Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Spravovaná instance Azure pro Apache Cassandra poskytuje automatizované operace nasazení a škálování pro spravovaná opensourcová datacentra Apache Cassandra. Tato funkce urychluje hybridní scénáře a pomáhá snižovat průběžnou údržbu.
Tento rychlý start ukazuje, jak pomocí webu Azure Portal vytvořit plně spravovaný cluster Apache Spark ve virtuální síti Azure vašeho clusteru Azure Managed Instance for Apache Cassandra. Cluster Spark vytvoříte v Azure Databricks. Později můžete vytvářet nebo připojovat poznámkové bloky ke clusteru, číst data z různých zdrojů dat a analyzovat přehledy.
Další informace najdete v podrobných pokynech k nasazení Azure Databricks ve virtuální síti Azure (injektáž virtuální sítě).
Požadavky
Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet.
Vytvoření clusteru Azure Databricks
Pomocí následujícího postupu vytvořte cluster Azure Databricks ve virtuální síti, která má spravovanou instanci Azure pro Apache Cassandra:
Přihlaste se k portálu Azure.
V levém podokně vyhledejte skupiny prostředků. Přejděte do skupiny prostředků, která obsahuje virtuální síť, ve které je nasazená spravovaná instance.
Otevřete prostředek virtuální sítě a poznamenejte si adresní prostor.
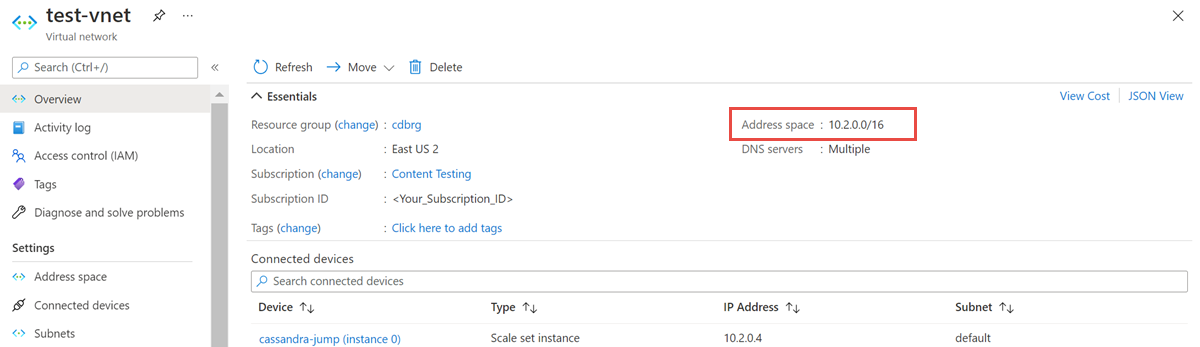
Ve skupině prostředků vyberte Přidat a vyhledat Azure Databricks ve vyhledávacím poli.
Výběrem možnosti Vytvořit vytvořte účet Azure Databricks.
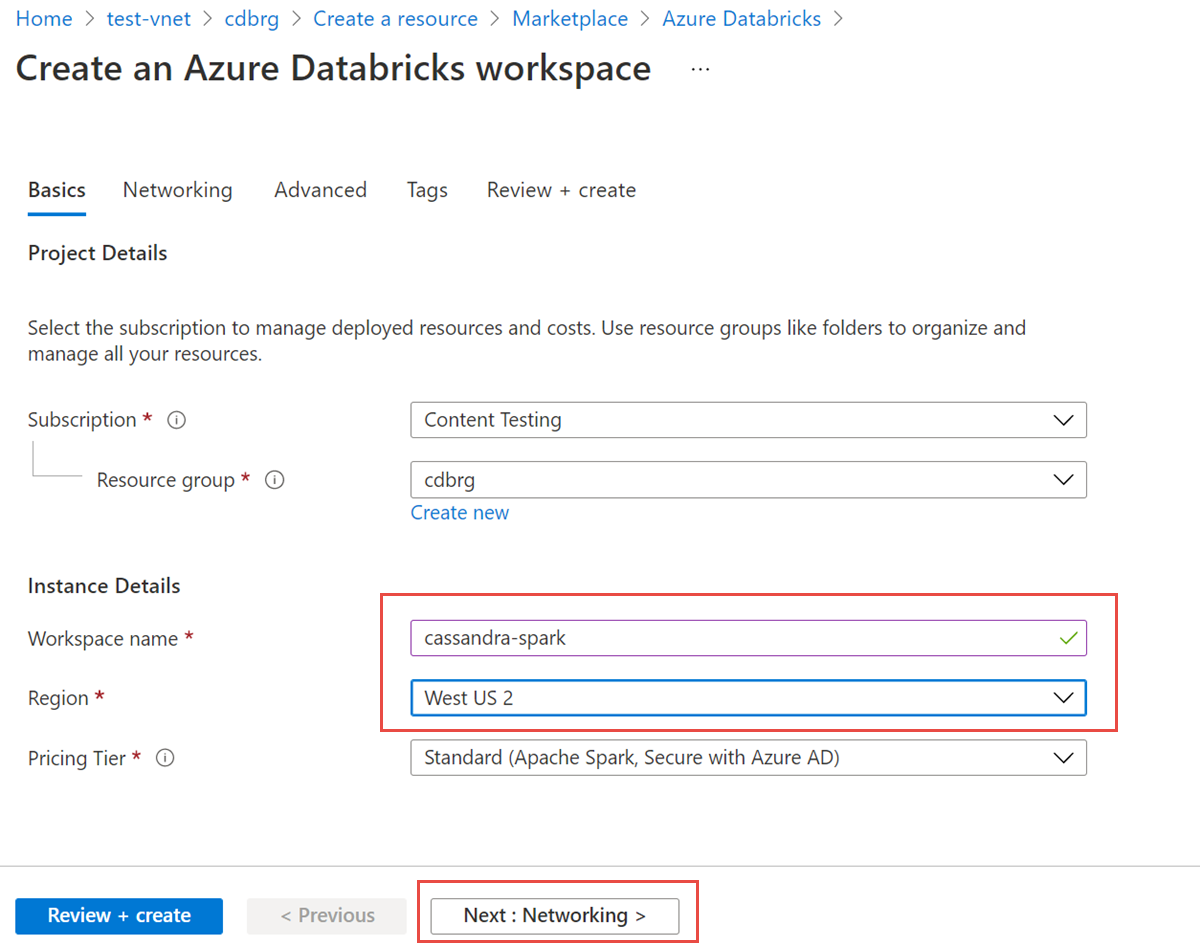
Zadejte následující hodnoty:
- Název pracovního prostoru: Zadejte název pracovního prostoru Azure Databricks.
- Oblast: Nezapomeňte vybrat stejnou oblast jako virtuální síť.
- Cenová úroveň: Vyberte Standard, Premium nebo Zkušební verzi. Další informace o těchto úrovních najdete na stránce s cenami Azure Databricks.
Vyberte kartu Sítě a zadejte následující podrobnosti:
- Nasazení pracovního prostoru Azure Databricks ve virtuální síti: Vyberte Ano.
- Virtuální síť: V rozevíracím seznamu zvolte virtuální síť, ve které existuje vaše spravovaná instance.
- Název veřejné podsítě: Zadejte název veřejné podsítě.
- Rozsah CIDR veřejné podsítě: Zadejte rozsah IP adres pro veřejnou podsíť.
- Název privátní podsítě: Zadejte název privátní podsítě.
- Rozsah CIDR privátní podsítě: Zadejte rozsah IP adres privátní podsítě.
Abyste se vyhnuli kolizím rozsahů, ujistěte se, že vyberete vyšší rozsahy. V případě potřeby rozdělte rozsahy pomocí vizuální kalkulačky podsítě.
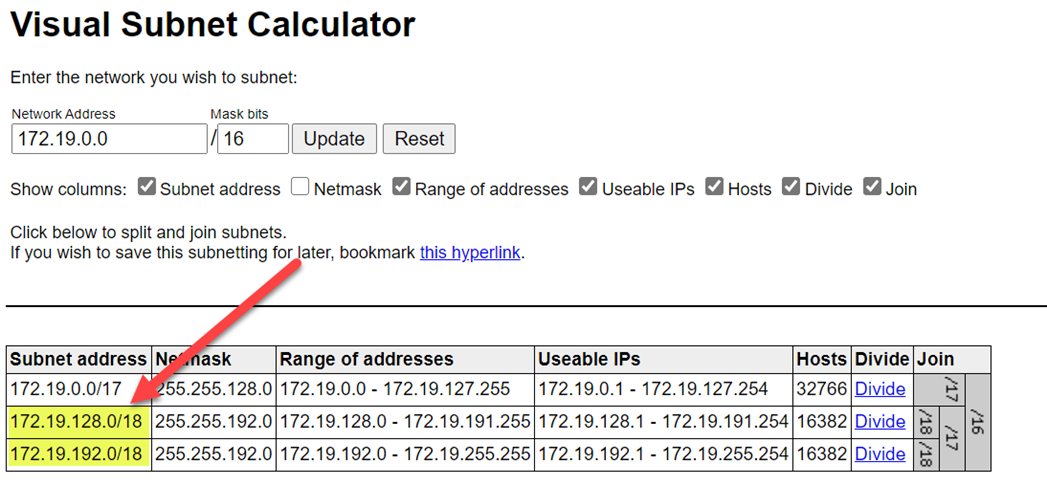
Následující snímek obrazovky ukazuje ukázkové podrobnosti v podokně sítě.
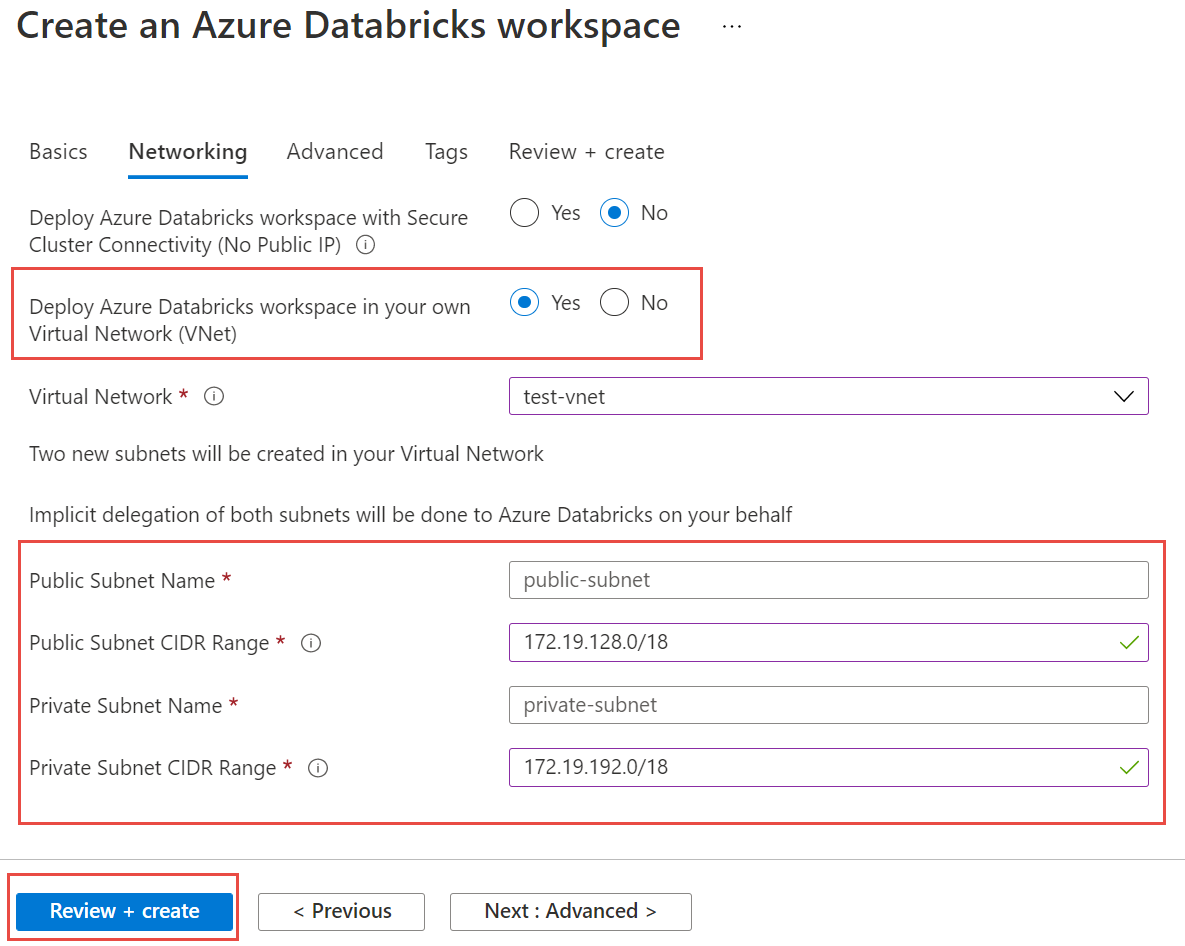
Vyberte Zkontrolovat a vytvořit a pak vyberte Vytvořit a nasaďte pracovní prostor.
Po vytvoření pracovního prostoru otevřete pracovní prostor.
Budete přesměrováni na portál Azure Databricks. Na portálu vyberte Nový cluster.
V podokně Nový cluster přijměte výchozí hodnoty pro všechna jiná pole než následující pole:
- Název clusteru: Zadejte název clusteru.
- Verze modulu Runtime Databricks: Pro podporu Sparku 3.x doporučujeme vybrat modul runtime Azure Databricks verze 7.5 nebo novější.
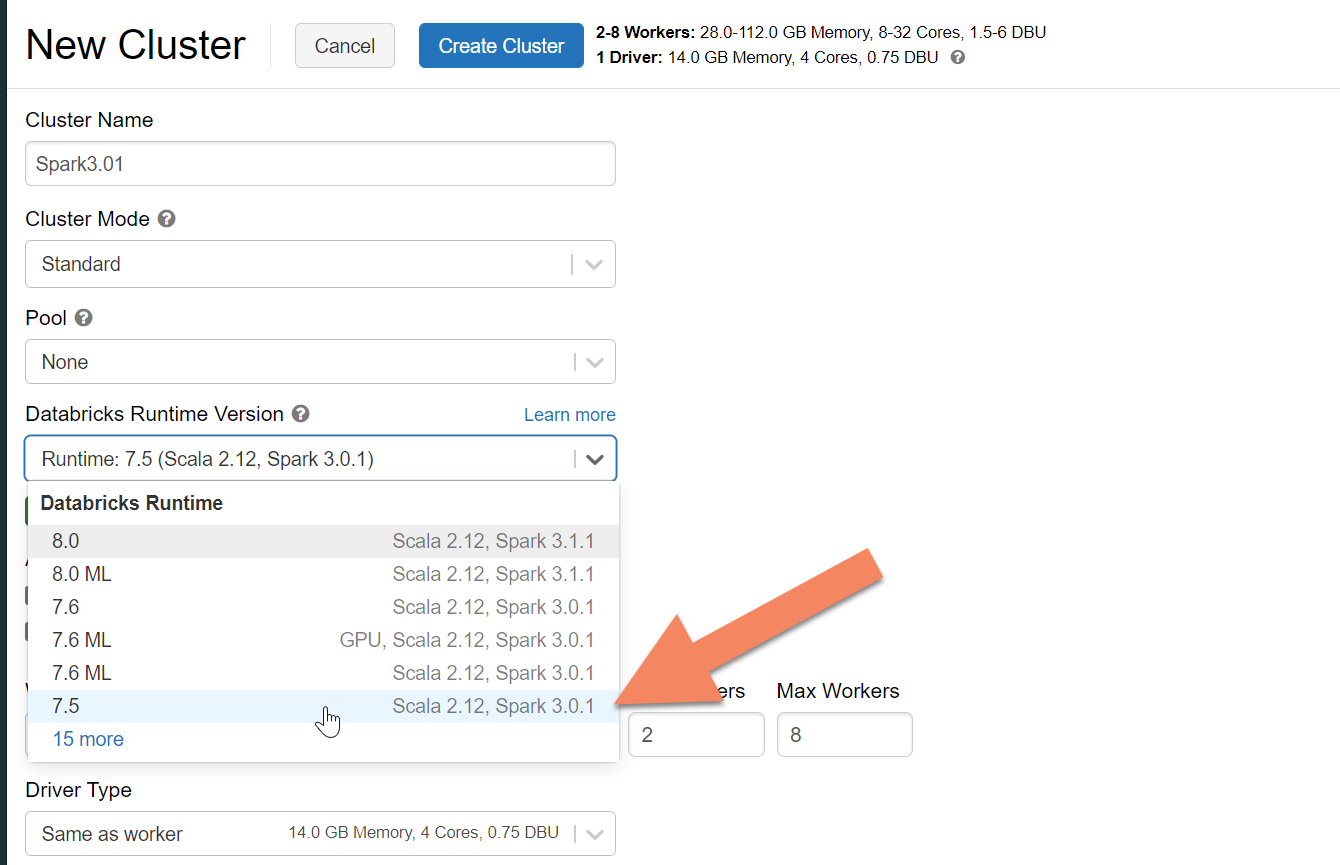
Rozbalte rozšířené možnosti a přidejte následující konfiguraci. Nezapomeňte nahradit IP adresy a přihlašovací údaje uzlu.
spark.cassandra.connection.host <node1 IP>,<node 2 IP>, <node IP> spark.cassandra.auth.password cassandra spark.cassandra.connection.port 9042 spark.cassandra.auth.username cassandra spark.cassandra.connection.ssl.enabled truePřidejte do clusteru knihovnu konektoru Apache Spark Cassandra pro připojení k nativním i koncovým bodům Cassandra služby Azure Cosmos DB. V clusteru vyberte Knihovny>Nainstalovat nové>Maven a pak přidejte
com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0do pole souřadnic Maven.
Vyberte volbu Instalovat.
Vyčištění prostředků
Pokud nebudete dál používat tento cluster spravovaných instancí, odstraňte ho následujícím postupem:
- V levé nabídce webu Azure Portal vyberte skupiny prostředků.
- V seznamu vyberte skupinu prostředků, kterou jste vytvořili pro účely tohoto rychlého startu.
- V podokně Přehled skupiny prostředků vyberte Odstranit skupinu prostředků.
- V dalším podokně zadejte název skupiny prostředků, která se má odstranit, a pak vyberte Odstranit.
Další krok
V tomto rychlém startu jste zjistili, jak vytvořit plně spravovaný cluster Apache Spark ve virtuální síti clusteru Azure Managed Instance for Apache Cassandra. Dále se dozvíte, jak spravovat prostředky clusteru a datacentra.