Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
K dispozici v cloudu i v Azure IoT Edge nabízí Azure Stream Analytics integrované funkce detekce anomálií založených na strojovém učení, které můžete použít k monitorování dvou nejčastěji se vyskytujících anomálií: dočasných a trvalých. Pomocí funkcí AnomalyDetection_SpikeAndDip a AnomalyDetection_ChangePoint můžete provádět detekci anomálií přímo v úloze Stream Analytics.
Modely strojového učení předpokládají jednotně vzorkovanou časovou řadu. Pokud časová řada není jednotná, před voláním detekce anomálií vložte krok agregace s přeskakujícím oknem.
Operace strojového učení v současné době nepodporují trendy sezónnosti ani multivariátní korelace.
Detekce anomálií pomocí strojového učení v Azure Stream Analytics
Následující video ukazuje, jak detekovat anomálie v reálném čase pomocí funkcí strojového učení v Azure Stream Analytics.
Chování modelu
Obecně platí, že přesnost modelu se zlepšuje s více daty v posuvném okně. Data v zadaném posuvném okně se považují za součást svého normálního rozsahu hodnot pro daný časový rámec. Model posuzuje historii událostí pouze v rámci posuvného okna, aby zjistil, zda je aktuální událost neobvyklá. Při pohybu posuvného okna se staré hodnoty vyřadí z trénování modelu.
Funkce pracují vytvořením určitého standardu na základě toho, co bylo dosud zaznamenáno. Odlehlé hodnoty jsou identifikovány porovnáním se zavedenou normou v rámci intervalu spolehlivosti. Velikost okna by měla být založena na minimálních událostech potřebných k trénování modelu pro normální chování, aby při výskytu anomálií bylo možné ho rozpoznat.
Doba odezvy modelu se zvyšuje s velikostí historie, protože musí porovnat s vyšším počtem minulých událostí. Pokud chcete dosáhnout lepšího výkonu, zahrňte pouze potřebný počet událostí.
Mezery v časové řadě můžou nastat, když model v určitých bodech v čase nepřijímá události. Stream Analytics tuto situaci zpracovává pomocí logiky imputace. Velikost historie a doba trvání pro stejné posuvné okno se používá k výpočtu průměrné rychlosti, s jakou se očekává příchod událostí.
Pomocí generátoru anomaly můžete poskytnout IoT Hub daty, která obsahují různé vzory anomálií. Úlohu Azure Stream Analytics můžete nastavit pomocí těchto funkcí detekce anomálií ke čtení z tohoto IoT Hubu a k detekci anomálií.
Špička a pokles
Dočasné anomálie v datovém proudu událostí časové řady se označují jako špičky a poklesy. Špičky a poklesy můžete monitorovat pomocí operátoru založeného na Machine Learning AnomalyDetection_SpikeAndDip.
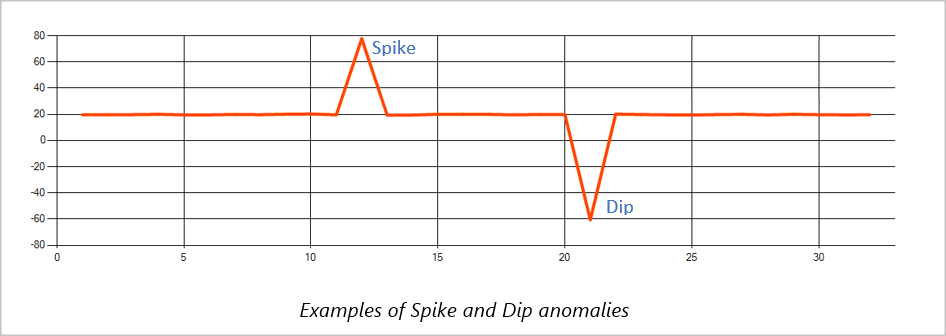
Pokud je ve stejném posuvném okně druhá špička menší než první, vypočítané skóre pro menší špičku nemusí být ve srovnání se skóre pro první špičku na zadané úrovni spolehlivosti dostatečně významné. Pokud chcete zjistit takové anomálie, můžete zkusit snížit úroveň spolehlivosti modelu. Pokud ale začnete dostávat příliš mnoho upozornění, použijte vyšší interval spolehlivosti.
Následující příklad dotazu předpokládá jednotnou vstupní rychlost jedné události za sekundu v 2minutovém posuvném okně s historií 120 událostí. Konečný příkaz SELECT extrahuje a vypíše skóre a stav anomálií s úrovní spolehlivosti 95%.
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_SpikeAndDip(CAST(temperature AS float), 95, 120, 'spikesanddips')
OVER(LIMIT DURATION(second, 120)) AS SpikeAndDipScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'Score') AS float) AS
SpikeAndDipScore,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'IsAnomaly') AS bigint) AS
IsSpikeAndDipAnomaly
INTO output
FROM AnomalyDetectionStep
Bod změny
Trvalé anomálie v datovém proudu událostí časové řady jsou změny v distribuci hodnot v datovém proudu událostí, jako jsou změny na úrovni a trendy. Ve službě Stream Analytics operátor založený na strojovém učení AnomalyDetection_ChangePoint detekuje tyto anomálie.
Trvalé změny trvají mnohem déle než špičky a poklesy a mohly by značit katastrofické události. Trvalé změny nejsou obvykle viditelné pro nahý oko, ale operátor AnomalyDetection_ChangePoint je dokáže rozpoznat.
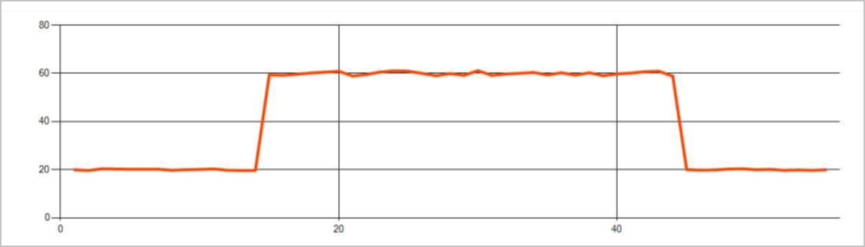
Následující obrázek je příkladem změny úrovně:
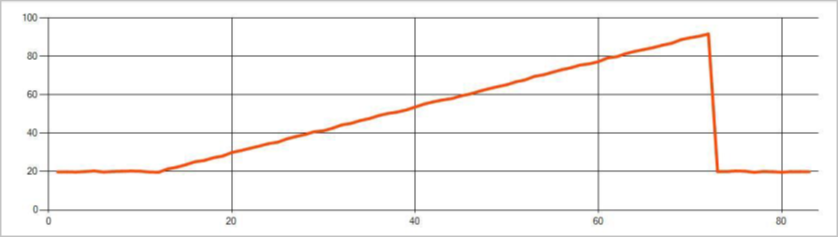
Na následujícím obrázku je příklad změny trendu:
Následující příklad dotazu předpokládá jednotnou vstupní rychlost jedné události za sekundu v 20minutovém posuvném okně s velikostí historie 1 200 událostí. Konečný příkaz SELECT extrahuje a vypíše skóre a stav anomálií s úrovní spolehlivosti 80%.
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_ChangePoint(CAST(temperature AS float), 80, 1200)
OVER(LIMIT DURATION(minute, 20)) AS ChangePointScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(ChangePointScores, 'Score') AS float) AS
ChangePointScore,
CAST(GetRecordPropertyValue(ChangePointScores, 'IsAnomaly') AS bigint) AS
IsChangePointAnomaly
INTO output
FROM AnomalyDetectionStep
Charakteristiky výkonu
Výkon těchto modelů závisí na velikosti historie, délce okna, zatížení událostí a na tom, zda je použito dělení na úrovni funkcí. Tato část popisuje tyto konfigurace a poskytuje ukázky pro udržení míry příjmu 1 K, 5 K a 10 K událostí za sekundu.
- Velikost historie – Tyto modely fungují lineárně s velikostí historie. Čím delší je délka historie, tím déle trvá modelům vyhodnotit novou událost. Modely porovnávají novou událost s každou z minulých událostí ve vyrovnávací paměti historie.
- Doba trvání okna – Doba trvání okna by měla odrážet dobu trvání příjmu tolik událostí, kolik určuje velikost historie. Bez dostatečného počtu událostí v okně by služby Azure Stream Analytics doplňovaly chybějící hodnoty. Proto je spotřeba procesoru funkcí velikosti historie.
- Zatížení událostí – čím větší je zatížení událostí, tím více fungují modely, což má vliv na spotřebu procesoru. Kapacitu úlohy můžete škálovat tak, že ji rozdělíte na triviálně paralelní části, pokud to dává smysl z hlediska obchodní logiky a při použití více vstupních oddílů.
-
Dělení na úrovni funkce – Při volání funkce detekce anomálií použijte
PARTITION BYk provedení dělení na úrovni funkce. Tento typ dělení přidává náklady, protože úloha musí současně udržovat stav pro více modelů. Používejte dělení na úrovni funkcí ve scénářích, jako je dělení na úrovni zařízení.
Vztah
Velikost historie, doba trvání okna a celkové zatížení událostí souvisejí následujícím způsobem:
windowDuration (v ms) = 1000 * historySize / (celkový počet vstupních událostí za sekundu / počet vstupních oddílů)
Při dělení funkce podle id zařízení přidejte "PARTITION BY deviceId" do volání funkce detekce anomálií.
Postřehy
Následující tabulka ukazuje pozorování propustnosti jednoho uzlu (šest jednotek SU) pro případ bez rozdělení na části:
| Velikost historie (události) | Doba trvání okna (ms) | Celkový počet vstupních událostí za sekundu |
|---|---|---|
| 60 | 55 | 2 200 |
| 600 | 728 | 1,650 |
| 6 000 | 10,910 | 1 100 |
Následující tabulka ukazuje pozorování propustnosti jednoho uzlu (šest jednotek SU) pro dělený případ:
| Velikost historie (události) | Doba trvání okna (ms) | Celkový počet vstupních událostí za sekundu | Počet zařízení |
|---|---|---|---|
| 60 | 1,091 | 1 100 | 10 |
| 600 | 10,910 | 1 100 | 10 |
| 6 000 | 218,182 | <550 | 10 |
| 60 | 21,819 | 550 | 100 |
| 600 | 218,182 | 550 | 100 |
| 6 000 | 2,181,819 | <550 | 100 |
Vzorový kód pro spuštění nedílených konfigurací najdete v úložišti Streaming At Scale Azure Samples. Kód vytvoří úlohu Stream Analytics bez dělení na úrovni funkce, která jako vstup a výstup používá službu Event Hubs. Testovací klienti generují vstupní zatížení. Každá vstupní událost je dokument JSON 1 kB. Události simulují zařízení IoT odesílající data JSON (až pro 1 K zařízení). Velikost historie, doba trvání okna a celkové zatížení událostí se liší mezi dvěma vstupními oddíly.
Poznámka:
Pokud chcete přesnější odhad, přizpůsobte si vzorky tak, aby vyhovovaly vašemu scénáři.
Identifikace kritických bodů
K identifikaci kritických bodů v pipeline použijte podokno Metriky v úloze Azure Stream Analytics. Zkontrolujte vstupní a výstupní události pro propustnost a zpoždění vodoznaku nebo nevyřízených událostí a zjistěte, jestli úloha udržuje krok se vstupní rychlostí. V případě metrik služby Event Hubs vyhledejte omezené požadavky a odpovídajícím způsobem upravte prahové jednotky. V případě metrik Azure Cosmos DB zkontrolujte Max využité RU/s na rozsah klíčů oddílu v části Propustnost a zajistěte, aby byly rozsahy klíčů oddílů rovnoměrně spotřebovávány. V případě databáze Azure SQL monitorujte Log io a CPU.