Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Naučte se používat předem natrénovaný model ONNX v ML.NET k detekci objektů v obrázcích.
Trénování modelu detekce objektů od začátku vyžaduje nastavení milionů parametrů, velké množství trénovacích dat s popiskem a obrovské množství výpočetních prostředků (stovky hodin GPU). Použití natrénovaného předem modelu vám umožní zkrátit proces trénování.
V tomto návodu se naučíte, jak:
- Pochopení problému
- Zjistěte, co je ONNX a jak funguje s ML.NET
- Vysvětlení modelu
- Opakované použití předtrénovaného modelu
- Detekce objektů s načteným modelem
Požadavky
- Visual Studio 2022 nebo novější
- balíček NuGet Microsoft.ML
- Balíček NuGet Microsoft.ML.ImageAnalytics
- Balíček NuGet Microsoft.ML.OnnxTransformer
- Malý předtrénovaný model YOLOv2
- Netron (volitelné)
Přehled ukázky detekce objektů ONNX
Tato ukázka vytvoří konzolovou aplikaci .NET Core, která pomocí předem natrénovaného modelu ONNX detekuje objekty v rámci image. Kód pro tuto ukázku najdete v úložišti dotnet/machinelearning-samples na GitHubu.
Co je detekce objektů?
Rozpoznávání objektů je problém počítačového zpracování obrazu. Zatímco úzce souvisí s klasifikací obrázků, detekce objektů provádí klasifikaci obrázků v podrobnějším měřítku. Rozpoznávání objektů vyhledá i kategorizuje entity v obrázcích. Modely rozpoznávání objektů se běžně trénují pomocí hlubokého učení a neurálních sítí. Další informace najdete v tématu Hluboké učení a strojové učení .
Rozpoznávání objektů použijte, když obrázky obsahují více objektů různých typů.

Mezi případy použití detekce objektů patří:
- Autonomní vozidla
- Robotika
- Rozpoznávání tváře
- Zabezpečení pracoviště
- Počítání objektů
- Rozpoznávání aktivit
Výběr modelu hlubokého učení
Hluboké učení je podmnožinou strojového učení. K trénování modelů hlubokého učení se vyžaduje velké množství dat. Vzory v datech jsou reprezentovány řadou vrstev. Relace v datech jsou zakódovány jako propojení mezi vrstvami obsahujícími váhy. Čím vyšší je váha, tím silnější je vztah. Souhrnně se tato řada vrstev a spojení označuje jako umělé neurální sítě. Čím více vrstev v síti, tím "hlubší" je, že se jedná o hlubokou neurální síť.
Existují různé typy neurálních sítí, nejběžnější je vícevrstvý perceptron (MLP), konvoluční neurální síť (CNN) a rekurentní neurální síť (RNN). Nejzásadnější je MLP, který mapuje sadu vstupů na sadu výstupů. Tato neurální síť je dobrá, pokud data nemají prostorovou nebo časovou komponentu. Síť CNN využívá konvoluční vrstvy ke zpracování prostorových informací obsažených v datech. Dobrým případem použití sítí CNN je zpracování obrázků, aby bylo možné zjistit přítomnost funkce v oblasti obrázku (například je uprostřed obrázku nos?). Sítě RNN nakonec umožňují používat jako vstup trvalost stavu nebo paměti. Sítě RNN se používají pro analýzu časových řad, kde je důležité sekvenční řazení a kontext událostí.
Vysvětlení modelu
Rozpoznávání objektů je úloha zpracování obrázků. Proto většina modelů hlubokého učení natrénovaných k vyřešení tohoto problému jsou sítě CNN. Model použitý v tomto kurzu je model Tiny YOLOv2, kompaktnější verze modelu YOLOv2 popsané v dokumentu: "YOLO9000: Better, Faster, Stronger" od Redmon a Farhadi. Tiny YOLOv2 je trénován na datové sadě Pascal VOC a skládá se z 15 vrstev, které mohou předpovědět 20 různých tříd objektů. Vzhledem k tomu, že Tiny YOLOv2 je zhuštěná verze původního modelu YOLOv2, je kompromis mezi rychlostí a přesností. Různé vrstvy, které tvoří model, je možné vizualizovat pomocí nástrojů, jako je Netron. Při kontrole modelu by se zobrazilo mapování propojení mezi všemi vrstvami, které tvoří neurální síť, kde by každá vrstva obsahovala název vrstvy spolu s dimenzemi příslušného vstupu a výstupu. Datové struktury používané k popisu vstupů a výstupů modelu se označují jako tensory. Tensors lze považovat za kontejnery, které ukládají data v N dimenzích. V případě Tiny YOLOv2 je název vstupní vrstvy image a očekává tensor dimenzí 3 x 416 x 416. Název výstupní vrstvy je grid a generuje výstupní tensor dimenzí 125 x 13 x 13.
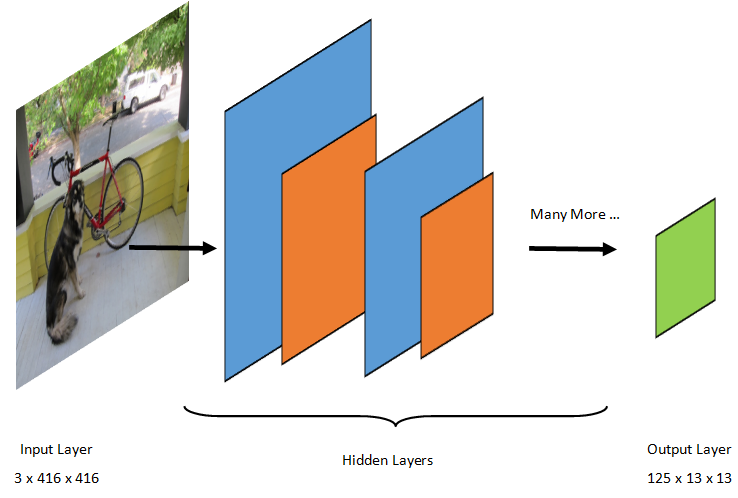
Model YOLO vezme obrázek 3(RGB) x 416px x 416px. Model vezme tento vstup a předá ho různými vrstvami, aby vytvořil výstup. Výstup rozdělí vstupní obrázek do 13 x 13 mřížky, přičemž každá buňka v mřížce se skládá z 125 hodnot.
Co je model ONNX?
Open Neural Network Exchange (ONNX) je open source formát pro modely AI. ONNX podporuje interoperabilitu mezi architekturami. To znamená, že model můžete trénovat v některé z mnoha oblíbených architektur strojového učení, jako je PyTorch, převést ho na formát ONNX a využívat model ONNX v jiné rozhraní, jako je ML.NET. Další informace najdete na webu ONNX.

Předem natrénovaný model Tiny YOLOv2 je uložen ve formátu ONNX, serializované znázornění vrstev a naučených vzorů těchto vrstev. V ML.NET se interoperabilita s ONNX dosahuje prostřednictvím balíčků NuGet ImageAnalytics a OnnxTransformer. Balíček ImageAnalytics obsahuje řadu transformací, které převezmou obrázek a zakódují ho do číselných hodnot, které lze použít jako vstup do prediktivního nebo trénovacího kanálu. Balíček OnnxTransformer využívá modul runtime ONNX k načtení modelu ONNX a jeho použití k vytváření předpovědí na základě zadaného vstupu.
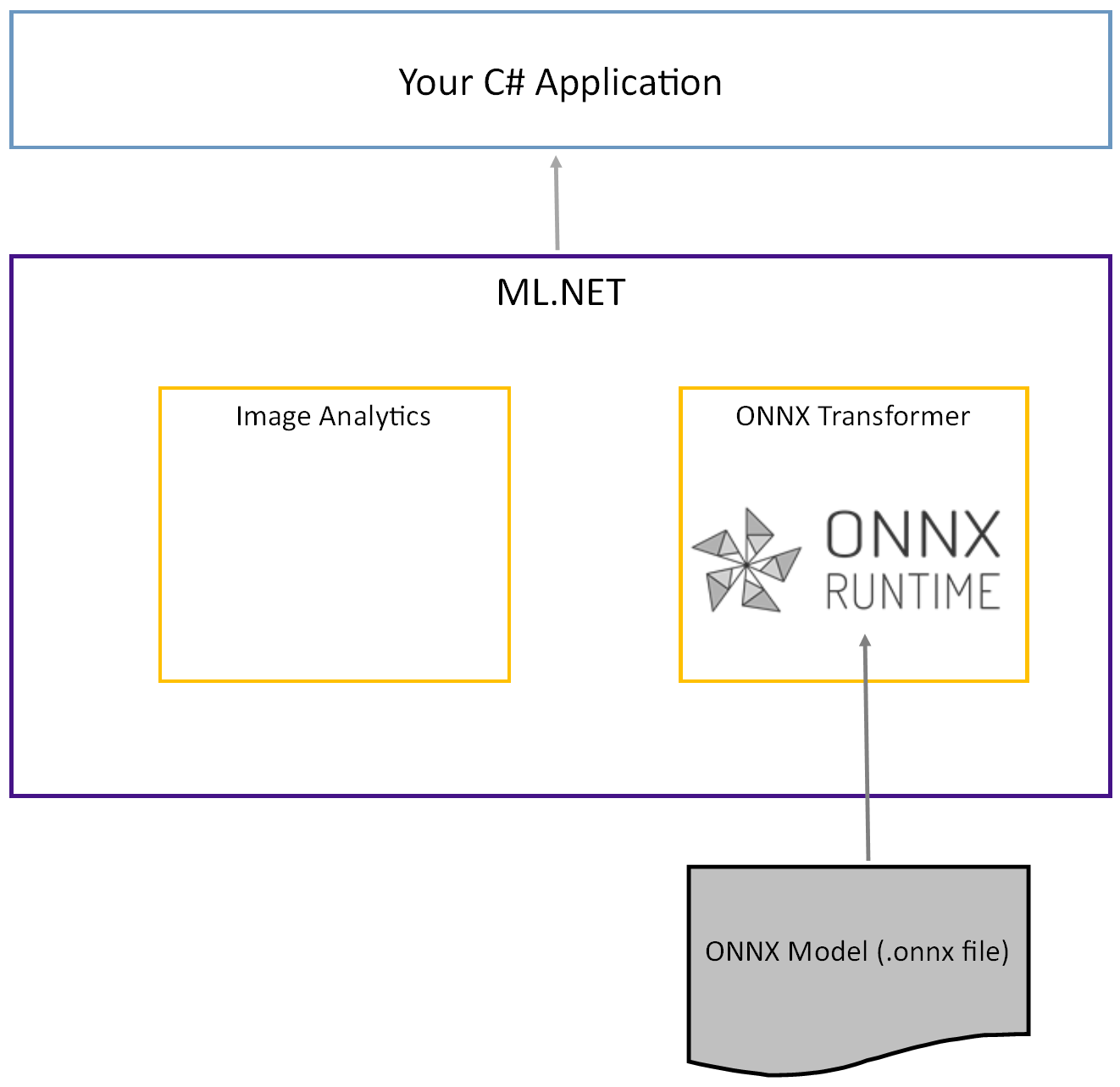
Nastavení projektu konzoly .NET
Teď, když máte obecný přehled o tom, co je ONNX a jak Tiny YOLOv2 funguje, je čas sestavit aplikaci.
Vytvoření konzolové aplikace
Vytvořte konzolovou aplikaci jazyka C# s názvem ObjectDetection. Klikněte na tlačítko Next.
Jako architekturu, která se má použít, zvolte .NET 8. Klikněte na tlačítko Vytvořit.
Nainstalujte balíček NuGet Microsoft.ML:
Poznámka:
Tato ukázka používá nejnovější stabilní verzi uvedených balíčků NuGet, pokud není uvedeno jinak.
- V Průzkumníku řešení klikněte pravým tlačítkem na projekt a vyberte Spravovat balíčky NuGet.
- Jako zdroj balíčku zvolte "nuget.org", vyberte kartu Procházet a vyhledejte Microsoft.ML.
- Vyberte tlačítko Instalovat.
- V dialogovém okně Náhled změn vyberte tlačítko OK a pak v dialogovém okně Přijetí licence vyberte tlačítko Přijmout, pokud souhlasíte s licenčními podmínkami pro uvedené balíčky.
- Opakujte tyto kroky pro Microsoft.Windows.Compatibility, Microsoft.ML.ImageAnalytics, Microsoft.ML.OnnxTransformer a Microsoft.ML.OnnxRuntime.
Příprava dat a předem natrénovaného modelu
Stáhněte soubor ZIP adresáře prostředků projektu a rozbalte ho.
assetsZkopírujte adresář do adresáře projektu ObjectDetection. Tento adresář a jeho podadresáře obsahují soubory obrázků (s výjimkou modelu Tiny YOLOv2, který si stáhnete a přidáte v dalším kroku) potřebný pro tento kurz.Stáhněte si model Tiny YOLOv2 z modelové zoo ONNX.
model.onnxZkopírujte soubor do adresáře projektuassets\Modela přejmenujte ho naTinyYolo2_model.onnx. Tento adresář obsahuje model potřebný pro tento kurz.V Průzkumníku řešení klikněte pravým tlačítkem na všechny soubory v adresáři prostředků a podadresářích a vyberte Vlastnosti. V části Upřesnit změňte hodnotu „Kopírovat do výstupního adresáře“ na „Kopírovat, pokud je novější“.
Vytváření tříd a definování cest
Otevřete soubor Program.cs a na začátek souboru přidejte následující další using direktivy:
using System.Drawing;
using System.Drawing.Drawing2D;
using ObjectDetection.YoloParser;
using ObjectDetection.DataStructures;
using ObjectDetection;
using Microsoft.ML;
Dále definujte cesty různých prostředků.
Nejprve vytvořte metodu
GetAbsolutePathv dolní části souboru Program.cs .string GetAbsolutePath(string relativePath) { FileInfo _dataRoot = new FileInfo(typeof(Program).Assembly.Location); string assemblyFolderPath = _dataRoot.Directory.FullName; string fullPath = Path.Combine(assemblyFolderPath, relativePath); return fullPath; }Pak pod direktivami
usingvytvořte pole pro uložení umístění vašich prostředků.var assetsRelativePath = @"../../../assets"; string assetsPath = GetAbsolutePath(assetsRelativePath); var modelFilePath = Path.Combine(assetsPath, "Model", "TinyYolo2_model.onnx"); var imagesFolder = Path.Combine(assetsPath, "images"); var outputFolder = Path.Combine(assetsPath, "images", "output");
Přidejte do projektu nový adresář pro ukládání vstupních dat a tříd predikcí.
V Průzkumníku řešení klikněte pravým tlačítkem myši na projekt a pak vyberte Přidat>novou složku. Když se nová složka zobrazí v Průzkumníku řešení, pojmenujte ji "Datové struktury".
Vytvořte vstupní třídu dat v nově vytvořeném adresáři DataStructures .
V Průzkumníku řešení klikněte pravým tlačítkem na adresář Datové struktury a pak vyberte Přidat>novou položku.
V dialogovém okně Přidat novou položku vyberte Třída a změňte pole Název na ImageNetData.cs. Pak vyberte Přidat.
Soubor ImageNetData.cs se otevře v editoru kódu. Na začátek
usingpřidejte následující direktivu:using System.Collections.Generic; using System.IO; using System.Linq; using Microsoft.ML.Data;Odeberte existující definici třídy a do
ImageNetDatapřidejte následující kód třídy:public class ImageNetData { [LoadColumn(0)] public string ImagePath; [LoadColumn(1)] public string Label; public static IEnumerable<ImageNetData> ReadFromFile(string imageFolder) { return Directory .GetFiles(imageFolder) .Where(filePath => Path.GetExtension(filePath) != ".md") .Select(filePath => new ImageNetData { ImagePath = filePath, Label = Path.GetFileName(filePath) }); } }ImageNetDataje vstupní třída dat obrázku a má následující String pole:-
ImagePathobsahuje cestu, kde je obrázek uložen. -
Labelobsahuje název souboru.
Kromě toho obsahuje metodu
ImageNetData,ReadFromFilekterá načte více souborů obrázků uloženýchimageFolderv zadané cestě a vrací je jako kolekciImageNetDataobjektů.-
Vytvořte prediktivní třídu v adresáři DataStructures .
V Průzkumníku řešení klikněte pravým tlačítkem na adresář Datové struktury a pak vyberte Přidat>novou položku.
V dialogovém okně Přidat novou položku vyberte Třída a změňte pole Název na ImageNetPrediction.cs. Pak vyberte Přidat.
Soubor ImageNetPrediction.cs se otevře v editoru kódu. Na začátek
usingpřidejte následující direktivu:using Microsoft.ML.Data;Odeberte existující definici třídy a přidejte do
ImageNetPredictionnásledující kód pro třídu:public class ImageNetPrediction { [ColumnName("grid")] public float[] PredictedLabels; }ImageNetPredictionje třída dat předpovědi a má následujícífloat[]pole:-
PredictedLabelsobsahuje rozměry, skóre objektu a pravděpodobnosti tříd pro každou ohraničující rámečky rozpoznané na obrázku.
-
Inicializujte proměnné
MLContext třída je výchozím bodem pro všechny operace ML.NET a inicializace mlContext vytvoří nové ML.NET prostředí, které lze sdílet napříč objekty pracovního postupu vytváření modelu. Je to podobné, koncepčně, jako DBContext v Entity Frameworku.
Inicializace mlContext proměnné s novou instancí MLContext přidáním následujícího řádku pod outputFolder pole.
MLContext mlContext = new MLContext();
Vytvoření analyzátoru pro výstupy modelu po zpracování
Model segmentuje obrázek do 13 x 13 mřížky, kde je 32px x 32pxkaždá buňka mřížky . Každá buňka mřížky obsahuje 5 potenciálních ohraničovacích rámečků objektů. Ohraničující rámeček má 25 prvků:
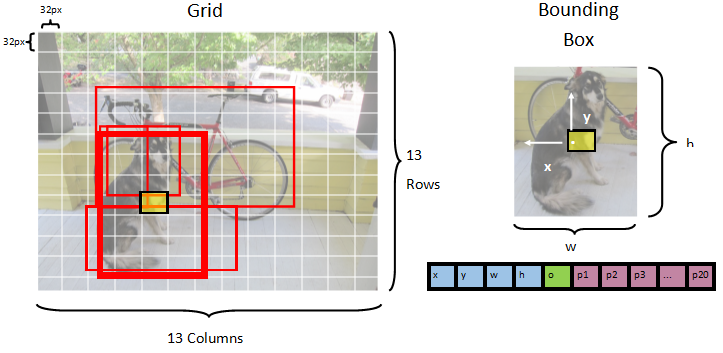
-
xx pozice středu ohraničujícího rámečku vzhledem k buňce mřížky, s níž je spojena. -
yy pozice středu ohraničujícího rámečku vzhledem k buňce mřížky, se kterou je spojen. -
wšířka ohraničujícího rámečku. -
hvýška ohraničujícího rámečku. -
ohodnota spolehlivosti existence objektu v ohraničujícím rámečku, označovaná také jako skóre objektnosti. -
p1-p20pravděpodobnosti třídy pro každou z 20 tříd predikovaných modelem.
Celkem 25 prvků popisujících každou z 5 ohraničujících polí tvoří 125 prvků obsažených v každé buňce mřížky.
Výstup vygenerovaný předem natrénovaným modelem ONNX je pole s plovoucí délkou 21125, představující prvky tensoru s rozměry 125 x 13 x 13. Aby bylo možné transformovat předpovědi vygenerované modelem na tensor, je vyžadována nějaká práce po zpracování. Uděláte to tak, že vytvoříte sadu tříd, které vám pomůžou analyzovat výstup.
Přidejte do projektu nový adresář pro uspořádání sady tříd analyzátoru.
- V Průzkumníku řešení klikněte pravým tlačítkem myši na projekt a pak vyberte Přidat>novou složku. Když se nová složka zobrazí v Průzkumníku řešení, pojmenujte ji YoloParser.
Vytvoření ohraničujících polí a dimenzí
Výstup dat modelu obsahuje souřadnice a rozměry ohraničujících rámečků objektů v rámci obrázku. Vytvořte základní třídu pro dimenze.
V Průzkumníku řešení klikněte pravým tlačítkem myši na adresář YoloParser a pak vyberte Přidat>novou položku.
V dialogovém okně Přidat novou položku vyberte Třída a změňte pole Název na DimensionsBase.cs. Pak vyberte Přidat.
Soubor DimensionsBase.cs se otevře v editoru kódu. Odeberte všechny
usingdirektivy a existující definici třídy.Do souboru
DimensionsBasepřidejte následující kód třídy:public class DimensionsBase { public float X { get; set; } public float Y { get; set; } public float Height { get; set; } public float Width { get; set; } }DimensionsBasemá následujícífloatvlastnosti:-
Xobsahuje pozici objektu podél osy x. -
Yobsahuje pozici objektu podél osy y. -
Heightobsahuje výšku objektu. -
Widthobsahuje šířku objektu.
-
Dále vytvořte třídu pro ohraničující rámečky.
V Průzkumníku řešení klikněte pravým tlačítkem myši na adresář YoloParser a pak vyberte Přidat>novou položku.
V dialogovém okně Přidat novou položku vyberte Třída a změňte pole Název na YoloBoundingBox.cs. Pak vyberte Přidat.
Soubor YoloBoundingBox.cs se otevře v editoru kódu. Na začátek
usingpřidejte následující direktivu:using System.Drawing;Přímo nad existující definici třídy přidejte novou definici třídy,
BoundingBoxDimensionskterá dědí zDimensionsBasetřídy tak, aby obsahovala rozměry příslušného ohraničujícího rámečku.public class BoundingBoxDimensions : DimensionsBase { }Odeberte existující
YoloBoundingBoxdefinici třídy a doYoloBoundingBoxpřidejte následující kód pro třídu:public class YoloBoundingBox { public BoundingBoxDimensions Dimensions { get; set; } public string Label { get; set; } public float Confidence { get; set; } public RectangleF Rect { get { return new RectangleF(Dimensions.X, Dimensions.Y, Dimensions.Width, Dimensions.Height); } } public Color BoxColor { get; set; } }YoloBoundingBoxmá následující vlastnosti:-
Dimensionsobsahuje rozměry ohraničujícího rámečku. -
Labelobsahuje třídu objektu rozpoznaného v ohraničujícím rámečku. -
Confidenceobsahuje jistotu třídy. -
Rectobsahuje obdélníkové znázornění rozměrů ohraničujícího rámečku. -
BoxColorobsahuje barvu přidruženou k příslušné třídě použité k kreslení na obrázku.
-
Vytvoření analyzátoru
Teď, když jsou vytvořeny třídy pro dimenze a ohraničující rámečky, je čas vytvořit analyzátor.
V Průzkumníku řešení klikněte pravým tlačítkem myši na adresář YoloParser a pak vyberte Přidat>novou položku.
V dialogovém okně Přidat novou položku vyberte Třída a změňte pole Název na YoloOutputParser.cs. Pak vyberte Přidat.
Soubor YoloOutputParser.cs se otevře v editoru kódu. Na začátek
usingpřidejte následující direktivy:using System; using System.Collections.Generic; using System.Drawing; using System.Linq;Uvnitř existující
YoloOutputParserdefinice třídy přidejte vnořenou třídu, která obsahuje rozměry jednotlivých buněk na obrázku. Přidejte následující kód proCellDimensionstřídu, která dědí zDimensionsBasetřídy v horní částiYoloOutputParserdefinice třídy.class CellDimensions : DimensionsBase { }YoloOutputParserDo definice třídy přidejte následující konstanty a pole.public const int ROW_COUNT = 13; public const int COL_COUNT = 13; public const int CHANNEL_COUNT = 125; public const int BOXES_PER_CELL = 5; public const int BOX_INFO_FEATURE_COUNT = 5; public const int CLASS_COUNT = 20; public const float CELL_WIDTH = 32; public const float CELL_HEIGHT = 32; private int channelStride = ROW_COUNT * COL_COUNT;-
ROW_COUNTje počet řádků v mřížce, do které je obrázek rozdělený. -
COL_COUNTje počet sloupců v mřížce, do kterých je obrázek rozdělen. -
CHANNEL_COUNTje celkový počet hodnot obsažených v jedné buňce mřížky. -
BOXES_PER_CELLje počet ohraničujících boxů v buňce, -
BOX_INFO_FEATURE_COUNTje počet funkcí obsažených v rámečku (x,y, výška, šířka, spolehlivost). -
CLASS_COUNTje počet predikcí tříd obsažených v každém ohraničujícím rámečku. -
CELL_WIDTHje šířka jedné buňky v mřížce obrázku. -
CELL_HEIGHTje výška jedné buňky v mřížce obrázku. -
channelStrideje počáteční pozice aktuální buňky v mřížce.
Když model vytvoří předpověď, označovanou také jako bodování, rozdělí
416px x 416pxvstupní obrázek na mřížku buněk o velikosti13 x 13. Každá buňka obsahuje .32px x 32pxV každé buňce je 5 ohraničujících boxů, z nichž každý obsahuje 5 vlastností (x, y, šířka, výška, spolehlivost). Kromě toho každý ohraničující rámeček obsahuje pravděpodobnost každé třídy, která v tomto případě je 20. Proto každá buňka obsahuje 125 informací (5 funkcí + 20 pravděpodobností třídy).-
Vytvořte seznam ukotvení níže channelStride pro 5 ohraničujících polí:
private float[] anchors = new float[]
{
1.08F, 1.19F, 3.42F, 4.41F, 6.63F, 11.38F, 9.42F, 5.11F, 16.62F, 10.52F
};
Kotvy jsou předdefinované poměry výšky a šířky ohraničujících polí. Většina objektů nebo tříd zjištěných modelem má podobné poměry. To je cenné, pokud jde o vytváření ohraničujících boxů. Místo predikce ohraničujících rámečků se vypočítá posun od předdefinovaných dimenzí, čímž se sníží potřeba výpočtů k predikci ohraničujícího rámečku. Obvykle se tyto poměry ukotvení počítají na základě použité datové sady. V tomto případě, protože datová sada je známá a hodnoty byly předem vypočítány, mohou být ukotvení pevně zakódována.
Dále definujte popisky nebo třídy, které model predikuje. Tento model předpovídá 20 tříd, což je podmnožina celkového počtu tříd předpovídaných původním modelem YOLOv2.
Přidejte seznam popisků pod .anchors
private string[] labels = new string[]
{
"aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow",
"diningtable", "dog", "horse", "motorbike", "person",
"pottedplant", "sheep", "sofa", "train", "tvmonitor"
};
K jednotlivým třídám jsou přidruženy barvy. Přiřaďte své barvy předmětu pod:labels
private static Color[] classColors = new Color[]
{
Color.Khaki,
Color.Fuchsia,
Color.Silver,
Color.RoyalBlue,
Color.Green,
Color.DarkOrange,
Color.Purple,
Color.Gold,
Color.Red,
Color.Aquamarine,
Color.Lime,
Color.AliceBlue,
Color.Sienna,
Color.Orchid,
Color.Tan,
Color.LightPink,
Color.Yellow,
Color.HotPink,
Color.OliveDrab,
Color.SandyBrown,
Color.DarkTurquoise
};
Vytváření pomocných funkcí
Fáze následného zpracování zahrnuje řadu kroků. K tomu lze použít několik pomocných metod.
Pomocné metody používané analyzátorem jsou:
-
Sigmoidpoužije funkci sigmoid, která vypíše číslo od 0 do 1. -
Softmaxnormalizuje vstupní vektor do rozdělení pravděpodobnosti. -
GetOffsetmapuje prvky ve výstupu jednorozměrného modelu na odpovídající pozici v tensoru125 x 13 x 13. -
ExtractBoundingBoxesextrahuje rozměry ohraničujícího boxu pomocí metodyGetOffsetz výstupu modelu. -
GetConfidenceextrahuje hodnotu spolehlivosti, která uvádí, že model zjistil objekt a pomocí funkce hoSigmoidpřevede na procento. -
MapBoundingBoxToCellpoužívá ohraničující rozměry rámečku a mapuje je na příslušnou buňku v obrázku. -
ExtractClassesextrahuje predikce třídy pro ohraničující rámeček z výstupu modelu pomocíGetOffsetmetody a pomocí metody je převede na rozděleníSoftmaxpravděpodobnosti. -
GetTopResultvybere třídu ze seznamu predikovaných tříd s nejvyšší pravděpodobností. -
IntersectionOverUnionfiltruje překrývající se ohraničující rámečky s nižší pravděpodobností.
Přidejte kód pro všechny pomocné metody pod seznamem classColors.
private float Sigmoid(float value)
{
var k = (float)Math.Exp(value);
return k / (1.0f + k);
}
private float[] Softmax(float[] values)
{
var maxVal = values.Max();
var exp = values.Select(v => Math.Exp(v - maxVal));
var sumExp = exp.Sum();
return exp.Select(v => (float)(v / sumExp)).ToArray();
}
private int GetOffset(int x, int y, int channel)
{
// YOLO outputs a tensor that has a shape of 125x13x13, which
// WinML flattens into a 1D array. To access a specific channel
// for a given (x,y) cell position, we need to calculate an offset
// into the array
return (channel * this.channelStride) + (y * COL_COUNT) + x;
}
private BoundingBoxDimensions ExtractBoundingBoxDimensions(float[] modelOutput, int x, int y, int channel)
{
return new BoundingBoxDimensions
{
X = modelOutput[GetOffset(x, y, channel)],
Y = modelOutput[GetOffset(x, y, channel + 1)],
Width = modelOutput[GetOffset(x, y, channel + 2)],
Height = modelOutput[GetOffset(x, y, channel + 3)]
};
}
private float GetConfidence(float[] modelOutput, int x, int y, int channel)
{
return Sigmoid(modelOutput[GetOffset(x, y, channel + 4)]);
}
private CellDimensions MapBoundingBoxToCell(int x, int y, int box, BoundingBoxDimensions boxDimensions)
{
return new CellDimensions
{
X = ((float)x + Sigmoid(boxDimensions.X)) * CELL_WIDTH,
Y = ((float)y + Sigmoid(boxDimensions.Y)) * CELL_HEIGHT,
Width = (float)Math.Exp(boxDimensions.Width) * CELL_WIDTH * anchors[box * 2],
Height = (float)Math.Exp(boxDimensions.Height) * CELL_HEIGHT * anchors[box * 2 + 1],
};
}
public float[] ExtractClasses(float[] modelOutput, int x, int y, int channel)
{
float[] predictedClasses = new float[CLASS_COUNT];
int predictedClassOffset = channel + BOX_INFO_FEATURE_COUNT;
for (int predictedClass = 0; predictedClass < CLASS_COUNT; predictedClass++)
{
predictedClasses[predictedClass] = modelOutput[GetOffset(x, y, predictedClass + predictedClassOffset)];
}
return Softmax(predictedClasses);
}
private ValueTuple<int, float> GetTopResult(float[] predictedClasses)
{
return predictedClasses
.Select((predictedClass, index) => (Index: index, Value: predictedClass))
.OrderByDescending(result => result.Value)
.First();
}
private float IntersectionOverUnion(RectangleF boundingBoxA, RectangleF boundingBoxB)
{
var areaA = boundingBoxA.Width * boundingBoxA.Height;
if (areaA <= 0)
return 0;
var areaB = boundingBoxB.Width * boundingBoxB.Height;
if (areaB <= 0)
return 0;
var minX = Math.Max(boundingBoxA.Left, boundingBoxB.Left);
var minY = Math.Max(boundingBoxA.Top, boundingBoxB.Top);
var maxX = Math.Min(boundingBoxA.Right, boundingBoxB.Right);
var maxY = Math.Min(boundingBoxA.Bottom, boundingBoxB.Bottom);
var intersectionArea = Math.Max(maxY - minY, 0) * Math.Max(maxX - minX, 0);
return intersectionArea / (areaA + areaB - intersectionArea);
}
Jakmile definujete všechny pomocné metody, je čas je použít ke zpracování výstupu modelu.
Pod metodou IntersectionOverUnion vytvořte metodu ParseOutputs pro zpracování výstupu vygenerovaného modelem.
public IList<YoloBoundingBox> ParseOutputs(float[] yoloModelOutputs, float threshold = .3F)
{
}
Vytvořte seznam pro uložení ohraničujících polí a definování proměnných uvnitř ParseOutputs metody.
var boxes = new List<YoloBoundingBox>();
Každý obrázek je rozdělený do mřížky 13 x 13 buněk. Každá buňka obsahuje pět ohraničujících rámečků. Pod proměnnou boxes přidejte kód pro zpracování všech polí v jednotlivých buňkách.
for (int row = 0; row < ROW_COUNT; row++)
{
for (int column = 0; column < COL_COUNT; column++)
{
for (int box = 0; box < BOXES_PER_CELL; box++)
{
}
}
}
Uvnitř nejvnitřnější smyčky vypočítejte počáteční pozici aktuálního boxu ve výstupu jednorozměrného modelu.
var channel = (box * (CLASS_COUNT + BOX_INFO_FEATURE_COUNT));
Přímo pod tím použijte ExtractBoundingBoxDimensions metodu k získání dimenzí aktuálního ohraničujícího rámečku.
BoundingBoxDimensions boundingBoxDimensions = ExtractBoundingBoxDimensions(yoloModelOutputs, row, column, channel);
Pak pomocí GetConfidence metody získáte jistotu pro aktuální ohraničující rámeček.
float confidence = GetConfidence(yoloModelOutputs, row, column, channel);
Potom pomocí MapBoundingBoxToCell metody namapujte aktuální ohraničující pole na aktuální buňku, která se zpracovává.
CellDimensions mappedBoundingBox = MapBoundingBoxToCell(row, column, box, boundingBoxDimensions);
Před dalším zpracováním zkontrolujte, jestli je hodnota spolehlivosti větší než zadaná prahová hodnota. Pokud ne, zpracujte další ohraničující rámeček.
if (confidence < threshold)
continue;
V opačném případě pokračujte ve zpracování výstupu. Dalším krokem je získání rozdělení pravděpodobnosti predikovaných tříd pro aktuální omezenou oblast pomocí ExtractClasses metody.
float[] predictedClasses = ExtractClasses(yoloModelOutputs, row, column, channel);
Pak použijte GetTopResult metodu k získání hodnoty a indexu třídy s nejvyšší pravděpodobností pro aktuální box a vypočítejte jeho skóre.
var (topResultIndex, topResultScore) = GetTopResult(predictedClasses);
var topScore = topResultScore * confidence;
Znovu použijte topScore k zachování pouze těch ohraničujících rámečků, které jsou nad zadanou prahovou hodnotou.
if (topScore < threshold)
continue;
A konečně, pokud aktuální ohraničující rámeček překročí prahovou hodnotu, vytvořte nový BoundingBox objekt a přidejte ho do boxes seznamu.
boxes.Add(new YoloBoundingBox()
{
Dimensions = new BoundingBoxDimensions
{
X = (mappedBoundingBox.X - mappedBoundingBox.Width / 2),
Y = (mappedBoundingBox.Y - mappedBoundingBox.Height / 2),
Width = mappedBoundingBox.Width,
Height = mappedBoundingBox.Height,
},
Confidence = topScore,
Label = labels[topResultIndex],
BoxColor = classColors[topResultIndex]
});
Po zpracování všech buněk na obrázku vraťte seznam boxes. Přidejte následující návratový příkaz pod vnější-most for-loop v ParseOutputs metodě.
return boxes;
Filtrování překrývajících se polí
Teď, když byly z výstupu modelu extrahovány všechny vysoce pravděpodobné ohraničující rámečky, je třeba provést další filtrování, aby se odstranily překrývající se obrázky. Přidejte metodu s názvem FilterBoundingBoxes pod metodu ParseOutputs :
public IList<YoloBoundingBox> FilterBoundingBoxes(IList<YoloBoundingBox> boxes, int limit, float threshold)
{
}
FilterBoundingBoxes Uvnitř metody začněte vytvořením pole, které se rovná velikosti rozpoznaných polí a označení všech slotů jako aktivní nebo připravené ke zpracování.
var activeCount = boxes.Count;
var isActiveBoxes = new bool[boxes.Count];
for (int i = 0; i < isActiveBoxes.Length; i++)
isActiveBoxes[i] = true;
Potom seřaďte seznam obsahující ohraničující pole v sestupném pořadí podle spolehlivosti.
var sortedBoxes = boxes.Select((b, i) => new { Box = b, Index = i })
.OrderByDescending(b => b.Box.Confidence)
.ToList();
Potom vytvořte seznam pro uložení filtrovaných výsledků.
var results = new List<YoloBoundingBox>();
Začněte zpracovávat jednotlivé ohraničující rámečky iterací nad jednotlivými ohraničujícími rámečky.
for (int i = 0; i < boxes.Count; i++)
{
}
Uvnitř této smyčky for-loop zkontrolujte, zda je možné zpracovat aktuální ohraničující rámeček.
if (isActiveBoxes[i])
{
}
Pokud ano, přidejte ohraničovací rámeček do seznamu výsledků. Pokud výsledky překročí zadaný limit krabic, které se mají extrahovat, ukončete smyčku. Do příkazu if přidejte následující kód.
var boxA = sortedBoxes[i].Box;
results.Add(boxA);
if (results.Count >= limit)
break;
Jinak se podívejte na sousední ohraničující rámečky. Pod kontrolu limitu pole přidejte následující kód.
for (var j = i + 1; j < boxes.Count; j++)
{
}
Podobně jako u prvního pole, pokud je sousední pole aktivní nebo připravené ke zpracování, použijte IntersectionOverUnion metodu ke kontrole, zda první a druhé pole překročí zadanou prahovou hodnotu. Do nejvnitřnější smyčky for-loop přidejte následující kód.
if (isActiveBoxes[j])
{
var boxB = sortedBoxes[j].Box;
if (IntersectionOverUnion(boxA.Rect, boxB.Rect) > threshold)
{
isActiveBoxes[j] = false;
activeCount--;
if (activeCount <= 0)
break;
}
}
Po dokončení vnitřní smyčky for, která kontroluje sousední ohraničovací rámečky, zjistěte, zda existují nějaké zbývající ohraničovací rámečky ke zpracování. Pokud ne, prolomte vnější smyčku for-loop.
if (activeCount <= 0)
break;
Nakonec mimo počáteční smyčku pro metodu FilterBoundingBoxes vraťte výsledky:
return results;
Skvělé! Teď je čas použít tento kód společně s modelem pro bodování.
Použití modelu k bodování
Stejně jako při následném zpracování je v bodovacím postupu několik kroků. Chcete-li s tím pomoct, přidejte do projektu třídu, která bude obsahovat logiku bodování.
V Průzkumníku řešení klikněte pravým tlačítkem myši na projekt a pak vyberte Přidat>novou položku.
V dialogovém okně Přidat novou položku vyberte Třída a změňte pole Název na OnnxModelScorer.cs. Pak vyberte Přidat.
Soubor OnnxModelScorer.cs se otevře v editoru kódu. Na začátek
usingpřidejte následující direktivy:using System; using System.Collections.Generic; using System.Linq; using Microsoft.ML; using Microsoft.ML.Data; using ObjectDetection.DataStructures; using ObjectDetection.YoloParser;OnnxModelScorerDo definice třídy přidejte následující proměnné.private readonly string imagesFolder; private readonly string modelLocation; private readonly MLContext mlContext; private IList<YoloBoundingBox> _boundingBoxes = new List<YoloBoundingBox>();Přímo pod tím vytvořte konstruktor pro
OnnxModelScorertřídu, která inicializuje dříve definované proměnné.public OnnxModelScorer(string imagesFolder, string modelLocation, MLContext mlContext) { this.imagesFolder = imagesFolder; this.modelLocation = modelLocation; this.mlContext = mlContext; }Po vytvoření konstruktoru definujte několik struktur, které obsahují proměnné související s nastavením image a modelu. Vytvořte volanou
ImageNetSettingsstrukturu, která bude obsahovat výšku a šířku očekávanou jako vstup pro model.public struct ImageNetSettings { public const int imageHeight = 416; public const int imageWidth = 416; }Potom vytvořte další strukturu,
TinyYoloModelSettingskterá obsahuje názvy vstupních a výstupních vrstev modelu. Pokud chcete vizualizovat název vstupní a výstupní vrstvy modelu, můžete použít nástroj, jako je Netron.public struct TinyYoloModelSettings { // for checking Tiny yolo2 Model input and output parameter names, //you can use tools like Netron, // which is installed by Visual Studio AI Tools // input tensor name public const string ModelInput = "image"; // output tensor name public const string ModelOutput = "grid"; }Dále vytvořte první sadu metod, které se používají k bodování. Vytvořte metodu
LoadModeluvnitř třídyOnnxModelScorer.private ITransformer LoadModel(string modelLocation) { }LoadModelDo metody přidejte následující kód pro protokolování.Console.WriteLine("Read model"); Console.WriteLine($"Model location: {modelLocation}"); Console.WriteLine($"Default parameters: image size=({ImageNetSettings.imageWidth},{ImageNetSettings.imageHeight})");ML.NET kanály potřebují znát schéma dat, které bude použito, když je metoda
Fitzavolána. V tomto případě se použije proces podobný trénování. Vzhledem k tomu, že se neprobíhá žádné skutečné trénování, je přijatelné použít prázdnýIDataView. Vytvořte novýIDataViewkanál z prázdného seznamu.var data = mlContext.Data.LoadFromEnumerable(new List<ImageNetData>());Pod tím definujte kanál. Potrubí bude sestávat ze čtyř transformací.
-
LoadImagesnačte obrázek jako bitmapu. -
ResizeImageszmění velikost obrázku na zadanou velikost (v tomto případě na416 x 416). -
ExtractPixelszmění reprezentaci obrázku z bitmapy na číselný vektor. -
ApplyOnnxModelnačte model ONNX a použije ho k určení skóre zadaných dat.
Důležité
Používejte pouze modely z důvěryhodných zdrojů. Použití modelů z nedůvěryhodných zdrojů představuje bezpečnostní riziko.
Definujte svůj kanál v
LoadModelmetodě pod proměnnoudata.var pipeline = mlContext.Transforms.LoadImages(outputColumnName: "image", imageFolder: "", inputColumnName: nameof(ImageNetData.ImagePath)) .Append(mlContext.Transforms.ResizeImages(outputColumnName: "image", imageWidth: ImageNetSettings.imageWidth, imageHeight: ImageNetSettings.imageHeight, inputColumnName: "image")) .Append(mlContext.Transforms.ExtractPixels(outputColumnName: "image")) .Append(mlContext.Transforms.ApplyOnnxModel(modelFile: modelLocation, outputColumnNames: new[] { TinyYoloModelSettings.ModelOutput }, inputColumnNames: new[] { TinyYoloModelSettings.ModelInput }));Teď je čas vytvořit instanci modelu pro bodování. Zavolejte metodu
Fitkanálu a vraťte ji pro další zpracování.var model = pipeline.Fit(data); return model;-
Jakmile se model načte, můžete ho použít k předpovědím. Chcete-li tento proces usnadnit, vytvořte metodu volanou PredictDataUsingModel pod metodou LoadModel .
private IEnumerable<float[]> PredictDataUsingModel(IDataView testData, ITransformer model)
{
}
Do pole PredictDataUsingModel, přidejte následující kód pro protokolování.
Console.WriteLine($"Images location: {imagesFolder}");
Console.WriteLine("");
Console.WriteLine("=====Identify the objects in the images=====");
Console.WriteLine("");
Pak použijte metodu Transform k určení skóre dat.
IDataView scoredData = model.Transform(testData);
Extrahujte predikované pravděpodobnosti a vraťte je k dalšímu zpracování.
IEnumerable<float[]> probabilities = scoredData.GetColumn<float[]>(TinyYoloModelSettings.ModelOutput);
return probabilities;
Teď, když jsou oba kroky nastavené, je zkombinujte do jedné metody. Pod metodu PredictDataUsingModel přidejte novou metodu s názvem Score.
public IEnumerable<float[]> Score(IDataView data)
{
var model = LoadModel(modelLocation);
return PredictDataUsingModel(data, model);
}
Skoro tam! Teď je čas všechno použít.
Detekce objektů
Teď, když je všechna nastavení dokončená, je čas zjistit některé objekty.
Určení skóre a parsování výstupů modelu
Pod vytvoření mlContext proměnné přidejte příkaz try-catch.
try
{
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
}
try Uvnitř bloku začněte implementovat logiku detekce objektů. Nejprve načtěte data do objektu IDataView.
IEnumerable<ImageNetData> images = ImageNetData.ReadFromFile(imagesFolder);
IDataView imageDataView = mlContext.Data.LoadFromEnumerable(images);
Pak vytvořte instanci OnnxModelScorer a použijte ji k určení skóre načtených dat.
// Create instance of model scorer
var modelScorer = new OnnxModelScorer(imagesFolder, modelFilePath, mlContext);
// Use model to score data
IEnumerable<float[]> probabilities = modelScorer.Score(imageDataView);
Teď je čas na krok následného zpracování. Vytvořte instanci YoloOutputParser a použijte ji ke zpracování výstupu modelu.
YoloOutputParser parser = new YoloOutputParser();
var boundingBoxes =
probabilities
.Select(probability => parser.ParseOutputs(probability))
.Select(boxes => parser.FilterBoundingBoxes(boxes, 5, .5F));
Po zpracování výstupu modelu je čas nakreslit ohraničující rámečky na obrázcích.
Vizualizace předpovědí
Jakmile model vyhodnotí skóre obrázků a výstupy, musí být ohraničující rámečky na obrázku nakresleny. Uděláte to tak, že do DrawBoundingBox přidáte metodu GetAbsolutePath s názvem pod metodu.
void DrawBoundingBox(string inputImageLocation, string outputImageLocation, string imageName, IList<YoloBoundingBox> filteredBoundingBoxes)
{
}
Nejprve načtěte obrázek a získejte rozměry výšky a šířky v DrawBoundingBox metodě.
Image image = Image.FromFile(Path.Combine(inputImageLocation, imageName));
var originalImageHeight = image.Height;
var originalImageWidth = image.Width;
Pak vytvořte smyčku for-each, která bude iterovat přes každý ohraničující box rozpoznaný modelem.
foreach (var box in filteredBoundingBoxes)
{
}
Uvnitř smyčky typu for-each určete rozměry ohraničujícího rámečku.
var x = (uint)Math.Max(box.Dimensions.X, 0);
var y = (uint)Math.Max(box.Dimensions.Y, 0);
var width = (uint)Math.Min(originalImageWidth - x, box.Dimensions.Width);
var height = (uint)Math.Min(originalImageHeight - y, box.Dimensions.Height);
Vzhledem k tomu, že rozměry ohraničujícího rámečku odpovídají vstupu 416 x 416modelu , škálujte rozměry ohraničujícího rámečku tak, aby odpovídaly skutečné velikosti obrázku.
x = (uint)originalImageWidth * x / OnnxModelScorer.ImageNetSettings.imageWidth;
y = (uint)originalImageHeight * y / OnnxModelScorer.ImageNetSettings.imageHeight;
width = (uint)originalImageWidth * width / OnnxModelScorer.ImageNetSettings.imageWidth;
height = (uint)originalImageHeight * height / OnnxModelScorer.ImageNetSettings.imageHeight;
Pak definujte šablonu pro text, který se zobrazí nad každým ohraničujícím rámečkem. Text bude obsahovat třídu objektu uvnitř příslušného ohraničujícího rámečku a také důvěru.
string text = $"{box.Label} ({(box.Confidence * 100).ToString("0")}%)";
Pokud chcete na obrázku kreslit, převeďte ho Graphics na objekt.
using (Graphics thumbnailGraphic = Graphics.FromImage(image))
{
}
using Uvnitř bloku kódu vylaďte nastavení objektu grafikyGraphics.
thumbnailGraphic.CompositingQuality = CompositingQuality.HighQuality;
thumbnailGraphic.SmoothingMode = SmoothingMode.HighQuality;
thumbnailGraphic.InterpolationMode = InterpolationMode.HighQualityBicubic;
Pod tím nastavte možnosti písma a barvy pro text a ohraničující pole.
// Define Text Options
Font drawFont = new Font("Arial", 12, FontStyle.Bold);
SizeF size = thumbnailGraphic.MeasureString(text, drawFont);
SolidBrush fontBrush = new SolidBrush(Color.Black);
Point atPoint = new Point((int)x, (int)y - (int)size.Height - 1);
// Define BoundingBox options
Pen pen = new Pen(box.BoxColor, 3.2f);
SolidBrush colorBrush = new SolidBrush(box.BoxColor);
Vytvořte a vyplňte obdélník nad ohraničujícím rámečkem, který bude obsahovat text pomocí FillRectangle metody. To pomůže s kontrastem textu a zlepšit čitelnost.
thumbnailGraphic.FillRectangle(colorBrush, (int)x, (int)(y - size.Height - 1), (int)size.Width, (int)size.Height);
Potom pomocí metod DrawString a DrawRectangle nakreslete text a ohraničující pole na obrázku.
thumbnailGraphic.DrawString(text, drawFont, fontBrush, atPoint);
// Draw bounding box on image
thumbnailGraphic.DrawRectangle(pen, x, y, width, height);
Mimo smyčku for-each přidejte kód pro uložení obrázků v souboru outputFolder.
if (!Directory.Exists(outputImageLocation))
{
Directory.CreateDirectory(outputImageLocation);
}
image.Save(Path.Combine(outputImageLocation, imageName));
Pokud chcete získat další zpětnou vazbu, že aplikace provádí předpovědi podle očekávání v době běhu, přidejte metodu zvanou LogDetectedObjects pod DrawBoundingBox metodu v souboru Program.cs pro výstup rozpoznaných objektů do konzoly.
void LogDetectedObjects(string imageName, IList<YoloBoundingBox> boundingBoxes)
{
Console.WriteLine($".....The objects in the image {imageName} are detected as below....");
foreach (var box in boundingBoxes)
{
Console.WriteLine($"{box.Label} and its Confidence score: {box.Confidence}");
}
Console.WriteLine("");
}
Teď, když máte pomocné metody pro vytvoření vizuální zpětné vazby z předpovědí, přidejte smyčku for-loop, která bude iterovat nad každou z vyhodnocených obrázků.
for (var i = 0; i < images.Count(); i++)
{
}
Uvnitř cyklu for získejte název souboru obrázku a ohraničující rámečky s ním spojené.
string imageFileName = images.ElementAt(i).Label;
IList<YoloBoundingBox> detectedObjects = boundingBoxes.ElementAt(i);
Pod tím pomocí DrawBoundingBox metody nakreslete ohraničující rámečky na obrázku.
DrawBoundingBox(imagesFolder, outputFolder, imageFileName, detectedObjects);
Nakonec použijte metodu LogDetectedObjects k výstupu předpovědí do konzoly.
LogDetectedObjects(imageFileName, detectedObjects);
Po příkazu try-catch přidejte další logiku, která indikuje, že proces je spuštěný.
Console.WriteLine("========= End of Process..Hit any Key ========");
A je to!
Results
Po provedení předchozích kroků spusťte konzolovou aplikaci (Ctrl + F5). Výsledky by měly být podobné následujícímu výstupu. Mohou se zobrazit upozornění nebo zpracovatelské zprávy, ale tyto zprávy byly z následujících výsledků odebrány pro větší přehlednost výsledků.
=====Identify the objects in the images=====
.....The objects in the image image1.jpg are detected as below....
car and its Confidence score: 0.9697262
car and its Confidence score: 0.6674225
person and its Confidence score: 0.5226039
car and its Confidence score: 0.5224892
car and its Confidence score: 0.4675332
.....The objects in the image image2.jpg are detected as below....
cat and its Confidence score: 0.6461141
cat and its Confidence score: 0.6400049
.....The objects in the image image3.jpg are detected as below....
chair and its Confidence score: 0.840578
chair and its Confidence score: 0.796363
diningtable and its Confidence score: 0.6056048
diningtable and its Confidence score: 0.3737402
.....The objects in the image image4.jpg are detected as below....
dog and its Confidence score: 0.7608147
person and its Confidence score: 0.6321323
dog and its Confidence score: 0.5967442
person and its Confidence score: 0.5730394
person and its Confidence score: 0.5551759
========= End of Process..Hit any Key ========
Pokud chcete zobrazit obrázky s ohraničujícími poli, přejděte do assets/images/output/ adresáře. Níže je ukázka z jedné z zpracovaných imagí.

Gratulujeme! Nyní jste úspěšně vytvořili model strojového učení pro detekci objektů opětovným použitím předem natrénovaného ONNX modelu v ML.NET.
Zdrojový kód pro tento kurz najdete v úložišti dotnet/machinelearning-samples .
V tomto kurzu jste se naučili:
- Pochopení problému
- Zjistěte, co je ONNX a jak funguje s ML.NET
- Vysvětlení modelu
- Opakované použití předtrénovaného modelu
- Detekce objektů s načteným modelem
Podívejte se na úložiště GitHub s ukázkami služby Machine Learning a prozkoumejte rozbalenou ukázku detekce objektů.
Spolupracujte s námi na GitHubu
Zdroj tohoto obsahu najdete na GitHubu, kde můžete také vytvářet a kontrolovat problémy a žádosti o přijetí změn. Další informace najdete v našem průvodci pro přispěvatele.