Diagnostika běžných scénářů pomocí Service Fabric
Tento článek ukazuje běžné scénáře, se kterými se uživatelé setkávají v oblasti monitorování a diagnostiky pomocí Service Fabric. Uvedené scénáře pokrývají všechny tři vrstvy service fabric: aplikace, cluster a infrastruktura. Každé řešení používá k dokončení každého scénáře protokoly Application Insights a Azure Monitor, nástroje pro monitorování Azure. Kroky v jednotlivých řešeních poskytují uživatelům úvod k používání protokolů Application Insights a Azure Monitoru v kontextu Service Fabric.
Požadavky a doporučení
Řešení v tomto článku používají následující nástroje. Doporučujeme, abyste měli tyto nastavení a konfiguraci:
- Application Insights s Využitím Service Fabric
- Povolení diagnostiky Azure v clusteru
- Nastavení pracovního prostoru služby Log Analytics
- Agent Log Analytics ke sledování čítačů výkonu
Jak se v aplikaci zobrazují neošetřené výjimky?
Přejděte k prostředku Application Insights, se kterým je vaše aplikace nakonfigurovaná.
V levém horním rohu vyberte Hledat . Pak vyberte filtr na dalším panelu.
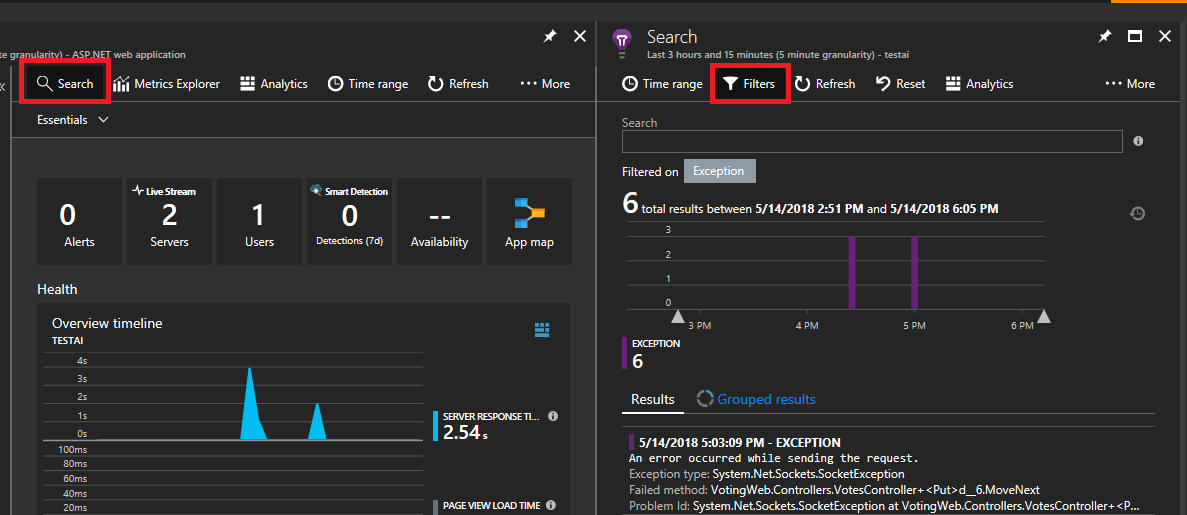
Zobrazí se spousta typů událostí (trasování, požadavky, vlastní události). Jako filtr zvolte "Výjimka".
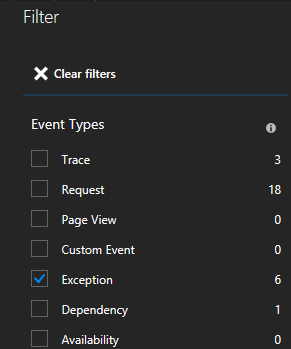
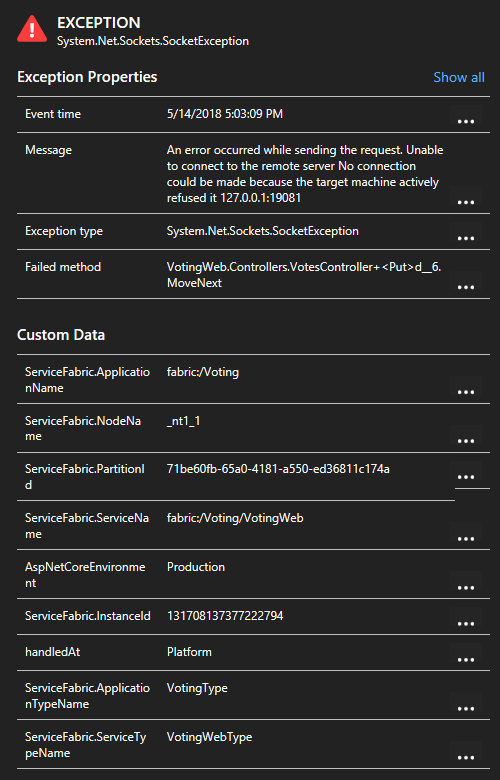
Kliknutím na výjimku v seznamu se můžete podívat na další podrobnosti, včetně kontextu služby, pokud používáte sadu Service Fabric Application Insights SDK.
Návody zobrazit, která volání HTTP se používají v mých službách?
Ve stejném prostředku Application Insights můžete místo výjimek filtrovat podle požadavků a zobrazit všechny provedené žádosti.
Pokud používáte sadu Service Fabric Application Insights SDK, můžete zobrazit vizuální znázornění služeb propojených s sebou a počet úspěšných a neúspěšných požadavků. Na levé straně vyberte "Mapa aplikace"
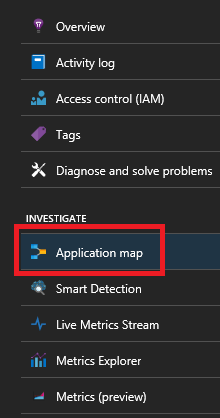
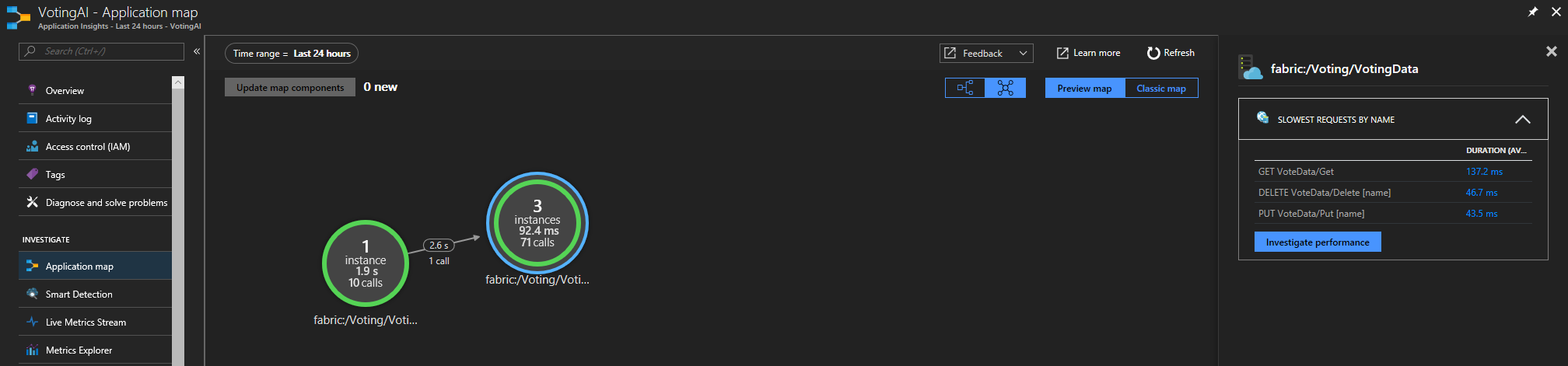
Další informace o mapě aplikace najdete v dokumentaci k mapě aplikace.
Návody vytvoření výstrahy při výpadku uzlu
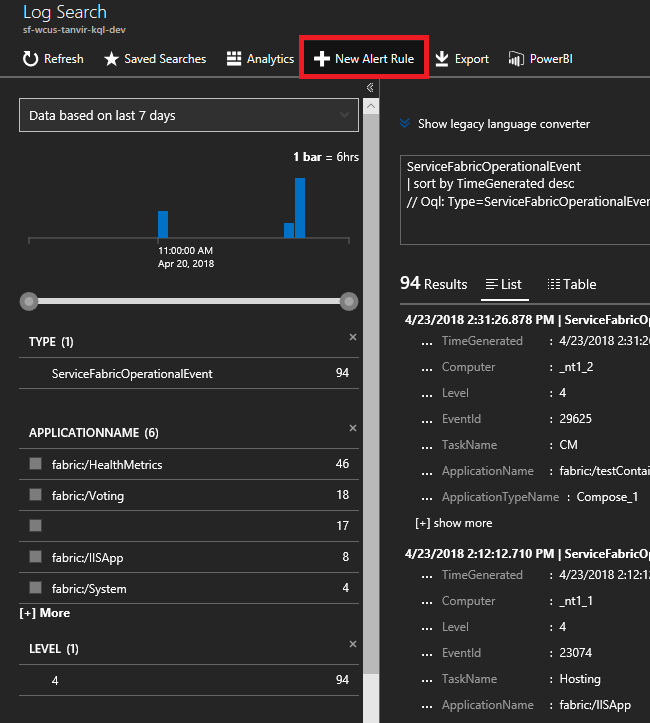
Události uzlů jsou sledovány clusterem Service Fabric. Přejděte k prostředku řešení Service Fabric Analytics s názvem ServiceFabric(NameofResourceGroup).
Vyberte graf v dolní části okna s názvem Souhrn.

Tady máte mnoho grafů a dlaždic zobrazující různé metriky. Vyberte jeden z grafů a přejdete do prohledávání protokolu. Tady můžete dotazovat na všechny události clusteru nebo čítače výkonu.
Zadejte následující dotaz. Tato ID událostí se nacházejí v referenčních informacích k událostem uzlu.
ServiceFabricOperationalEvent | where EventID >= 25622 and EventID <= 25626V horní části vyberte "Nové pravidlo upozornění" a nyní kdykoli na základě tohoto dotazu přijde událost, dostanete upozornění ve zvolené metodě komunikace.
Jak můžu být upozorněn(a) na vrácení zpět při upgradu aplikace?
Ve stejném okně prohledávání protokolu jako předtím zadejte následující dotaz pro vrácení zpět upgradu. Tato ID událostí se nacházejí v referenčních informacích k událostem aplikace.
ServiceFabricOperationalEvent | where EventID == 29623 or EventID == 29624V horní části vyberte "Nové pravidlo upozornění" a kdykoliv na základě tohoto dotazu přijde událost, zobrazí se upozornění.
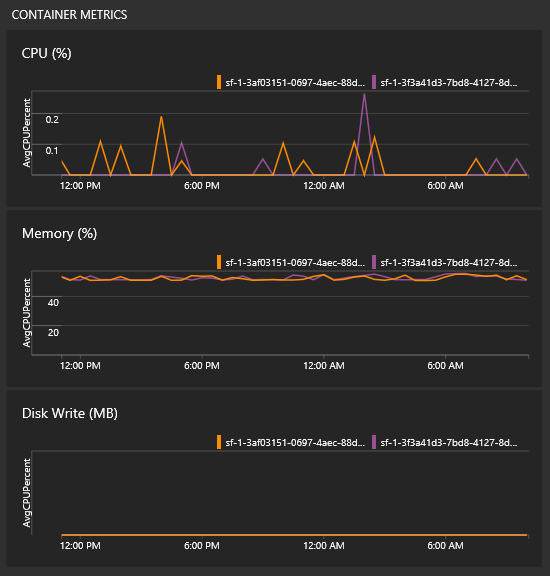
Návody zobrazit metriky kontejneru?
Ve stejném zobrazení se všemi grafy uvidíte některé dlaždice pro výkon kontejnerů. K naplnění těchto dlaždic potřebujete řešení Log Analytics Agent a Container Monitoring.
Poznámka:
Pokud chcete instrumentovat telemetrii z vašeho kontejneru, budete muset přidat balíček NuGet Application Insights pro kontejnery.
Jak můžu monitorovat čítače výkonu?
Po přidání agenta Log Analytics do clusteru musíte přidat konkrétní čítače výkonu, které chcete sledovat. Na portálu přejděte na stránku pracovního prostoru služby Log Analytics – na stránce řešení je karta pracovního prostoru v levé nabídce.
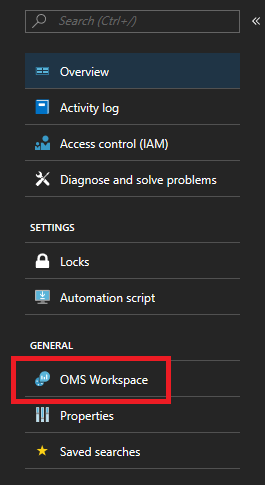
Jakmile budete na stránce pracovního prostoru, v nabídce vlevo vyberte Upřesnit nastavení.
Výběrem čítačů výkonu systému > Windows (Čítače výkonu pro > Linux pro počítače s Linuxem) začněte shromažďovat konkrétní čítače z uzlů prostřednictvím agenta Log Analytics. Tady jsou příklady formátu pro čítače, které chcete přidat.
.NET CLR Memory(<ProcessNameHere>)\\# Total committed BytesProcessor(_Total)\\% Processor TimeV rychlém startu jsou použité názvy procesů VotingData a VotingWeb, takže sledování těchto čítačů by vypadalo takto:
.NET CLR Memory(VotingData)\\# Total committed Bytes.NET CLR Memory(VotingWeb)\\# Total committed Bytes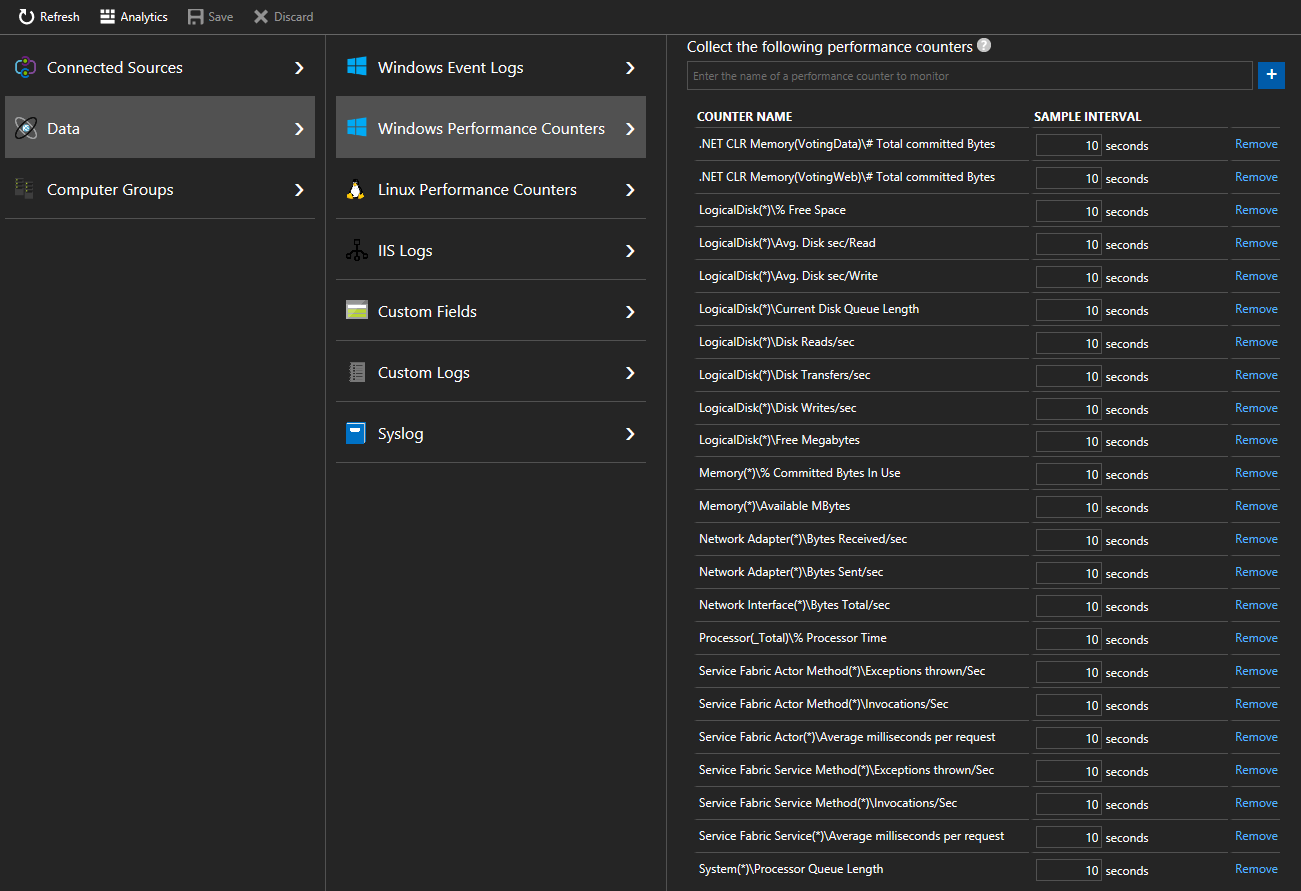
To vám umožní zjistit, jak vaše infrastruktura zpracovává vaše úlohy, a nastavit relevantní výstrahy na základě využití prostředků. Můžete například nastavit upozornění, pokud celkové využití procesoru překročí 90 % nebo nižší než 5 %. Název čítače, který byste použili, je %Time procesoru. Můžete to udělat vytvořením pravidla upozornění pro následující dotaz:
Perf | where CounterName == "% Processor Time" and InstanceName == "_Total" | where CounterValue >= 90 or CounterValue <= 5.
Návody sledovat výkon mých služeb Reliable Services a Actors?
Pokud chcete sledovat výkon Reliable Services nebo Actors ve vašich aplikacích, měli byste shromáždit také čítače Service Fabric Actor, Actor Method, Service a Service Method. Tady jsou příklady spolehlivých čítačů výkonu služby a objektu actor ke shromažďování.
Poznámka:
Čítače výkonu Service Fabric v současné době neshromažďuje agent Log Analytics, ale můžou je shromažďovat jiná diagnostická řešení.
Service Fabric Service(*)\\Average milliseconds per requestService Fabric Service Method(*)\\Invocations/SecService Fabric Actor(*)\\Average milliseconds per requestService Fabric Actor Method(*)\\Invocations/Sec
Na těchto odkazech najdete úplný seznam čítačů výkonu pro Reliable Services a Actors.
Další kroky
- Vyhledání běžných chyb aktivace balíčku kódu
- Nastavení upozornění v AI tak, aby dostávala oznámení o změnách výkonu nebo využití
- Inteligentní zjišťování v Application Insights provádí proaktivní analýzu telemetrie odesílané do AI, která vás upozorní na potenciální problémy s výkonem.
- Přečtěte si další informace o upozorňování protokolů služby Azure Monitor, které vám pomůžou s detekcí a diagnostikou.
- V případě místních clusterů nabízí protokoly Služby Azure Monitor bránu (přesměrovávaný proxy server HTTP), kterou je možné použít k odesílání dat do protokolů služby Azure Monitor. Přečtěte si další informace o připojení počítačů bez přístupu k internetu k protokolům služby Azure Monitor pomocí brány Log Analytics.
- Seznamte se s funkcemi prohledávání protokolů a dotazováním nabízenými jako součást protokolů služby Azure Monitor
- Podrobný přehled protokolů služby Azure Monitor a jeho nabídky najdete v tématu Co jsou protokoly služby Azure Monitor?