Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Azure Vision in Foundry Tools je nástroj Microsoft Foundry , který umožňuje zpracovávat obrázky a vracet informace na základě vizuálních funkcí. V tomto kurzu se naučíte používat Vision k analýze obrázků ve službě Azure Synapse Analytics.
Tento kurz ukazuje použití analýzy textu se službou SynapseML k:
- Extrahování vizuálních funkcí z obsahu obrázku
- Rozpoznávání znaků z obrázků (OCR)
- Analýza obsahu obrázku a vygenerování miniatury
- Detekce a identifikace obsahu specifického pro doménu na obrázku
- Generování značek souvisejících s obrázkem
- Vygenerování popisu celého obrázku v jazyce čitelným pro člověka
Analyzovat obrázek
Extrahuje bohatou sadu vizuálních funkcí na základě obsahu obrázku, jako jsou objekty, tváře, obsah pro dospělé a automaticky generované popisy textu.
Příklad vstupu

# Create a dataframe with the image URLs
df = spark.createDataFrame([
("<replace with your file path>/dog.jpg", )
], ["image", ])
# Run the Vision service. Analyze Image extracts information from/about the images.
analysis = (AnalyzeImage()
.setLinkedService(ai_service_name)
.setVisualFeatures(["Categories","Color","Description","Faces","Objects","Tags"])
.setOutputCol("analysis_results")
.setImageUrlCol("image")
.setErrorCol("error"))
# Show the results of what you wanted to pull out of the images.
display(analysis.transform(df).select("image", "analysis_results.description.tags"))
Očekávané výsledky
["dog","outdoor","fence","wooden","small","brown","building","sitting","front","bench","standing","table","walking","board","beach","holding","bridge"]
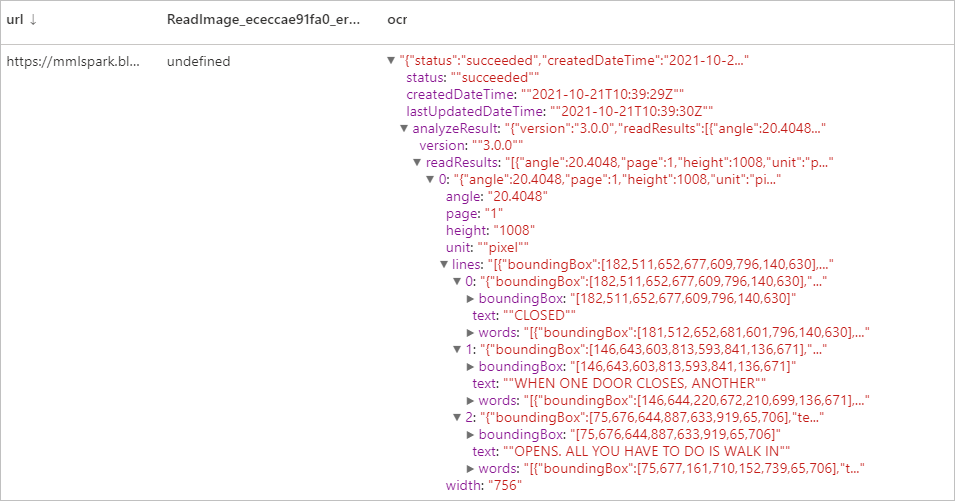
Optické rozpoznávání znaků (OCR)
Extrahujte tištěný text, rukou psaný text, číslice a symboly měny z fotografií, například pouličních cedulí a produktů, a také z dokumentů, jako jsou faktury, účty, finanční zprávy, články a další. Je optimalizovaná pro extrakci textu z textově náročných obrázků a dokumentů PDF s více stránkami se smíšenými jazyky. Podporuje rozpoznávání tištěného i rukou psaného textu ve stejném obrázku nebo dokumentu.
Příklad vstupu

df = spark.createDataFrame([
("<replace with your file path>/ocr.jpg", )
], ["url", ])
ri = (ReadImage()
.setLinkedService(ai_service_name)
.setImageUrlCol("url")
.setOutputCol("ocr"))
display(ri.transform(df))
Očekávané výsledky
Generovat miniatury
Analyzuje obsah obrázku a vytvoří pro obrázek odpovídající miniaturu. Služba Vision nejprve vygeneruje vysoce kvalitní miniaturu a pak analyzuje objekty v obrázku, aby určila oblast zájmu. Vision pak ořezá obrázek tak, aby odpovídal požadavkům oblasti zájmu. Vytvořená miniatura může mít podle vašich potřeb jiný poměr stran než původní obrázek.
Příklad vstupu

df = spark.createDataFrame([
("<replace with your file path>/satya.jpeg", )
], ["url", ])
gt = (GenerateThumbnails()
.setLinkedService(ai_service_name)
.setHeight(50)
.setWidth(50)
.setSmartCropping(True)
.setImageUrlCol("url")
.setOutputCol("thumbnails"))
thumbnails = gt.transform(df).select("thumbnails").toJSON().first()
import json
img = json.loads(thumbnails)["thumbnails"]
displayHTML("<img src='data:image/jpeg;base64," + img + "'>")
Očekávané výsledky

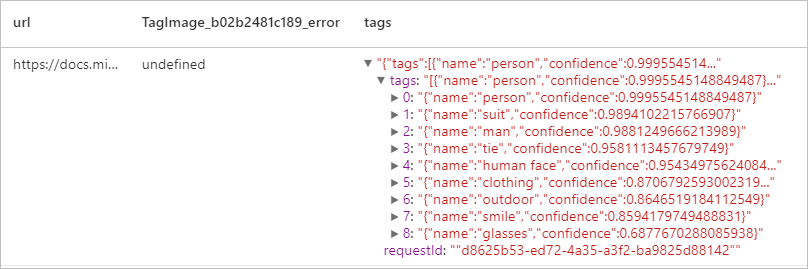
Tagovat obrázek
Vygeneruje seznam slov nebo značek, které jsou relevantní pro obsah zadaného obrázku. Značky jsou vráceny na základě tisíců rozpoznatelných objektů, živých bytostí, scenérií nebo akcí nalezených na obrázcích. Značky mohou obsahovat rady, aby se zabránilo nejednoznačnosti nebo poskytnout kontext, například značka "ascomycete" může být doprovázena nápovědou "houba".
Jako příklad můžeme pokračovat v používání obrázku Satya.
df = spark.createDataFrame([
("<replace with your file path>/satya.jpeg", )
], ["url", ])
ti = (TagImage()
.setLinkedService(ai_service_name)
.setImageUrlCol("url")
.setOutputCol("tags"))
display(ti.transform(df))
Očekávaný výsledek
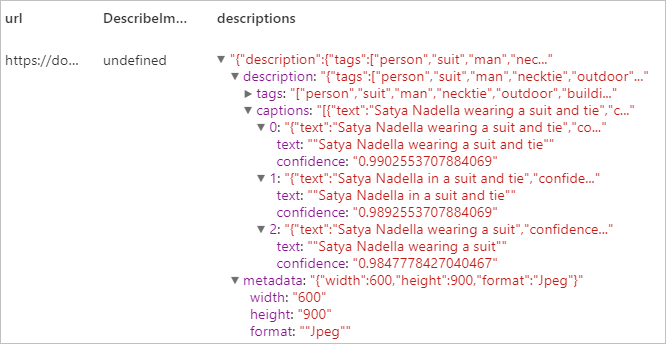
Popsat obrázek
Vygeneruje popis celého obrázku v celých větách v čitelném jazyce. Algoritmy služby Vision generují různé popisy na základě objektů identifikovaných na obrázku. Jednotlivé popisy se vyhodnotí a vygeneruje se pro ně skóre spolehlivosti. Pak se vrátí seznam seřazený od nejvyššího skóre spolehlivosti po nejnižší.
Jako příklad můžeme pokračovat v používání obrázku Satya.
df = spark.createDataFrame([
("<replace with your file path>/satya.jpeg", )
], ["url", ])
di = (DescribeImage()
.setLinkedService(ai_service_name)
.setMaxCandidates(3)
.setImageUrlCol("url")
.setOutputCol("descriptions"))
display(di.transform(df))
Očekávaný výsledek
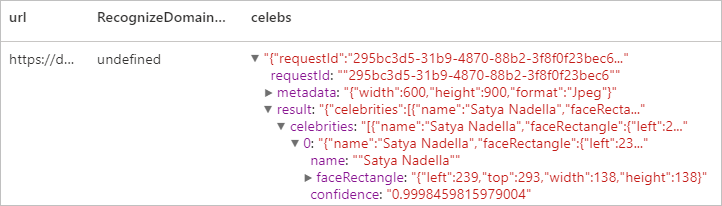
Rozpoznávání obsahu specifického pro doménu
S využitím doménových modelů rozpoznává a identifikuje obsah obrázku specifický pro doménu, například celebrity a památky. Pokud například obrázek obsahuje lidi, může Vision použít doménový model pro celebrity k určení, jestli jsou lidé rozpoznaní na obrázku známé celebrity.
Jako příklad můžeme pokračovat v používání obrázku Satya.
df = spark.createDataFrame([
("<replace with your file path>/satya.jpeg", )
], ["url", ])
celeb = (RecognizeDomainSpecificContent()
.setLinkedService(ai_service_name)
.setModel("celebrities")
.setImageUrlCol("url")
.setOutputCol("celebs"))
display(celeb.transform(df))
Očekávaný výsledek
Vyčištění prostředků
Pokud chcete zajistit, aby se instance Sparku vypnula, ukončete všechny připojené relace (poznámkové bloky). Pool se vypne, když je dosažena zadaná doba nečinnosti ve fondu Apache Spark. Také můžete vybrat zastavit relaci ze stavového řádku v pravém horním rohu poznámkového bloku.
