Svazky NFS v4.1 ve službě Azure NetApp Files pro SAP HANA
Azure NetApp Files poskytuje nativní sdílené složky NFS, které je možné použít pro svazky /hana/shared, /hana/data a /hana/log . Použití sdílených složek NFS založených na ANF pro svazky /hana/data a /hana/log vyžaduje použití protokolu NFS verze 4.1. Protokol NFS v3 se nepodporuje při použití svazků /hana/data a /hana/log při založit sdílené složky na ANF.
Důležité
Protokol NFS v3 implementovaný ve službě Azure NetApp Files se nepodporuje pro /hana/data a /hana/log. Použití svazků NFS 4.1 je povinné pro svazky /hana/data a /hana/log z funkčního hlediska. Zatímco pro /hana/sdílený svazek NFS v3 nebo protokol NFS v4.1 lze použít z funkčního hlediska.
Důležitá poznámka
Při zvažování služby Azure NetApp Files pro SAP Netweaver a SAP HANA mějte na paměti následující důležité aspekty:
Minimální fond kapacity je 4 TiB.
Minimální velikost svazku je 100 GiB.
Sdílené složky NFS založené na ANF a virtuální počítače, které tyto sdílené složky připojují, musí být ve stejné virtuální síti Azure nebo v partnerských virtuálních sítích ve stejné oblasti.
Vybraná virtuální síť musí mít podsíť delegovanou do služby Azure NetApp Files. Pro úlohy SAP se důrazně doporučuje nakonfigurovat rozsah /25 pro podsíť delegovanou do ANF.
Je důležité, aby virtuální počítače nasadily dostatečnou vzdálenost k úložišti Azure NetApp, aby se snížila latence, například vyžaduje SAP HANA pro zápisy do protokolu znovu.
- Služba Azure NetApp Files mezitím nabízí funkce pro nasazení svazků NFS do konkrétních Zóny dostupnosti Azure. Tato zónová vzdálenost bude ve většině případů dostatečná k dosažení latence menší než 1 milisekundy. Funkce jsou ve verzi Public Preview a jsou popsané v článku Správa umístění svazků zóny dostupnosti pro Službu Azure NetApp Files. Tato funkce nevyžaduje žádný interaktivní proces s Microsoftem k dosažení blízkosti mezi vaším virtuálním počítačem a svazky NFS, které přidělíte.
- K dosažení optimální blízkosti je k dispozici funkce skupin svazků aplikací. Tato funkce nejen hledá optimální blízkost, ale pro optimální umístění svazků NFS, takže data HANA a svazky protokolu znovu zpracovávají různé kontrolery. Nevýhodou je, že tato metoda potřebuje nějaký interaktivní proces s Microsoftem k připnutí virtuálních počítačů.
Ujistěte se, že je měřena latence z databázového serveru na svazek ANF a nižší než 1 milisekunda.
Propustnost svazku Azure NetApp je funkce kvóty svazku a úrovně služby, jak je uvedeno na úrovni služby pro Azure NetApp Files. Při nastavování velikosti svazků AZURE NetApp HANA se ujistěte, že výsledná propustnost splňuje systémové požadavky HANA. Alternativně zvažte použití ručního fondu kapacity QoS, kde je možné kapacitu svazku a propustnost konfigurovat a škálovat nezávisle (příklady pro SAP HANA jsou v tomto dokumentu.
Zkuste "konsolidovat" svazky, abyste dosáhli vyššího výkonu ve větším svazku, například použijte jeden svazek pro /sapmnt, /usr/sap/trans, ... pokud je to možné
Azure NetApp Files nabízí zásady exportu: můžete řídit povolené klienty, typ přístupu (čtení&zápis, jen pro čtení atd.).
ID uživatele pro sidadm a ID skupiny pro
sapsysvirtuální počítače musí odpovídat konfiguraci v Azure NetApp Files.Implementace parametrů operačního systému Linux uvedených v poznámce SAP 3024346
Důležité
U úloh SAP HANA je klíčová nízká latence. Spolupracujte se zástupcem Microsoftu a ujistěte se, že jsou virtuální počítače a svazky Azure NetApp Files nasazené v těsné blízkosti.
Důležité
Pokud dojde k neshodě mezi ID uživatele pro sidadm a ID skupiny mezi sapsys virtuálním počítačem a konfigurací Azure NetApp, zobrazí se oprávnění pro soubory na svazcích Azure NetApp připojených k virtuálnímu počítači jako nobody. Při zprovoznění nového systému do služby Azure NetApp Files nezapomeňte zadat správné ID uživatele pro sidadm a ID skupiny prosapsys.
Možnost připojení NCONNECT
Nconnect je možnost připojení pro svazky NFS hostované na ANF, která umožňuje klientovi NFS otevřít více relací s jedním svazkem NFS. Když použijete nconnect s hodnotou větší než 1, aktivuje klient NFS také použití více než jedné relace RPC na straně klienta (v hostovaném operačním systému) ke zpracování provozu mezi hostovaným operačním systémem a připojenými svazky NFS. Použití více relací zpracovávajících provoz jednoho svazku NFS, ale také použití více relací RPC může řešit scénáře výkonu a propustnosti, jako jsou:
- Připojení několika svazků NFS hostovaných službou ANF s různými úrovněmi služeb na jednom virtuálním počítači
- Maximální propustnost zápisu svazku a jedna relace Linuxu je mezi 1,2 a 1,4 GB/s. Pokud máte více relací s jedním svazkem NFS hostovaným systémem ANF, může zvýšit propustnost.
Pro verze operačního systému Linux, které podporují nconnect jako možnost připojení a některé důležité aspekty konfigurace nconnect, zejména s různými koncovými body serveru NFS, si přečtěte dokument s možnostmi připojení systému Souborů NFS pro Linux pro Azure NetApp Files.
Určení velikosti databáze HANA ve službě Azure NetApp Files
Propustnost svazku Azure NetApp je funkce velikosti svazku a úrovně služby, jak je uvedeno v úrovních služeb pro Azure NetApp Files.
Důležité je pochopit, že velikost vztahu výkonu a že existují fyzická omezení koncového bodu úložiště služby. Každý koncový bod úložiště se při vytváření svazku dynamicky vloží do delegované podsítě služby Azure NetApp Files a obdrží IP adresu. Svazky Azure NetApp Files můžou – v závislosti na dostupné kapacitě a logice nasazení – sdílet koncový bod úložiště
Následující tabulka ukazuje, že by bylo vhodné vytvořit velký "standardní" svazek pro ukládání záloh a že nemá smysl vytvořit svazek "Ultra" větší než 12 TB, protože by byla překročena maximální kapacita fyzické šířky pásma jednoho svazku.
Pokud potřebujete více než maximální propustnost zápisu pro svazek /hana/data než jednu linuxovou relaci, můžete jako alternativu použít také dělení datového svazku SAP HANA. Dělení datového svazku SAP HANA proloží vstupně-výstupní aktivitu během opětovného načítání dat nebo ukládání HANA napříč několika datovými soubory HANA umístěnými ve více sdílených složkách NFS. Další podrobnosti o prokládání datových svazků HANA najdete v těchto článcích:
- Příručka k Správa astratoru HANA
- Blog o SAP HANA – Dělení datových svazků
- SAP Note #2400005
- SAP Note #2700123
| Velikost | Propustnost úrovně Standard | Propustnost Premium | Propustnost Ultra |
|---|---|---|---|
| 1 TB | 16 MB/s | 64 MB/s | 128 MB/s |
| 2 TB | 32 MB/s | 128 MB/s | 256 MB/s |
| 4 TB | 64 MB/s | 256 MB/s | 512 MB/s |
| 10 TB | 160 MB/s | 640 MB/s | 1 280 MB/s |
| 15 TB | 240 MB/s | 960 MB/s | 1 400 MB/s1 |
| 20 TB | 320 MB/s | 1 280 MB/s | 1 400 MB/s1 |
| 40 TB | 640 MB/s | 1 400 MB/s1 | 1 400 MB/s1 |
1: Omezení propustnosti zápisu nebo čtení jedné relace (v případě, že se nepoužívá možnost připojení NFS nconnect)
Je důležité si uvědomit, že data se zapisují na stejné disky SSD v back-endu úložiště. Byla vytvořena kvóta výkonu z fondu kapacity, aby bylo možné spravovat prostředí. Klíčové ukazatele výkonu úložiště jsou stejné pro všechny velikosti databází HANA. V téměř všech případech tento předpoklad neodráží realitu a očekávání zákazníka. Velikost systémů HANA nemusí nutně znamenat, že malý systém vyžaduje nízkou propustnost úložiště a velký systém vyžaduje vysokou propustnost úložiště. Obecně ale můžeme očekávat vyšší požadavky na propustnost pro větší instance databáze HANA. V důsledku pravidel velikosti SAP pro základní hardware, jako jsou větší instance HANA, také poskytují více prostředků procesoru a vyšší paralelismus v úlohách, jako je načítání dat po restartování instancí. V důsledku toho by měly být velikosti svazků přijaty k očekávání a požadavkům zákazníků. A to nejen díky čistým požadavkům na kapacitu.
Při návrhu infrastruktury pro SAP v Azure byste měli znát některé požadavky na minimální propustnost úložiště (pro produkční systémy) od SAP. Tyto požadavky se překládají na charakteristiky minimální propustnosti:
| Typ svazku a vstupně-výstupní typ | Minimální požadovaný klíčový ukazatel výkonu podle SAP | Úroveň služby Premium | Úroveň služeb Úrovně ultra |
|---|---|---|---|
| Zápis svazku protokolu | 250 MB/s | 4 TB | 2 TB |
| Zápis datového svazku | 250 MB/s | 4 TB | 2 TB |
| Čtení datového svazku | 400 MB/s | 6,3 TB | 3,2 TB |
Vzhledem k tomu, že jsou požadovány všechny tři klíčové ukazatele výkonu, musí mít objem dat /hana/data velikost směrem k větší kapacitě, aby bylo možné splnit minimální požadavky na čtení. Pokud používáte ruční fondy kapacity QoS, je možné nezávisle definovat velikost a propustnost svazků. Vzhledem k tomu, že kapacita i propustnost pocházejí ze stejného fondu kapacity, musí být úroveň a velikost fondu dostatečně velká, aby se zajistil celkový výkon (viz příklad tady).
U systémů HANA, které nevyžadují velkou šířku pásma, může propustnost svazku ANF snížit buď menší velikost svazku, nebo pomocí ručního QoS úpravou propustnosti přímo. A v případě, že systém HANA vyžaduje větší propustnost, může být svazek upraven změnou velikosti kapacity online. Pro svazky zálohování nejsou definovány žádné klíčové ukazatele výkonu. Propustnost svazku zálohování je ale nezbytná pro dobře výkonné prostředí. Protokol – a výkon objemu dat musí být navrženy pro očekávání zákazníků.
Důležité
Nezávisle na kapacitě, kterou nasadíte na jednom svazku NFS, se očekává, že propustnost bude v rozsahu 1,2 až 1,4 GB/s šířky pásma využitá příjemcem v jedné relaci. To musí souviset s základní architekturou nabídky ANF a souvisejícími omezeními relací Linuxu týkajícími se systému souborů NFS. Čísla výkonu a propustnosti, jak je uvedeno v článku Výsledky testu srovnávacího testu výkonu pro službu Azure NetApp Files , byla provedena na jednom sdíleném svazku NFS s více klientskými virtuálními počítači a v důsledku toho s více relacemi. Tento scénář se liší od scénáře, který měříme v SAP. Kde měříme propustnost z jednoho virtuálního počítače proti svazku NFS. Hostováno v ANF.
Aby bylo možné splnit požadavky na minimální propustnost SAP pro data a protokoly a podle pokynů pro /hana/shared, doporučené velikosti by vypadaly takto:
| Objem | Velikost Úroveň Premium Storage |
Velikost Úroveň Ultra Storage |
Podporovaný protokol NFS |
|---|---|---|---|
| /hana/log/ | 4 TiB | 2 TiB | v4.1 |
| /hana/data | 6.3 TiB | 3.2 TiB | v4.1 |
| /hana/sdílené vertikální navýšení kapacity | Min(1 TB, 1 x RAM) | Min(1 TB, 1 x RAM) | v3 nebo v4.1 |
| /hana/shared scale-out | 1 x ram pracovního uzlu na čtyři pracovní uzly |
1 x ram pracovního uzlu na čtyři pracovní uzly |
v3 nebo v4.1 |
| /hana/logbackup | 3 x ram | 3 x ram | v3 nebo v4.1 |
| /hana/backup | 2 x RAM | 2 x RAM | v3 nebo v4.1 |
Pro všechny svazky se důrazně doporučuje systém souborů NFS verze 4.1.
Pečlivě zkontrolujte, co je potřeba vzít v úvahu při nastavení velikosti /hana/shared, protože velikost /hana/sdílený svazek přispívá ke stabilitě systému.
Velikosti svazků zálohování jsou odhady. Přesné požadavky je potřeba definovat na základě procesů úloh a operací. U záloh můžete konsolidovat mnoho svazků pro různé instance SAP HANA na jeden (nebo dva) větší svazky, které můžou mít nižší úroveň služby ANF.
Poznámka:
Doporučení pro změnu velikosti uvedená v tomto dokumentu v Azure NetApp Files cílí na minimální požadavky, které SAP vyjadřuje vůči poskytovatelům infrastruktury. V reálných scénářích nasazení a úloh zákazníka to nemusí stačit. Tato doporučení používejte jako výchozí bod a přizpůsobte se na základě požadavků konkrétní úlohy.
Proto byste mohli zvážit nasazení podobné propustnosti pro svazky ANF uvedené pro diskové úložiště Úrovně Ultra. Zvažte také velikosti velikostí uvedených pro svazky pro různé skladové položky virtuálních počítačů, jak je to provedeno v tabulkách disků Úrovně Ultra.
Tip
Svazky Azure NetApp Files můžete dynamicky měnit, aniž byste museli unmount svazek zastavovat, zastavovat virtuální počítače nebo zastavovat SAP HANA. To umožňuje flexibilitu splnit očekávané i nepředvídatelné požadavky na propustnost vaší aplikace.
Dokumentace k nasazení konfigurace horizontálního navýšení kapacity SAP HANA s pohotovostním uzlem pomocí svazků NFS založených na ANF verze 4.1 se publikuje ve škálovacím režimu SAP HANA s pohotovostním uzlem na virtuálních počítačích Azure s Azure NetApp Files na SUSE Linux Enterprise Serveru.
Nastavení jádra Linuxu
K úspěšnému nasazení SAP HANA v ANF je potřeba implementovat nastavení jádra Linuxu podle 3024346 poznámky SAP.
Pro systémy používající vysokou dostupnost (HA) s využitím pacemakeru a Azure Load Balanceru je potřeba implementovat následující nastavení v souboru /etc/sysctl.d/91-NetApp-HANA.conf.
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 131072 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.netdev_max_backlog = 300000
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 0
net.ipv4.tcp_sack = 1
Systémy spuštěné bez pacemakeru a Azure Load Balanceru by měly implementovat tato nastavení v souboru /etc/sysctl.d/91-NetApp-HANA.conf.
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 131072 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.netdev_max_backlog = 300000
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_sack = 1
Nasazení s zónovou blízkostí
Pokud chcete získat zónovou vzdálenost svazků a virtuálních počítačů NFS, můžete postupovat podle pokynů popsaných v tématu Správa umístění svazků zóny dostupnosti pro Azure NetApp Files. S touto metodou budou virtuální počítače a svazky NFS ve stejné zóně dostupnosti Azure. Ve většiněoblastíchch Tato metoda nevyžaduje, aby microsoft umístil a připnul virtuální počítače do konkrétního datacentra. V důsledku toho můžete flexibilně měnit velikosti a rodiny virtuálních počítačů ve všech typech a rodinách virtuálních počítačů nabízených v zóně dostupnosti, kterou jste nasadili. Takže můžete reagovat flexibilní na chanign podmínky nebo můžete rychleji přejít na nákladově efektivnější velikosti virtuálních počítačů nebo rodiny. Tuto metodu doporučujeme pro neprodukční systémy a produkční systémy, které můžou pracovat s latencemi protokolu opakování, které jsou blíž k 1 milisekundám. Funkce jsou aktuálně ve verzi Public Preview.
Nasazení prostřednictvím skupiny svazků aplikací Azure NetApp Files pro SAP HANA (AVG)
Pro nasazení svazků ANF s blízkost k virtuálnímu počítači se vyvinula nová funkce označovaná jako skupina svazků aplikací Azure NetApp Files pro SAP HANA (AVG). K dispozici je řada článků, které dokumentuje funkce. Nejlepší je začít s článkem Vysvětlení skupiny svazků aplikací Azure NetApp Files pro SAP HANA. Při čtení článků je zřejmé, že použití AVG zahrnuje také použití skupin umístění bezkontaktní komunikace Azure. Skupiny umístění bezkontaktní komunikace používají nové funkce pro svázání se svazky, které se vytvářejí. Pokud chcete zajistit, aby se virtuální počítače po celou dobu životnosti systému HANA nepřesunuly ze svazků ANF, doporučujeme pro každou z nasazovaných zón použít kombinaci Avset/PPG. Pořadí nasazení by vypadalo takto:
- Pomocí formuláře, který potřebujete požádat o připnutí prázdné avSet na výpočetní HW, aby se zajistilo, že se virtuální počítače nepřesouvají
- Přiřaďte skupině dostupnosti PPG a spusťte virtuální počítač přiřazený k této skupině dostupnosti.
- Použití skupiny svazků aplikací Azure NetApp Files pro funkce SAP HANA k nasazení svazků HANA
Konfigurace skupiny umístění bezkontaktní komunikace tak, aby používala skupiny avg optimálním způsobem, by vypadala takto:
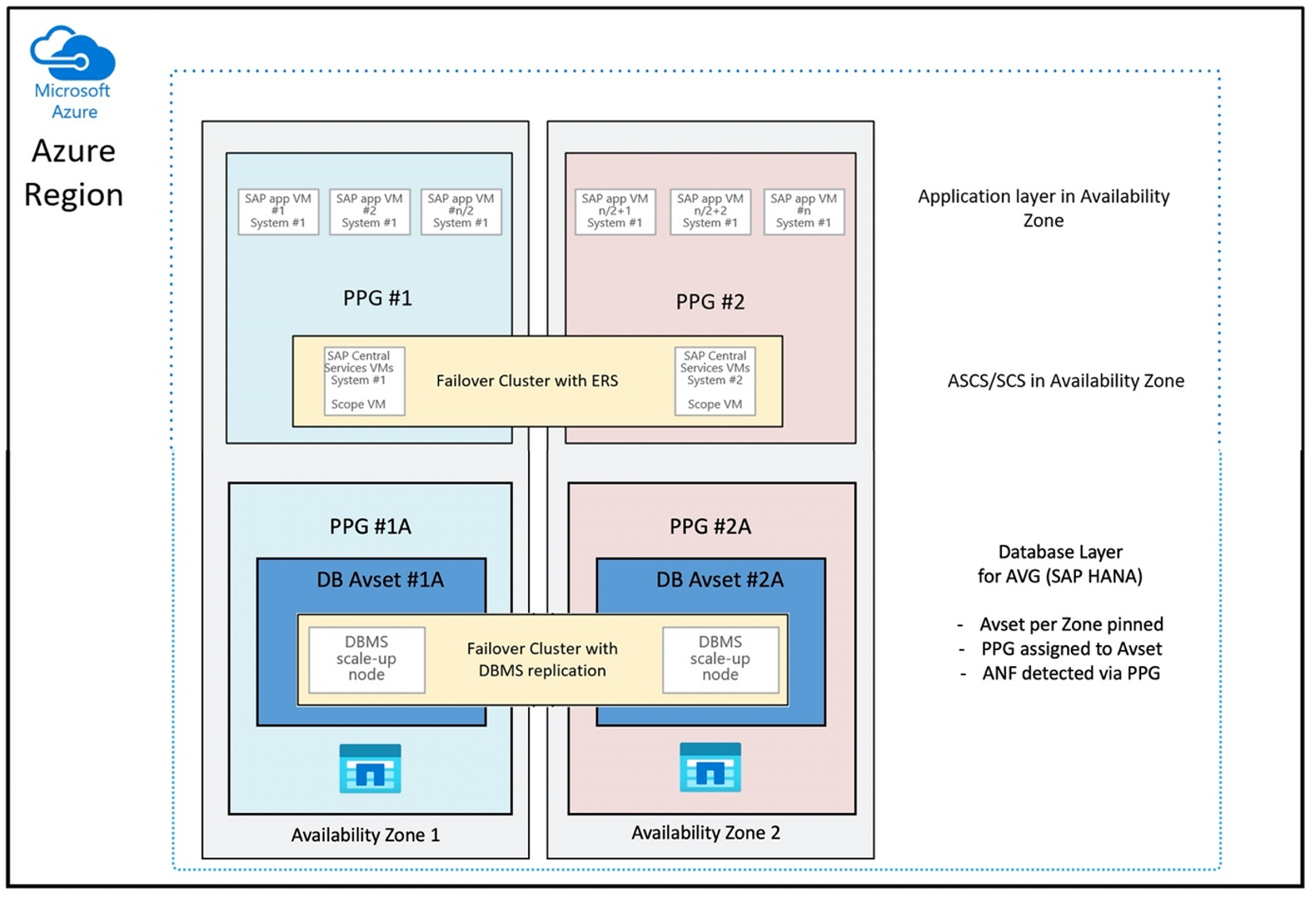
Diagram ukazuje, že pro vrstvu DBMS použijete skupinu umístění bezkontaktní komunikace Azure. To znamená, že se může používat společně s AVG. Nejlepší je zahrnout pouze virtuální počítače, které spouští instance HANA ve skupině umístění bezkontaktní komunikace. Skupina umístění bezkontaktní komunikace je nezbytná, i když se použije jenom jeden virtuální počítač s jednou instancí HANA, aby AVG identifikoval nejbližší blízkost hardwaru ANF. A pokud chcete přidělit svazek NFS na ANF co nejblíže virtuálním počítačům, které používají svazky NFS.
Tato metoda generuje nejoptimálnější výsledky, protože souvisí s nízkou latencí. Nejen získáním svazků NFS a virtuálních počítačů co nejblíže. Je však třeba vzít v úvahu také aspekty umístění svazků dat a opětovného protokolování mezi různými kontrolery na back-end NetApp. Nevýhodou je ale to, že nasazení virtuálního počítače je připnuté k jednomu datacentru. S tím, že ztrácíte flexibilitu při změně typů a rodin virtuálních počítačů. V důsledku toho byste tuto metodu měli omezit na systémy, které absolutně vyžadují takovou nízkou latenci úložiště. U všech ostatních systémů byste se měli pokusit o nasazení s tradičním zónovým nasazením virtuálního počítače a ANF. Ve většiněpřípadůch To také zajišťuje snadnou údržbu a správu virtuálního počítače a ANF.
Dostupnost
Aktualizace a upgrady systému ANF se použijí bez dopadu na prostředí zákazníka. Definovaná smlouva SLA je 99,99 %.
Svazky a IP adresy a fondy kapacity
Při použití ANF je důležité pochopit, jak je vytvořená základní infrastruktura. Fond kapacity je pouze konstrukce, která poskytuje rozpočet kapacity a výkonu a jednotku fakturace na základě úrovně služeb fondu kapacity. Fond kapacity nemá žádný fyzický vztah k základní infrastruktuře. Když ve službě vytvoříte svazek, vytvoří se koncový bod úložiště. K tomuto koncovému bodu úložiště je přiřazena jedna IP adresa, která poskytuje přístup k datům ke svazku. Pokud vytvoříte několik svazků, všechny svazky se distribuují napříč základní holou flotilou, které jsou svázané s tímto koncovým bodem úložiště. ANF má logiku, která automaticky distribuuje úlohy zákazníků, jakmile svazky nebo/a kapacita nakonfigurovaného úložiště dosáhnou interní předdefinované úrovně. Takové případy si můžete všimnout, protože se automaticky vytvoří nový koncový bod úložiště s novou IP adresou pro přístup ke svazkům. Služba ANF neposkytuje kontrolu nad touto distribuční logikou zákazníka.
Svazek protokolu a zálohovací svazek protokolu
K zápisu online protokolu se používá "svazek protokolu" (/hana/log). Proto jsou v tomto svazku umístěné otevřené soubory a nemá smysl vytvořit snímek tohoto svazku. Soubory protokolu online znovu se archivují nebo zálohují do záložního svazku protokolu, jakmile se online soubor protokolu znovu zaplní nebo se spustí zálohování protokolu znovu. Aby bylo možné zajistit přiměřený výkon zálohování, vyžaduje svazek zálohování protokolů dobrou propustnost. Pokud chcete optimalizovat náklady na úložiště, může být vhodné konsolidovat svazek zálohování protokolů více instancí HANA. Aby více instancí HANA používalo stejný svazek a zapisovaly zálohy do různých adresářů. Pomocí takové konsolidace můžete získat větší propustnost, protože potřebujete, aby byl svazek o něco větší.
Totéž platí pro svazek, na který používáte úplné zálohy databáze HANA.
Backup
Kromě streamování záloh a služby Azure Back zálohující databáze SAP HANA, jak je popsáno v článku Průvodce zálohováním pro SAP HANA na virtuálních počítačích Azure, azure NetApp Files otevírá možnost provádět zálohy snímků založené na úložišti.
SAP HANA podporuje:
- Podpora zálohování snímků založeného na úložišti pro jeden kontejnerový systém se SAP HANA 1.0 SPS7 a vyšší
- Podpora zálohování snímků založeného na úložišti pro prostředí HANA s více databázemi (MDC) s jedním tenantem se SAP HANA 2.0 SPS1 a novějším
- Podpora zálohování snímků založeného na úložišti pro prostředí MDC (Multi Database Container) HANA s více tenanty se SAP HANA 2.0 SPS4 a novějšími
Vytváření záloh snímků založených na úložišti je jednoduchý čtyřstupňový postup.
- Vytvoření snímku databáze HANA (interní) – aktivita, kterou potřebujete provést vy nebo nástroje
- SAP HANA zapisuje data do datových souborů za účelem vytvoření konzistentního stavu úložiště – HANA tento krok provede v důsledku vytvoření snímku HANA.
- Vytvořte snímek na svazku /hana/data v úložišti – krok, který je potřeba provést vy nebo nástroje. Není nutné provádět snímek na svazku /hana/log .
- Odstranění snímku databáze HANA (interní) a obnovení normálního provozu – krok, který je potřeba provést vy nebo nástroje
Upozorňující
Chybějící poslední krok nebo selhání posledního kroku má závažný dopad na poptávku po paměti SAP HANA a může vést k zastavení SAP HANA.
BACKUP DATA FOR FULL SYSTEM CREATE SNAPSHOT COMMENT 'SNAPSHOT-2019-03-18:11:00';

az netappfiles snapshot create -g mygroup --account-name myaccname --pool-name mypoolname --volume-name myvolname --name mysnapname
BACKUP DATA FOR FULL SYSTEM CLOSE SNAPSHOT BACKUP_ID 47110815 SUCCESSFUL SNAPSHOT-2020-08-18:11:00';
Tento postup zálohování snímků je možné spravovat různými způsoby pomocí různých nástrojů. Jedním z příkladů je skript Pythonu "ntaphana_azure.py", který je k dispozici na GitHubu https://github.com/netapp/ntaphana . Toto je ukázkový kód, který poskytuje "tak, jak je", bez jakékoli údržby nebo podpory.
Upozornění
Samotný snímek není chráněná záloha, protože se nachází ve stejném fyzickém úložišti jako svazek, na který jste právě pořídili snímek. Je povinné "chránit" alespoň jeden snímek za den do jiného umístění. Můžete to provést ve stejném prostředí, ve vzdálené oblasti Azure nebo v úložišti objektů blob v Azure.
Dostupná řešení pro zálohování konzistentní vzhledem ke snímkům úložiště:
- Microsoft What is Aplikace Azure Consistent Snapshot tool is a command-line tool that enables data protection for third-party databases. Zpracovává veškerou orchestraci potřebnou k umístění databází do konzistentního stavu aplikace před pořízením snímku úložiště. Po pořízení snímku úložiště nástroj vrátí databáze do provozního stavu. AzAcSnap podporuje zálohy založené na snímcích pro velké instance HANA a Azure NetApp Files. Další podrobnosti najdete v článku Co je Aplikace Azure nástroj Konzistentní snímek
- Další možností pro uživatele produktů commvault backup je Commvault IntelliSnap V.11.21 a novější. Tato nebo novější verze commvault nabízejí podporu snímků Azure NetApp Files. Další informace najdete v článku Commvault IntelliSnap 11.21 .
Zálohování snímku pomocí úložiště objektů blob v Azure
Zálohování do úložiště objektů blob v Azure je nákladově efektivní a rychlá metoda, jak ušetřit zálohy snímků úložiště databáze HANA založené na ANF. Pokud chcete snímky uložit do úložiště objektů blob v Azure, je upřednostňovaný nástroj AzCopy. Stáhněte si nejnovější verzi tohoto nástroje a nainstalujte ho například v adresáři bin, kde je nainstalovaný skript Pythonu z GitHubu. Stáhněte si nejnovější nástroj AzCopy:
root # wget -O azcopy_v10.tar.gz https://aka.ms/downloadazcopy-v10-linux && tar -xf azcopy_v10.tar.gz --strip-components=1
Saving to: ‘azcopy_v10.tar.gz’
Nejpokročilejší funkcí je možnost SYNCHRONIZACE. Pokud použijete možnost SYNCHRONIZACE, azcopy zachová zdroj a cílový adresář synchronizovaný. Použití parametru --delete-destination je důležité. Bez tohoto parametru azcopy neodstraní soubory v cílové lokalitě a využití místa na cílové straně by se zvětšovalo. Ve svém účtu úložiště Azure vytvořte kontejner objektů blob bloku. Pak vytvořte klíč SAS pro kontejner objektů blob a synchronizujte složku snímků s kontejnerem objektů blob Azure.
Pokud by se například měl denní snímek synchronizovat s kontejnerem objektů blob Azure za účelem ochrany dat. A pouze jeden snímek by měl být zachován, můžete použít následující příkaz.
root # > azcopy sync '/hana/data/SID/mnt00001/.snapshot' 'https://azacsnaptmytestblob01.blob.core.windows.net/abc?sv=2021-02-02&ss=bfqt&srt=sco&sp=rwdlacup&se=2021-02-04T08:25:26Z&st=2021-02-04T00:25:26Z&spr=https&sig=abcdefghijklmnopqrstuvwxyz' --recursive=true --delete-destination=true
Další kroky
Přečtěte si tento článek:
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro