Replikace zpráv a federace mezi oblastmi
Azure Service Bus v rámci oborů názvů podporuje vytváření topologií zřetězených front a odběrů témat pomocí automatického převrážení , aby bylo možné implementovat různé vzory směrování. Můžete například partnerům poskytnout vyhrazené fronty, ke kterým mají oprávnění odesílat nebo přijímat a které je možné v případě potřeby dočasně pozastavit a pružně je připojit k dalším entitám, které jsou soukromé s aplikací. Můžete také vytvořit složité topologie směrování ve vícefázové fázi nebo můžete vytvořit fronty ve stylu poštovní schránky, které vyprázdní odběry témat podobných frontám a umožňují větší kapacitu úložiště na předplatitele.
Řada sofistikovaných řešení také vyžaduje, aby se zprávy replikovaly přes hranice oboru názvů, aby bylo možné tyto a další vzory implementovat. Zprávy můžou být potřeba přetékat mezi obory názvů přidruženými k více tenantům aplikací nebo mezi několika různými oblastmi Azure.
Vaše řešení bude udržovat několik oborů názvů služby Service Bus v různých oblastech a replikovat zprávy mezi frontami a tématy a/nebo že budete vyměňovat zprávy se zdroji a cíli, jako jsou Azure Event Hubs, Azure IoT Hub nebo Apache Kafka.
Tyto scénáře jsou zaměřeny na tento článek.
Vzory federace
Existuje mnoho potenciálních motivací, proč můžete chtít přesouvat zprávy mezi entitami služby Service Bus, jako jsou fronty nebo témata, nebo mezi Service Bus a dalšími zdroji a cíli.
Ve srovnání s podobnou sadou vzorů pro službu Event Hubs je federace entit podobných frontám složitější, protože fronty zpráv slibují svým příjemcům výhradní vlastnictví nad libovolnou zprávou, očekává se, že zachová pořadí doručení zprávy a zprostředkovatel bude koordinovat spravedlivé rozdělení zpráv mezi konkurenčními příjemci.
Existují praktické překážky, včetně omezení teorému CAP, které ztěžují poskytnutí jednotného zobrazení fronty, která je současně dostupná ve více oblastech a která umožňuje regionální distribuci konkurenčních spotřebitelů převzít výhradní vlastnictví zpráv. Taková geograficky distribuovaná fronta by vyžadovala plně konzistentní replikaci nejen zpráv, ale také stav doručení každé zprávy, aby bylo možné zprávy zpřístupnit příjemcům. Cílem úplné konzistence hypotetické a regionálně distribuované fronty je přímý konflikt s klíčovým cílem, který má prakticky všichni zákazníci služby Azure Service Bus při zvažování scénářů federace: Maximální dostupnost a spolehlivost pro svá řešení.
Zde uvedené vzory se proto zaměřují na dostupnost a spolehlivost a zároveň se zaměřují na to, aby se co nejlépe vyhnuly ztrátě informací i duplicitnímu zpracování zpráv.
Odolnost proti událostem regionální dostupnosti
I když maximální dostupnost a spolehlivost představují hlavní provozní priority služby Service Bus, existuje mnoho způsobů, jak může producent nebo spotřebitel zabránit v komunikaci s přiřazenou "primární" službou Service Bus kvůli problémům se sítí nebo překladem názvů nebo v případě, že entita služby Service Bus skutečně dočasně nereaguje nebo vrací chyby. Určený procesor zpráv může být také nedostupný.
Takové podmínky nejsou "katastrofální" tak, že budete chtít úplně opustit regionální nasazení, protože byste to mohli udělat v situaci zotavení po havárii, ale obchodní scénář některých aplikací už může mít vliv na události dostupnosti, které trvají déle než několik minut nebo dokonce sekund. Azure Service Bus se často používá v hybridních cloudových prostředích a s klienty, kteří se nacházejí na hraniční síti, například v maloobchodních prodejnách, restauracích, bankovních pobočkách, výrobních lokalitách, logistických zařízeních a letištích. Problém se směrováním nebo zahlcením sítě může ovlivnit schopnost každé lokality dosáhnout přiřazeného koncového bodu služby Service Bus, zatímco sekundární koncový bod v jiné oblasti může být dostupný. Systémy zpracovávající zprávy přicházející z těchto lokalit mohou mít současně neomezený přístup k primárnímu i sekundárnímu koncovému bodu služby Service Bus.
Existuje mnoho praktických příkladů takových hybridních cloudových a hraničních aplikací s nízkou obchodní odolností pro dopad problémů se směrováním sítě nebo přechodných problémů s dostupností entity služby Service Bus. Patří sem zpracování plateb v maloobchodních lokalitách, paluba na letištích a objednávky mobilních telefonů v restauracích, z nichž všechny přicházejí okamžitě, a úplné zastavení vždy, když spolehlivá komunikační cesta není k dispozici.
V této kategorii probereme tři odlišné distribuované vzory: replikaci "all-active", replikaci typu aktivní-pasivní a replikaci přelévání.
Všechny aktivní replikace
Model replikace "vše-aktivní" umožňuje, aby aktivní replika stejného logického tématu (nebo fronty) byla k dispozici ve více oborech názvů (a oblastech) a aby všechny zprávy byly dostupné ve všech replikách bez ohledu na to, kde byly zařazeny do fronty. Vzor obecně zachovává pořadí zpráv vzhledem k libovolnému vydavateli.
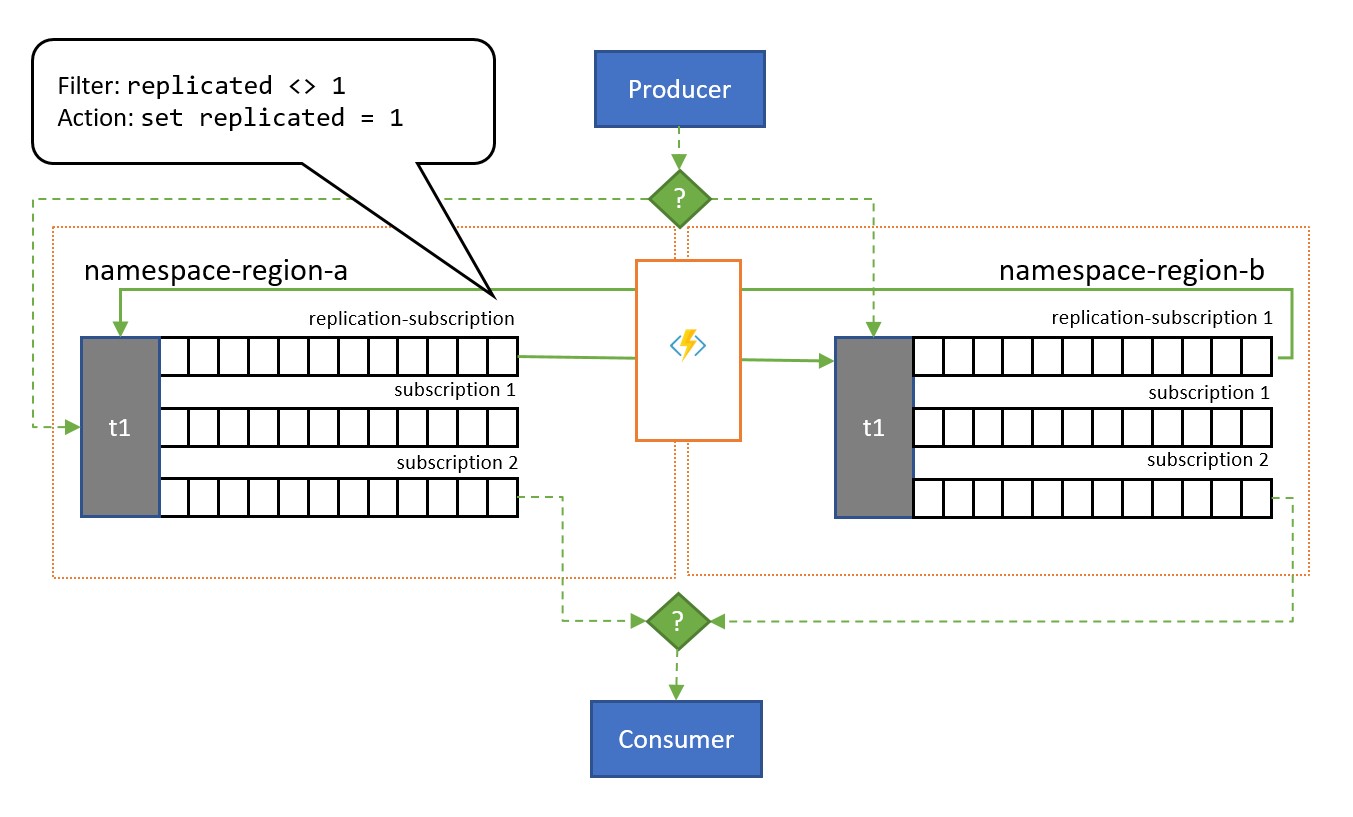
Jak je znázorněno na obrázku, vzor se obecně spoléhá na témata služby Service Bus. Jedno téma pro každý obor názvů, který se účastní schématu replikace. Každé z těchto témat má jedno "předplatné replikace" pro každé z ostatních témat, do kterého se zprávy replikují. Na obrázku výše máme jednoduše dvojici témat, a proto jedno předplatné replikace pro příslušné druhé téma. Ve scénáři se třemi obory názvů {n1, n2, n3} by téma v oboru názvů n1 měla dvě předplatná replikace, jedno pro odpovídající téma v n2 a jedno pro odpovídající téma v n3.
Každé předplatné replikace má pravidlo, které kombinuje výraz filtru SQL (replicated <> 1) a akci SQL (set replicated = 1). Filtr pravidla zajistí, že pouze zprávy, ve kterých není nastavena vlastní vlastnost replication nebo nemá hodnotu 1 , se stane způsobilým pro toto předplatné a akce nastaví tuto přesnou vlastnost na hodnotu 1 u každé vybrané zprávy hned potom. Výsledkem je, že když se zpráva zkopíruje do odpovídajícího tématu, už nemá nárok na replikaci v opačném směru, a proto se vyhneme zprávám, které se mezi replikami odrazí.
Předplatné s příslušným pravidlem se dá snadno přidat do libovolného tématu pomocí Rozhraní příkazového řádku Azure CLI, jako je tento.
az servicebus topic subscription rule create --resource-group myresourcegroup \
--namespace mynamespace --topic-name mytopic \
--subscription-name replication --name replication \
--action-sql-expression "set replication = 1" \
--filter-sql-expression "replication IS NULL"
Při modelování fronty je každé téma omezeno pouze na jedno běžné předplatné (jiné než předplatná replikace), které sdílejí všichni uživatelé.
Model replikace, který je aktivní, vloží do každého z témat kopii každé zprávy odeslané do každého z témat. To znamená, že kód aplikace v každé oblasti uvidí a zpracuje všechny zprávy. Tento model je vhodný pro scénáře, kdy se data sdílí do více oblastí nebo pokud je obecně potřeba redundantní zpracování. Pokud potřebujete zpracovat každou zprávu jenom jednou, stejně jako u běžné fronty, musíte zvážit jeden z následujících dvou vzorů.
Replikace aktivní-pasivní
Model replikace typu aktivní-pasivní je variantou předchozího modelu, kdy aplikace aktivně používá pouze jedno z témat ("primární") k odesílání a přijímání zpráv a zpráv se replikuje do sekundárního tématu pro případ, že primární téma může být nedostupné nebo nedostupné.
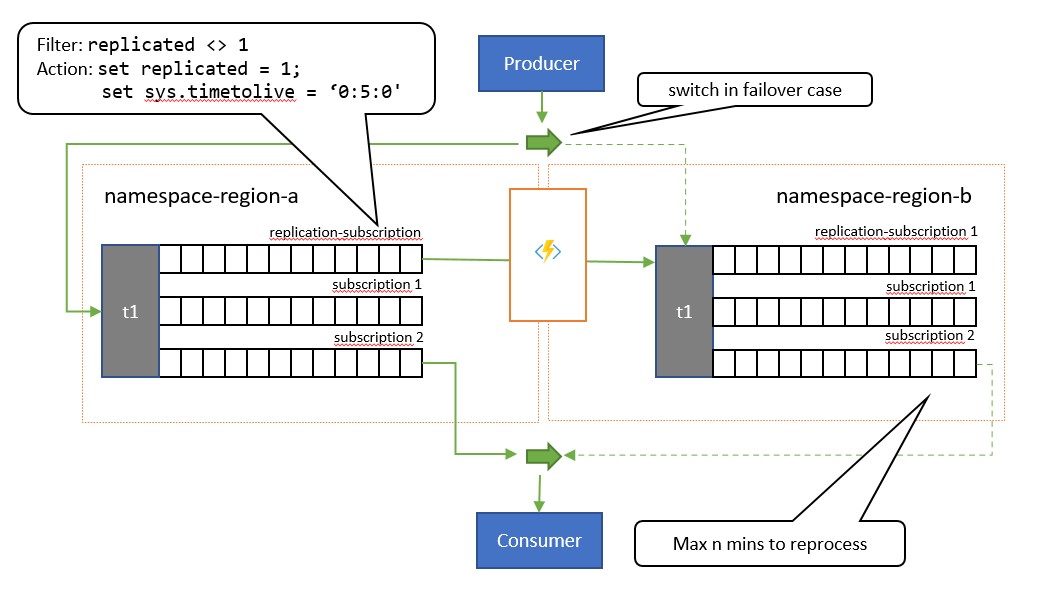
Klíčovým rozdílem mezi tímto vzorem a předchozím vzorem je, že replikace je jednosměrná z primárního tématu do sekundárního tématu. Sekundární téma se nikdy nestane primárním, ale je to možnost zálohování, pokud je primární téma dočasně nepoužitelné.
Nevýhodou použití tohoto modelu je, že se snaží minimalizovat duplicitní zpracování. Během replikace TimeToLive je vlastnost zprávy nastavena na dobu trvání replikovaných zpráv, které odrážejí očekávanou dobu, během které selhání primárního serveru povede k převzetí služeb při selhání. Pokud například váš scénář použití vyžaduje přechod příjemce na sekundární během maximálně 1 minuty od načtení zpráv z primárního začátku, kdy se zobrazí problémy, měl by sekundární server ideálně mít k dispozici všechny zprávy, ke kterým jste nemohli získat přístup v primárním serveru, ale minimální počet zpráv, které jste už z primárního počítače zpracovali dříve, než se zobrazí problémy. Pokud nastavíme TimeToLive dvakrát toto období, 2 minuty během replikace (set sys.TimeToLive = '0:2:0' v akci pravidla), sekundární zachová zprávy pouze po dobu 2 minut a zahodí starší. To znamená, že když příjemce přepne na sekundární, může rychle číst a zahodit zprávy starší než poslední, které zpracoval, a pak zpracovat z první zprávy, kterou ještě neviděl. Skutečná doba uchování bude záviset na konkrétním případu použití a na rychlém, které chcete a můžete přepnout na sekundární v aplikaci. Nastavení TimeToLive se respektuje v rozsahu od několika sekund po dny.
I když aplikace používá sekundární, může také publikovat přímo do sekundárního tématu, které pak funguje jako jakékoli běžné téma. Po přepnutí na sekundární příjemce uvidí kombinaci replikovaných zpráv a zpráv publikovaných přímo do sekundárního serveru. Aplikace by proto měla nejprve přepnout publikování zpět na primární a přesto povolit vyprázdnění místně publikovaných zpráv před přepnutím příjemce zpět na sekundární. Vzhledem k tomu, že replikace probíhá automaticky, jakmile bude primární server znovu dostupný, příjemce by během této doby získal také nové zprávy publikované na primární server, i když s poněkud vyšší latencí.
Tento model je vhodný pro scénáře, ve kterých by se zprávy měly zpracovávat pouze jednou. Aplikace musí spolupracovat při sledování zpráv, které z primárního serveru zpracovala, protože najde duplicity po dobu trvání okna převzetí služeb při selhání v sekundárním prostředí a při přepínání zpět znovu najde duplicity. Kritérium odstranění duplicit by mělo být nejvhodnější pro aplikaci
MessageId. HodnotaEnqueuedTimeUtcje také vhodná jako ukazatel meze, ale aplikace musí umožňovat určité množství posunů hodin (několik sekund) mezi primárním a sekundárním, stejně jako u jakéhokoli distribuovaného systému.
Replikace přelití
Model replikace přelití umožňuje aktivní/aktivní použití více entit služby Service Bus ve více oblastech k řešení scénáře, ve kterém je Service Bus v pořádku, ale příjemce se zahltí počtem nevyřízených zpráv nebo je přímo nedostupný. Důvodem může být, že databáze, která zálohuje proces příjemce, může být pomalá nebo nedostupná. Tento model funguje s prostými frontami a s odběry témat.
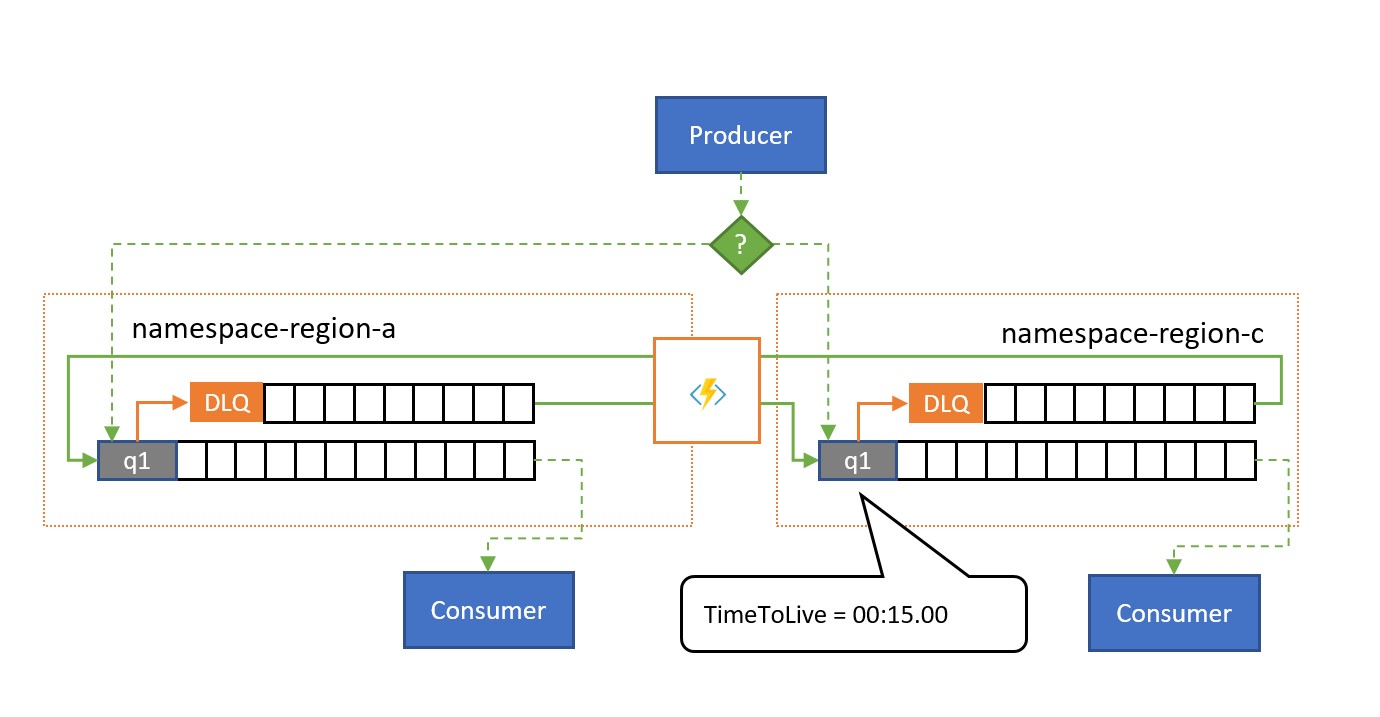
Jak je znázorněno na obrázku, model replikace přelévání replikuje zprávy z fronty nebo odběru přidružené do spárované fronty nebo tématu v jiném oboru názvů.
Bez situace selhání se oba obory názvů používají paralelně, přičemž každý přijímá určitou podmnožinu celkového provozu zpráv a jejich přidružené příjemce, kteří tuto podmnožinu zpracovávají. Jakmile jeden z příjemců začne vykazovat vysoké míry selhání nebo se přímo zastaví, příslušné zprávy skončí ve frontě nedoručených zpráv buď překročením počtu doručení, nebo proto, že vyprší. Úlohy replikace je pak vyzvednou a znovu zařadí do spárované fronty, kde se pak předají předpokládanému příjemci, který je v pořádku.
Pokud zpracování musí proběhnout v určitém termínu, je třeba nastavit frontu nebo zprávy tak, TimeToLive aby zpracování mohlo probíhat v čase sekundárním přelitím, například TimeToLive může být nastaveno na polovinu povoleného času.
Stejně jako u všech aktivních vzorů může aplikace do zprávy přidat indikátor, jestli se zpráva už jednou replikovala, aby se mezi párem front neodskakovala, ale spíše se zasílají do pomocné fronty, která funguje jako fronta nedoručených zpráv pro složený vzor.
Tento model je vhodný pro scénáře, kdy hlavním zájmem je bránit se problémům s dostupností v konzumentech nebo prostředcích, na kterých se spotřebitelé spoléhají, a také k redistribuci špiček provozu v jedné z spárovaných front. Poskytuje také ochranu proti nedostupnosti jednoho z oborů názvů, pokud uživatelé čtou z obou front, ale prodleva replikace uložená vypršením
TimeToLiveplatnosti může způsobit, že zprávy v daném časovém intervalu budou zřetězené v nedostupném oboru názvů.
Optimalizace latence
Témata se používají k distribuci informací více příjemcům. V některých případech, zejména spotřebitelé s širokou geografickou distribucí, může být užitečné replikovat zprávy z tématu do tématu v sekundárním oboru názvů blíže spotřebitelům.
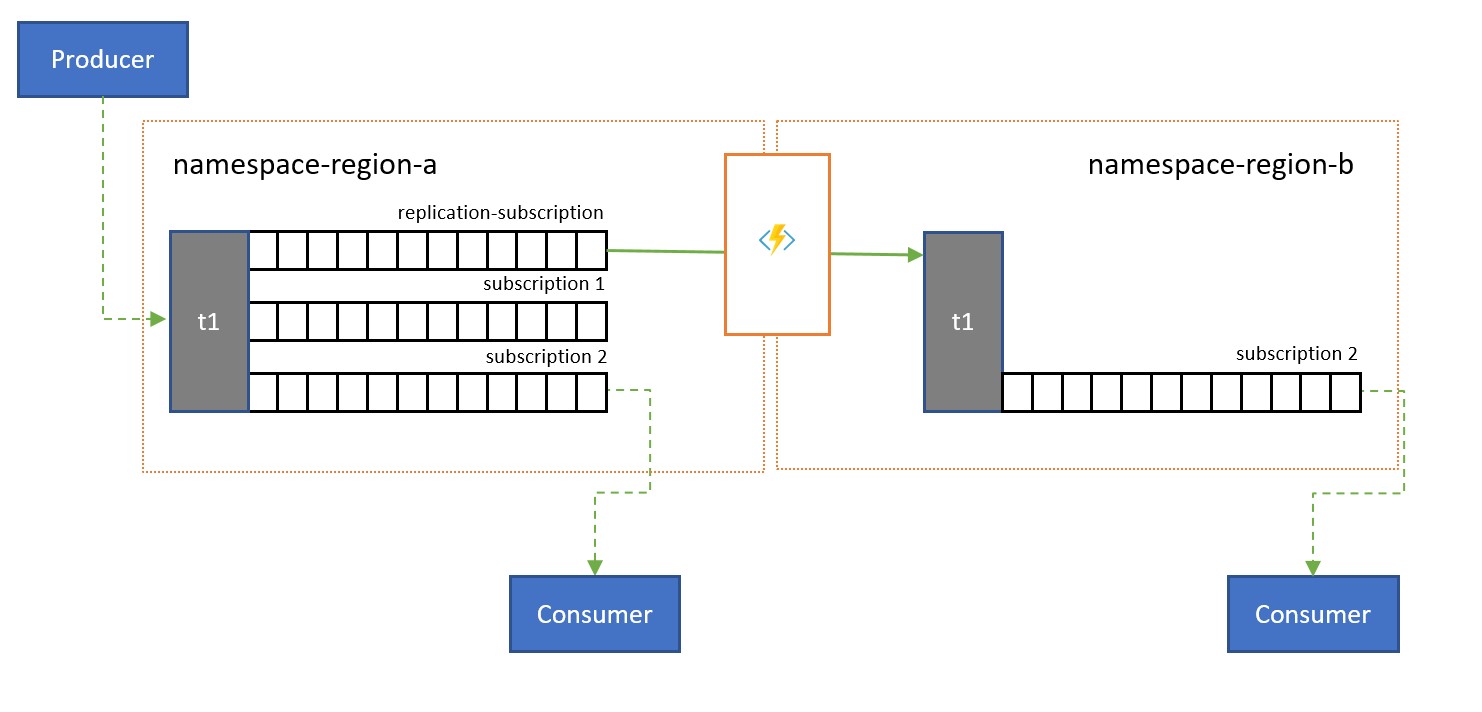
Například při sdílení dat mezi regionálními, kontinentálními rozbočovači je efektivnější přenášet informace pouze jednou mezi centry a získat jejich kopii z těchto center.
Přenosy replikace je možné provádět v dávkách, které uživatelé často získávají a urovnávat zprávy o jedné po druhé. Při základní latenci sítě o délce 100 ms mezi Severní Amerika a Evropou trvá zpracování každé zprávy o délce 200 ms déle, než se dvě doby odezvy na vzdálenou entitu pro získání a vyrovnání zpráv v porovnání s entitou ve stejné oblasti.
Ověřování, redukce a rozšiřování
Zprávy mohou být odeslány do fronty služby Service Bus nebo tématu klienty, kteří jsou externí pro vaše vlastní řešení.
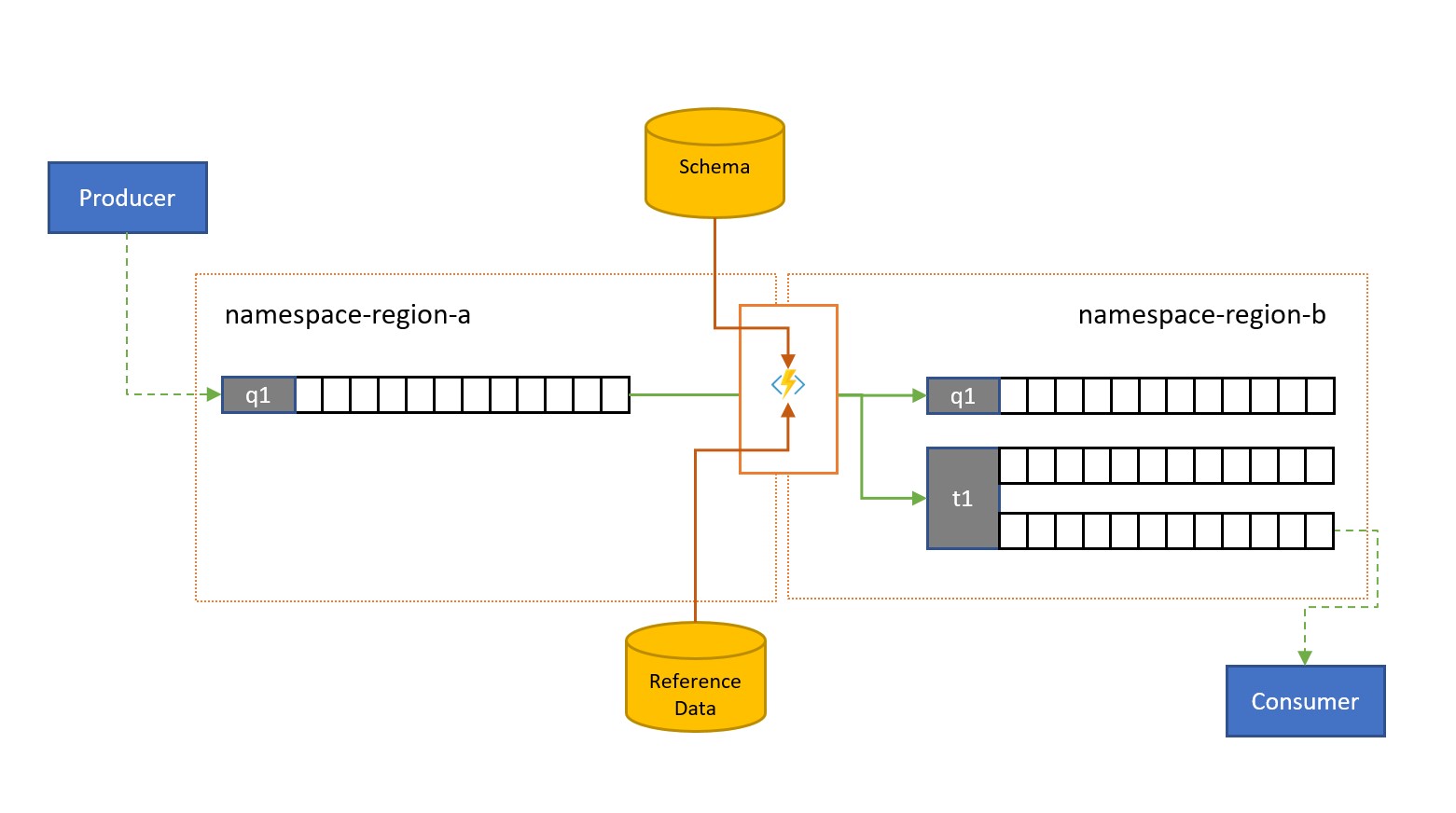
Tyto zprávy můžou vyžadovat kontrolu dodržování předpisů s daným schématem a pro zprávy, které nedodržují předpisy, nebo nedoručené dopisy. Některé zprávy můžou být složité snížit vynecháním dat a některé se můžou rozšířit přidáním dat na základě vyhledávání referenčních dat. Operace je možné provádět s vlastními funkcemi v úloze replikace.
Replikace streamu do fronty
Azure Event Hubs je ideální řešení pro zpracování extrémních objemů příchozích událostí. Služba Event Hubs ani podobné moduly, jako je Apache Kafka, ale poskytují model příjemců spravovaný službou, kde více příjemců dokáže zpracovávat zprávy ze stejného zdroje souběžně bez rizika duplikování zpracování a nakonec tyto zprávy po zpracování vyřešte.
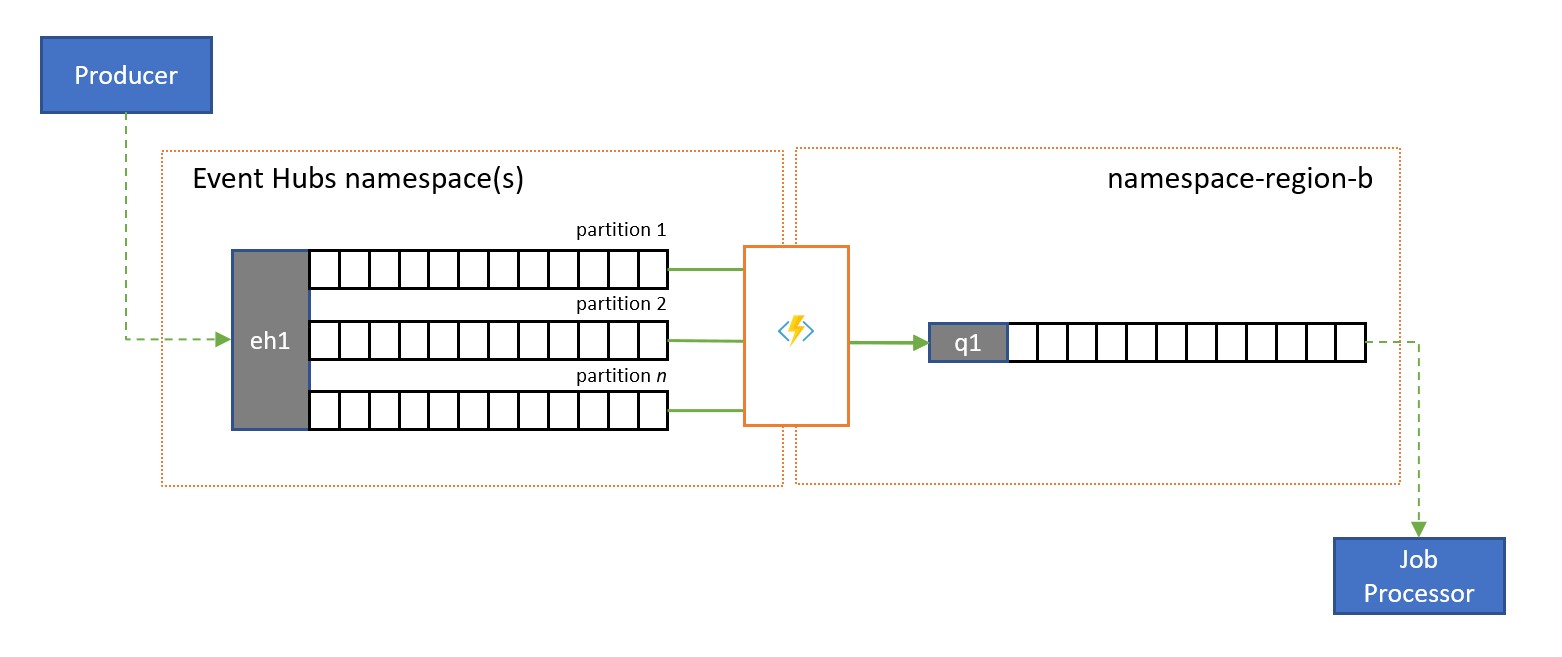
Datový proud pro replikaci fronty přenáší obsah jednoho oddílu centra událostí nebo obsahu úplného centra událostí do fronty služby Service Bus, odkud lze zprávy bezpečně zpracovávat, transakčním způsobem a s konkurenčními příjemci. Tato replikace také umožňuje používat všechny ostatní funkce služby Service Bus pro tyto zprávy, včetně směrování s tématy a demultiplexem založeným na relacích.
Konsolidace a normalizace
Globální řešení se často skládají z regionálních stop, které jsou z velké části nezávislé, včetně jejich vlastních možností zpracování, ale nadnárodní a globální perspektivy budou vyžadovat integraci dat, a proto centrální konsolidace stejných dat zpráv, která se vyhodnocují v příslušných regionálních stopách pro místní perspektivu.
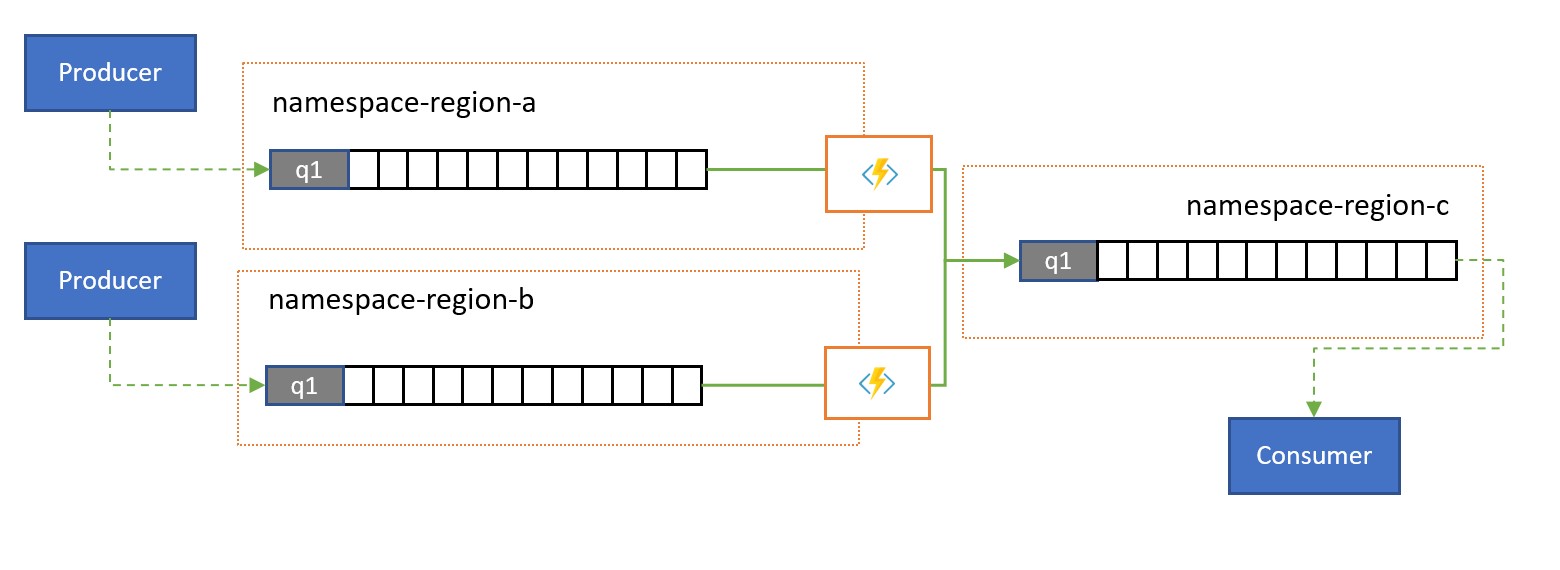
Normalizace je příchuť scénáře konsolidace, kdy dvě nebo více příchozích sekvencí zpráv obsahují stejný druh informací, ale s různými strukturami nebo různými kódováními a zprávy musí být před použitím transkódovány nebo transformovány.
Normalizace může také zahrnovat kryptografickou práci, jako je dešifrování komplexních šifrovaných datových částí a jejich opětovné šifrování pomocí různých klíčů a algoritmů pro cílovou skupinu příjemců podřízeného příjemce.
Rozdělení a směrování
Témata služby Service Bus a jejich pravidla odběru se často používají k filtrování datového proudu zpráv pro určitou cílovou skupinu a tato cílová skupina pak získala filtrovanou sadu z odběru.
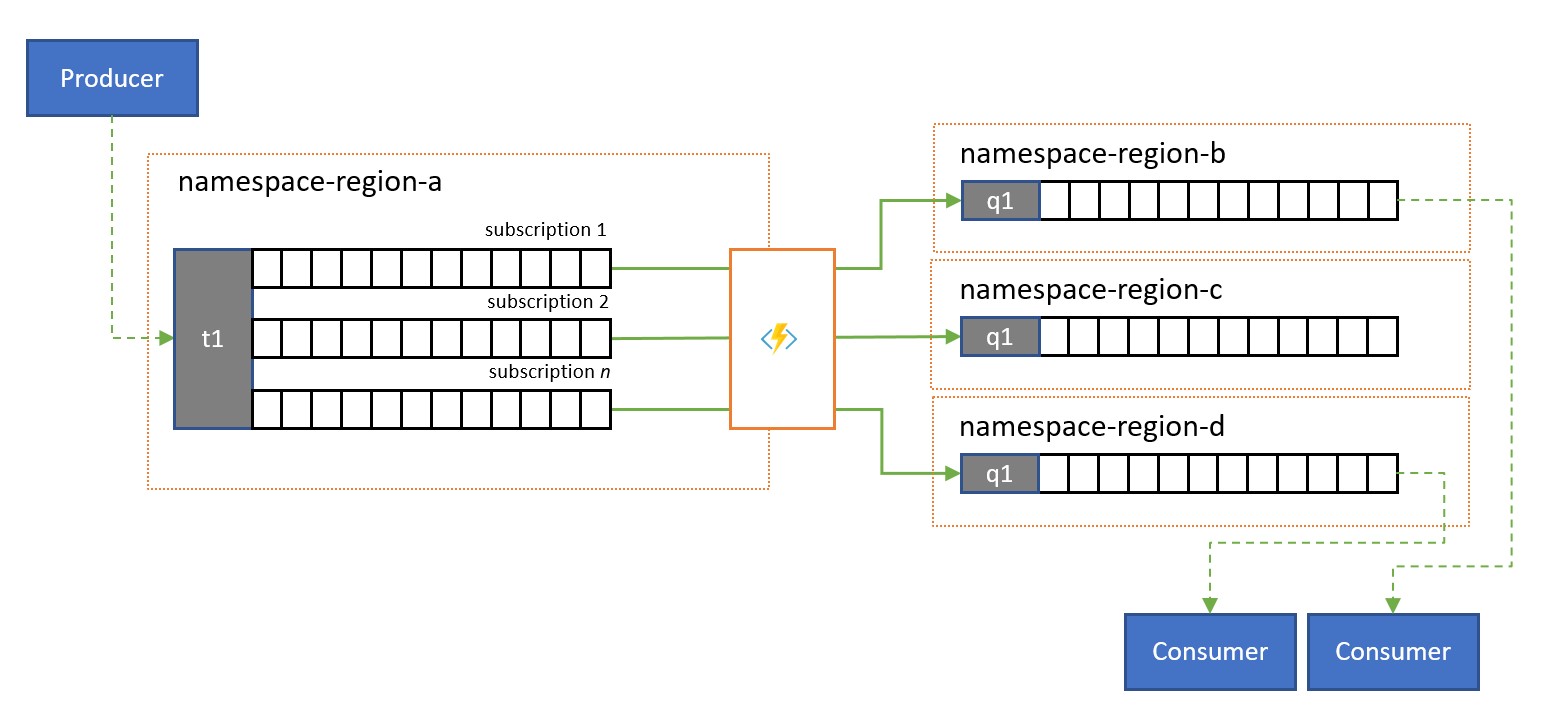
V globálním systému, kde je cílová skupina pro tyto zprávy globálně distribuovaná nebo patří do různých aplikací, je možné replikaci použít k přenosu zpráv z takového odběru do fronty nebo tématu v jiném oboru názvů, odkud se využívají.
Aplikace replikace ve službě Azure Functions
Implementace výše uvedených vzorů vyžaduje škálovatelné a spolehlivé spouštěcí prostředí pro úlohy replikace, které chcete nakonfigurovat a spustit. V Azure je prostředí runtime, které je nejvhodnější pro bezstavové úlohy , Azure Functions.
Služba Azure Functions může běžet pod spravovanou identitou Azure, aby se úlohy replikace mohly integrovat s pravidly řízení přístupu na základě role zdrojové a cílové služby, aniž byste museli spravovat tajné kódy v cestě replikace. Pro zdroje a cíle replikace, které vyžadují explicitní přihlašovací údaje, může Služba Azure Functions uchovávat hodnoty konfigurace těchto přihlašovacích údajů v úzce řízeném úložišti v rámci služby Azure Key Vault.
Azure Functions navíc umožňuje úlohy replikace přímo integrovat s virtuálními sítěmi Azure a koncovými body služby pro všechny služby zasílání zpráv Azure a je snadno integrována se službou Azure Monitor.
Nejdůležitější je, že Azure Functions má předem připravené, škálovatelné triggery a výstupní vazby pro Azure Event Hubs, Azure IoT Hub, Azure Service Bus, Azure Event Grid a Azure Queue Storage, vlastní rozšíření pro RabbitMQ a Apache Kafka. Většina triggerů se dynamicky přizpůsobí potřebám propustnosti škálováním počtu souběžně spuštěných instancí nahoru a dolů na základě zdokumentovaných metrik.
S plánem consumption služby Azure Functions můžou předem připravené triggery dokonce vertikálně snížit kapacitu na nulu, i když nejsou k dispozici žádné zprávy pro replikaci, což znamená, že vám nebudou účtovány žádné náklady na udržování konfigurace připravené na vertikální navýšení kapacity. Klíčovou nevýhodou použití plánu consumption je, že latence úloh replikace se z tohoto stavu "probouzí" výrazně vyšší než u plánů hostování, ve kterých je infrastruktura stále spuštěná.
Na rozdíl od všech těchto nejběžnějších replikovacích modulů pro zasílání zpráv a událostí, jako je zrcadlení Apache Kafka, vyžadují, abyste poskytli hostitelské prostředí a škálujte replikační modul sami. To zahrnuje konfiguraci a integraci funkcí zabezpečení a sítí a usnadnění toku dat monitorování a pak ještě nemáte možnost vkládat do toku vlastní úlohy replikace.
Úlohy replikace pomocí Azure Logic Apps
Nekódovací alternativou k replikaci pomocí služby Functions by bylo místo toho použít Logic Apps . Logic Apps mají předdefinované úlohy replikace pro Service Bus. To může pomoct s nastavením replikace mezi různými instancemi a je možné je upravit pro další přizpůsobení.
Další kroky
V tomto článku jsme prozkoumali řadu vzorů federace a vysvětlili jsme roli Azure Functions jako modulu runtime replikace událostí a zasílání zpráv v Azure.
Dále si můžete přečíst, jak nastavit aplikaci replikátoru pomocí azure Functions a jak pak replikovat toky událostí mezi event Hubs a různými dalšími systémy událostí a zasílání zpráv: