Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Návod
Tento obsah je výňatek z eBooku, architektury mikroslužeb .NET pro kontejnerizované aplikace .NET, které jsou k dispozici na .NET Docs nebo jako zdarma ke stažení PDF, které lze číst offline.

V distribuovaných systémech, jako jsou aplikace založené na mikroslužbách, existuje stále přítomné riziko částečného selhání. Například jedna mikroslužba nebo kontejner může selhat nebo nemusí být dostupná pro krátkou dobu, jinak může dojít k chybovému ukončení jednoho virtuálního počítače nebo serveru. Vzhledem k tomu, že klienti a služby jsou samostatné procesy, nemusí služba včas reagovat na žádost klienta. Služba může být přetížená a reaguje velmi pomalu na požadavky nebo může být kvůli problémům se sítí jednoduše nedostupná po krátkou dobu.
Představte si například stránku s podrobnostmi objednávky z ukázkové aplikace eShopOnContainers. Pokud mikroslužba pro objednávání nereaguje, když se uživatel pokusí odeslat objednávku, špatná implementace klientského procesu (webová aplikace MVC) — například použití synchronních RPC volání bez časového limitu — by blokovala vlákna a čekala na odpověď neomezenou dobu. Kromě vytváření špatného uživatelského zážitku každé neodpovídající čekání spotřebovává nebo blokuje vlákna a ta jsou velmi cenná ve vysoce škálovatelných aplikacích. Pokud existuje mnoho blokovaných vláken, může nakonec dojít k výpadku vláken modulu runtime aplikace. V takovém případě se aplikace může stát globálně nereagující místo jen částečně nereagující, jak je znázorněno na obrázku 8-1.
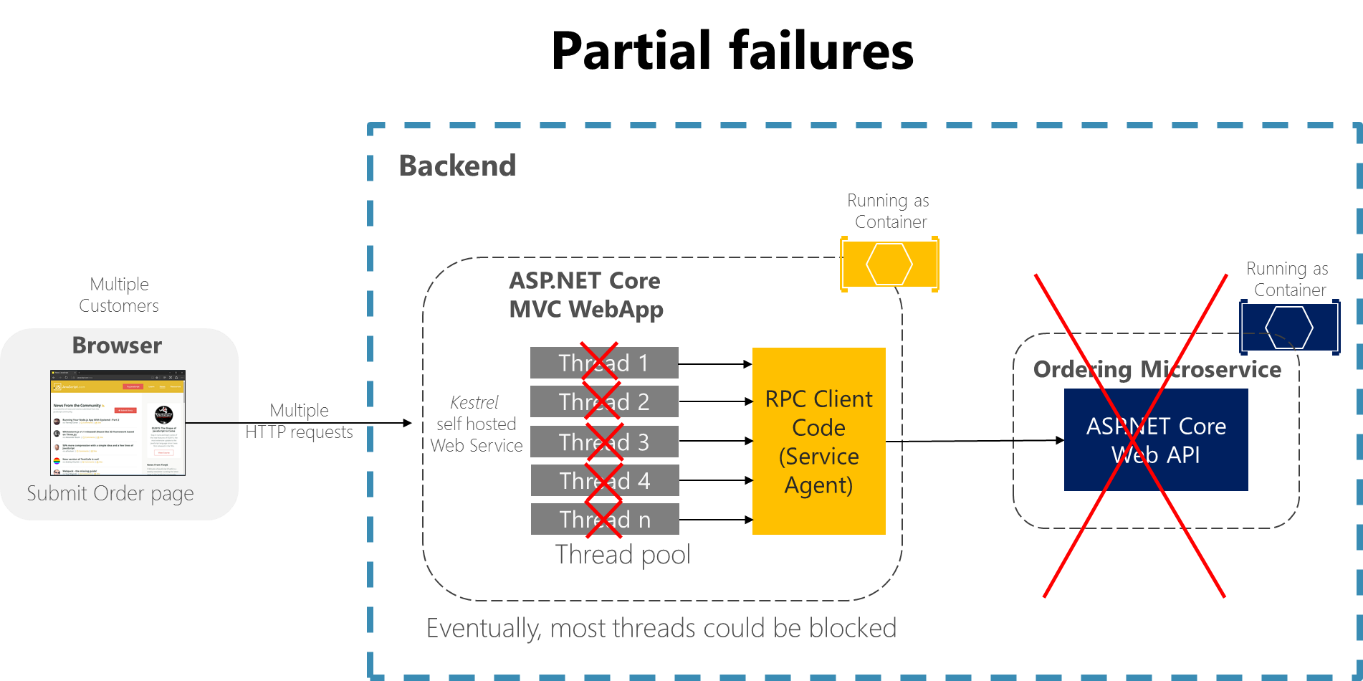
obrázek 8-1. Částečná selhání kvůli závislostem, které mají vliv na dostupnost vlákna služby
Ve velké aplikaci založené na mikroslužbách může být jakékoliv částečné selhání zvětšeno, zejména pokud je většina interakcí interních mikroslužeb založené na synchronním volání HTTP (což se považuje za anti-pattern). Zamyslete se nad systémem, který přijímá miliony příchozích hovorů za den. Pokud má váš systém špatný návrh založený na dlouhých řetězech synchronních volání HTTP, může tato příchozí volání vést k mnoha milionům odchozích volání (předpokládejme, že poměr 1:4) k desítkám interních mikroslužeb jako synchronních závislostí. Tato situace je znázorněna na obrázku 8-2, zejména závislost č. 3, která spouští řetěz, volá závislost č. 4, která pak volá závislost č. 5.
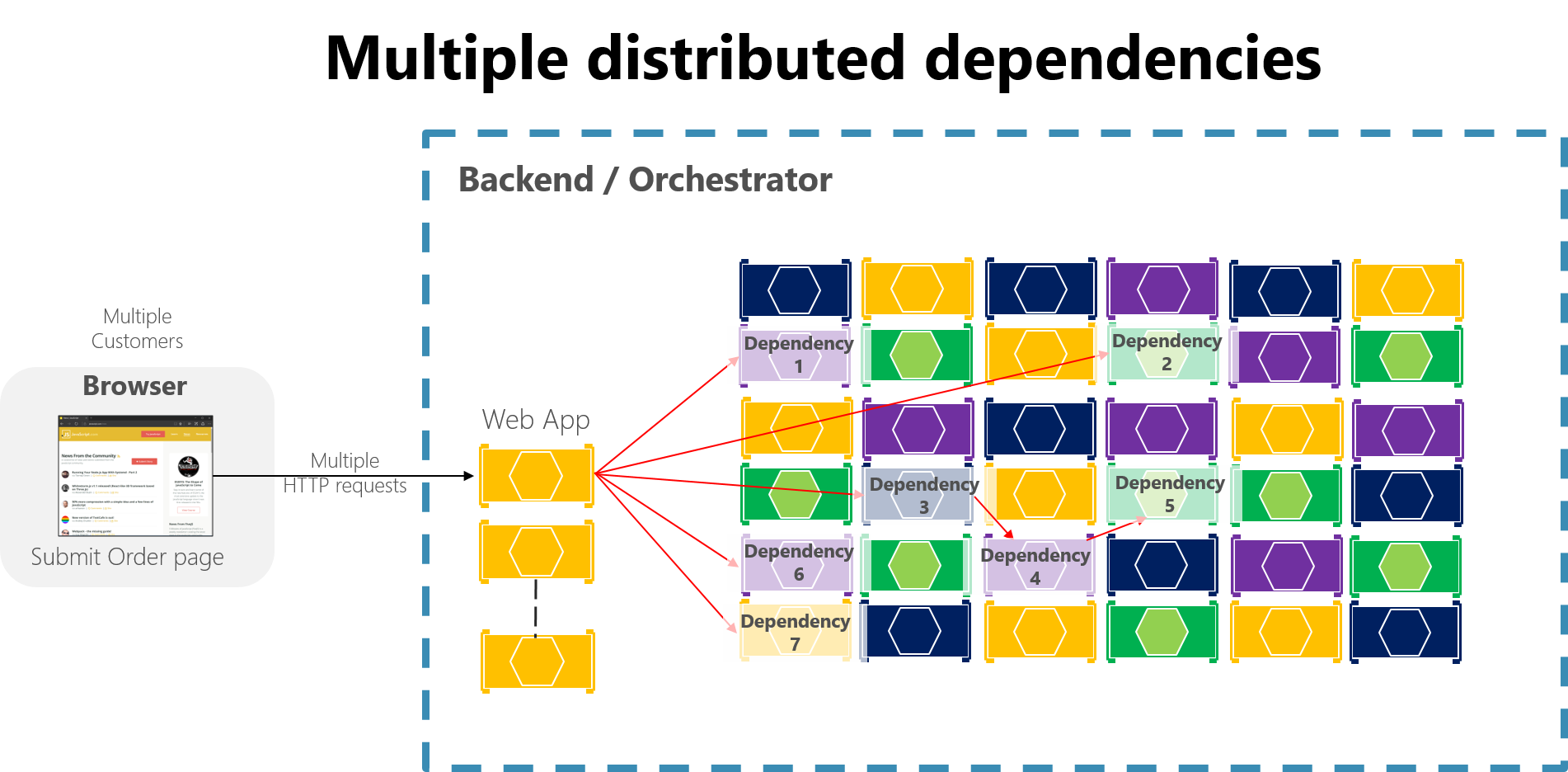
obrázek 8–2. Dopad nesprávného návrhu s dlouhými řetězy požadavků HTTP
Přerušované selhání je zaručeno v distribuovaném a cloudovém systému, i když má každá jednotlivá závislost vynikající dostupnost. Je to fakt, který je potřeba zvážit.
Pokud nenavrhnete a neimplementujete techniky pro zajištění odolnosti proti chybám, i malé výpadky se mohou umocnit. Například 50 závislostí, každá s dostupností 99,99%, by kvůli tomuto vlnovému efektu vedlo k několika hodinám výpadků každý měsíc. Pokud závislost mikroslužby selže při zpracování velkého objemu požadavků, může toto selhání rychle nasytit všechna dostupná vlákna požadavků v každé službě a zhroutí celou aplikaci.
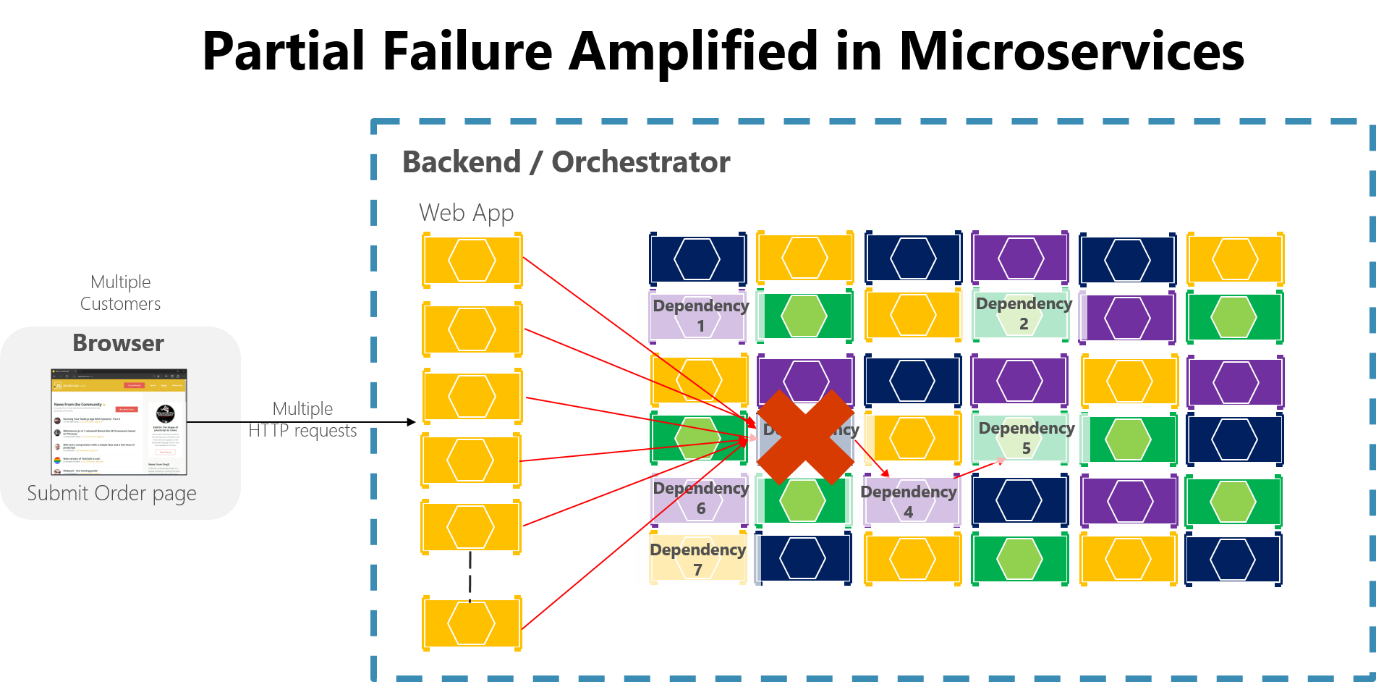
Obrázek 8-3 Částečné selhání amplifikované mikroslužbami s dlouhými řetězy synchronních volání HTTP
Pokud chcete tento problém minimalizovat, v části Asynchronní integrace mikroslužeb vynucuje autonomii mikroslužeb, tato příručka vás vyzývá k použití asynchronní komunikace mezi interními mikroslužbami.
Kromě toho je nezbytné navrhnout mikroslužby a klientské aplikace tak, aby zvládly částečné selhání – to znamená k vytváření odolných mikroslužeb a klientských aplikací.
Spolupracujte s námi na GitHubu
Zdroj tohoto obsahu najdete na GitHubu, kde můžete také vytvářet a kontrolovat problémy a žádosti o přijetí změn. Další informace najdete v našem průvodci pro přispěvatele.