Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Zjistěte, jak vytvořit aplikaci pro detekci anomálií pro prodejní data produktů. Tento kurz vytvoří konzolovou aplikaci .NET pomocí jazyka C# v sadě Visual Studio.
V tomto kurzu se naučíte:
- Načtení dat
- Vytvořit transformaci pro detekci výkyvů anomálií
- Detekce špičkových anomálií pomocí transformace
- Vytvoření transformace pro detekci anomálií bodu změn
- Detekce anomálií bodů změn pomocí transformace
Zdrojový kód pro tento kurz najdete v úložišti dotnet/samples.
Požadavky
Visual Studio 2022 nebo novější s nainstalovanou úlohou vývoj aplikací pro .NET Desktop
Poznámka
Formát dat v datovém product-sales.csv je založený na datové sadě "Prodeje šampónů za tříleté období," pocházející původně z DataMarketu a poskytované Knihovnou časových řad (TSDL), kterou vytvořil Rob Hyndman.
Datová sada "Shampoo Sales Over a Three Year Period" (Prodej šampónu za období tří let) licencovaná v rámci výchozí otevřené licence DataMarket.
Vytvoření konzolové aplikace
Vytvořte konzolovou aplikaci jazyka C# s názvem ProductSalesAnomalyDetection. Klikněte na tlačítko Další.
Jako architekturu, která se má použít, zvolte .NET 8. Klikněte na tlačítko Vytvořit.
Vytvořte adresář s názvem Data v projektu a uložte soubory datové sady.
Nainstalujtebalíčku NuGet
Microsoft.ML: Poznámka
Tato ukázka používá nejnovější stabilní verzi uvedených balíčků NuGet, pokud není uvedeno jinak.
V Průzkumníku řešení klikněte pravým tlačítkem na projekt a vyberte Spravovat balíčky NuGet. Jako zdroj balíčku zvolte "nuget.org", vyberte kartu Procházet, vyhledejte Microsoft.ML a vyberte Nainstalovat. V dialogovém okně
Náhled změn vyberte tlačítkoOK a pak v dialogovém okněSouhlas s licenčními podmínkami pro uvedené balíčky vyberte tlačítko . Opakujte tyto kroky pro Microsoft.ML.TimeSeries.Přijmout Na začátek souboru
usingpřidejte následující direktivy :using Microsoft.ML; using ProductSalesAnomalyDetection;
Stažení dat
Stáhněte datovou sadu a uložte ji do složky Data, kterou jste vytvořili dříve:
Klikněte pravým tlačítkem na product-sales.csv a vyberte Uložit odkaz (nebo cíl) jako...
Ujistěte se, že buď uložíte soubor *.csv do složky Data, nebo pokud ho uložíte jinam, přesuňte poté soubor *.csv do složky Data.
V Průzkumníku řešení klikněte pravým tlačítkem myši na soubor *.csv a vyberte Vlastnosti. V části Upřesnitzměňte hodnotu Kopírovat do výstupního adresáře na Kopírovat, pokud je novější.
Následující tabulka obsahuje náhled dat ze souboru *.csv:
| Měsíc | Prodej výrobků |
|---|---|
| 1.ledna | 271 |
| 2. ledna | 150.9 |
| ..... | ..... |
| 1. únor | 199.3 |
| ..... | ..... |
Vytváření tříd a definování cest
Dále definujte datové struktury vstupní a prediktivní třídy.
Přidejte do projektu novou třídu:
V Průzkumník řešeníklikněte pravým tlačítkem myši na projekt a pak vyberte Přidat > Nová položka.
V dialogovém okně Přidat novou položkuvyberte Třída a změňte pole Název na ProductSalesData.cs. Pak vyberte Přidat.
Soubor ProductSalesData.cs se otevře v editoru kódu.
Přidejte následující direktivu
usingna začátek ProductSalesData.cs:using Microsoft.ML.Data;Odeberte existující definici třídy a do souboru
ProductSalesDatapřidejte následující kód, který má dvě třídyProductSalesPredictiona :public class ProductSalesData { [LoadColumn(0)] public string? Month; [LoadColumn(1)] public float numSales; } public class ProductSalesPrediction { //vector to hold alert,score,p-value values [VectorType(3)] public double[]? Prediction { get; set; } }ProductSalesDataurčuje vstupní datovou třídu. Atribut LoadColumn určuje sloupce (podle indexu sloupců) v datové sadě, které se mají načíst.ProductSalesPredictionurčuje třídu prediktivních dat. Pro detekci anomálií se předpověď skládá z výstrahy, která označuje, jestli existuje anomálie, nezpracované skóre a p-hodnota. Čím blíž je p-hodnota 0, tím je pravděpodobnější, že došlo k anomálii.Vytvořte dvě globální pole pro uložení nedávno stažené cesty k souboru datové sady a uložené cesty k souboru modelu:
-
_dataPathmá cestu k datové sadě použité k trénování modelu. -
_docsizemá počet záznamů v souboru datové sady. K výpočtu_docSizepoužijetepvalueHistoryLength.
-
Přidejte následující kód na řádek přímo pod direktivy
using, které určují tyto cesty:string _dataPath = Path.Combine(Environment.CurrentDirectory, "Data", "product-sales.csv"); //assign the Number of records in dataset file to constant variable const int _docsize = 36;
Inicializujte proměnné
Nahraďte řádek
Console.WriteLine("Hello World!")následujícím kódem, který deklaruje a inicializuje proměnnoumlContext:MLContext mlContext = new MLContext();Třída MLContext je výchozím bodem pro všechny operace ML.NET a inicializace
mlContextvytvoří nové ML.NET prostředí, které lze sdílet napříč objekty pracovního postupu vytváření modelu. Je to podobné, koncepčně,DBContextv Entity Frameworku.
Načtení dat
Data v ML.NET jsou reprezentována jako rozhraní IDataView.
IDataView je flexibilní, efektivní způsob popisu tabulkových dat (číselných a textových). Data je možné načíst z textového souboru nebo z jiných zdrojů (například z databáze SQL nebo souborů protokolu) do objektu IDataView.
Po vytvoření proměnné
mlContextpřidejte následující kód:IDataView dataView = mlContext.Data.LoadFromTextFile<ProductSalesData>(path: _dataPath, hasHeader: true, separatorChar: ',');LoadFromTextFile() definuje schéma dat a načte ze souboru. Přebírá proměnné cesty k datům a vrací
IDataView.
Detekce anomálií časových řad
Detekce anomálií označuje neočekávané nebo neobvyklé události nebo chování. Poskytuje vodítka, kde hledat problémy a pomáhá odpovědět na otázku "Je to divný?".

Detekce anomálií je proces zjišťování odlehlých hodnot dat časových řad; odkazuje na danou vstupní časovou řadu, kde chování není očekávané nebo "divné".
Detekce anomálií může být užitečná mnoha způsoby. Například:
Pokud máte auto, možná vás zajímá: Je tento měřič oleje v pořádku, nebo mám únik oleje? Pokud monitorujete spotřebu energie, měli byste vědět: Došlo k výpadku?
Existují dva typy anomálií časových řad, které je možné zjistit:
Píky značí dočasné nárůsty neobvyklého chování v systému.
Body změny označují začátek časově trvalých změn v systému.
V ML.NET jsou algoritmy pro detekci špiček IID nebo detekci bodu změn IID vhodné pro nezávislé a identicky rozložené datové sady. Předpokládají, že vaše vstupní data jsou posloupností datových bodů, které jsou nezávisle vzorkovány z jedné stacionární distribuce .
Na rozdíl od modelů v jiných tutoriálech detektor anomálií časových řad transformuje přímo na vstupních datech. Metoda IEstimator.Fit() k vytvoření transformace nepotřebuje trénovací data. Potřebuje však schéma dat, které je poskytováno zobrazením dat vygenerovaným z prázdného seznamu ProductSalesData.
Budete analyzovat stejná data o prodeji produktů, abyste zjistili špičky a body změn. Proces modelu sestavování a trénování je stejný pro detekci špiček a detekci bodů změn; Hlavním rozdílem je použitý konkrétní algoritmus detekce.
Detekce výkyvů
Cílem detekce špiček je identifikovat náhlé, ale dočasné nárůsty, které se výrazně liší od většiny datových hodnot časových řad. Je důležité včas detekovat tyto podezřelé vzácné položky, události nebo pozorování, aby se minimalizovaly. Následující přístup se dá použít k detekci nejrůznějších anomálií, jako jsou výpadky, kybernetické útoky nebo virální webový obsah. Následující obrázek je příkladem špiček v datové sadě časových řad:
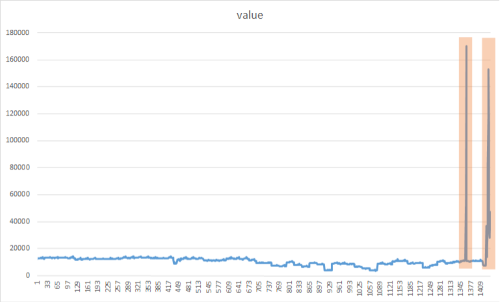
Přidání metody CreateEmptyDataView()
Do Program.cspřidejte následující metodu:
IDataView CreateEmptyDataView(MLContext mlContext) {
// Create empty DataView. We just need the schema to call Fit() for the time series transforms
IEnumerable<ProductSalesData> enumerableData = new List<ProductSalesData>();
return mlContext.Data.LoadFromEnumerable(enumerableData);
}
CreateEmptyDataView() vytvoří prázdný objekt zobrazení dat se správným schématem, který se použije jako vstup do metody IEstimator.Fit().
Vytvoření metody DetectSpike()
Metoda DetectSpike():
- Vytvoří transformaci z estimatoru.
- Detekuje špičky na základě historických prodejních dat.
- Zobrazí výsledky.
V dolní části souboru
DetectSpike()vytvořte metodu pomocí následujícího kódu:DetectSpike(MLContext mlContext, int docSize, IDataView productSales) { }Pomocí IidSpikeEstimator vytrénujte model pro detekci špiček. Přidejte ho do
DetectSpike()metody s následujícím kódem:var iidSpikeEstimator = mlContext.Transforms.DetectIidSpike(outputColumnName: nameof(ProductSalesPrediction.Prediction), inputColumnName: nameof(ProductSalesData.numSales), confidence: 95d, pvalueHistoryLength: docSize / 4);Vytvořte transformaci detekce špiček tak, že do metody
DetectSpike()přidáte následující řádek kódu:Spropitné
Parametry
confidenceapvalueHistoryLengthovlivňují způsob zjištění špiček.confidenceurčuje, jak citlivý je váš model na výkyvy. Čím nižší je spolehlivost, tím pravděpodobnější je, že algoritmus detekuje "menší" špičky. ParametrpvalueHistoryLengthdefinuje počet datových bodů v posuvném okně. Hodnota tohoto parametru je obvykle procento celé datové sady. Čím nižšípvalueHistoryLength, tím rychleji model zapomene předchozí velké špičky.ITransformer iidSpikeTransform = iidSpikeEstimator.Fit(CreateEmptyDataView(mlContext));Přidejte následující řádek kódu, který transformuje data
productSalesjako další řádek v metoděDetectSpike():IDataView transformedData = iidSpikeTransform.Transform(productSales);Předchozí kód používá metodu
Transform() k předpovědím pro více vstupních řádků datové sady. Pomocí metody
transformedDatamůžete převést vašeIEnumerablena silně typovaný pro jednodušší zobrazení s použitím následujícího kódu:var predictions = mlContext.Data.CreateEnumerable<ProductSalesPrediction>(transformedData, reuseRowObject: false);Pomocí následujícího Console.WriteLine() kódu vytvořte řádek záhlaví zobrazení:
Console.WriteLine("Alert\tScore\tP-Value");Ve výsledcích detekce špiček zobrazíte následující informace:
-
Alertindikuje upozornění na špičku pro daný datový bod. -
Scoreje hodnotaProductSalespro daný datový bod v datové sadě. -
P-Value"P" znamená pravděpodobnost. Čím blíže je p-hodnota 0, tím pravděpodobnější je, že datový bod je anomálie.
-
Pomocí následujícího kódu iterujte
predictionsIEnumerablea zobrazte výsledky:foreach (var p in predictions) { if (p.Prediction is not null) { var results = $"{p.Prediction[0]}\t{p.Prediction[1]:f2}\t{p.Prediction[2]:F2}"; if (p.Prediction[0] == 1) { results += " <-- Spike detected"; } Console.WriteLine(results); } } Console.WriteLine("");Přidejte volání metody
DetectSpike()pod volání metodyLoadFromTextFile():DetectSpike(mlContext, _docsize, dataView);
Výsledky detekce špiček
Výsledky by měly být podobné následujícímu. Během zpracování se zobrazí zprávy. Můžete vidět varování nebo zprávy o zpracování. Některé zprávy byly z následujících výsledků odebrány, aby byly přehledné.
Detect temporary changes in pattern
=============== Training the model ===============
=============== End of training process ===============
Alert Score P-Value
0 271.00 0.50
0 150.90 0.00
0 188.10 0.41
0 124.30 0.13
0 185.30 0.47
0 173.50 0.47
0 236.80 0.19
0 229.50 0.27
0 197.80 0.48
0 127.90 0.13
1 341.50 0.00 <-- Spike detected
0 190.90 0.48
0 199.30 0.48
0 154.50 0.24
0 215.10 0.42
0 278.30 0.19
0 196.40 0.43
0 292.00 0.17
0 231.00 0.45
0 308.60 0.18
0 294.90 0.19
1 426.60 0.00 <-- Spike detected
0 269.50 0.47
0 347.30 0.21
0 344.70 0.27
0 445.40 0.06
0 320.90 0.49
0 444.30 0.12
0 406.30 0.29
0 442.40 0.21
1 580.50 0.00 <-- Spike detected
0 412.60 0.45
1 687.00 0.01 <-- Spike detected
0 480.30 0.40
0 586.30 0.20
0 651.90 0.14
Detekce bodu změn
Change points jsou stálé změny v distribuci hodnot v toku událostí časové řady, například změny úrovně a trendy. Tyto trvalé změny trvají mnohem déle než spikes a mohly by značit katastrofické události.
Change points nejsou obvykle viditelné pro nahý oko, ale je možné je zjistit ve vašich datech pomocí přístupů, jako je následující metoda. Následující obrázek je příkladem detekce bodu změn:
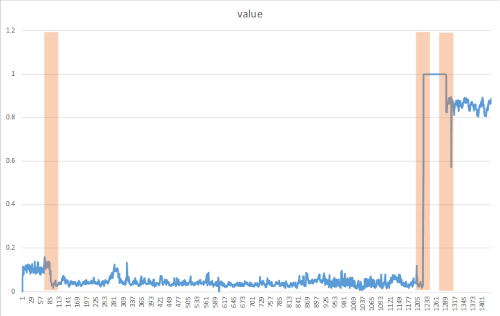
Vytvoření metody DetectChangepoint()
Metoda DetectChangepoint() provádí následující úlohy:
- Vytvoří transformaci z estimatoru.
- Detekuje body změn na základě historických prodejních dat.
- Zobrazí výsledky.
Pomocí následujícího kódu vytvořte metodu
DetectChangepoint()hned po deklaraci metodyDetectSpike():void DetectChangepoint(MLContext mlContext, int docSize, IDataView productSales) { }V metodě vytvořte
DetectChangepoint()následujícím kódem:var iidChangePointEstimator = mlContext.Transforms.DetectIidChangePoint(outputColumnName: nameof(ProductSalesPrediction.Prediction), inputColumnName: nameof(ProductSalesData.numSales), confidence: 95d, changeHistoryLength: docSize / 4);Jak jste to udělali dříve, vytvořte transformaci z odhadce přidáním následujícího řádku kódu do
DetectChangePoint()metody:Spropitné
K detekci bodů změn dochází s mírným zpožděním, protože model musí zajistit, aby aktuální odchylka byla trvalá změna, a ne jen několik náhodných špiček před vytvořením výstrahy. Množství tohoto zpoždění se rovná
changeHistoryLengthparametru. Zvýšením hodnoty tohoto parametru budou upozornění detekce změn zaměřena na trvalejší změny, ale kompromisem bude delší prodleva.var iidChangePointTransform = iidChangePointEstimator.Fit(CreateEmptyDataView(mlContext));Pomocí metody
Transform()transformujte data přidáním následujícího kódu doDetectChangePoint():IDataView transformedData = iidChangePointTransform.Transform(productSales);Podobně jako předtím, převeďte váš
transformedDatana silně typovanýIEnumerablepro snadnější zobrazení pomocí metodyCreateEnumerable()pomocí následujícího kódu:var predictions = mlContext.Data.CreateEnumerable<ProductSalesPrediction>(transformedData, reuseRowObject: false);Vytvořte záhlaví zobrazení s následujícím kódem jako další řádek v metodě
DetectChangePoint():Console.WriteLine("Alert\tScore\tP-Value\tMartingale value");Ve výsledcích detekce bodu změn zobrazíte následující informace:
-
Alertoznačuje upozornění na bod změny pro daný datový bod. -
Scoreje hodnotaProductSalespro daný datový bod v datové sadě. -
P-Value"P" znamená pravděpodobnost. Čím blíž je P-hodnota 0, tím pravděpodobnější je, že datový bod je anomálie. -
Martingale valueslouží k identifikaci toho, jak "divný" datový bod je založený na sekvenci P-hodnot.
-
Iterujte
predictionsIEnumerablea zobrazte výsledky následujícím kódem:foreach (var p in predictions) { if (p.Prediction is not null) { var results = $"{p.Prediction[0]}\t{p.Prediction[1]:f2}\t{p.Prediction[2]:F2}\t{p.Prediction[3]:F2}"; if (p.Prediction[0] == 1) { results += " <-- alert is on, predicted changepoint"; } Console.WriteLine(results); } } Console.WriteLine("");Za volání metody
DetectChangepoint()přidejte následující volání metodyDetectSpike().DetectChangepoint(mlContext, _docsize, dataView);
Výsledky detekce bodů změn
Výsledky by měly být podobné následujícímu. Během zpracování se zobrazí zprávy. Můžete vidět varování nebo zprávy o zpracování. Některé zprávy byly z následujících výsledků odebrány, aby byly přehledné.
Detect Persistent changes in pattern
=============== Training the model Using Change Point Detection Algorithm===============
=============== End of training process ===============
Alert Score P-Value Martingale value
0 271.00 0.50 0.00
0 150.90 0.00 2.33
0 188.10 0.41 2.80
0 124.30 0.13 9.16
0 185.30 0.47 9.77
0 173.50 0.47 10.41
0 236.80 0.19 24.46
0 229.50 0.27 42.38
1 197.80 0.48 44.23 <-- alert is on, predicted changepoint
0 127.90 0.13 145.25
0 341.50 0.00 0.01
0 190.90 0.48 0.01
0 199.30 0.48 0.00
0 154.50 0.24 0.00
0 215.10 0.42 0.00
0 278.30 0.19 0.00
0 196.40 0.43 0.00
0 292.00 0.17 0.01
0 231.00 0.45 0.00
0 308.60 0.18 0.00
0 294.90 0.19 0.00
0 426.60 0.00 0.00
0 269.50 0.47 0.00
0 347.30 0.21 0.00
0 344.70 0.27 0.00
0 445.40 0.06 0.02
0 320.90 0.49 0.01
0 444.30 0.12 0.02
0 406.30 0.29 0.01
0 442.40 0.21 0.01
0 580.50 0.00 0.01
0 412.60 0.45 0.01
0 687.00 0.01 0.12
0 480.30 0.40 0.08
0 586.30 0.20 0.03
0 651.90 0.14 0.09
Blahopřejeme! Nyní jste úspěšně vytvořili modely strojového učení pro detekci špiček a anomálií bodů změn v prodejních datech.
Zdrojový kód pro tento kurz najdete v úložišti dotnet/samples.
V tomto kurzu jste se naučili:
- Načtení dat
- Školení modelu pro detekci anomálií špiček
- Detekce anomálií špiček pomocí vytrénovaného modelu
- Trénování modelu pro detekci anomálií bodů změn
- Detekce anomálií bodů změn pomocí vytrénovaného režimu
Další kroky
Podívejte se na ukázkové úložiště GitHubu ve službě Machine Learning a prozkoumejte ukázku detekce anomálií dat sezónnosti.
Spolupracujte s námi na GitHubu
Zdroj tohoto obsahu najdete na GitHubu, kde můžete také vytvářet a kontrolovat problémy a žádosti o přijetí změn. Další informace najdete v našem průvodci pro přispěvatele.