Shromažďování dat z modelů v produkčním prostředí
PLATÍ PRO: Sada Python SDK azureml v1
Sada Python SDK azureml v1
Tento článek ukazuje, jak shromažďovat data z modelu Azure Machine Learning nasazeného v clusteru Azure Kubernetes Service (AKS). Shromážděná data se pak uloží ve službě Azure Blob Storage.
Jakmile je shromažďování povolené, shromažďovaná data vám pomůžou:
Monitorujte posuny dat na produkčních datech, která shromažďujete.
Analýza shromážděných dat pomocí Power BI nebo Azure Databricks
Lépe se rozhodujte o tom, kdy model přetrénovat nebo optimalizovat.
Znovu vytrénujte model pomocí shromážděných dat.
Omezení
- Funkce shromažďování dat modelu může fungovat jenom s obrázkem Ubuntu 18.04.
Důležité
Od 10. 3. 2023 je image Ubuntu 18.04 zastaralá. Podpora imagí Ubuntu 18.04 bude ukončena od ledna 2023, když dosáhne EOL 30. dubna 2023.
Funkce MDC není kompatibilní s žádnou jinou image než Ubuntu 18.04, která po vyřazení image Ubuntu 18.04 není k dispozici.
mDalší informace, na které se můžete podívat:
Poznámka
Funkce shromažďování dat je aktuálně ve verzi Preview, pro produkční úlohy se žádné funkce verze Preview nedoporučují.
Co se shromažďuje a kam směřuje
Je možné shromažďovat následující data:
Vstupní data modelu z webových služeb nasazených v clusteru AKS Hlasový zvuk, obrázky a video se neshromažďují.
Modelování predikcí pomocí produkčních vstupních dat
Poznámka
Preaggregation and precalculations on this data are not part of the collection service.
Výstup se uloží ve službě Blob Storage. Vzhledem k tomu, že se data přidávají do úložiště objektů blob, můžete zvolit svůj oblíbený nástroj pro spuštění analýzy.
Cesta k výstupním datům v objektu blob se řídí touto syntaxí:
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv
# example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv
Poznámka
Ve verzích sady Azure Machine Learning SDK pro Python starší než verze 0.1.0a16 designation se argument jmenuje identifier. Pokud jste kód vyvinuli ve starší verzi, musíte ho odpovídajícím způsobem aktualizovat.
Požadavky
Pokud ještě nemáte předplatné Azure, vytvořte si bezplatný účet před tím, než začnete.
Musí být nainstalovaný pracovní prostor Azure Machine Learning, místní adresář obsahující vaše skripty a sada Azure Machine Learning SDK pro Python. Informace o tom, jak je nainstalovat, najdete v tématu Konfigurace vývojového prostředí.
K nasazení do AKS potřebujete natrénovaný model strojového učení. Pokud model nemáte, projděte si kurz trénování modelu klasifikace obrázků .
Potřebujete cluster AKS. Informace o tom, jak ho vytvořit a nasadit do něj, najdete v tématu Nasazení modelů strojového učení do Azure.
Nastavte své prostředí a nainstalujte sadu SDK pro monitorování služby Azure Machine Learning.
Použijte image Dockeru založenou na Ubuntu 18.04, která se dodává s
libssl 1.0.0, což je základní závislost modeldatacollectoru. Můžete si projít předem sestavené image.
Povolení shromažďování dat
Shromažďování dat můžete povolit bez ohledu na model, který nasadíte prostřednictvím služby Azure Machine Learning nebo jiných nástrojů.
Pokud chcete povolit shromažďování dat, musíte:
Otevřete soubor s hodnocením.
Na začátek souboru přidejte následující kód:
from azureml.monitoring import ModelDataCollectorDeklarujte proměnné shromažďování dat ve vaší
initfunkci:global inputs_dc, prediction_dc inputs_dc = ModelDataCollector("best_model", designation="inputs", feature_names=["feat1", "feat2", "feat3", "feat4", "feat5", "feat6"]) prediction_dc = ModelDataCollector("best_model", designation="predictions", feature_names=["prediction1", "prediction2"])CorrelationId je volitelný parametr. Pokud ho váš model nevyžaduje, nemusíte ho používat. Použití Id korelace vám pomůže snadněji mapovat s jinými daty, jako je LoanNumber nebo CustomerId.
Parametr Identifier se později použije k vytvoření struktury složek v objektu blob. Můžete ho použít k odlišení nezpracovaných dat od zpracovaných dat.
Do funkce přidejte následující řádky kódu
run(input_df):data = np.array(data) result = model.predict(data) inputs_dc.collect(data) #this call is saving our input data into Azure Blob prediction_dc.collect(result) #this call is saving our prediction data into Azure BlobPři nasazení služby v AKS se shromažďování dat automaticky nenastaví na hodnotu true . Aktualizujte konfigurační soubor, jak je uvedeno v následujícím příkladu:
aks_config = AksWebservice.deploy_configuration(collect_model_data=True)Můžete také povolit Application Insights pro monitorování služeb změnou této konfigurace:
aks_config = AksWebservice.deploy_configuration(collect_model_data=True, enable_app_insights=True)Pokud chcete vytvořit novou image a nasadit model strojového učení, přečtěte si téma Nasazení modelů strojového učení do Azure.
Přidejte balíček pip Azure-Monitoring do conda-dependencies prostředí webové služby:
env = Environment('webserviceenv')
env.python.conda_dependencies = CondaDependencies.create(conda_packages=['numpy'],pip_packages=['azureml-defaults','azureml-monitoring','inference-schema[numpy-support]'])
Zakázání shromažďování dat
Shromažďování dat můžete kdykoli ukončit. Pomocí kódu Pythonu zakažte shromažďování dat.
## replace <service_name> with the name of the web service
<service_name>.update(collect_model_data=False)
Ověření a analýza dat
Můžete si vybrat nástroj podle svých preferencí pro analýzu dat shromážděných ve vašem úložišti objektů blob.
Rychlý přístup k datům objektů blob
Přihlaste se k portálu Azure.
Otevřete pracovní prostor.
Vyberte Úložiště.

Postupujte podle cesty k výstupním datům objektu blob pomocí této syntaxe:
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv # example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv

Analýza dat modelu pomocí Power BI
Stáhněte a otevřete Power BI Desktop.
Vyberte Získat data a vyberte Azure Blob Storage.

Přidejte název účtu úložiště a zadejte svůj klíč úložiště. Tyto informace najdete tak, že v objektu blob vyberetePřístupové klíčenastavení>.
Vyberte kontejner dat modelu a vyberte Upravit.
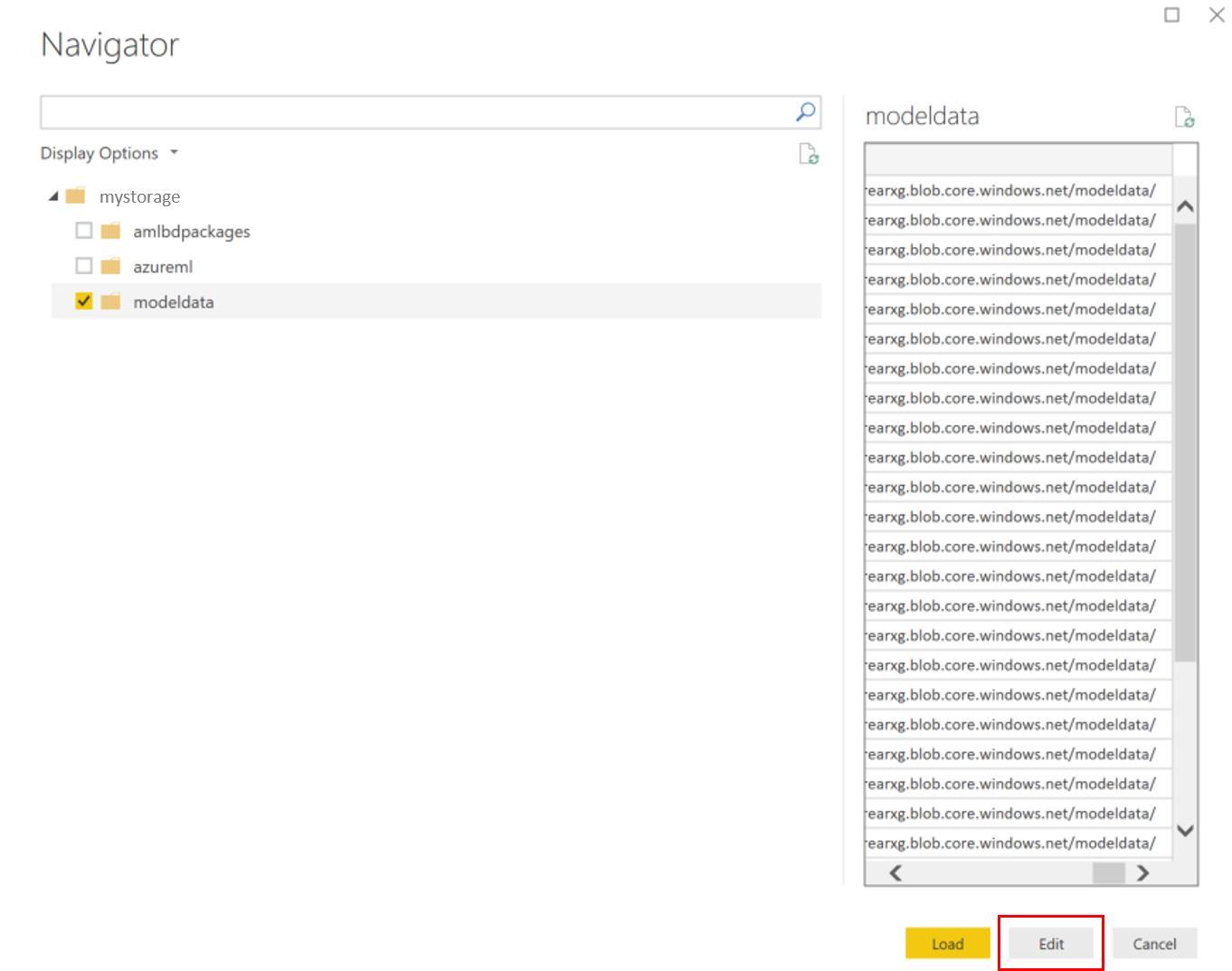
V editoru dotazů klikněte pod sloupec Název a přidejte svůj účet úložiště.
Do filtru zadejte cestu k modelu. Pokud se chcete podívat jenom na soubory z určitého roku nebo měsíce, jednoduše rozbalte cestu filtru. Pokud se například chcete podívat jenom na data z března, použijte tuto cestu filtru:
/modeldata/<subscriptionid>/<resourcegroupname>/<workspacename>/<webservicename>/<modelname>/<modelversion>/<designation>/<year>/3
Vyfiltrujte data, která jsou pro vás relevantní, na základě hodnot názvu . Pokud jste uložili předpovědi a vstupy, musíte pro každou z nich vytvořit dotaz.
Pokud chcete soubory zkombinovat, vyberte dvojitou šipku dolů vedle záhlaví sloupce Obsah .
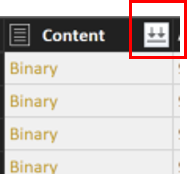
Vyberte OK. Data se přednačtou.

Vyberte Zavřít a použít.
Pokud jste přidali vstupy a předpovědi, tabulky se automaticky seřadí podle hodnot RequestId .
Začněte vytvářet vlastní sestavy na datech modelu.




Analýza dat modelu pomocí Azure Databricks
Vytvořte pracovní prostor Azure Databricks.
Přejděte do pracovního prostoru Databricks.
V pracovním prostoru Databricks vyberte Nahrát data.

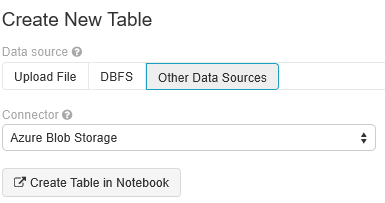
Vyberte Vytvořit novou tabulku a vyberte Další zdroje> dat Azure Blob Storage>Vytvořit tabulku v poznámkovém bloku.
Aktualizujte umístění vašich dat. Zde naleznete příklad:
file_location = "wasbs://mycontainer@storageaccountname.blob.core.windows.net/modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/*/*/data.csv" file_type = "csv"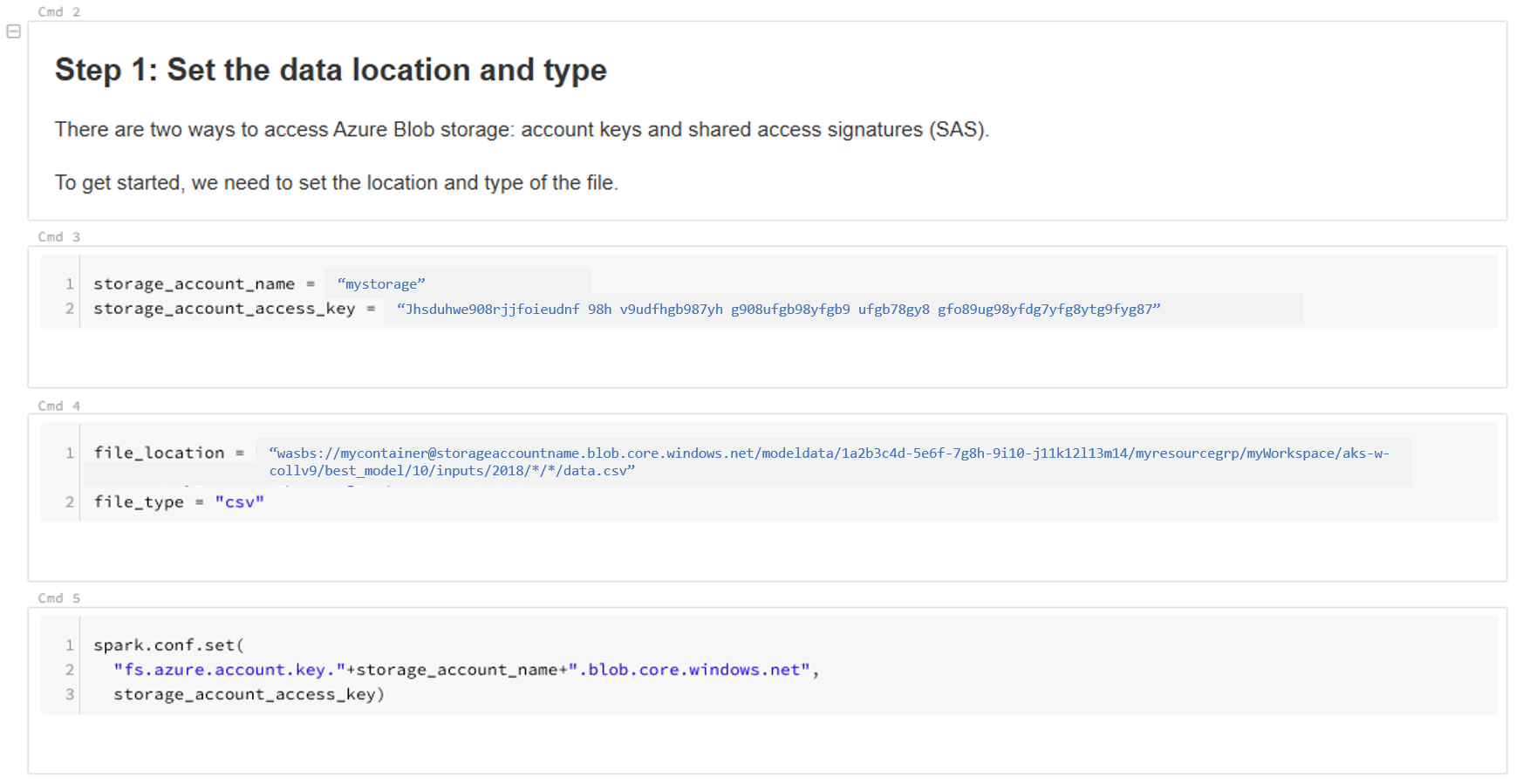
Pokud chcete zobrazit a analyzovat data, postupujte podle pokynů v šabloně.



Další kroky
Detekujte posun dat u shromážděných dat.