Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Ve vyhrazeném fondu SQL materializovaná zobrazení poskytují metodu nízké údržby složitých analytických dotazů, která zajistí rychlý výkon beze změny dotazu. Tento článek popisuje obecné pokyny k používání materializovaných zobrazení.
Materializovaná zobrazení vs. standardní zobrazení
Fond SQL podporuje standardní i materializovaná zobrazení. Obě jsou virtuální tabulky vytvořené pomocí výrazů SELECT a předávají se dotazům jako logické tabulky. Zobrazení odhalí složitost běžného výpočtu dat a do změn výpočtů přidá abstrakční vrstvu, takže nemusíte přepisovat dotazy.
Standardní zobrazení vypočítá data při každém použití zobrazení. Na disku nejsou uložená žádná data. Lidé obvykle používají standardní zobrazení jako nástroj, který pomáhá uspořádat logické objekty a dotazy v databázi. Pokud chcete použít standardní zobrazení, musí dotaz na něj přímo odkazovat.
Materializované zobrazení předpočítá, ukládá a udržuje svá data ve vyhrazeném fondu SQL stejně jako tabulka. Při každém použití materializovaného zobrazení není potřeba přepočítání. Proto dotazy, které používají všechna data nebo podmnožinu dat v materializovaných zobrazeních, můžou dosáhnout rychlejšího výkonu. Ještě lepší je, že dotazy můžou použít materializované zobrazení bez přímého odkazu na něj, takže není nutné měnit kód aplikace.
Většina standardních požadavků na zobrazení se stále vztahuje na materializované zobrazení. Podrobnosti o syntaxi materializovaného zobrazení a dalších požadavcích najdete v tématu CREATE MATERIALIZED VIEW AS SELECT.
| Porovnání | Zobrazit | Materializované zobrazení |
|---|---|---|
| Zobrazit definici | Uložené v datovém skladu Azure. | Uložené v datovém skladu Azure. |
| Zobrazení obsahu | Vygeneruje se při každém použití zobrazení. | Předzpracované a uložené v datovém skladu Azure během vytváření zobrazení. Aktualizováno při přidávání dat do podkladových tabulek. |
| Aktualizace dat | Vždy aktualizováno | Vždy aktualizováno |
| Rychlost načítání dat ze složitých dotazů | Pomalá | Rychlý |
| Extra úložiště | Ne | Ano |
| Syntaxe | VYTVOŘIT ZOBRAZENÍ | VYTVOŘENÍ MATERIALIZOVANÉHO ZOBRAZENÍ JAKO VÝBĚRU |
Výhody materializovaných zobrazení
Správně navržené materializované zobrazení poskytuje následující výhody:
Zkrátila se doba provádění složitých dotazů s JOIN a agregačními funkcemi. Čím složitější je dotaz, tím vyšší je potenciál pro úsporu času provádění. Největší výhodu získáte, když jsou náklady na výpočet dotazu vysoké a výsledná datová sada je malá.
Optimalizátor dotazů ve vyhrazeném fondu SQL může automaticky použít nasazená materializovaná zobrazení ke zlepšení plánů provádění dotazů. Tento proces je pro uživatele transparentní a poskytuje rychlejší výkon dotazů a nevyžaduje dotazy k přímému odkazování na materializovaná zobrazení.
Vyžaduje nízkou údržbu zobrazení. Materializované zobrazení ukládá data na dvou místech: clusterovaném columnstore indexu pro původní data při vytvoření zobrazení a v rozdílovém úložišti pro přírůstkové změny dat. Data ze základních tabulek se automaticky synchronně přidávají do delta úložiště. Proces na pozadí (tuple mover) pravidelně přesouvá data z delta úložiště do columnstore indexu pohledu. Tento návrh umožňuje dotazování materializovaných zobrazení vrátit stejná data jako přímé dotazování základních tabulek.
Data v materializovaném zobrazení je možné distribuovat odlišně od základních tabulek.
Data v materializovaných zobrazeních získávají stejné výhody vysoké dostupnosti a odolnosti jako data v běžných tabulkách.
Ve srovnání s jinými poskytovateli datového skladu poskytují materializovaná zobrazení implementovaná ve vyhrazeném fondu SQL také následující další výhody:
- Automatická a synchronní aktualizace dat se změnami dat v základních tabulkách Není nutná žádná akce uživatele.
- Podpora širokých agregačních funkcí Viz CREATE MATERIALIZED VIEW AS SELECT (Transact-SQL).
- Podpora doporučení materializovaného zobrazení specifického pro dotazy. Viz EXPLAIN (Transact-SQL).
Obvyklé scénáře
Materializovaná zobrazení se obvykle používají v následujících scénářích:
Potřeba zlepšit výkon složitých analytických dotazů s velkými objemy dat
Složité analytické dotazy obvykle používají více agregačních funkcí a spojení tabulek, což způsobuje více operací náročných na výpočetní výkon, jako jsou náhodné prohazování a spojení při provádění dotazů. Proto dokončení těchto dotazů trvá déle, zejména u velkých tabulek.
Uživatelé mohou vytvářet materializovaná zobrazení pro data vrácená z běžných výpočtů dotazů, takže když dotazy potřebují tato data, není nutné provádět žádné další výpočty, což umožňuje snížit náklady na výpočetní výkon a zrychlit odezvu dotazů.
Potřebujete rychlejší výkon beze změn dotazů nebo minimálních změn dotazů.
Změny schématu a dotazů v datových skladech jsou obvykle udržovány na minimální úrovni, aby podporovaly pravidelné provádění operací ETL a vytváření sestav. Lidé můžou použít materializovaná zobrazení pro ladění výkonu dotazů, pokud náklady vzniklé zobrazením můžou být posunuty zvýšením výkonu dotazů.
Ve srovnání s dalšími možnostmi ladění, jako je například škálování a správa statistik, je vytvoření a údržba materializovaného zobrazení mnohem méně zásadní změnou v provozu a jeho potenciální zlepšení výkonu je také vyšší.
- Vytváření nebo údržba materializovaných zobrazení nemá vliv na dotazy spuštěné na základní tabulky.
- Optimalizátor dotazů může automaticky používat nasazená materializovaná zobrazení bez přímého odkazu na zobrazení v dotazu. Tato funkce snižuje potřebu změny dotazů při ladění výkonu.
K zajištění rychlejšího výkonu dotazů potřebujete jinou strategii distribuce dat.
Datový sklad Azure je distribuovaný systém MPP (Massively Parallel Processing).
Synapse SQL je distribuovaný dotazovací systém, který podnikům umožňuje implementovat scénáře datových skladů a virtualizace dat pomocí standardních prostředí T-SQL známých datovým inženýrům. Rozšiřuje také možnosti SQL pro řešení scénářů streamování a strojového učení. Data v tabulce datového skladu se distribuují napříč 60 uzly pomocí jedné ze tří distribučních strategií (hash, round_robin nebo replikovaných).
Distribuce dat se zadává v době vytvoření tabulky a zůstane beze změny, dokud se tabulka nesmaže. Materializované zobrazení, které je virtuální tabulkou na disku, podporuje datové distribuce hash a round_robin. Uživatelé můžou zvolit distribuci dat, která se liší od základních tabulek, ale optimální pro výkon dotazů, které často používají zobrazení.
Pokyny pro návrh
Tady jsou obecné pokyny k použití materializovaných zobrazení ke zlepšení výkonu dotazů:
Návrh pro úlohu
Než začnete vytvářet materializovaná zobrazení, je důležité, abyste svoji úlohu podrobně pochopili z hlediska vzorů dotazů, důležitosti, frekvence a velikosti výsledných dat.
Uživatelé mohou spustit EXPLAIN WITH_RECOMMENDATIONS <SQL_statement> pro materializovaná zobrazení doporučená optimalizátorem dotazů. Vzhledem k tomu, že tato doporučení jsou specifická pro dotazy, materializované zobrazení, které má výhody jednoho dotazu, nemusí být optimální pro jiné dotazy ve stejné úloze.
Vyhodnoťte tato doporučení s ohledem na potřeby vašich úloh. Ideální materializovaná zobrazení jsou ta, která přispívají k výkonu úlohy.
Mějte na paměti kompromis mezi rychlejšími dotazy a náklady
U každého materializovaného zobrazení jsou náklady na úložiště dat a náklady na údržbu zobrazení. Při změnách dat v základních tabulkách se velikost materializovaného zobrazení zvyšuje a také se mění její fyzická struktura.
Aby nedocházelo ke zhoršení výkonu dotazů, udržuje každé materializované zobrazení stroj datového skladu samostatně, včetně přesunu řádků z delta úložiště do segmentů indexu columnstore a konsolidace změn dat.
Zatížení údržby se zvyšuje, když vzroste počet materializovaných zobrazení a změn základních tabulek. Uživatelé by měli zkontrolovat, jestli náklady vzniklé ze všech materializovaných zobrazení mohou být vyváženy zlepšením výkonu dotazu.
Tento dotaz můžete spustit pro seznam materializovaných zobrazení v databázi:
SELECT V.name as materialized_view, V.object_id
FROM sys.views V
JOIN sys.indexes I ON V.object_id= I.object_id AND I.index_id < 2;
Možnosti snížení počtu materializovaných zobrazení:
Identifikujte běžné datové sady, které často používají složité dotazy ve vaší úloze. Vytvořte materializovaná zobrazení pro ukládání těchto sad dat, aby je optimalizátor mohl použít jako stavební bloky při vytváření plánů provádění.
Odstraňte materializovaná zobrazení s nízkým využitím nebo ta, která už nejsou potřebná. Zakázané materializované zobrazení se neudržuje, ale stále se za něj účtují náklady na úložiště.
Zkombinujte materializovaná zobrazení vytvořená ve stejných nebo podobných základních tabulkách, i když se jejich data nepřekrývají. Kombinace materializovaných zobrazení může vést k větší velikosti zobrazení, než je součet samostatných zobrazení, ale náklady na údržbu zobrazení by se měly snížit. Například:
-- Query 1 would benefit from having a materialized view created with this SELECT statement
SELECT A, SUM(B)
FROM T
GROUP BY A
-- Query 2 would benefit from having a materialized view created with this SELECT statement
SELECT C, SUM(D)
FROM T
GROUP BY C
-- You could create a single materialized view of this form
SELECT A, C, SUM(B), SUM(D)
FROM T
GROUP BY A, C
Ne všechna ladění výkonu vyžadují změnu dotazu.
Optimalizátor datového skladu může automaticky použít nasazená materializovaná zobrazení ke zlepšení výkonu dotazů. Tato podpora se používá transparentně na dotazy, které neodkazují na zobrazení a na dotazy, které používají agregace nepodporované při vytváření materializovaných zobrazení. Není nutná žádná změna dotazu. Můžete zkontrolovat odhadovaný plán provádění dotazu a ověřit, jestli se používá materializované zobrazení.
- Další informace o získání skutečného plánu provádění najdete v tématu Monitorování úloh specifického fondu SQL služby Azure Synapse Analytics pomocí zobrazení dynamické správy.
- Odhadovaný plán provádění můžete načíst prostřednictvím aplikace SQL Server Management Studio (SSMS) nebo SHOWPLAN_XML SET.
Sledujte materializovaná zobrazení
Materializované zobrazení je uložené v datovém skladu stejně jako tabulka s clusterovaným indexem columnstore (CCI). Čtení dat z materializovaného zobrazení zahrnuje skenování indexu a použití změn z delta úložiště. Pokud je počet řádků v delta úložišti příliš vysoký, vyřešení dotazu z materializovaného pohledu může trvat déle než přímé dotazování základních tabulek.
Abyste se vyhnuli snížení výkonu dotazů, je vhodné spustit DBCC PDW_SHOWMATERIALIZEDVIEWOVERHEAD a monitorovat overhead_ratio zobrazení (total_rows / base_view_row). Pokud je overhead_ratio příliš vysoká, zvažte opětovné sestavení materializovaného zobrazení, aby se všechny řádky v rozdílovém úložišti přesunuly do indexu columnstore.
Ukládání do mezipaměti materializovaného zobrazení a sady výsledků
Tyto dvě funkce jsou zavedeny ve vyhrazeném fondu SQL přibližně ve stejnou dobu pro ladění výkonu dotazů. Ukládání do mezipaměti sady výsledků se používá k dosažení vysoké souběžnosti a rychlé doby odezvy z opakovaných dotazů na statická data.
Pokud chcete použít výsledek uložený v mezipaměti, musí se formulář dotazu žádajícího o mezipaměť shodovat s dotazem, který mezipaměť vytvořil. Kromě toho se výsledek uložený v mezipaměti musí vztahovat na celý dotaz.
Materializovaná zobrazení umožňují změny dat v základních tabulkách. Data v materializovaných zobrazeních je možné použít u části dotazu. Tato podpora umožňuje použití stejných materializovaných zobrazení různými dotazy, které sdílejí některé výpočty, aby se zrychlil výkon.
Příklad
Tento příklad používá dotaz podobný TPCDS, který najde zákazníky, kteří tráví více peněz prostřednictvím katalogu než v obchodech. Identifikuje také upřednostňované zákazníky a jejich zemi/oblast původu. Dotaz zahrnuje výběr prvních 100 záznamů ze union tří příkazů sub-SELECT zahrnujících SUM() a GROUP BY.
WITH year_total AS (
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ss_ext_list_price-ss_ext_wholesale_cost-ss_ext_discount_amt+ss_ext_sales_price, 0)/2) year_total
,'s' sale_type
FROM customer
,store_sales
,date_dim
WHERE c_customer_sk = ss_customer_sk
AND ss_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
UNION ALL
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(cs_ext_list_price-cs_ext_wholesale_cost-cs_ext_discount_amt+cs_ext_sales_price, 0)/2) year_total
,'c' sale_type
FROM customer
,catalog_sales
,date_dim
WHERE c_customer_sk = cs_bill_customer_sk
AND cs_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
UNION ALL
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ws_ext_list_price-ws_ext_wholesale_cost-ws_ext_discount_amt+ws_ext_sales_price, 0)/2) year_total
,'w' sale_type
FROM customer
,web_sales
,date_dim
WHERE c_customer_sk = ws_bill_customer_sk
AND ws_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
)
SELECT TOP 100
t_s_secyear.customer_id
,t_s_secyear.customer_first_name
,t_s_secyear.customer_last_name
,t_s_secyear.customer_birth_country
FROM year_total t_s_firstyear
,year_total t_s_secyear
,year_total t_c_firstyear
,year_total t_c_secyear
,year_total t_w_firstyear
,year_total t_w_secyear
WHERE t_s_secyear.customer_id = t_s_firstyear.customer_id
AND t_s_firstyear.customer_id = t_c_secyear.customer_id
AND t_s_firstyear.customer_id = t_c_firstyear.customer_id
AND t_s_firstyear.customer_id = t_w_firstyear.customer_id
AND t_s_firstyear.customer_id = t_w_secyear.customer_id
AND t_s_firstyear.sale_type = 's'
AND t_c_firstyear.sale_type = 'c'
AND t_w_firstyear.sale_type = 'w'
AND t_s_secyear.sale_type = 's'
AND t_c_secyear.sale_type = 'c'
AND t_w_secyear.sale_type = 'w'
AND t_s_firstyear.dyear+0 = 1999
AND t_s_secyear.dyear+0 = 1999+1
AND t_c_firstyear.dyear+0 = 1999
AND t_c_secyear.dyear+0 = 1999+1
AND t_w_firstyear.dyear+0 = 1999
AND t_w_secyear.dyear+0 = 1999+1
AND t_s_firstyear.year_total > 0
AND t_c_firstyear.year_total > 0
AND t_w_firstyear.year_total > 0
AND CASE WHEN t_c_firstyear.year_total > 0 THEN t_c_secyear.year_total / t_c_firstyear.year_total ELSE NULL END
> CASE WHEN t_s_firstyear.year_total > 0 THEN t_s_secyear.year_total / t_s_firstyear.year_total ELSE NULL END
AND CASE WHEN t_c_firstyear.year_total > 0 THEN t_c_secyear.year_total / t_c_firstyear.year_total ELSE NULL END
> CASE WHEN t_w_firstyear.year_total > 0 THEN t_w_secyear.year_total / t_w_firstyear.year_total ELSE NULL END
ORDER BY t_s_secyear.customer_id
,t_s_secyear.customer_first_name
,t_s_secyear.customer_last_name
,t_s_secyear.customer_birth_country
OPTION ( LABEL = 'Query04-af359846-253-3');
Zkontrolujte odhadovaný plán provádění dotazu. Existuje 18 operací zamíchání a 17 operací spojení, které trvají déle na provedení.
Teď vytvoříme jedno materializované zobrazení pro každý ze tří příkazů sub-SELECT.
CREATE materialized view nbViewSS WITH (DISTRIBUTION=HASH(customer_id)) AS
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ss_ext_list_price-ss_ext_wholesale_cost-ss_ext_discount_amt+ss_ext_sales_price, 0)/2) year_total
, count_big(*) AS cb
FROM dbo.customer
,dbo.store_sales
,dbo.date_dim
WHERE c_customer_sk = ss_customer_sk
AND ss_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
GO
CREATE materialized view nbViewCS WITH (DISTRIBUTION=HASH(customer_id)) AS
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(cs_ext_list_price-cs_ext_wholesale_cost-cs_ext_discount_amt+cs_ext_sales_price, 0)/2) year_total
, count_big(*) as cb
FROM dbo.customer
,dbo.catalog_sales
,dbo.date_dim
WHERE c_customer_sk = cs_bill_customer_sk
AND cs_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
GO
CREATE materialized view nbViewWS WITH (DISTRIBUTION=HASH(customer_id)) AS
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ws_ext_list_price-ws_ext_wholesale_cost-ws_ext_discount_amt+ws_ext_sales_price, 0)/2) year_total
, count_big(*) AS cb
FROM dbo.customer
,dbo.web_sales
,dbo.date_dim
WHERE c_customer_sk = ws_bill_customer_sk
AND ws_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
Znovu zkontrolujte plán provádění původního dotazu. Počet spojení se teď změní z 17 na 5 a nedochází již k žádnému přesunu dat. V plánu vyberte ikonu operace filtru. Jeho výstupní seznam ukazuje, že data se čtou z materializovaných zobrazení místo základních tabulek.
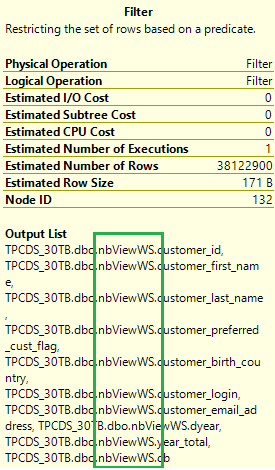
V materializovaných zobrazeních se stejný dotaz spouští mnohem rychleji bez jakékoli změny kódu.
Další kroky
Další tipy pro vývoj najdete v tématu Přehled vývoje Synapse SQL.