Principy a příprava na zotavení po havárii
V tomto článku probereme důležité principy zotavení po havárii (DR) pro velké instance HANA (označované také jako BareMetal Infrastructure). Provedeme kroky, které je potřeba provést při přípravě na zotavení po havárii. Dozvíte se také, jak v případě havárie dosáhnout cíle doby obnovení (RTO) a cíle bodu obnovení (RPO).
Principy zotavení po havárii pro velké instance HANA
Velké instance HANA nabízejí funkci zotavení po havárii mezi kolky velkých instancí HANA v různých oblastech Azure. Řekněme například, že nasadíte velké instance HANA v oblasti Usa – západ v Azure. Pak můžete použít velké instance HANA v oblasti USA – východ jako jednotky zotavení po havárii. Zotavení po havárii se nenakonfiguruje automaticky, protože vyžaduje, abyste zaplatili za jinou velkou instanci HANA v oblasti zotavení po havárii. Nastavení zotavení po havárii funguje pro nastavení vertikálního a horizontálního navýšení kapacity.
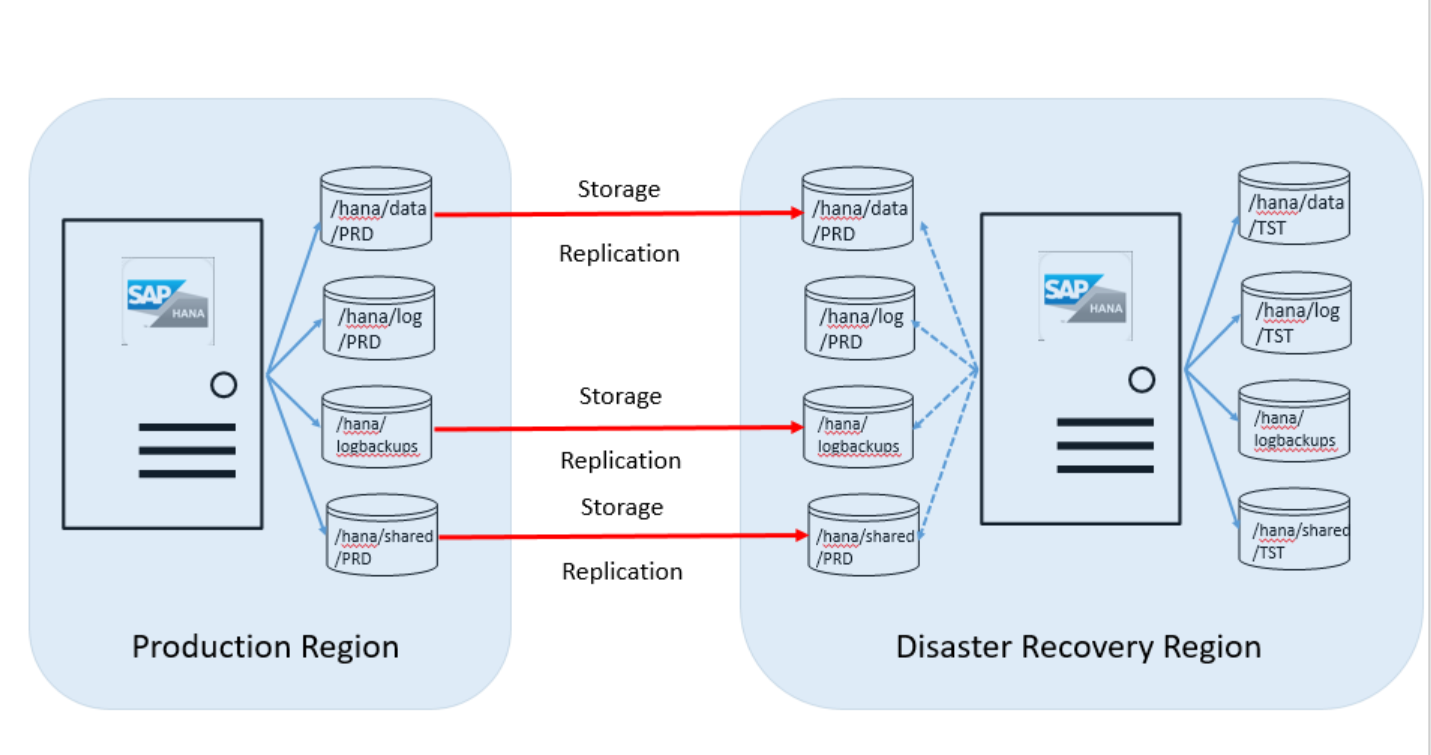
Většina zákazníků používá jednotku v oblasti zotavení po havárii ke spouštění neprodukčních systémů, které používají nainstalovanou instanci HANA. Velká instance HANA musí mít stejnou skladovou položku jako skladová položka použitá pro produkční účely. Následující obrázek ukazuje, jak vypadá konfigurace disku mezi jednotkou serveru v produkční oblasti Azure a oblastí zotavení po havárii:
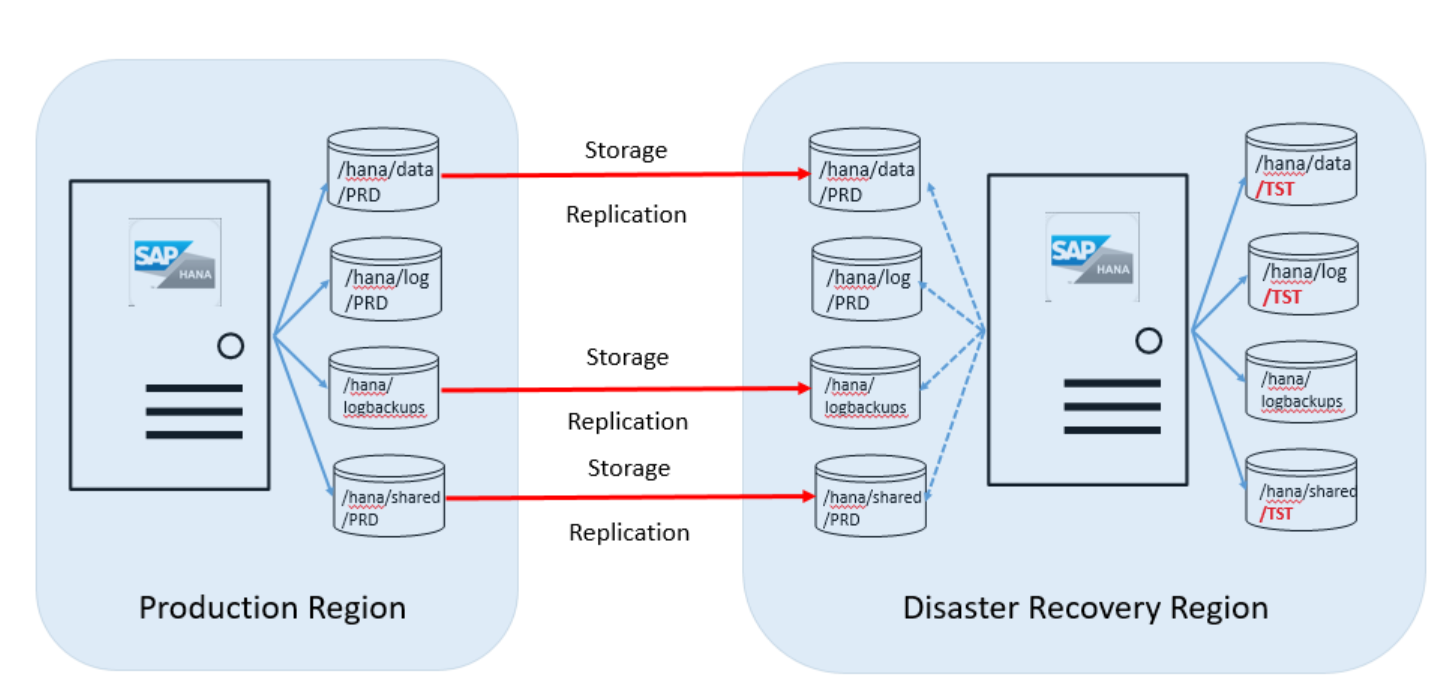
Jak je znázorněno v tomto přehledu, budete muset objednat druhou sadu diskových svazků. Cílové diskové svazky přidružené k serveru velké instance HANA v lokalitě zotavení po havárii mají stejnou velikost jako produkční svazky.
Následující svazky se replikují z produkční oblasti do lokality zotavení po havárii:
- /hana/data
- /hana/logbackups
- /hana/shared (zahrnuje /usr/sap)
Svazek /hana/log se nereplikuje. Při obnovování z těchto svazků není potřeba transakční protokol SAP HANA.
Replikace úložiště velkých instancí HANA
Základem funkce zotavení po havárii v infrastruktuře velké instance HANA je její replikace úložiště. Funkce používané na straně úložiště nejsou konstantním proudem změn, které se replikují asynchronním způsobem, jak ke změnám dochází na svazku úložiště. Místo toho jde o mechanismus, který spoléhá na pravidelné vytváření snímků těchto svazků. Rozdíl mezi již replikovaným snímkem a novým snímkem, který ještě není replikovaný, se pak přenese do lokality zotavení po havárii na cílové diskové svazky. Tyto snímky se ukládají na svazky. Pokud dojde k převzetí služeb při selhání zotavení po havárii, je potřeba je obnovit na těchto svazcích.
První přenos kompletních dat svazku by měl proběhnout dříve, než se objem dat zmenší než rozdíly mezi snímky. Svazky v lokalitě pro zotavení po havárii pak budou obsahovat všechny snímky svazků pořízené v produkční lokalitě. Nakonec můžete tento systém zotavení po havárii použít k dřívějšímu stavu a obnovit ztracená data, aniž byste museli vrátit zpět produkční systém.
Pokud na jedné velké instanci HANA existuje nasazení MCOD s několika nezávislými instancemi SAP HANA, všechny instance SAP HANA by měly mít úložiště replikované na stranu zotavení po havárii.
Pokud pro zajištění vysoké dostupnosti v produkční lokalitě použijete replikaci systému HANA a pro lokalitu zotavení po havárii použijete replikaci založenou na úložišti, budou se replikovat svazky obou uzlů z primární lokality do instance zotavení po havárii. Zakupte si v lokalitě zotavení po havárii další úložiště (stejnou velikost jako primární uzel), které umožní replikaci z primárního i sekundárního uzlu na zotavení po havárii.
Poznámka
Funkce replikace úložiště velké instance HANA zrcadlí a replikuje snímky úložiště. Pokud neřídíte snímky úložiště, jak je popsáno v tématu Zálohování a obnovení, nemůže dojít k žádné replikaci do lokality pro zotavení po havárii. Provedení snímku úložiště je předpokladem pro replikaci úložiště do lokality pro zotavení po havárii.
Příprava scénáře zotavení po havárii
V tomto scénáři zotavení po havárii máte produkční systém spuštěný na velkých instancích HANA v produkční oblasti Azure. V následujících krocích řekněme, že identifikátor SID tohoto systému HANA je PRD. Máte také neprodukční systém spuštěný na velkých instancích HANA v oblasti Azure pro zotavení po havárii. Jeho IDENTIFIKÁTOR SID je TST. Následující obrázek ukazuje tuto konfiguraci:
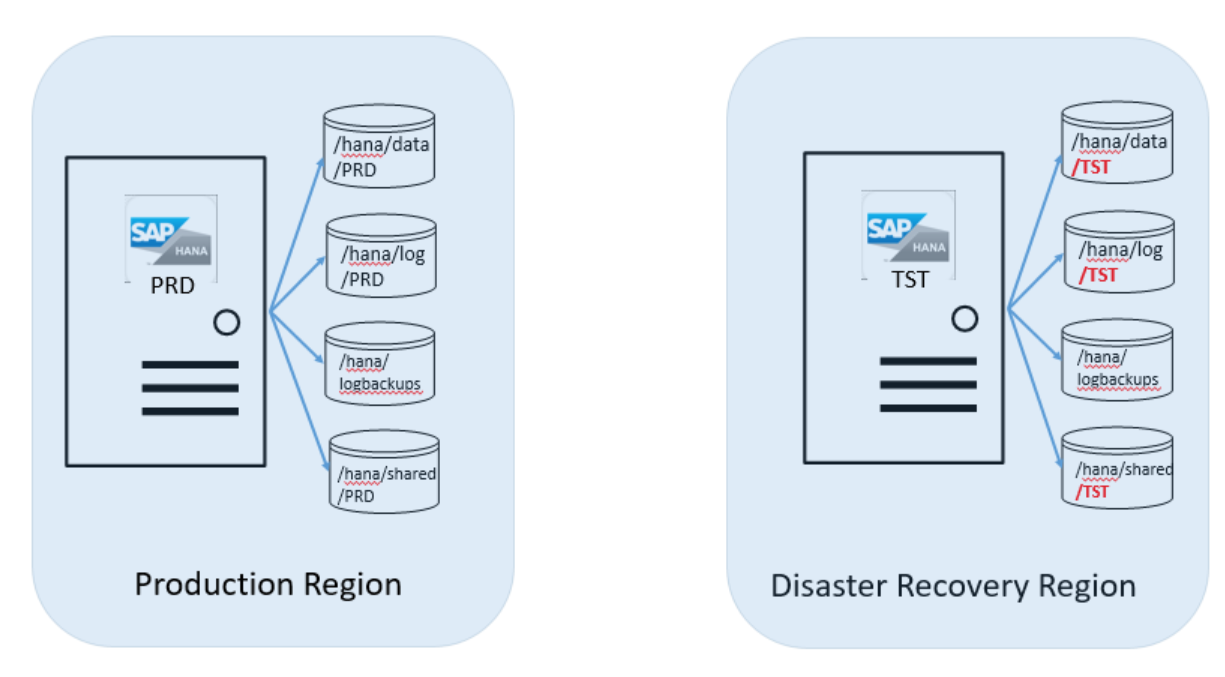
Řekněme, že instance serveru ještě není seřazená s nastaveným svazkem úložiště navíc. Sap HANA ve službě Azure Service Management pak připojí přidané svazky. Jsou cílem produkční repliky velké instance HANA, na které spouštíte instanci TST HANA. Budete muset zadat IDENTIFIKÁTOR SID produkční instance HANA. Jakmile SAP HANA ve službě Azure Service Management potvrdí připojení těchto svazků, budete muset tyto svazky připojit k velké instanci HANA.
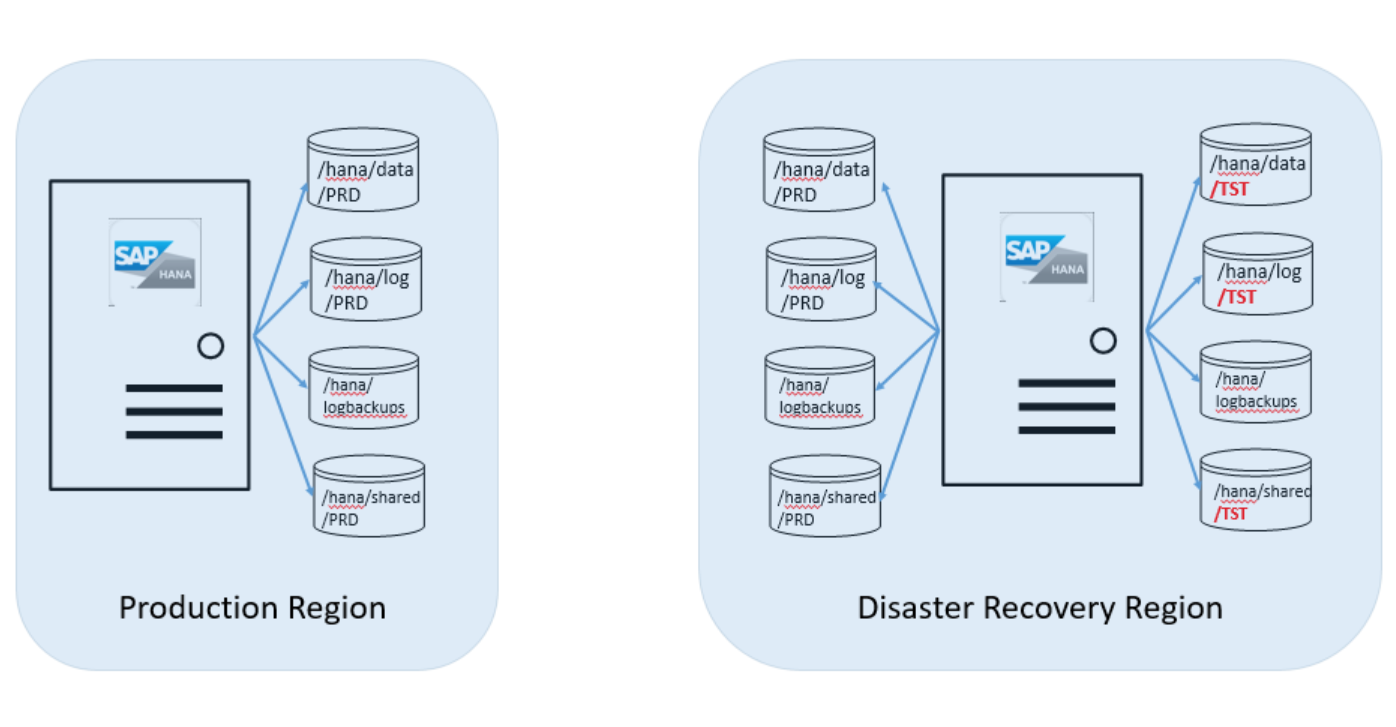
Dalším krokem je instalace druhé instance SAP HANA do velké instance HANA v oblasti Azure zotavení po havárii, ve které spouštíte instanci TST HANA. Nově nainstalovaná instance SAP HANA musí mít stejný identifikátor SID. Vytvoření uživatelé musí mít stejné UID a ID skupiny jako produkční instance. Podrobnosti najdete v tématu Zálohování a obnovení . Pokud instalace proběhne úspěšně, budete muset:
- Proveďte krok 2 přípravy snímků úložiště popsaných v tématu Zálohování a obnovení.
- Pokud jste to ještě neudělali, vytvořte veřejný klíč pro jednotku zotavení po havárii velké instance HANA. Viz krok 3 přípravy snímků úložiště popsaný v tématu Zálohování a obnovení.
- Udržujte HANABackupCustomerDetails.txt s novou instancí HANA a otestujte, jestli připojení k úložišti funguje správně.
- Zastavte nově nainstalovanou instanci SAP HANA ve velké instanci HANA v oblasti Azure pro zotavení po havárii.
- Odpojte tyto svazky PRD a kontaktujte SAP HANA ve správě služeb Azure. Svazky nemůžou zůstat připojené k jednotce, protože nemůžou být přístupné, když fungují jako cíl replikace úložiště.
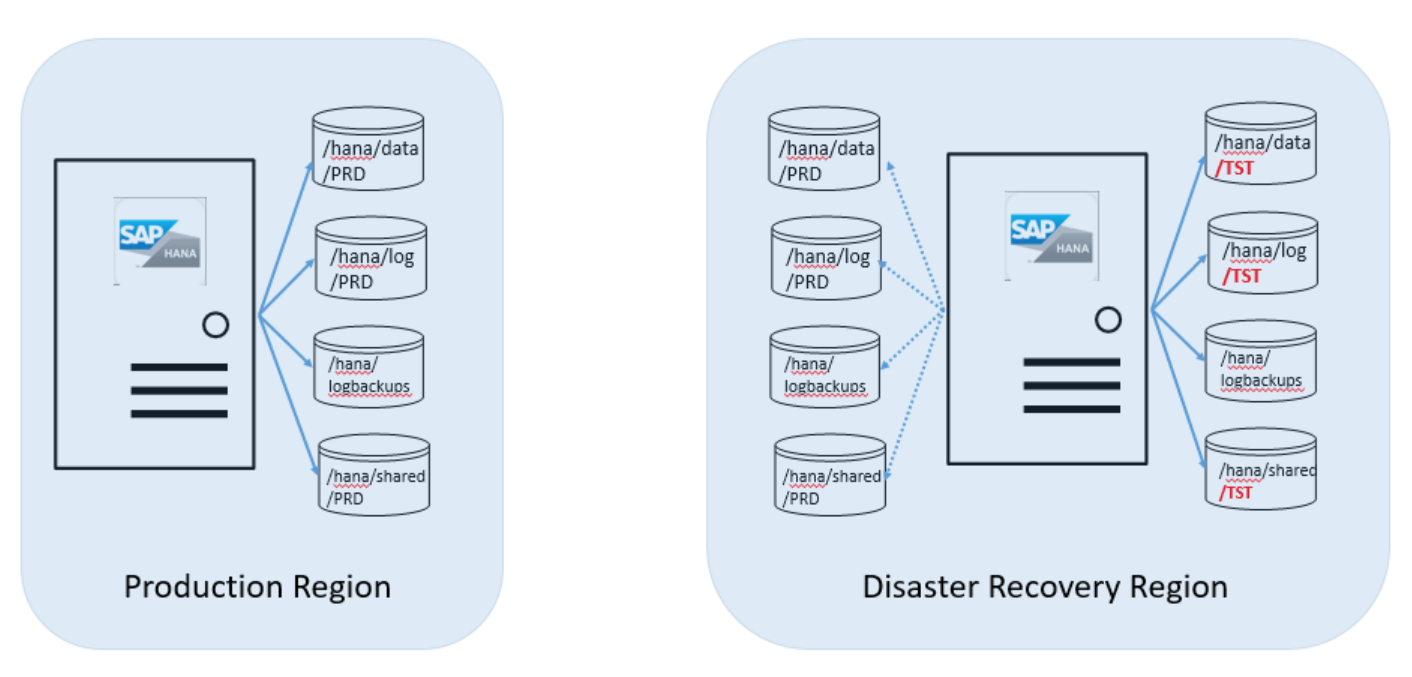
Provozní tým vytvoří vztah replikace mezi svazky PRD v produkční oblasti a svazky PRD v oblasti zotavení po havárii.
Důležité
Svazek /hana/log se nereplikuje, protože není nutné obnovit replikovanou databázi SAP HANA do konzistentního stavu v lokalitě pro zotavení po havárii.
V dalším kroku nastavte plán zálohování snímků úložiště, abyste dosáhli plánované doby obnovení (RTO) a cíle bodu obnovení (RPO), pokud dojde k havárii. Pokud chcete cíl bodu obnovení minimalizovat, nastavte ve službě velké instance HANA následující intervaly replikace:
- Pro svazky pokryté kombinovaným snímkem (typ snímku hana) se nastavte na replikaci každých 15 minut na ekvivalentní cíle svazku úložiště v lokalitě pro zotavení po havárii.
- Pro záložní svazek transakčního protokolu ( protokoly typu snímku) nastavte replikaci každé 3 minuty na ekvivalentní cíle svazku úložiště v lokalitě pro zotavení po havárii.
Pokud chcete minimalizovat cíl bodu obnovení:
- Pořiďte snímek úložiště typu hana každých 30 minut až 1 hodinu. Další informace najdete v tématu Zálohování pomocí nástroje Aplikace Azure Konzistentní snímek.
- Zálohování transakčních protokolů SAP HANA každých 5 minut
- Každých 5 až 15 minut pořiďte snímek úložiště typu protokoly . S tímto intervalem dosáhnete cíle bodu obnovení přibližně 15–25 minut.
Při tomto nastavení může posloupnost záloh transakčních protokolů, snímků úložiště a replikace svazku zálohování transakčních protokolů HANA a svazků /hana/data a /hana/shared (včetně /usr/sap) vypadat jako data znázorněná na tomto obrázku:
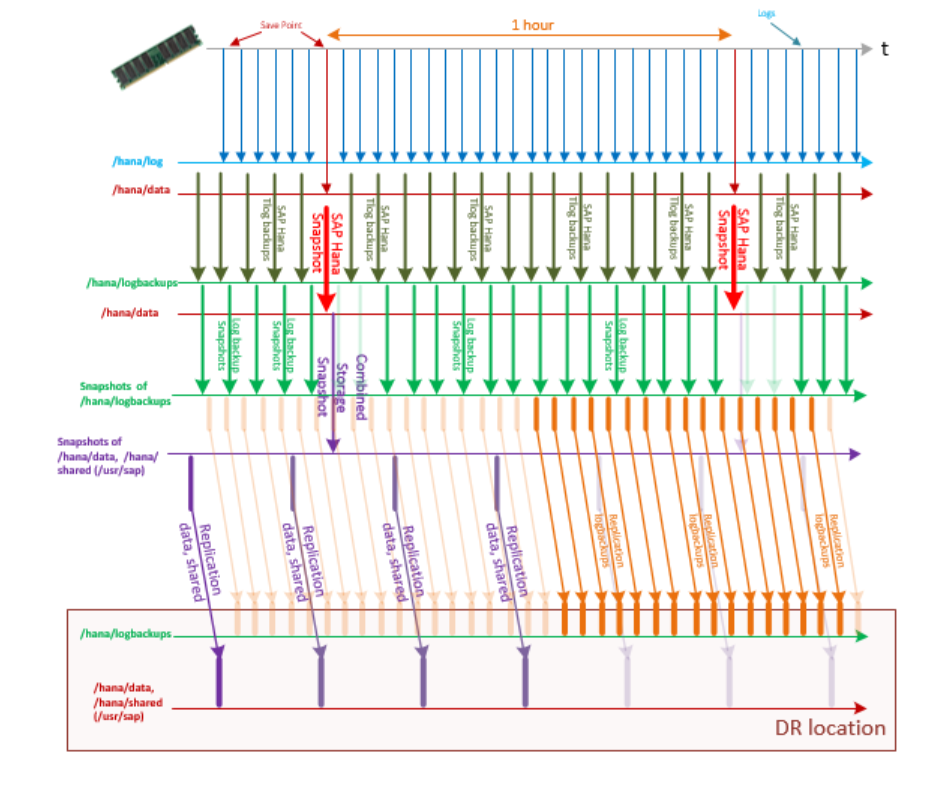
Pokud chcete v případě zotavení po havárii dosáhnout ještě lepšího cíle bodu obnovení, můžete zkopírovat zálohy transakčních protokolů HANA ze SAP HANA v Azure (velké instance) do jiné oblasti Azure. Pokud chcete dosáhnout tohoto dalšího snížení cíle bodu obnovení, proveďte následující kroky:
- Co nejčastěji zálohujte transakční protokol HANA do souboru /hana/logbackups.
- Pomocí rsync zkopírujte zálohy transakčních protokolů do virtuálních počítačů Azure hostovaných ve sdílené složce NFS. Virtuální počítače jsou ve virtuálních sítích Azure v produkční oblasti Azure a v oblasti zotavení po havárii. Připojte obě virtuální sítě Azure k okruhu, který spojuje produkční velké instance HANA s Azure. Další informace najdete v tématu Důležité informace o síti pro zotavení po havárii s využitím velkých instancí HANA.
- Uchovávejte zálohy transakčních protokolů v oblasti virtuálního počítače připojeného k exportovanýmu úložišti NFS.
- V případě převzetí služeb při selhání po havárii doplňte zálohy transakčních protokolů, které najdete na svazku /hana/logbackups, o nedávno pořízené zálohy transakčních protokolů ve sdílené složce NFS na webu pro zotavení po havárii.
- Spusťte zálohování transakčních protokolů a obnovte nejnovější zálohu, která se může uložit do oblasti zotavení po havárii.
Když operace velkých instancí HANA potvrdí nastavení vztahu replikace a spustíte spouštěcí zálohy snímků úložiště, zahájí se replikace dat.
V průběhu replikace se snímky na svazcích PRD v oblastech Azure pro zotavení po havárii neobnoví. Snímky jsou pouze uložené. Pokud jsou svazky připojené v takovém stavu, představují stav, ve kterém jste tyto svazky odpojí po instalaci instance PRD SAP HANA na server v oblasti Azure pro zotavení po havárii. Představují také zálohy úložiště, které se ještě neobnovily.
Pokud dojde k převzetí služeb při selhání, můžete se také rozhodnout provést obnovení na starší snímek úložiště místo na nejnovější snímek úložiště.
Další kroky
Přečtěte si o postupu převzetí služeb při selhání zotavení po havárii.