Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento článek obsahuje doporučení pro návrh tabulek distribuovaných pomocí hodnot hash a tabulek distribuovaných kruhovým způsobem ve fondech vyhrazených pro SQL.
Tento článek předpokládá, že znáte koncepty distribuce dat a přesunu dat ve vyhrazeném fondu SQL. Další informace najdete v tématu Architektura služby Azure Synapse Analytics.
Co je distribuovaná tabulka?
Distribuovaná tabulka se zobrazí jako jedna tabulka, ale řádky se ve skutečnosti ukládají napříč 60 distribucemi. Řádky se distribuují pomocí algoritmu hash nebo algoritmu round-robin.
Hashová distribuce zlepšuje výkon dotazů u velkých tabulek faktů a je hlavním tématem tohoto článku. Kruhová distribuce je užitečná pro zlepšení rychlosti načítání. Tyto volby návrhu mají významný vliv na zlepšení výkonu dotazů a načítání.
Další možností úložiště tabulek je replikace malé tabulky napříč všemi výpočetními uzly. Další informace najdete v pokynech k návrhu replikovaných tabulek. Pokud si chcete rychle vybrat ze tří možností, podívejte se na distribuované tabulky v přehledu tabulek.
V rámci návrhu tabulky získáte co nejvíce informací o datech a způsobu dotazování dat. Představte si například tyto otázky:
- Jak velký je stůl?
- Jak často se tabulka aktualizuje?
- Mám tabulky faktů a dimenzí ve vyhrazeném fondu SQL?
Distribuovaná pomocí hash funkcí
Distribuovaná tabulka hash distribuuje řádky tabulky napříč výpočetními uzly pomocí deterministické hashovací funkce, která přiřadí každý řádek k jedné distribuci.
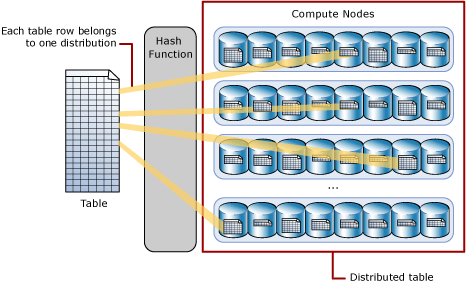
Vzhledem k tomu, že identické hodnoty jsou vždy hashovány do stejné distribuce, má SQL Analytics integrované znalosti o umístění řádků. Ve vyhrazeném fondu SQL se tyto znalosti používají k minimalizaci přesunu dat během dotazů, což zlepšuje výkon dotazů.
Distribuované tabulky hash fungují dobře pro velké tabulky faktů ve hvězdicovém schématu. Můžou mít velmi velký počet řádků a přesto dosáhnout vysokého výkonu. Existuje několik aspektů návrhu, které vám pomůžou získat výkon, který distribuovaný systém nabízí. Volba vhodného distribučního sloupce nebo sloupců je jedním z takových aspektů, které jsou popsány v tomto článku.
Zvažte použití tabulky distribuované podle hodnoty hash v následujících případech:
- Velikost tabulky na disku je větší než 2 GB.
- Tabulka obsahuje časté operace vložení, aktualizace a odstranění.
Kruhové dotazování distribuované
Distribuovaná tabulka cyklickou metodou distribuuje řádky rovnoměrně napříč všemi distribucemi. Přiřazení řádků k rozdělení je náhodné. Na rozdíl od tabulek distribuovaných pomocí hodnot hash není zaručeno, že se řádky se stejnými hodnotami přiřazují stejné distribuci.
V důsledku toho systém někdy potřebuje vyvolat operaci přesunu dat, aby lépe uspořádal vaše data, než dokáže vyřídit dotaz. Tento dodatečný krok může zpomalit vaše dotazy. Například spojení round-robin tabulky obvykle vyžaduje přemístění řádků, což představuje zásah do výkonu.
Zvažte použití round-robin distribuce pro vaši tabulku v následujících scénářích:
- Při zahájení práce zvolte jednoduchý výchozí bod, protože se jedná o přednastavenou možnost.
- Pokud neexistuje žádný zjevný spojovací klíč
- Pokud neexistuje žádný vhodný sloupec pro hash distribuci tabulky
- Pokud tabulka nesdílí společný spojovací klíč s jinými tabulkami
- Pokud je spojení v dotazu méně významné než jiná spojení
- Pokud je tabulka dočasnou přípravnou tabulkou
Kurz Načtení dat taxicab v New Yorku poskytuje příklad načtení dat do pracovní tabulky s kruhovým dotazem.
Volba distribučního sloupce
Tabulka s distribucí podle hash má distribuční sloupec nebo sadu sloupců, které tvoří klíč hash. Následující kód například vytvoří tabulku distribuovanou hodnotou hash s distribučním sloupcem ProductKey .
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([ProductKey])
);
Distribuci hodnot hash je možné použít u více sloupců pro rovnoměrnější distribuci základní tabulky. Distribuce s více sloupci umožňuje zvolit až osm sloupců pro distribuci. To nejen snižuje nerovnoměrnou distribuci dat v průběhu času, ale také zlepšuje výkon dotazů. Příklad:
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([ProductKey], [OrderDateKey], [CustomerKey] , [PromotionKey])
);
Poznámka:
Je možné povolit distribuci více sloupců ve službě Azure Synapse Analytics změnou úrovně kompatibility databáze na 50 pomocí tohoto příkazu.
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = 50; Další informace o nastavení úrovně kompatibility databáze naleznete v tématu ALTER DATABASE SCOPED CONFIGURATION. Další informace o rozdělení s více sloupci naleznete v dokumentaci k CREATE MATERIALIZED VIEW, CREATE TABLE nebo CREATE TABLE AS SELECT.
Data uložená v distribučních sloupcích je možné aktualizovat. Aktualizace dat v distribučních sloupcích mohou vést k operaci přesunu dat.
Volba distribučních sloupců je důležitým rozhodnutím návrhu, protože hodnoty ve sloupcích hash určují, jak se řádky distribuují. Nejlepší volba závisí na několika faktorech a obvykle zahrnuje kompromisy. Jakmile vyberete distribuční sloupec nebo sadu sloupců, nemůžete ho změnit. Pokud jste poprvé nevybrali nejlepší sloupce, můžete tabulku vytvořit znovu pomocí příkazu CREATE TABLE AS SELECT (CTAS) s požadovaným distribučním hashovým klíčem.
Volba distribučního sloupce s daty, která distribuují rovnoměrně
Pro zajištění nejlepšího výkonu by všechny distribuce měly mít přibližně stejný počet řádků. Pokud má jedna nebo více distribucí nepřiměřený počet řádků, některé distribuce dokončí svou část paralelního dotazu před ostatními. Vzhledem k tomu, že dotaz se nedá dokončit, dokud se nedokončí zpracování všech distribucí, je každý dotaz tak rychlý jako nejpomalejší distribuce.
- Nerovnoměrná distribuce dat znamená, že data nejsou rovnoměrně distribuována napříč distribucemi.
- Nerovnoměrná distribuce zpracování znamená, že některé distribuce při spouštění paralelních dotazů trvá déle než jiné. K tomu může dojít při nerovnoměrné distribuci dat.
Chcete-li vyrovnávat paralelní zpracování, vyberte distribuční sloupec nebo sadu sloupců, které:
- Má mnoho jedinečných hodnot. Jeden nebo více distribučních sloupců může mít duplicitní hodnoty. Všechny řádky se stejnou hodnotou jsou přiřazeny ke stejnému rozdělení. Vzhledem k tomu, že existuje 60 distribucí, mohou mít > některé distribuce 1 jedinečné hodnoty, zatímco jiné můžou končit nulovými hodnotami.
- Nemá NULLy, nebo má pouze několik NULLů. V případě extrémního příkladu platí, že pokud jsou všechny hodnoty v distribučních sloupcích NULL, přiřadí se všechny řádky ke stejnému rozdělení. V důsledku toho se zpracování dotazů zkosí na jednu distribuci a nemá prospěch z paralelního zpracování.
- Není sloupec s datem. Všechna data pro stejné datum budou umístěna ve stejné distribuci nebo budou záznamy seskupeny podle data. Pokud všichni uživatelé filtrují stejné datum (například dnešní datum), provede zpracování pouze 1 ze 60 distribucí.
Volba distribučního sloupce, který minimalizuje přesun dat
Chcete-li získat správné výsledky dotazu, může být data přesunuta z jednoho výpočetního uzlu do druhého. Přesun dat se často stává, když dotazy mají spojení a agregace v distribuovaných tabulkách. Volba distribučního sloupce nebo sady sloupců, která pomáhá minimalizovat přesun dat, je jednou z nejdůležitějších strategií pro optimalizaci výkonu vyhrazeného fondu SQL.
Pokud chcete minimalizovat přesun dat, vyberte distribuční sloupec nebo sadu sloupců, které:
- Používá se v klauzuli
JOIN,GROUP BY,DISTINCT,OVERaHAVING. Pokud dvě velké tabulky faktů mají časté spojení, výkon dotazů se zlepší, když distribuujete obě tabulky do jednoho ze sloupců spojení. Pokud se tabulka nepoužívá ve spojeních, zvažte distribuci tabulky ve sloupci nebo sadě sloupců, která je často vGROUP BYklauzuli. - V klauzulích se nepoužívá
WHERE. Pokud jsou klauzule dotazuWHEREa sloupce distribuce tabulky na stejném sloupci, dotaz může narazit na výraznou nerovnoměrnost v distribuci dat, což vede k tomu, že zatížení zpracování padá pouze na několik distribucí. To má vliv na výkon dotazů, ideálně mnoho distribucí sdílí zatížení zpracování. -
Není sloupec kalendářního data.
WHEREklauzule často filtrují podle data. Když k tomu dojde, veškeré zpracování může běžet pouze v několika distribucích, které ovlivňují výkon dotazů. V ideálním případě mnoho distribucí sdílí zatížení zpracování.
Jakmile navrhnete tabulku distribuovanou hodnotou hash, dalším krokem je načtení dat do tabulky. Pokyny k načítání najdete v tématu Přehled načítání.
Jak zjistit, jestli je vaše distribuce dobrou volbou
Po načtení dat do tabulky distribuované hodnotou hash zkontrolujte, jak rovnoměrně se řádky distribuují napříč 60 distribucemi. Řádky na jednu distribuci se můžou lišit až o 10 % bez znatelného dopadu na výkon.
Zvažte následující způsoby vyhodnocení distribučních sloupců.
Určení, jestli tabulka obsahuje nerovnoměrnou distribuci dat
Rychlý způsob, jak zkontrolovat nerovnoměrnou distribuci dat, je použít DBCC PDW_SHOWSPACEUSED. Následující kód SQL vrátí počet řádků tabulky, které jsou uloženy v každé z 60 distribucí. V případě vyváženého výkonu by měly být řádky v distribuované tabulce rovnoměrně rozloženy napříč všemi distribucemi.
-- Find data skew for a distributed table
DBCC PDW_SHOWSPACEUSED('dbo.FactInternetSales');
Identifikace tabulek, které mají více než 10% nerovnoměrnou distribuci dat:
- Vytvořte zobrazení
dbo.vTableSizes, které je zobrazeno v článku Přehled tabulek. - Spusťte tento dotaz:
select *
from dbo.vTableSizes
where two_part_name in
(
select two_part_name
from dbo.vTableSizes
where row_count > 0
group by two_part_name
having (max(row_count * 1.000) - min(row_count * 1.000))/max(row_count * 1.000) >= .10
)
order by two_part_name, row_count;
Kontrola plánů dotazů pro pohyb dat
Dobrá sada distribučních sloupců umožňuje spojení a agregace, aby měly minimální přesun dat. To má vliv na způsob zápisu spojů. Pokud chcete dosáhnout minimálního pohybu dat při spojování dvou tabulek s distribucí pomocí hash, musí být jeden ze sloupců spojení zahrnut do distribučního sloupce nebo sloupců. Pokud se dvě tabulky distribuované hodnotou hash spojí v distribučním sloupci stejného datového typu, spojení nevyžaduje přesun dat. Spojení můžou používat další sloupce bez nutnosti přesunu dat.
Abyste se vyhnuli přesunu dat během spojení:
- Tabulky, které jsou součástí spojení, musí být hash rozdělené podle jednoho ze sloupců zapojených do spojení.
- Datové typy sloupců spojení se musí shodovat mezi oběma tabulkami.
- Sloupce musí být spojené s operátorem rovnosti.
- Typ spojení nemůže být
CROSS JOIN.
Pokud chcete zjistit, jestli u dotazů dochází k přesunu dat, můžete se podívat na plán dotazu.
Řešení problému s distribučním sloupcem
Není nutné vyřešit všechny případy nerovnoměrné distribuce dat. Distribuce dat je otázkou nalezení správné rovnováhy mezi minimalizací nerovnoměrné distribuce dat a přesunem dat. Není vždy možné minimalizovat nerovnoměrnou distribuci dat i přesun dat. Někdy může být výhoda minimálního přesunu dat převažovaná nad vlivem nerovnoměrné distribuce dat.
Pokud se chcete rozhodnout, jestli byste měli vyřešit nerovnoměrnou distribuci dat v tabulce, měli byste porozumět co nejvíce objemům dat a dotazům ve vaší úloze. Pomocí kroků v článku Monitorování dotazů můžete sledovat účinek zkreslení na výkon dotazů. Konkrétně hledejte, jak dlouho trvá dokončení velkých dotazů v jednotlivých distribucích.
Vzhledem k tomu, že nemůžete změnit distribuční sloupce v existující tabulce, typickým způsobem, jak vyřešit nerovnoměrnou distribuci dat, je znovu vytvořit tabulku s různými distribučními sloupci.
Opětovné vytvoření tabulky s novou sadou distribučních sloupců
Tento příklad používá funkci CREATE TABLE AS SELECT k opětovnému vytvoření tabulky s různými sloupci distribuce hash.
Nejprve použijte CREATE TABLE AS SELECT novou tabulku (CTAS) s novým klíčem. Pak znovu vytvořte statistiku a nakonec prohoďte tabulky jejich přejmenováním.
CREATE TABLE [dbo].[FactInternetSales_CustomerKey]
WITH ( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([CustomerKey])
, PARTITION ( [OrderDateKey] RANGE RIGHT FOR VALUES ( 20000101, 20010101, 20020101, 20030101
, 20040101, 20050101, 20060101, 20070101
, 20080101, 20090101, 20100101, 20110101
, 20120101, 20130101, 20140101, 20150101
, 20160101, 20170101, 20180101, 20190101
, 20200101, 20210101, 20220101, 20230101
, 20240101, 20250101, 20260101, 20270101
, 20280101, 20290101
)
)
)
AS
SELECT *
FROM [dbo].[FactInternetSales]
OPTION (LABEL = 'CTAS : FactInternetSales_CustomerKey')
;
--Create statistics on new table
CREATE STATISTICS [ProductKey] ON [FactInternetSales_CustomerKey] ([ProductKey]);
CREATE STATISTICS [OrderDateKey] ON [FactInternetSales_CustomerKey] ([OrderDateKey]);
CREATE STATISTICS [CustomerKey] ON [FactInternetSales_CustomerKey] ([CustomerKey]);
CREATE STATISTICS [PromotionKey] ON [FactInternetSales_CustomerKey] ([PromotionKey]);
CREATE STATISTICS [SalesOrderNumber] ON [FactInternetSales_CustomerKey] ([SalesOrderNumber]);
CREATE STATISTICS [OrderQuantity] ON [FactInternetSales_CustomerKey] ([OrderQuantity]);
CREATE STATISTICS [UnitPrice] ON [FactInternetSales_CustomerKey] ([UnitPrice]);
CREATE STATISTICS [SalesAmount] ON [FactInternetSales_CustomerKey] ([SalesAmount]);
--Rename the tables
RENAME OBJECT [dbo].[FactInternetSales] TO [FactInternetSales_ProductKey];
RENAME OBJECT [dbo].[FactInternetSales_CustomerKey] TO [FactInternetSales];
Související obsah
Pokud chcete vytvořit distribuovanou tabulku, použijte jeden z těchto příkazů: