Sledování modelů ML pomocí MLflow a Azure Machine Learning
PLATÍ PRO: Python SDK azureml v1
Python SDK azureml v1
V tomto článku se dozvíte, jak povolit funkci MLflow Tracking pro připojení služby Azure Machine Learning jako back-end experimentů MLflow.
MLflow je opensourcová knihovna pro správu životního cyklu experimentů strojového učení. MLflow Tracking je komponenta MLflow, která protokoluje a sleduje metriky trénování a artefakty modelu, bez ohledu na prostředí experimentu – místně na vašem počítači, na vzdáleném cílovém výpočetním objektu, virtuálním počítači nebo clusteru Azure Databricks.
Všechny podporované funkce MLflow a Azure Machine Learning, včetně podpory projektu MLflow (Preview) a nasazení modelu, najdete v tématu MLflow a Azure Machine Learning .
Tip
Pokud chcete sledovat experimenty spuštěné v Azure Databricks nebo Azure Synapse Analytics, podívejte se na vyhrazené články Sledování experimentů Azure Databricks ML pomocí MLflow a Azure Machine Learning nebo sledování experimentů Azure Synapse Analytics ML pomocí MLflow a Azure Machine Learning.
Poznámka:
Informace v tomto dokumentu jsou primárně určené datovým vědcům a vývojářům, kteří chtějí monitorovat proces trénování modelu. Pokud máte zájem o monitorování využití prostředků a událostí ze služby Azure Machine Learning, jako jsou kvóty, dokončené trénovací úlohy nebo dokončená nasazení modelu, přečtěte si téma Monitorování služby Azure Machine Learning.
Požadavky
Nainstalujte balíček
mlflow.- Můžete použít MLflow Skinny , což je jednoduchý balíček MLflow bez sql storage, serveru, uživatelského rozhraní nebo závislostí datových věd. To se doporučuje pro uživatele, kteří primárně potřebují možnosti sledování a protokolování bez importu celé sady funkcí MLflow včetně nasazení.
Nainstalujte balíček
azureml-mlflow.Vytvořte pracovní prostor Azure Machine Learning.
Nainstalujte a nastavte Azure Machine Learning CLI (v1) a ujistěte se, že jste nainstalovali rozšíření ml.
Důležité
Některé příkazy Azure CLI v tomto článku používají
azure-cli-mlrozšíření (nebo v1) pro Azure Machine Learning. Podpora rozšíření v1 skončí 30. září 2025. Do tohoto data budete moct nainstalovat a používat rozšíření v1.Doporučujeme přejít na
mlrozšíření (nebo v2) před 30. zářím 2025. Další informace o rozšíření v2 najdete v tématu Rozšíření Azure ML CLI a Python SDK v2.Nainstalujte a nastavte sadu Azure Machine Learning SDK pro Python.
Sledování spuštění z místního počítače nebo vzdáleného výpočetního prostředí
Sledování pomocí MLflow se službou Azure Machine Learning umožňuje ukládat protokolované metriky a spuštění artefaktů, které se spustily na místním počítači, do pracovního prostoru Azure Machine Learning.
Nastavení prostředí pro sledování
Pokud chcete sledovat spuštění, které není spuštěné na výpočetních prostředcích služby Azure Machine Learning (odteď se označuje jako místní výpočetní prostředí), musíte místní výpočetní prostředky nasměrovat na identifikátor URI sledování MLflow služby Azure Machine Learning.
Poznámka:
Při spouštění ve službě Azure Compute (Poznámkové bloky Azure, Poznámkové bloky Jupyter hostované ve výpočetních instancích Nebo výpočetních clusterech Azure) nemusíte konfigurovat identifikátor URI pro sledování. Automaticky se nakonfiguruje za vás.
- Použití sady Azure Machine Learning SDK
- Použití proměnné prostředí
- Sestavení identifikátoru URI sledování MLflow
PLATÍ PRO: Python SDK azureml v1
Identifikátor URI pro sledování MLflow služby Azure Machine Learning můžete získat pomocí sady Azure Machine Learning SDK v1 pro Python. Ujistěte se, že máte v clusteru, který používáte, nainstalovanou knihovnu azureml-sdk . Následující ukázka získá jedinečný identifikátor URI sledování MLFLow přidružený k vašemu pracovnímu prostoru. Pak metoda set_tracking_uri() odkazuje identifikátor URI sledování MLflow na tento identifikátor URI.
Použití konfiguračního souboru pracovního prostoru:
from azureml.core import Workspace import mlflow ws = Workspace.from_config() mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())Tip
Konfigurační soubor pracovního prostoru si můžete stáhnout pomocí:
- Přejděte na studio Azure Machine Learning
- Klikněte na uper-right corner of the page -> Download config file.
- Uložte soubor
config.jsondo stejného adresáře, na kterém pracujete.
Pomocí ID předplatného, názvu skupiny prostředků a názvu pracovního prostoru:
from azureml.core import Workspace import mlflow #Enter details of your Azure Machine Learning workspace subscription_id = '<SUBSCRIPTION_ID>' resource_group = '<RESOURCE_GROUP>' workspace_name = '<AZUREML_WORKSPACE_NAME>' ws = Workspace.get(name=workspace_name, subscription_id=subscription_id, resource_group=resource_group) mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
Nastavení názvu experimentu
Všechna spuštění MLflow se protokolují do aktivního experimentu. Ve výchozím nastavení se spuštění protokolují do experimentu s názvem Default , který se automaticky vytvoří za vás. Ke konfiguraci experimentu, na který chcete pracovat, použijte příkaz mlflow.set_experiment()MLflow .
experiment_name = 'experiment_with_mlflow'
mlflow.set_experiment(experiment_name)
Tip
Při odesílání úloh pomocí sady Azure Machine Learning SDK můžete při odeslání nastavit název experimentu pomocí vlastnosti experiment_name . Nemusíte ho konfigurovat ve svém trénovacím skriptu.
Spuštění trénování
Po nastavení názvu experimentu MLflow můžete spustit trénovací spuštění pomocí start_run(). Pak použijte log_metric() k aktivaci rozhraní API pro protokolování MLflow a začněte protokolovat metriky trénovacího spuštění.
import os
from random import random
with mlflow.start_run() as mlflow_run:
mlflow.log_param("hello_param", "world")
mlflow.log_metric("hello_metric", random())
os.system(f"echo 'hello world' > helloworld.txt")
mlflow.log_artifact("helloworld.txt")
Podrobnosti o tom, jak protokolovat metriky, parametry a artefakty při spuštění pomocí zobrazení MLflow, jak protokolovat a zobrazit metriky.
Sledování spuštění spuštěných ve službě Azure Machine Learning
PLATÍ PRO: Python SDK azureml v1
Vzdálená spuštění (úlohy) umožňují trénovat modely robustnějším a opakujícím se způsobem. Můžou také využívat výkonnější výpočetní prostředky, jako jsou výpočetní clustery Machine Learning. Informace o různých možnostech výpočetních prostředků najdete v tématu Použití cílových výpočetních objektů pro trénování modelu.
Při odesílání spuštění azure Machine Learning automaticky nakonfiguruje MLflow tak, aby fungoval s pracovním prostorem, ve kterém běží spuštění. To znamená, že není nutné konfigurovat identifikátor URI sledování MLflow. Nad tím se experimenty automaticky pojmenují na základě podrobností odeslání experimentu.
Důležité
Při odesílání trénovacích úloh do služby Azure Machine Learning nemusíte konfigurovat identifikátor URI pro sledování MLflow, protože už je pro vás nakonfigurovaný. V rutině trénování nemusíte konfigurovat název experimentu.
Vytvoření rutiny trénování
Nejprve byste měli vytvořit src podadresář a vytvořit soubor s trénovacím kódem train.py v souboru v src podadresáři. Veškerý trénovací kód přejde do src podadresáře, včetně train.py.
Trénovací kód je převzat z tohoto příkladu MLflow v ukázkovém úložišti Služby Azure Machine Learning.
Zkopírujte tento kód do souboru:
# imports
import os
import mlflow
from random import random
# define functions
def main():
mlflow.log_param("hello_param", "world")
mlflow.log_metric("hello_metric", random())
os.system(f"echo 'hello world' > helloworld.txt")
mlflow.log_artifact("helloworld.txt")
# run functions
if __name__ == "__main__":
# run main function
main()
Konfigurace experimentu
K odeslání experimentu do služby Azure Machine Learning budete muset použít Python. V poznámkovém bloku nebo souboru Pythonu nakonfigurujte výpočetní a trénovací prostředí Environment s využitím třídy.
from azureml.core import Environment
from azureml.core.conda_dependencies import CondaDependencies
env = Environment(name="mlflow-env")
# Specify conda dependencies with scikit-learn and temporary pointers to mlflow extensions
cd = CondaDependencies.create(
conda_packages=["scikit-learn", "matplotlib"],
pip_packages=["azureml-mlflow", "pandas", "numpy"]
)
env.python.conda_dependencies = cd
Pak vytvořte ScriptRunConfig vzdálený výpočetní objekt jako cílový výpočetní objekt.
from azureml.core import ScriptRunConfig
src = ScriptRunConfig(source_directory="src",
script=training_script,
compute_target="<COMPUTE_NAME>",
environment=env)
Pomocí této konfigurace výpočetního a trénovacího spuštění použijte Experiment.submit() metodu k odeslání spuštění. Tato metoda automaticky nastaví identifikátor URI sledování MLflow a směruje protokolování z MLflow do vašeho pracovního prostoru.
from azureml.core import Experiment
from azureml.core import Workspace
ws = Workspace.from_config()
experiment_name = "experiment_with_mlflow"
exp = Experiment(workspace=ws, name=experiment_name)
run = exp.submit(src)
Zobrazení metrik a artefaktů v pracovním prostoru
Metriky a artefakty z protokolování MLflow se sledují ve vašem pracovním prostoru. Pokud je chcete kdykoli zobrazit, přejděte do svého pracovního prostoru a vyhledejte experiment podle názvu v pracovním prostoru v studio Azure Machine Learning. Nebo spusťte následující kód.
Načtěte metriku spuštění pomocí MLflow get_run().
from mlflow.tracking import MlflowClient
# Use MlFlow to retrieve the run that was just completed
client = MlflowClient()
run_id = mlflow_run.info.run_id
finished_mlflow_run = MlflowClient().get_run(run_id)
metrics = finished_mlflow_run.data.metrics
tags = finished_mlflow_run.data.tags
params = finished_mlflow_run.data.params
print(metrics,tags,params)
Pokud chcete zobrazit artefakty spuštění, můžete použít MlFlowClient.list_artifacts().
client.list_artifacts(run_id)
Pokud chcete stáhnout artefakt do aktuálního adresáře, můžete použít MLFlowClient.download_artifacts().
client.download_artifacts(run_id, "helloworld.txt", ".")
Další podrobnosti o načtení informací z experimentů a spuštění ve službě Azure Machine Learning pomocí zobrazení MLflow umožňuje spravovat experimenty a spouštět s MLflow.
Porovnání a dotazování
Porovnejte a dotazujte se na všechna spuštění MLflow v pracovním prostoru Služby Azure Machine Learning s následujícím kódem. Přečtěte si další informace o dotazování spuštění pomocí MLflow.
from mlflow.entities import ViewType
all_experiments = [exp.experiment_id for exp in MlflowClient().list_experiments()]
query = "metrics.hello_metric > 0"
runs = mlflow.search_runs(experiment_ids=all_experiments, filter_string=query, run_view_type=ViewType.ALL)
runs.head(10)
Automatické protokolování
Díky Azure Machine Learning a MLFlow můžou uživatelé protokolovat metriky, parametry modelu a artefakty modelu automaticky při trénování modelu. Podporují se různé oblíbené knihovny strojového učení.
Pokud chcete povolit automatické protokolování , vložte před trénovací kód následující kód:
mlflow.autolog()
Přečtěte si další informace o automatickém protokolování pomocí MLflow.
Správa modelů
Zaregistrujte a sledujte modely pomocí registru modelů Azure Machine Learning, který podporuje registr modelů MLflow. Modely Azure Machine Learning jsou v souladu se schématem modelu MLflow, což usnadňuje export a import těchto modelů napříč různými pracovními postupy. Metadata související s MLflow, jako je ID spuštění, se také sledují s registrovaným modelem pro sledovatelnost. Uživatelé můžou odesílat trénovací běhy, registrovat a nasazovat modely vytvořené z běhů MLflow.
Pokud chcete nasadit a zaregistrovat model připravený pro produkční prostředí v jednom kroku, přečtěte si téma Nasazení a registrace modelů MLflow.
K registraci a zobrazení modelu ze spuštění použijte následující kroky:
Po dokončení spuštění zavolejte metodu
register_model().# the model folder produced from a run is registered. This includes the MLmodel file, model.pkl and the conda.yaml. model_path = "model" model_uri = 'runs:/{}/{}'.format(run_id, model_path) mlflow.register_model(model_uri,"registered_model_name")Zobrazte zaregistrovaný model v pracovním prostoru pomocí studio Azure Machine Learning.
V následujícím příkladu zaregistrovaný model
my-modelobsahuje metadata sledování MLflow označená.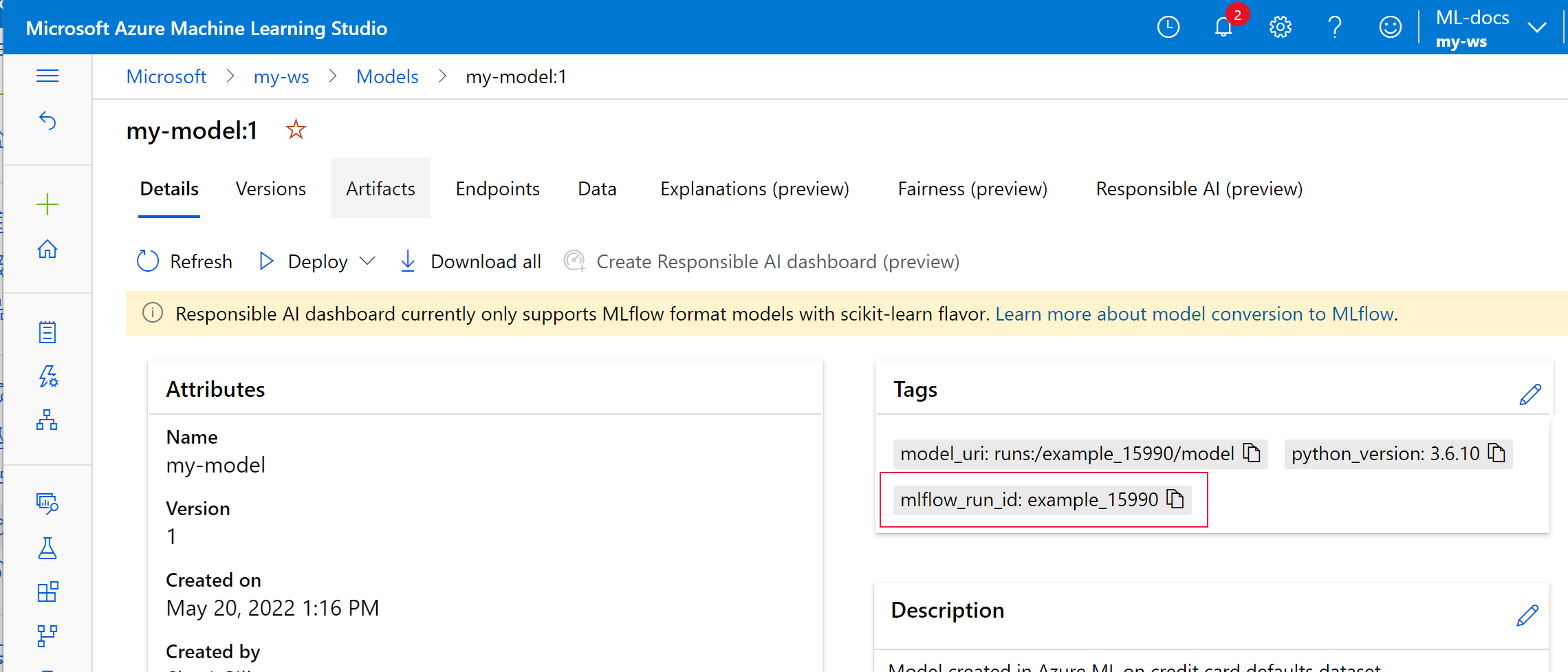
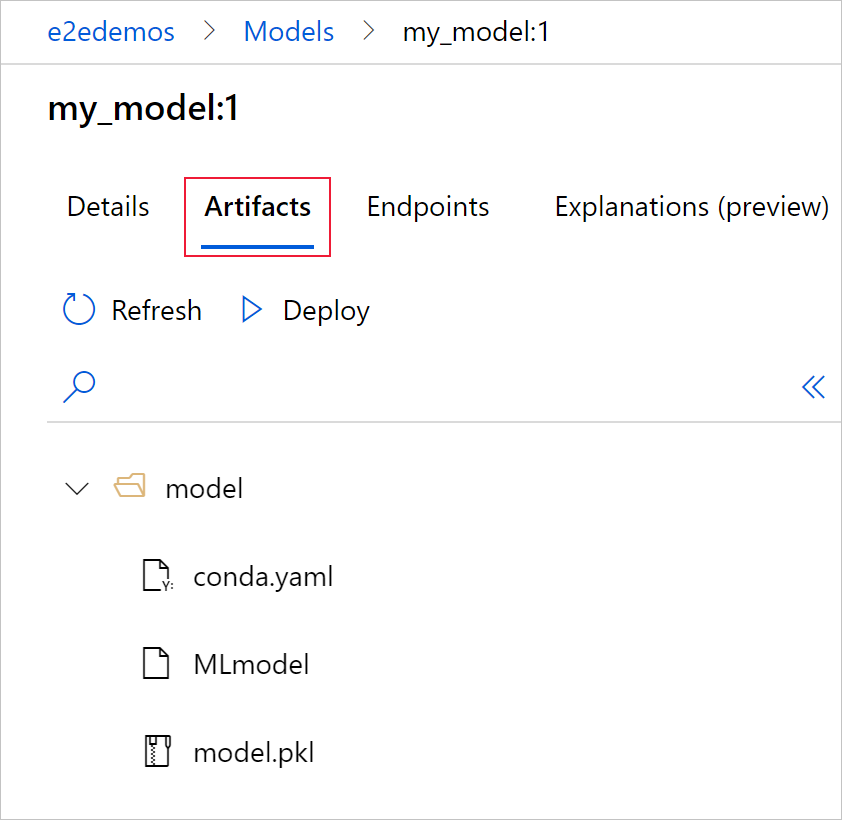
Výběrem karty Artefakty zobrazíte všechny soubory modelu, které odpovídají schématu modelu MLflow (conda.yaml, MLmodel, model.pkl).
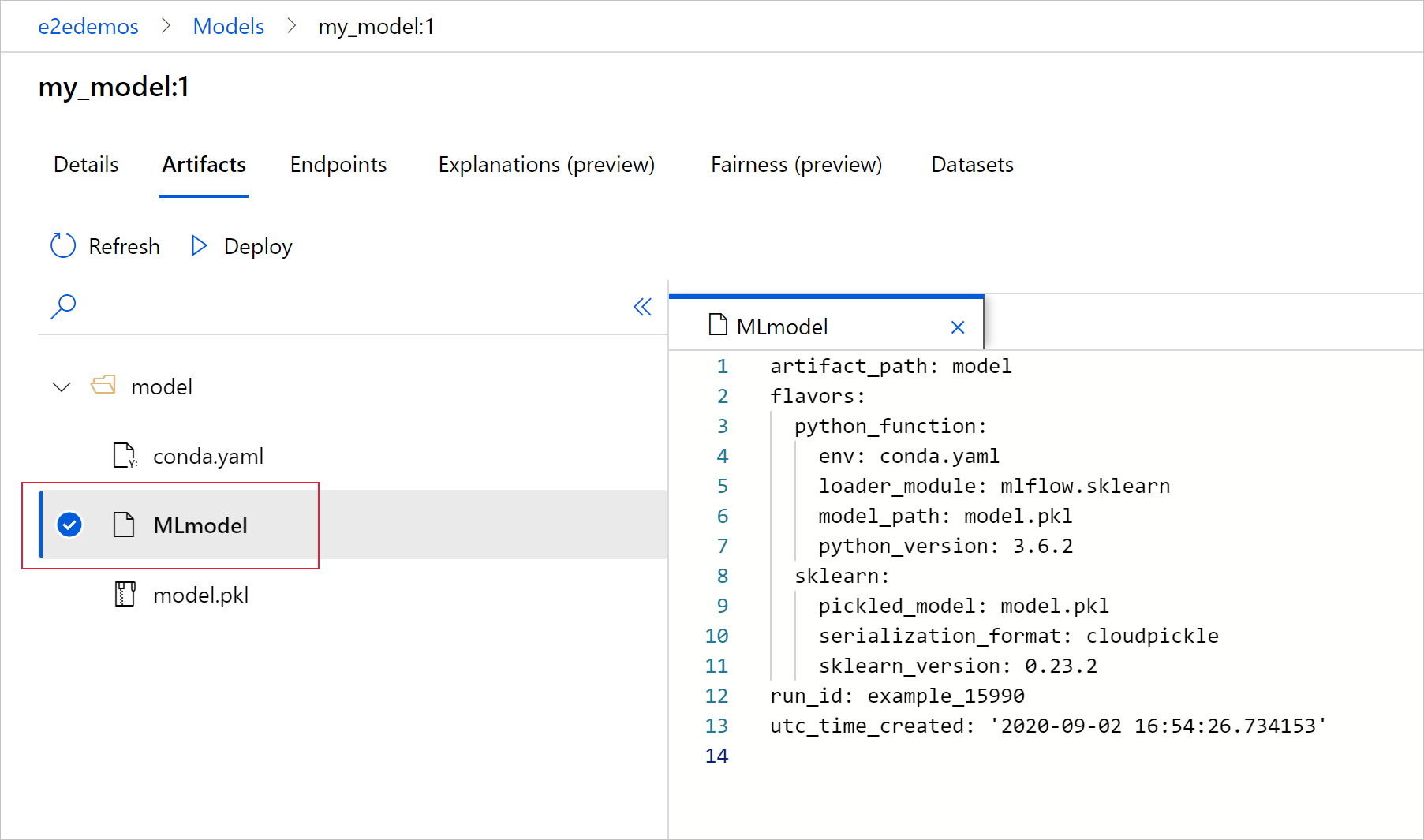
Výběrem MLmodel zobrazíte soubor MLmodel vygenerovaný spuštěním.
Vyčištění prostředků
Pokud nemáte v úmyslu používat protokolované metriky a artefakty ve vašem pracovním prostoru, možnost je odstranit jednotlivě, momentálně není dostupná. Místo toho odstraňte skupinu prostředků, která obsahuje účet úložiště a pracovní prostor, takže vám nebudou účtovány žádné poplatky:
Úplně nalevo na webu Azure Portal vyberte Skupiny prostředků.
V seznamu vyberte skupinu prostředků, kterou jste vytvořili.
Vyberte Odstranit skupinu prostředků.
Zadejte název skupiny prostředků. Poté vyberte Odstranit.
Příklady poznámkových bloků
MLflow s poznámkovými bloky Azure Machine Learning ukazuje a rozšiřuje koncepty uvedené v tomto článku. Podívejte se také na úložiště řízené komunitou, příklady AzureML.< a1/>.
Další kroky
- Nasazení modelů pomocí MLflow
- Monitorujte produkční modely pro posun dat.
- Sledování spuštění Azure Databricks pomocí MLflow
- Spravujte své modely.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro