Správa verzí a sledování datových sad služby Azure Machine Learning
PLATÍ PRO: Sada Python SDK azureml v1
Sada Python SDK azureml v1
V tomto článku se dozvíte, jak používat a sledovat datové sady Azure Machine Learning pro účely reprodukovatelnosti. Správa verzí datové sady je způsob, jak vytvořit záložku stavu dat, abyste mohli použít konkrétní verzi datové sady pro budoucí experimenty.
Typické scénáře správy verzí:
- Kdy jsou k dispozici nová data pro opětovné natrénování
- Při použití různých přístupů k přípravě dat nebo přípravě atributů
Požadavky
Pro účely tohoto kurzu potřebujete:
Nainstalovaná sada Azure Machine Learning SDK pro Python Tato sada SDK obsahuje balíček azureml-datasets .
Pracovní prostor Služby Azure Machine Learning. Spuštěním následujícího kódu načtěte existující nebo vytvořte nový pracovní prostor.
import azureml.core from azureml.core import Workspace ws = Workspace.from_config()
Registrace a načtení verzí datové sady
Když datovou sadu zaregistrujete, můžete ji verzí, opakovaně používat a sdílet napříč experimenty a s kolegy. Můžete zaregistrovat více datových sad pod stejným názvem a načíst konkrétní verzi podle názvu a čísla verze.
Registrace verze datové sady
Následující kód zaregistruje novou verzi titanic_ds datové sady nastavením parametru create_new_version na True. Pokud v pracovním prostoru není zaregistrovaná žádná datová titanic_ds sada, kód vytvoří novou datovou sadu s názvem titanic_ds a nastaví její verzi na 1.
titanic_ds = titanic_ds.register(workspace = workspace,
name = 'titanic_ds',
description = 'titanic training data',
create_new_version = True)
Načtení datové sady podle názvu
Ve výchozím nastavení metoda get_by_name() ve Dataset třídě vrací nejnovější verzi datové sady zaregistrované v pracovním prostoru.
Následující kód získá verzi 1 titanic_ds datové sady.
from azureml.core import Dataset
# Get a dataset by name and version number
titanic_ds = Dataset.get_by_name(workspace = workspace,
name = 'titanic_ds',
version = 1)
Osvědčený postup správy verzí
Když vytváříte verzi datové sady, nevytvoříte s pracovním prostorem další kopii dat. Vzhledem k tomu, že datové sady jsou odkazy na data ve službě úložiště, máte jediný zdroj pravdy spravovaný službou úložiště.
Důležité
Pokud jsou data, na která datová sada odkazuje, přepsána nebo odstraněna, voláním konkrétní verze datové sady se změna nevrátí .
Když načtete data z datové sady, načte se vždy aktuální datový obsah, na který datová sada odkazuje. Pokud chcete zajistit, aby bylo možné reprodukovat každou verzi datové sady, doporučujeme neupravovat datový obsah, na který verze datové sady odkazuje. Když přijdou nová data, uložte nové datové soubory do samostatné datové složky a pak vytvořte novou verzi datové sady, která bude obsahovat data z této nové složky.
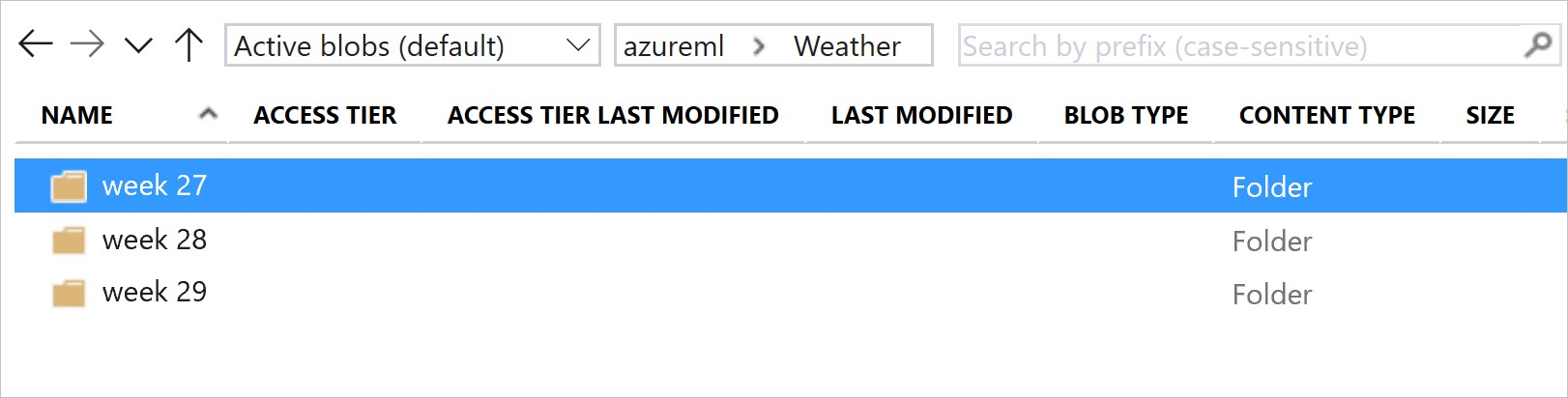
Následující obrázek a ukázkový kód ukazují doporučený způsob strukturování datových složek a vytvoření verzí datových sad, které na tyto složky odkazují:
from azureml.core import Dataset
# get the default datastore of the workspace
datastore = workspace.get_default_datastore()
# create & register weather_ds version 1 pointing to all files in the folder of week 27
datastore_path1 = [(datastore, 'Weather/week 27')]
dataset1 = Dataset.File.from_files(path=datastore_path1)
dataset1.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27',
create_new_version = True)
# create & register weather_ds version 2 pointing to all files in the folder of week 27 and 28
datastore_path2 = [(datastore, 'Weather/week 27'), (datastore, 'Weather/week 28')]
dataset2 = Dataset.File.from_files(path = datastore_path2)
dataset2.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27, 28',
create_new_version = True)
Verze výstupní datové sady kanálu ML
Datovou sadu můžete použít jako vstup a výstup každého kroku kanálu ML . Při opětovném spuštění kanálů se výstup každého kroku kanálu zaregistruje jako nová verze datové sady.
Kanály ML naplní výstup každého kroku do nové složky při každém opětovném spuštění kanálu. Toto chování umožňuje reprodukovat výstupní datové sady se správou verzí. Přečtěte si další informace o datových sadách v kanálech.
from azureml.core import Dataset
from azureml.pipeline.steps import PythonScriptStep
from azureml.pipeline.core import Pipeline, PipelineData
from azureml.core. runconfig import CondaDependencies, RunConfiguration
# get input dataset
input_ds = Dataset.get_by_name(workspace, 'weather_ds')
# register pipeline output as dataset
output_ds = PipelineData('prepared_weather_ds', datastore=datastore).as_dataset()
output_ds = output_ds.register(name='prepared_weather_ds', create_new_version=True)
conda = CondaDependencies.create(
pip_packages=['azureml-defaults', 'azureml-dataprep[fuse,pandas]'],
pin_sdk_version=False)
run_config = RunConfiguration()
run_config.environment.docker.enabled = True
run_config.environment.python.conda_dependencies = conda
# configure pipeline step to use dataset as the input and output
prep_step = PythonScriptStep(script_name="prepare.py",
inputs=[input_ds.as_named_input('weather_ds')],
outputs=[output_ds],
runconfig=run_config,
compute_target=compute_target,
source_directory=project_folder)
Sledování dat v experimentech
Azure Machine Learning sleduje vaše data v celém experimentu jako vstupní a výstupní datové sady.
Následují scénáře, ve kterých se vaše data sledují jako vstupní datová sada.
DatasetConsumptionConfigJako objekt prostřednictvím parametruinputsneboargumentsobjektuScriptRunConfigpři odesílání úlohy experimentu.Když se ve skriptu volají metody jako get_by_name() nebo get_by_id(). V tomto scénáři se zobrazí název přiřazený datové sadě, když jste ji zaregistrovali v pracovním prostoru.
Následují scénáře, ve kterých se vaše data sledují jako výstupní datová sada.
Při odesílání úlohy experimentu
OutputFileDatasetConfigpředejte objekt prostřednictvím parametruoutputsneboarguments.OutputFileDatasetConfigObjekty se dají použít také k uchování dat mezi kroky kanálu. Viz Přesun dat mezi kroky kanálu ML.Zaregistrujte ve skriptu datovou sadu. V tomto scénáři se zobrazí název přiřazený datové sadě, když jste ji zaregistrovali v pracovním prostoru. V následujícím příkladu je název,
training_dskterý by se zobrazil.training_ds = unregistered_ds.register(workspace = workspace, name = 'training_ds', description = 'training data' )Odeslání podřízené úlohy s neregistrovanou datovou sadou ve skriptu Výsledkem je anonymní uložená datová sada.
Trasování datových sad v úlohách experimentů
Pro každý experiment Služby Machine Learning můžete snadno sledovat datové sady použité jako vstup s objektem experimentu Job .
Následující kód používá metodu get_details() ke sledování, které vstupní datové sady byly použity při spuštění experimentu:
# get input datasets
inputs = run.get_details()['inputDatasets']
input_dataset = inputs[0]['dataset']
# list the files referenced by input_dataset
input_dataset.to_path()
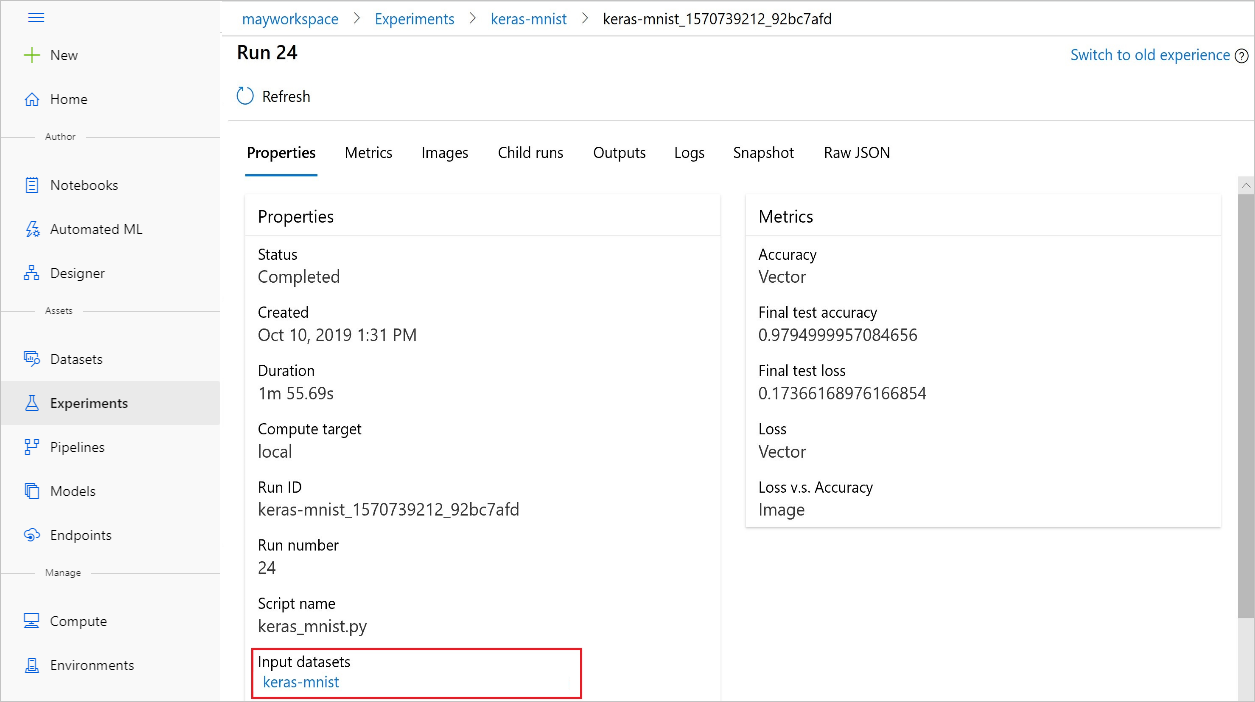
Experimenty můžete najít input_datasets také pomocí studio Azure Machine Learning.
Následující obrázek ukazuje, kde najít vstupní datovou sadu experimentu na studio Azure Machine Learning. V tomto příkladu přejděte do podokna Experimenty a otevřete kartu Vlastnosti pro konkrétní spuštění experimentu keras-mnist.
K registraci modelů v datových sadách použijte následující kód:
model = run.register_model(model_name='keras-mlp-mnist',
model_path=model_path,
datasets =[('training data',train_dataset)])
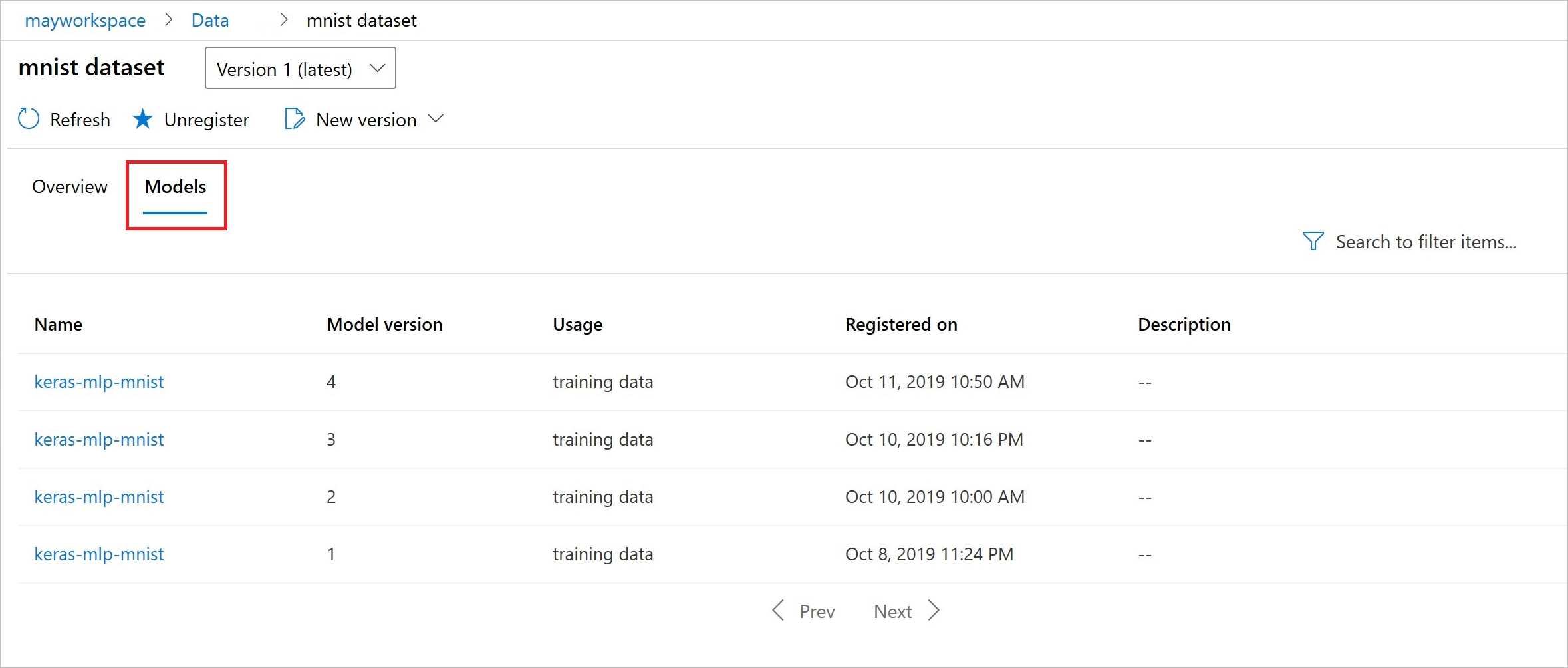
Po registraci můžete zobrazit seznam modelů zaregistrovaných v datové sadě pomocí Pythonu nebo přejít do studia.
Následující zobrazení je z podokna Datové sady v části Prostředky. Vyberte datovou sadu a pak na kartě Modely zobrazte seznam modelů zaregistrovaných v datové sadě.