Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Spravovaný HSM služby Azure Key Vault je plně spravovaná, vysoce dostupná cloudová služba kompatibilní s jedním tenantem, která umožňuje chránit kryptografické klíče pro cloudové aplikace pomocí ověřených modulů hardwarového zabezpečení (HSM) standardu FIPS 140-3 Level 3. Spravovaný HSM poskytuje řadu integrovaných funkcí spolehlivosti, které vám pomůžou zajistit, aby vaše klíče zůstaly dostupné.
Při používání Azure je spolehlivost sdílenou odpovědností. Microsoft nabízí celou řadu možností, které podporují odolnost a obnovení. Zodpovídáte za pochopení toho, jak tyto možnosti fungují ve všech službách, které používáte, a výběrem možností, které potřebujete ke splnění vašich obchodních cílů a cílů dostupnosti.
Tento článek popisuje, jak je spravovaný HSM odolný vůči nejrůznějším potenciálním výpadkům a problémům, včetně přechodných chyb, selhání hardwaru a výpadků oblastí. Popisuje také, jak můžete použít zálohy a doménu zabezpečení k zotavení z jiných typů problémů, funkcí obnovení, aby se zabránilo náhodnému odstranění, a zvýrazní některé klíčové informace o smlouvě o úrovni služeb spravovaného HSM (SLA).
Doporučení pro produkční nasazení pro spolehlivost
Pro produkční úlohy doporučujeme:
- Okamžitě po zřízení spravovaného HSM stáhněte a bezpečně uložte doménu zabezpečení . Pro zotavení po havárii se vyžaduje doména zabezpečení.
- Vytvořte kvorum více osob alespoň se třemi držiteli klíčů pro zabezpečovací doménu.
- Povolte ochranu před vymazáním , abyste zabránili náhodnému nebo škodlivému odstranění.
- Implementujte pravidelné zálohy do účtu služby Azure Storage a v podporovaných oblastech používejte geograficky redundantní úložiště.
- Pro klíčové úlohy, které vyžadují vyšší smlouvu SLA, povolte replikaci ve více oblastech.
Přehled architektury spolehlivosti
Při použití spravovaného HSM nasadíte instanci, která se také někdy označuje jako fond.
Spravovaný HSM je navržený pro vysokou dostupnost a odolnost prostřednictvím své architektury:
Izolace s jedním tenantem: Každá spravovaná instance HSM je vyhrazená jednomu zákazníkovi a skládá se z clusteru několika oddílů HSM, které jsou kryptograficky izolované.
Trojinásobně redundantní oddíly: Spravovaný fond HSM se skládá ze tří oddílů HSM s vyrovnáváním zatížení distribuovaných mezi samostatné racky v rámci datacentra. Tato distribuce poskytuje redundanci proti selhání hardwaru a zajišťuje, že ztráta jedné komponenty (například napájecího zdroje racku nebo síťového přepínače) nemá vliv na všechny oddíly.
Důvěrné výpočty: Každá instance služby běží v důvěryhodném spouštěcím prostředí (TEE), které používá enklávy Intel SGX. Pracovníci Microsoftu, včetně těch, kteří mají fyzický přístup k serverům, nemají přístup k vašemu kryptografickému klíči.
Automatické opravy: Pokud selhání hardwaru nebo jiný problém ovlivní jeden ze tří oddílů, služba automaticky znovu sestaví ovlivněný oddíl na hardwaru, který je v pořádku, bez zásahu zákazníka a bez vystavení tajných kódů.
Další informace o tom, jak spravované HSM tyto funkce implementuje, najdete v tématu Klíčová suverenita, dostupnost, výkon a škálovatelnost ve spravovaném HSM.
Doména zabezpečení
Doména zabezpečení je důležitou součástí pro zotavení po havárii. Jedná se o šifrovaný objekt blob, který obsahuje všechny přihlašovací údaje potřebné k opětovnému sestavení spravované instance HSM od začátku, včetně klíče vlastníka oddílu, přihlašovacích údajů oddílu, klíče pro zabalení dat a počáteční zálohy HSM.
Important
Bez domény zabezpečení není zotavení po havárii možné. Microsoft nemá žádný způsob, jak obnovit doménu zabezpečení a nemá přístup k vašim klíčům bez ní.
Domény zabezpečení jsou důležitou součástí zabezpečení a spolehlivosti spravovaného HSM. Doporučujeme postupovat podle těchto osvědčených postupů:
- Bezpečné generování klíčů: V produkčních prostředích vygenerujte páry klíčů RSA, které chrání doménu zabezpečení v prostředí s mezerou vzduchu (jako je místní HSM nebo izolovaná pracovní stanice).
- Uložení offline: Ukládejte klíče domény zabezpečení na šifrovaných USB discích nebo jiném offline úložišti, přičemž každá sdílená složka klíčů je na samostatném zařízení v samostatných geografických umístěních.
- Vytvoření kvora s více osobami: Použijte aspoň tři vlastníky klíčů, abyste zabránili všem osobám v přístupu ke všem klíčům kvora a vyhnuli se závislosti na jedné osobě.
Další informace najdete v tématu Přehled domény zabezpečení ve spravovaném HSM.
Odolnost proti přechodným chybám
Přechodné chyby jsou krátká, přerušovaná selhání ve složkách. V distribuovaném prostředí, jako je cloud, se vyskytují často a jsou normální součástí provozu. Přechodné chyby se opravují po krátké době. Je důležité, aby vaše aplikace mohly zpracovávat přechodné chyby, obvykle opakováním ovlivněných požadavků.
Všechny aplikace hostované v cloudu by měly postupovat podle Azure pokynů pro zpracování přechodných chyb, když komunikují s libovolnými rozhraními API, databázemi a dalšími komponentami hostovanými v cloudu. Další informace najdete v tématu Doporučení pro zpracování přechodných chyb.
Pokud používáte služby Azure, které se integrují se spravovaným HSM, tyto služby zpracovávají přechodné chyby automaticky.
Pokud vytváříte vlastní aplikace, které se integrují se spravovaným HSM, zvažte následující osvědčené postupy pro zpracování přechodných chyb, ke kterým může dojít:
Použijte sady SDK poskytované Microsoftem pro Azure Key Vault, které zahrnují integrované mechanismy opakování. Sady SDK jsou k dispozici pro .NET, Python a JavaScript.
Implementujte logiku opakovaného pokusu při přímé interakci se spravovaným HSM, včetně zásad exponenciálního záložního opakování.
Snižte počet přímých závislostí na spravovaném HSM. Ukládejte výsledky kryptografických operací do mezipaměti, pokud je to možné, aby se snížily přímé požadavky na spravované HSM. Pro operace veřejného klíče, jako je šifrování, zabalení a ověření, proveďte tyto operace místně uložením do mezipaměti materiálu veřejného klíče. Provádění operací místně snižuje závislosti na Managed HSM a zabraňuje přechodným chybám, které by mohly přerušit tyto operace.
Pokud používáte spravované HSM ve scénářích s vysokou propustností, mějte na paměti, že spravovaný HSM neomezuje kryptografické operace. Využívá svůj hardware HSM k plné kapacitě. Každá spravovaná instance HSM má tři oddíly. Během operací údržby nebo opravy může být jeden oddíl nedostupný. Při plánování kapacity je třeba předpokládat, že jsou k dispozici dva oddíly. Pokud požadujete zaručenou propustnost, naplánujte plán na základě dostupného jednoho oddílu. Monitorujte metriku dostupnosti spravovaného HSM, abyste porozuměli stavu služby.
Pro škálování šifrování velkých objemů dat použijte hierarchii klíčů, ve které je uložený pouze šifrovací klíč klíče (KEK) ve spravovaném HSM a slouží k zabalení klíčů nižší úrovně uložených v jiném zabezpečeném umístění úložiště klíčů.
Podrobné pokyny k srovnávacím testům výkonu a plánování kapacity najdete v pokynech ke škálování spravovaného HSM v Azure.
Odolnost vůči selháním při rozdělení systému
Spravovaný HSM dosahuje vysoké dostupnosti prostřednictvím trojité redundantní architektury, kde se každý fond HSM skládá ze tří oddílů HSM distribuovaných mezi samostatné serverové racky v rámci datacentra. Tato distribuce na úrovni racku poskytuje redundanci vůči lokalizovaným selháním hardwaru.
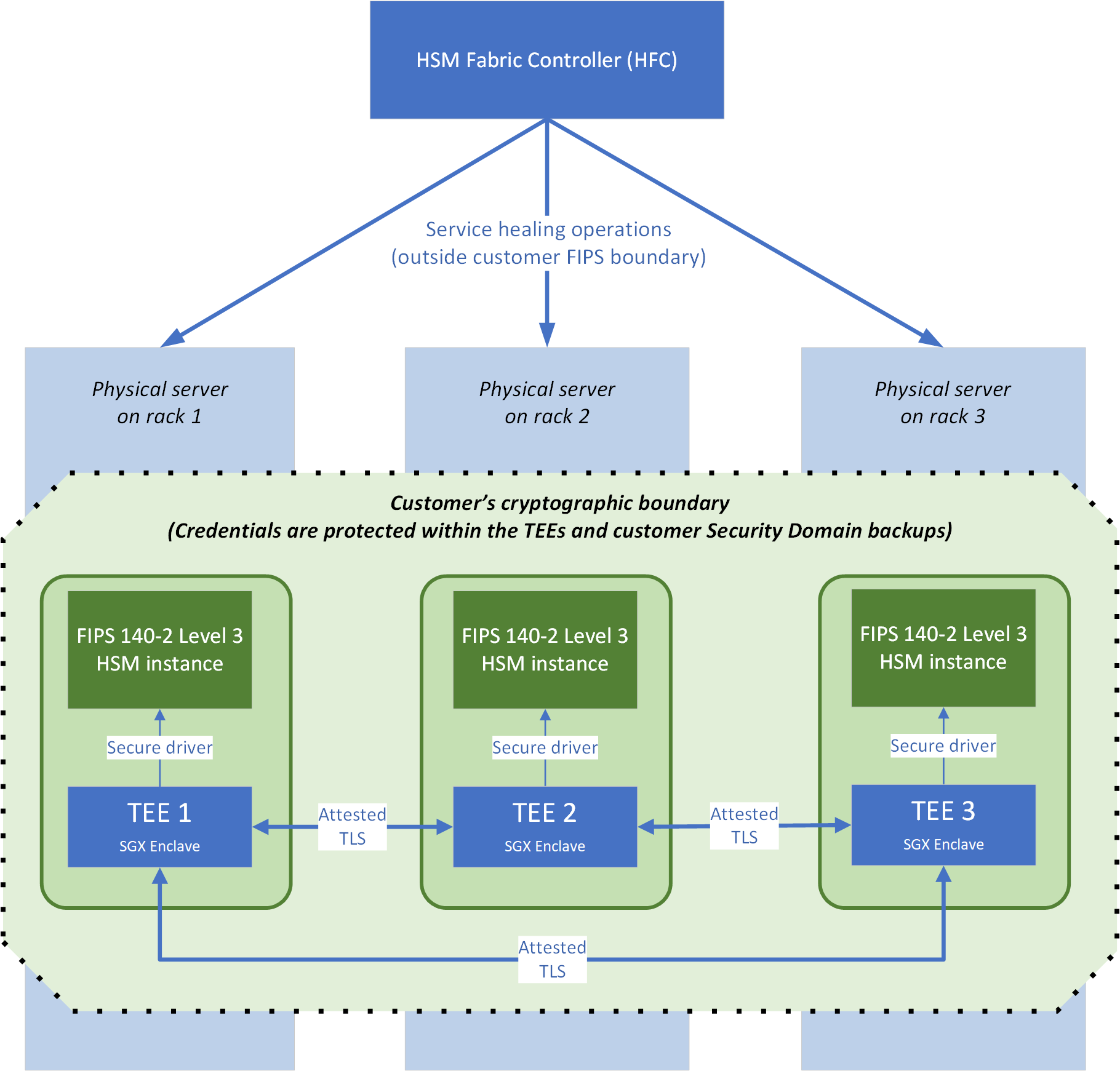
Diagram, znázorňující tři oddíly spravovaného HSM fondu, každý na samostatném fyzickém serveru a v jiném serverovém racku.
Pokud dojde k selhání hardwaru nebo lokalizovaným výpadkům, spravovaný HSM automaticky přesměruje vaše požadavky na oddíly, které jsou v pořádku, a znovu sestaví ovlivněné oddíly prostřednictvím procesu označovaného jako oprava důvěrných služeb. Selhané oddíly jsou automaticky znovu sestavovány na spolehlivém hardwaru pomocí atestovaných TLS a enkláv Intel SGX k ochraně tajemství během obnovy.
Cost
S integrovanou vysokou dostupností ve spravovaném HSM nejsou spojené žádné další náklady. Ceny vycházejí z počtu fondů HSM a počtu provedených operací. Další informace najdete v tématu Ceny spravovaného HSM v Azure.
Chování, když jsou všechny oddíly zdravé
Tato část popisuje, co očekávat, když jsou spravované fondy HSM funkční a nejsou k dispozici žádné oddíly.
Směrování provozu: Spravovaný HSM automaticky spravuje směrování provozu napříč třemi oddíly. Během normálních operací se požadavky transparentně distribuují napříč oddíly.
Replikace dat: Všechna data, včetně klíčů, přiřazení rolí a zásad řízení přístupu, se synchronně replikují napříč všemi třemi oddíly. Tím zajistíte konzistenci a dostupnost i v případě, že oddíl přestane být dostupný.
Chování při selhání oddílu
Tato část popisuje, co očekávat, když jeden nebo více oddílů není dostupný.
Detekce a odpověď: Spravovaná služba HSM zodpovídá za zjišťování selhání oddílů a automatické reakce na ně. Během selhání oddílu nemusíte provádět žádnou akci.
Aktivní požadavky: Během selhání oddílu mohou požadavky směřující k ovlivněnému oddílu selhat a vyžadovat, aby je klientské aplikace zkusily zopakovat. Aby se minimalizovaly dopady výpadků oddílů, klientské aplikace by měly dodržovat praktiky zpracování přechodných chyb.
Očekávaná ztráta dat: Během selhání diskového oddílu se neočekává žádná ztráta dat kvůli synchronní replikaci mezi oddíly.
Očekávaný výpadek: U operací čtení a většiny kryptografických operací by během selhání oddílu mělo dojít k minimálnímu nebo žádnému výpadku. Zbývající oddíly, které jsou v pořádku, nadále obsluhují požadavky.
Přesměrování provozu: Spravovaný HSM automaticky směruje provoz z ovlivněného oddílu na oddíly, které jsou v pořádku, aniž by vyžadoval zásah zákazníka.
Obnovení oddílů
Když se ovlivněný oddíl obnoví, spravovaný HSM automaticky obnoví operace prostřednictvím opravy důvěrných služeb. Tento proces:
- Vytvoří novou instanci služby na hardwaru, který je v pořádku.
- Navazuje ověřené připojení TLS s primární partí.
- Bezpečně vyměňuje přihlašovací údaje a kryptografický materiál.
- Uzamkne data služby pro nový procesor.
Platforma Azure tento proces plně spravuje a nevyžaduje žádný zásah zákazníka.
Odolnost proti chybám zóny dostupnosti
Vysoká dostupnost spravovaného HSM je založená na distribuci na úrovni racku v datacentru, nikoli explicitním nasazením zóny dostupnosti. Každý oddíl běží na samostatném serveru v jiném racku, který chrání před selháním na úrovni racku, jako jsou problémy s napájením nebo síťovým přepínačem.
Pokud potřebujete být odolní vůči výpadkům v rámci datového centra nebo zóny dostupnosti, zvažte použití jednoho z přístupů k odolnosti vůči selháním v celé oblasti.
Odolnost proti selháním v celé oblasti
Spravované prostředky HSM se nasazují do jedné oblasti Azure. Pokud se oblast stane nedostupnou, váš spravovaný HSM je také nedostupný. Existují ale přístupy, které vám pomůžou zajistit odolnost vůči výpadkům oblastí.
Replikace ve více oblastech
Managed HSM podporuje volitelnou replikaci ve více oblastech, která umožňuje rozšířit fond spravovaných HSM z jedné oblasti Azure ( primární oblasti) do druhé oblasti Azure ( rozšířené oblasti). Po nakonfigurování:
- Oba regiony jsou aktivní a jsou schopné reagovat na žádosti.
- Mezi oblastmi se automaticky replikují klíčové materiály, role a oprávnění.
- Požadavky se směrují do nejbližší dostupné oblasti pomocí Azure Traffic Manageru.
- Úroveň kombinované SLA se zvyšuje.
Requirements
Podpora oblastí: Všechny oblasti spravované HSM Azure se podporují jako primární oblasti. Není žádná závislost na párování oblastí Azure.
Managed HSM nepodporuje všechny oblasti jako rozšířené oblasti. Další informace najdete v tématu Podpora oblastí Azure.
Maximální počet oblastí: Pro maximálně dvě oblasti můžete přidat jednu rozšířenou oblast.
Cost
Replikace ve více oblastech způsobuje další fakturaci, protože v rozšířené oblasti se spotřebovává druhý fond HSM. Další informace najdete v tématu Ceny spravovaného HSM v Azure.
Konfigurace replikace ve více oblastech
Přidejte rozšířenou oblast: Podrobnosti o přidání rozšířené oblasti do existující primární oblasti najdete v tématu Rozšíření primárního HSM do rozšířené oblasti.
Rozšíření spravovaného HSM do jiné oblasti může trvat až 30 minut.
Odebrání rozšířené oblasti: Podrobnosti o odebrání rozšířené oblasti z existující primární oblasti najdete v tématu Odebrání rozšířené oblasti z primárního HSM.
Chování, když jsou všechny oblasti v pořádku
Pokud je povolená replikace ve více oblastech a obě oblasti jsou funkční:
Směrování provozu: Všechny oblasti můžou obsluhovat požadavky. Azure Traffic Manager směruje požadavky do oblasti s nejbližší geografickou blízkostí nebo nejnižší latencí.
Pokud používáte Private Link, nakonfigurujte privátní koncové body v obou oblastech pro optimální směrování během převzetí služeb. Další informace najdete v tématu Chování privátního propojení s replikací ve více oblastech.
Replikace dat: Všechny změny klíčů, definic rolí a přiřazení rolí se replikují asynchronně do rozšířené oblasti během šesti minut. Před použitím klíče v rozšířené oblasti počkejte šest minut po vytvoření nebo aktualizaci klíče.
Chování při selhání oblasti
Pokud je povolená replikace ve více oblastech a u jedné oblasti dojde k výpadku:
- Detekce a odpověď: Azure Traffic Manager detekuje oblast, která není v pořádku, a směruje budoucí požadavky do oblasti, která je v pořádku. Záznamy DNS mají pětisekundové TTL, i když klienti, kteří ukládají vyhledávání DNS do mezipaměti, mohou zaznamenat mírné prodloužení doby přepnutí na zálohu.
- Oznámení: Microsoft vás při výpadku oblasti automaticky neoznámí. Můžete ale použít Azure Service Health, abyste porozuměli celkovému stavu služby, včetně jakýchkoli selhání oblastí, a můžete nastavit upozornění služby Služba Health, která vás upozorní na problémy.
Aktivní žádosti: Žádosti v testovacích verzích do ovlivněné oblasti můžou selhat a vyžadovat opakování.
Očekávaná ztráta dat: Pokud tyto změny nedokončily replikaci, může dojít ke ztrátě dat během šesti minut před selháním oblasti.
Očekávaný výpadek: Operace čtení i zápisu zůstanou dostupné v neporušené oblasti během převzetí služeb při selhání.
Klientské aplikace, které jsou blízko oblasti, které nejsou v pořádku, můžou být dál směrovány do této oblasti, dokud se neaktualizují záznamy DNS, ale tato aktualizace probíhá přibližně během pěti sekund. Aby se minimalizovala doba při selhání, klienti by se měli vyhnout ukládání výsledků vyhledávání DNS do mezipaměti na dobu delší, než je TTL záznamu DNS.
Přesměrování: Azure Traffic Manager automaticky směruje požadavky do oblasti, která je v pořádku.
Obnovení oblasti
Když se ovlivněná oblast obnoví, spravovaný HSM automaticky obnoví operace. Traffic Manager začne znovu směrovat požadavky do obou oblastí na základě blízkosti.
Testování selhání regionů
Spravovaný HSM plně spravuje směrování provozu, převzetí služeb při selhání a obnovení služeb pro selhání regionů, takže nemusíte ověřovat procesy selhání regionů ani poskytovat další vstup.
Vlastní řešení pro více regionů pro odolnost systémů
Pokud replikace ve více oblastech není vhodná pro vaše potřeby, můžete implementovat ruční zotavení po havárii. To vyžaduje:
- Doména zabezpečení zdrojového HSM.
- Privátní klíče (alespoň číslo kvora), které šifrují doménu zabezpečení.
- Nedávná úplná záloha HSM ze zdrojového HSM.
Postup zotavení po havárii:
- Vytvořte novou spravovanou instanci HSM v jiné oblasti.
- Aktivujte režim obnovení domény zabezpečení a nahrajte doménu zabezpečení.
- Vytvořte zálohu nového HSM (vyžaduje se před obnovením).
- Obnovte zálohu ze zdrojového HSM.
Important
Nový HSM má jiný název a identifikátor URI koncového bodu služby. Abyste mohli používat nové umístění, musíte aktualizovat konfiguraci aplikace.
Podrobné postupy zotavení po havárii najdete v tématu Zotavení po havárii spravovaného HSM.
Zálohování a obnovení
Managed HSM podporuje úplné zálohování a obnovení všech klíčů, verzí, atributů, značek a přiřazení rolí. Zálohy se ukládají do účtu Azure Storage. Pokud ji vaše oblast podporuje, doporučujeme zálohovat spravovaný HSM do účtu služby Azure Storage, který má povolené geograficky redundantní úložiště (GRS).
Zálohy se šifrují pomocí kryptografických klíčů přidružených k doméně zabezpečení HSM a je možné je obnovit jenom do HSM se stejnou doménou zabezpečení.
Spravovaný HSM nepodporuje plánování záloh, ale můžete vytvořit vlastní plánovač pomocí služby, jako je Azure Functions nebo Azure Automation.
Zatímco probíhá zálohování, hsm nemusí fungovat s plnou propustností, protože některé oddíly jsou zaneprázdněné prováděním operace zálohování.
Podrobné postupy zálohování a obnovení najdete v tématu Úplné zálohování a obnovení.
Odolnost proti náhodnému odstranění
Managed HSM poskytuje dvě funkce obnovení klíčů, které brání náhodnému nebo škodlivému odstranění:
Měkké odstranění: Když odstraníte HSM nebo klíč, zůstane obnovitelný po konfigurovatelnou dobu uchovávání (7 až 90 dnů, výchozí 90 dnů). Měkké odstranění je vždy povolené a nelze jej zakázat.
Note
Obnovitelné odstraněné spravované prostředky HSM se budou dál účtovat, dokud se nevyprázdní.
Ochrana před vymazáním: Pokud je tato možnost povolená, zabrání trvalému odstranění spravovaného HSM a jeho klíčů, dokud neuplyne doba uchovávání. Ochranu před vymazáním nejde zakázat ani přepsat nikdo, včetně Microsoftu.
Důrazně doporučujeme povolit ochranu před vymazáním pro produkční prostředí. Další informace naleznete v článku Měkké odstranění a ochrana proti vymazání u spravovaného HSM.
Odolnost vůči údržbě služeb
Spravovaný HSM zpracovává údržbu služeb, včetně aktualizací firmwaru, oprav a oprav hardwaru bez zásahu zákazníka. Během údržby:
- Oddíly můžou být během instalace aktualizací dočasně nedostupné.
- Během běžné údržby zůstanou k dispozici alespoň dva ze tří oddílů.
- Klientské aplikace by měly implementovat logiku opakování pro zpracování krátkých přerušení.
Proces zajištění integrity důvěrných služeb zajišťuje, že tajemství nebudou během operací údržby nikdy vystavena.
Smlouva o úrovni služeb
Smlouva o úrovni služeb (SLA) pro služby Azure popisuje očekávanou dostupnost každé služby a podmínky, které musí vaše řešení splnit, aby bylo dosaženo očekávané dostupnosti. Další informace najdete v tématu Smlouvy SLA pro online služby.
Managed HSM poskytuje standardní smlouvu SLA pro nasazení v jedné oblasti. Když povolíte replikaci ve více oblastech, kombinovaná smlouva SLA pro obě oblasti se zvýší.