Vysoká dostupnost systému souborů NFS na virtuálních počítačích Azure na serveru SUSE Linux Enterprise Server
Poznámka:
Pro ukládání sdílených dat do vysoce dostupného systému SAP doporučujeme nasadit jednu ze služeb NFS první strany: NFS na svazcích Azure Files nebo NFS ANF. Mějte na paměti, že s využitím clusterů NFS de-emphasizujeme referenční architektury SAP.
Tento článek popisuje, jak nasadit virtuální počítače, nakonfigurovat virtuální počítače, nainstalovat architekturu clusteru a nainstalovat server NFS s vysokou dostupností, který se dá použít k ukládání sdílených dat systému SAP s vysokou dostupností. Tato příručka popisuje, jak nastavit server NFS s vysokou dostupností, který používají dva systémy SAP, NW1 a NW2. Názvy prostředků (například virtuálních počítačů, virtuálních sítí) v příkladu předpokládají, že jste použili šablonu souborového serveru SAP s předponou prostředků.
Poznámka:
Tento článek obsahuje odkazy na termíny, které už Microsoft nepoužívá. Po odebrání podmínek ze softwaru je z tohoto článku odebereme.
Nejprve si přečtěte následující poznámky a dokumenty SAP.
SAP Note 1928533, který má:
- Seznam velikostí virtuálních počítačů Azure podporovaných pro nasazení softwaru SAP
- Důležité informace o kapacitě pro velikosti virtuálních počítačů Azure
- Podporované kombinace softwaru SAP a operačního systému (OS) a databází
- Požadovaná verze jádra SAP pro Windows a Linux v Microsoft Azure
SAP Note 2015553 uvádí požadavky pro nasazení softwaru SAP s podporou SAP v Azure.
SAP Note 2205917 doporučil nastavení operačního systému pro SUSE Linux Enterprise Server pro aplikace SAP
SAP Note 1944799 obsahuje pokyny PRO SAP HANA pro SUSE Linux Enterprise Server pro aplikace SAP
SAP Note 2178632 obsahuje podrobné informace o všech metrikách monitorování hlášených pro SAP v Azure.
SAP Note 2191498 má požadovanou verzi agenta hostitele SAP pro Linux v Azure.
SAP Note 2243692 obsahuje informace o licencování SAP v Linuxu v Azure.
SAP Note 1984787 obsahuje obecné informace o SUSE Linux Enterprise Serveru 12.
SAP Note 1999351 obsahuje další informace o řešení potíží pro rozšíření rozšířeného monitorování Azure pro SAP.
Wikiweb komunity SAP obsahuje všechny požadované poznámky SAP pro Linux.
Plánování a implementace virtuálních počítačů Azure pro SAP v Linuxu
Nasazení služby Azure Virtual Machines pro SAP v Linuxu (tento článek)
Osvědčené postupy rozšíření SUSE Linux Enterprise s vysokou dostupností 12 SP3
- Vysoce dostupné úložiště NFS s DRBD a Pacemakerem
Průvodci osvědčenými postupy pro SUSE Linux Enterprise Server for SAP Applications 12 SP3
Zpráva k vydání verze rozšíření SUSE High Availability 12 SP3
Přehled
K dosažení vysoké dostupnosti vyžaduje SAP NetWeaver server NFS. Server NFS je nakonfigurovaný v samostatném clusteru a může ho používat několik systémů SAP.
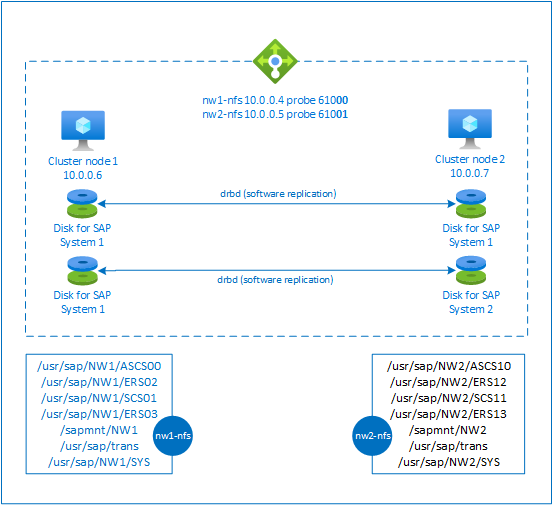
Server NFS používá vyhrazený název virtuálního hostitele a virtuální IP adresy pro každý systém SAP, který používá tento server NFS. V Azure se k použití virtuální IP adresy vyžaduje nástroj pro vyrovnávání zatížení. Zobrazená konfigurace ukazuje nástroj pro vyrovnávání zatížení s:
- IP adresa front-endu 10.0.0.4 pro NW1
- IP adresa front-endu 10.0.0.5 pro NW2
- Port sondy 61000 pro NW1
- Port sondy 61001 pro NW2
Nastavení serveru NFS s vysokou dostupností
Ruční nasazení Linuxu přes Azure Portal
Tento dokument předpokládá, že jste už nasadili skupinu prostředků, virtuální síť Azure a podsíť.
Nasaďte dva virtuální počítače pro servery NFS. Zvolte vhodnou image SLES, která je podporována ve vašem systému SAP. Virtuální počítač můžete nasadit v libovolné z možností dostupnosti – škálovací sada, zóna dostupnosti nebo skupina dostupnosti.
Konfigurace nástroje pro vyrovnávání zatížení Azure
Postupujte podle průvodce vytvořením nástroje pro vyrovnávání zatížení a nakonfigurujte standardní nástroj pro vyrovnávání zatížení pro vysokou dostupnost serveru NFS. Při konfiguraci nástroje pro vyrovnávání zatížení zvažte následující body.
- Konfigurace front-endové IP adresy: Vytvořte dvě front-endové IP adresy. Vyberte stejnou virtuální síť a podsíť jako server NFS.
- Back-endový fond: Vytvořte back-endový fond a přidejte virtuální počítače serveru NFS.
- Příchozí pravidla: Vytvořte dvě pravidlo vyrovnávání zatížení, jedno pro NW1 a druhé pro NW2. Pro obě pravidla vyrovnávání zatížení postupujte stejně.
- IP adresa front-endu: Vyberte ip adresu front-endu.
- Back-endový fond: Vyberte back-endový fond.
- Zkontrolujte porty s vysokou dostupností.
- Protokol: TCP
- Sonda stavu: Vytvořte sondu stavu s následujícími podrobnostmi (platí pro NW1 i NW2).
- Protokol: TCP
- Port: [například: 61000 pro NW1, 61001 pro NW2]
- Interval: 5
- Prahová hodnota sondy: 2
- Časový limit nečinnosti (minuty): 30
- Zaškrtněte políčko Povolit plovoucí IP adresu.
Poznámka:
Číslo vlastnosti konfigurace sondy stavuOfProbes, jinak označované jako "Prahová hodnota není v pořádku" na portálu, se nerespektuje. Chcete-li tedy řídit počet úspěšných nebo neúspěšných po sobě jdoucích sond, nastavte vlastnost probeThreshold na hodnotu 2. V současné době není možné tuto vlastnost nastavit pomocí webu Azure Portal, takže použijte příkaz Azure CLI nebo PowerShell .
Poznámka:
Pokud jsou virtuální počítače bez veřejných IP adres umístěny do back-endového fondu interního (bez veřejné IP adresy) služby Azure Load Balancer úrovně Standard, nebude k dispozici žádné odchozí připojení k internetu, pokud není provedena další konfigurace umožňující směrování do veřejných koncových bodů. Podrobnosti o tom, jak dosáhnout odchozího připojení, najdete v tématu Připojení k veřejnému koncovému bodu pro virtuální počítače pomocí Azure Standard Load Balanceru ve scénářích s vysokou dostupností SAP.
Důležité
- Nepovolujte na virtuálních počítačích Azure umístěných za Azure Load Balancerem časové razítko TCP. Povolení časových razítek PROTOKOLU TCP způsobí selhání sond stavu. Nastavte parametr na
net.ipv4.tcp_timestamps0. Podrobnosti najdete v sondách stavu Load Balanceru. - Pokud chcete zabránit tomu, aby saptune měnil hodnotu ručně nastavenou
net.ipv4.tcp_timestampszpět0na1, měli byste aktualizovat verzi saptune na verzi 3.1.1 nebo vyšší. Další podrobnosti najdete v tématu saptune 3.1.1 – Musím aktualizovat?.
Vytvoření clusteru Pacemaker
Postupujte podle kroků v nastavení Pacemakeru na SUSE Linux Enterprise Serveru v Azure a vytvořte základní cluster Pacemaker pro tento server NFS.
Konfigurace serveru NFS
Následující položky mají předponu [A] – platí pro všechny uzly, [1] – platí pouze pro uzel 1 nebo [2] – platí pouze pro uzel 2.
[A] Nastavení překladu názvů hostitelů
Můžete použít server DNS nebo upravit /etc/hosts na všech uzlech. Tento příklad ukazuje, jak používat soubor /etc/hosts. Nahraďte IP adresu a název hostitele v následujících příkazech.
sudo vi /etc/hostsDo /etc/hosts vložte následující řádky. Změňte IP adresu a název hostitele tak, aby odpovídaly vašemu prostředí.
# IP address of the load balancer frontend configuration for NFS 10.0.0.4 nw1-nfs 10.0.0.5 nw2-nfs[A] Povolení serveru NFS
Vytvoření položky exportu kořenového systému souborů NFS
sudo sh -c 'echo /srv/nfs/ *\(rw,no_root_squash,fsid=0\)>/etc/exports' sudo mkdir /srv/nfs/[A] Instalace komponent drbd
sudo zypper install drbd drbd-kmp-default drbd-utils[A] Vytvoření oddílu pro zařízení drbd
Výpis všech dostupných datových disků
sudo ls /dev/disk/azure/scsi1/ # Example output # lun0 lun1Vytváření oddílů pro každý datový disk
sudo sh -c 'echo -e "n\n\n\n\n\nw\n" | fdisk /dev/disk/azure/scsi1/lun0' sudo sh -c 'echo -e "n\n\n\n\n\nw\n" | fdisk /dev/disk/azure/scsi1/lun1'[A] Vytvoření konfigurací LVM
Výpis všech dostupných oddílů
ls /dev/disk/azure/scsi1/lun*-part* # Example output # /dev/disk/azure/scsi1/lun0-part1 /dev/disk/azure/scsi1/lun1-part1Vytvoření svazků LVM pro každý oddíl
sudo pvcreate /dev/disk/azure/scsi1/lun0-part1 sudo vgcreate vg-NW1-NFS /dev/disk/azure/scsi1/lun0-part1 sudo lvcreate -l 100%FREE -n NW1 vg-NW1-NFS sudo pvcreate /dev/disk/azure/scsi1/lun1-part1 sudo vgcreate vg-NW2-NFS /dev/disk/azure/scsi1/lun1-part1 sudo lvcreate -l 100%FREE -n NW2 vg-NW2-NFS[A] Konfigurace nástroje drbd
sudo vi /etc/drbd.confUjistěte se, že soubor drbd.conf obsahuje následující dva řádky.
include "drbd.d/global_common.conf"; include "drbd.d/*.res";Změna globální konfigurace drbd
sudo vi /etc/drbd.d/global_common.confDo obslužné rutiny a oddílu net přidejte následující položky.
global { usage-count no; } common { handlers { fence-peer "/usr/lib/drbd/crm-fence-peer.9.sh"; after-resync-target "/usr/lib/drbd/crm-unfence-peer.9.sh"; split-brain "/usr/lib/drbd/notify-split-brain.sh root"; pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f"; } startup { wfc-timeout 0; } options { } disk { md-flushes yes; disk-flushes yes; c-plan-ahead 1; c-min-rate 100M; c-fill-target 20M; c-max-rate 4G; } net { after-sb-0pri discard-younger-primary; after-sb-1pri discard-secondary; after-sb-2pri call-pri-lost-after-sb; protocol C; tcp-cork yes; max-buffers 20000; max-epoch-size 20000; sndbuf-size 0; rcvbuf-size 0; } }[A] Vytvoření zařízení drbd systému souborů NFS
sudo vi /etc/drbd.d/NW1-nfs.resVložte konfiguraci pro nové zařízení drbd a ukončete
resource NW1-nfs { protocol C; disk { on-io-error detach; } net { fencing resource-and-stonith; } on prod-nfs-0 { address 10.0.0.6:7790; device /dev/drbd0; disk /dev/vg-NW1-NFS/NW1; meta-disk internal; } on prod-nfs-1 { address 10.0.0.7:7790; device /dev/drbd0; disk /dev/vg-NW1-NFS/NW1; meta-disk internal; } }sudo vi /etc/drbd.d/NW2-nfs.resVložte konfiguraci pro nové zařízení drbd a ukončete
resource NW2-nfs { protocol C; disk { on-io-error detach; } net { fencing resource-and-stonith; } on prod-nfs-0 { address 10.0.0.6:7791; device /dev/drbd1; disk /dev/vg-NW2-NFS/NW2; meta-disk internal; } on prod-nfs-1 { address 10.0.0.7:7791; device /dev/drbd1; disk /dev/vg-NW2-NFS/NW2; meta-disk internal; } }Vytvořte zařízení drbd a spusťte ho.
sudo drbdadm create-md NW1-nfs sudo drbdadm create-md NW2-nfs sudo drbdadm up NW1-nfs sudo drbdadm up NW2-nfs[1] Přeskočení počáteční synchronizace
sudo drbdadm new-current-uuid --clear-bitmap NW1-nfs sudo drbdadm new-current-uuid --clear-bitmap NW2-nfs[1] Nastavení primárního uzlu
sudo drbdadm primary --force NW1-nfs sudo drbdadm primary --force NW2-nfs[1] Počkejte na synchronizaci nových zařízení drbd.
sudo drbdsetup wait-sync-resource NW1-nfs sudo drbdsetup wait-sync-resource NW2-nfs[1] Vytvoření systémů souborů na zařízeních drbd
sudo mkfs.xfs /dev/drbd0 sudo mkdir /srv/nfs/NW1 sudo chattr +i /srv/nfs/NW1 sudo mount -t xfs /dev/drbd0 /srv/nfs/NW1 sudo mkdir /srv/nfs/NW1/sidsys sudo mkdir /srv/nfs/NW1/sapmntsid sudo mkdir /srv/nfs/NW1/trans sudo mkdir /srv/nfs/NW1/ASCS sudo mkdir /srv/nfs/NW1/ASCSERS sudo mkdir /srv/nfs/NW1/SCS sudo mkdir /srv/nfs/NW1/SCSERS sudo umount /srv/nfs/NW1 sudo mkfs.xfs /dev/drbd1 sudo mkdir /srv/nfs/NW2 sudo chattr +i /srv/nfs/NW2 sudo mount -t xfs /dev/drbd1 /srv/nfs/NW2 sudo mkdir /srv/nfs/NW2/sidsys sudo mkdir /srv/nfs/NW2/sapmntsid sudo mkdir /srv/nfs/NW2/trans sudo mkdir /srv/nfs/NW2/ASCS sudo mkdir /srv/nfs/NW2/ASCSERS sudo mkdir /srv/nfs/NW2/SCS sudo mkdir /srv/nfs/NW2/SCSERS sudo umount /srv/nfs/NW2[A] Nastavení drbd split-brain detection
Pokud k synchronizaci dat z jednoho hostitele do druhého používáte drbd, může dojít k tzv. rozdělení mozku. Rozdělený mozek je scénář, kdy oba uzly clusteru propagovaly drbd zařízení jako primární a nesynchronizují se. Může to být vzácná situace, ale přesto chcete zvládnout a vyřešit rozdělený mozek co nejrychleji. Proto je důležité upozornit, když došlo k rozdělení mozku.
Přečtěte si oficiální dokumentaci drbd o tom, jak nastavit rozdělené oznámení mozku.
Je také možné se automaticky zotavit z rozděleného mozku scénáře. Další informace najdete v tématu Automatické rozdělení zásad obnovení mozku
Konfigurace architektury clusteru
[1] Přidejte zařízení systému souborů NFS pro systém SAP NW1 do konfigurace clusteru.
Důležité
Nedávné testování odhalilo situace, kdy netcat přestane reagovat na požadavky kvůli backlogu a jeho omezení zpracování pouze jednoho připojení. Prostředek netcat přestane naslouchat požadavkům azure Load Balanceru a plovoucí IP adresa přestane být k dispozici.
Pro stávající clustery Pacemaker doporučujeme v minulosti nahradit netcat socat. V současné době doporučujeme používat agenta prostředků azure-lb, který je součástí agentů prostředků balíčku s následujícími požadavky na verzi balíčku:- Pro SLES 12 SP4/SP5 musí být verze alespoň resource-agents-4.3.018.a7fb5035-3.30.1.
- Pro SLES 15/15 SP1 musí být verze alespoň resource-agents-4.3.0184.6ee15eb2-4.13.1.
Upozorňujeme, že změna bude vyžadovat krátký výpadek.
Pokud už konfigurace pro existující clustery Pacemaker změnila na použití socat, jak je popsáno v posílení zabezpečení detekce Nástroje pro vyrovnávání zatížení Azure, není nutné okamžitě přepnout na agenta prostředků azure-lb.sudo crm configure rsc_defaults resource-stickiness="200" # Enable maintenance mode sudo crm configure property maintenance-mode=true sudo crm configure primitive drbd_NW1_nfs \ ocf:linbit:drbd \ params drbd_resource="NW1-nfs" \ op monitor interval="15" role="Master" \ op monitor interval="30" role="Slave" sudo crm configure ms ms-drbd_NW1_nfs drbd_NW1_nfs \ meta master-max="1" master-node-max="1" clone-max="2" \ clone-node-max="1" notify="true" interleave="true" sudo crm configure primitive fs_NW1_sapmnt \ ocf:heartbeat:Filesystem \ params device=/dev/drbd0 \ directory=/srv/nfs/NW1 \ fstype=xfs \ op monitor interval="10s" sudo crm configure primitive nfsserver systemd:nfs-server \ op monitor interval="30s" sudo crm configure clone cl-nfsserver nfsserver sudo crm configure primitive exportfs_NW1 \ ocf:heartbeat:exportfs \ params directory="/srv/nfs/NW1" \ options="rw,no_root_squash,crossmnt" clientspec="*" fsid=1 wait_for_leasetime_on_stop=true op monitor interval="30s" sudo crm configure primitive vip_NW1_nfs IPaddr2 \ params ip=10.0.0.4 op monitor interval=10 timeout=20 sudo crm configure primitive nc_NW1_nfs azure-lb port=61000 \ op monitor timeout=20s interval=10 sudo crm configure group g-NW1_nfs \ fs_NW1_sapmnt exportfs_NW1 nc_NW1_nfs vip_NW1_nfs sudo crm configure order o-NW1_drbd_before_nfs inf: \ ms-drbd_NW1_nfs:promote g-NW1_nfs:start sudo crm configure colocation col-NW1_nfs_on_drbd inf: \ g-NW1_nfs ms-drbd_NW1_nfs:Master[1] Přidání zařízení systému souborů NFS pro systém SAP NW2 do konfigurace clusteru
# Enable maintenance mode sudo crm configure property maintenance-mode=true sudo crm configure primitive drbd_NW2_nfs \ ocf:linbit:drbd \ params drbd_resource="NW2-nfs" \ op monitor interval="15" role="Master" \ op monitor interval="30" role="Slave" sudo crm configure ms ms-drbd_NW2_nfs drbd_NW2_nfs \ meta master-max="1" master-node-max="1" clone-max="2" \ clone-node-max="1" notify="true" interleave="true" sudo crm configure primitive fs_NW2_sapmnt \ ocf:heartbeat:Filesystem \ params device=/dev/drbd1 \ directory=/srv/nfs/NW2 \ fstype=xfs \ op monitor interval="10s" sudo crm configure primitive exportfs_NW2 \ ocf:heartbeat:exportfs \ params directory="/srv/nfs/NW2" \ options="rw,no_root_squash,crossmnt" clientspec="*" fsid=2 wait_for_leasetime_on_stop=true op monitor interval="30s" sudo crm configure primitive vip_NW2_nfs IPaddr2 \ params ip=10.0.0.5 op monitor interval=10 timeout=20 sudo crm configure primitive nc_NW2_nfs azure-lb port=61001 \ op monitor timeout=20s interval=10 sudo crm configure group g-NW2_nfs \ fs_NW2_sapmnt exportfs_NW2 nc_NW2_nfs vip_NW2_nfs sudo crm configure order o-NW2_drbd_before_nfs inf: \ ms-drbd_NW2_nfs:promote g-NW2_nfs:start sudo crm configure colocation col-NW2_nfs_on_drbd inf: \ g-NW2_nfs ms-drbd_NW2_nfs:MasterMožnost
crossmntv prostředcích clusteruexportfsje k dispozici v naší dokumentaci pro zpětnou kompatibilitu se staršími verzemi SLES.[1] Zakázat režim údržby
sudo crm configure property maintenance-mode=false
Další kroky
- Instalace SAP ASCS a databáze
- Plánování a implementace virtuálních počítačů Azure pro SAP
- Nasazení virtuálních počítačů Azure pro SAP
- Nasazení DBMS pro Azure Virtual Machines pro SAP
- Informace o vytvoření vysoké dostupnosti a plánování zotavení po havárii SAP HANA na virtuálních počítačích Azure najdete v tématu Vysoká dostupnost SAP HANA na virtuálních počítačích Azure.