiště a cílové umístění výpočetních prostředků by měly být stejné. Pokud se úložiště a cíl výpočetních prostředků nachází v různých oblastech, výkon se sníží, protože data se musí přenášet mezi oblastmi. Další informace o tom, jak zajistit, aby vaše data byla společně s výpočetními prostředky, najdete v tématu Colocate data s výpočetními prostředky.
- Cílová velikost výpočetních prostředků: Malé výpočetní prostředky mají nižší počet jader (menší paralelismus) a menší očekávanou šířku pásma sítě ve srovnání s většími velikostmi výpočetních prostředků – oba faktory ovlivňují výkon načítání dat.
- Pokud například používáte malou velikost virtuálního počítače, například
Standard_D2_v2(2 jádra, 1500 Mb/s nic) a pokusíte se načíst 50 000 MB (50 GB) dat, nejlepší dosažitelná doba načítání dat by byla ~270 sekund (za předpokladu, že síťové rozhraní nasytíte při propustnosti 187,5 MB/s). Naproti tomuStandard_D5_v2(16 jader, 12 000 Mb/s) by se stejná data načetla do přibližně 33 sekund (za předpokladu, že síťové rozhraní saturujete při propustnosti 1500 MB/s).
- Pokud například používáte malou velikost virtuálního počítače, například
- Úroveň úložiště: Pro většinu scénářů – včetně velkých jazykových modelů (LLM) – storage úrovně Standard poskytuje nejlepší profil nákladů a výkonu. Pokud ale máte mnoho malých souborů, nabízí Premium Storage lepší profil nákladů a výkonu. Další informace najdete v možnostech služby Azure Storage.
- Zatížení úložiště: Pokud je účet úložiště pod vysokým zatížením – například mnoho uzlů GPU v clusteru požadujících data – pak riskujete dosažení výstupní kapacity úložiště. Další informace najdete v tématu Načtení úložiště. Pokud máte mnoho malých souborů, které potřebují přístup paralelně, možná dosáhnete limitů požadavků úložiště. Přečtěte si aktuální informace o limitech pro požadavky na výchozí kapacitu i úložiště v cílech škálování pro účty úložiště úrovně Standard.
- Vzor přístupu k datům v uživatelském kódu: Při použití režimu připojení se data načítají na základě otevřených a přečtených akcí v kódu. Například při čtení náhodných oddílů velkého souboru může výchozí nastavení předběžného načtení dat připojení vést ke stahování bloků, které se nebudou číst. Možná budete muset vyladit některá nastavení, abyste dosáhli maximální propustnosti. Další informace najdete v tématu Optimální nastavení montáže pro běžné scénáře.
Použití protokolů k diagnostice problémů
Přístup k protokolům modulu runtime dat z vaší úlohy:
- Na stránce úlohy vyberte Výstupy a protokoly .
- Vyberte složku system_logs následovanou data_capability složkou.
- Měly by se zobrazit dva soubory protokolu:
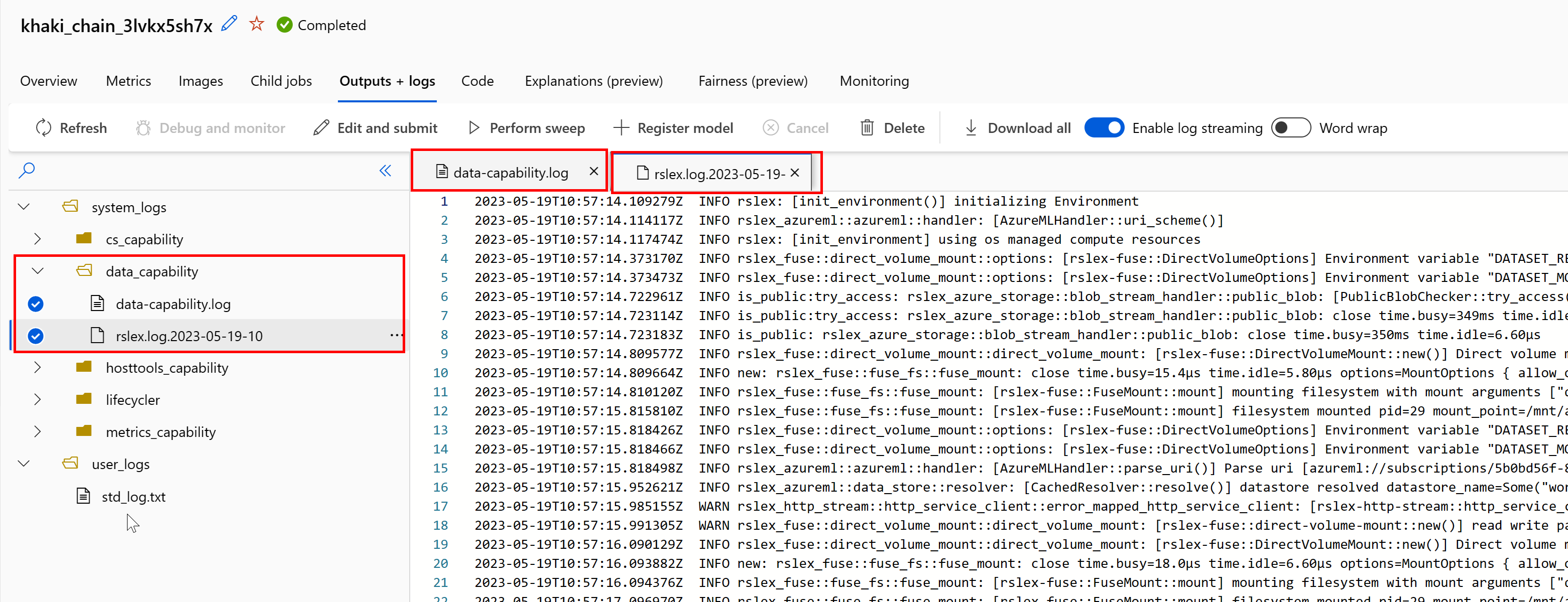

Soubor protokolu data-capability.log zobrazuje základní informace o době strávené při načítání klíčových dat. Například při stahování dat protokoluje modul runtime časy zahájení a dokončení aktivity stahování:
INFO 2023-05-18 17:14:47,790 sdk_logger.py:44 [28] - ActivityStarted, download
INFO 2023-05-18 17:14:50,295 sdk_logger.py:44 [28] - ActivityCompleted: Activity=download, HowEnded=Success, Duration=2504.39 [ms]
Pokud je propustnost stahování zlomkem očekávané šířky pásma sítě pro velikost virtuálního počítače, můžete zkontrolovat soubor protokolu rslex.log.<ČASOVÉ RAZÍTKO>. Tento soubor obsahuje veškeré podrobné protokolování z modulu runtime založeného na Rustu; Například paralelizace:
2023-05-18T14:08:25.388670Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce:get_iter: rslex::prefetching: close time.busy=23.2µs time.idle=1.90µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0 index=0
2023-05-18T14:08:25.388731Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce: rslex::dataset_crossbeam: close time.busy=90.9µs time.idle=9.10µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0
2023-05-18T14:08:25.388762Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:combine: rslex::dataset_crossbeam: close time.busy=1.22ms time.idle=9.50µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4
Soubor rslex.log poskytuje podrobnosti o veškerém kopírování souboru bez ohledu na to, jestli jste zvolili režimy připojení nebo stahování. Popisuje také použitá nastavení (proměnné prostředí). Pokud chcete spustit ladění, zkontrolujte, jestli jste nastavili optimální nastavení připojení pro běžné scénáře.
Monitorování úložiště Azure
Na webu Azure Portal můžete vybrat svůj účet úložiště a pak metriky úložiště zobrazit:

Pak vykreslíte SuccessE2ELatency s SuccessServerLatency. Pokud metriky zobrazují vysokou hodnotu SuccessE2ELatency a nízkou hodnotu SuccessServerLatency, máte omezená dostupná vlákna nebo máte nedostatek prostředků, jako je procesor, paměť nebo šířka pásma sítě, měli byste:
- Pomocí zobrazení monitorování v studio Azure Machine Learning zkontrolujte využití procesoru a paměti vaší úlohy. Pokud nemáte procesor a paměť, zvažte zvýšení velikosti cílového výpočetního virtuálního počítače.
- Zvažte zvýšení
RSLEX_DOWNLOADER_THREADS, pokud stahujete a nevyužíváte procesor a paměť. Pokud používáte připojení, měli byste zvýšitDATASET_MOUNT_READ_BUFFER_BLOCK_COUNT, aby bylo možné provést více předběžného načítání a zvýšitDATASET_MOUNT_READ_THREADSpočet vláken čtení.
Pokud metriky zobrazují nízkou hodnotu SuccessE2ELatency a low SuccessServerLatency, ale u klienta dochází k vysoké latenci, máte zpoždění v požadavku na úložiště, které dosáhne služby. Měli byste zkontrolovat:
- Určuje, jestli je počet vláken používaných pro připojení/stahování (
DATASET_MOUNT_READ_THREADS/RSLEX_DOWNLOADER_THREADS) nastavený příliš nízký vzhledem k počtu jader dostupných v cílovém výpočetním objektu. Pokud je nastavení příliš nízké, zvyšte počet vláken. - Určuje, jestli je počet opakovaných pokusů o stažení (
AZUREML_DATASET_HTTP_RETRY_COUNT) příliš vysoký. Pokud ano, snižte počet opakování.
Monitorování využití disků během úlohy
Z studio Azure Machine Learning můžete během provádění úlohy také monitorovat vstupně-výstupní operace a využití cílového výpočetního disku. Přejděte do své úlohy a vyberte kartu Monitorování . Tato karta poskytuje přehledy o prostředcích vaší úlohy za 30 dnů. Příklad:

Poznámka:
Monitorování úloh podporuje pouze výpočetní prostředky, které spravuje Azure Machine Learning. Úlohy s modulem runtime kratším než 5 minut nebudou mít dostatek dat k naplnění tohoto zobrazení.
Azure Machine Learning Data Runtime nepoužívá poslední RESERVED_FREE_DISK_SPACE bajty místa na disku, aby byl výpočetní výkon v pořádku (výchozí hodnota je 150MB). Pokud je disk plný, kód zapisuje soubory na disk bez deklarování souborů jako výstupu. Zkontrolujte proto kód a ujistěte se, že se data nepíšou chybně na dočasný disk. Pokud musíte zapisovat soubory na dočasný disk a tento prostředek se zaplní, zvažte následující:
- Zvětšení velikosti virtuálního počítače na virtuální počítač s větším dočasným diskem
- Nastavení hodnoty TTL u dat uložených v mezipaměti (
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL) pro vymazání dat z disku
Společné přidělení dat pomocí výpočetních prostředků
Upozornění
Pokud jsou úložiště a výpočetní prostředky v různých oblastech, výkon se sníží, protože data se musí přenášet mezi oblastmi. Tím se zvyšují náklady. Ujistěte se, že váš účet úložiště a výpočetní prostředky jsou ve stejné oblasti.
Pokud jsou vaše data a pracovní prostor Služby Azure Machine Learning uložené v různých oblastech, doporučujeme data zkopírovat do účtu úložiště ve stejné oblasti pomocí nástroje azcopy . AzCopy používá rozhraní API typu server-server, aby se data zkopírovala přímo mezi servery úložiště. Tyto operace kopírování nepoužívají šířku pásma sítě vašeho počítače. Propustnost těchto operací můžete zvýšit pomocí AZCOPY_CONCURRENCY_VALUE proměnné prostředí. Další informace najdete v tématu Zvýšení souběžnosti.
Načtení úložiště
Při vysokém zatížení může dojít k omezení jednoho účtu úložiště, když:
- Vaše úloha používá mnoho uzlů GPU.
- Váš účet úložiště má mnoho souběžných uživatelů a aplikací, které při spuštění úlohy přistupují k datům.
Tato část ukazuje výpočty, které určují, jestli se omezování může stát problémem pro vaši úlohu a jak přistupovat ke snížení omezování.
Výpočet limitů šířky pásma
Účet Služby Azure Storage má výchozí limit výchozího výchozího přenosu dat 120 Gbit/s. Virtuální počítače Azure mají různé šířky pásma sítě, které mají vliv na teoreticky počet výpočetních uzlů potřebných k dosažení maximální výchozí výstupní kapacity úložiště:
| Velikost | Karta GPU | Virtuální procesory | Paměť: GiB | Dočasné úložiště (SSD): GiB | Počet karet GPU | Paměť GPU: GiB | Očekávaná šířka pásma sítě (Gbit/s) | Výchozí výchozí maximum účtu úložiště (Gbit/s)* | Počet uzlů, které se mají dostat do výchozí výstupní kapacity |
|---|---|---|---|---|---|---|---|---|---|
| Standard_ND96asr_v4 | A100 | 96 | 900 | 6000 | 8 | 40 | 24 | 120 | 5 |
| Standard_ND96amsr_A100_v4 | A100 | 96 | 1900 | 6400 | 8 | 80 | 24 | 120 | 5 |
| Standard_NC6s_v3 | V100 | 6 | 112 | 736 | 0 | 16 | 24 | 120 | 5 |
| Standard_NC12s_v3 | V100 | 12 | 224 | 1474 | 2 | 32 | 24 | 120 | 5 |
| Standard_NC24s_v3 | V100 | 24 | 448 | 2948 | 4 | 64 | 24 | 120 | 5 |
| Standard_NC24rs_v3 | V100 | 24 | 448 | 2948 | 4 | 64 | 24 | 120 | 5 |
| Standard_NC4as_T4_v3 | T4 | 4 | 28 | 180 | 0 | 16 | 8 | 120 | 15 |
| Standard_NC8as_T4_v3 | T4 | 8 | 56 | 360 | 0 | 16 | 8 | 120 | 15 |
| Standard_NC16as_T4_v3 | T4 | 16 | 110 | 360 | 0 | 16 | 8 | 120 | 15 |
| Standard_NC64as_T4_v3 | T4 | 64 | 440 | 2880 | 4 | 64 | 32 | 120 | 3 |
Skladové položky A100/V100 mají maximální šířku pásma sítě na uzel 24 Gbit/s. Pokud každý uzel, který čte data z jednoho účtu, může číst téměř teoreticky maximálně 24 gb/s, dojde k výstupní kapacitě s pěti uzly. Použití šesti nebo více výpočetních uzlů by začalo snižovat propustnost dat napříč všemi uzly.
Důležité
Pokud vaše úloha potřebuje více než 6 uzlů A100/V100 nebo se domníváte, že překročíte výchozí výstupní kapacitu úložiště (120Gbit/s), obraťte se na podporu (prostřednictvím webu Azure Portal) a požádejte o navýšení limitu výchozího přenosu dat úložiště.
Škálování napříč několika účty úložiště
Můžete překročit maximální výstupní kapacitu úložiště a/nebo můžete narazit na limity přenosové rychlosti požadavků. Pokud k těmto problémům dojde, doporučujeme nejprve kontaktovat podporu, abyste tyto limity pro účet úložiště zvýšili.
Pokud nemůžete zvýšit maximální kapacitu výchozího přenosu dat nebo limit rychlosti požadavků, měli byste zvážit replikaci dat napříč několika účty úložiště. Zkopírujte data do více účtů pomocí služby Azure Data Factory, Průzkumník služby Azure Storage nebo azcopya připojte všechny účty ve vaší trénovací úloze. Stáhnou se jenom data přístupná k připojení. Trénovací kód proto může číst RANK z proměnné prostředí, abyste vybrali, ze kterých z více vstupů se připojí, ze kterých se má číst. Definice úlohy se předává v seznamu účtů úložiště:
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
code: src
command: >-
python train.py
--epochs ${{inputs.epochs}}
--learning-rate ${{inputs.learning_rate}}
--data ${{inputs.cifar_storage1}}, ${{inputs.cifar_storage2}}
inputs:
epochs: 1
learning_rate: 0.2
cifar_storage1:
type: uri_folder
path: azureml://datastores/storage1/paths/cifar
cifar_storage2:
type: uri_folder
path: azureml://datastores/storage2/paths/cifar
environment: azureml:AzureML-pytorch-1.9-ubuntu18.04-py37-cuda11-gpu@latest
compute: azureml:gpu-cluster
distribution:
type: pytorch
process_count_per_instance: 1
resources:
instance_count: 2
display_name: pytorch-cifar-distributed-example
experiment_name: pytorch-cifar-distributed-example
description: Train a basic convolutional neural network (CNN) with PyTorch on the CIFAR-10 dataset, distributed via PyTorch.
Trénovací kód Pythonu pak může použít RANK k získání účtu úložiště specifického pro daný uzel:
import argparse
import os
parser = argparse.ArgumentParser()
parser.add_argument('--data', nargs='+')
args = parser.parse_args()
world_size = int(os.environ["WORLD_SIZE"])
rank = int(os.environ["RANK"])
local_rank = int(os.environ["LOCAL_RANK"])
data_path_for_this_rank = args.data[rank]
Problém s mnoha malými soubory
Čtení souborů z úložiště zahrnuje provádění požadavků na každý soubor. Počet požadavků na soubor se liší v závislosti na velikostech souborů a nastavení softwaru, který zpracovává čtení souboru.
Soubory se obvykle čtou v blocích o velikosti 1–4 MB. Soubory menší než blok se čtou jedním požadavkem (GET file.jpg 0–4 MB) a soubory větší než blok mají jeden požadavek na jeden blok (GET file.jpg 0–4 MB, GET file.jpg 4–8 MB). Tato tabulka ukazuje, že soubory menší než blok o velikosti 4 MB mají za následek více požadavků na úložiště v porovnání s většími soubory:
| # Soubory | Velikost souboru | Celková velikost dat | Velikost bloku | # Požadavky na úložiště |
|---|---|---|---|---|
| 2,000,000 | 500 kB | 1 TB | 4 MB | 2,000,000 |
| 1000 | 1 GB | 1 TB | 4 MB | 256,000 |
U malých souborů interval latence většinou zahrnuje zpracování požadavků na úložiště místo přenosů dat. Proto nabízíme tato doporučení ke zvýšení velikosti souboru:
- U nestrukturovaných dat (obrázků, textu, videa atd.), archivace (zip/tar) malých souborů, aby se ukládaly jako větší soubor, který je možné číst v několika blocích dat. Tyto větší archivované soubory je možné otevřít ve výpočetním prostředku a PyTorch Archive DataPipes může extrahovat menší soubory.
- U strukturovaných dat (CSV, parquet atd.) zkontrolujte proces ETL a ujistěte se, že se soubory shodují, aby se zvětšila velikost. Spark má
repartition()acoalesce()metody, které vám pomůžou zvýšit velikost souborů.
Pokud nemůžete zvětšit velikost souborů, prozkoumejte možnosti služby Azure Storage.
Možnosti služby Azure Storage
Azure Storage nabízí dvě úrovně – Standard a Premium:
| Úložiště | Scénář |
|---|---|
| Azure Blob – Standard (HDD) | Vaše data jsou strukturovaná ve větších objektech blob – obrázky, video atd. |
| Azure Blob – Premium (SSD) | Vysoké rychlosti transakcí, menší objekty nebo konzistentně nízké požadavky na latenci úložiště |
Tip
U "mnoha" malých souborů (velikost KB) doporučujeme použít premium (SSD), protože náklady na úložiště jsou menší než náklady na provoz výpočetních prostředků GPU.
Čtení datových prostředků V1
Tato část vysvětluje, jak číst entity V1 FileDataset a TabularDataset dat v úloze V2.
Čtení FileDataset
V objektu Input type zadejte jako AssetTypes.MLTABLE a mode jako InputOutputModes.EVAL_MOUNT:
Poznámka:
Pokud chcete používat bezserverové výpočetní prostředky, odstraňte compute="cpu-cluster", ho v tomto kódu.
Další informace o objektu MLClient, možnostech inicializace objektů MLClient a o tom, jak se připojit k pracovnímu prostoru, najdete v tématu Připojení k pracovnímu prostoru.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<filedataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
job = command(
code="./src", # Local path where the code is stored
command="ls ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the job status
returned_job.services["Studio"].endpoint
Čtení TabularDataset
V objektu Input type zadejte jako AssetTypes.MLTABLEa mode jako InputOutputModes.DIRECT:
Poznámka:
Pokud chcete používat bezserverové výpočetní prostředky, odstraňte compute="cpu-cluster", ho v tomto kódu.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<tabulardataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.DIRECT
)
}
job = command(
code="./src", # Local path where the code is stored
command="python train.py --inputs ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the status of the job
returned_job.services["Studio"].endpoint