Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Posun doprava je postup přesunutí testování později v procesu DevOps k testování v produkčním prostředí. Testování v produkčním prostředí využívá skutečná nasazení k ověření a měření chování a výkonu aplikace v produkčním prostředí.
Jedním ze způsobů, jak týmy DevOps můžou zvýšit rychlost, je strategie testování vlevo posunu. Posun doleva nasdílí většinu testování dříve v kanálu DevOps, aby zkrátil dobu, po kterou může nový kód dosáhnout produkčního prostředí a spolehlivě pracovat.
Zatímco mnoho druhů testů, jako jsou testy jednotek, se dá snadno posunout doleva, některé třídy testů se nedají spustit bez nasazení části nebo celého řešení. Nasazení do qa nebo přípravné služby může simulovat srovnatelné prostředí, ale neexistuje žádná úplná náhrada produkčního prostředí. Týmy zjistí, že určité typy testování musí proběhnout v produkčním prostředí.
Testování v produkčním prostředí poskytuje:
- Úplná šířka a rozmanitost produkčního prostředí.
- Skutečná úloha provozu zákazníků.
- Profily a chování, jak se poptávka po produkci v průběhu času vyvíjí.
Produkční prostředí se neustále mění. I když se aplikace nezmění, infrastruktura, na které neustále spoléhá, závisí na změnách. Testování v produkčním prostředí ověřuje stav a kvalitu daného produkčního nasazení a neustále se měnícího produkčního prostředí.
Přechod doprava na testování v produkčním prostředí je zvlášť důležitý pro následující scénáře:
Nasazení mikroslužeb
Řešení založená na mikroslužbách můžou mít velký počet mikroslužeb, které se vyvíjejí, nasazují a spravují nezávisle. Posunování testování doprava je zvláště důležité pro tyto projekty, protože různé verze a konfigurace mohou dosáhnout produkčního prostředí mnoha způsoby. Bez ohledu na pokrytí předprodukčního testu je nutné otestovat kompatibilitu v produkčním prostředí.
Zajištění kvality po nasazení
Uvolnění do produkčního prostředí je jen polovina dodávky softwaru. Druhá polovina zajišťuje kvalitu ve velkém s reálným zatížením v produkčním prostředí. Vzhledem k tomu, že se prostředí neustále mění, tým se nikdy neskončí s testováním v produkčním prostředí.
Testovací data z produkčního prostředí jsou doslova výsledky testů ze skutečné úlohy zákazníka. Testování v produkčním prostředí zahrnuje monitorování, testování převzetí služeb při selhání a injektáž chyb. Toto testování sleduje selhání, výjimky, metriky výkonu a události zabezpečení. Testovací telemetrie také pomáhá detekovat anomálie.
Úrovně nasazení
Aby bylo možné chránit produkční prostředí, můžou týmy zavést změny progresivním a řízeným způsobem pomocí nasazení na základě vrstev a příznaků funkcí. Je například lepší zachytit chybu, která brání nakupujícímu v dokončení nákupu, když je na této úrovni nasazení méně než 1% zákazníků, než když přepnete všechny zákazníky najednou. Hodnota funkce se zjištěnými selháními musí překročit čisté ztráty těchto selhání měřené smysluplným způsobem pro danou firmu.
První úroveň by měla být nejmenší velikost potřebná ke spuštění standardní integrační sady. Testy můžou být podobné těm, které už běží dříve v kanálu v jiných prostředích, ale testování ověří, že chování je v produkčním prostředí stejné. Tato úroveň identifikuje zjevné chyby, jako jsou chybné konfigurace, než ovlivní všechny zákazníky.
Po ověření počáteční úrovně může další vrstva rozšířit tak, aby zahrnovala podmnožinu skutečných uživatelů pro testovací běh. Pokud všechno vypadá dobře, může nasazení projít dalšími úrovněmi a testy, dokud ho všichni nepoužívají. Úplné nasazení neznamená, že testování skončilo. Sledování telemetrie je velmi důležité pro testování v produkčním prostředí.
Simulace chyb
Týmy často využívají injektáž chyb a inženýrství chaosu , aby viděly, jak se systém chová za podmínek selhání. Tyto postupy vám pomůžou:
- Ověřte, že implementované mechanismy odolnosti skutečně fungují.
- Ověřte, že selhání v jednom subsystému je obsaženo v tomto subsystému a neprovádí kaskádový výpadek.
- Ověřte, že práce na opravě předchozího incidentu má požadovaný účinek, aniž byste museli čekat na další incident.
- Vytvářejte realističtější postupy trénování pro živé techniky webu, aby se mohli lépe připravit na řešení incidentů.
Je vhodné automatizovat experimenty injektáže chyb, protože jde o nákladné testy, které se musí spouštět na neustále se měnících systémech.
Chaos engineering může být účinný nástroj, ale měl by být omezený na kanárská prostředí , která mají malý nebo žádný dopad na zákazníka.
Testování převzetí služeb při selhání
Jednou z forem injektáže selhání je testování převzetí služeb při selhání , které podporuje provozní kontinuitu a zotavení po havárii (BCDR). Týmy by měly mít plány převzetí služeb při selhání pro všechny služby a subsystémy. Plány by měly zahrnovat:
- Jasné vysvětlení obchodního dopadu služby.
- Mapa všech závislostí z hlediska platforem, technologií a lidí, kteří plán BCDR vymýšlili.
- Formální dokumentace postupů zotavení po havárii
- Četnost pravidelného provádění postupů zotavení po havárii.
Testování chyb jističe
Mechanismus jističe ořízne danou komponentu z většího systému, obvykle aby se zabránilo selháním v dané komponentě, aby se rozprostřela mimo jeho hranice. K otestování následujících scénářů můžete záměrně aktivovat jističe:
Určuje, jestli náhradní zařízení funguje, když se jistič otevře. Náhradní řešení může fungovat s testy jednotek, ale jediný způsob, jak zjistit, jestli se bude chovat podle očekávání v produkčním prostředí, je vložit chybu, která ji aktivuje.
Jestli má jistič správnou prahovou hodnotu citlivosti, která se má otevřít, když je potřeba. Injektáž chyb může vynutit latenci nebo odpojit závislosti, aby bylo možné sledovat odezvu jističe. Je důležité ověřit nejen, že dochází ke správnému chování, ale že k němu dochází dostatečně rychle.
Příklad: Testování jističe mezipaměti Redis
Redis Cache zlepšuje výkon produktů tím, že urychluje přístup k běžně používaným datům. Představte si scénář, který využívá nekritické závislosti na Redisu. Pokud Redis přestane fungovat, měl by systém dál fungovat, protože se může vrátit k použití původního zdroje dat pro požadavky. Pokud chcete ověřit, že selhání Redis aktivuje jistič a že náhradní funkce funguje v produkčním prostředí, pravidelně spouštět testy proti těmto chováním.
Následující diagram znázorňuje testy náhradního chování jističe Redis. Cílem je zajistit, aby se při otevření jističe nakonec volání přešla do SQL.
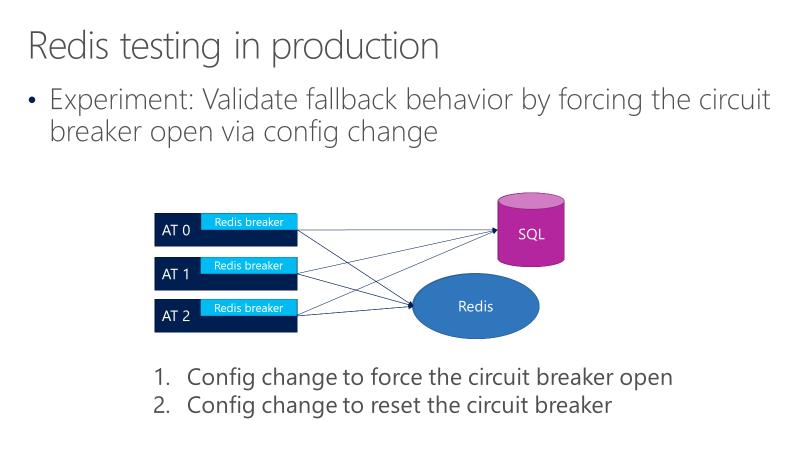
Předchozí diagram znázorňuje tři AT s jističi před voláními Redisu. Jeden test vynutí, aby jistič otevřel prostřednictvím změny konfigurace a pak sleduje, jestli volání přejdou do SQL. Dalším testem pak zkontrolujete opačnou změnu konfigurace tím, že zavřete jistič a ověříte, že se volání vrátí zpět do Redisu.
Tento test ověří, že při otevření jističe funguje záložní chování, ale neověřuje, že konfigurace jističe otevře jistič, když by mělo. Testování takového chování vyžaduje simulaci skutečných selhání.
Agent chyby může při voláních do Redisu zavést chyby. Následující diagram znázorňuje testování pomocí injektáže chyb.
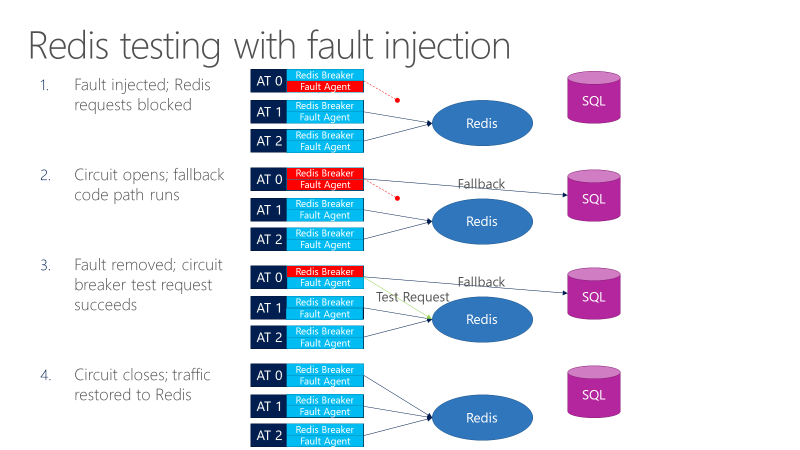
- Injektor selhání blokuje požadavky Redis.
- Otevře se jistič a test může sledovat, jestli funguje náhradní zařízení.
- Chyba se odebere a jistič odešle do Redis testovací požadavek.
- Pokud požadavek proběhne úspěšně, volání se vrátí zpět na Redis.
Další kroky by mohly otestovat citlivost jističe, zda je prahová hodnota příliš vysoká nebo příliš nízká a jestli jiné časové limity systému kolidují s chováním jističe.
Pokud se v tomto příkladu jistič neotevře nebo nezavře podle očekávání, může to způsobit incident živého webu (LSI). Bez testování injektáže chyb může být problém nedetekovaný, protože je těžké tento typ testování provést v testovacím prostředí.
Další kroky
- [Posunutí testování doleva pomocí jednotkových testů]posunout testování doleva
- Co jsou mikroslužby?
- Spuštění testovacího převzetí služeb při selhání (postup zotavení po havárii) do Azure
- Postupy bezpečného nasazení
- Co je monitorování?
- Co je příprava platformy?