Ladění výzev pomocí variant
Vytvoření dobré výzvy je náročný úkol, který vyžaduje spoustu kreativity, srozumitelnosti a relevance. Dobrý příkaz může vyvolat požadovaný výstup z předem natrénovaného jazykového modelu, zatímco chybná výzva může vést k nepřesným, irelevantním nebo nesmyslným výstupům. Proto je nutné ladit výzvy k optimalizaci jejich výkonu a odolnosti pro různé úlohy a domény.
Proto představujeme koncept variant, které vám můžou pomoct otestovat chování modelu za různých podmínek, jako jsou různé formulace, formátování, kontext, teplota nebo top-k, porovnat a najít nejlepší výzvu a konfiguraci, která maximalizuje přesnost, rozmanitost nebo soudržnost modelu.
V tomto článku vám ukážeme, jak pomocí variant ladit výzvy a vyhodnotit výkon různých variant.
Požadavky
Než si přečtete tento článek, je lepší si projít:
Jak ladit výzvy pomocí variant?
V tomto článku jako příklad použijeme ukázkový tok klasifikace webu.
Otevřete ukázkový tok a odeberte uzel prepare_examples jako začátek.
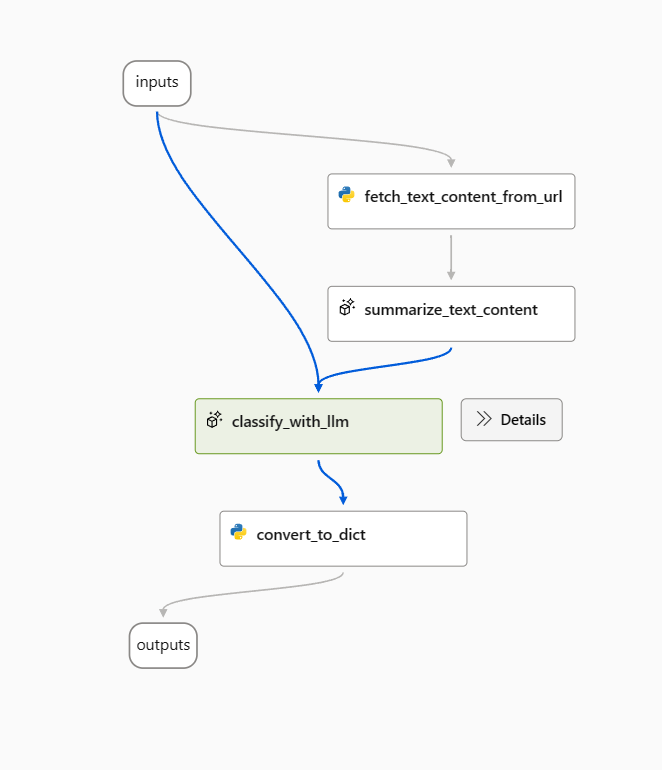
Jako základní výzvu v uzlu classify_with_llm použijte následující výzvu.

Your task is to classify a given url into one of the following types:
Movie, App, Academic, Channel, Profile, PDF or None based on the text content information.
The classification will be based on the url, the webpage text content summary, or both.
For a given URL : {{url}}, and text content: {{text_content}}.
Classify above url to complete the category and indicate evidence.
The output shoule be in this format: {"category": "App", "evidence": "Both"}
OUTPUT:
Pro optimalizaci tohoto toku může existovat několik způsobů a následující jsou dva směry:
Pro classify_with_llm uzel: Naučil jsem se z komunity a novinek, že nižší teplota dává vyšší přesnost, ale méně kreativity a překvapení, takže nižší teplota je vhodná pro úkoly klasifikace a také několik snímků výzvy může zvýšit výkon LLM. Proto bych chtěl otestovat, jak se tok chová, když se teplota změní z 1 na 0, a když se zobrazí výzva s několika snímky příkladů.
Pro summarize_text_content uzel: Chci také otestovat chování toku při změně souhrnu z 100 slov na 300, aby se zjistilo, jestli může zvýšit výkon další textový obsah.
Vytváření variant
- Vyberte tlačítko Zobrazit varianty v pravém horním rohu uzlu LLM. Existující uzel LLM je variant_0 a je výchozí variantou.
- Výběrem tlačítka Klonovat na variant_0 vygenerujte variant_1 a pak můžete nakonfigurovat parametry pro různé hodnoty nebo aktualizovat výzvu na variant_1.
- Opakováním kroku vytvořte další varianty.
- Pokud chcete přestat přidávat další varianty, vyberte Skrýt varianty. Všechny varianty jsou přeloženy. Výchozí varianta se zobrazí pro uzel.
Pro uzel classify_with_llm na základě variant_0:
- Vytvořte variant_1, kde se teplota změní z 1 na 0.
- Vytvořte variant_2, kde je teplota 0, a můžete použít následující výzvu včetně příkladů několika snímků.
Your task is to classify a given url into one of the following types:
Movie, App, Academic, Channel, Profile, PDF or None based on the text content information.
The classification will be based on the url, the webpage text content summary, or both.
Here are a few examples:
URL: https://play.google.com/store/apps/details?id=com.spotify.music
Text content: Spotify is a free music and podcast streaming app with millions of songs, albums, and original podcasts. It also offers audiobooks, so users can enjoy thousands of stories. It has a variety of features such as creating and sharing music playlists, discovering new music, and listening to popular and exclusive podcasts. It also has a Premium subscription option which allows users to download and listen offline, and access ad-free music. It is available on all devices and has a variety of genres and artists to choose from.
OUTPUT: {"category": "App", "evidence": "Both"}
URL: https://www.youtube.com/channel/UC_x5XG1OV2P6uZZ5FSM9Ttw
Text content: NFL Sunday Ticket is a service offered by Google LLC that allows users to watch NFL games on YouTube. It is available in 2023 and is subject to the terms and privacy policy of Google LLC. It is also subject to YouTube's terms of use and any applicable laws.
OUTPUT: {"category": "Channel", "evidence": "URL"}
URL: https://arxiv.org/abs/2303.04671
Text content: Visual ChatGPT is a system that enables users to interact with ChatGPT by sending and receiving not only languages but also images, providing complex visual questions or visual editing instructions, and providing feedback and asking for corrected results. It incorporates different Visual Foundation Models and is publicly available. Experiments show that Visual ChatGPT opens the door to investigating the visual roles of ChatGPT with the help of Visual Foundation Models.
OUTPUT: {"category": "Academic", "evidence": "Text content"}
URL: https://ab.politiaromana.ro/
Text content: There is no content available for this text.
OUTPUT: {"category": "None", "evidence": "None"}
For a given URL : {{url}}, and text content: {{text_content}}.
Classify above url to complete the category and indicate evidence.
OUTPUT:
Pro uzel summarize_text_content na základě variant_0 můžete vytvořit variant_1, kde 100 words se změní na 300 slova ve výzvě.
Tok teď vypadá následovně, 2 varianty pro summarize_text_content uzel a 3 pro classify_with_llm uzel.

Spuštění všech variant s jedním řádkem dat a kontrola výstupů
Abyste měli jistotu, že se všechny varianty můžou úspěšně spouštět a fungovat podle očekávání, můžete tok spustit s jedním řádkem dat, který se má otestovat.
Poznámka:
Pokaždé, když můžete vybrat pouze jeden uzel LLM s variantami, které se mají spustit, zatímco ostatní uzly LLM budou používat výchozí variantu.
V tomto příkladu nakonfigurujeme varianty pro uzel summarize_text_content i pro uzel classify_with_llm , takže musíte spustit dvakrát, abyste testovali všechny varianty.
- Vyberte tlačítko Spustit v pravém horním rohu.
- Vyberte uzel LLM s variantami. Ostatní uzly LLM budou používat výchozí variantu.
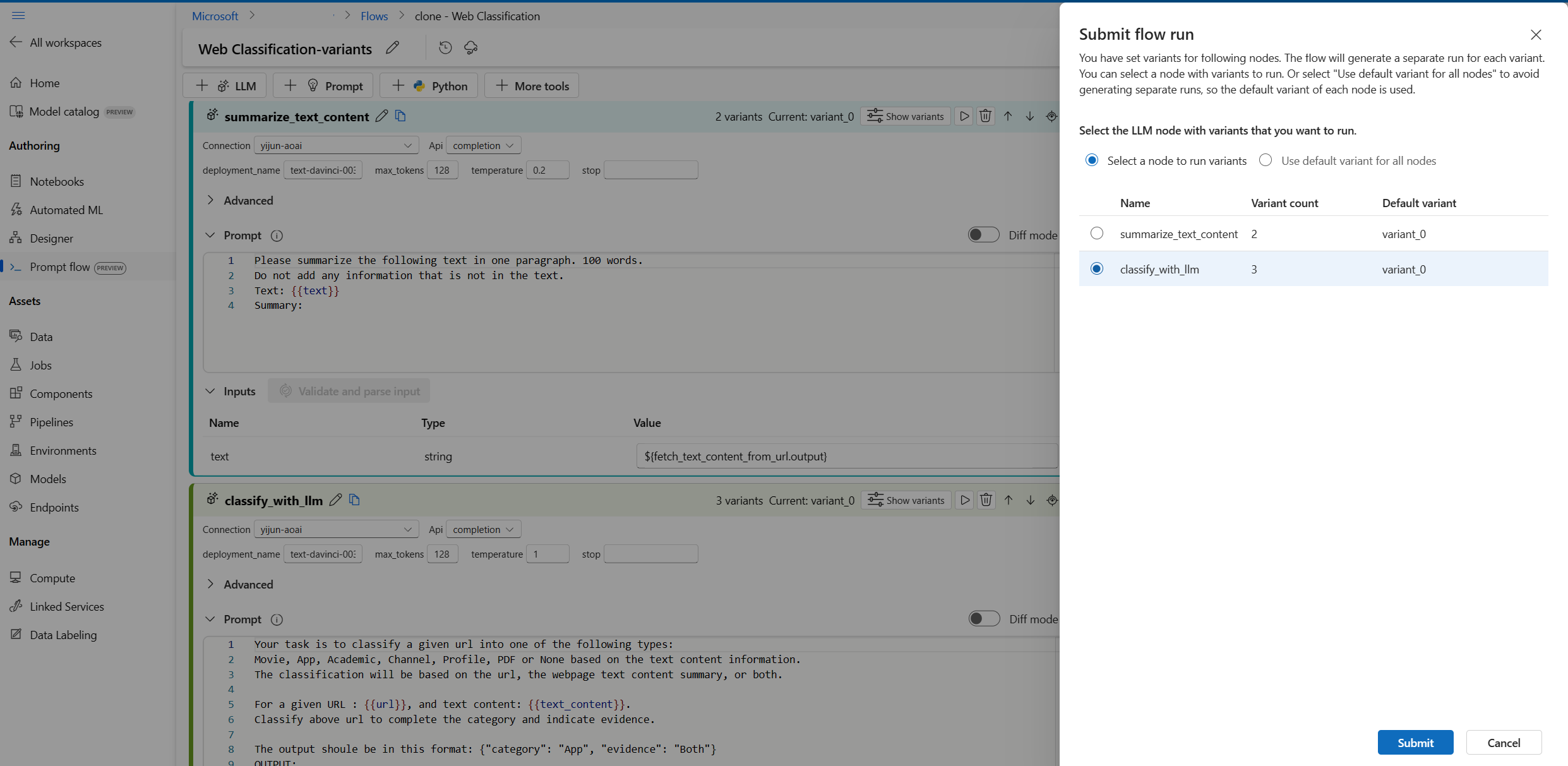
- Odešlete spuštění toku.
- Po dokončení spuštění toku můžete zkontrolovat odpovídající výsledek pro každou variantu.
- Odešlete další spuštění toku s druhým uzlem LLM s variantami a zkontrolujte výstupy.
- Můžete změnit další vstupní data (například použít adresu URL stránky Wikipedie) a opakováním výše uvedených kroků otestovat varianty pro různá data.

Vyhodnocení variant
Když spustíte varianty s několika jedními částmi dat a zkontrolujete výsledky pouhým okem, nemůže odrážet složitost a rozmanitost skutečných dat, zatímco výstup není měřitelný, takže je těžké porovnat efektivitu různých variant a pak zvolit to nejlepší.
Můžete odeslat dávkové spuštění, které vám umožní otestovat varianty s velkým množstvím dat a vyhodnotit je pomocí metrik, abyste našli to nejlepší.
Nejprve je potřeba připravit datovou sadu, která představuje dostatečný počet skutečných problémů, které chcete vyřešit pomocí toku výzvy. V tomto příkladu se jedná o seznam adres URL a jejich základní pravdu klasifikace. Přesnost použijeme k vyhodnocení výkonu variant.
V pravém horním rohu stránky vyberte Vyhodnotit .
Spustí se průvodce pro dávkové spuštění a vyhodnocení . Prvním krokem je vybrat uzel, který se má spustit ve všech jeho variantách.
Pokud chcete otestovat, jak dobře fungují různé varianty pro každý uzel v toku, musíte spustit dávkové spuštění pro každý uzel s variantami 1 po druhém. To vám pomůže vyhnout se vlivu variant jiných uzlů a zaměřit se na výsledky variant tohoto uzlu. To se řídí pravidlem řízeného experimentu, což znamená, že změníte vždy jen jednu věc a zachováte všechno ostatní stejné.
Můžete například vybrat classify_with_llm uzel ke spuštění všech variant. Uzel summarize_text_content použije výchozí variantu pro toto dávkové spuštění.
Dále v nastavení spuštění služby Batch můžete nastavit název dávkového spuštění, zvolit modul runtime a nahrát připravená data.
Dále v nastavení vyhodnocení vyberte metodu vyhodnocení.
Vzhledem k tomu, že je tento tok určen pro klasifikaci, můžete vybrat metodu hodnocení přesnosti klasifikace a vyhodnotit přesnost.
Přesnost se vypočítá porovnáním predikovaných popisků přiřazených tokem (predikce) se skutečnými popisky dat (základní pravdou) a počítáním, kolik z nich odpovídá.
V části Mapování vstupu vyhodnocení je potřeba zadat základní pravdu ze sloupce kategorie vstupní datové sady a předpověď pochází z jednoho z výstupů toku: kategorie.
Po kontrole všech nastavení můžete odeslat dávkové spuštění.
Po odeslání spuštění vyberte odkaz a přejděte na stránku podrobností spuštění.
Poznámka:
Dokončení spuštění může trvat několik minut.
Vizualizace výstupů
- Po dokončení dávkového spuštění a vyhodnocení na stránce podrobností spuštění vyberte vícenásobné spuštění dávky pro každou variantu a pak vyberte Vizualizovat výstupy. Zobrazí se metriky 3 variant pro classify_with_llm uzel a výstupy LLM predikované pro každý záznam dat.
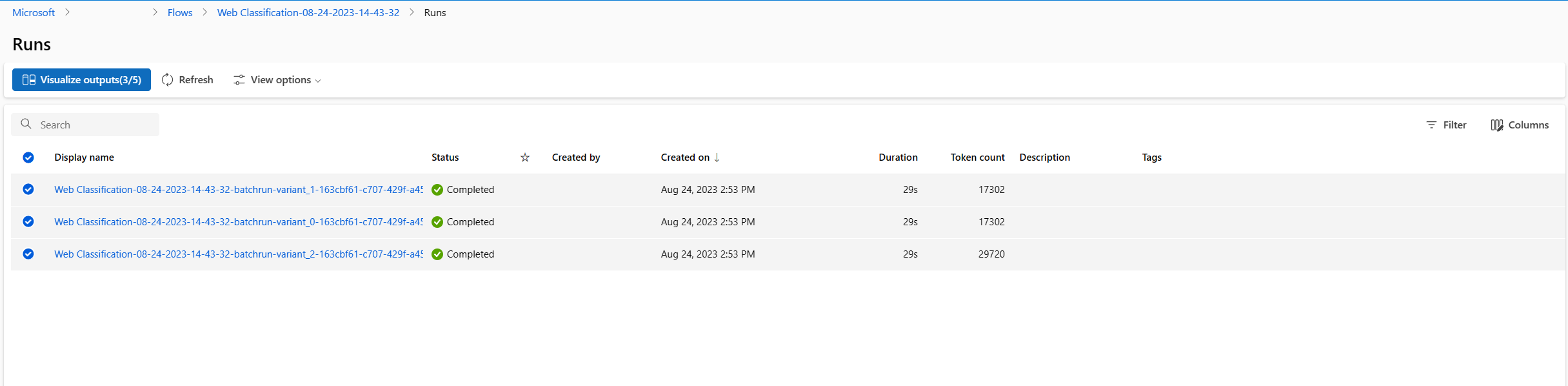
- Jakmile zjistíte, která varianta je nejlepší, můžete se vrátit na stránku vytváření toku a nastavit tuto variantu jako výchozí variantu uzlu.
- Výše uvedené kroky můžete zopakovat a vyhodnotit také varianty summarize_text_content uzlu.
Teď jste dokončili proces ladění výzev pomocí variant. Tuto techniku můžete použít na vlastní tok výzvy, abyste našli nejlepší variantu pro uzel LLM.