Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Návod
Tento obsah je výňatek z elektronické knihy Architektura cloud-native .NET aplikací pro Azure, která je k dispozici na .NET Docs nebo jako bezplatné PDF ke stažení, které si můžete přečíst offline.

Stejně jako byly vyvinuty vzory, které pomáhají při rozložení kódu v aplikacích, existují vzory pro provoz aplikací spolehlivým způsobem. Objevily se tři užitečné vzory při údržbě aplikací: protokolování, monitorování a výstrahy.
Kdy použít zaznamenávání
Bez ohledu na to, jak opatrní jsme, se aplikace téměř vždy chovají neočekávaně v produkčním prostředí. Když uživatelé hlásí problémy s aplikací, je užitečné zjistit, co se s aplikací děje, když k problému došlo. Jedním z nejskutenějších a skutečných způsobů zachycení informací o tom, co aplikace dělá, když je spuštěná, je, aby aplikace zapisuje, co dělá. Tento proces se označuje jako protokolování. Kdykoli dojde k selháním nebo problémům v produkčním prostředí, měl by být cílem reprodukovat podmínky, za kterých došlo k selháním v neprodukčním prostředí. Správné protokolování poskytuje vývojářům plán, jak postupovat, aby mohli duplikovat problémy v prostředí, se kterým je možné testovat a experimentovat.
Problémy při protokolování pomocí aplikací nativních pro cloud
V tradičních aplikacích jsou soubory protokolů obvykle uložené na místním počítači. Ve skutečnosti je v operačních systémech Unix definována struktura složek, která uchovává všechny protokoly, obvykle pod /var/log.
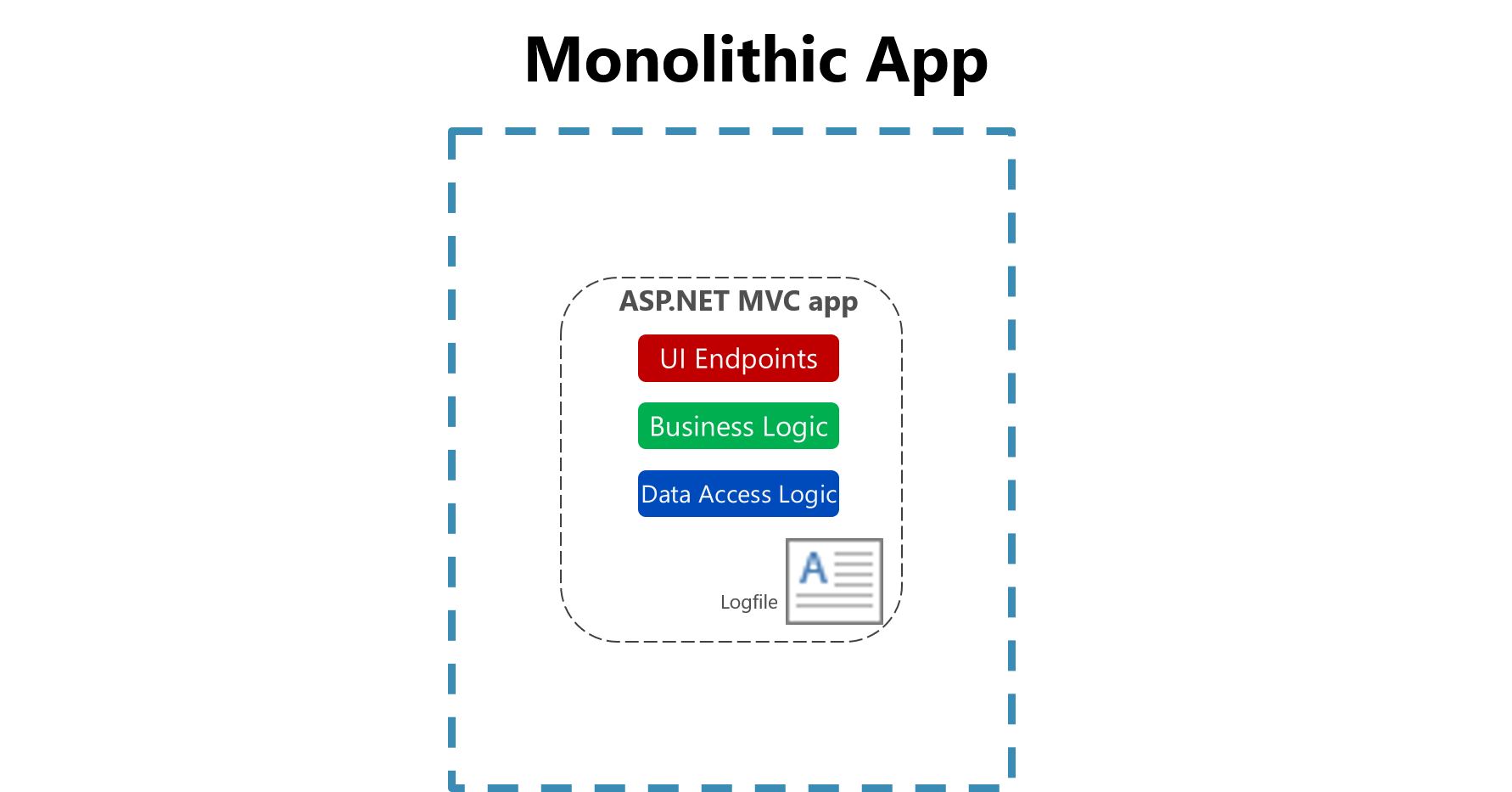 Obrázek 7–1 Protokolování do souboru v monolitické aplikaci
Obrázek 7–1 Protokolování do souboru v monolitické aplikaci
Užitečnost protokolování do plochého souboru na jednom počítači se výrazně snižuje v cloudovém prostředí. Aplikace vytvářející protokoly nemusí mít přístup k místnímu disku nebo místní disk může být vysoce přechodný, protože kontejnery se prohazují kolem fyzických počítačů. I jednoduché škálování monolitických aplikací na více uzlech může ztížit nalezení příslušného souboru s logy.
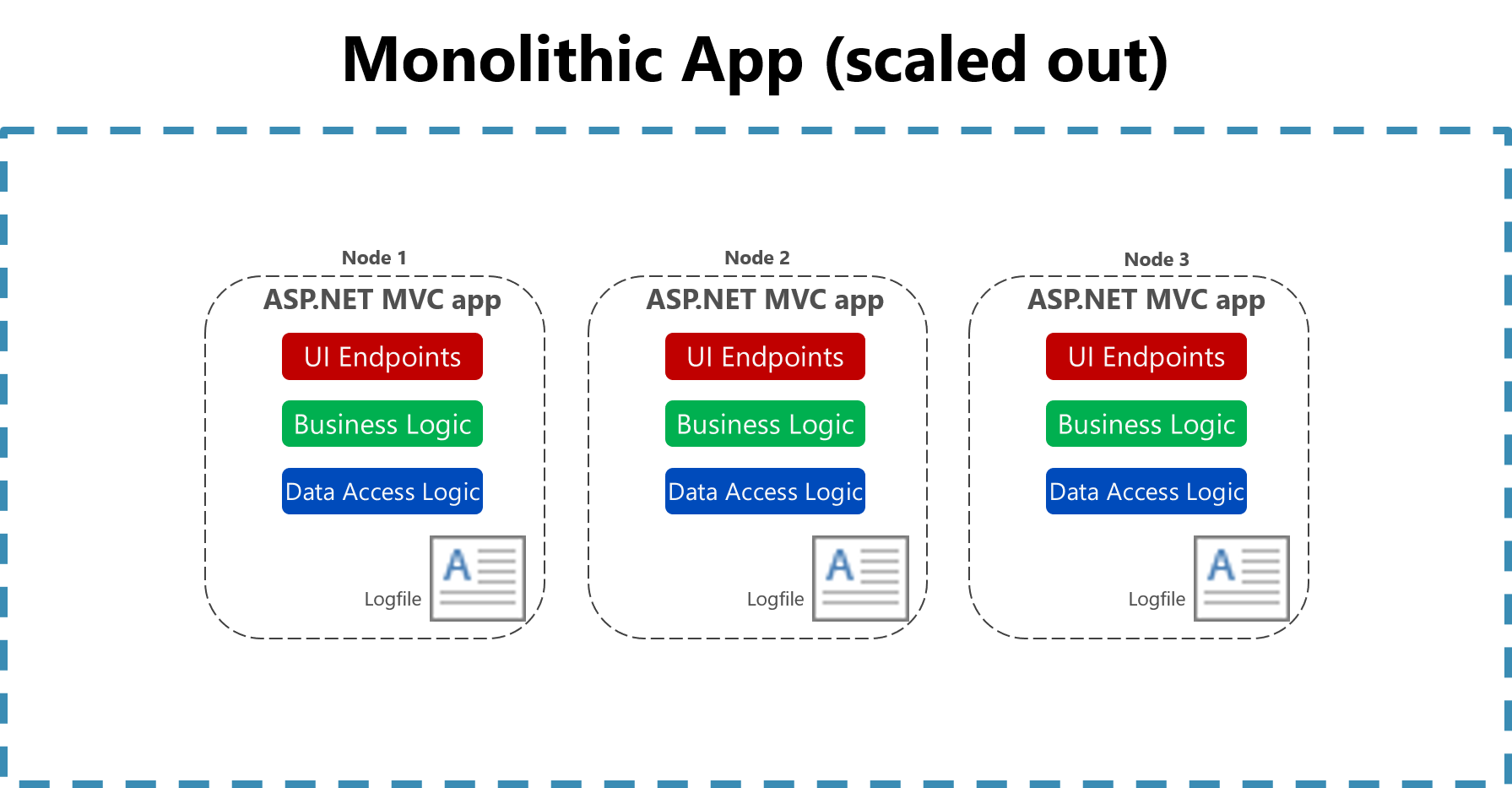 Obrázek 7–2 Protokolování do souborů ve škálované monolitické aplikaci
Obrázek 7–2 Protokolování do souborů ve škálované monolitické aplikaci
Aplikace nativní pro cloud vyvinuté pomocí architektury mikroslužeb také představují některé výzvy pro protokolovací nástroje založené na souborech. Požadavky uživatelů teď můžou zahrnovat více služeb, které běží na různých počítačích, a můžou obsahovat funkce bez serveru bez přístupu k místnímu systému souborů. Bylo by velmi náročné korelovat protokoly od uživatele nebo relace napříč těmito mnoha službami a počítači.
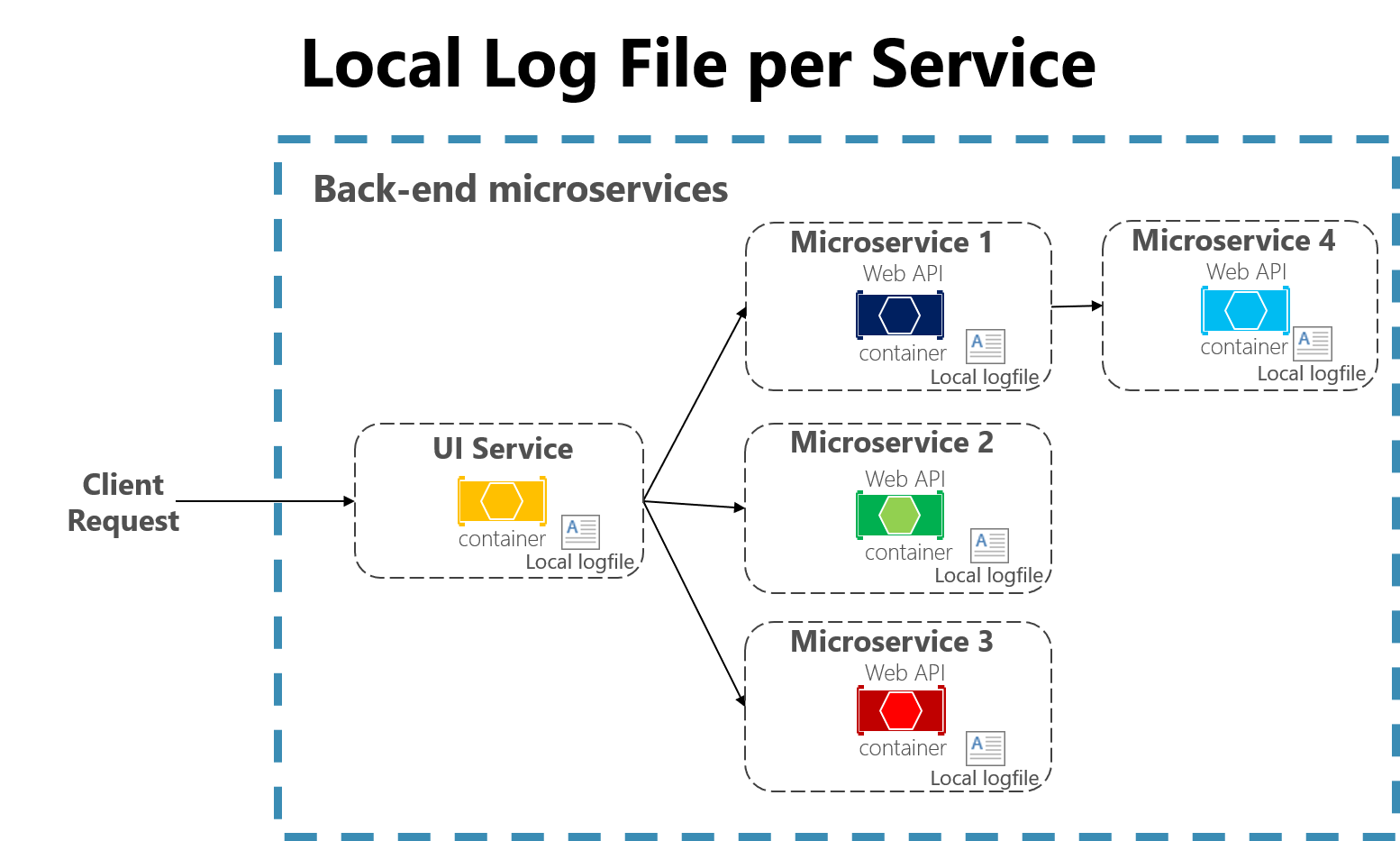 Obrázek 7-3 Zaznamenávání do lokálních souborů v mikroslužební aplikaci.
Obrázek 7-3 Zaznamenávání do lokálních souborů v mikroslužební aplikaci.
Počet uživatelů v některých aplikacích nativních pro cloud je nakonec vysoký. Představte si, že každý uživatel při přihlášení k aplikaci generuje stovky řádků zpráv protokolu. V izolaci je to spravovatelné, ale když to vynásobíme více než 100 000 uživateli, objem protokolů je tak velký, že je potřeba specializovaných nástrojů k podpoře efektivního využívání protokolů.
Protokolování v aplikacích nativních pro cloud
Každý programovací jazyk má nástroje, které umožňují zápis protokolů a obvykle režijní náklady na zápis těchto protokolů jsou nízké. Mnoho knihoven protokolování poskytuje protokolování různých úrovní závažnosti, které lze upravit za běhu. Knihovna Serilog je například oblíbenou knihovnou strukturovaného protokolování pro .NET, která poskytuje následující úrovně protokolování:
- Zdlouhavý
- Ladění
- Informace
- Výstraha
- Chyba
- Fatální
Tyto různé úrovně protokolů poskytují členitost protokolování. Pokud aplikace funguje správně v produkčním prostředí, může být nakonfigurovaná tak, aby protokolovala jenom důležité zprávy. Při nesprávném chování aplikace je možné zvýšit úroveň protokolu, aby se shromáždily více podrobných protokolů. Tím se vyvažuje výkon a snadnost ladění.
Vysoký výkon nástrojů pro protokolování a nastavitelnost podrobnosti by měly vývojáře podporovat, aby často protokolovali. Mnoho dává přednost vzoru protokolování vstupu a ukončení každé metody. Tento přístup může znít jako zbytečný, ale je neobvyklé, že vývojáři budou přát si méně logování. Ve skutečnosti není neobvyklé provádět nasazení pouze za účelem přidání protokolování kolem problematické metody. Přiklánějte se k příliš častému protokolování než k příliš malému. Některé nástroje lze použít k automatickému poskytování tohoto typu protokolování.
Kvůli problémům spojeným s používáním protokolů založených na souborech v aplikacích nativních pro cloud se preferují centralizované protokoly. Protokoly shromažďují aplikace a odesílají se do centrální aplikace protokolování, která protokoly indexuje a ukládá. Tento typ systému může každý den zpracovat desítky gigabajtů logů.
Je také užitečné dodržovat některé standardní postupy při vytváření protokolování, které zahrnuje mnoho služeb. Například generování ID korelace na začátku dlouhé interakce a následné protokolování v každé zprávě, která souvisí s danou interakcí, usnadňuje hledání všech souvisejících zpráv. Stačí najít jenom jednu zprávu a extrahovat ID korelace, aby se našly všechny související zprávy. Dalším příkladem je zajištění, aby byl formát protokolu pro každou službu stejný, ať už používá jazyk nebo knihovnu protokolování. Tato standardizace usnadňuje čtení protokolů. Obrázek 7–4 ukazuje, jak může architektura mikroslužeb využívat centralizované protokolování jako součást pracovního postupu.
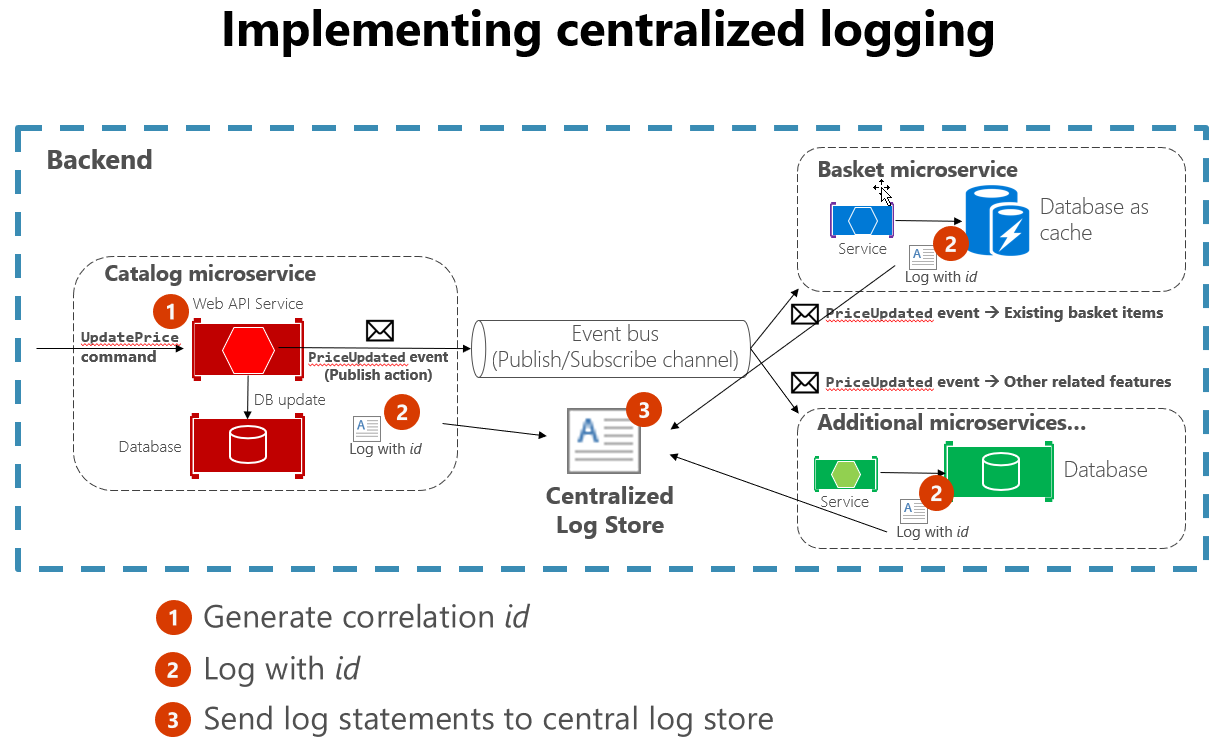 Obrázek 7–4 Protokoly z různých zdrojů se ingestují do centralizovaného úložiště protokolů.
Obrázek 7–4 Protokoly z různých zdrojů se ingestují do centralizovaného úložiště protokolů.
Problémy se zjišťováním a reagováním na potenciální problémy se stavem aplikace
Některé aplikace nejsou klíčové. Možná se používají interně a když dojde k problému, uživatel může kontaktovat zodpovědný tým a aplikaci je možné restartovat. Zákazníci ale často mají vyšší očekávání pro aplikace, které spotřebovávají. Měli byste vědět, kdy u vaší aplikace dojde k problémům, než o nich budou vědět uživatelé nebo než vás upozorní. V opačném případě může být první, co se dozvíte o problému, když si všimnete rozhořčené záplavy příspěvků na sociálních médiích, které zesměšňují vaši aplikaci nebo dokonce vaši organizaci.
Mezi scénáře, které možná budete muset zvážit, patří:
- Jedna služba ve vaší aplikaci neustále selhává a restartuje, což vede k přerušovaným pomalým odpovědím.
- V některých denních časech je doba odezvy vaší aplikace pomalá.
- Po posledním nasazení se zatížení databáze ztrojnásobí.
Správně implementované monitorování vám může dát vědět o podmínkách, které můžou vést k problémům, což vám umožní vyřešit základní podmínky, než způsobí jakýkoli významný dopad na uživatele.
Monitorování aplikací nativních pro cloud
Některé centralizované systémy protokolování přebírají další roli shromažďování telemetrických dat vedle běžných protokolů. Můžou shromažďovat metriky, například čas spuštění databázového dotazu, průměrnou dobu odezvy z webového serveru a dokonce průměrné zatížení procesoru a zatížení paměti, jak hlásí operační systém. Ve spojení s protokoly mohou tyto systémy poskytovat ucelený pohled na stav uzlů v systému a aplikaci jako celek.
Možnosti shromažďování metrik monitorovacích nástrojů lze také ručně předávat z aplikace. Obchodní toky, které jsou obzvláště zajímavé, jako je registrace nových uživatelů nebo zadávání objednávek, mohou být instrumentovány tak, aby inkrementovaly čítač v centrálním monitorovacím systému. Tento aspekt odemyká monitorovací nástroje nejen ke sledování stavu aplikace, ale i ke stavu firmy.
Dotazy je možné vytvořit v nástrojích pro agregaci protokolů a hledat určité statistiky nebo vzory, které se pak dají zobrazit v grafické podobě na vlastních řídicích panelech. Týmy často investují do velkých displejů upevněných na zdi, které otáčejí se statistikami souvisejícími s aplikací. Tímto způsobem je jednoduché vidět problémy, ke kterým dochází.
Nástroje pro monitorování nativní pro cloud poskytují telemetrii a přehled o aplikacích v reálném čase bez ohledu na to, jestli jde o monolitické aplikace s jedním procesem nebo distribuované architektury mikroslužeb. Zahrnují nástroje, které umožňují shromažďování dat z aplikace a také nástroje pro dotazování a zobrazování informací o stavu aplikace.
Problémy s reakcí na kritické problémy v aplikacích nativních pro cloud
Pokud potřebujete reagovat na problémy s aplikací, potřebujete nějaký způsob, jak upozornit správné pracovníky. Jedná se o třetí model pozorovatelnosti aplikací nativní pro cloud a závisí na protokolování a monitorování. Vaše aplikace musí mít zavedené protokolování, aby bylo možné diagnostikovat problémy, a v některých případech je potřeba ho připojit k monitorovacím nástrojům. Potřebuje monitorování pro agregaci metrik aplikací a dat o stavu na jednom místě. Po vytvoření je možné vytvořit pravidla, která aktivují výstrahy, když některé metriky spadají mimo přijatelné úrovně.
Obecně platí, že výstrahy jsou vrstvené nad monitorováním, aby určité podmínky aktivovaly příslušné výstrahy, které upozorní členy týmu na naléhavé problémy. Mezi scénáře, které můžou vyžadovat upozornění, patří:
- Jedna ze služeb vaší aplikace nereaguje po 1 minutě výpadku.
- Vaše aplikace vrací neúspěšné odpovědi HTTP u více než 1% případů požadavků.
- Průměrná doba odezvy vaší aplikace pro hlavní koncové body překračuje 2 000 ms.
Upozornění v aplikacích nativních pro cloud
Můžete vytvářet dotazy na monitorovací nástroje a hledat známé stavy selhání. Dotazy můžou například prohledat příchozí protokoly s informacemi o stavovém kódu HTTP 500, což značí problém na webovém serveru. Jakmile se zjistí některá z těchto možností, může se odeslat e-mail nebo zpráva SMS vlastníkovi původní služby, která může začít zkoumat.
Obvykle ale jedna chyba 500 nestačí k určení, že došlo k problému. Může to znamenat, že uživatel nesprávně zadal heslo nebo zadal nějaká poškozená data. Dotazy na výstrahy je možné vytvořit tak, aby se aktivovaly pouze v případech, kdy se zjistí větší než průměrný počet chyb 500.
Jedním z nejškodivějších vzorců v upozorňování je aktivovat příliš mnoho výstrah, aby lidé mohli vyšetřovat. Vlastníci služeb se rychle stanou necitlivými na chyby, které dříve prošetřili a zjistili, že jsou neškodné. Poté, když dojde ke skutečným chybám, ztratí se v šumu stovek falešných pozitiv. Podobenství chlapce, který volal 'Vlk, vlk' se často vypráví dětem, aby je varovalo před tímto nebezpečím. Je důležité zajistit, aby alarmy, které se aktivují, indikují skutečný problém.
Spolupracujte s námi na GitHubu
Zdroj tohoto obsahu najdete na GitHubu, kde můžete také vytvářet a kontrolovat problémy a žádosti o přijetí změn. Další informace najdete v našem průvodci pro přispěvatele.