Optimalizace úloh Apache Sparku ve službě Azure Synapse Analytics
Zjistěte, jak optimalizovat konfiguraci clusteru Apache Spark pro konkrétní úlohu. Nejběžnější výzvou je zatížení paměti kvůli nesprávným konfiguracím (zejména kvůli nesprávně nastavené velikosti exekutorů), dlouhotrvajícím operacím a úlohám, které vedou ke kartézským operacím. Úlohy můžete urychlit s odpovídající ukládáním do mezipaměti a povolit nerovnoměrnou distribuci dat. Pokud chcete dosáhnout nejlepšího výkonu, monitorujte a zkontrolujte dlouhotrvající spouštění úloh Sparku a jejich využití prostředků.
Následující části popisují běžné optimalizace úloh Sparku a doporučení.
Volba abstrakce dat
Starší verze Sparku používají sady RDD k abstrakci dat, Spark 1.3 a 1.6 zavedly datové rámce a datové sady v uvedeném pořadí. Zvažte následující relativní výhody:
- Datové rámce
- Nejlepší volba ve většině situací.
- Poskytuje optimalizaci dotazů prostřednictvím nástroje Catalyst.
- Kdo generování kódu fáze.
- Přímý přístup k paměti.
- Nízké režijní náklady na uvolňování paměti (GC).
- Ne tak přívětivé pro vývojáře jako datové sady, protože neexistují žádné kontroly kompilace ani programování objektů domény.
- Soubory
- Dobré ve složitých kanálech ETL, kde je přijatelný dopad na výkon.
- Není dobré v agregacích, kde může být dopad na výkon značný.
- Poskytuje optimalizaci dotazů prostřednictvím nástroje Catalyst.
- Vhodné pro vývojáře tím, že poskytuje programování objektů domény a kontroly času kompilace.
- Přidá režii serializace/deserializace.
- Vysoké režijní náklady na GC.
- Přeruší generování kódu celé fáze.
- Sady RDD
- Sady RDD nemusíte používat, pokud nepotřebujete vytvořit novou vlastní sadu RDD.
- Optimalizace dotazů prostřednictvím nástroje Catalyst.
- Generování kódu celé fáze.
- Vysoké režijní náklady na GC.
- Musí používat starší rozhraní API Sparku 1.x.
Použití optimálního formátu dat
Spark podporuje mnoho formátů, jako jsou csv, json, xml, parquet nebo avro. Spark je možné rozšířit tak, aby podporoval mnoho dalších formátů s externími zdroji dat – další informace najdete v balíčcích Apache Spark.
Nejlepším formátem pro výkon je parquet s kompresí snappy, což je výchozí hodnota ve Sparku 2.x. Parquet ukládá data ve sloupcových formátech a je vysoce optimalizovaná ve Sparku. Komprese přichycení navíc může mít za následek větší soubory, než například komprese gzip. Vzhledem k rozdělené povaze těchto souborů se dekomprimují rychleji.
Použití mezipaměti
Spark poskytuje své vlastní nativní mechanismy ukládání do mezipaměti, které lze použít různými metodami, jako .persist()je , .cache()a CACHE TABLE. Toto nativní ukládání do mezipaměti je efektivní u malých datových sad a také v kanálech ETL, kde potřebujete ukládat mezilehlé výsledky. Nativní ukládání do mezipaměti Sparku v současné době s dělením nefunguje dobře, protože tabulka s mezipamětí neuchovává data dělení.
Efektivní využití paměti
Spark funguje tak, že umísťuje data do paměti, takže správa prostředků paměti je klíčovým aspektem optimalizace provádění úloh Sparku. Existuje několik technik, které můžete použít k efektivnímu využití paměti clusteru.
Upřednostňujte menší datové oddíly a upřednostňujte velikost dat, typy a distribuci ve vaší strategii dělení.
Ve službě Synapse Spark (runtime 3.1 nebo vyšší) je serializace dat Kryo ve výchozím nastavení povolená serializace dat Kryo.
Velikost vyrovnávací paměti kryoserializátoru můžete přizpůsobit pomocí konfigurace Sparku na základě vašich požadavků na úlohy:
// Set the desired property spark.conf.set("spark.kryoserializer.buffer.max", "256m")Monitorování a ladění nastavení konfigurace Sparku
Pro vaši referenci se na následujícím obrázku zobrazí struktura paměti Sparku a některé parametry paměti exekutoru klíčů.
Aspekty paměti Sparku
Apache Spark v Azure Synapse používá YARN Apache Hadoop YARN, YARN řídí maximální součet paměti používané všemi kontejnery na každém uzlu Sparku. Následující diagram znázorňuje klíčové objekty a jejich vztahy.
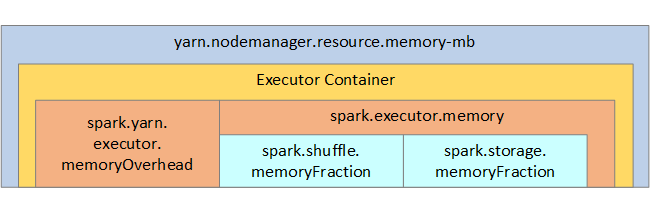
Pokud chcete vyřešit zprávy typu nedostatek paměti, zkuste:
- Projděte si shuffles správy DAG. Zmenšete omezením zdrojových dat na straně mapy, před oddílem (nebo rozdělením do kontejnerů), maximalizujte jednoduché náhodné prohazování a snižte množství odesílaných dat.
- Preferujte
ReduceByKeys pevným limitem paměti ,GroupByKeykterý poskytuje agregace, okna a další funkce, ale má omezení nevázané paměti. - Preferujte
TreeReduce, což dělá více práce na exekutorech nebo oddílech, do , kteréReducevšechny pracují na ovladači. - Využijte datové rámce místo objektů RDD nižší úrovně.
- Vytvořte komplexní typy, které zapouzdřují akce, jako je například "Horní N", různé agregace nebo operace vytváření oken.
Optimalizace serializace dat
Úlohy Sparku se distribuují, proto je pro zajištění nejlepšího výkonu důležitá odpovídající serializace dat. Spark nabízí dvě možnosti serializace:
- Serializace Java je výchozí.
- Serializace Kryo je novější formát a může vést k rychlejší a kompaktnější serializaci než Java. Kryo vyžaduje, abyste zaregistrovali třídy ve svém programu a zatím nepodporuje všechny serializovatelné typy.
Použití rozdělování do kbelíků
Dělení dat se podobá dělení dat, ale každý kbelík může obsahovat sadu hodnot sloupců, nikoli jenom jednu. Kontejnery dobře fungují pro dělení na velké (v milionech nebo více) číslech hodnot, jako jsou identifikátory produktů. Kontejner je určen hodnotou hash klíče kontejneru řádku. Kontejnerové tabulky nabízejí jedinečné optimalizace, protože ukládají metadata o tom, jak byly uspořádané a seřazené.
Mezi pokročilé funkce dělení na kontejnery patří:
- Optimalizace dotazů na základě metainformací o kontejnerech
- Optimalizované agregace.
- Optimalizovaná spojení.
Můžete použít dělení a dělení najednou.
Optimalizace spojení a náhodného prohazování metodou shuffle
Pokud máte pomalé úlohy ve spojení nebo náhodném prohazování, příčinou je pravděpodobně nerovnoměrná distribuce dat, což je asymetrie v datech vaší úlohy. Například úloha mapování může trvat 20 sekund, ale spuštění úlohy, ve které jsou data připojena nebo prohazována, trvá hodiny. Pokud chcete opravit nerovnoměrnou distribuci dat, měli byste celý klíč zasolit nebo použít izolovanou sůl pouze pro určitou podmnožinu klíčů. Pokud používáte izolovanou sůl, měli byste dále filtrovat a izolovat podmnožinu slaných klíčů ve spojeních s mapami. Další možností je nejprve zavést sloupec kbelíku a předem agregovat v kontejnerech.
Dalším faktorem, který způsobuje pomalé spojení, může být typ spojení. Spark ve výchozím nastavení používá SortMerge typ spojení. Tento typ spojení je nejvhodnější pro velké datové sady, ale je jinak výpočetně nákladný, protože musí před sloučením nejprve seřadit levé a pravé strany dat.
Spojení Broadcast je nejvhodnější pro menší datové sady nebo je-li jedna strana spojení mnohem menší než druhá. Tento typ spojení vysílá jednu stranu všem exekutorům, a proto vyžaduje více paměti pro všesměrové vysílání obecně.
Typ spojení v konfiguraci můžete změnit nastavením spark.sql.autoBroadcastJoinThresholdnebo můžete nastavit nápovědu pro spojení pomocí rozhraní API datového rámce (dataframe.join(broadcast(df2))).
// Option 1
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 1*1024*1024*1024)
// Option 2
val df1 = spark.table("FactTableA")
val df2 = spark.table("dimMP")
df1.join(broadcast(df2), Seq("PK")).
createOrReplaceTempView("V_JOIN")
sql("SELECT col1, col2 FROM V_JOIN")
Pokud používáte kontejnerové tabulky, máte třetí typ spojení, spojení Merge . Správně předem rozdělená a předem seřazená datová sada přeskočí náročnou SortMerge fázi řazení z spojení.
Pořadí spojení je důležité, zejména v složitějších dotazech. Začněte s nejvýraznějšími spojeními. Pokud je to možné, přesuňte také spojení, která zvyšují počet řádků za agregacemi.
Pokud chcete spravovat paralelismus pro kartézské spojení, můžete přidat vnořené struktury, okna a možná přeskočit jeden nebo více kroků v úloze Sparku.
Vyberte správnou velikost exekutoru.
Při rozhodování o konfiguraci exekutoru zvažte režii uvolňování paměti (GC) v Javě.
Faktory pro zmenšení velikosti exekutoru:
- Zmenšete velikost haldy o 32 GB, abyste udrželi režii < 10 %.
- Snižte počet jader, abyste udrželi režii < GC 10 %.
Faktory pro zvětšení velikosti exekutoru:
- Snižte komunikační režii mezi exekutory.
- Snižte počet otevřených připojení mezi exekutory (N2) ve větších clusterech (>100 exekutorů).
- Zvětšete velikost haldy tak, aby vyhovovala úkolům náročným na paměť.
- Volitelné: Snižte režii paměti exekutoru.
- Volitelné: Zvýšení využití a souběžnosti prostřednictvím přihlášení k odběru procesoru.
Obecně platí, že při výběru velikosti exekutoru:
- Začněte s 30 GB na exekutor a distribuujte dostupná jádra počítačů.
- Zvyšte počet jader exekutoru pro větší clustery (> 100 exekutorů).
- Upravte velikost na základě zkušebních spuštění i na předchozích faktorech, jako jsou režijní náklady na GC.
Při spouštění souběžných dotazů zvažte následující:
- Začněte 30 GB na exekutor a všechna jádra počítačů.
- Vytváření více paralelních aplikací Sparku prostřednictvím nadměrného odběru procesoru (přibližně 30% zlepšení latence)
- Distribuce dotazů napříč paralelními aplikacemi
- Upravte velikost na základě zkušebních spuštění i na předchozích faktorech, jako jsou režijní náklady na GC.
Sledujte výkon dotazů pro odlehlé hodnoty nebo jiné problémy s výkonem, a to tak, že se podíváte na zobrazení časové osy, graf SQL, statistiky úloh atd. Někdy je jeden nebo několik exekutorů pomalejší než ostatní a provádění úkolů trvá mnohem déle. K tomu často dochází u větších clusterů (> 30 uzlů). V tomto případě rozdělte práci na větší počet úkolů, aby plánovač mohl kompenzovat pomalé úkoly.
Například mít alespoň dvakrát tolik úkolů jako počet jader exekutoru v aplikaci. Můžete také povolit spekulativní provádění úkolů pomocí conf: spark.speculation = true.
Optimalizace spouštění úloh
- Mezipaměť podle potřeby, například pokud data použijete dvakrát, pak je uložíte do mezipaměti.
- Všesměrové proměnné všem exekutorům. Proměnné jsou serializovány pouze jednou, což vede k rychlejšímu vyhledávání.
- Použijte fond vláken na ovladači, což vede k rychlejšímu provozu pro mnoho úloh.
Klíčem k výkonu dotazů Sparku 2.x je modul Tungsten, který závisí na generování kódu celé fáze. V některých případech může být generování kódu celé fáze zakázáno.
Pokud například použijete nesměnitelný typ (string) ve výrazu agregace, SortAggregate zobrazí se místo HashAggregate. Pokud chcete například dosáhnout lepšího výkonu, zkuste následující kód a znovu povolte generování kódu:
MAX(AMOUNT) -> MAX(cast(AMOUNT as DOUBLE))
Další kroky
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro