Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Naučte se používat ML.NET CLI k automatickému vygenerování modelu ML.NET a základního kódu jazyka C#. Zadáte datovou sadu a úlohu strojového učení, kterou chcete implementovat, a rozhraní příkazového řádku použije modul AutoML k vytvoření zdrojového kódu modelu a nasazení a také klasifikačního modelu.
V tomto kurzu provedete následující kroky:
- Příprava dat pro vybranou úlohu strojového učení
- Spuštění příkazu mlnet classification z rozhraní příkazového řádku
- Kontrola výsledků metriky kvality
- Vysvětlení vygenerovaného kódu jazyka C# pro použití modelu ve vaší aplikaci
- Prozkoumání vygenerovaného kódu jazyka C#, který se použil k trénování modelu
Poznámka
Toto téma odkazuje na nástroj ML.NET CLI, který je aktuálně ve verzi Preview, a materiál se může měnit. Další informace najdete na stránce ML.NET .
Rozhraní příkazového řádku ML.NET je součástí ML.NET a jeho hlavním cílem je "demokratizovat" ML.NET pro vývojáře .NET při učení ML.NET, abyste nemuseli kódovat od začátku, abyste mohli začít.
ML.NET CLI můžete spustit na libovolném příkazovém řádku (Windows, Mac nebo Linux) a vygenerovat kvalitní modely ML.NET a zdrojový kód na základě zadaných trénovacích datových sad.
Požadavky
- .NET Core 6 SDK nebo novější
- (Volitelné) Visual Studio
- Rozhraní příkazového řádku ML.NET
Vygenerované projekty kódu jazyka C# můžete spustit ze sady Visual Studio nebo pomocí dotnet run (.NET CLI).
Příprava dat
Použijeme existující datovou sadu používanou pro scénář analýzy mínění, což je úloha strojového učení binární klasifikace. Podobným způsobem můžete použít vlastní datovou sadu a model a kód se vygenerují za vás.
Stáhněte si soubor zip datové sady UCI Sentiment Labeled Sentences (viz citace v následující poznámce) a rozbalte ho do libovolné složky, kterou zvolíte.
Poznámka
Datové sady v tomto kurzu používají datovou sadu ze skupiny na jednotlivé popisky pomocí hlubokých funkcí Kotzias a kol. KDD 2015 a hostované v úložišti UCI Machine Learning – Dua, D. a Karra Taniskidou, E. (2017). Úložiště UCI Machine Learning [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science.
yelp_labelled.txtZkopírujte soubor do libovolné dříve vytvořené složky (například/cli-test).Otevřete upřednostňovaný příkazový řádek a přejděte do složky, do které jste zkopírovali soubor datové sady. Příklad:
cd /cli-testPomocí libovolného textového editoru, jako je Visual Studio Code, můžete soubor datové sady otevřít a prozkoumat
yelp_labelled.txt. Vidíte, že struktura je:Soubor nemá žádnou hlavičku. Použijete index sloupce.
Existují jenom dva sloupce:
Text (index sloupce 0) Popisek (index sloupce 1) Wow... Miloval toto místo. 1 Kůra není dobrá. 0 Není chutné a textura byla jen ošklivá. 0 ... MNOHO DALŠÍCH ŘÁDKŮ TEXTU... ... (1 nebo 0)...
Ujistěte se, že jste soubor datové sady zavřeli z editoru.
Teď jste připraveni začít používat rozhraní příkazového řádku pro tento scénář analýzy mínění.
Poznámka
Po dokončení tohoto kurzu můžete také vyzkoušet s vlastními datovými sadami, pokud jsou připravené k použití pro některou z úloh ML aktuálně podporovaných ML.NET CLI Preview, což jsou binární klasifikace, klasifikace, regrese a doporučení.
Spuštění příkazu mlnet classification
Spusťte následující příkaz ML.NET CLI:
mlnet classification --dataset "yelp_labelled.txt" --label-col 1 --has-header false --train-time 10Tento příkaz spustí
mlnet classificationpříkaz:- pro úlohu MLklasifikace
- používá soubor
yelp_labelled.txtdatové sady jako trénovací a testovací datovou sadu (interně rozhraní příkazového řádku buď použije křížové ověření, nebo ho rozdělí na dvě datové sady, jednu pro trénování a druhou pro testování). - kde sloupec cíle, který chcete předpovědět (běžně označovaný jako popisek), je sloupec s indexem 1 (to je druhý sloupec, protože index je založený na nule).
- nepoužívá záhlaví souboru s názvy sloupců, protože tento konkrétní soubor datové sady záhlaví nemá.
- doba cílového průzkumu nebo trénování experimentu je 10 sekund
Zobrazí se výstup z rozhraní příkazového řádku podobný následujícímu:
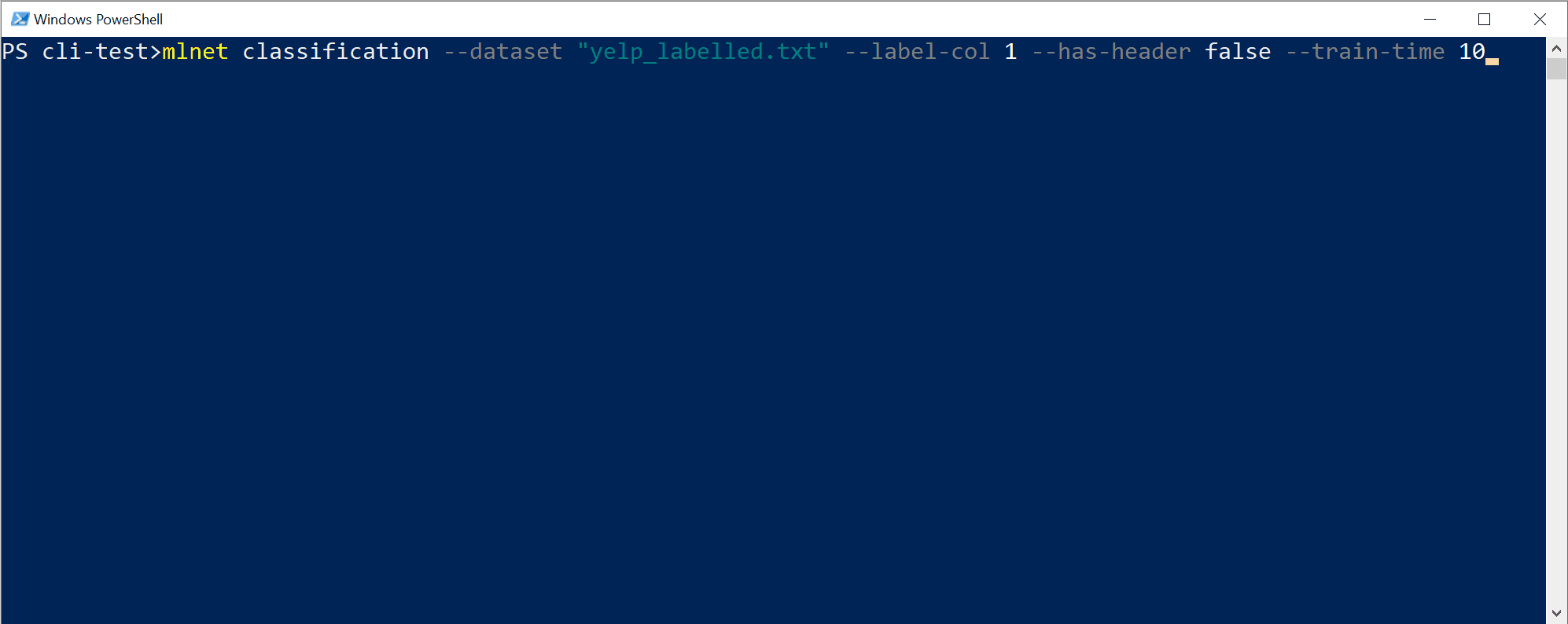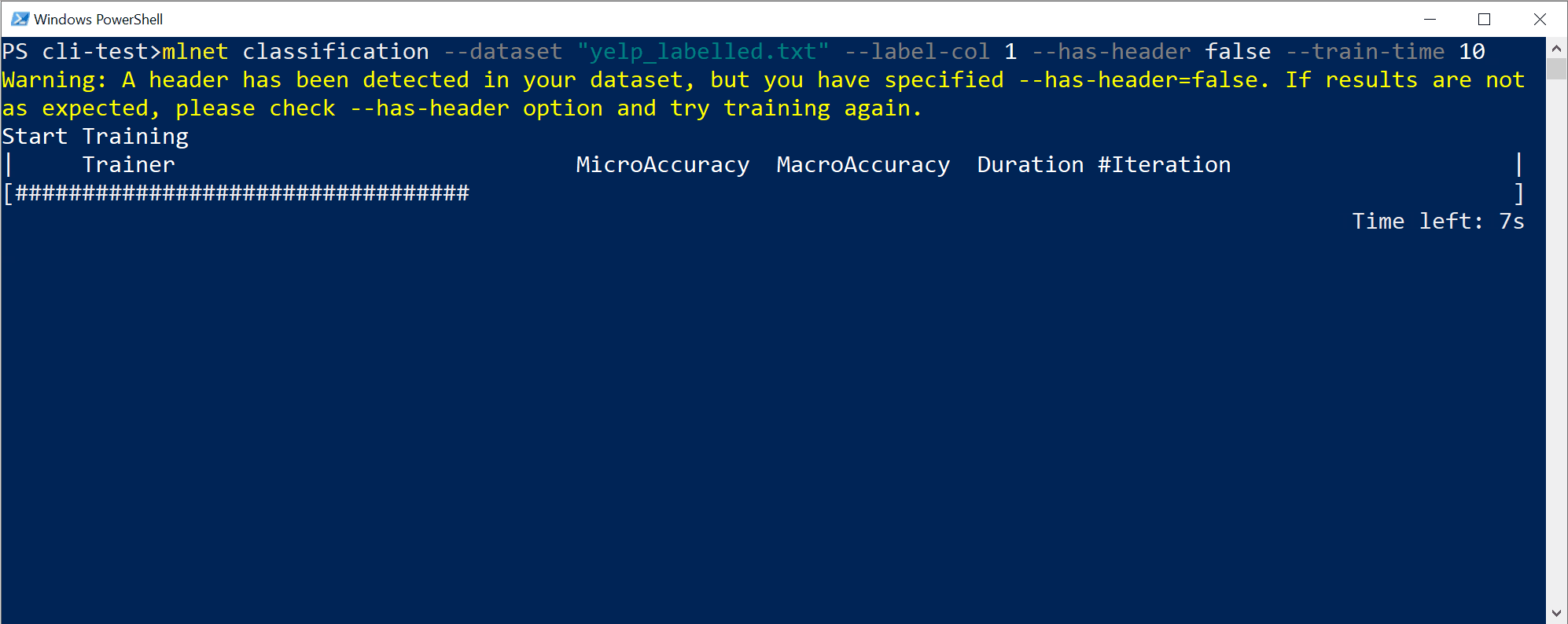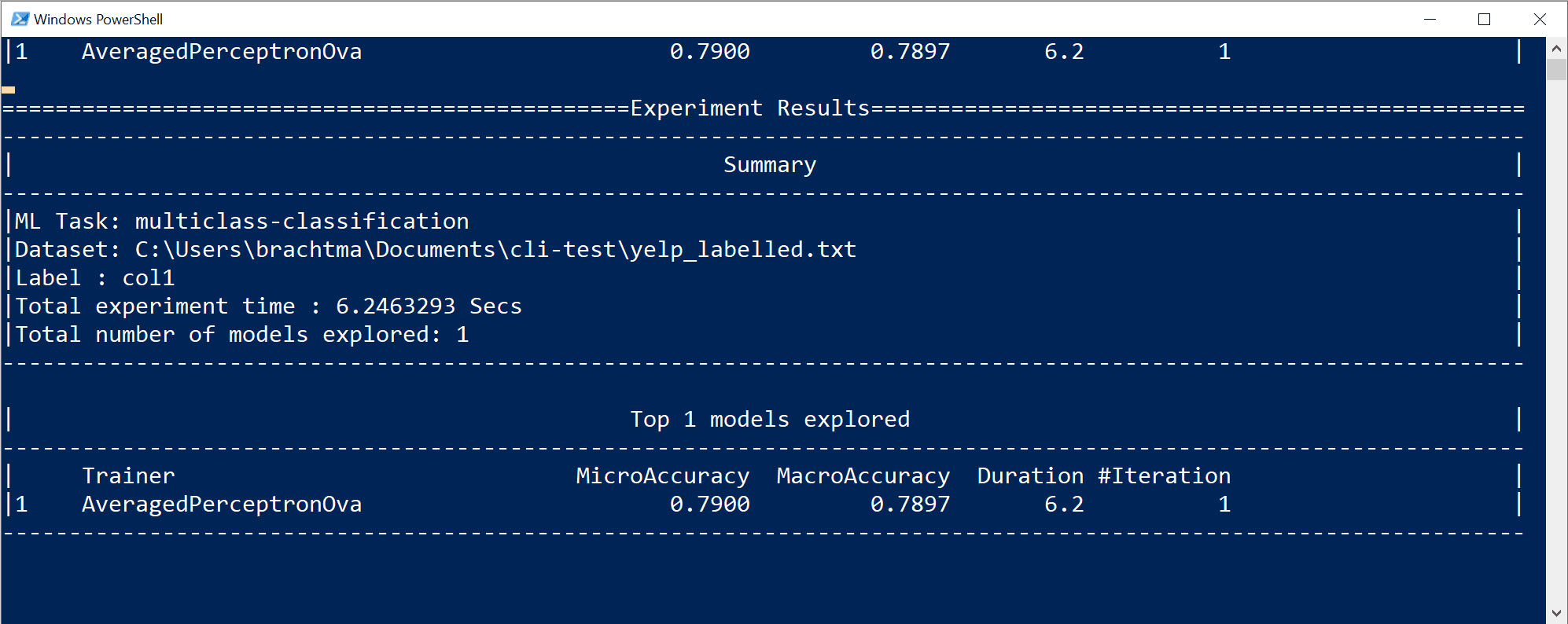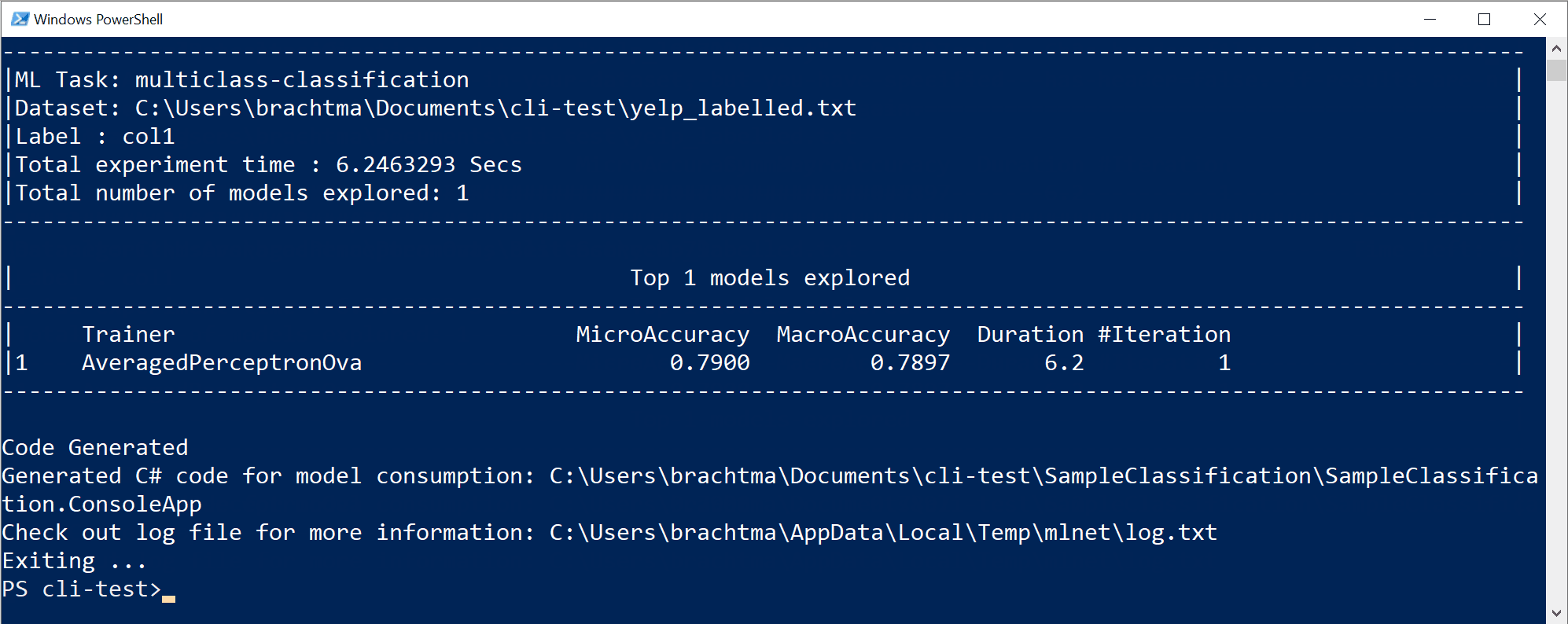
V tomto konkrétním případě během pouhých 10 sekund a s malou datovou sadou, kterou poskytuje, byl nástroj rozhraní příkazového řádku schopen spustit několik iterací, což znamená trénování vícekrát na základě různých kombinací algoritmů a konfigurace s různými interními transformacemi dat a hyperparametry algoritmu.
A konečně, model "nejvyšší kvality" nalezený za 10 sekund je model používající konkrétního trenéra nebo algoritmus s libovolnou konkrétní konfigurací. V závislosti na době zkoumání může příkaz vytvořit jiný výsledek. Výběr je založený na několika zobrazených metrikách, jako
Accuracyje .Vysvětlení metrik kvality modelu
První a nejsnadnější metrikou pro vyhodnocení modelu binární klasifikace je přesnost, která je snadno pochopitelná. "Přesnost je podíl správných předpovědí s testovací sadou dat.". Čím blíže ke 100 % (1,00), tím lépe.
Existují však případy, kdy pouhé měření pomocí metriky přesnosti nestačí, zejména pokud je popisek (v tomto případě 0 a 1) v testovací datové sadě nevyvážený.
Další metriky a podrobnější informace o metrikách , jako jsou Přesnost, AUC, AUCPR a skóre F1 použité k vyhodnocení různých modelů, najdete v tématu Principy metrik ML.NET.
Poznámka
Můžete vyzkoušet stejnou datovou sadu a zadat několik minut pro
--max-exploration-time(například tři minuty, abyste zadali 180 sekund), který pro vás najde lepší "nejlepší model" s jinou konfigurací trénovacího kanálu pro tuto datovou sadu (což je docela malý, 1 000 řádků).Pokud chcete najít model "nejlepší/dobrá kvalita", který je modelem připraveným pro produkční prostředí, který cílí na větší datové sady, měli byste provádět experimenty s rozhraním příkazového řádku, které obvykle určují mnohem delší dobu zkoumání v závislosti na velikosti datové sady. Ve skutečnosti můžete v mnoha případech vyžadovat více hodin doby zkoumání, zejména pokud je datová sada velká na řádcích a sloupcích.
Předchozí spuštění příkazu vygenerovalo následující prostředky:
- Serializovaný model .zip ("nejlepší model") připravený k použití.
- Kód jazyka C# ke spuštění/skóre, který vygeneroval model (k vytváření predikcí v aplikacích koncových uživatelů s tímto modelem).
- Trénovací kód jazyka C# použitý k vygenerování tohoto modelu (výukové účely).
- Soubor protokolu se všemi zkoumanými iteracemi s konkrétními podrobnými informacemi o každém algoritmu, který jste vyzkoušeli pomocí kombinace hyperpara parametrů a transformací dat.
První dva prostředky (.ZIP souborový model a kód jazyka C# pro spuštění modelu) se dají přímo použít v aplikacích koncových uživatelů (ASP.NET Core webové aplikace, služby, desktopová aplikace atd.) k vytváření předpovědí s tímto vygenerovaným modelem ML.
Třetí prostředek, trénovací kód, ukazuje, jaký kód ML.NET rozhraní API rozhraní příkazového řádku použilo k trénování vygenerovaného modelu, takže můžete prozkoumat, jaký konkrétní trenér/algoritmus a hyperparametry rozhraní příkazového řádku vybralo.
Tyto výčtové prostředky jsou vysvětleny v následujících krocích kurzu.
Prozkoumejte vygenerovaný kód jazyka C#, který se použije ke spuštění modelu k vytváření předpovědí.
V sadě Visual Studio otevřete řešení vygenerované ve složce s názvem
SampleClassificationv původní cílové složce (v kurzu bylo pojmenováno/cli-test). Mělo by se zobrazit řešení podobné následujícímu: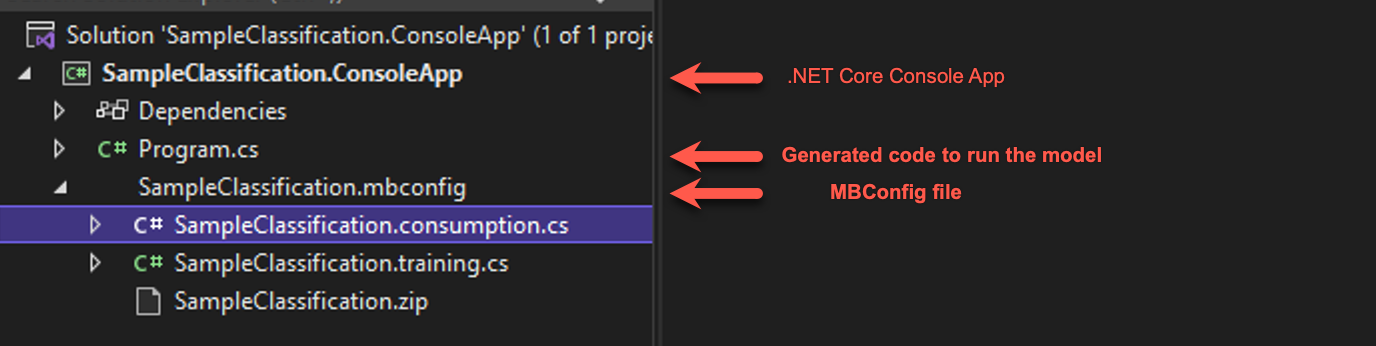
Poznámka
V tomto kurzu doporučujeme použít Visual Studio, ale můžete také prozkoumat vygenerovaný kód C# (dva projekty) v libovolném textovém editoru a spustit vygenerovanou konzolovou aplikaci na počítači s
dotnet CLImacOS, Linuxem nebo Windows.- Vygenerovaná konzolová aplikace obsahuje spouštěcí kód, který musíte zkontrolovat, a pak obvykle znovu použijete bodovací kód (kód, který spouští model ML pro vytváření predikcí) přesunutím jednoduchého kódu (jen několik řádků) do aplikace koncového uživatele, kde chcete předpovědi provádět.
- Vygenerovaný soubor mbconfig je konfigurační soubor, který lze použít k opětovnému trénování modelu, a to buď prostřednictvím rozhraní příkazového řádku, nebo prostřednictvím Tvůrce modelů. K tomu budou přidruženy také dva soubory kódu a soubor ZIP.
- Trénovací soubor obsahuje kód pro sestavení kanálu modelu pomocí rozhraní API ML.NET.
- Soubor consumption obsahuje kód pro využití modelu.
- Soubor zip , který je modelem vygenerovaným z rozhraní příkazového řádku.
Otevřete soubor SampleClassification.consumption.cs v souboru mbconfig . Uvidíte, že existují vstupní a výstupní třídy. Jedná se o datové třídy neboli třídy POCO, které se používají k uchovávání dat. Třídy obsahují často používaný kód, který je užitečný, pokud má datová sada desítky nebo dokonce stovky sloupců.
- Třída se
ModelInputpoužívá při čtení dat z datové sady. - Třída
ModelOutputse používá k získání výsledku předpovědi (prediktivních dat).
- Třída se
Otevřete soubor Program.cs a prozkoumejte kód. Na několika řádcích můžete model spustit a vytvořit ukázkovou predikci.
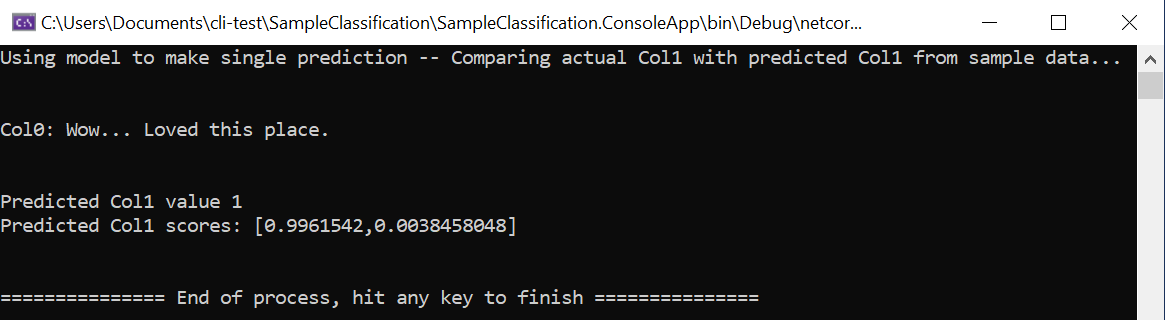
static void Main(string[] args) { // Create single instance of sample data from first line of dataset for model input ModelInput sampleData = new ModelInput() { Col0 = @"Wow... Loved this place.", }; // Make a single prediction on the sample data and print results var predictionResult = SampleClassification.Predict(sampleData); Console.WriteLine("Using model to make single prediction -- Comparing actual Col1 with predicted Col1 from sample data...\n\n"); Console.WriteLine($"Col0: {sampleData.Col0}"); Console.WriteLine($"\n\nPredicted Col1 value {predictionResult.PredictedLabel} \nPredicted Col1 scores: [{String.Join(",", predictionResult.Score)}]\n\n"); Console.WriteLine("=============== End of process, hit any key to finish ==============="); Console.ReadKey(); }První řádky kódu vytvoří jedno ukázkové data, v tomto případě na základě prvního řádku datové sady, který se použije pro předpověď. Aktualizací kódu můžete také vytvořit vlastní pevně zakódovaná data:
ModelInput sampleData = new ModelInput() { Col0 = "The ML.NET CLI is great for getting started. Very cool!" };Další řádek kódu používá metodu
SampleClassification.Predict()pro zadaná vstupní data k vytvoření předpovědi a vrácení výsledků (na základě schématu ModelOutput.cs).Poslední řádky kódu vypisují vlastnosti ukázkových dat (v tomto případě Komentář), předpověď mínění a odpovídající skóre pozitivního mínění (1) a negativního mínění (2).
Spusťte projekt buď pomocí původních ukázkových dat načtených z prvního řádku datové sady, nebo zadáním vlastních pevně zakódovaných ukázkových dat. Měli byste získat předpověď srovnatelnou s:
 ).
).
- Zkuste změnit pevně zakódovaná ukázková data na jiné věty s jiným míněním a podívejte se, jak model predikuje pozitivní nebo negativní mínění.
Využití aplikací koncových uživatelů pomocí predikcí modelů ML
Podobný kód vyhodnocení modelu ML můžete použít ke spuštění modelu v aplikaci koncového uživatele a k vytváření předpovědí.
Tento kód můžete například přesunout přímo do jakékoli desktopové aplikace pro Windows, jako je WPF a WinForms , a spustit model stejným způsobem jako v aplikaci konzoly.
Způsob, jakým implementujete tyto řádky kódu pro spuštění modelu ML, by ale měl být optimalizovaný (to znamená, že soubor modelu .zip uložíte do mezipaměti a načtete ho jednou) a nebudete je vytvářet při každém požadavku, zejména pokud vaše aplikace potřebuje být škálovatelná, jako je webová aplikace nebo distribuovaná služba, jak je vysvětleno v následující části.
Spouštění modelů ML.NET ve škálovatelných webových aplikacích a službách ASP.NET Core (aplikace s více vlákny)
Vytvoření objektu modelu (ITransformer načteného ze souboru .zip modelu) a objektu PredictionEngine by měly být optimalizované zejména při spuštění ve škálovatelných webových aplikacích a distribuovaných službách. V prvním případě je optimalizace objektu modelu (ITransformer) jednoduchá. Vzhledem k tomu, že ITransformer je objekt bezpečný pro přístup z více vláken, můžete ho uložit do mezipaměti jako jednoúčelový nebo statický objekt, abyste model načetli jednou.
U druhého objektu, objektuPredictionEngine, to není tak jednoduché, protože PredictionEngine objekt není bezpečný pro přístup z více vláken, a proto v aplikaci ASP.NET Core nemůžete vytvořit instanci tohoto objektu jako jednoúčelového nebo statického objektu. Tento problém s bezpečným vláknem a škálovatelností je podrobně popsán v tomto příspěvku na blogu.
Věci pro vás ale byly mnohem jednodušší než to, co je vysvětleno v příspěvku na blogu. Zapracovali jsme na jednodušším přístupu a vytvořili jsme pěkný integrační balíček .NET Core, který můžete snadno použít ve svých ASP.NET Core aplikacích a službách tak, že ho zaregistrujete ve službách DI aplikace (služby injektáže závislostí) a pak ho použijete přímo ze svého kódu. Projděte si následující kurz a příklad:
- Kurz: Spouštění modelů ML.NET ve škálovatelných webových aplikacích ASP.NET Core a webových rozhraních API
- Ukázka: Škálovatelný model ML.NET na ASP.NET Core WebAPI
Prozkoumejte vygenerovaný kód C#, který se použil k trénování modelu "nejvyšší kvality".
Pro pokročilejší účely výuky můžete také prozkoumat vygenerovaný kód jazyka C#, který nástroj rozhraní příkazového řádku použil k trénování vygenerovaného modelu.
Tento kód trénovacího modelu se vygeneruje v souboru s názvem SampleClassification.training.cs, abyste ho mohli prozkoumat.
Důležitější je, že pro tento konkrétní scénář (model Analýzy mínění) můžete také porovnat vygenerovaný trénovací kód s kódem vysvětleným v následujícím kurzu:
Je zajímavé porovnat zvolený algoritmus a konfiguraci kanálu v tomto kurzu s kódem vygenerovaným nástrojem cli. V závislosti na tom, kolik času strávíte iterací a hledáním lepších modelů, se zvolený algoritmus může lišit spolu s konkrétními hyperparametry a konfigurací kanálu.
V tomto kurzu jste se naučili:
- Příprava dat pro vybranou úlohu ML (problém, který se má vyřešit)
- Spuštění příkazu mlnet classification v nástroji CLI
- Kontrola výsledků metrik kvality
- Vysvětlení vygenerovaného kódu C# pro spuštění modelu (kód pro použití v aplikaci koncového uživatele)
- Prozkoumejte vygenerovaný kód C#, který se použil k trénování modelu "nejvyšší kvality" (pro účely získávání).
Viz také
- Automatizace trénování modelu pomocí rozhraní příkazového řádku ML.NET
- Kurz: Spouštění modelů ML.NET ve škálovatelných webových aplikacích ASP.NET Core a webových rozhraních API
- Ukázka: Škálovatelný model ML.NET na ASP.NET Core WebAPI
- Referenční příručka k příkazům automatického trénovat ML.NET CLI
- Telemetrie v ML.NET CLI
Spolupracujte s námi na GitHubu
Zdroj tohoto obsahu najdete na GitHubu, kde můžete také vytvářet a kontrolovat problémy a žádosti o přijetí změn. Další informace najdete v našem průvodci pro přispěvatele.