Příklady kanálů a datových sad pro návrháře služby Azure Machine Learning
Pomocí předdefinovaných příkladů v návrháři služby Azure Machine Learning můžete rychle začít vytvářet vlastní kanály strojového učení. Úložiště GitHubu návrháře služby Azure Machine Learning obsahuje podrobnou dokumentaci, která vám pomůže pochopit některé běžné scénáře strojového učení.
Požadavky
- Předplatné Azure. Pokud ještě předplatné Azure nemáte, vytvořte si bezplatný účet.
- Pracovní prostor Azure Machine Learning
Důležité
Pokud v tomto dokumentu nevidíte grafické prvky, jako jsou tlačítka v sadě studio nebo návrháři, možná nemáte správnou úroveň oprávnění k pracovnímu prostoru. Obraťte se na správce předplatného Azure a ověřte, že máte udělenou správnou úroveň přístupu. Další informace najdete v tématu Správa uživatelů a rolí.
Použití ukázkových kanálů
Návrhář uloží kopii ukázkových kanálů do pracovního prostoru studia. Kanál můžete upravit tak, aby se přizpůsobil vašim potřebám, a uložit ho jako vlastní. Použijte je jako výchozí bod, abyste mohli začít s projekty.
Tady je postup použití ukázky návrháře:
Přihlaste se k ml.azure.com a vyberte pracovní prostor, se kterým chcete pracovat.
Vyberte možnost Návrhář.
V části Nový kanál vyberte ukázkový kanál.
Vyberte Zobrazit další ukázky pro úplný seznam ukázek.
Pokud chcete spustit kanál, musíte nejprve nastavit výchozí cílový výpočetní objekt pro spuštění kanálu.
V podokně Nastavení napravo od plátna vyberte Vybrat cílový výpočetní objekt.
V zobrazeném dialogovém okně vyberte existující cílový výpočetní objekt nebo vytvořte nový. Zvolte Uložit.
Výběrem možnosti Odeslat v horní části plátna odešlete úlohu kanálu.
V závislosti na ukázkovém kanálu a nastavení výpočetních prostředků může dokončení úloh nějakou dobu trvat. Výchozí nastavení výpočetních prostředků má minimální velikost uzlu 0, což znamená, že návrhář musí po nečinnosti přidělit prostředky. Opakované úlohy kanálu budou trvat méně času, protože výpočetní prostředky jsou už přidělené. Kromě toho návrhář používá výsledky uložené v mezipaměti pro každou komponentu k dalšímu zlepšení efektivity.
Po dokončení spuštění kanálu můžete zkontrolovat kanál a zobrazit výstup pro každou komponentu, abyste se dozvěděli více. Výstupy komponent zobrazíte pomocí následujících kroků:
- Klikněte pravým tlačítkem myši na komponentu na plátně, jejíž výstup chcete zobrazit.
- Vyberte Vizualizovat.
Ukázky použijte jako výchozí body pro některé nejběžnější scénáře strojového učení.
Regrese
Prozkoumejte tyto předdefinované regresní ukázky.
| Ukázkový název | Popis |
|---|---|
| Regrese – Predikce cen automobilů (základní) | Predikce cen aut pomocí lineární regrese |
| Regrese – Predikce cen automobilů (Advanced) | Predikce cen aut pomocí rozhodovacího lesa a zesílených regresorů rozhodovacího stromu Porovnejte modely a najděte nejlepší algoritmus. |
Klasifikace
Prozkoumejte tyto předdefinované ukázky klasifikace. Další informace o ukázkách najdete otevřením ukázek a zobrazením komentářů ke komponentám v návrháři.
| Ukázkový název | Popis |
|---|---|
| Binární klasifikace s výběrem funkce – predikce příjmu | Pomocí rozhodovacího stromu se dvěma třídami můžete předpovědět příjem jako vysoký nebo nízký. Pomocí Pearsonové korelace vyberte funkce. |
| Binární klasifikace pomocí vlastního skriptu Pythonu – Predikce úvěrového rizika | Klasifikovat úvěrové aplikace jako vysoké nebo nízké riziko. Ke závažce dat použijte komponentu Spustit skript Pythonu. |
| Binární klasifikace – predikce vztahu zákazníka | Predikce četnosti změn zákazníků pomocí rozhodovacích stromů se dvěma třídami Pomocí funkce SMOTE můžete vzorkovat zkreslená data. |
| Klasifikace textu – Wikipedie SP 500 Dataset | Klasifikujte typy společnosti z článků Wikipedie s vícetřídovou logistickou regresí. |
| Vícetřídová klasifikace – Rozpoznávání písmen | Vytvořte soubor binárních klasifikátorů pro klasifikaci psaných písmen. |
Počítačové zpracování obrazu
Prozkoumejte tyto předdefinované ukázky počítačového zpracování obrazu. Další informace o ukázkách najdete otevřením ukázek a zobrazením komentářů ke komponentám v návrháři.
| Ukázkový název | Popis |
|---|---|
| Klasifikace obrázků s využitím DenseNet | Pomocí komponent počítačového zpracování obrazu můžete vytvářet model klasifikace obrázků na základě PyTorch DenseNet. |
Doporučovací systém
Prozkoumejte tyto předdefinované ukázky doporučovačů. Další informace o ukázkách najdete otevřením ukázek a zobrazením komentářů ke komponentám v návrháři.
| Ukázkový název | Popis |
|---|---|
| Širokoúhlé a hloubkové doporučení - Předpověď hodnocení restaurace | Vytvořte modul pro doporučování restaurace z funkcí a hodnocení pro restaurace a uživatele. |
| Doporučení – tweety hodnocení filmů | Vytvořte modul pro doporučování filmů z funkcí a hodnocení filmů/uživatelů. |
Nástroj
Přečtěte si další informace o ukázkách, které demonstrují nástroje a funkce strojového učení. Další informace o ukázkách najdete otevřením ukázek a zobrazením komentářů ke komponentám v návrháři.
| Ukázkový název | Popis |
|---|---|
| Binární klasifikace pomocí modelu Vowpal Wabbit – predikce příjmu pro dospělé | Vowpal Wabbit je systém strojového učení, který posouvá hranice strojového učení technikami, jako je online, hashování, areduce, snížení, učení2search, aktivní a interaktivní učení. Tato ukázka ukazuje, jak pomocí modelu Wabbit Vowpal sestavit binární klasifikační model. |
| Použití vlastního skriptu R – předpověď zpoždění letů | Pomocí přizpůsobeného skriptu R můžete předpovědět, jestli bude naplánovaný let cestujících zpožděn o více než 15 minut. |
| Křížové ověření pro binární klasifikaci – predikce příjmu pro dospělé | K vytvoření binárního klasifikátoru pro příjem dospělých použijte křížové ověření. |
| Důležitost funkce permutací | Důležitost funkce permutace slouží k výpočtu skóre důležitosti testovací datové sady. |
| Ladění parametrů pro binární klasifikaci – predikce příjmu pro dospělé | Pomocí hyperparametrů Tune Model vyhledejte optimální hyperparametry pro sestavení binárního klasifikátoru. |
Datové sady
Při vytváření nového kanálu v návrháři služby Azure Machine Learning se ve výchozím nastavení zahrne řada ukázkových datových sad. Tyto ukázkové datové sady používají ukázkové kanály na domovské stránce návrháře.
Ukázkové datové sady jsou k dispozici v kategorii Ukázky datových-sad. Najdete ho v paletě komponent vlevo od plátna v návrháři. Libovolnou z těchto datových sad můžete použít ve vlastním kanálu přetažením na plátno.
| Název datové sady | Popis datové sady |
|---|---|
| Datová sada pro sčítání lidu dospělých v binární klasifikaci příjmů | Podmnožina databáze sčítání lidu z roku 1994 využívající pracovní dospělé ve věku 16 let s upraveným indexem > příjmů 100. Použití: Klasifikovat lidi pomocí demografických údajů, abyste mohli předpovědět, jestli osoba získá více než 50 tisíc za rok. Související výzkum: Kohavi, R., Becker, B., (1996). Úložiště strojového učení UCI Irvine, CA: University of California, School of Information and Computer Science |
| Automobile price data (Raw) | Informace o automobilech podle značky a modelu, včetně ceny, funkcí, jako je počet válců a MPG, a také skóre rizika pojištění. Rizikové skóre je zpočátku spojeno s automatickou cenou. Následně se upraví pro skutečné riziko v procesu, který se označuje jako symboly. Hodnota +3 označuje, že auto je rizikové a hodnota -3, že je pravděpodobně bezpečná. Použití: Predikce skóre rizika podle funkcí pomocí regrese nebo vícevariátní klasifikace Související výzkum: Schlimmer, J.C. (1987). Úložiště strojového učení UCI Irvine, CA: University of California, School of Information and Computer Science. |
| Sdílené popisky appetency CRM | Popisky z výzvy predikce vztahů se zákazníky KDD Cup 2009 (orange_small_train_appetency.labels). |
| Sdílené popisky změn CRM | Popisky z výzvy predikce vztahů zákazníka KDD Cup 2009 (orange_small_train_churn.labels). |
| Sdílená datová sada CRM | Tato data pocházejí z výzvy predikce vztahů zákazníka KDD Cup 2009 (orange_small_train.data.zip). Datová sada obsahuje 50 tisíc zákazníků z francouzské telekomunikační společnosti Orange. Každý zákazník má 230 anonymizovaných funkcí, z nichž 190 jsou číselné a 40 jsou kategorické. Funkce jsou velmi řídké. |
| Sdílené popisky pro upselling CRM | Popisky z výzvy predikce vztahů zákazníka KDD Cup 2009 (orange_large_train_upselling.labels |
| Data zpoždění letů | Údaje o výkonu cestujících na čase převzaté ze sběru dat TranStats ministerstva dopravy USA (on-Time). Datová sada pokrývá časové období duben–říjen 2013. Před nahráním do návrháře se datová sada zpracovala následujícím způsobem: - Datová sada byla filtrována tak, aby pokrývala pouze 70 nejrušnějších letišť v kontinentální USA. - Zrušené lety byly označeny jako zpožděné o více než 15 minut - Odpojené lety byly vyfiltrovány. - Byly vybrány následující sloupce: Year, Month, DayofMonth, DayOfWeek, Carrier, OriginAirportID, DestAirportID, CRSDepTime, DepDelay, DepDel15, CRSArrTime, ArrDelay, ArrDel15, Canceled |
| Datová sada UCI pro německou platební kartu | Datová sada UCI Statlog (německá platební karta) (Statlog+German+Credit+Data) pomocí souboru german.data. Datová sada klasifikuje lidi, které jsou popsány sadou atributů, jako nízká nebo vysoká úvěrové rizika. Každý příklad představuje osobu. Existuje 20 funkcí, číselných i kategorických a binárního popisku (hodnota úvěrového rizika). Položky s vysokým úvěrovým rizikem mají popisek = 2, položky nízkého úvěrového rizika mají popisek = 1. Náklady na špatně klasifikující příklad s nízkým rizikem jsou 1, zatímco náklady na nesprávnou klasifikaci příkladu s vysokým rizikem jsou 5. |
| Názvy filmů IMDB | Datová sada obsahuje informace o filmech, které byly hodnoceny ve tweetech X: ID filmu IMDB, název filmu, žánr a produkční rok. V datové sadě je 17 tisíc filmů. Datová sada byla představena v dokumentu "S. Dooms, T. De Pessemier a L. Martens. MovieTweetings: datová sada hodnocení filmů shromážděná z Twitteru. Workshop o Crowdsourcingu a human computation for Recommender Systems, CrowdRec at RecSys 2013." |
| Hodnocení filmů | Datová sada je rozšířená verze datové sady Video Tweetings. Datová sada má 170 tisíc hodnocení filmů extrahovaných z dobře strukturovaných tweetů na X. Každá instance představuje tweet a je řazenou kolekcí členů: ID uživatele, ID filmu IMDB, hodnocení, časové razítko, počet oblíbených položek pro tento tweet a počet retweetů tohoto tweetu. Datovou sadu zpřístupnil A. Said, S. Dooms, B. Loni a D. Tikk for Recommender Systems Challenge 2014. |
| Datová sada počasí | Hodinová pozorování počasí z NOAA (sloučená data z 201304 do roku 201310). Údaje o počasí zahrnují pozorování z meteorologické stanice letiště, která pokrývají časové období duben-říjen 2013. Před nahráním do návrháře se datová sada zpracovala následujícím způsobem: - ID meteorologické stanice byly mapovány na odpovídající ID letiště - Meteorologické stanice, které nejsou přidružené k 70 nejrušnějším letištím, byly odfiltrovány - Sloupec Datum byl rozdělen do samostatných sloupců Rok, Měsíc a Den. - Byly vybrány následující sloupce: AirportID, Year, Month, Day, Time, TimeZone, SkyCondition, Visibility, WeatherType, DryBulbFarenheit, DryBulbCelsius, WetBulbFarenheit, WetBulbCelsius, DewPointFarenheit, DewPointCelsius, RelativeHumidity, WindSpeed, WindDirection, ValueForWindCharacter, StationPressure, PressureTendency, PressureChange, SeaLevelPressure, RecordType, HourlyPrecip, Altimeter |
| Wikipedie SP 500 Dataset | Data se odvozují z Wikipedie (https://www.wikipedia.org/) na základě článků každé společnosti S&P 500 uložené jako data XML. Před nahráním do návrháře se datová sada zpracovala následujícím způsobem: - Extrahování textového obsahu pro každou konkrétní společnost - Odebrat formátování wikiwebu – Odebere neal alfanumerické znaky. - Převést veškerý text na malá písmena - Byly přidány známé kategorie společnosti. Všimněte si, že u některých společností se nepodařilo najít článek, takže počet záznamů je menší než 500. |
| Data o funkcích restaurace | Sada metadat o restauracích a jejich funkcích, jako je typ jídla, styl stravování a poloha. Použití: Tuto datovou sadu použijte v kombinaci s ostatními dvěma datovými sadami restaurace k trénování a testování doporučovacího systému. Související výzkum: Bache, K. a Lichman, M. (2013). Úložiště strojového učení UCI Irvine, CA: University of California, School of Information and Computer Science. |
| Hodnocení restaurací | Obsahuje hodnocení od uživatelů do restaurací v měřítku od 0 do 2. Použití: Tuto datovou sadu použijte v kombinaci s ostatními dvěma datovými sadami restaurace k trénování a testování doporučovacího systému. Související výzkum: Bache, K. a Lichman, M. (2013). Úložiště strojového učení UCI Irvine, CA: University of California, School of Information and Computer Science. |
| Zákaznická data restaurace | Sada metadat o zákaznících, včetně demografických údajů a preferencí. Použití: Tuto datovou sadu použijte v kombinaci s ostatními dvěma datovými sadami restaurace k trénování a testování doporučovacího systému. Související výzkum: Bache, K. a Lichman, M. (2013). UCI Machine Learning Repository Irvine, CA: University of California, School of Information and Computer Science. |
Vyčištění prostředků
Důležité
Prostředky, které jste vytvořili, můžete použít jako předpoklady pro další kurzy a články s postupy služby Azure Machine Learning.
Odstranit vše
Pokud nemáte v úmyslu používat nic, co jste vytvořili, odstraňte celou skupinu prostředků, takže vám nebudou účtovány žádné poplatky.
Na webu Azure Portal vyberte skupiny prostředků na levé straně okna.
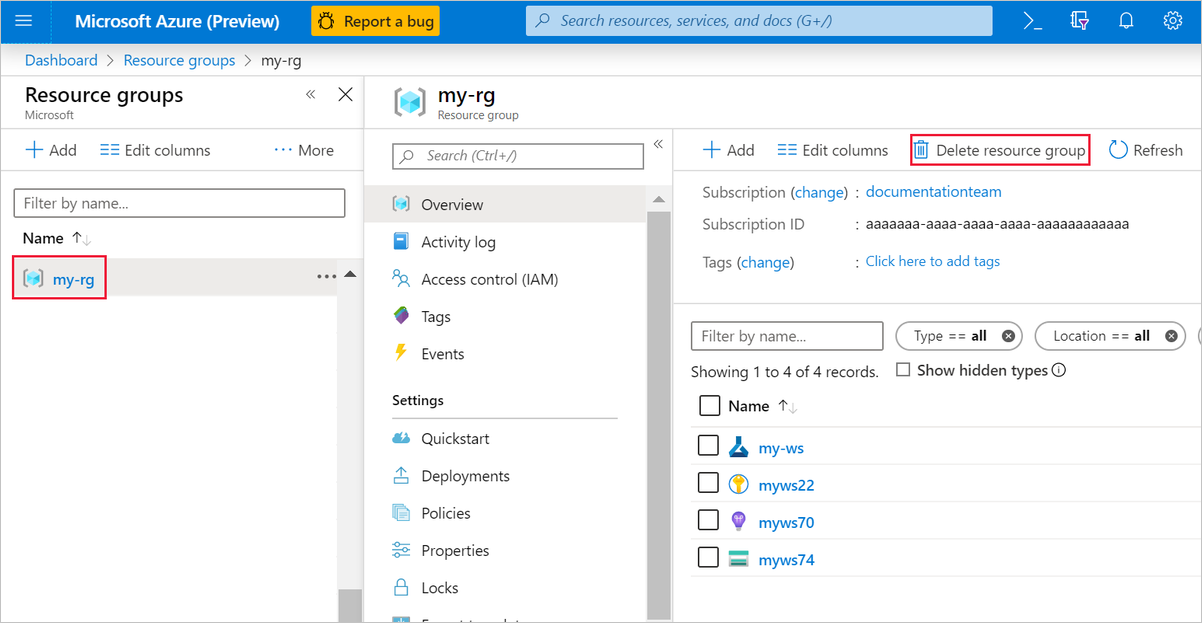
V seznamu vyberte skupinu prostředků, kterou jste vytvořili.
Vyberte Odstranit skupinu prostředků.
Odstraněním skupiny prostředků se odstraní také všechny prostředky, které jste vytvořili v návrháři.
Odstranění jednotlivých prostředků
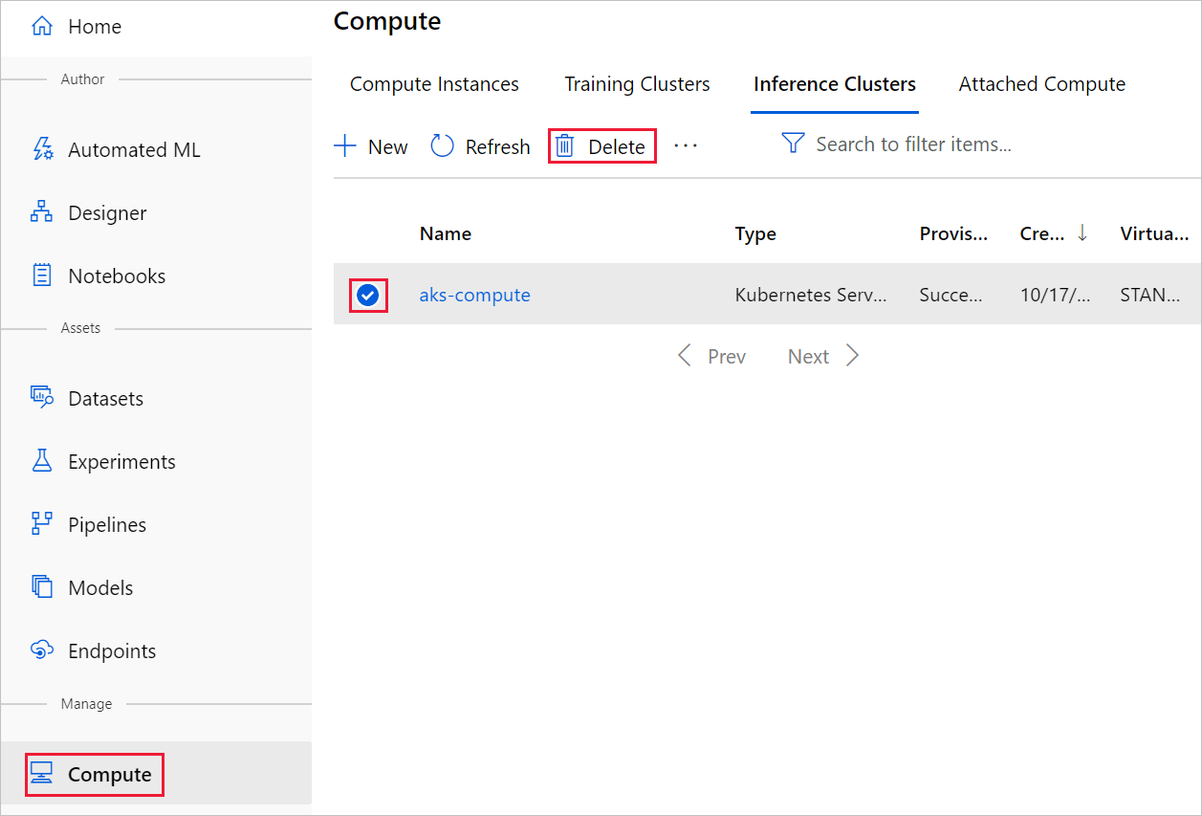
V návrháři, ve kterém jste experiment vytvořili, odstraňte jednotlivé prostředky tak, že je vyberete a pak vyberete tlačítko Odstranit .
Cílový výpočetní objekt, který jste zde vytvořili, automaticky škáluje na nula uzlů, když se nepoužívá. Tato akce se provede, aby se minimalizovaly poplatky. Pokud chcete odstranit cílový výpočetní objekt, postupujte takto:
Datové sady z pracovního prostoru můžete zrušit tak, že vyberete každou datovou sadu a vyberete Zrušit registraci.
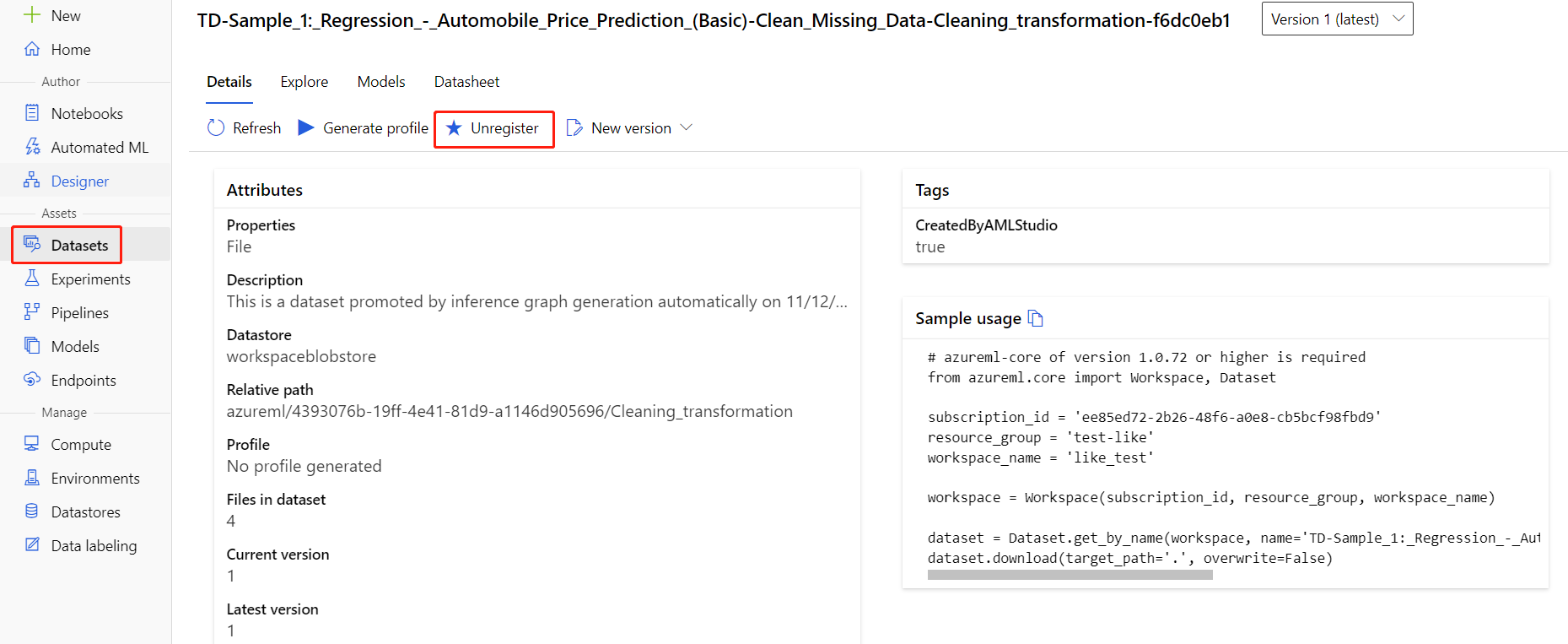
Pokud chcete datovou sadu odstranit, přejděte na účet úložiště pomocí webu Azure Portal nebo Průzkumník služby Azure Storage a odstraňte tyto prostředky ručně.
Další kroky
Seznamte se se základy prediktivní analýzy a strojového učení pomocí kurzu: Předpověď ceny automobilů pomocí návrháře