Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
V tomto kurzu se dozvíte, jak pomocí nástroje Synapse Studio vytvořit definice úloh Apache Sparku a pak je odeslat do bezserverového fondu Apache Spark.
Tento kurz se zabývá následujícími úkony:
- Vytvoření definice úlohy Apache Spark pro PySpark (Python)
- Vytvoření definice úlohy Apache Spark pro Spark (Scala)
- Vytvoření definice úlohy Apache Sparku pro .NET Spark (C#/F#)
- Vytvoření definice úlohy importem souboru JSON
- Export definičního souboru úlohy Apache Sparku do místního prostředí
- Odeslání definice úlohy Apache Sparku jako dávkové úlohy
- Přidání definice úlohy Apache Spark do kanálu
Požadavky
Než začnete s tímto kurzem, ujistěte se, že splňujete následující požadavky:
- Pracovní prostor Azure Synapse Analytics Pokyny najdete v tématu Vytvoření pracovního prostoru Azure Synapse Analytics.
- Bezserverový fond Apache Spark.
- Účet úložiště ADLS Gen2. Musíte být přispěvatelem dat objektů blob úložiště systému souborů ADLS Gen2, se kterým chcete pracovat. Pokud ne, musíte oprávnění přidat ručně.
- Pokud nechcete používat výchozí úložiště pracovního prostoru, propojte požadovaný účet úložiště ADLS Gen2 ve službě Synapse Studio.
Vytvoření definice úlohy Apache Spark pro PySpark (Python)
V této části vytvoříte definici úlohy Apache Spark pro PySpark (Python).
Otevřete Synapse Studio.
Pokud chcete stáhnout ukázkové soubory pro python.zip, rozbalte komprimovaný balíček a extrahujte wordcount.py a shakespeare.txt soubory.
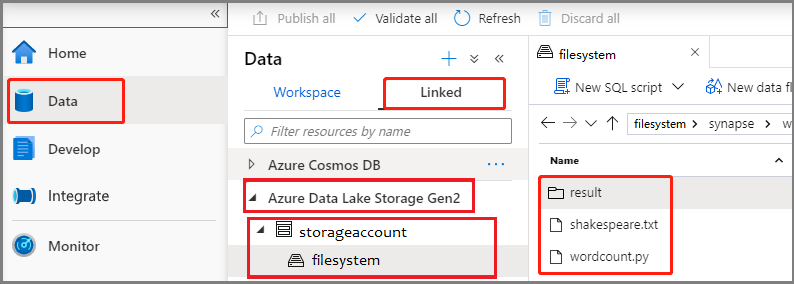
Vyberte Data -Linked ->>Azure Data Lake Storage Gen2 a nahrajte wordcount.py a shakespeare.txt do systému souborů ADLS Gen2.
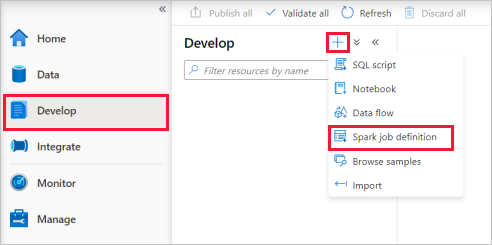
Vyberte Vyvíjet centrum, vyberte ikonu + a výběrem definice úlohy Spark vytvořte novou definici úlohy Sparku.
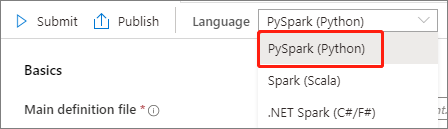
V rozevíracím seznamu Jazyk v hlavním okně definice úlohy Apache Spark vyberte PySpark (Python ).
Vyplňte informace pro definici úlohy Apache Sparku.
Vlastnost Popis Název definice úlohy Zadejte název definice úlohy Apache Sparku. Tento název lze kdykoli aktualizovat, dokud nebude publikován.
Ukázka:job definition sampleHlavní definiční soubor Hlavní soubor použitý pro úlohu. Vyberte soubor PY z úložiště. Pokud chcete soubor nahrát do účtu úložiště, vyberte Nahrát soubor .
Ukázka:abfss://…/path/to/wordcount.pyArgumenty příkazového řádku Volitelné argumenty pro úlohu.
Ukázka:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Poznámka: Dva argumenty pro definici ukázkové úlohy jsou oddělené mezerou.Referenční soubory Další soubory používané pro referenci v hlavním definičním souboru. Pokud chcete soubor nahrát do účtu úložiště, vyberte Nahrát soubor . Fond Sparku Úloha se odešle do vybraného fondu Apache Spark. Verze Sparku Verze Apache Sparku, na které běží fond Apache Sparku Exekutory Početexech Velikost exekutoru Počet jaderachch Velikost ovladače Počet jaderachch Konfigurace Apache Sparku Přizpůsobte konfigurace přidáním vlastností níže. Pokud nepřidáte vlastnost, Azure Synapse použije výchozí hodnotu, pokud je k dispozici. 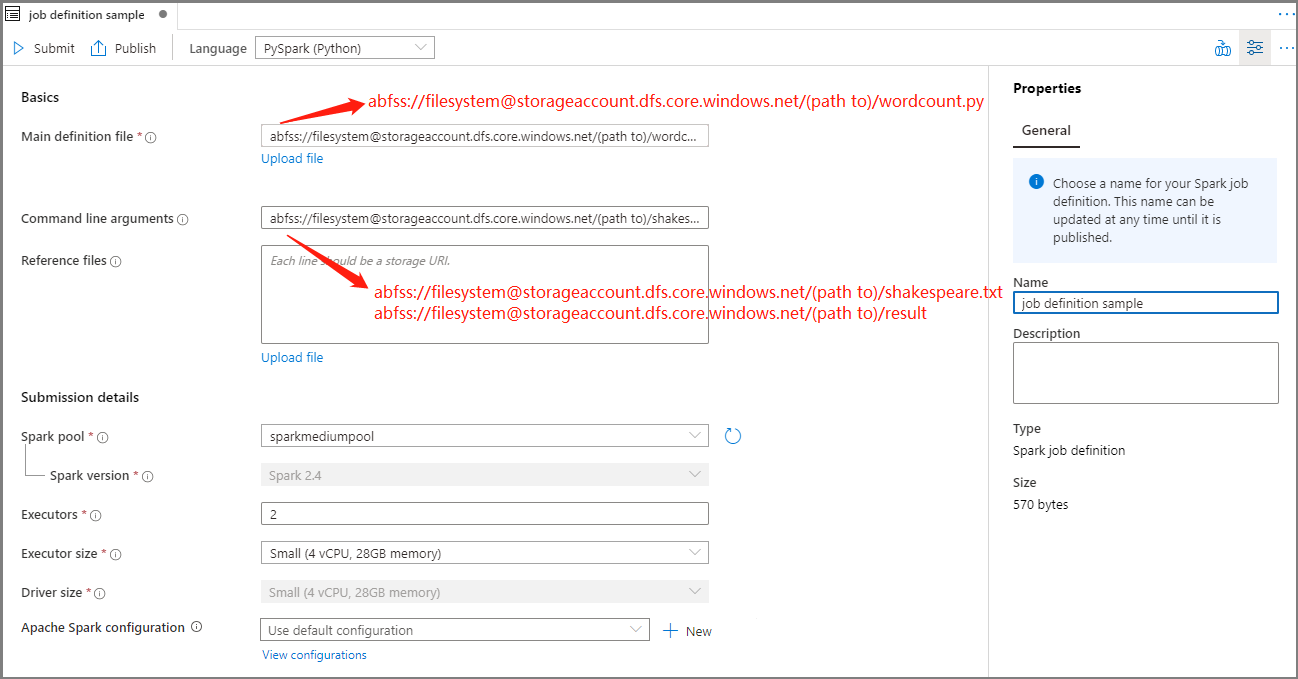
Výběrem možnosti Publikovat uložte definici úlohy Apache Sparku.

Vytvoření definice úlohy Apache Spark pro Apache Spark (Scala)
V této části vytvoříte definici úlohy Apache Spark pro Apache Spark (Scala).
Otevřete Azure Synapse Studio.
Pokud chcete stáhnout ukázkové soubory pro scala.zip, můžete přejít do ukázkových souborů pro vytváření definic úloh Apache Sparku, rozbalit komprimovaný balíček a extrahovat wordcount.jar a shakespeare.txt soubory.
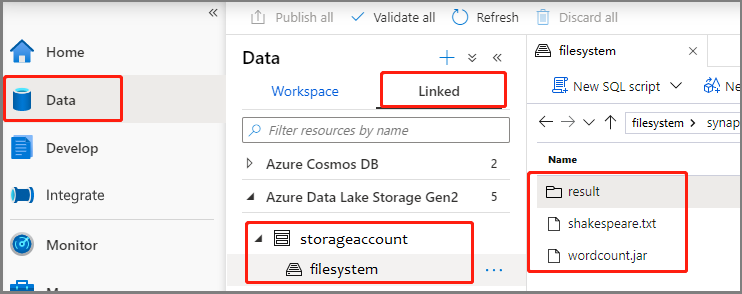
Vyberte Data -Linked ->>Azure Data Lake Storage Gen2 a nahrajte wordcount.jar a shakespeare.txt do systému souborů ADLS Gen2.
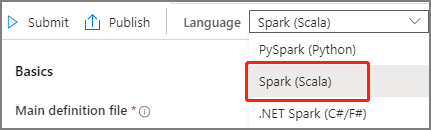
Vyberte Vyvíjet centrum, vyberte ikonu + a výběrem definice úlohy Spark vytvořte novou definici úlohy Sparku. (Ukázkový obrázek je stejný jako krok 4 z Vytvoření definice úlohy Apache Sparku (Python) pro PySpark.)
V hlavním okně definice úlohy Apache Spark vyberte Spark(Scala) z rozevíracího seznamu Jazyk.
Vyplňte informace pro definici úlohy Apache Sparku. Ukázkové informace můžete zkopírovat.
Vlastnost Popis Název definice úlohy Zadejte název definice úlohy Apache Sparku. Tento název lze kdykoli aktualizovat, dokud nebude publikován.
Ukázka:scalaHlavní definiční soubor Hlavní soubor použitý pro úlohu. Vyberte soubor JAR z úložiště. Pokud chcete soubor nahrát do účtu úložiště, vyberte Nahrát soubor .
Ukázka:abfss://…/path/to/wordcount.jarNázev hlavní třídy Plně kvalifikovaný identifikátor nebo hlavní třída, která je v hlavním definičním souboru.
Ukázka:WordCountArgumenty příkazového řádku Volitelné argumenty pro úlohu.
Ukázka:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Poznámka: Dva argumenty pro definici ukázkové úlohy jsou oddělené mezerou.Referenční soubory Další soubory používané pro referenci v hlavním definičním souboru. Pokud chcete soubor nahrát do účtu úložiště, vyberte Nahrát soubor . Fond Sparku Úloha se odešle do vybraného fondu Apache Spark. Verze Sparku Verze Apache Sparku, na které běží fond Apache Sparku Exekutory Početexech Velikost exekutoru Počet jaderachch Velikost ovladače Počet jaderachch Konfigurace Apache Sparku Přizpůsobte konfigurace přidáním vlastností níže. Pokud nepřidáte vlastnost, Azure Synapse použije výchozí hodnotu, pokud je k dispozici. 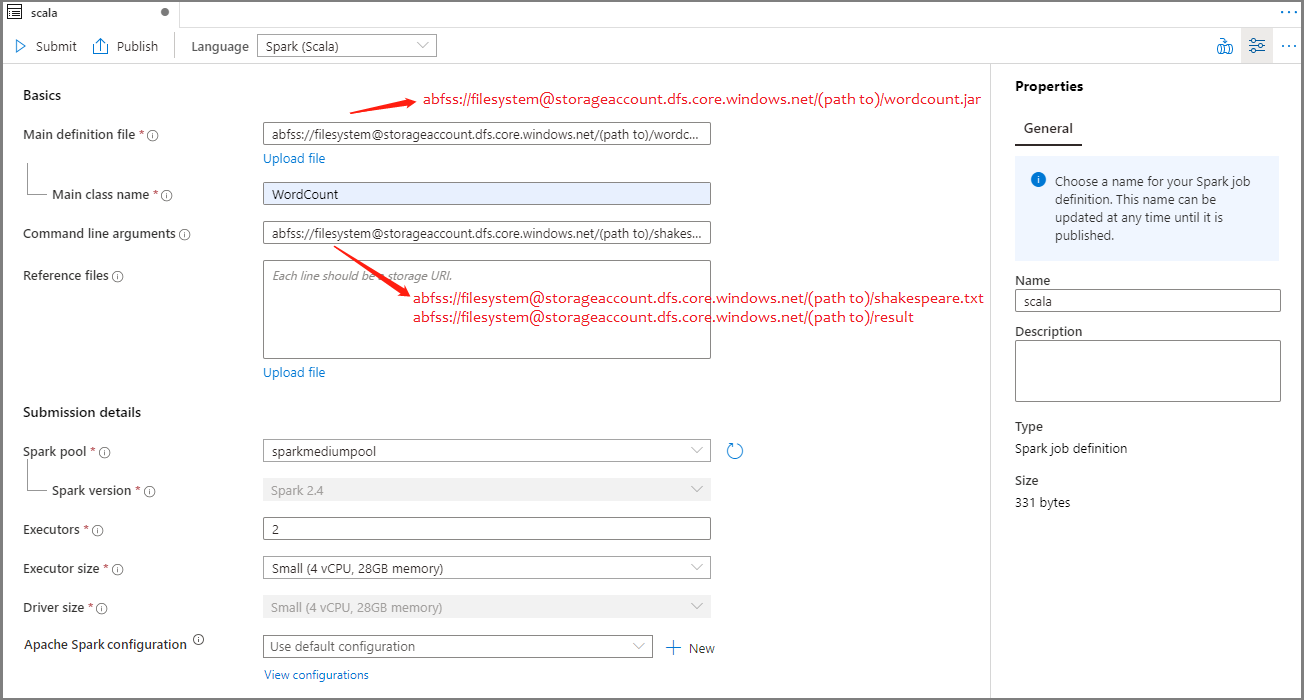
Výběrem možnosti Publikovat uložte definici úlohy Apache Sparku.

Vytvoření definice úlohy Apache Spark pro .NET Spark(C#/F#)
V této části vytvoříte definici úlohy Apache Spark pro .NET Spark(C#/F#).
Otevřete Azure Synapse Studio.
Pokud chcete stáhnout ukázkové soubory pro dotnet.zip, rozbalte komprimovaný balíček a extrahujte wordcount.zip a shakespeare.txt soubory.
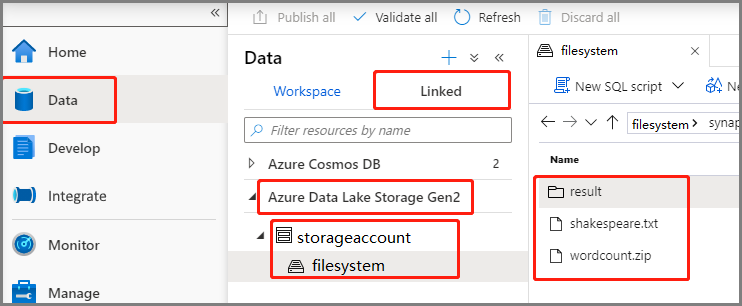
Vyberte Data -Linked ->>Azure Data Lake Storage Gen2 a nahrajte wordcount.zip a shakespeare.txt do systému souborů ADLS Gen2.
Vyberte Vyvíjet centrum, vyberte ikonu + a výběrem definice úlohy Spark vytvořte novou definici úlohy Sparku. (Ukázkový obrázek je stejný jako krok 4 z Vytvoření definice úlohy Apache Sparku (Python) pro PySpark.)
V rozevíracím seznamu Jazyk v hlavním okně Definice úlohy Apache Spark vyberte .NET Spark (C#/F# ).
Vyplňte informace pro definici úlohy Apache Spark. Ukázkové informace můžete zkopírovat.
Vlastnost Popis Název definice úlohy Zadejte název definice úlohy Apache Sparku. Tento název lze kdykoli aktualizovat, dokud nebude publikován.
Ukázka:dotnetHlavní definiční soubor Hlavní soubor použitý pro úlohu. Vyberte soubor ZIP, který obsahuje vaši aplikaci .NET pro Apache Spark (tj. hlavní spustitelný soubor, knihovny DLL obsahující uživatelem definované funkce a další požadované soubory) z vašeho úložiště. Pokud chcete soubor nahrát do účtu úložiště, vyberte Nahrát soubor .
Ukázka:abfss://…/path/to/wordcount.zipHlavní spustitelný soubor Hlavní spustitelný soubor v hlavním definičním souboru ZIP.
Ukázka:WordCountArgumenty příkazového řádku Volitelné argumenty pro úlohu.
Ukázka:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Poznámka: Dva argumenty pro definici ukázkové úlohy jsou oddělené mezerou.Referenční soubory Další soubory potřebné pracovními uzly pro spuštění aplikace .NET pro Apache Spark, která není součástí souboru ZIP hlavní definice (tj. závislé soubory JAR, další knihovny DLL funkcí definované uživatelem a další konfigurační soubory). Pokud chcete soubor nahrát do účtu úložiště, vyberte Nahrát soubor . Fond Sparku Úloha se odešle do vybraného fondu Apache Spark. Verze Sparku Verze Apache Sparku, na které běží fond Apache Sparku Exekutory Početexech Velikost exekutoru Počet jaderachch Velikost ovladače Počet jaderachch Konfigurace Apache Sparku Přizpůsobte konfigurace přidáním vlastností níže. Pokud nepřidáte vlastnost, Azure Synapse použije výchozí hodnotu, pokud je k dispozici. 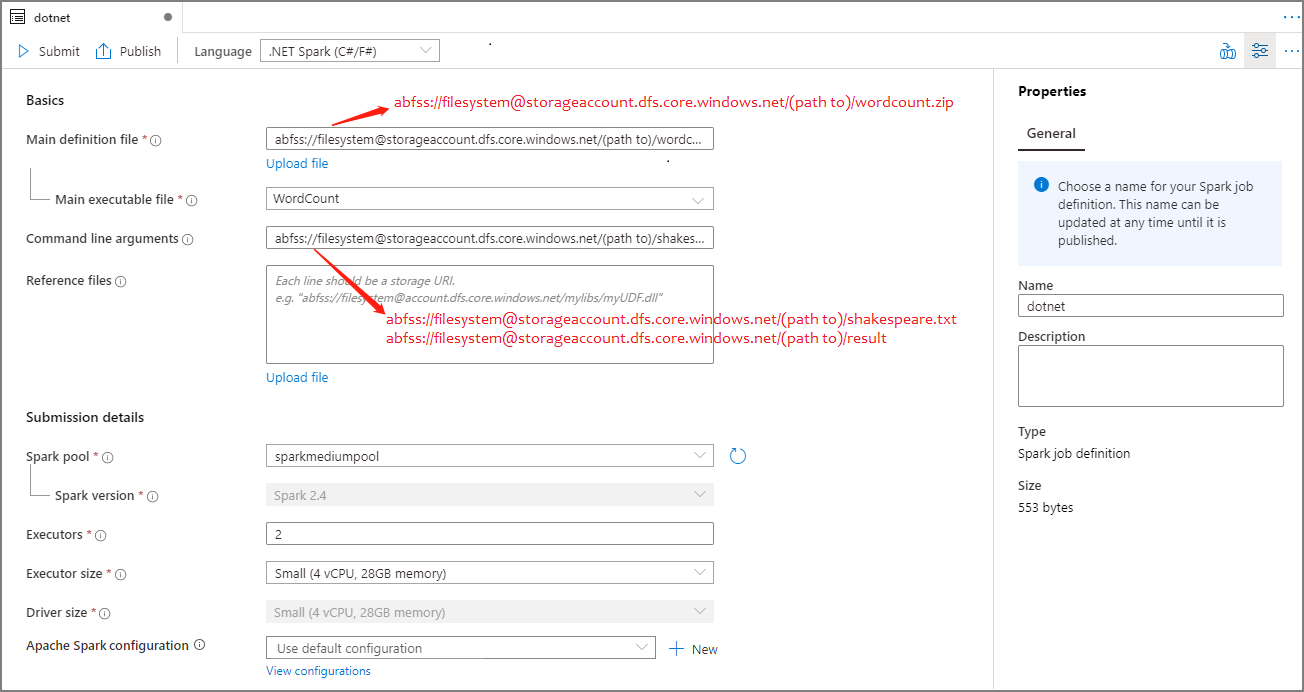
Výběrem možnosti Publikovat uložte definici úlohy Apache Sparku.

Poznámka:
Pokud pro konfiguraci Apache Sparku konfigurace Apache Sparku definice úlohy Apache Sparku nedělá nic zvláštního, použije se při spuštění úlohy výchozí konfigurace.
Vytvoření definice úlohy Apache Sparku importem souboru JSON
Existující místní soubor JSON můžete importovat do pracovního prostoru Azure Synapse z nabídky Actions (...) v Průzkumníku definic úloh Apache Spark a vytvořit novou definici úlohy Apache Spark.
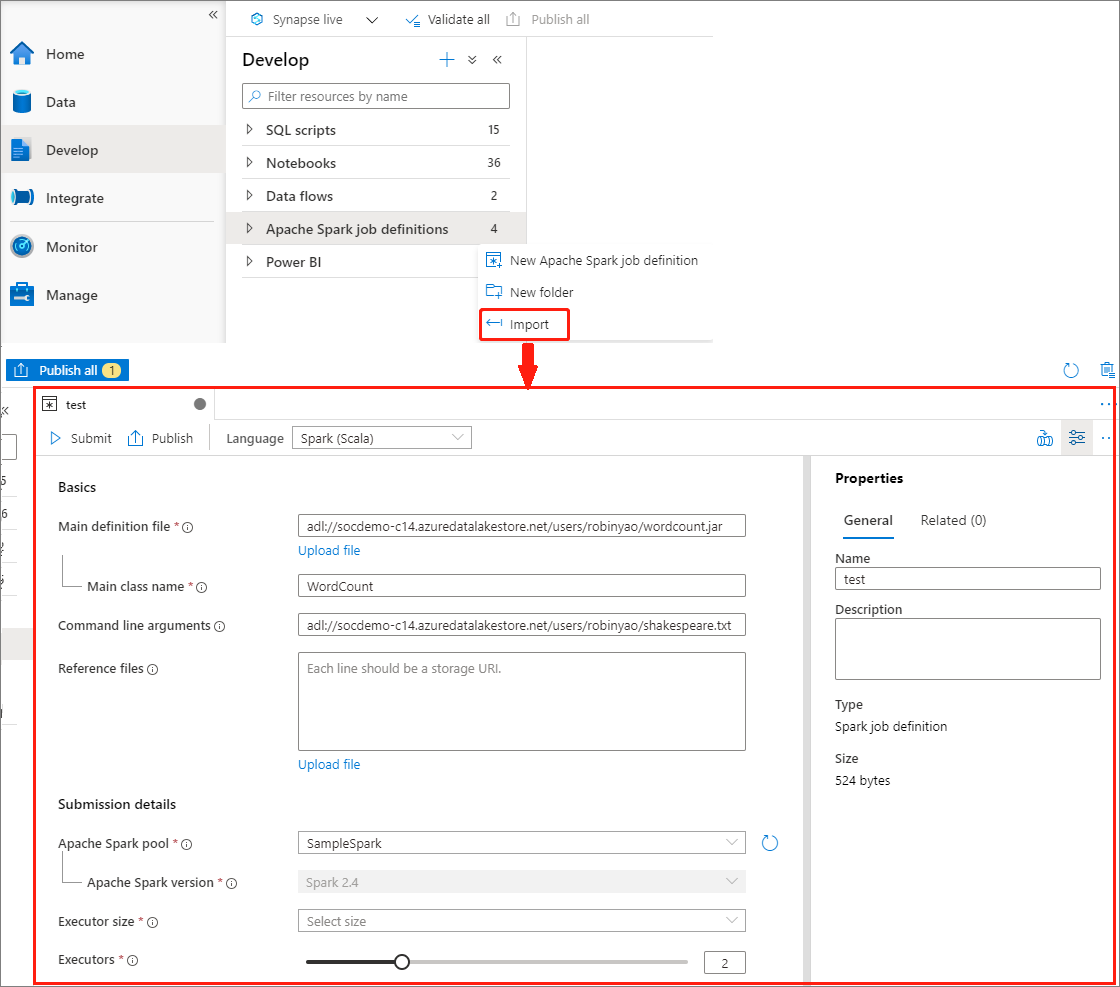
Definice úlohy Spark je plně kompatibilní s rozhraním Livy API. Do místního souboru JSON můžete přidat další parametry pro další vlastnosti Livy (Livy Docs – REST API (apache.org). V konfigurační vlastnosti můžete také zadat parametry související s konfigurací Sparku, jak je znázorněno níže. Potom můžete importovat soubor JSON zpět a vytvořit novou definici úlohy Apache Spark pro vaši dávkovou úlohu. Příklad JSON pro import definice Sparku:
{
"targetBigDataPool": {
"referenceName": "socdemolarge",
"type": "BigDataPoolReference"
},
"requiredSparkVersion": "2.3",
"language": "scala",
"jobProperties": {
"name": "robinSparkDefinitiontest",
"file": "adl://socdemo-c14.azuredatalakestore.net/users/robinyao/wordcount.jar",
"className": "WordCount",
"args": [
"adl://socdemo-c14.azuredatalakestore.net/users/robinyao/shakespeare.txt"
],
"jars": [],
"files": [],
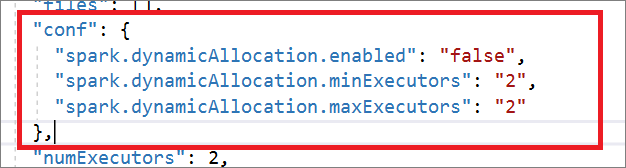
"conf": {
"spark.dynamicAllocation.enabled": "false",
"spark.dynamicAllocation.minExecutors": "2",
"spark.dynamicAllocation.maxExecutors": "2"
},
"numExecutors": 2,
"executorCores": 8,
"executorMemory": "24g",
"driverCores": 8,
"driverMemory": "24g"
}
}
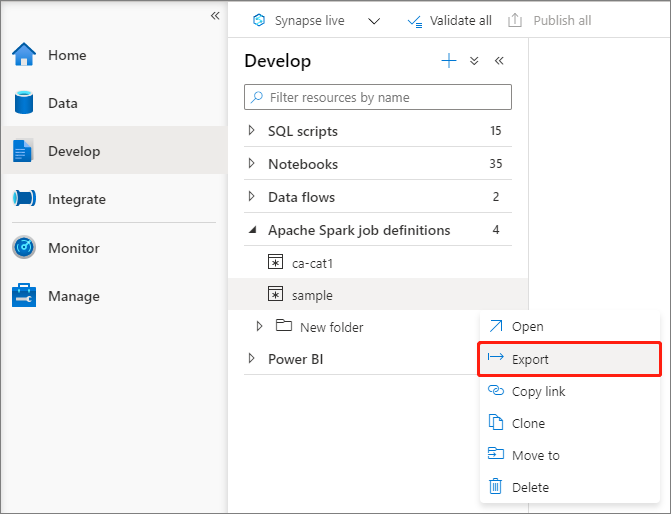
Export existujícího definičního souboru úlohy Apache Sparku
Existující definiční soubory úloh Apache Sparku můžete exportovat do místní nabídky Actions (...) Průzkumník souborů. Soubor JSON můžete dále aktualizovat pro další vlastnosti Livy a v případě potřeby ho importovat zpět a vytvořit novou definici úlohy.
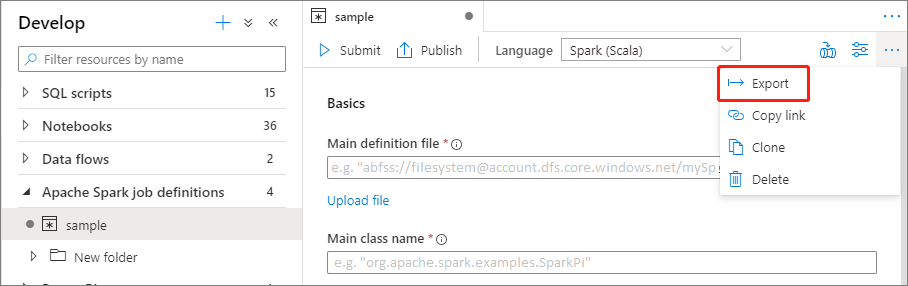
Odeslání definice úlohy Apache Sparku jako dávkové úlohy
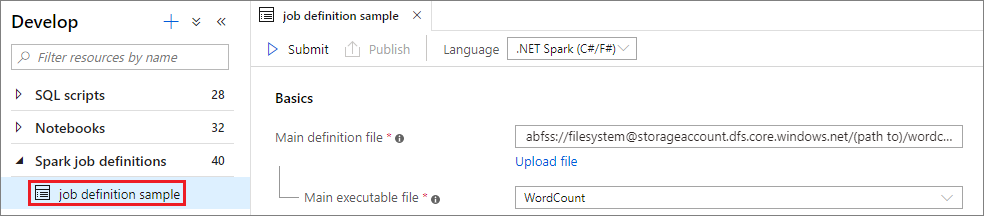
Po vytvoření definice úlohy Apache Sparku ji můžete odeslat do fondu Apache Spark. Ujistěte se, že jste přispěvatelem dat objektů blob úložiště systému souborů ADLS Gen2, se kterým chcete pracovat. Pokud ne, musíte oprávnění přidat ručně.
Scénář 1: Odeslání definice úlohy Apache Spark
Výběrem okna definice úlohy Apache Spark otevřete okno definice úlohy Apache Spark.
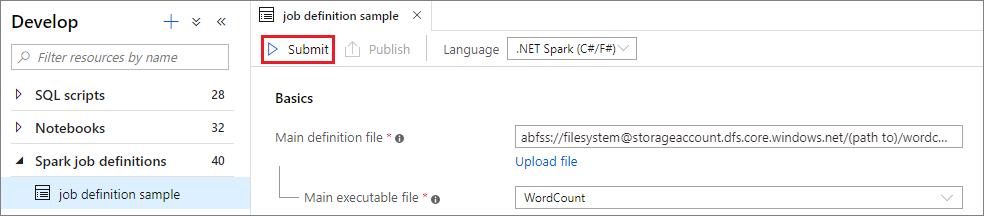
Výběrem tlačítka Odeslat odešlete projekt do vybraného fondu Apache Spark. Pokud chcete zobrazit LogQuery aplikace Apache Spark, můžete vybrat kartu adresy URL monitorování Sparku.
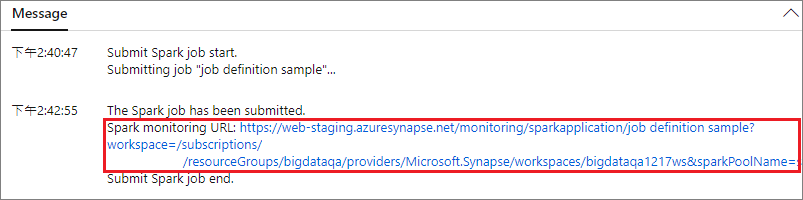
Scénář 2: Zobrazení průběhu spuštěné úlohy Apache Spark
Vyberte Možnost Sledovat a pak vyberte možnost Aplikace Apache Spark. Odeslanou aplikaci Apache Spark najdete.
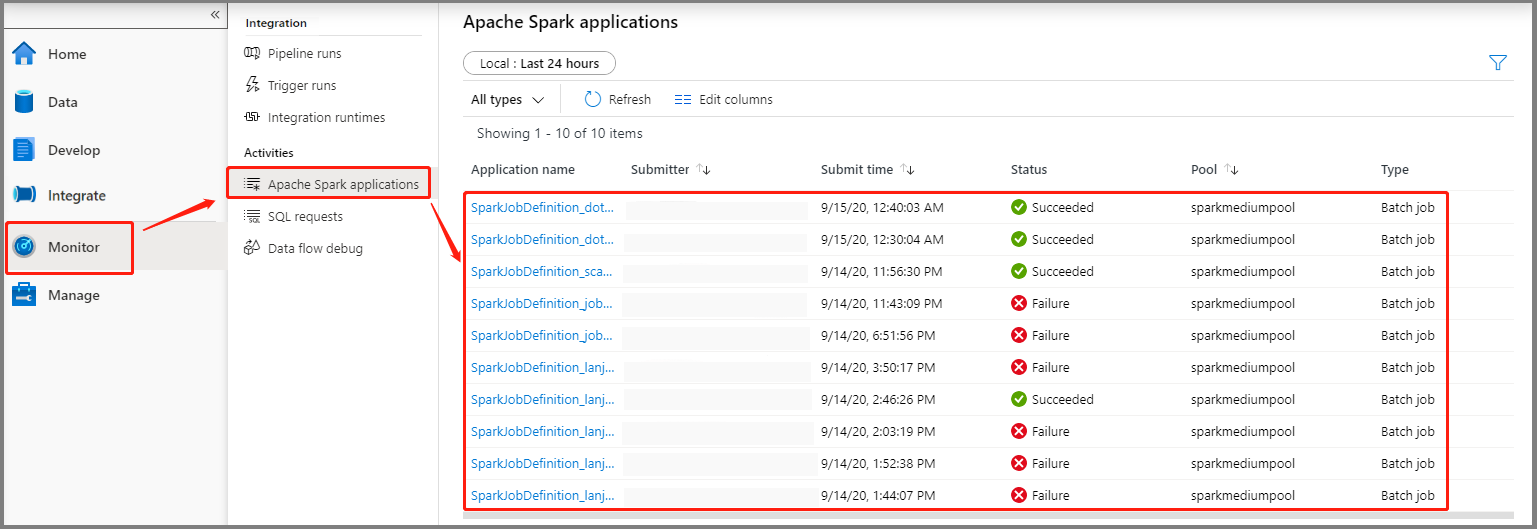
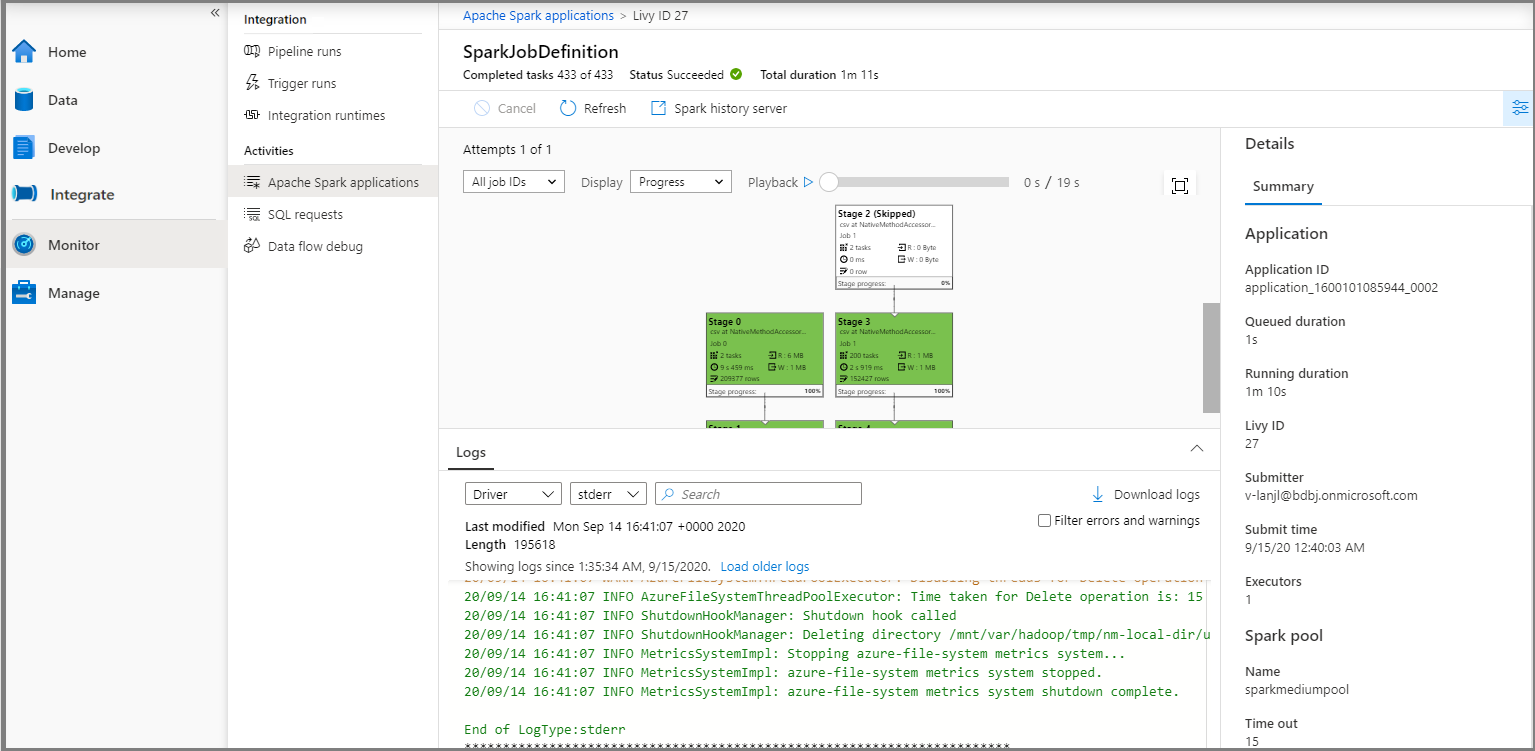
Pak vyberte aplikaci Apache Spark, zobrazí se okno úlohy SparkJobDefinition . Průběh provádění úlohy můžete zobrazit odsud.
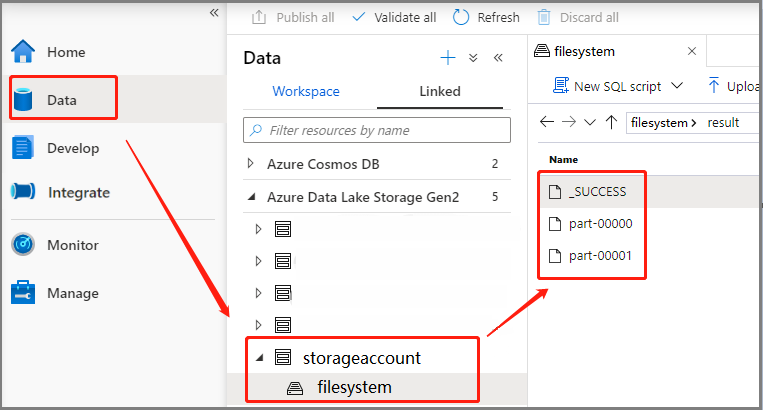
Scénář 3: Kontrola výstupního souboru
Vyberte Data -Linked ->>Azure Data Lake Storage Gen2 (hozhaobdbj), otevřete složku výsledků vytvořenou dříve, můžete přejít do složky výsledků a zkontrolovat, jestli se vygeneruje výstup.
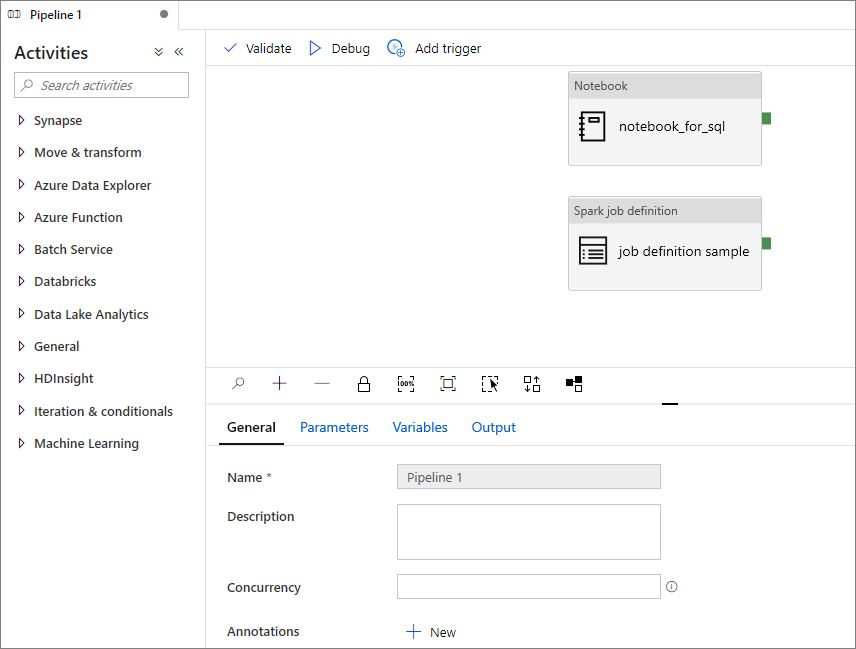
Přidání definice úlohy Apache Spark do kanálu
V této části přidáte do kanálu definici úlohy Apache Spark.
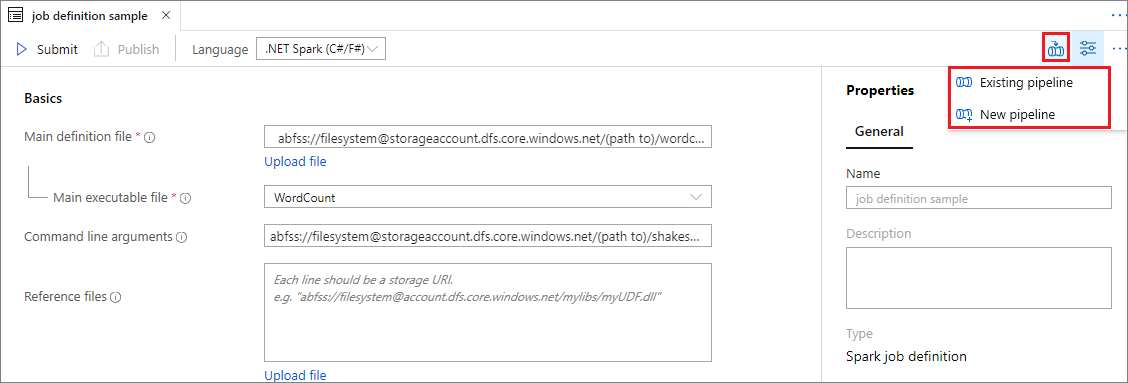
Otevřete existující definici úlohy Apache Spark.
Vyberte ikonu v pravém horním rohu definice úlohy Apache Sparku, zvolte Existující kanál nebo Nový kanál. Další informace najdete na stránce kanálu.
Další kroky
V dalším kroku můžete pomocí nástroje Azure Synapse Studio vytvářet datové sady Power BI a spravovat data Power BI. Další informace najdete v článku Propojení pracovního prostoru Power BI s pracovním prostorem Synapse.