Plánování kapacity pro aplikace Service Fabric
V tomto dokumentu se dozvíte, jak odhadnout množství prostředků (procesory, paměť RAM, diskové úložiště), které potřebujete ke spuštění aplikací Azure Service Fabric. Běžné je, že vaše požadavky na prostředky se v průběhu času mění. Při vývoji nebo otestování služby obvykle potřebujete několik prostředků a pak při přechodu do produkčního prostředí potřebujete další prostředky a vaše aplikace roste oblíbeně. Při návrhu aplikace si promyslete dlouhodobé požadavky a volby, které vaší službě umožní škálovat tak, aby splňovaly vysokou poptávku zákazníků.
Při vytváření clusteru Service Fabric se rozhodnete, jaké druhy virtuálních počítačů tvoří cluster. Každý virtuální počítač má omezené množství prostředků ve formě procesorů (jader a rychlosti), šířky pásma sítě, paměti RAM a diskového úložiště. S tím, jak vaše služba v průběhu času roste, můžete upgradovat na virtuální počítače, které nabízejí větší prostředky, nebo přidat do clusteru další virtuální počítače. Pokud to chcete udělat, musíte nejprve navrhnout službu, aby mohl využívat nové virtuální počítače, které se dynamicky přidají do clusteru.
Některé služby spravují málo dat na samotných virtuálních počítačích. Plánování kapacity pro tyto služby by se proto mělo zaměřit především na výkon, což znamená výběr vhodných procesorů (jader a rychlosti) virtuálních počítačů. Kromě toho byste měli zvážit šířku pásma sítě, včetně toho, jak často dochází k síťovým přenosům a kolik dat se přenáší. Pokud vaše služba potřebuje provádět i zvýšení využití služeb, můžete do clusteru přidat další virtuální počítače a vyrovnávat zatížení síťových požadavků napříč všemi virtuálními počítači.
U služeb, které spravují velké objemy dat na virtuálních počítačích, by se plánování kapacity mělo zaměřit především na velikost. Proto byste měli pečlivě zvážit kapacitu paměti RAM virtuálního počítače a diskového úložiště. Systém pro správu virtuální paměti ve Windows zajišťuje, aby místo na disku vypadalo jako paměť RAM pro kód aplikace. Modul runtime Service Fabric navíc poskytuje inteligentní stránkování, které uchovává jen horká data v paměti a přesouvá studená data na disk. Aplikace tak mohou využívat více paměti, než je fyzicky dostupné na virtuálním počítači. Více paměti RAM jednoduše zvyšuje výkon, protože virtuální počítač může udržovat větší diskové úložiště v paměti RAM. Vybraný virtuální počítač by měl mít dost velký disk pro uložení požadovaných dat na virtuálním počítači. Podobně by měl mít virtuální počítač dostatek paměti RAM k zajištění požadovaného výkonu. Pokud data vaší služby v průběhu času rostou, můžete do clusteru přidat další virtuální počítače a rozdělit data mezi všechny virtuální počítače.
Určení, kolik uzlů potřebujete
Rozdělením služby můžete škálovat data vaší služby na více instancí. Další informace o dělení najdete v tématu Dělení Service Fabric. Každý oddíl se musí vejít do jednoho virtuálního počítače, ale na jeden virtuální počítač je možné umístit několik (malých) oddílů. Díky většímu počtu malých oddílů tedy získáte větší flexibilitu než mít několik větších oddílů. Kompromisem je, že velké množství oddílů zvyšuje režii Service Fabric a nemůžete provádět transakce napříč oddíly. Existuje také více potenciálního síťového provozu, pokud váš kód služby často potřebuje přístup k částem dat, která žijí v různých oddílech. Při návrhu služby byste měli pečlivě zvážit tyto výhody a nevýhody, abyste došli k efektivní strategii dělení.
Předpokládejme, že vaše aplikace má jednu stavovou službu, která má velikost úložiště, kterou očekáváte, DB_Size GB za rok. Jste ochotni přidávat další aplikace (a oddíly) během růstu nad rámec tohoto roku. Faktor replikace (RF), který určuje počet replik pro vaši službu, ovlivňuje celkový DB_Size. Celkový DB_Size napříč všemi replikami je faktor replikace vynásobený DB_Size. Node_Size představuje místo na disku nebo paměť RAM na uzel, který chcete pro svou službu použít. Pro zajištění nejlepšího výkonu by se DB_Size měly vejít do paměti v clusteru a zvolit Node_Size, která se nachází kolem paměti RAM virtuálního počítače. Přidělením Node_Size, která je větší než kapacita paměti RAM, spoléháte na stránkování poskytované modulem runtime Service Fabric. Proto výkon nemusí být optimální, pokud jsou celá data považována za horká (od té doby se data stránkuje v/ven). U mnoha služeb, kde je jen zlomek dat horký, je ale nákladově efektivnější.
Počet uzlů požadovaných pro maximální výkon je možné vypočítat následujícím způsobem:
Number of Nodes = (DB_Size * RF)/Node_Size
Účet pro růst
Kromě DB_Size, se kterými jste začali, můžete chtít vypočítat počet uzlů na základě DB_Size, na které očekáváte, že vaše služba roste. Pak s růstem služby zvětšujte počet uzlů, abyste nezřídili příliš mnoho uzlů. Počet oddílů by ale měl být založený na počtu uzlů, které jsou potřeba při maximálním růstu služby.
Je dobré mít kdykoli k dispozici několik dalších počítačů, abyste mohli zvládnout jakékoli neočekávané špičky nebo selhání (například pokud dojde k výpadku několika virtuálních počítačů). I když by se měla kapacita navíc určit pomocí očekávaných špiček, výchozím bodem je rezervovat několik dalších virtuálních počítačů (5 až 10 procent navíc).
Předchozí předpokládá jednu stavovou službu. Pokud máte více stavových služeb, musíte do rovnice přidat DB_Size přidružené k ostatním službám. Alternativně můžete vypočítat počet uzlů samostatně pro každou stavovou službu. Vaše služba může mít repliky nebo oddíly, které nejsou vyváženy. Mějte na paměti, že oddíly můžou mít také více dat než ostatní. Další informace o dělení najdete v článku o dělení na osvědčené postupy. Předchozí rovnice je ale nezávislá na oddílech a replikách, protože Service Fabric zajišťuje, že se repliky rozdělí mezi uzly optimalizovaným způsobem.
Použití tabulky pro výpočet nákladů
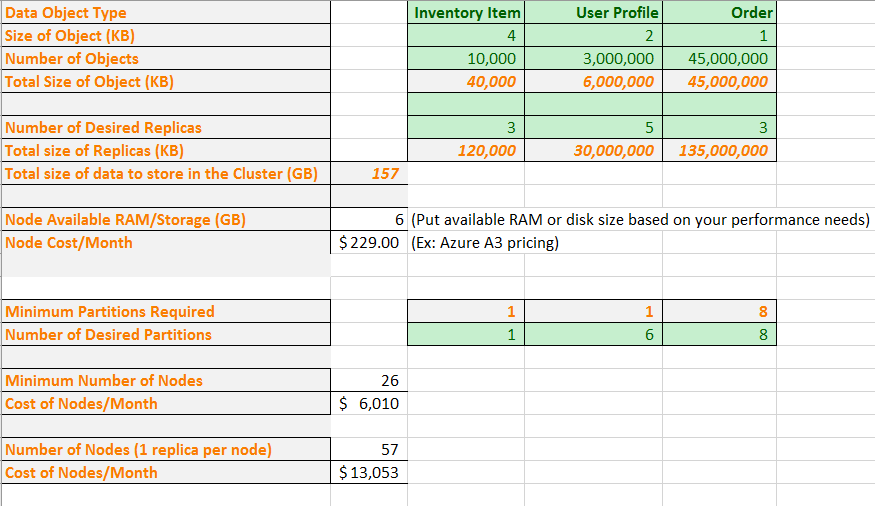
Teď do vzorce vložíme nějaká reálná čísla. Příklad tabulky ukazuje, jak naplánovat kapacitu aplikace, která obsahuje tři typy datových objektů. U každého objektu odhadujeme jeho velikost a počet objektů, které očekáváme. Také vybereme, kolik replik chceme pro každý typ objektu. Tabulka vypočítá celkovou velikost paměti, která se má uložit v clusteru.
Pak zadáme velikost virtuálního počítače a měsíční náklady. Na základě velikosti virtuálního počítače tabulka uvádí minimální počet oddílů, které musíte použít k rozdělení dat tak, aby se fyzicky vešly do uzlů. Můžete chtít větší počet oddílů, aby vyhovovaly konkrétním výpočtům a potřebám síťového provozu vaší aplikace. Tabulka ukazuje počet oddílů, které spravují objekty profilů uživatelů, se zvýšil z jedné na šest.
Na základě všech těchto informací teď tabulka ukazuje, že můžete fyzicky získat všechna data s požadovanými oddíly a replikami v clusteru s 26 uzly. Tento cluster by ale byl hustě zabalený, takže můžete chtít, aby některé další uzly vyhovovaly selháním a upgradům uzlů. Tabulka také ukazuje, že mít více než 57 uzlů neposkytuje žádnou další hodnotu, protože byste měli prázdné uzly. Opět můžete chtít přejít na více než 57 uzlů, aby se chovala selhání a upgrady uzlů. Tabulku můžete upravit tak, aby odpovídala konkrétním potřebám vaší aplikace.
Další kroky
Další informace o dělení služby Service Fabric najdete v tématu Dělení služeb Service Fabric.