Kurz: Návrhář – trénování regresního modelu bez kódu
Trénování modelu lineární regrese, který predikuje ceny aut pomocí návrháře služby Azure Machine Učení. Tento kurz je první částí z dvoudílné série.
Tento kurz používá návrháře služby Azure Machine Učení, kde najdete další informace v tématu Co je Návrhář Učení Azure Machine?
Poznámka:
Návrhář podporuje dva typy komponent, klasické předem připravené komponenty (v1) a vlastní komponenty (v2). Tyto dva typy součástí nejsou kompatibilní.
Klasické předem připravené komponenty poskytují předem připravené komponenty pro zpracování dat a tradiční úlohy strojového učení, jako je regrese a klasifikace. Tento typ komponenty se podporuje i nadále, ale nebudou se přidávat žádné nové komponenty.
Vlastní komponenty umožňují zabalit vlastní kód jako součást. Podporuje sdílení komponent mezi pracovními prostory a bezproblémové vytváření v rozhraních Studio, CLI v2 a SDK v2.
Pro nové projekty důrazně doporučujeme používat vlastní komponentu, která je kompatibilní s AzureML V2 a bude nadále přijímat nové aktualizace.
Tento článek se týká klasických předem připravených komponent, které nejsou kompatibilní s rozhraním příkazového řádku v2 a sadou SDK verze 2.
V první části kurzu se naučíte:
- Vytvoření nového kanálu.
- Import data.
- Příprava dat.
- Trénování modelu strojového učení
- Vyhodnocení modelu strojového učení
Ve druhé části kurzu nasadíte model jako koncový bod pro odvozování v reálném čase, abyste předpověděli cenu jakéhokoli vozu na základě technických specifikací, které ho pošlete.
Poznámka:
Dokončená verze tohoto kurzu je k dispozici jako ukázkový kanál.
Najdete ho tak, že přejdete do návrháře ve vašem pracovním prostoru. V části Nový kanál vyberte Sample 1 - Regression: Automobile Price Prediction(Basic).
Důležité
Pokud v tomto dokumentu nevidíte grafické prvky, jako jsou tlačítka v sadě studio nebo návrháři, možná nemáte správnou úroveň oprávnění k pracovnímu prostoru. Obraťte se na správce předplatného Azure a ověřte, že máte udělenou správnou úroveň přístupu. Další informace najdete v tématu Správa uživatelů a rolí.
Vytvoření nového kanálu
Kanály Azure Machine Učení uspořádají několik kroků pro strojové učení a zpracování dat do jednoho prostředku. Kanály umožňují uspořádat, spravovat a opakovaně používat složité pracovní postupy strojového učení napříč projekty a uživateli.
K vytvoření kanálu Učení počítače Azure potřebujete pracovní prostor Učení azure. V této části se dozvíte, jak tyto prostředky vytvořit.
Vytvořit nový pracovní prostor
K používání návrháře potřebujete pracovní prostor Azure Machine Učení. Pracovní prostor je prostředek nejvyšší úrovně pro azure machine Učení, který poskytuje centralizované místo pro práci se všemi artefakty, které vytvoříte v Azure Machine Učení. Pokyny k vytvoření pracovního prostoru najdete v tématu Vytvoření prostředků pracovního prostoru.
Poznámka:
Pokud váš pracovní prostor používá virtuální síť, musíte k použití návrháře použít další kroky konfigurace. Další informace najdete v tématu Použití studio Azure Machine Learning ve virtuální síti Azure
Vytvoření kanálu
Poznámka:
Návrhář podporuje dva typy komponent, klasické předem připravené komponenty a vlastní komponenty. Tyto dva typy komponent nejsou kompatibilní.
Klasické předem připravené komponenty poskytují předem připravené komponenty pro zpracování dat a tradiční úlohy strojového učení, jako je regrese a klasifikace. Tento typ komponenty se podporuje i nadále, ale nebudou se přidávat žádné nové komponenty.
Vlastní komponenty umožňují poskytnout vlastní kód jako součást. Podporuje sdílení mezi pracovními prostory a bezproblémové vytváření obsahu v sadě Studio, CLI a rozhraních sady SDK.
Tento článek se týká klasických předem připravených komponent.
Přihlaste se k ml.azure.com a vyberte pracovní prostor, se kterým chcete pracovat.
Výběr předem připraveného návrháře ->Classic
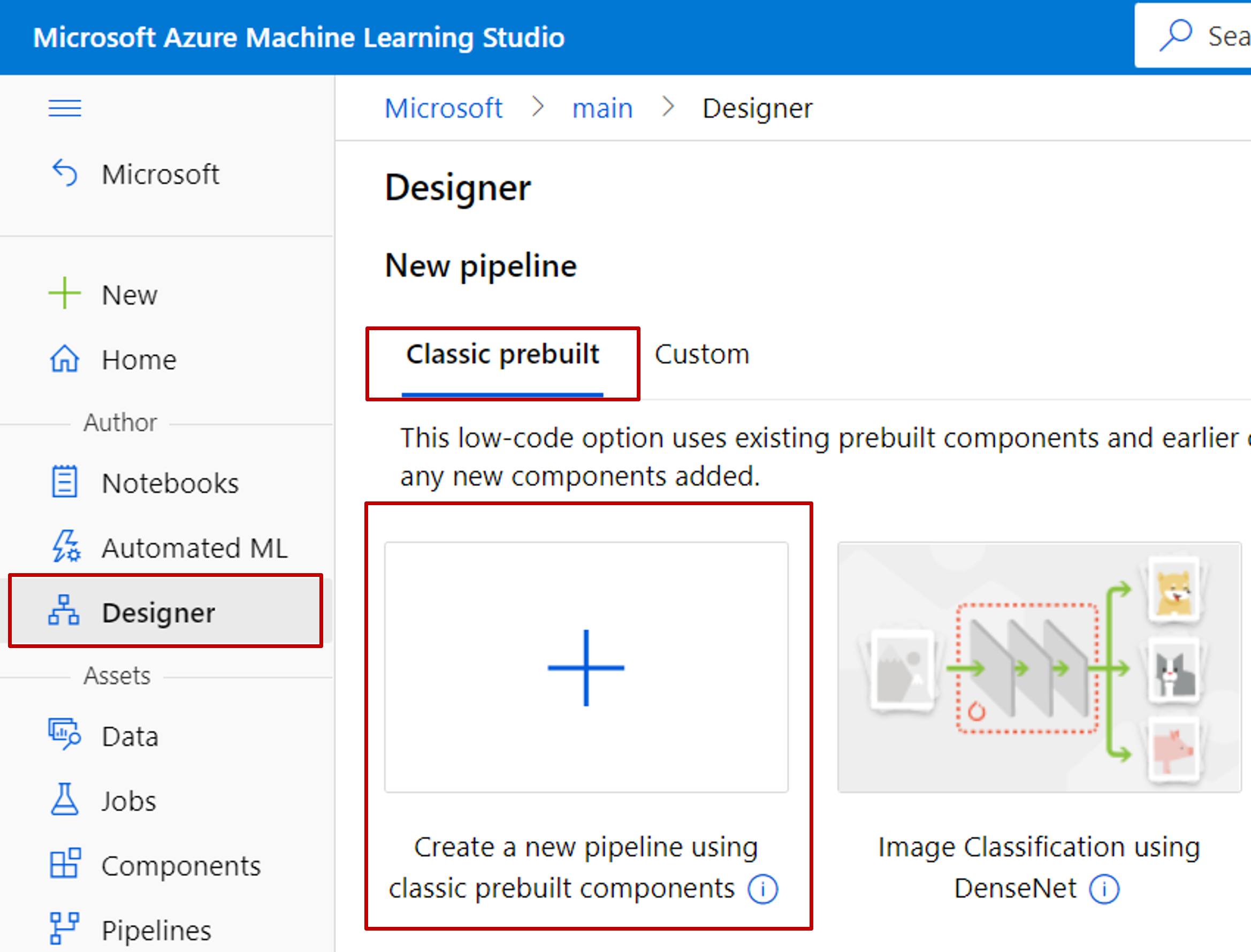
Vyberte Vytvořit nový kanál pomocí klasických předem připravených komponent.
Klikněte na ikonu tužky vedle automaticky generovaného názvu konceptu kanálu a přejmenujte ho na predikci ceny automobilů. Název nemusí být jedinečný.
Importovat data
V návrháři je k dispozici několik ukázkových datových sad, se kterými můžete experimentovat. Pro účely tohoto kurzu použijte údaje o cenách automobilů (Raw).
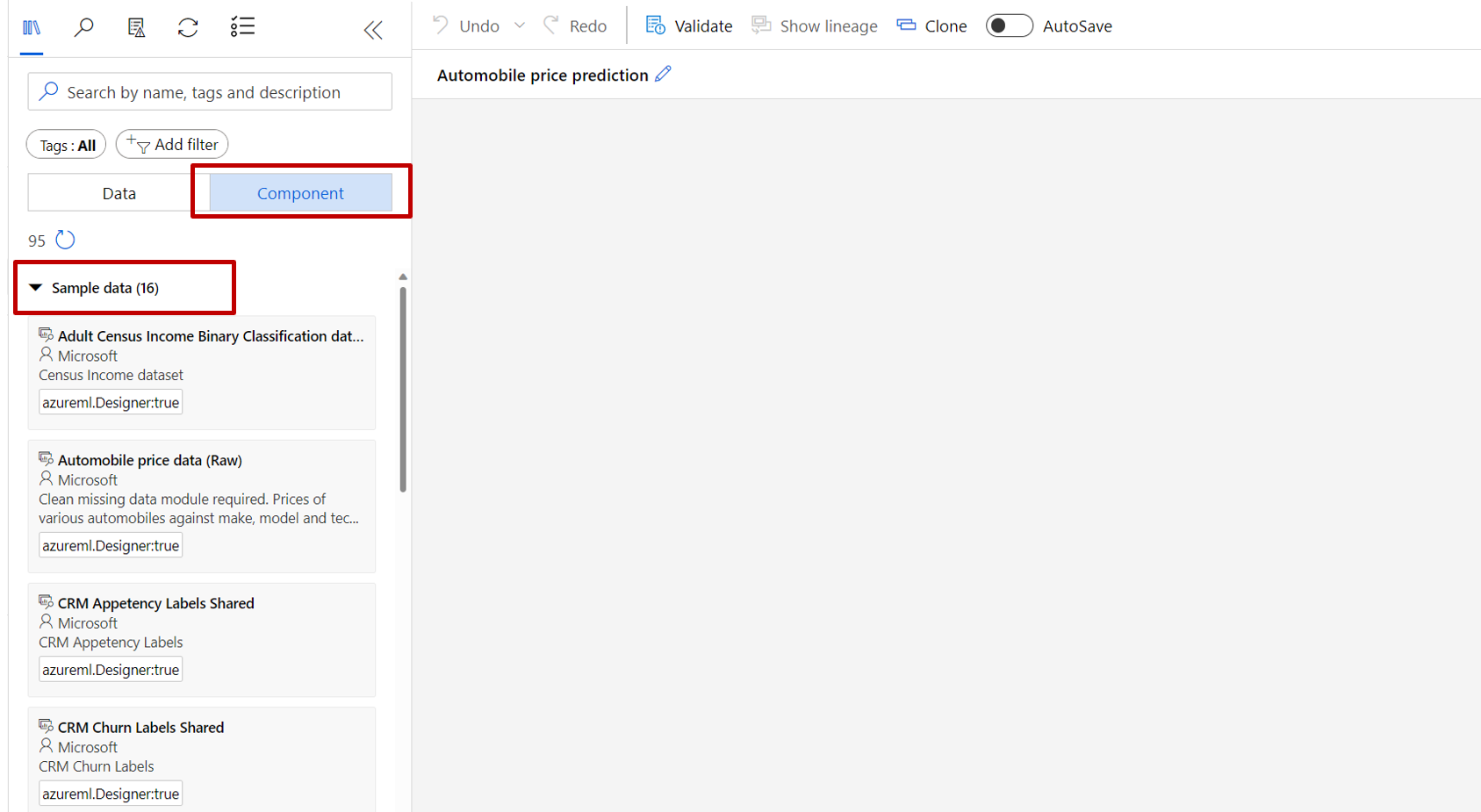
Vlevo od plátna kanálu je paleta datových sad a komponent. Vyberte komponenta –> ukázková data.
Vyberte datovou sadu Automobile price data (Raw) a přetáhněte ji na plátno.
Vizualizace dat
Data můžete vizualizovat, abyste pochopili datovou sadu, kterou budete používat.
Klikněte pravým tlačítkem myši na data cen automobilů (Raw) a vyberte Náhled dat.
Výběrem různých sloupců v okně dat zobrazíte informace o jednotlivých sloupcích.
Každý řádek představuje automobil a proměnné přidružené k jednotlivým automobilům se zobrazují jako sloupce. V této datové sadě je 205 řádků a 26 sloupců.
Příprava dat
Datové sady obvykle před analýzou vyžadují určité předběžné zpracování. Při kontrole datové sady jste si možná všimli některých chybějících hodnot. Tyto chybějící hodnoty musí být vyčištěny, aby model mohl správně analyzovat data.
Odebrání sloupce
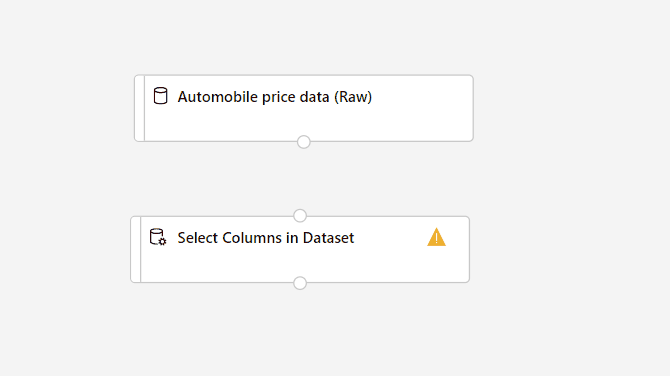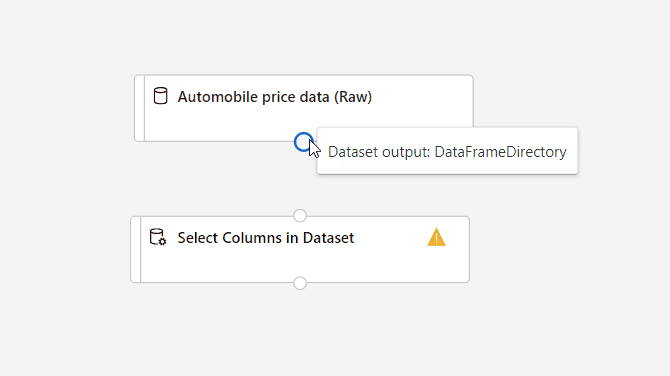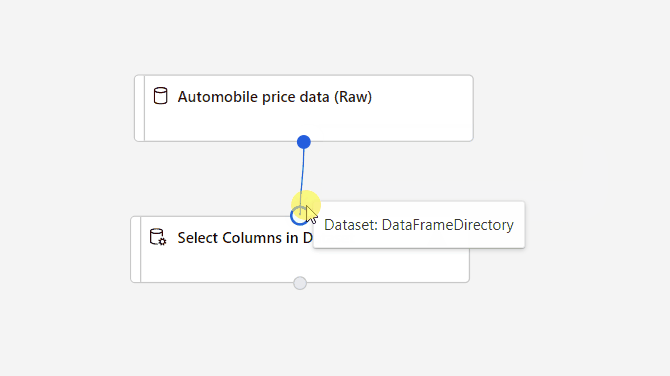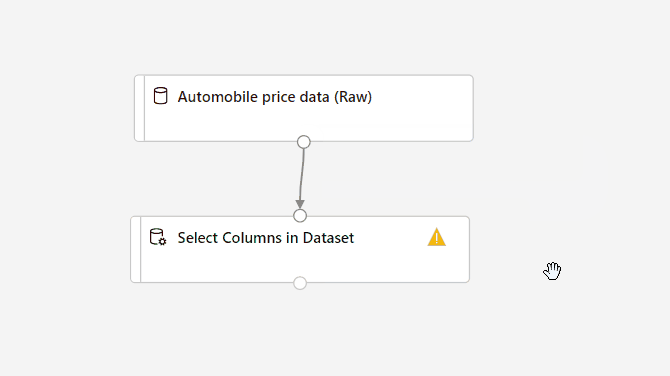
Při trénování modelu musíte udělat něco o chybějících datech. V této datové sadě chybí sloupec normalized-losses mnoho hodnot, takže tento sloupec z modelu úplně vyloučíte.
V datové sadě a paletě komponent vlevo od plátna klikněte na Komponenta a vyhledejte komponentu Vybrat sloupce v datové sadě.
Přetáhněte komponentu Vybrat sloupce v datové sadě na plátno. Zahoďte komponentu pod komponentu datové sady.
PřipojeníDatová sada Automobile Price Data (Raw) do komponenty Vybrat sloupce v datové sadě Přetáhněte z výstupního portu datové sady, což je malý kruh v dolní části datové sady na plátně, na vstupní port Vybrat sloupce v datové sadě, což je malý kruh v horní části komponenty.
Tip
Tok dat vytvoříte prostřednictvím kanálu, když připojíte výstupní port jedné komponenty ke vstupnímu portu jiného.
Vyberte komponentu Vybrat sloupce v datové sadě .
Kliknutím na ikonu šipky pod Nastavení napravo od plátna otevřete podokno podrobností komponenty. Případně můžete poklikáním na komponentu Vybrat sloupce v datové sadě otevřít podokno podrobností.
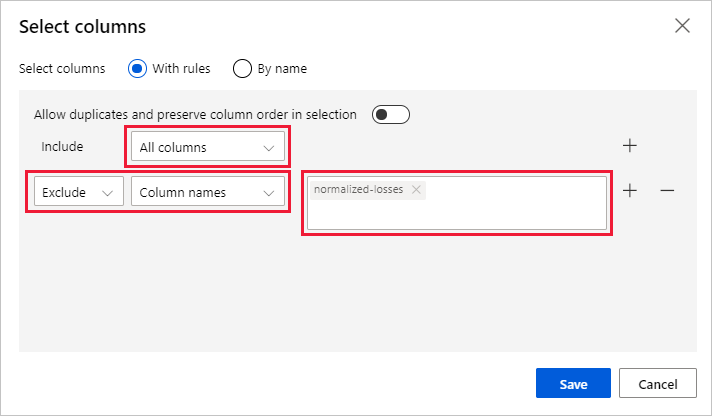
Vyberte Upravit sloupec napravo od podokna.
Rozbalte rozevírací seznam Názvy sloupců vedle položky Zahrnout a vyberte Všechny sloupce.
Vyberte tlačítko + pro přidání nového pravidla.
V rozevíracích nabídkách vyberte Vyloučit a Sloupce názvy.
Do textového pole zadejte normalizované ztráty .
V pravém dolním rohu vyberte Uložit a zavřete selektor sloupců.
V podokně podrobností o komponentě Datové sady vyberte sloupce a rozbalte informace o uzlu.
Vyberte textové pole Komentář a zadejte Vyloučit normalizované ztráty.
Komentáře se zobrazí v grafu, které vám pomůžou s uspořádáním kanálu.
Vyčištění chybějících dat
Vaše datová sada stále chybí hodnoty po odebrání sloupce normalized-losses . Zbývající chybějící data můžete odebrat pomocí komponenty Vyčistit chybějící data .
Tip
Čištění chybějících hodnot ze vstupních dat je předpokladem pro použití většiny součástí v návrháři.
V datové sadě a paletě součástí vlevo od plátna klikněte na Komponenta a vyhledejte součást Vyčistit chybějící data .
Přetáhněte komponentu Vyčistit chybějící data na plátno kanálu. Připojení do Vyberte sloupce v komponentě Datová sada.
Vyberte komponentu Vyčistit chybějící data .
Kliknutím na ikonu šipky pod Nastavení napravo od plátna otevřete podokno podrobností komponenty. Případně můžete poklikáním na komponentu Vyčistit chybějící data otevřít podokno podrobností.
Vyberte Upravit sloupec napravo od podokna.
V okně Sloupce, které se mají vyčistit , rozbalte rozevírací nabídku vedle položky Zahrnout. Vybrat, Všechny sloupce
Zvolte Uložit.
V podokně Podrobnosti o komponentě Vyčistit chybějící data v režimu čištění vyberte Odebrat celý řádek.
V podokně Podrobnosti o komponentě Vyčistit chybějící data rozbalte informace o uzlu.
Vyberte textové pole Komentář a zadejte Odebrat chybějící řádky hodnot.
Váš kanál by teď měl vypadat nějak takto:
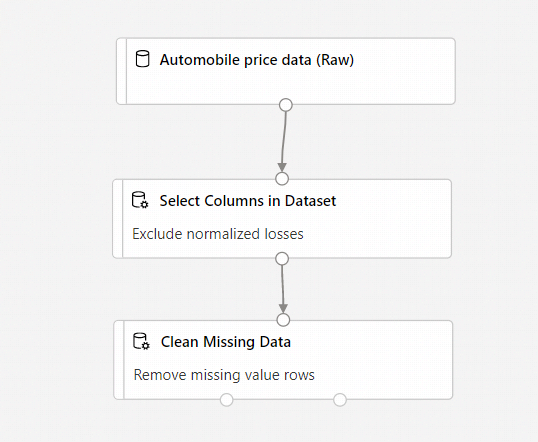
Trénování modelu strojového učení
Teď, když máte k dispozici komponenty pro zpracování dat, můžete nastavit trénovací komponenty.
Protože chcete predikovat cenu, což je číslo, můžete použít regresní algoritmus. V tomto příkladu použijete lineární regresní model.
Rozdělení dat
Rozdělení dat je běžnou úlohou strojového učení. Data rozdělíte do dvou samostatných datových sad. Jedna datová sada trénuje model a druhá otestuje, jak dobře model fungoval.
Na levé straně plátna v datových sadách a paletě komponent klikněte na Komponenta a vyhledejte součást Rozdělit data .
Přetáhněte komponentu Rozdělit data na plátno kanálu.
Připojení levý port Vyčistíte chybějící datovou komponentu do komponenty Rozdělit data.
Důležité
Ujistěte se, že se levý výstupní port funkce Vyčištění chybějících dat připojuje k rozdělení dat. Levý port obsahuje vyčištěná data. Pravý port obsahuje zahozená data.
Vyberte komponentu Rozdělit data .
Kliknutím na ikonu šipky pod Nastavení napravo od plátna otevřete podokno podrobností komponenty. Případně můžete poklikáním na komponentu Rozdělit data otevřít podokno podrobností.
V podokně Podrobností rozdělení dat nastavte zlomek řádků v první výstupní datové sadě na hodnotu 0,7.
Tato možnost rozdělí 70 procent dat na trénování modelu a 30 procent pro jeho testování. Datová sada s 70 procenty bude přístupná přes levý výstupní port. Zbývající data jsou k dispozici přes správný výstupní port.
V podokně Podrobností o rozdělení dat rozbalte informace o uzlu.
Vyberte textové pole Komentář a zadejte Rozdělit datovou sadu na trénovací sadu (0,7) a testovací sadu (0.3).
Trénování modelu
Vytrénujte model tím, že jí poskytnete datovou sadu, která zahrnuje cenu. Algoritmus vytvoří model, který vysvětluje vztah mezi funkcemi a cenou, jak je znázorněno trénovacími daty.
V paletě datových sad a komponent vlevo od plátna klikněte na Komponenta a vyhledejte komponentu Lineární regrese.
Přetáhněte komponentu Lineární regrese na plátno kanálu.
Na levé straně plátna v datových sadách a paletě komponent klikněte na Komponenta a vyhledejte komponentu Trénování modelu .
Přetáhněte komponentu Trénování modelu na plátno kanálu.
Připojení výstupu Komponenta lineární regrese do levého vstupu komponenty Train Model.
Připojení výstupu trénovacích dat (levý port)Rozdělte datovou komponentu na správný vstup komponenty Trénování modelu.
Důležité
Ujistěte se, že se levý výstupní port rozdělených dat připojuje k trénování modelu. Levý port obsahuje trénovací sadu. Pravý port obsahuje testovací sadu.
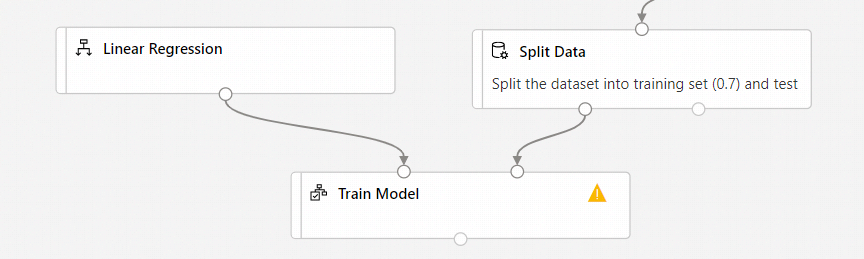
Vyberte komponentu Trénování modelu .
Kliknutím na ikonu šipky pod Nastavení napravo od plátna otevřete podokno podrobností komponenty. Případně můžete poklikáním na komponentu Train Model (Trénovat model ) otevřít podokno podrobností.
Vyberte Upravit sloupec napravo od podokna.
V okně Sloupec Popisek, které se zobrazí, rozbalte rozevírací nabídku a vyberte Názvy sloupců.
Do textového pole zadejte cenu , která určuje hodnotu, kterou bude model predikovat.
Důležité
Ujistěte se, že přesně zadáte název sloupce. Nevyučujte cenu.
Kanál by měl vypadat takto:
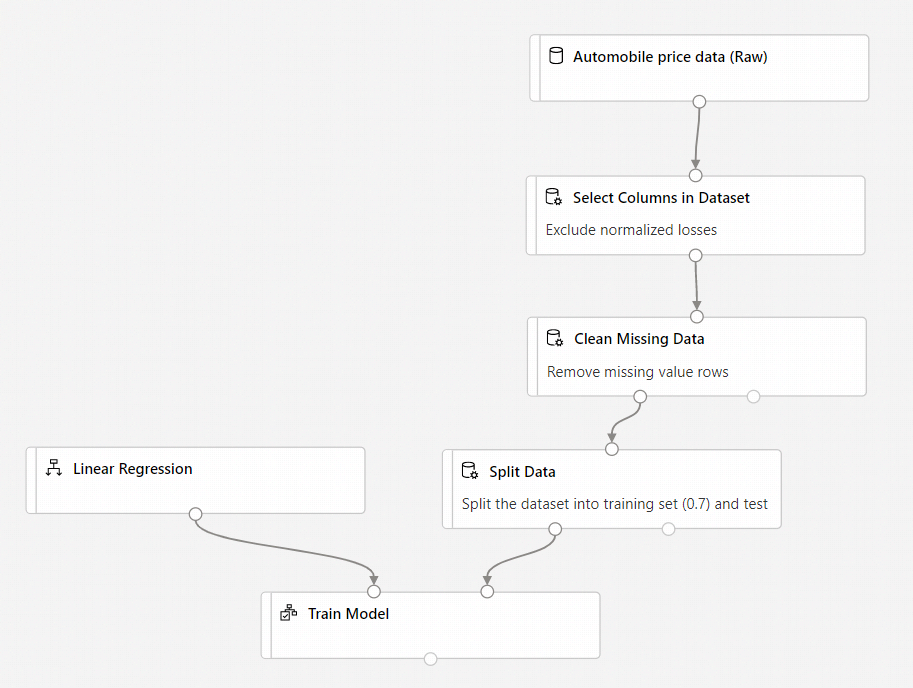
Přidání komponenty Score Model
Jakmile model vytrénujete pomocí 70 procent dat, můžete ho použít k určení skóre ostatních 30 procent a zjistit, jak dobře funguje váš model.
V datové sadě a paletě komponent vlevo od plátna klikněte na Komponenta a vyhledejte komponentu Určení skóre modelu.
Přetáhněte komponentu Určení skóre modelu na plátno kanálu.
Připojení výstupu Natrénujte komponentu Model na levý vstupní port určení skóre modelu. Připojení výstupu testovacích dat (pravý port)Rozdělte datovou komponentu na správný vstupní port modelu určení skóre.
Přidání komponenty Vyhodnotit model
Pomocí komponenty Vyhodnotit model vyhodnoťte, jak dobře model vyhodnocoval testovací datovou sadu.
V datové sadě a paletě komponent vlevo od plátna klikněte na Komponenta a vyhledejte komponentu Vyhodnotit model .
Přetáhněte komponentu Vyhodnotit model na plátno kanálu.
Připojení výstupu Komponenta Určení skóre modelu do levého vstupu vyhodnocení modelu
Konečný kanál by měl vypadat přibližně takto:
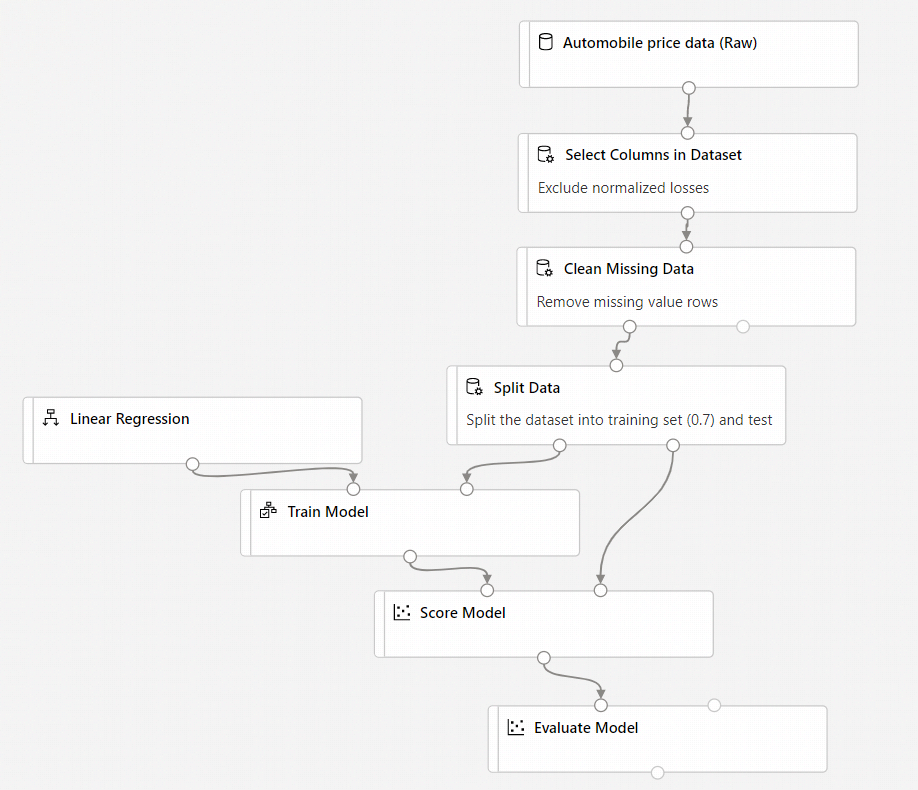
Odeslání kanálu
V pravém horním rohu vyberte Konfigurovat a odeslat kanál.

Pak uvidíte podrobného průvodce, podle pokynů v průvodci odešlete úlohu kanálu.
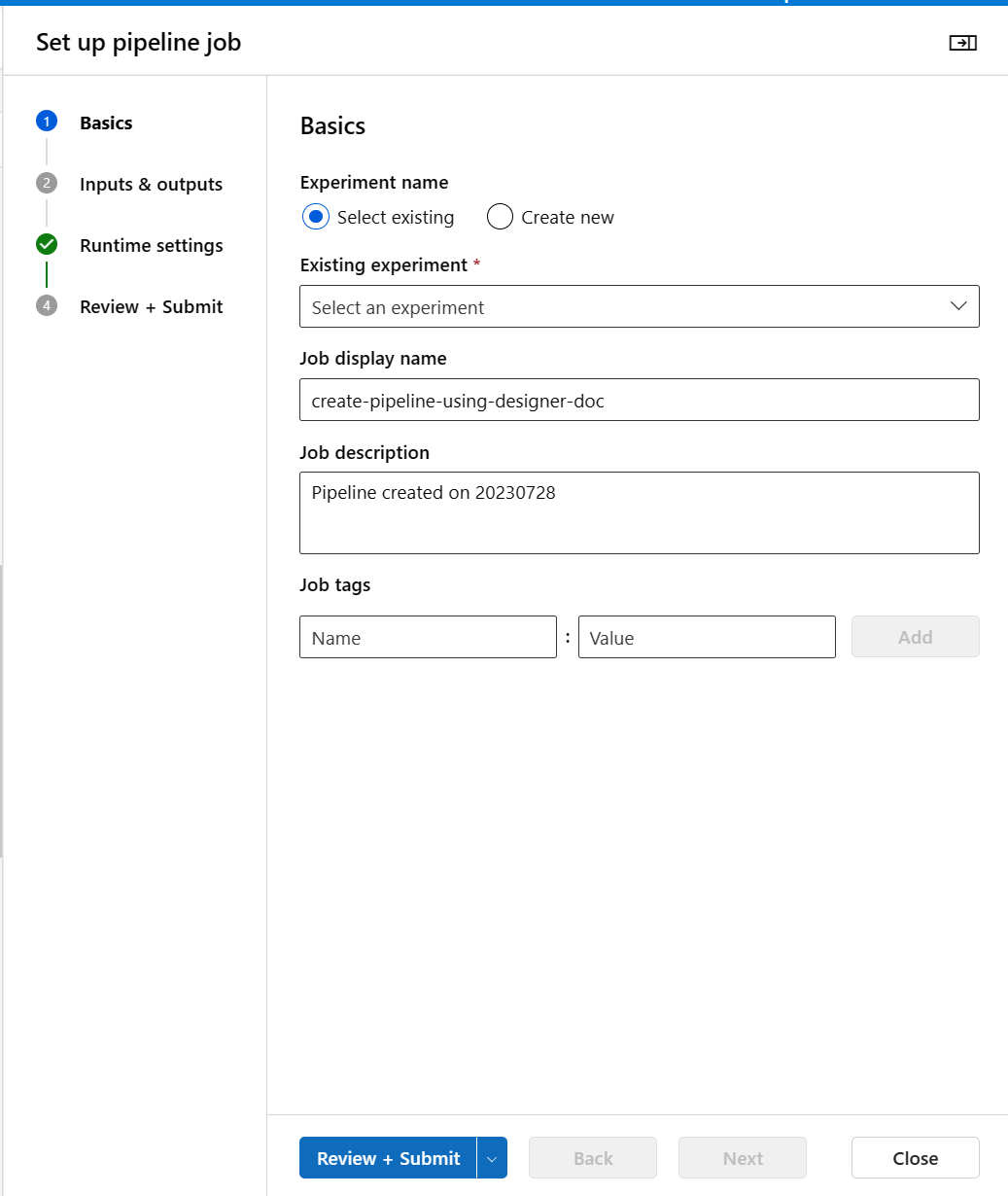

V kroku Základy můžete nakonfigurovat experiment, zobrazovaný název úlohy, popis úlohy atd.
V kroku Vstupy a výstupy můžete přiřadit hodnotu vstupním/výstupním vstupům, které jsou povýšeny na úroveň kanálu. V tomto příkladu bude prázdný, protože jsme nezvýšili úroveň vstupu a výstupu na úroveň kanálu.
V nastavení modulu runtime můžete pro kanál nakonfigurovat výchozí úložiště dat a výchozí výpočetní prostředky. Jedná se o výchozí úložiště dat a výpočetní prostředky pro všechny komponenty v kanálu. Pokud však pro komponentu nastavíte jiný výpočetní objekt nebo úložiště dat explicitně, systém respektuje nastavení na úrovni komponenty. V opačném případě použije výchozí hodnotu.
Krok Zkontrolovat a odeslat je posledním krokem ke kontrole všech nastavení před odesláním. Průvodce si zapamatuje vaši poslední konfiguraci, pokud kanál odešlete.
Po odeslání úlohy kanálu se nahoře zobrazí zpráva s odkazem na podrobnosti úlohy. Výběrem tohoto odkazu můžete zkontrolovat podrobnosti o úloze.

Zobrazení popisků se skóre
Na stránce podrobností úlohy můžete zkontrolovat stav úlohy kanálu, výsledky a protokoly.
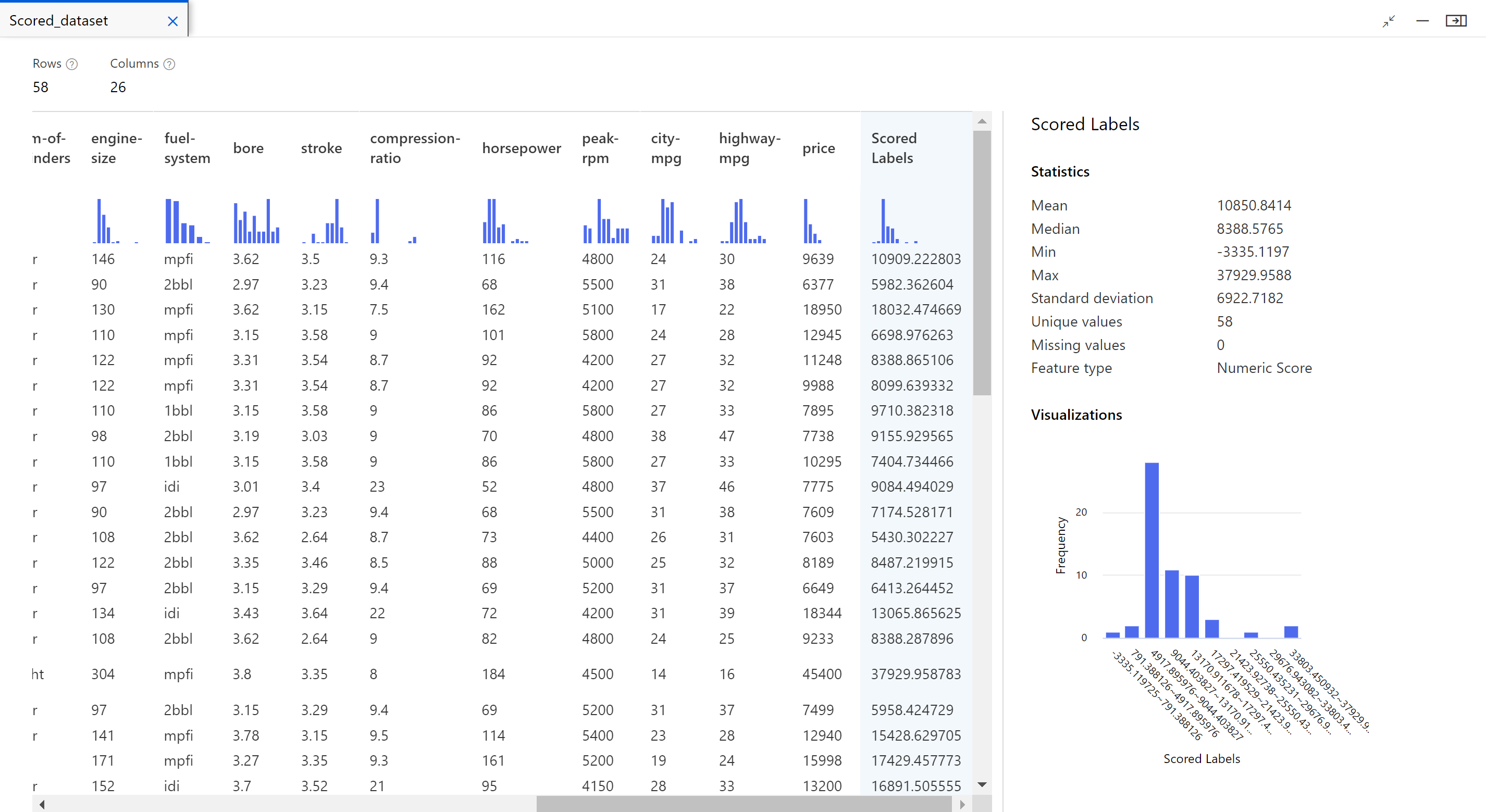
Po dokončení úlohy můžete zobrazit výsledky úlohy kanálu. Nejprve se podívejte na předpovědi generované regresním modelem.
Klikněte pravým tlačítkem myši na komponentu Score Model (Určení skóre modelu) a vyberte náhled datové sady Scored (Skóre dat>) a zobrazte její výstup.
Tady vidíte predikované ceny a skutečné ceny z testovacích dat.
Vyhodnocení modelů
Pomocí testovací datové sady můžete zjistit, jak dobře trénovaný model fungoval s testovací datovou sadou.
- Klikněte pravým tlačítkem myši na komponentu Vyhodnotit model a výběrem náhledu výsledků vyhodnocení dat>zobrazte jeho výstup.
Pro váš model se zobrazují následující statistiky:
- Střední absolutní chyba (MAE):: Průměr absolutních chyb. Chyba je rozdíl mezi predikovanou hodnotou a skutečnou hodnotou.
- Odmocnina střední kvadratické chyby (RMSE): Druhá odmocnina průměru kvadratických chyb předpovědí na základě testovací datové sady
- Relativní absolutní chyba: Průměr absolutních chyb relativních k absolutnímu rozdílu mezi skutečnými hodnotami a průměrem všech skutečných hodnot
- Relativní kvadratická chyba: Průměr kvadratických chyb relativních ke kvadratickému rozdílu mezi skutečnými hodnotami a průměrem všech skutečných hodnot
- Koeficient stanovení: Tato statistická metrika označuje, jak dobře model odpovídá datům.
Pro každou statistiku chyb platí, že menší hodnota je lepší. Menší hodnota označuje, že předpovědi jsou blíže skutečným hodnotám. Pro koeficient určení je čím blíže jeho hodnota k jedné (1,0), tím lepší predikce.
Vyčištění prostředků
Pokud chcete pokračovat v části 2 kurzu, nasazení modelů přeskočte tuto část.
Důležité
Prostředky, které jste vytvořili, můžete použít jako předpoklady pro další kurzy a postupy pro azure machine Učení články.
Odstranit vše
Pokud nemáte v úmyslu používat nic, co jste vytvořili, odstraňte celou skupinu prostředků, takže vám nebudou účtovány žádné poplatky.
Na webu Azure Portal vyberte skupiny prostředků na levé straně okna.
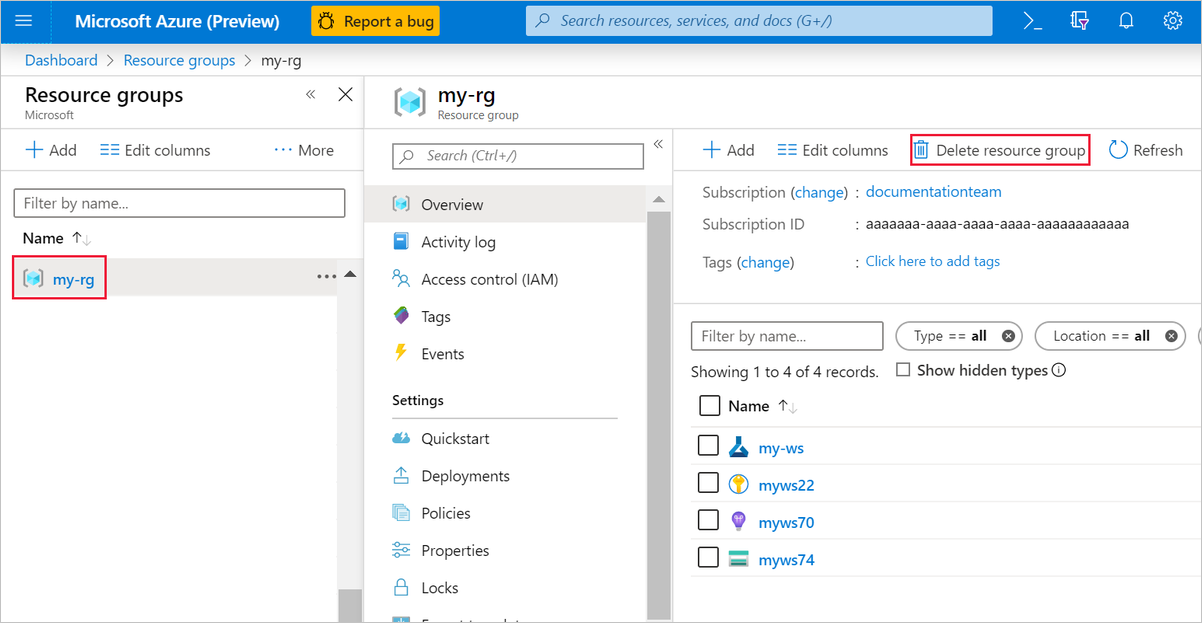
V seznamu vyberte skupinu prostředků, kterou jste vytvořili.
Vyberte Odstranit skupinu prostředků.
Odstraněním skupiny prostředků se odstraní také všechny prostředky, které jste vytvořili v návrháři.
Odstranění jednotlivých prostředků
V návrháři, ve kterém jste experiment vytvořili, odstraňte jednotlivé prostředky tak, že je vyberete a pak vyberete tlačítko Odstranit .
Cílový výpočetní objekt, který jste zde vytvořili, automaticky škáluje na nula uzlů, když se nepoužívá. Tato akce se provede, aby se minimalizovaly poplatky. Pokud chcete odstranit cílový výpočetní objekt, postupujte takto:
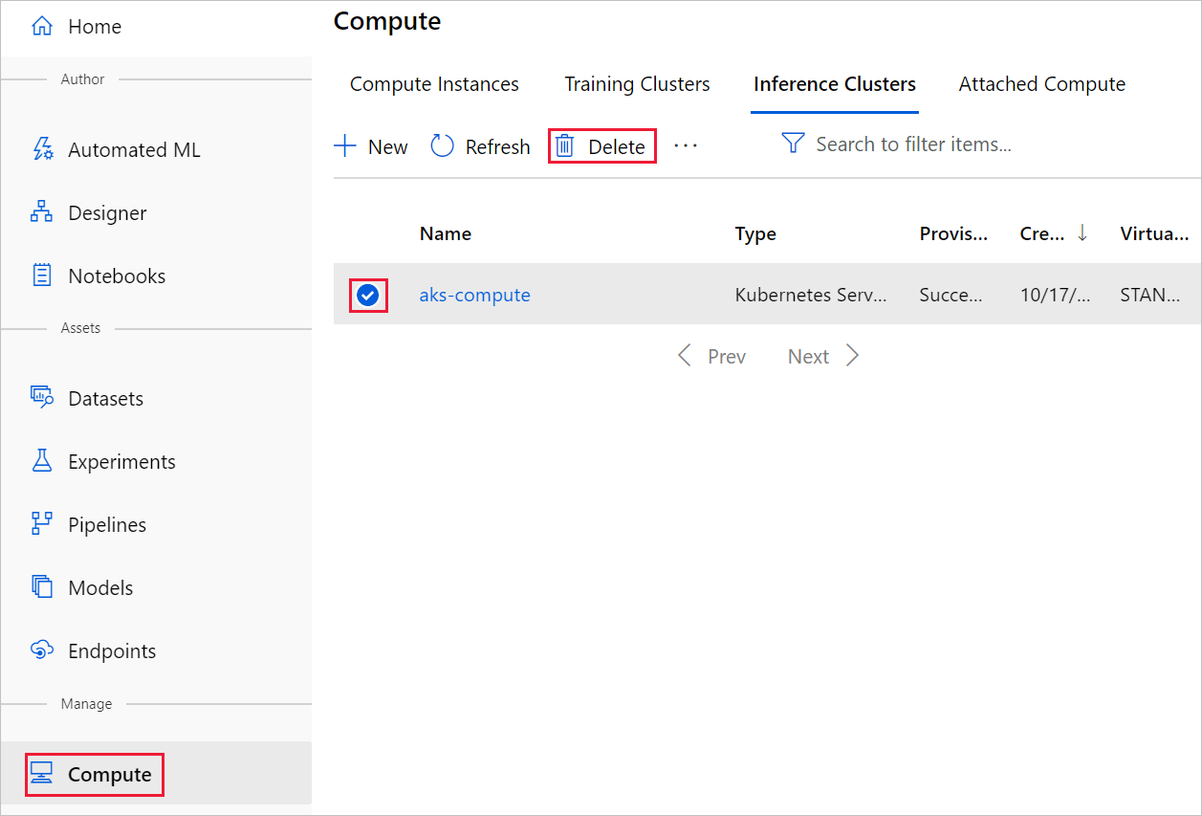
Datové sady z pracovního prostoru můžete zrušit tak, že vyberete každou datovou sadu a vyberete Zrušit registraci.
Pokud chcete datovou sadu odstranit, přejděte na účet úložiště pomocí webu Azure Portal nebo Průzkumník služby Azure Storage a odstraňte tyto prostředky ručně.
Další kroky
V druhé části se dozvíte, jak model nasadit jako koncový bod v reálném čase.