Nastavení vysoké dostupnosti v SUSE pomocí oplocení
V tomto článku si projdeme kroky nastavení vysoké dostupnosti (HA) ve velkých instancích HANA v operačním systému SUSE pomocí oplocení zařízení.
Poznámka
Tato příručka je odvozena od úspěšného testování instalace v prostředí Microsoft HANA Large Instances. Tým pro správu služeb Microsoftu pro velké instance HANA nepodporuje operační systém. Pokud chcete řešit potíže nebo objasnit informace o vrstvě operačního systému, obraťte se na SUSE.
Tým pro správu služeb Microsoftu zařízení nastavuje a plně podporuje. Může vám pomoct při řešení potíží s oplocením zařízení.
Požadavky
Pokud chcete nastavit vysokou dostupnost pomocí clusteringu SUSE, musíte:
- Zřiďte velké instance HANA.
- Nainstalujte a zaregistrujte operační systém s nejnovějšími opravami.
- Připojte servery velkých instancí HANA k serveru SMT a získejte opravy a balíčky.
- Nastavení protokolu NTP (Network Time Protocol)
- Přečtěte si nejnovější dokumentaci k SUSE o nastavení vysoké dostupnosti a seznamte se s tím.
Podrobnosti o nastavení
Tato příručka používá následující nastavení:
- Operační systém: SLES 12 SP1 pro SAP
- Velké instance HANA: 2xS192 (čtyři sokety, 2 TB)
- Verze HANA: HANA 2.0 SP1
- Názvy serverů: sapprdhdb95 (node1) a sapprdhdb96 (node2)
- Oplocení zařízení: založené na iSCSI
- NTP na jednom z uzlů velké instance HANA
Když nastavujete velké instance HANA s replikací systému HANA, můžete požádat, aby tým pro správu služeb Microsoftu nastavil zařízení pro ohraničení. Proveďte to v době zřizování.
Pokud jste stávající zákazník se zřízenými velkými instancemi HANA, můžete zařízení pro oplocení nastavit. Ve formuláři žádosti o službu (SRF) poskytněte týmu microsoftu pro správu služeb následující informace. SRF můžete získat prostřednictvím technického manažera účtů nebo vašeho kontaktu Microsoftu pro onboarding velké instance HANA.
- Název serveru a IP adresa serveru (například myhanaserver1 a 10.35.0.1)
- Umístění (například USA – východ)
- Jméno zákazníka (například Microsoft)
- Identifikátor systému HANA (SID) (například H11)
Po nakonfigurování zařízení pro ohraničení vám tým pro správu služeb Microsoftu poskytne název SBD a IP adresu úložiště iSCSI. Tyto informace můžete použít ke konfiguraci nastavení oplocení.
Postupujte podle kroků v následujících částech a nastavte vysokou dostupnost pomocí zařízení pro oplocení.
Identifikace zařízení SBD
Poznámka
Tato část se vztahuje jenom na stávající zákazníky. Pokud jste novým zákazníkem, tým pro správu služeb Microsoftu vám poskytne název zařízení SBD, takže tuto část přeskočte.
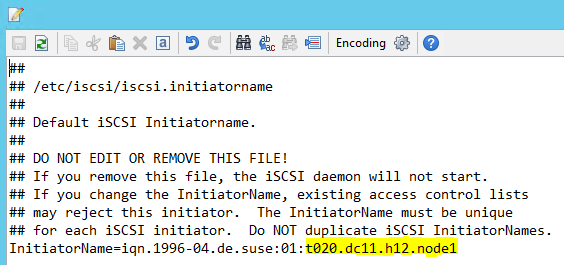
Upravte soubor /etc/iscsi/initiatorname.isci tak, aby:
iqn.1996-04.de.suse:01:<Tenant><Location><SID><NodeNumber>Microsoft Service Management poskytuje tento řetězec. Upravte soubor na obou uzlech. Číslo uzlu se ale na každém uzlu liší.
Upravte soubor /etc/iscsi/iscsid.conf nastavením
node.session.timeo.replacement_timeout=5anode.startup = automatic. Upravte soubor na obou uzlech.Na obou uzlech spusťte následující příkaz zjišťování.
iscsiadm -m discovery -t st -p <IP address provided by Service Management>:3260Výsledky ukazují čtyři relace.

Spuštěním následujícího příkazu na obou uzlech se přihlaste k zařízení iSCSI.
iscsiadm -m node -lVýsledky ukazují čtyři relace.

Pomocí následujícího příkazu spusťte skript rescan-scsi-bus.sh znovu prohledat. Tento skript zobrazí nové disky, které jsou pro vás vytvořené. Spusťte ho na obou uzlech.
rescan-scsi-bus.shVe výsledcích by se mělo zobrazit číslo logické jednotky větší než nula (například 1, 2 atd.).

Pokud chcete získat název zařízení, spusťte na obou uzlech následující příkaz.
fdisk –lVe výsledcích zvolte zařízení s velikostí 178 MiB.

Inicializace zařízení SBD
Pomocí následujícího příkazu inicializujete zařízení SBD na obou uzlech.
sbd -d <SBD Device Name> create
Pomocí následujícího příkazu na obou uzlech zkontrolujte, co se do zařízení zapíše.
sbd -d <SBD Device Name> dump
Konfigurace clusteru SUSE s vysokou dostupností
Pomocí následujícího příkazu zkontrolujte, jestli jsou na obou uzlech nainstalované vzory ha_sles a SAPHanaSR-doc. Pokud nejsou nainstalované, nainstalujte je.
zypper in -t pattern ha_sles zypper in SAPHanaSR SAPHanaSR-doc

Nastavte cluster pomocí
ha-cluster-initpříkazu nebo průvodce yast2. V tomto příkladu používáme průvodce yast2. Tento krok proveďte pouze na primárním uzlu.Přejděte na yast2>High Availability>Cluster.
V dialogovém okně, které se zobrazí o instalaci balíčku hawk, vyberte Zrušit , protože balíček halk2 je již nainstalován.

V dialogovém okně, které se zobrazí o pokračování, vyberte Pokračovat.

Očekávaná hodnota je počet nasazených uzlů (v tomto případě 2). Vyberte Další.
Přidejte názvy uzlů a pak vyberte Přidat navrhované soubory.

Vyberte Zapnout csync2.
Vyberte Generovat předsdílené klíče.
V automaticky otevírané zprávě, která se zobrazí, vyberte OK.

Ověřování se provádí pomocí IP adres a předsdílených klíčů v Csync2. Soubor klíče se vygeneruje pomocí
csync2 -k /etc/csync2/key_hagrouppříkazu .Po vytvoření ručně zkopírujte soubor key_hagroup všem členům clusteru. Nezapomeňte zkopírovat soubor z node1 do node2. Pak vyberte Další.

Ve výchozím nastavení bylo spouštěnívypnuté. Změňte ho na Zapnuto, aby se služba Pacemaker spustila při spuštění. Můžete se rozhodnout na základě vašich požadavků na nastavení.

Vyberte Další a konfigurace clusteru je dokončená.
Nastavení hlídacího zařízení softdog
Přidejte následující řádek do souboru /etc/init.d/boot.local na obou uzlech.
modprobe softdog
Pomocí následujícího příkazu aktualizujte soubor /etc/sysconfig/sbd na obou uzlech.
SBD_DEVICE="<SBD Device Name>"
Spuštěním následujícího příkazu načtěte modul jádra na obou uzlech.
modprobe softdog
Pomocí následujícího příkazu se ujistěte, že je softdog spuštěný na obou uzlech.
lsmod | grep dog
Pomocí následujícího příkazu spusťte zařízení SBD na obou uzlech.
/usr/share/sbd/sbd.sh start
Pomocí následujícího příkazu otestujte proces démon SBD na obou uzlech.
sbd -d <SBD Device Name> listVýsledky zobrazují dvě položky po konfiguraci na obou uzlech.

Do jednoho z uzlů odešlete následující testovací zprávu.
sbd -d <SBD Device Name> message <node2> <message>Na druhém uzlu (node2) pomocí následujícího příkazu zkontrolujte stav zprávy.
sbd -d <SBD Device Name> list
Pokud chcete přijmout konfiguraci SBD, aktualizujte soubor /etc/sysconfig/sbd následujícím způsobem na obou uzlech.
SBD_DEVICE=" <SBD Device Name>" SBD_WATCHDOG="yes" SBD_PACEMAKER="yes" SBD_STARTMODE="clean" SBD_OPTS=""Pomocí následujícího příkazu spusťte službu Pacemaker na primárním uzlu (node1).
systemctl start pacemaker
Pokud služba Pacemaker selže, přečtěte si část Scénář 5: Selhání služby Pacemaker dále v tomto článku.
Připojení uzlu ke clusteru
Spusťte na node2 následující příkaz, aby se tento uzel připojil ke clusteru.
ha-cluster-join
Pokud se při připojování clusteru zobrazí chyba, přečtěte si část Scénář 6: Uzel 2 se nemůže připojit ke clusteru dále v tomto článku.
Ověření clusteru
Pomocí následujících příkazů můžete zkontrolovat a volitelně spustit cluster poprvé na obou uzlech.
systemctl status pacemaker systemctl start pacemaker
Spuštěním následujícího příkazu ověřte, že jsou oba uzly online. Můžete ho spustit na libovolném uzlu clusteru.
crm_mon
Můžete se také přihlásit ke službě Hawk a zkontrolovat stav clusteru:
https://\<node IP>:7630. Výchozí uživatel je hacluster a heslo je linux. V případě potřeby můžete heslo změnit pomocípasswdpříkazu .
Konfigurace vlastností a prostředků clusteru
Tato část popisuje postup konfigurace prostředků clusteru. V tomto příkladu nastavíte následující prostředky. Zbytek (v případě potřeby) můžete nakonfigurovat pomocí průvodce vysokou dostupností SUSE.
- Spouštěcístrap clusteru
- Oplocení zařízení
- Virtuální IP adresa
Proveďte konfiguraci pouze na primárním uzlu .
Vytvořte soubor bootstrap clusteru a nakonfigurujte ho přidáním následujícího textu.
sapprdhdb95:~ # vi crm-bs.txt # enter the following to crm-bs.txt property $id="cib-bootstrap-options" \ no-quorum-policy="ignore" \ stonith-enabled="true" \ stonith-action="reboot" \ stonith-timeout="150s" rsc_defaults $id="rsc-options" \ resource-stickiness="1000" \ migration-threshold="5000" op_defaults $id="op-options" \ timeout="600"Pomocí následujícího příkazu přidejte konfiguraci do clusteru.
crm configure load update crm-bs.txt
Nakonfigurujte zařízení ohraničení přidáním prostředku, vytvořením souboru a přidáním textu následujícím způsobem.
# vi crm-sbd.txt # enter the following to crm-sbd.txt primitive stonith-sbd stonith:external/sbd \ params pcmk_delay_max="15"Pomocí následujícího příkazu přidejte konfiguraci do clusteru.
crm configure load update crm-sbd.txtPřidejte virtuální IP adresu prostředku tak, že vytvoříte soubor a přidáte následující text.
# vi crm-vip.txt primitive rsc_ip_HA1_HDB10 ocf:heartbeat:IPaddr2 \ operations $id="rsc_ip_HA1_HDB10-operations" \ op monitor interval="10s" timeout="20s" \ params ip="10.35.0.197"Pomocí následujícího příkazu přidejte konfiguraci do clusteru.
crm configure load update crm-vip.txtPomocí příkazu
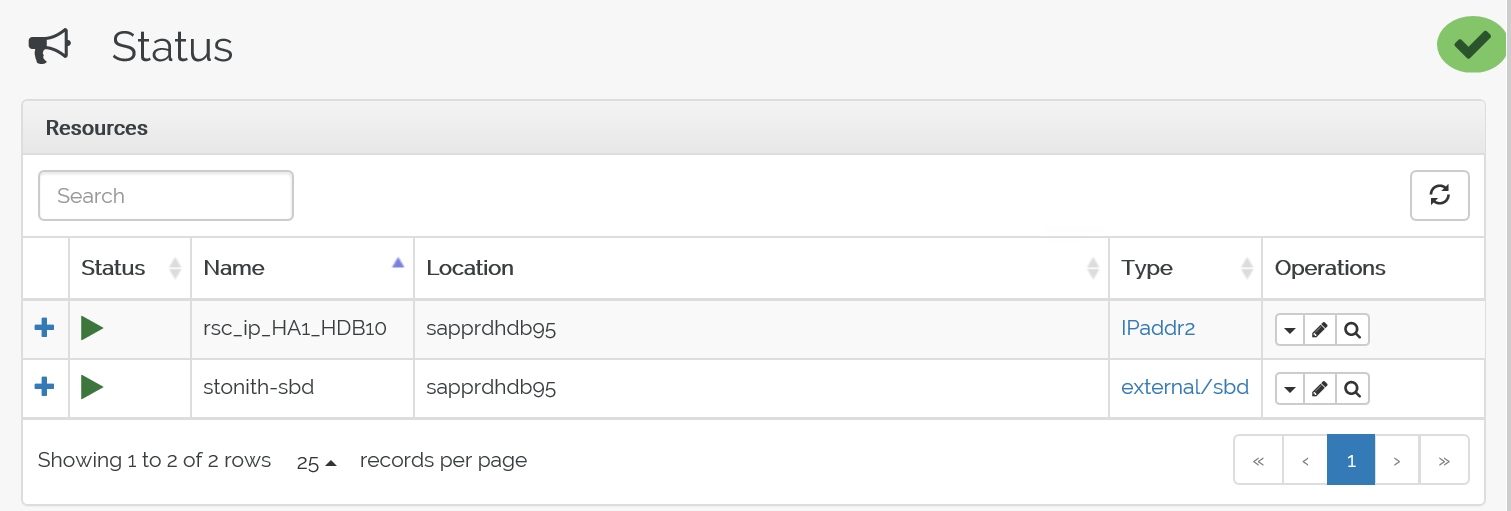
crm_monověřte prostředky.Výsledky ukazují tyto dva prostředky.

Stav můžete zkontrolovat také na adrese IP adresa> https://< uzlu:7630/cib/live/state.

Testování procesu převzetí služeb při selhání
Pokud chcete otestovat proces převzetí služeb při selhání, pomocí následujícího příkazu zastavte službu Pacemaker na uzlu1.
Service pacemaker stopPřevzetí služeb při selhání prostředků na node2.
Zastavte službu Pacemaker na uzlu 2 a prostředky přebíjejí služby při selhání na node1.
Tady je stav před převzetím služeb při selhání:

Tady je stav po převzetí služeb při selhání:

Řešení potíží
Tato část popisuje scénáře selhání, se kterými se můžete setkat během instalace.
Scénář 1: Uzel clusteru není online
Pokud se některý z uzlů ve Správci clusterů nezobrazuje online, můžete ho zkusit převést do režimu online.
Pomocí následujícího příkazu spusťte službu iSCSI.
service iscsid startPomocí následujícího příkazu se přihlaste k uzlu iSCSI.
iscsiadm -m node -lOčekávaný výstup vypadá takto:
sapprdhdb45:~ # iscsiadm -m node -l Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.11,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.12,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.22,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.21,3260] (multiple) Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.11,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.12,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.22,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.21,3260] successful.
Scénář 2: Yast2 nezobrazuje grafické zobrazení
Grafická obrazovka yast2 slouží k nastavení clusteru s vysokou dostupností v tomto článku. Pokud se yast2 neotevře s grafickým oknem, jak je znázorněno na obrázku, a vyvolá chybu Qt, nainstalujte požadované balíčky pomocí následujících kroků. Pokud se otevře s grafickým oknem, můžete kroky přeskočit.
Tady je příklad chyby Qt:

Tady je příklad očekávaného výstupu:
Ujistěte se, že jste přihlášeni jako uživatel root a že máte SMT nastavený na stahování a instalaci balíčků.
Přejděte na yast> Software ManagementDependencies (Závislostisprávy>softwaru>) a pak vyberte Install recommended packages (Nainstalovat doporučené balíčky).
Poznámka
Proveďte kroky na obou uzlech, abyste měli přístup k grafickému zobrazení yast2 z obou uzlů.
Následující snímek obrazovky ukazuje očekávanou obrazovku.

V části Závislosti vyberte Nainstalovat doporučené balíčky.

Zkontrolujte změny a vyberte OK.

Instalace balíčku pokračuje.

Vyberte Další.
Jakmile se zobrazí obrazovka Instalace úspěšně dokončena , vyberte Dokončit.

Pomocí následujících příkazů nainstalujte balíčky libqt4 a libyui-qt.
zypper -n install libqt4
zypper -n install libyui-qt

Yast2 teď může otevřít grafické zobrazení.

Scénář 3: Yast2 nezobrazuje možnost vysoké dostupnosti
Aby byla možnost vysoké dostupnosti viditelná v řídicím centru yast2, musíte nainstalovat další balíčky.
Přejděte na Yast2>Software>Management. Pak vyberteOnline aktualizacesoftwaru>.
Vyberte vzory pro následující položky. Pak vyberte Přijmout.
- Serverová základna SAP HANA
- Kompilátor a nástroje C/C++
- Vysoká dostupnost
- Základ aplikačního serveru SAP


V seznamu balíčků, které byly změněny tak, aby přeložily závislosti, vyberte Pokračovat.
Na stránce Stav instalace vyberteDalší.

Po dokončení instalace se zobrazí sestava instalace. Vyberte Dokončit.

Scénář 4: Instalace HANA selže s chybou sestavení gcc
Pokud se instalace HANA nezdaří, může se zobrazit následující chyba.

Pokud chcete tento problém vyřešit, nainstalujte knihovny libgcc_sl a libstdc++6, jak je znázorněno na následujícím snímku obrazovky.

Scénář 5: Selhání služby Pacemaker
Pokud se služba pacemakeru nedá spustit, zobrazí se následující informace.
sapprdhdb95:/ # systemctl start pacemaker
A dependency job for pacemaker.service failed. See 'journalctl -xn' for details.
sapprdhdb95:/ # journalctl -xn
-- Logs begin at Thu 2017-09-28 09:28:14 EDT, end at Thu 2017-09-28 21:48:27 EDT. --
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync configuration map
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync configuration ser
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync cluster closed pr
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync cluster quorum se
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync profile loading s
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [MAIN ] Corosync Cluster Engine exiting normally
Sep 28 21:48:27 sapprdhdb95 systemd[1]: Dependency failed for Pacemaker High Availability Cluster Manager
-- Subject: Unit pacemaker.service has failed
-- Defined-By: systemd
-- Support: https://lists.freedesktop.org/mailman/listinfo/systemd-devel
--
-- Unit pacemaker.service has failed.
--
-- The result is dependency.
sapprdhdb95:/ # tail -f /var/log/messages
2017-09-28T18:44:29.675814-04:00 sapprdhdb95 corosync[57600]: [QB ] withdrawing server sockets
2017-09-28T18:44:29.676023-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync cluster closed process group service v1.01
2017-09-28T18:44:29.725885-04:00 sapprdhdb95 corosync[57600]: [QB ] withdrawing server sockets
2017-09-28T18:44:29.726069-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync cluster quorum service v0.1
2017-09-28T18:44:29.726164-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync profile loading service
2017-09-28T18:44:29.776349-04:00 sapprdhdb95 corosync[57600]: [MAIN ] Corosync Cluster Engine exiting normally
2017-09-28T18:44:29.778177-04:00 sapprdhdb95 systemd[1]: Dependency failed for Pacemaker High Availability Cluster Manager.
2017-09-28T18:44:40.141030-04:00 sapprdhdb95 systemd[1]: [/usr/lib/systemd/system/fstrim.timer:8] Unknown lvalue 'Persistent' in section 'Timer'
2017-09-28T18:45:01.275038-04:00 sapprdhdb95 cron[57995]: pam_unix(crond:session): session opened for user root by (uid=0)
2017-09-28T18:45:01.308066-04:00 sapprdhdb95 CRON[57995]: pam_unix(crond:session): session closed for user root
Opravíte ho tak, že ze souboru /usr/lib/systemd/system/fstrim.timer odstraníte následující řádek:
Persistent=true

Scénář 6: Node2 se nemůže připojit ke clusteru
Následující chyba se zobrazí, pokud dojde k problému s připojením node2 ke stávajícímu clusteru pomocí příkazu ha-cluster-join .
ERROR: Can’t retrieve SSH keys from <Primary Node>

Jak to opravit:
Na obou uzlech spusťte následující příkazy.
ssh-keygen -q -f /root/.ssh/id_rsa -C 'Cluster Internal' -N '' cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys

Ověřte, že je do clusteru přidaný uzel node2.

Další kroky
Další informace o nastavení vysoké dostupnosti SUSE najdete v následujících článcích:
- Scénář SAP HANA SR optimalizovaný z hlediska výkonu (web SUSE)
- Zařízení pro oplocení a oplocení (web SUSE)
- Připravte se na používání clusteru Pacemaker pro SAP HANA – Část 1: Základy (blog SAP)
- Připravte se na použití clusteru Pacemaker pro SAP HANA – Část 2: Selhání obou uzlů (blog SAP)
- Zálohování a obnovení operačního systému