Ladění hyperparametrů modelu (v2)
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)Azure-ai-ml v2 sady Python SDK (aktuální)
Rozšíření Azure CLI ml v2 (aktuální)Azure-ai-ml v2 sady Python SDK (aktuální)
Automatizujte efektivní ladění hyperparametrů pomocí sady Sdk služby Azure Machine Learning v2 a rozhraní příkazového řádku v2 pomocí typu SweepJob.
- Definování prostoru pro vyhledávání parametrů pro zkušební verzi
- Určení algoritmu vzorkování pro úlohu úklidu
- Zadejte cíl, který chcete optimalizovat.
- Určení zásad předčasného ukončení pro úlohy s nízkým výkonem
- Definování limitů pro úlohu úklidu
- Spuštění experimentu s definovanou konfigurací
- Vizualizace trénovacích úloh
- Vyberte nejlepší konfiguraci pro váš model.
Co je ladění hyperparametrů?
Hyperparametry jsou nastavitelné parametry, které umožňují řídit proces trénování modelu. Například u neurálních sítí rozhodujete o počtu skrytých vrstev a počtu uzlů v každé vrstvě. Výkon modelu do značné míry závisí na hyperparametrech.
Optimalizace hyperparametrů, označovaná také jako optimalizace hyperparametrů, je proces hledání konfigurace hyperparametrů, který vede k nejlepšímu výkonu. Tento proces je obvykle výpočetně náročný a ruční.
Azure Machine Learning umožňuje automatizovat ladění hyperparametrů a paralelně spouštět experimenty, aby se hyperparametry efektivně optimalizovaly.
Definování prostoru pro vyhledávání
Vylaďte hyperparametry prozkoumáním rozsahu hodnot definovaných pro každý hyperparametr.
Hyperparametry můžou být diskrétní nebo spojité a mají rozdělení hodnot popsaných výrazem parametru.
Diskrétní hyperparametry
Diskrétní hyperparametry se zadává jako Choice mezi diskrétními hodnotami. Choice může být:
- jednu nebo více hodnot oddělených čárkami
- objekt
range listlibovolný objekt
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32, 64, 128]),
number_of_hidden_layers=Choice(values=range(1,5)),
)
V tomto případě batch_size jedna z hodnot [16, 32, 64, 128] a number_of_hidden_layers přebírá jednu z hodnot [1, 2, 3, 4].
Následující pokročilé diskrétní hyperparametry lze také zadat pomocí distribuce:
QUniform(min_value, max_value, q)- Vrátí hodnotu jako round(Uniform(min_value; max_value) / q) * q.QLogUniform(min_value, max_value, q)- Vrátí hodnotu jako round(exp(Uniform(min_value; max_value)) / q) * qQNormal(mu, sigma, q)- Vrátí hodnotu jako round(Normal(mu; sigma) / q) * qQLogNormal(mu, sigma, q)- Vrátí hodnotu jako round(exp(Normal(mu, sigma)) / q) * q
Nepřetržité hyperparametry
Hyperparametry Continuous se zadají jako rozdělení v souvislém rozsahu hodnot:
Uniform(min_value, max_value)– Vrátí hodnotu rovnoměrně rozdělenou mezi min_value a max_valueLogUniform(min_value, max_value)- Vrátí hodnotu nakreslenou podle exp(Uniform(min_value, max_value)) tak, aby byl logaritmus návratové hodnoty rovnoměrně rozdělený.Normal(mu, sigma)- Vrátí reálnou hodnotu, která je normálně rozdělená se střední hodnotou mu a směrodatnou odchylkou sigma.LogNormal(mu, sigma)- Vrátí hodnotu nakreslenou podle exp(Normal(mu, sigma)) tak, aby byl logaritmus návratové hodnoty normálně rozdělený.
Příklad definice prostoru parametru:
from azure.ai.ml.sweep import Normal, Uniform
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
)
Tento kód definuje vyhledávací prostor se dvěma parametry – learning_rate a keep_probability. learning_rate má normální rozdělení se střední hodnotou 10 a směrodatnou odchylkou 3. keep_probability má jednotné rozdělení s minimální hodnotou 0,05 a maximální hodnotou 0,1.
Pro rozhraní příkazového řádku můžete použít schéma YAML úlohy uklidit k definování prostoru hledání v YAML:
search_space:
conv_size:
type: choice
values: [2, 5, 7]
dropout_rate:
type: uniform
min_value: 0.1
max_value: 0.2
Vzorkování prostoru hyperparametrů
Zadejte metodu vzorkování parametrů, která se má použít v prostoru hyperparametrů. Azure Machine Learning podporuje následující metody:
- Náhodné vzorkování
- Vzorkování mřížky
- Bayesovské vzorkování
Náhodné vzorkování
Náhodné vzorkování podporuje diskrétní a souvislé hyperparametry. Podporuje předčasné ukončení úloh s nízkým výkonem. Někteří uživatelé při počátečním hledání s náhodným vzorkováním zpřesní prostor hledání, aby se zlepšily výsledky.
Při náhodném vzorkování jsou hodnoty hyperparametrů náhodně vybrány z definovaného prostoru hledání. Po vytvoření úlohy příkazu můžete pomocí parametru uklidit definovat algoritmus vzorkování.
from azure.ai.ml.sweep import Normal, Uniform, RandomParameterSampling
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "random",
...
)
Sobol
Sobol je typ náhodného vzorkování podporovaný typy úloh úklidu. Sobol můžete použít k reprodukování výsledků pomocí seed a rovnoměrnější pokrytí distribuce prostoru vyhledávání.
Chcete-li použít sobol, použijte Třídu RandomParameterSampling k přidání seed a pravidla, jak je znázorněno v následujícím příkladu.
from azure.ai.ml.sweep import RandomParameterSampling
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = RandomParameterSampling(seed=123, rule="sobol"),
...
)
Vzorkování mřížky
Vzorkování mřížky podporuje diskrétní hyperparametry. Vzorkování mřížky použijte, pokud můžete vytvořit rozpočet, abyste mohli prohledávat prostor vyhledávání. Podporuje předčasné ukončení úloh s nízkým výkonem.
Vzorkování mřížky umožňuje jednoduché vyhledávání všech možných hodnot v mřížce. Vzorkování mřížky je možné použít pouze s choice hyperparametry. Například následující mezera obsahuje šest ukázek:
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32]),
number_of_hidden_layers=Choice(values=[1,2,3]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "grid",
...
)
Bayesovské vzorkování
Bayesovské vzorkování je založené na bayesovském optimalizačním algoritmu. Vybírá vzorky na základě toho, jak to dělaly předchozí ukázky, aby nové vzorky vylepšily primární metriku.
Bayesovské vzorkování se doporučuje, pokud máte dostatečný rozpočet na prozkoumání prostoru hyperparametrů. Pro dosažení nejlepších výsledků doporučujeme, aby byl maximální počet úloh větší nebo roven 20násobku počtu vyladěných hyperparametrů.
Počet souběžných úloh má vliv na efektivitu procesu ladění. Menší počet souběžných úloh může vést k lepšímu sblížení vzorkování, protože menší stupeň paralelismu zvyšuje počet úloh, které využívají dříve dokončené úlohy.
Bayesovské vzorkování podporuje choicepouze distribuce , uniforma quniform v prostoru hledání.
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
...
)
Určení cíle úklidu
Definujte cíl úlohy úklidu zadáním primární metriky a cíle, který má optimalizace hyperparametrů optimalizovat. Každá trénovací úloha se vyhodnocuje pro primární metriku. Zásady předčasného ukončení používají primární metriku k identifikaci úloh s nízkým výkonem.
primary_metric: Název primární metriky musí přesně odpovídat názvu metriky protokolované trénovacím skriptem.goal: Může to být buďMaximize, neboMinimizea určuje, jestli se primární metrika při vyhodnocování úloh maximalizuje nebo minimalizuje.
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
primary_metric="accuracy",
goal="Maximize",
)
Tato ukázka maximalizuje "přesnost".
Metriky protokolů pro ladění hyperparametrů
Trénovací skript pro váš model musí protokolovat primární metriku během trénování modelu pomocí stejného odpovídajícího názvu metriky, aby k ní úloha SweepJob přistupovala při ladění hyperparametrů.
Zapište do trénovacího skriptu primární metriku pomocí následujícího ukázkového fragmentu kódu:
import mlflow
mlflow.log_metric("accuracy", float(val_accuracy))
Trénovací skript vypočítá val_accuracy hodnotu a zaznamená ji jako primární metriku "přesnost". Pokaždé, když se metrika protokoluje, služba ladění hyperparametrů ji obdrží. Je na vás, abyste určili četnost hlášení.
Další informace o hodnotách protokolování pro trénovací úlohy najdete v tématu Povolení protokolování v trénovacích úlohách služby Azure Machine Learning.
Určení zásad předčasného ukončení
Automaticky ukončit úlohy s nízkým výkonem pomocí zásad předčasného ukončení. Předčasné ukončení zlepšuje efektivitu výpočtů.
Můžete nakonfigurovat následující parametry, které řídí, kdy se zásada použije:
evaluation_interval: frekvence uplatňování zásad. Pokaždé, když trénovací skript zaznamená, počítá se primární metrika jako jeden interval. Hodnotaevaluation_interval1 použije zásadu pokaždé, když trénovací skript hlásí primární metriku. Anevaluation_intervalof 2 použije zásadu pokaždé jindy. Pokud není zadaný,evaluation_intervalnastaví se ve výchozím nastavení na hodnotu 0.delay_evaluation: zpoždí první vyhodnocení zásad o zadaný počet intervalů. Jedná se o volitelný parametr, který zabraňuje předčasnému ukončení trénovacích úloh tím, že umožňuje spouštění všech konfigurací po minimální počet intervalů. Pokud je tato hodnota zadána, zásada použije každý násobek evaluation_interval, který je větší nebo roven delay_evaluation. Pokud není zadaný,delay_evaluationje ve výchozím nastavení nastaven na hodnotu 0.
Azure Machine Learning podporuje následující zásady předčasného ukončení:
Zásady banditů
Zásady banditů jsou založené na faktoru slack/výši časové rezervy a intervalu vyhodnocení. Zásady Bandit ukončí úlohu, pokud primární metrika není v rámci zadaného faktoru slack nebo časové rezervy nejúspěšnější úlohy.
Zadejte následující parametry konfigurace:
slack_factorneboslack_amount: časová rezerva povolená s ohledem na nejvýkonnější tréninkovou práci.slack_factorurčuje povolenou časovou rezervu jako poměr.slack_amounturčuje povolenou časovou rezervu jako absolutní částku místo poměru.Představte si například zásadu Bandit použitou v intervalu 10. Předpokládejme, že nejvýkonnější úloha v intervalu 10 hlášená primární metrikou je 0,8 s cílem maximalizovat primární metriku. Pokud zásada určuje
slack_factorhodnotu 0,2, budou ukončeny všechny trénovací úlohy, jejichž nejlepší metrika v intervalu 10 je menší než 0,66 (0,8/(1+slack_factor)).evaluation_interval: (volitelné) frekvence použití zásaddelay_evaluation: (volitelné) zpoždí první vyhodnocení zásad po zadaný počet intervalů.
from azure.ai.ml.sweep import BanditPolicy
sweep_job.early_termination = BanditPolicy(slack_factor = 0.1, delay_evaluation = 5, evaluation_interval = 1)
V tomto příkladu se zásady předčasného ukončení použijí v každém intervalu, kdy se metriky hlásí, počínaje intervalem vyhodnocení 5. Všechny úlohy, jejichž nejlepší metrika je menší než (1/(1+0,1) nebo 91 % nejvýkonnějších úloh, budou ukončeny.
Zásady mediánu zastavování
Medián zastavení je zásada předčasného ukončení založená na průběžných průměrech primárních metrik hlášených úlohami. Tato zásada vypočítá provozní průměry ve všech trénovacích úlohách a zastaví úlohy, jejichž primární hodnota metriky je horší než medián průměrů.
Tato zásada přijímá následující parametry konfigurace:
evaluation_interval: frekvence použití zásad (volitelný parametr).delay_evaluation: zpoždí první vyhodnocení zásad o zadaný počet intervalů (volitelný parametr).
from azure.ai.ml.sweep import MedianStoppingPolicy
sweep_job.early_termination = MedianStoppingPolicy(delay_evaluation = 5, evaluation_interval = 1)
V tomto příkladu se zásady předčasného ukončení použijí v každém intervalu počínaje intervalem vyhodnocení 5. Pokud je její nejlepší primární metrika horší než medián průběžných průměrů v intervalech 1:5 pro všechny trénovací úlohy, zastaví se úloha v intervalu 5.
Zásady výběru zkrácení
Výběr zkrácení zruší procento nejméně výkonných úloh v každém intervalu vyhodnocení. úlohy se porovnávají pomocí primární metriky.
Tato zásada přijímá následující parametry konfigurace:
truncation_percentage: procento nejméně výkonných úloh, které se mají ukončit v každém intervalu vyhodnocení. Celočíselná hodnota mezi 1 a 99.evaluation_interval: (volitelné) frekvence použití zásaddelay_evaluation: (volitelné) zpoždí první vyhodnocení zásad po zadaný počet intervalů.exclude_finished_jobs: Určuje, jestli se mají při použití zásad vyloučit dokončené úlohy.
from azure.ai.ml.sweep import TruncationSelectionPolicy
sweep_job.early_termination = TruncationSelectionPolicy(evaluation_interval=1, truncation_percentage=20, delay_evaluation=5, exclude_finished_jobs=true)
V tomto příkladu se zásady předčasného ukončení použijí v každém intervalu počínaje intervalem vyhodnocení 5. Úloha se ukončí v intervalu 5, pokud její výkon v intervalu 5 odpovídá nejnižším 20 % výkonu všech úloh v intervalu 5 a při použití zásad se vyloučí dokončené úlohy.
Žádné zásady ukončení (výchozí)
Pokud není zadána žádná zásada, služba ladění hyperparametrů umožní spuštění všech trénovacích úloh až do dokončení.
sweep_job.early_termination = None
Výběr zásad předčasného ukončení
- Pro konzervativní politiku, která poskytuje úspory bez ukončení slibných pracovních míst, zvažte medián zastavovací zásady s
evaluation_interval1 adelay_evaluation5. Jedná se o konzervativní nastavení, která mohou poskytnout přibližně 25%-35% úspory bez ztráty na primární metrice (na základě našich dat vyhodnocení). - Pokud chcete agresivnější úspory, použijte zásadu banditů s menší povolenou časovou rezervou nebo zásady výběru zkrácení s větším procentem zkrácení.
Nastavení limitů pro úlohu úklidu
Rozpočet zdrojů můžete řídit nastavením limitů pro úlohu úklidu.
max_total_trials: Maximální počet zkušebních úloh. Musí to být celé číslo od 1 do 1000.max_concurrent_trials: (volitelné) Maximální počet zkušebních úloh, které se můžou spouštět souběžně. Pokud není zadaný, max_total_trials počet úloh spuštěných paralelně. Pokud je zadáno, musí se jednat o celé číslo od 1 do 1000.timeout: Maximální doba v sekundách, po kterou může běžet celá úloha úklidu. Po dosažení tohoto limitu systém zruší úlohu úklidu, včetně všech zkušebních verzí.trial_timeout: Maximální doba v sekundách, kdy je možné spustit každou zkušební úlohu. Po dosažení tohoto limitu systém zkušební verzi zruší.
Poznámka
Pokud jsou zadány max_total_trials i časový limit, experiment ladění hyperparametrů se ukončí při dosažení první z těchto dvou prahových hodnot.
Poznámka
Počet souběžných zkušebních úloh se vztahuje na prostředky dostupné v zadaném cílovém výpočetním objektu. Ujistěte se, že cíl výpočetních prostředků má dostupné prostředky pro požadovanou souběžnost.
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=4, timeout=1200)
Tento kód nakonfiguruje experiment ladění hyperparametrů tak, aby používal maximálně 20 celkem zkušebních úloh a spouštěl čtyři zkušební úlohy najednou s časovým limitem 1200 sekund pro celou úlohu úklidu.
Konfigurace experimentu ladění hyperparametrů
Pokud chcete nakonfigurovat experiment ladění hyperparametrů, zadejte následující:
- Definovaný prostor pro vyhledávání hyperparametrů
- Váš algoritmus vzorkování
- Vaše zásady předčasného ukončení
- Váš cíl
- Omezení prostředků
- CommandJob nebo CommandComponent
- Úloha úklidu
SweepJob může spustit úklid hyperparametrů v command nebo command komponentě.
Poznámka
Cílový výpočetní objekt použitý v sweep_job nástroji musí mít dostatek prostředků, aby vyhovoval vaší úrovni souběžnosti. Další informace o cílových výpočetních prostředcích najdete v tématu Cíle výpočetních prostředků.
Nakonfigurujte experiment ladění hyperparametrů:
from azure.ai.ml import MLClient
from azure.ai.ml import command, Input
from azure.ai.ml.sweep import Choice, Uniform, MedianStoppingPolicy
from azure.identity import DefaultAzureCredential
# Create your base command job
command_job = command(
code="./src",
command="python main.py --iris-csv ${{inputs.iris_csv}} --learning-rate ${{inputs.learning_rate}} --boosting ${{inputs.boosting}}",
environment="AzureML-lightgbm-3.2-ubuntu18.04-py37-cpu@latest",
inputs={
"iris_csv": Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/iris.csv",
),
"learning_rate": 0.9,
"boosting": "gbdt",
},
compute="cpu-cluster",
)
# Override your inputs with parameter expressions
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.01, max_value=0.9),
boosting=Choice(values=["gbdt", "dart"]),
)
# Call sweep() on your command job to sweep over your parameter expressions
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm="random",
primary_metric="test-multi_logloss",
goal="Minimize",
)
# Specify your experiment details
sweep_job.display_name = "lightgbm-iris-sweep-example"
sweep_job.experiment_name = "lightgbm-iris-sweep-example"
sweep_job.description = "Run a hyperparameter sweep job for LightGBM on Iris dataset."
# Define the limits for this sweep
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=10, timeout=7200)
# Set early stopping on this one
sweep_job.early_termination = MedianStoppingPolicy(
delay_evaluation=5, evaluation_interval=2
)
Volá command_job se jako funkce, abychom mohli použít výrazy parametrů na vstupy úklidu. Funkce sweep se pak nakonfiguruje pomocí trial, sampling-algorithm, objective, limitsa compute. Výše uvedený fragment kódu je převzatý z ukázkového poznámkového bloku Spuštění úklidu hyperparametrů na příkaz nebo commandcomponent. V této ukázce se vyladí learning_rate parametry a boosting . Předčasné zastavení úloh bude určeno úlohou MedianStoppingPolicy, která zastaví úlohu, jejíž primární hodnota metriky je horší než medián průměrů ve všech trénovacích úlohách.( viz Referenční informace o třídě MedianStoppingPolicy).
Pokud chcete zjistit, jak se hodnoty parametrů přijímají, parsují a předávají do trénovacího skriptu, který se má vyladit, projděte si tuto ukázku kódu.
Důležité
Každá úloha úklidu hyperparametrů restartuje trénování od začátku, včetně opětovného sestavení modelu a všech zavaděčů dat. Tyto náklady můžete minimalizovat pomocí kanálu Azure Machine Learning nebo ručního procesu, abyste před trénovacími úlohami udělali co největší přípravu dat.
Odeslání experimentu ladění hyperparametrů
Po definování konfigurace ladění hyperparametrů odešlete úlohu:
# submit the sweep
returned_sweep_job = ml_client.create_or_update(sweep_job)
# get a URL for the status of the job
returned_sweep_job.services["Studio"].endpoint
Vizualizace úloh ladění hyperparametrů
Všechny úlohy ladění hyperparametrů můžete vizualizovat v studio Azure Machine Learning. Další informace o zobrazení experimentu na portálu najdete v tématu Zobrazení záznamů úloh ve studiu.
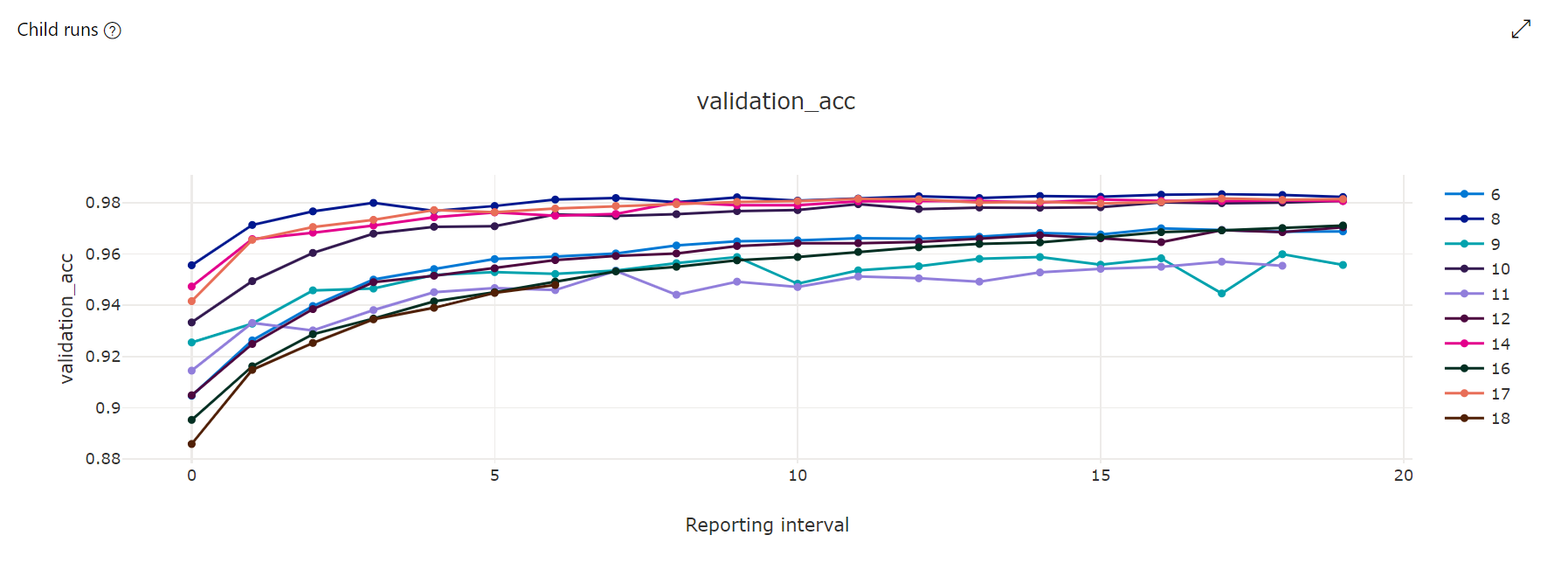
Graf metrik: Tato vizualizace sleduje metriky protokolované pro každou podřízenou úlohu hyperdrivu po dobu trvání ladění hyperparametrů. Každý řádek představuje podřízenou úlohu a každý bod měří primární hodnotu metriky v této iteraci modulu runtime.
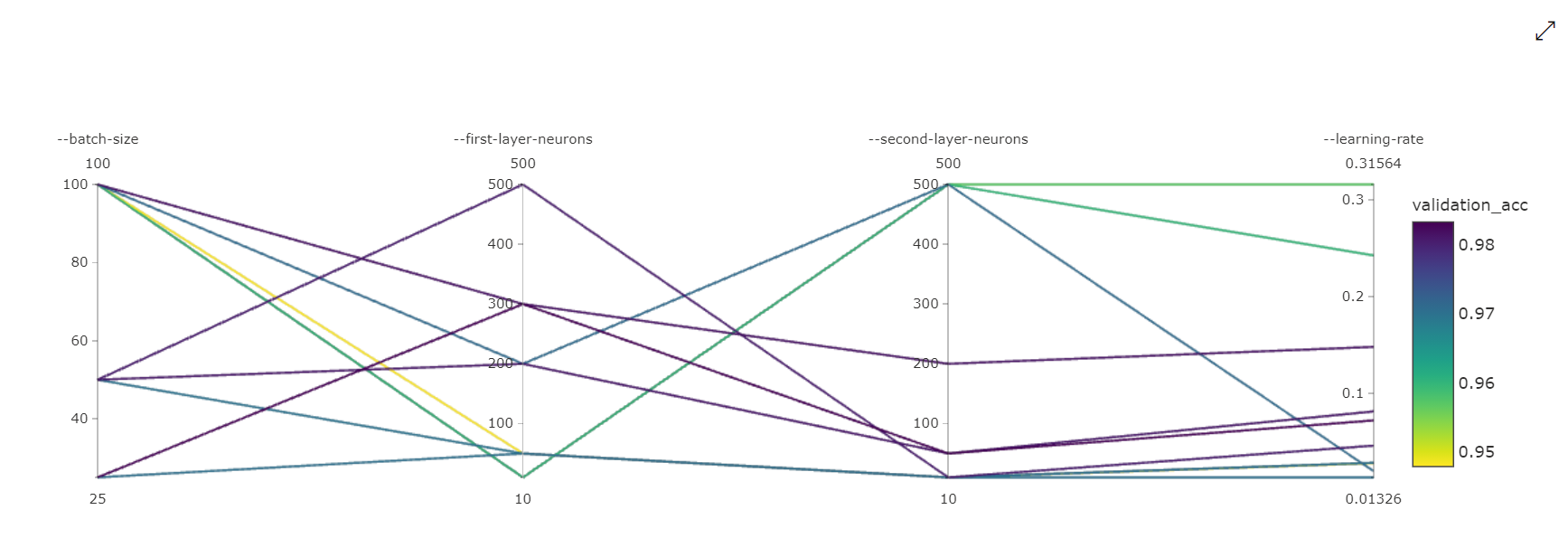
Graf paralelních souřadnic: Tato vizualizace ukazuje korelaci mezi výkonem primární metriky a jednotlivými hodnotami hyperparametrů. Graf je interaktivní prostřednictvím pohybu os (kliknutí a přetažení za popisek osy) a zvýraznění hodnot napříč jednou osou (kliknutím a přetažením svisle podél jedné osy zvýrazníte rozsah požadovaných hodnot). Graf paralelních souřadnic obsahuje osu v pravé části grafu, která vykreslí nejlepší hodnotu metriky odpovídající hyperparametrům nastaveným pro danou instanci úlohy. Tato osa je k dispozici za účelem promítání legendy přechodu grafu na data čitelnějším způsobem.
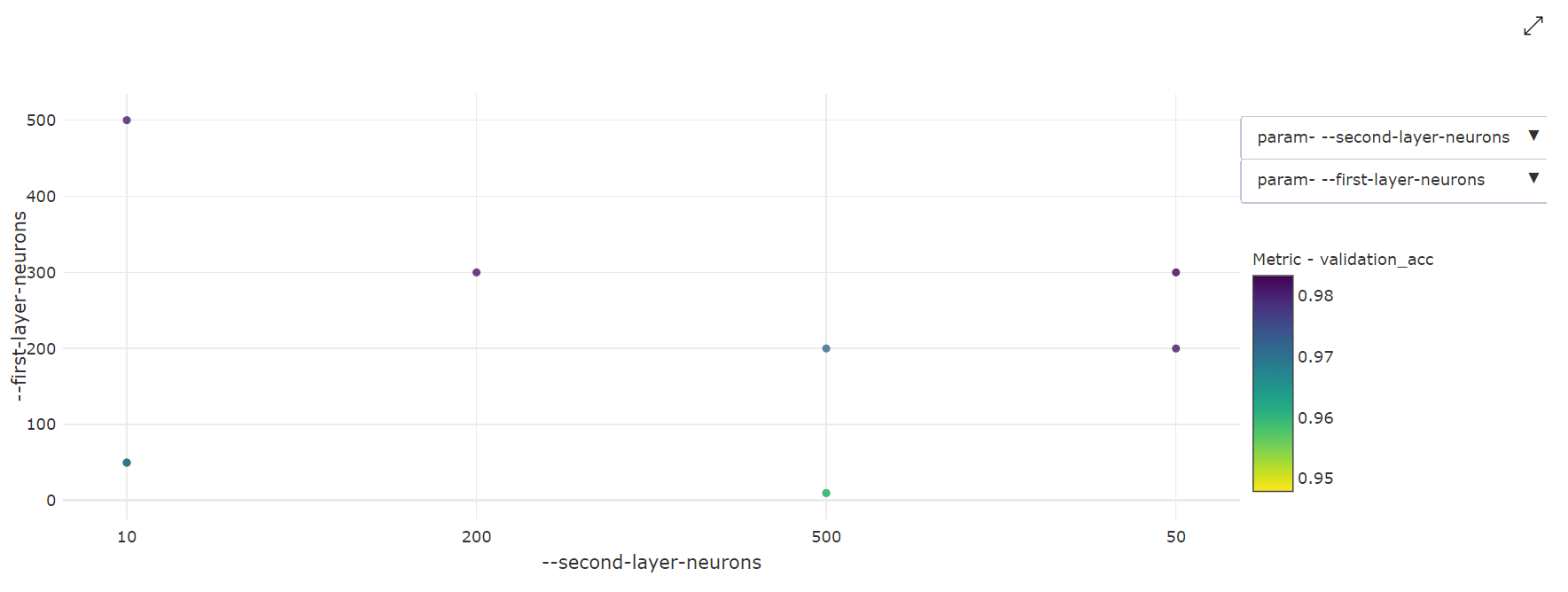
Dvojrozměrný bodový graf: Tato vizualizace ukazuje korelaci mezi libovolnými dvěma jednotlivými hyperparametry a jejich přidruženou primární hodnotou metriky.
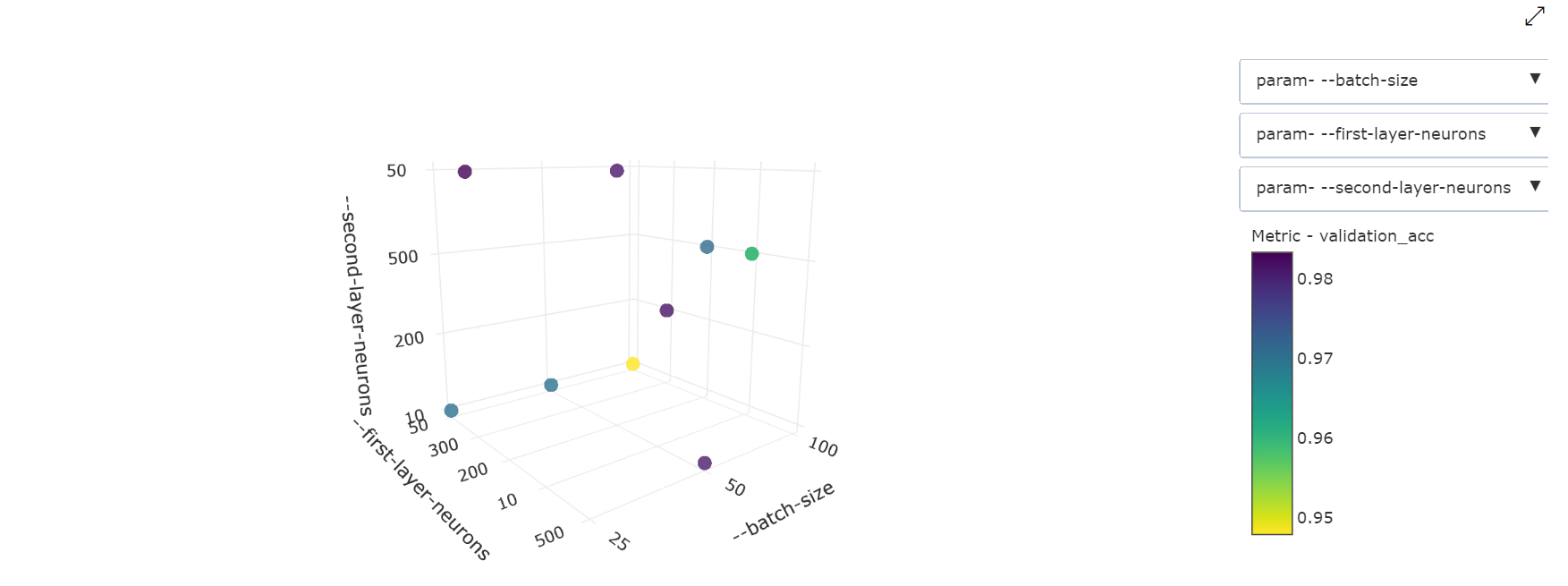
Trojrozměrný bodový graf: Tato vizualizace je stejná jako 2D, ale umožňuje tři hyperparametry korelace s primární hodnotou metriky. Kliknutím a přetažením můžete graf přeorientovat a zobrazit tak různé korelace v 3D prostoru.
Vyhledání nejlepší zkušební úlohy
Po dokončení všech úloh ladění hyperparametrů načtěte nejlepší výstupy zkušební verze:
# Download best trial model output
ml_client.jobs.download(returned_sweep_job.name, output_name="model")
Pomocí rozhraní příkazového řádku můžete stáhnout všechny výchozí a pojmenované výstupy nejlepší zkušební úlohy a protokoly úlohy úklidu.
az ml job download --name <sweep-job> --all
Volitelně můžete stáhnout výhradně nejlepší zkušební výstup.
az ml job download --name <sweep-job> --output-name model