Vyhodnocení výsledků experimentu automatizovaného strojového učení
V tomto článku se dozvíte, jak vyhodnotit a porovnat modely vytrénované experimentem automatizovaného strojového učení (automatizované strojové učení). V průběhu automatizovaného experimentu ML se vytvoří mnoho úloh a každá úloha vytvoří model. Automatizované strojové učení pro každý model vygeneruje hodnoticí metriky a grafy, které vám pomůžou měřit výkon modelů. Řídicí panel Zodpovědné umělé inteligence můžete dále vygenerovat, abyste ve výchozím nastavení mohli provést holistické posouzení a ladění doporučeného nejlepšího modelu. To zahrnuje přehledy, jako jsou vysvětlení modelů, nestrannost a Průzkumník výkonu, Průzkumník dat, analýza chyb modelu. Přečtěte si další informace o tom, jak můžete vygenerovat řídicí panel zodpovědné umělé inteligence.
Automatizované strojové učení například vygeneruje následující grafy na základě typu experimentu.
Důležité
Položky označené (Preview) v tomto článku jsou aktuálně ve verzi Public Preview. Verze Preview je poskytována bez smlouvy o úrovni služeb a nedoporučuje se pro produkční úlohy. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti. Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
Předpoklady
- Předplatné Azure. (Pokud nemáte předplatné Azure, vytvořte si před zahájením bezplatný účet .
- Experiment azure machine Učení vytvořený pomocí těchto akcí:
- Studio Azure Machine Learning (nevyžaduje se žádný kód)
- Sada Azure Machine Učení Python SDK
Zobrazení výsledků úlohy
Po dokončení experimentu automatizovaného strojového učení najdete historii úloh prostřednictvím:
- Prohlížeč s studio Azure Machine Learning
- Poznámkový blok Jupyter pomocí widgetu JobDetails Jupyter
Následující kroky a video ukazují, jak zobrazit historii spuštění a metriky vyhodnocení modelu a grafy v sadě Studio:
- Přihlaste se do studia a přejděte do svého pracovního prostoru.
- V nabídce vlevo vyberte Úlohy.
- V seznamu experimentů vyberte svůj experiment.
- V tabulce v dolní části stránky vyberte automatizovanou úlohu ML.
- Na kartě Modely vyberte název algoritmu pro model, který chcete vyhodnotit.
- Na kartě Metriky můžete pomocí zaškrtávacích políček vlevo zobrazit metriky a grafy.
Metriky klasifikace
Automatizované strojové učení vypočítá metriky výkonu pro každý klasifikační model vygenerovaný pro váš experiment. Tyto metriky jsou založené na implementaci scikit learn.
Mnoho metrik klasifikace je definováno pro binární klasifikaci ve dvou třídách a vyžaduje průměrování tříd, aby se vytvořilo jedno skóre pro klasifikaci s více třídami. Scikit-learn poskytuje několik průměrovaných metod, z nichž tři automatizované strojové učení zveřejňuje: makro, mikro a vážené.
- Makro – Výpočet metriky pro každou třídu a převzetí nevážného průměru
- Micro – Výpočet metriky globálně počítáním celkových pravdivě pozitivních výsledků, falešně negativních výsledků a falešně pozitivních výsledků (nezávisle na třídách).
- Vážené – vypočítá metriku pro každou třídu a vezme vážený průměr na základě počtu vzorků na třídu.
I když má každá metoda průměrování své výhody, je jednou z běžných aspektů při výběru vhodné metody nerovnováha tříd. Pokud mají třídy různý počet vzorků, může být informativnější použít průměr makra, kdy menšinové třídy mají stejnou váhu tříd většiny. Přečtěte si další informace o binárních a vícetřídových metrikách v automatizovaném strojovém učení.
Následující tabulka shrnuje metriky výkonu modelu, které automatizované strojové učení vypočítá pro každý klasifikační model vygenerovaný pro váš experiment. Další podrobnosti najdete v dokumentaci scikit-learn propojenou v poli Výpočet jednotlivých metrik.
Poznámka:
Další podrobnosti o metrikách pro modely klasifikace obrázků najdete v části s metrikami.
| Metrické | Popis | Výpočet |
|---|---|---|
| AUC | AUC je oblast pod křivkou provozních charakteristik přijímače. Cíl: Čím blíž k 1, tím lépe Rozsah: [0, 1] Mezi podporované názvy metrik patří: AUC_macro, aritmetický průměr AUC pro každou třídu.AUC_microvypočítané počítáním celkových pravdivě pozitivních výsledků, falešně negativních výsledků a falešně pozitivních výsledků. AUC_weighted, aritmetický průměr skóre pro každou třídu vážený počtem pravdivých instancí v každé třídě. AUC_binary, hodnota AUC tím, že zachází s jednou konkrétní třídou jako true se třídou a zkombinuje všechny ostatní třídy jako false třídy. |
Výpočet |
| accuracy | Přesnost je poměr předpovědí, které přesně odpovídají popiskům skutečné třídy. Cíl: Čím blíž k 1, tím lépe Rozsah: [0, 1] |
Výpočet |
| average_precision | Průměrná přesnost shrnuje křivku úplnosti přesnosti jako vážený průměr přesnosti dosaženého při každé prahové hodnotě a zvýšení úplnosti z předchozí prahové hodnoty použité jako váha. Cíl: Čím blíž k 1, tím lépe Rozsah: [0, 1] Mezi podporované názvy metrik patří: average_precision_score_macro, aritmetický průměr průměrného skóre přesnosti každé třídy.average_precision_score_microvypočítané počítáním celkových pravdivě pozitivních výsledků, falešně negativních výsledků a falešně pozitivních výsledků.average_precision_score_weighted, aritmetický průměr průměrného skóre přesnosti pro každou třídu vážený počtem pravdivých instancí v každé třídě. average_precision_score_binary, hodnota průměrné přesnosti tím, že zachází s jednou konkrétní třídou jako true se třídou a zkombinuje všechny ostatní třídy jako false třídu. |
Výpočet |
| balanced_accuracy | Vyvážená přesnost je aritmetická střední hodnota úplnosti pro každou třídu. Cíl: Čím blíž k 1, tím lépe Rozsah: [0, 1] |
Výpočet |
| f1_score | Skóre F1 je harmonický průměr přesnosti a úplnosti. Jedná se o dobrou vyváženou míru falešně pozitivních i falešně negativních výsledků. Nebere však v úvahu skutečné negativní hodnoty. Cíl: Čím blíž k 1, tím lépe Rozsah: [0, 1] Mezi podporované názvy metrik patří: f1_score_macro: aritmetický průměr skóre F1 pro každou třídu. f1_score_micro: vypočítáno počítáním celkových pravdivě pozitivních výsledků, falešně negativních výsledků a falešně pozitivních výsledků. f1_score_weighted: vážený průměr podle frekvence tříd skóre F1 pro každou třídu. f1_score_binary, hodnota f1 tím, že považuje jednu konkrétní třídu za true třídu a zkombinuje všechny ostatní třídy jako false třídu. |
Výpočet |
| log_loss | Jedná se o funkci ztráty, která se používá v logistické regresi (multinomické) a rozšíření, jako jsou neurální sítě definované jako negativní pravděpodobnosti skutečných popisků při predikcích pravděpodobnosti klasifikátoru pravděpodobnosti pravděpodobnosti. Cíl: Čím blíž k 0, tím lépe Rozsah: [0, inf) |
Výpočet |
| norm_macro_recall | Normalizované odvolání makra je zprůměrované a normalizované, takže náhodný výkon má skóre 0 a dokonalý výkon má skóre 1. Cíl: Čím blíž k 1, tím lépe Rozsah: [0, 1] |
(recall_score_macro - R) / (1 - R) kde, R je očekávaná hodnota recall_score_macro pro náhodné předpovědi.R = 0.5 pro binární klasifikaci. R = (1 / C) pro problémy klasifikace tříd jazyka C. |
| matthews_correlation | Korelační koeficient Matthews je vyvážená míra přesnosti, kterou lze použít i v případě, že jedna třída obsahuje více vzorků než jiné. Koeficient 1 označuje dokonalou předpověď, 0 náhodných předpovědí a -1 inverzní předpovědi. Cíl: Čím blíž k 1, tím lépe Rozsah: [-1, 1] |
Výpočet |
| přesnost | Přesnost je schopnost modelu vyhnout se označování negativních vzorků jako pozitivních. Cíl: Čím blíž k 1, tím lépe Rozsah: [0, 1] Mezi podporované názvy metrik patří: precision_score_macro, aritmetický průměr přesnosti pro každou třídu. precision_score_micro, vypočítaný globálně počítáním celkových pravdivě pozitivních výsledků a falešně pozitivních výsledků. precision_score_weighted, aritmetický průměr přesnosti pro každou třídu vážený počtem pravdivých instancí v každé třídě. precision_score_binary, hodnota přesnosti tím, že považuje jednu konkrétní třídu za true třídu a zkombinuje všechny ostatní třídy jako false třídu. |
Výpočet |
| úplnost | Připomeňme si, že model dokáže detekovat všechny pozitivní vzorky. Cíl: Čím blíž k 1, tím lépe Rozsah: [0, 1] Mezi podporované názvy metrik patří: recall_score_macro: aritmetický průměr úplnosti pro každou třídu. recall_score_micro: vypočítáno globálně počítáním celkových pravdivě pozitivních výsledků, falešně negativních výsledků a falešně pozitivních výsledků.recall_score_weighted: aritmetická střední hodnota úplnosti pro každou třídu, vážená počtem pravdivých instancí v každé třídě. recall_score_binary, hodnota odvolání tím, že zachází s jednou konkrétní třídou jako true se třídou a kombinuje všechny ostatní třídy jako false třídu. |
Výpočet |
| weighted_accuracy | Vážená přesnost je přesnost, při které je každý vzorek vážený celkovým počtem vzorků patřících do stejné třídy. Cíl: Čím blíž k 1, tím lépe Rozsah: [0, 1] |
Výpočet |
Binární a vícetřídové metriky klasifikace
Automatizované strojové učení automaticky zjistí, jestli jsou data binární, a také umožňuje uživatelům aktivovat binární klasifikační metriky, i když jsou data vícetřídová zadáním true třídy. Metriky klasifikace s více třídami jsou hlášeny, pokud má datová sada dvě nebo více tříd. Metriky binární klasifikace jsou hlášeny pouze v případech, kdy jsou data binární.
Všimněte si, že metriky klasifikace s více třídami jsou určeny pro klasifikaci s více třídami. Při použití na binární datovou sadu tyto metriky nezachází s žádnou třídou jako true s třídou, jak byste mohli očekávat. Metriky, které jsou jasně určeny pro vícetřídy, mají příponu s příponou micro, macronebo weighted. Mezi příklady patří average_precision_score, , f1_scoreprecision_score, recall_score, a AUC. Například místo výpočtu úplnosti jako tp / (tp + fn), vícetřídové průměrné úplnosti (micro, macronebo weighted) průměry nad oběma třídami binární klasifikační datové sady. To je ekvivalentem výpočtu úplnosti pro true třídu a false třídy samostatně a pak vezme průměr těchto dvou.
Kromě toho, i když je podporována automatická detekce binární klasifikace, je stále doporučeno vždy zadat true třídu ručně, aby se zajistilo, že binární metriky klasifikace se počítají pro správnou třídu.
Pokud chcete aktivovat metriky pro datové sady binární klasifikace, pokud je samotná datová sada vícetříd, uživatelé musí určit pouze třídu, která se má považovat za true třídu, a tyto metriky se počítají.
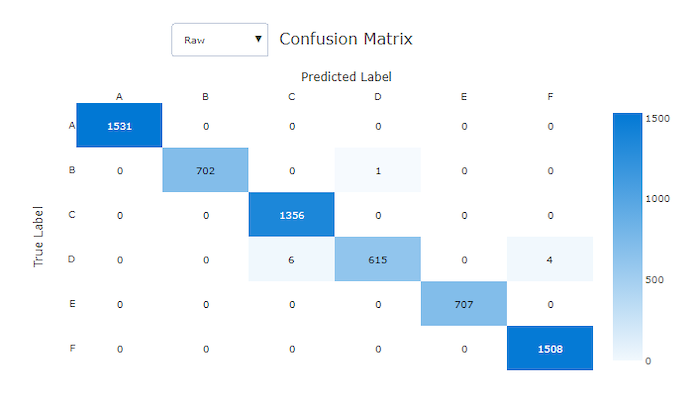
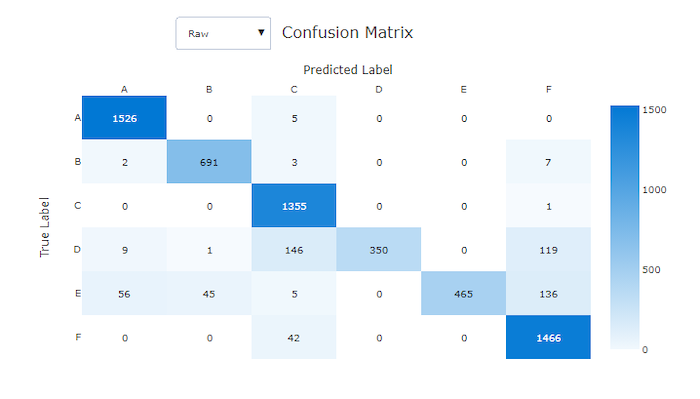
Matice zmatku
Matrice záměny poskytují vizuální informace o tom, jak model strojového učení provádí v předpovědích klasifikačních modelů systematickou chybu. Slovo "záměna" v názvu pochází z modelu "matoucí" nebo chybné označení vzorků. Buňka na řádku i a sloupci j v konfuzní matici obsahuje počet vzorků v testovací datové sadě, které patří do třídy C_i a byly klasifikovány modelem jako třída C_j.
V studiu tmavší buňka označuje vyšší počet vzorků. Výběrem normalizovaného zobrazení v rozevíracím seznamu se normalizuje přes každý řádek matice, aby se zobrazilo procento třídy C_i predikované jako třída C_j. Výhodou výchozího zobrazení Raw je, že můžete zjistit, jestli nerovnováha v rozdělení skutečných tříd způsobovala, že model nesprávně klasifikoval vzorky z menšinové třídy, běžnou problémem v nevyvážených datových sadách.
Matoucí matice dobrého modelu bude mít většinu vzorků podél diagonální.
Konfuzní matice pro dobrý model
Konfuzní matice pro chybný model
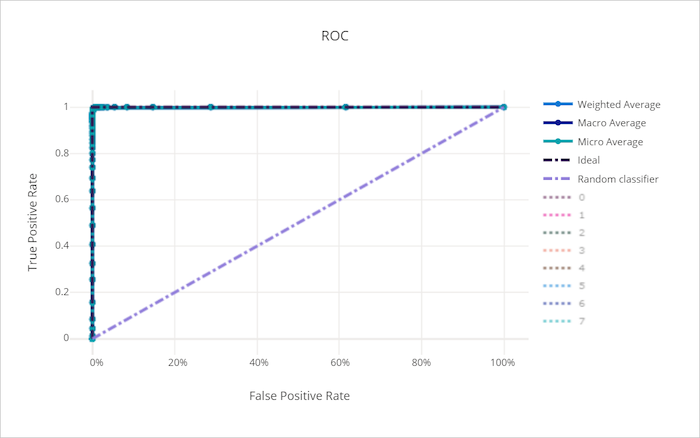
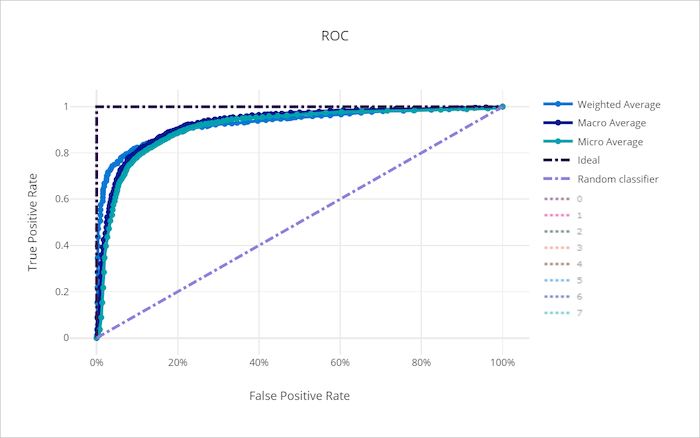
Křivka ROC
Křivka provozní charakteristiky příjemce (ROC) vykreslí vztah mezi skutečnou kladnou rychlostí (TPR) a falešně pozitivní sazbou (FPR) jako změny rozhodovací prahové hodnoty. Křivka ROC může být méně informativní při trénování modelů na datových sadách s vysokou nerovnováhou, protože většina třídy může utopit příspěvky z menšinových tříd.
Oblast pod křivkou (AUC) lze interpretovat jako poměr správně klasifikovaných vzorků. Přesněji řečeno, AUC je pravděpodobnost, že klasifikátor řadí náhodně zvolený pozitivní vzorek vyšší než náhodně zvolený záporný vzorek. Tvar křivky poskytuje intuici pro vztah mezi TPR a FPR jako funkcí prahové hodnoty klasifikace nebo rozhodovací hranice.
Křivka, která se blíží levému hornímu rohu grafu, se blíží 100% TPR a 0% FPR, nejlepší možný model. Náhodný model by vytvořil křivku ROC podél y = x čáry z levého dolního rohu do pravého horního rohu. Horší než náhodný model by měl křivku ROC, která se propadá pod čáru y = x .
Tip
U klasifikačních experimentů lze každý spojnicový graf vytvořený pro automatizované modely ML použít k vyhodnocení modelu podle třídy nebo průměru ve všech třídách. Mezi těmito různými zobrazeními můžete přepínat kliknutím na popisky tříd v legendě napravo od grafu.
Křivka ROC pro dobrý model
Křivka ROC pro špatný model
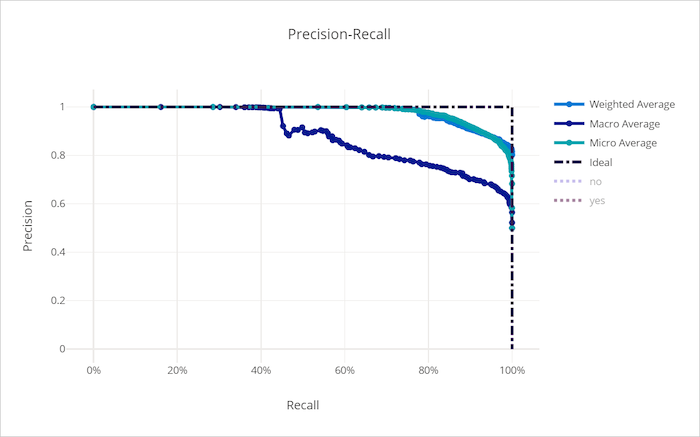
Křivka přesnosti úplnosti
Křivka přesnosti a úplnosti vykreslí vztah mezi přesností a úplností při změně rozhodovací prahové hodnoty. Připomeňme si, že model dokáže rozpoznat všechny pozitivní vzorky a přesnost, je schopnost modelu vyhnout se označování negativních vzorků jako pozitivních. Některé obchodní problémy můžou vyžadovat vyšší úplnost a vyšší přesnost v závislosti na relativní důležitosti, aby nedocházelo k falešně negativním výsledkům a falešně pozitivním výsledkům.
Tip
U klasifikačních experimentů lze každý spojnicový graf vytvořený pro automatizované modely ML použít k vyhodnocení modelu podle třídy nebo průměru ve všech třídách. Mezi těmito různými zobrazeními můžete přepínat kliknutím na popisky tříd v legendě napravo od grafu.
Křivka přesnosti úplnosti pro dobrý model
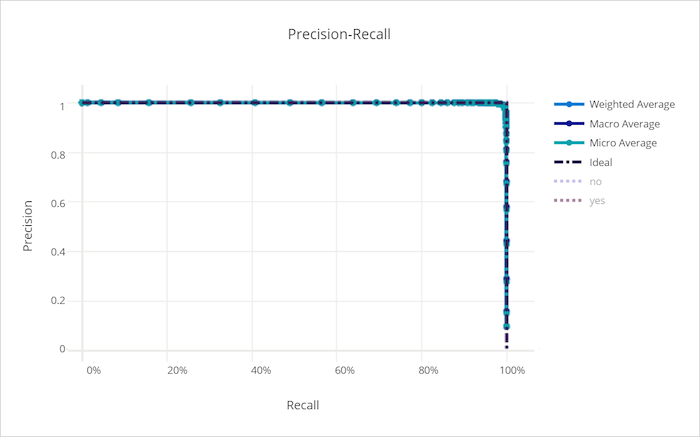
Křivka přesnosti úplnosti pro špatný model
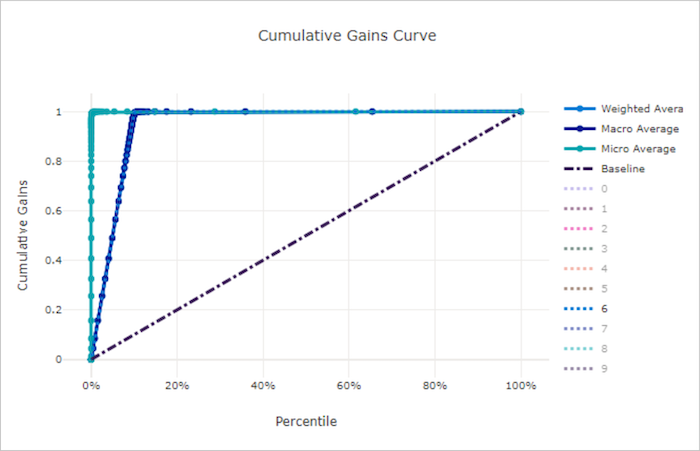
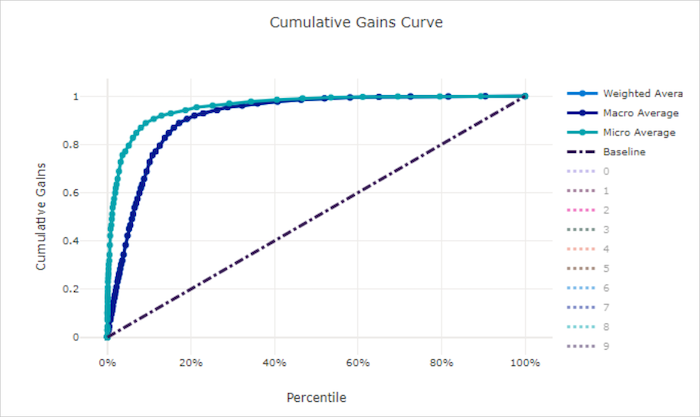
Křivka kumulativních zisků
Kumulativní zisky křivky vykreslují procento kladných vzorků správně klasifikovaných jako funkce procent vzorků, u kterých zvažujeme výběry v pořadí předpovídané pravděpodobnosti.
Pokud chcete vypočítat zisk, nejprve seřaďte všechny vzorky od nejvyšší po nejnižší pravděpodobnost předpovězené modelem. Pak využijte x% predikce nejvyšší spolehlivosti. Vydělí počet pozitivních vzorků zjištěných v tom x% celkovým počtem pozitivních vzorků, aby získal zisk. Kumulativní zisk je procento pozitivních vzorků, které zjistíme při zvažování některých procent dat, která s největší pravděpodobností patří do pozitivní třídy.
Dokonalý model bude seřadit všechny kladné vzorky nad všemi negativními vzorky, které poskytují kumulativní křivku zisků tvořenou dvěma rovnými segmenty. První je přímka se sklonem od (x, 1)(0, 0) místa1 / x, kde x je zlomek vzorků, které patří do kladné třídy (1 / num_classespokud jsou třídy vyváženy). Druhá je vodorovná čára od (x, 1) do (1, 1). V prvním segmentu jsou všechny pozitivní vzorky klasifikovány správně a kumulativní zisk přejde do 100% první x% z považovaných vzorků.
Náhodný model podle směrného plánu bude mít kumulativní křivku zisků, která následuje v y = x případě, že x% byly zjištěny pouze x% celkové kladné vzorky. Ideální model pro vyváženou datovou sadu bude mít mikroprůměrnou křivku a přímku průměru makra, která má sklon num_classes , dokud kumulativní zisk není 100 %, a pak vodorovně, dokud nebude 100 procent dat.
Tip
U klasifikačních experimentů lze každý spojnicový graf vytvořený pro automatizované modely ML použít k vyhodnocení modelu podle třídy nebo průměru ve všech třídách. Mezi těmito různými zobrazeními můžete přepínat kliknutím na popisky tříd v legendě napravo od grafu.
Křivka kumulativních zisků pro dobrý model
Křivka kumulativních zisků pro chybný model
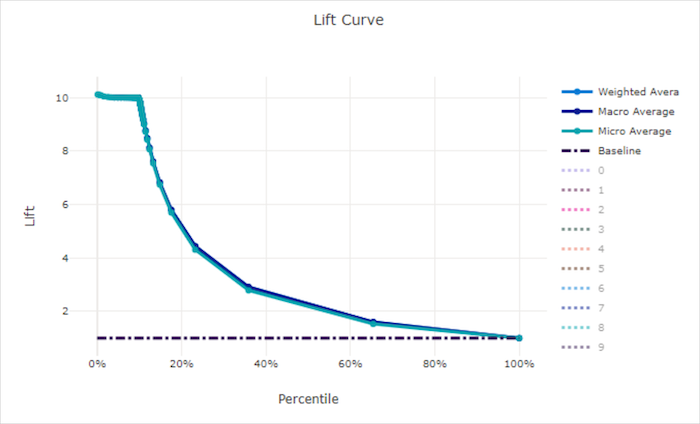
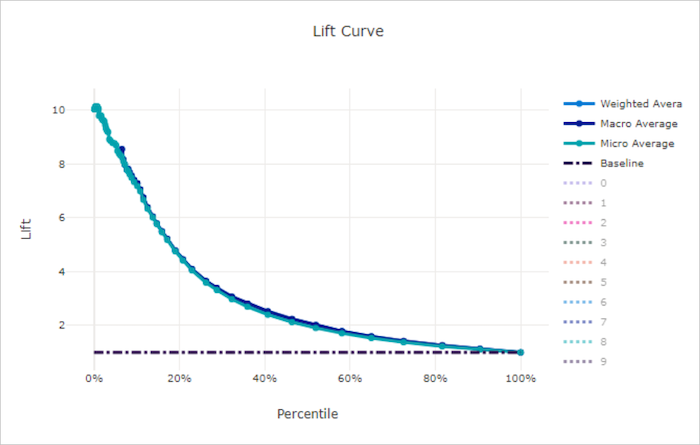
Křivka navýšení
Křivka lift ukazuje, kolikrát lépe model funguje v porovnání s náhodným modelem. Lift je definován jako poměr kumulativního zisku k kumulativnímu získání náhodného modelu (který by měl být 1vždy ).
Tento relativní výkon bere v úvahu skutečnost, že klasifikace je obtížnější při zvyšování počtu tříd. (Náhodný model nesprávně předpovídá vyšší zlomek vzorků z datové sady s 10 třídami ve srovnání s datovou sadou se dvěma třídami)
Směrná křivka lift je y = 1 přímka, ve které je výkon modelu konzistentní s výkonem náhodného modelu. Obecně platí, že křivka lift pro dobrý model bude na daném grafu vyšší a dále od osy X, která ukazuje, že když je model nejistější ve svých predikcích, provádí mnohokrát lépe než náhodné odhadování.
Tip
U klasifikačních experimentů lze každý spojnicový graf vytvořený pro automatizované modely ML použít k vyhodnocení modelu podle třídy nebo průměru ve všech třídách. Mezi těmito různými zobrazeními můžete přepínat kliknutím na popisky tříd v legendě napravo od grafu.
Lift curve for a good model
Lift curve for a bad model
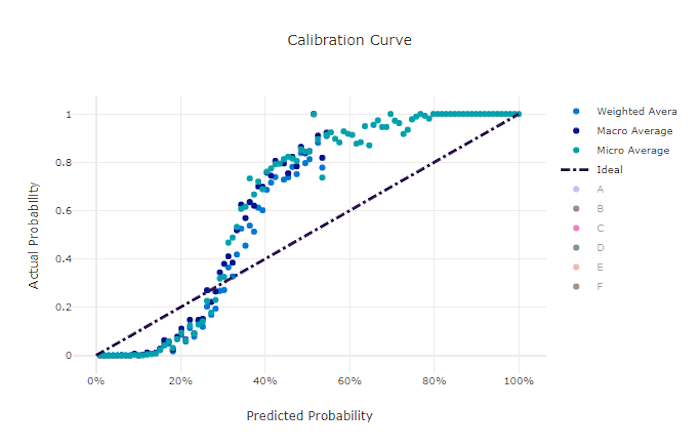
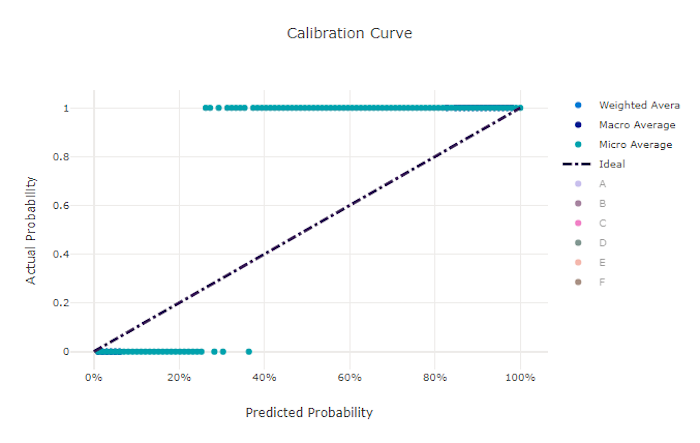
Kalibrační křivka
Křivka kalibrace vykreslí spolehlivost modelu ve svých předpovědích s poměrem kladných vzorků na každé úrovni spolehlivosti. Dobře kalibrovaný model správně klasifikuje 100 % predikcí, kterým přiřazuje 100% spolehlivost, 50 % predikcí přiřadí 50 % spolehlivosti, 20 % predikcí přiřadí 20 % spolehlivosti atd. Dokonale kalibrovaný model bude mít křivku kalibrace za y = x čárou, kde model dokonale předpovídá pravděpodobnost, že vzorky patří do každé třídy.
Příliš spolehlivý model přepovědí pravděpodobnosti blízko nuly a jedné, přičemž zřídka není jisté o třídě každého vzorku a křivka kalibrace bude vypadat podobně jako vzad "S". Model s nižší jistotou přiřadí průměrné pravděpodobnosti třídě, která předpovídá, a přidružená křivka kalibrace bude vypadat podobně jako "S". Křivka kalibrace nezobrazuje schopnost modelu správně klasifikovat, ale její schopnost správně přiřazovat spolehlivost jeho předpovědím. Špatný model může mít stále dobrou křivku kalibrace, pokud model správně přiřadí nízkou spolehlivost a vysokou nejistotu.
Poznámka:
Křivka kalibrace je citlivá na počet vzorků, takže malá ověřovací sada může vést k hlučným výsledkům, které je obtížné interpretovat. To nemusí nutně znamenat, že model není dobře kalibrovaný.
Křivka kalibrace pro dobrý model
Křivka kalibrace špatného modelu
Regrese / prognózování metrik
Automatizované strojové učení vypočítá stejné metriky výkonu pro každý vygenerovaný model bez ohledu na to, jestli se jedná o regresi nebo prognózovací experiment. Tyto metriky také procházejí normalizací, aby bylo možné porovnávat modely natrénované na datech s různými rozsahy. Další informace najdete v tématu normalizace metrik.
Následující tabulka shrnuje metriky výkonu modelu vygenerované pro regresi a prognózování experimentů. Podobně jako u klasifikačních metrik jsou tyto metriky také založené na implementacích scikit learn. Odpovídající dokumentace scikit learn je odpovídajícím způsobem propojena v poli Výpočet .
| Metrické | Popis | Výpočet |
|---|---|---|
| explained_variance | Vysvětlení rozptylu měří rozsah, ve kterém model představuje variaci v cílové proměnné. Jedná se o procentuální pokles odchylky původních dat od odchylky chyb. Pokud je průměr chyb 0, rovná se koeficientu stanovení (viz r2_score níže). Cíl: Čím blíž k 1, tím lépe Rozsah: (-inf, 1] |
Výpočet |
| mean_absolute_error | Střední absolutní chyba je očekávaná hodnota absolutní hodnoty rozdílu mezi cílem a predikcí. Cíl: Čím blíž k 0, tím lépe Rozsah: [0, inf) Typy: mean_absolute_error normalized_mean_absolute_error, mean_absolute_error děleno rozsahem dat. |
Výpočet |
| mean_absolute_percentage_error | Střední absolutní procentuální chyba (MAPE) je míra průměrného rozdílu mezi predikovanou hodnotou a skutečnou hodnotou. Cíl: Čím blíž k 0, tím lépe Rozsah: [0, inf) |
|
| median_absolute_error | Medián absolutní chyby je medián všech absolutních rozdílů mezi cílem a predikcí. Tato ztráta je robustní pro odlehlé hodnoty. Cíl: Čím blíž k 0, tím lépe Rozsah: [0, inf) Typy: median_absolute_errornormalized_median_absolute_error: median_absolute_error děleno rozsahem dat. |
Výpočet |
| r2_score | R2 (koeficient stanovení) měří proporcionální snížení střední kvadratická chyba (MSE) vzhledem k celkové odchylkě pozorovaných dat. Cíl: Čím blíž k 1, tím lépe Rozsah: [-1, 1] Poznámka: R2 má často rozsah (-inf, 1]. MsE může být větší než pozorovaný rozptyl, takže R2 může mít libovolně velké záporné hodnoty v závislosti na datech a předpovědích modelu. Automatizované klipy ML hlásily skóre R2 na -1, takže hodnota -1 pro R2 pravděpodobně znamená, že skutečné skóre R2 je menší než -1. Při interpretaci záporného skóre R2 zvažte další hodnoty metrik a vlastnosti dat. |
Výpočet |
| root_mean_squared_error | Odmocnina střední kvadratická chyba (RMSE) je druhá odmocnina očekávaného čtvercového rozdílu mezi cílem a predikcí. U nestranného odhadce se RMSE rovná směrodatné odchylce. Cíl: Čím blíž k 0, tím lépe Rozsah: [0, inf) Typy: root_mean_squared_error normalized_root_mean_squared_error: root_mean_squared_error děleno rozsahem dat. |
Výpočet |
| root_mean_squared_log_error | Odmocnina střední kvadratická chyba protokolu je druhou odmocninou očekávané logaritmické chyby. Cíl: Čím blíž k 0, tím lépe Rozsah: [0, inf) Typy: root_mean_squared_log_error normalized_root_mean_squared_log_error: root_mean_squared_log_error děleno rozsahem dat. |
Výpočet |
| spearman_correlation | Spearmanova korelace je neparametrické měřítko monotonicity vztahu mezi dvěma datovými sadami. Na rozdíl od Pearsonové korelace spearmanova korelace nepředpokládá, že obě datové sady jsou normálně distribuovány. Stejně jako ostatní korelační koeficienty se Spearman liší mezi -1 a 1 a 0 znamená žádnou korelaci. Korelace -1 nebo 1 znamenají přesnou monotónní relaci. Spearman je metrika korelace pořadí pořadí, což znamená, že změny predikovaných nebo skutečných hodnot nezmění výsledek Spearman, pokud nezmění pořadí předpovídané nebo skutečné hodnoty. Cíl: Čím blíž k 1, tím lépe Rozsah: [-1, 1] |
Výpočet |
Normalizace metrik
Automatizované strojové učení normalizuje regresi a prognózování metrik, které umožňují porovnání modelů natrénovaných na datech s různými rozsahy. Model natrénovaný na datech s větším rozsahem má vyšší chybu než stejný model natrénovaný na datech s menším rozsahem, pokud tato chyba není normalizována.
I když neexistuje žádná standardní metoda normalizace metrik chyb, automatizované strojové učení používá běžný přístup k rozdělení chyby rozsahem dat: normalized_error = error / (y_max - y_min)
Poznámka:
Rozsah dat se neuloží s modelem. Pokud odvozujete stejný model se stejným modelem v testovací sadě y_min blokování a y_max může se změnit podle testovacích dat a normalizované metriky nemusí být přímo použity k porovnání výkonu modelu u trénovacích a testovacích sad. Hodnotu trénovací y_max sady a hodnotu y_min můžete předat, aby bylo porovnání spravedlivé.
Metriky prognózy: normalizace a agregace
Výpočet metrik pro prognózování vyhodnocení modelu vyžaduje určité zvláštní aspekty, pokud data obsahují více časových řad. Existují dvě přirozené volby agregace metrik ve více řadách:
- Průměr makra , ve kterém jsou metriky vyhodnocení z každé řady dány stejné váze,
- Mikroprůměr, kde metriky vyhodnocení pro každou předpověď mají stejnou váhu.
Tyto případy mají přímé analogie k makrům a mikro průměrům v klasifikaci s více třídami.
Při výběru primární metriky pro výběr modelu může být důležité rozlišovat mezi makrem a mikroprůměrováním. Představte si například scénář maloobchodního prodeje, ve kterém chcete předpovídat poptávku po výběru spotřebitelských produktů. Některé produkty prodávají mnohem vyšší objemy než jiné. Pokud jako primární metriku zvolíte mikroprůměrovanou službu RMSE, je možné, že položky s velkým objemem přispívají většinou chyby modelování a následně dominují metrikě. Algoritmus výběru modelu pak může upřednostňování modelů s vyšší přesností u položek s velkým objemem než u objemových položek. Naproti tomu normalizovaná služba RMSE s průměrem maker poskytuje položky s nízkým objemem přibližně stejnou váhu pro položky s velkým objemem.
Následující tabulka ukazuje, které metriky prognózy AutoML používají makro vs. mikro průměrování:
| Průměr makra | Mikroprůměrované |
|---|---|
normalized_mean_absolute_error, normalized_median_absolute_error, normalized_root_mean_squared_error, normalized_root_mean_squared_log_error |
mean_absolute_error, median_absolute_error, root_mean_squared_error, root_mean_squared_log_error, r2_score, explained_variance, spearman_correlation, mean_absolute_percentage_error |
Všimněte si, že metriky s průměrem maker normalizují jednotlivé řady samostatně. Normalizované metriky z každé řady se pak zprůměrují, aby získaly konečný výsledek. Správná volba makra vs. mikro závisí na obchodním scénáři, ale obecně doporučujeme používat normalized_root_mean_squared_error.
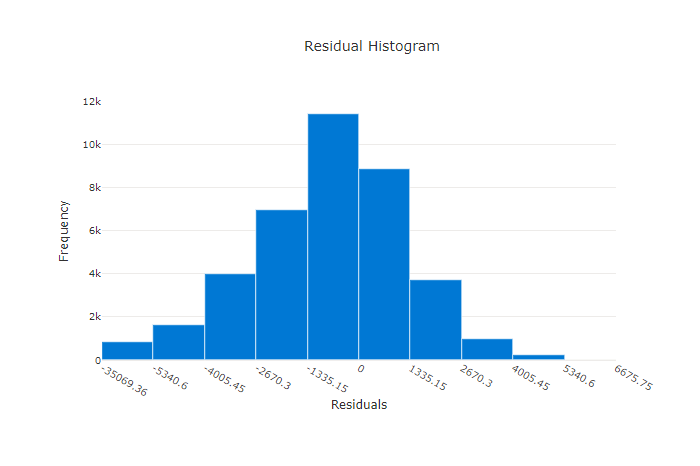
Rezidua
Graf reziduí je histogram predikčních chyb (reziduí) vygenerovaných pro regresi a prognózování experimentů. Rezidua se počítají jako y_predicted - y_true pro všechny vzorky a pak se zobrazí jako histogram, aby se zobrazila odchylka modelu.
V tomto příkladu si všimněte, že oba modely jsou mírně zkreslené, aby předpovídaly nižší než skutečná hodnota. To není neobvyklé u datové sady s nerovnoměrnou distribucí skutečných cílů, ale značí horší výkon modelu. Dobrý model bude mít rozdělení reziduí, které se zvýší na nulu s několika reziduími na extrémních úrovních. Horší model bude mít rozprostřenou distribuci reziduí s menším počtem vzorků kolem nuly.
Graf reziduí pro dobrý model
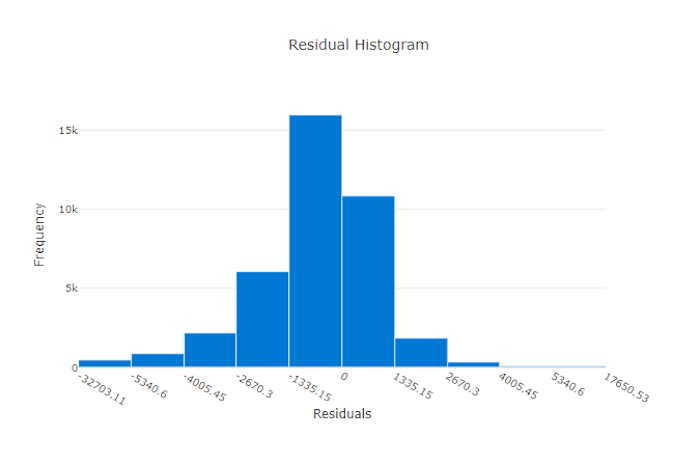
Graf reziduí pro chybný model
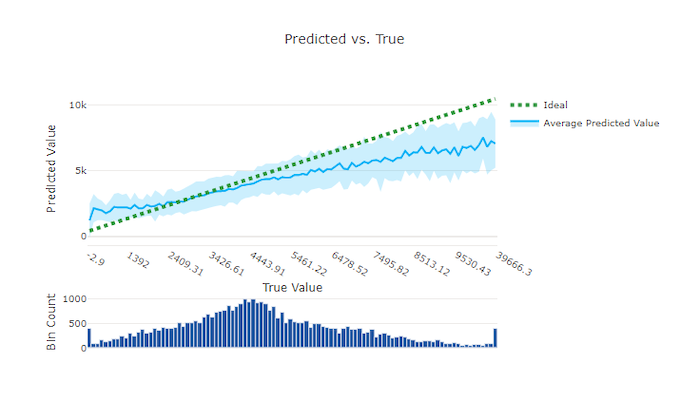
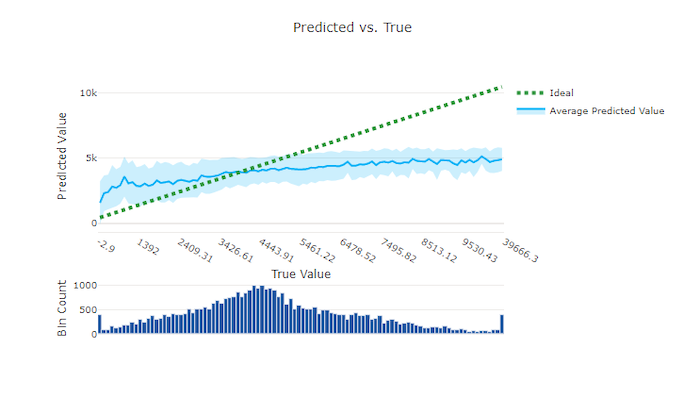
Predikované a skutečné hodnoty
Pokud chcete regresi a prognózování experimentovat s predikovanými a skutečnými hodnotami, vykreslí skutečný graf vztah mezi cílovou funkcí (pravda/skutečné hodnoty) a predikcemi modelu. Skutečné hodnoty jsou v intervalu podél osy x a pro každou přihrádku se střední předpovídaná hodnota vykreslí s chybovými úsečky. To vám umožní zjistit, jestli je model zkreslený směrem k předpovídání určitých hodnot. Čára zobrazuje průměrnou předpověď a vystínovanou oblast označuje odchylku předpovědí kolem tohoto průměru.
Nejčastější pravdivá hodnota bude mít často nejpřesnější předpovědi s nejnižší odchylkou. Vzdálenost spojnice trendu od ideální y = x čáry, kde existuje několik skutečných hodnot, je dobrým měřítkem výkonu modelu u odlehlých hodnot. Histogram v dolní části grafu můžete použít k odůvodnění skutečné distribuce dat. Zahrnutím dalších vzorků dat, ve kterých je distribuce zhuštěná, může zvýšit výkon modelu u nezobrazených dat.
V tomto příkladu si všimněte, že lepší model má předpovězenou a skutečnou čáru, která je blíže ideální y = x přímce.
Předpovězené a skutečné grafy pro dobrý model
Predikovaný a pravdivý graf pro chybný model
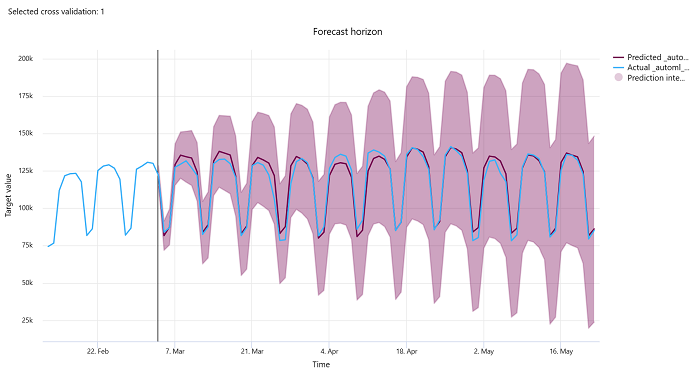
Horizont prognózy
V případě předpovědí experimentů graf horizont prognózy vykreslí vztah mezi předpovídaná hodnota modelů a skutečnými hodnotami namapovanými v průběhu času na překládání křížového ověření, a to až do 5 složených hodnot. Čas osy x mapuje podle frekvence, kterou jste zadali během nastavení trénování. Svislá čára v grafu označuje bod horizontu prognózy označovaný také jako vodorovná čára, což je časové období, ve kterém chcete začít generovat předpovědi. Nalevo od čáry horizontu prognózy můžete zobrazit historická trénovací data, abyste lépe vizualizovali minulé trendy. Napravo od horizontu prognózy můžete vizualizovat předpovědi (fialová čára) proti skutečným hodnotám (modrá čára) pro různé křížové překládání a identifikátory časových řad. Stínovaná fialová oblast označuje intervaly spolehlivosti nebo odchylku předpovědí kolem tohoto průměru.
Kliknutím na ikonu upravit tužku v pravém horním rohu grafu můžete zvolit, které kombinace identifikátorů časových řad a které se mají zobrazit. Vyberte z prvních 5 křížových ověření a až 20 různých identifikátorů časových řad, abyste mohli vizualizovat graf pro různé časové řady.
Důležité
Tento graf je k dispozici v trénovacím spuštění pro modely generované z trénovacích a ověřovacích dat a také v testovacím běhu na základě trénovacích dat a testovacích dat. Umožňujeme až 20 datových bodů před a až 80 datových bodů po původu prognózy. U modelů DNN tento graf v trénovacím běhu zobrazuje data z poslední epochy, tj. po úplném natrénování modelu. Tento graf v testovacím běhu může mít mezeru před horizontovou čárou, pokud byla během trénovacího běhu explicitně poskytována ověřovací data. Důvodem je to, že trénovací data a testovací data se použijí v testovacím běhu a vynechá se ověřovací data, která mají za následek mezeru.
Metriky pro modely obrázků (Preview)
Automatizované strojové učení používá obrázky z ověřovací datové sady k vyhodnocení výkonu modelu. Výkon modelu se měří na epochové úrovni , abyste pochopili, jak trénování postupuje. Epocha uplynula, když se celá datová sada předává dopředu a dozadu přes neurální síť přesně jednou.
Metriky klasifikace obrázků
Primární metrika pro vyhodnocení je přesnost pro binární a vícetřídové klasifikační modely a IoU (průnik nad Sjednocení) pro klasifikační modely s více popisky. Metriky klasifikace pro modely klasifikace obrázků jsou stejné jako metriky definované v části metrik klasifikace. Zaprotokolují se také hodnoty ztráty spojené s epochou, které můžou pomoct monitorovat průběh trénování a určit, jestli je model přezpracovaný nebo nedosažený.
Každá předpověď z klasifikačního modelu je přidružená ke skóre spolehlivosti, které označuje úroveň spolehlivosti, se kterou byla predikce provedena. Modely klasifikace obrázků s víceznačky se ve výchozím nastavení vyhodnocují s prahovou hodnotou skóre 0,5, což znamená, že se jako pozitivní předpověď pro přidruženou třídu považují pouze předpovědi s alespoň touto úrovní spolehlivosti. Klasifikace s více třídami nepoužívá prahovou hodnotu skóre, ale třída s maximálním skóre spolehlivosti se považuje za predikci.
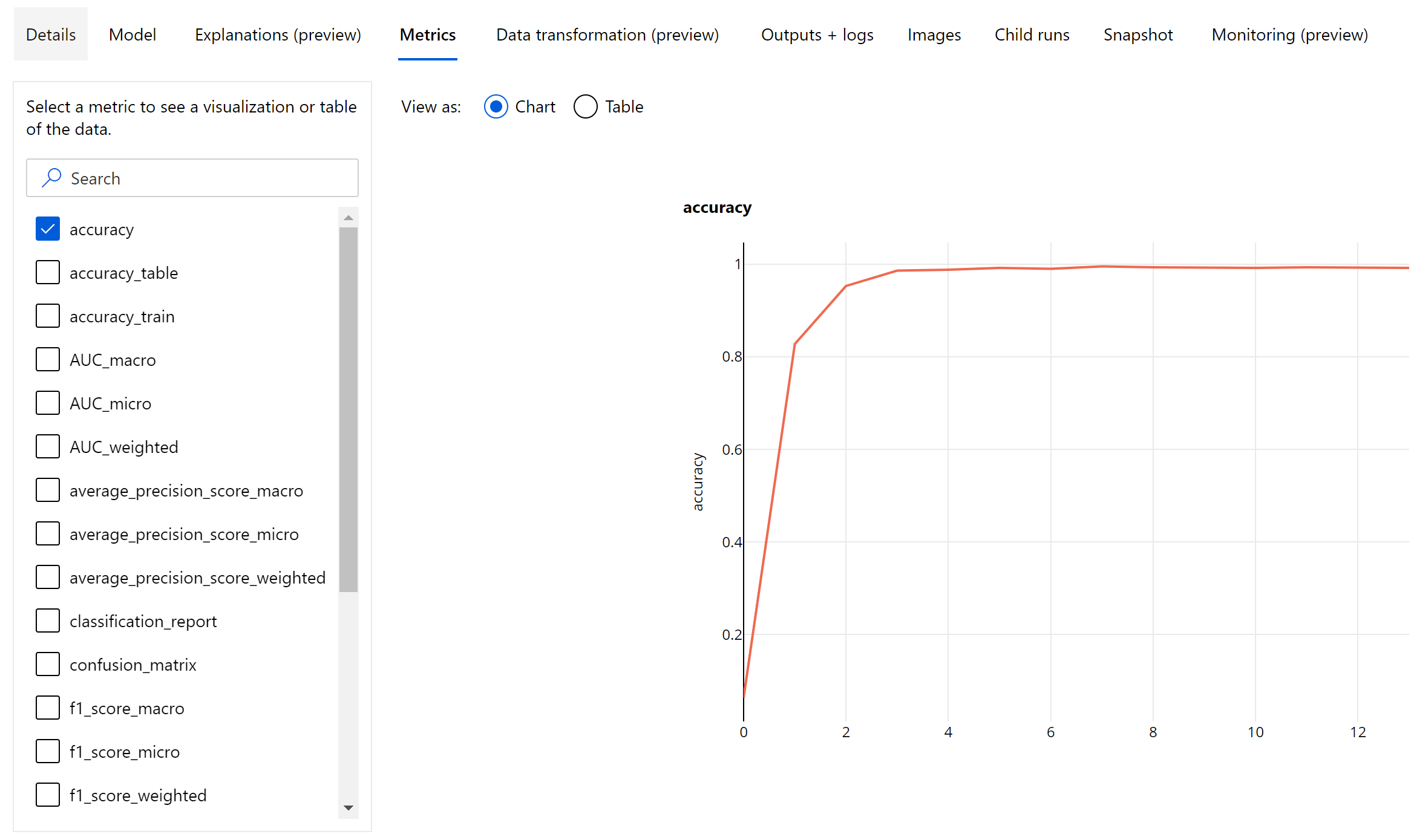
Metriky na úrovni epochy pro klasifikaci obrázků
Na rozdíl od metrik klasifikace tabulkových datových sad modely klasifikace obrázků protokolují všechny metriky klasifikace na epochové úrovni, jak je znázorněno níže.
Souhrnné metriky pro klasifikaci obrázků
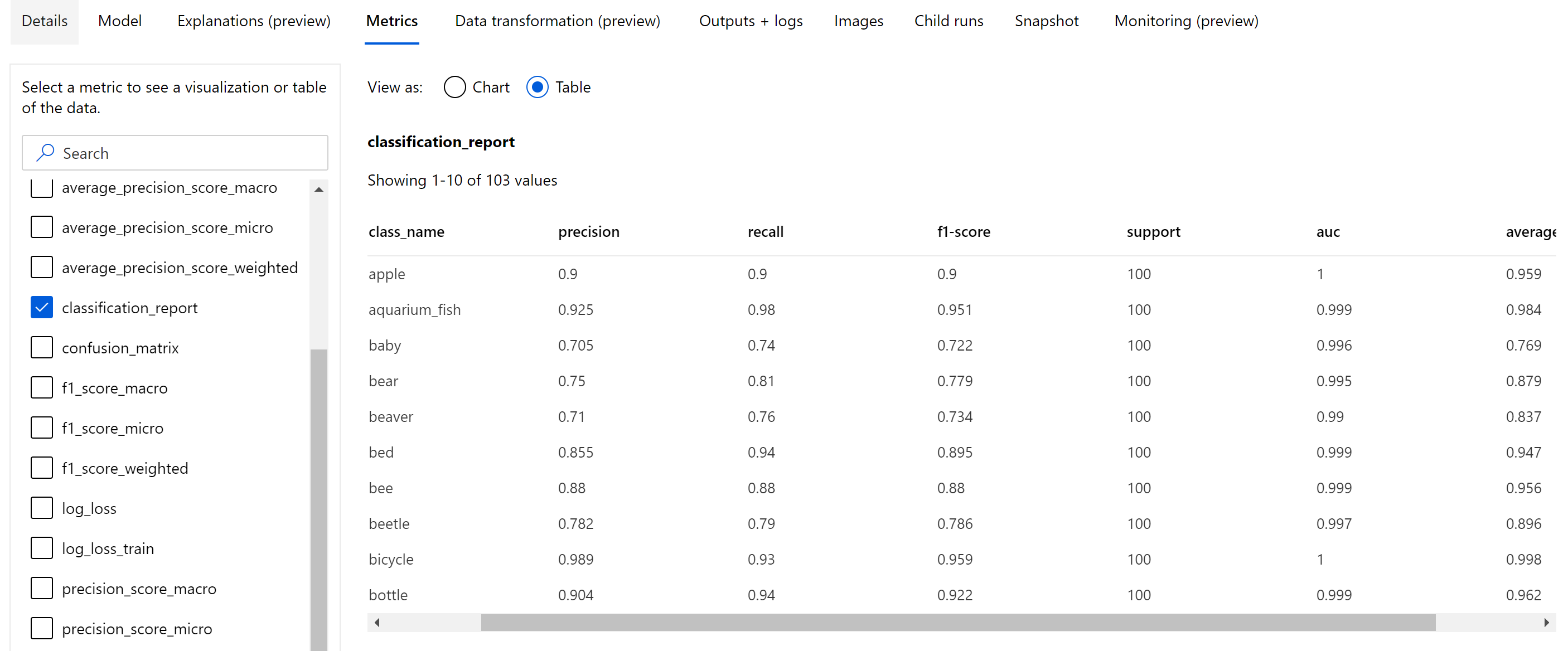
Kromě skalárních metrik, které jsou protokolovány na epochové úrovni, model klasifikace obrázků také protokoluje souhrnné metriky, jako jsou konfuzní matice, klasifikační grafy včetně křivky ROC, křivky přesnosti a sestavy klasifikace modelu z nejlepší epochy, při které získáme nejvyšší primární metriku (přesnost).
Sestava klasifikace poskytuje hodnoty na úrovni třídy pro metriky, jako je přesnost, úplnost, f1 skóre, podpora, auc a average_precision s různou úrovní průměrování – mikro, makro a vážené, jak je znázorněno níže. Projděte si definice metrik v části metrik klasifikace.
Metriky detekce objektů a segmentace instancí
Každá předpověď z modelu rozpoznávání objektů obrázku nebo modelu segmentace instancí je přidružena ke skóre spolehlivosti.
Předpovědi s skóre spolehlivosti vyšší než prahová hodnota skóre jsou výstupem jako předpovědi a používají se při výpočtu metriky, výchozí hodnota, která je specifická pro model a lze ji odkazovat ze stránky ladění hyperparametrů (box_score_threshold hyperparametr).
Výpočet metriky rozpoznávání objektů obrázku a modelu segmentace instancí je založený na měření překrytí definované metrikou s názvem IoU (průnik nad sjednocením), která se vypočítá rozdělením oblasti překrytí mezi zem-pravdou a předpověďmi podle oblasti sjednocení základní pravdy a předpovědí. IoU vypočítané z každé předpovědi se porovnává s prahovou hodnotou překrývání označovanou jako prahová hodnota IoU, která určuje, kolik predikce by se mělo překrývat s uživatelem anotovanou základní pravdou, aby bylo možné ji považovat za pozitivní predikci. Pokud je IoU vypočítaná z predikce menší než prahová hodnota překrytí, nebude predikce považována za kladnou předpověď pro přidruženou třídu.
Primární metrikou pro vyhodnocení modelů rozpoznávání objektů obrázků a segmentace instancí je průměrná průměrná přesnost (mAP). MAP je průměrná hodnota průměrné přesnosti (AP) ve všech třídách. Modely automatizovaného rozpoznávání objektů ML podporují výpočet mAP pomocí následujících dvou oblíbených metod.
Metriky Pascal VOC:
Pascal VOC mAP je výchozí způsob výpočtu mAP pro modely rozpoznávání objektů nebo segmentace instancí. Metoda mAP ve stylu Pascal VOC vypočítá oblast pod verzí křivky přesnosti a úplnosti. První p(ri), což je přesnost při úplnosti i je vypočítán pro všechny jedinečné hodnoty úplnosti. p(ri) se pak nahradí maximální přesností získanou pro všechny úplnosti r' >= ri. Hodnota přesnosti se v této verzi křivky monotonicky snižuje. Metrika Pascal VOC mAP se ve výchozím nastavení vyhodnocuje prahovou hodnotou IoU 0,5. Podrobné vysvětlení tohoto konceptu je k dispozici v tomto blogu.
Metriky COCO:
Metoda vyhodnocení COCO používá interpolovanou metodu 101 bodů pro výpočet AP spolu s průměrem nad deseti prahovými hodnotami IoU. AP@[.5:.95] odpovídá průměrnému AP pro IoU od 0,5 do 0,95 s velikostí kroku 0,05. Automatizované strojové učení protokoluje všech dvanáct metrik definovaných metodou COCO, včetně AP a AR (průměrné úplnosti) v různých škálách v protokolech aplikace, zatímco uživatelské rozhraní metrik zobrazuje pouze mAP na prahové hodnotě IoU 0,5.
Tip
Vyhodnocení modelu rozpoznávání objektů obrázku může použít metriky coco, pokud validation_metric_type je hyperparametr nastavený na "coco", jak je vysvětleno v části ladění hyperparametrů.
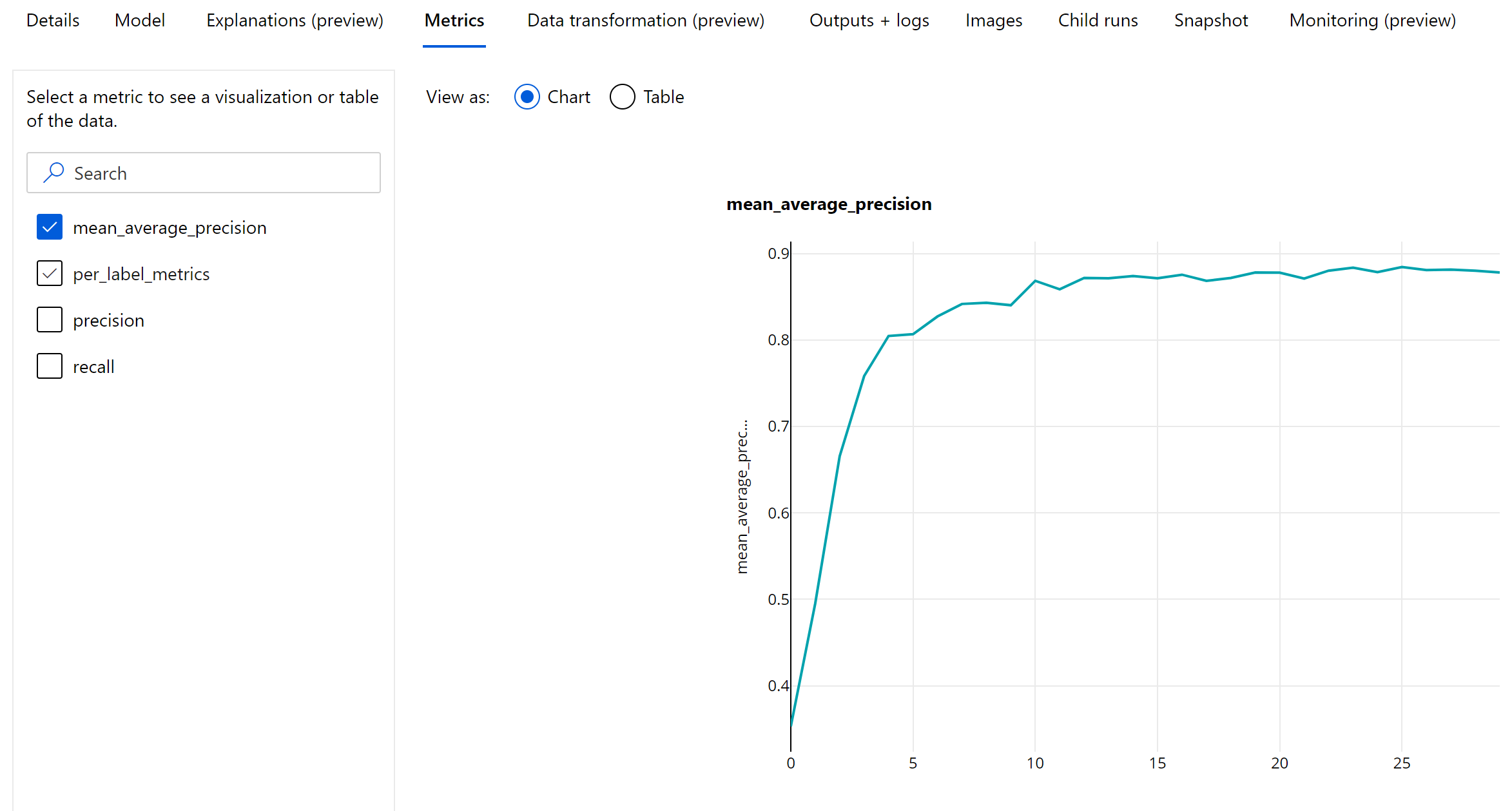
Metriky na úrovni epochy pro detekci objektů a segmentaci instancí
Hodnoty mAP, přesnosti a úplnosti se protokolují na epochové úrovni pro modely segmentace objektů obrázků nebo instancí. Metriky mAP, přesnosti a úplnosti se také protokolují na úrovni třídy s názvem "per_label_metrics". Per_label_metrics by se měla zobrazit jako tabulka.
Poznámka:
Metriky epochové úrovně pro přesnost, úplnost a per_label_metrics nejsou při použití metody coco k dispozici.
Zodpovědný řídicí panel AI pro nejvhodnější doporučený model AutoML (Preview)
Řídicí panel Azure Machine Učení Responsible AI poskytuje jedno rozhraní, které vám pomůže efektivně a efektivně implementovat zodpovědnou AI. Zodpovědný řídicí panel AI se podporuje jenom pomocí tabulkových dat a podporuje se jenom u klasifikačních a regresních modelů. Spojuje několik vyspělých nástrojů zodpovědné umělé inteligence v oblastech:
- Posouzení výkonu modelu a nestrannosti
- zkoumání dat
- Interpretovatelnost strojového učení
- Analýza chyb
I když jsou metriky a grafy vyhodnocení modelu vhodné pro měření obecné kvality modelu, operace, jako je kontrola nestrannosti modelu, zobrazení jeho vysvětlení (označované také jako to, které datové sady obsahuje model použitý k předpovědím), kontrola chyb a potenciálních slepých míst jsou nezbytné při cvičení zodpovědné umělé inteligence. Proto automatizované strojové učení poskytuje řídicí panel zodpovědné umělé inteligence, který vám pomůže sledovat různé přehledy modelu. Podívejte se, jak zobrazit řídicí panel Zodpovědné AI v studio Azure Machine Learning.
Podívejte se, jak můžete tento řídicí panel vygenerovat pomocí uživatelského rozhraní nebo sady SDK.
Vysvětlení modelů a důležitost funkcí
I když jsou metriky a grafy vyhodnocení modelu vhodné pro měření obecné kvality modelu, při kontrole toho, která datová sada obsahuje model, který model používá k předpovědím, je nezbytné při cvičení zodpovědné umělé inteligence. Proto automatizované strojové učení poskytuje řídicí panel s vysvětlením modelu, který měří a hlásí relativní příspěvky funkcí datové sady. Podívejte se, jak zobrazit řídicí panel vysvětlení v studio Azure Machine Learning.
Poznámka:
Interpretovatelnost, nejlepší vysvětlení modelu není k dispozici pro automatizované experimenty s prognózováním ML, které jako nejlepší model nebo soubor doporučují následující algoritmy:
- TCNForecaster
- Automatická archivace
- ExponentialSmoothing
- Prorok
- Průměr
- Naive
- Sezónní průměr
- Sezónní naive
Další kroky
- Vyzkoušejte ukázkové poznámkové bloky s vysvětlením modelu automatizovaného strojového učení.
- V případě konkrétních otázek automatizovaného strojového učení se spojte s askautomatedml@microsoft.com.