Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
System.IO.Pipelines je knihovna, která je navržená tak, aby usnadnila provádění vysoce výkonných vstupně-výstupních operací v .NET. Jedná se o knihovnu, která cílí na .NET Standard, která funguje na všech implementacích .NET.
Knihovna je k dispozici v balíčku NuGet System.IO.Pipelines .
Jaký problém řeší System.IO.Pipelines
Aplikace, které analyzují streamovaná data, se skládají z často používaného kódu, který má mnoho specializovaných a neobvyklých toků kódu. Často používaný a speciální kód případu je složitý a obtížně udržovatelná.
System.IO.Pipelines byl navržen tak, aby:
- Analýza streamovaných dat s vysokým výkonem
- Snižte složitost kódu.
Následující kód je typický pro server TCP, který přijímá zprávy oddělené řádky (oddělené ) '\n'od klienta:
async Task ProcessLinesAsync(NetworkStream stream)
{
var buffer = new byte[1024];
await stream.ReadAsync(buffer, 0, buffer.Length);
// Process a single line from the buffer
ProcessLine(buffer);
}
Předchozí kód má několik problémů:
- Celá zpráva (konec řádku) nemusí být přijata v jednom volání
ReadAsync. - Ignoruje výsledek
stream.ReadAsync.stream.ReadAsyncvrátí, kolik dat bylo přečteno. - Nezpracuje případ, kdy se v jednom
ReadAsyncvolání čte více řádků. - Přiděluje
bytepole s každým čtením.
Chcete-li vyřešit předchozí problémy, jsou vyžadovány následující změny:
Uložení příchozích dat do vyrovnávací paměti, dokud se nenajde nový řádek.
Parsujte všechny řádky vrácené v vyrovnávací paměti.
Je možné, že čára je větší než 1 kB (1024 bajtů). Kód musí změnit velikost vstupní vyrovnávací paměti, dokud se nenajde oddělovač, aby se do vyrovnávací paměti nevešel celý řádek.
- Pokud se velikost vyrovnávací paměti změní, vytvoří se více kopií vyrovnávací paměti, jakmile se ve vstupu zobrazí delší řádky.
- Pokud chcete snížit plýtvání místem, zkomprimujte vyrovnávací paměť použitou pro čtecí čáry.
Zvažte použití sdružování vyrovnávacích pamětí, abyste se vyhnuli opakovanému přidělování paměti.
Následující kód řeší některé z těchto problémů:
async Task ProcessLinesAsync(NetworkStream stream)
{
byte[] buffer = ArrayPool<byte>.Shared.Rent(1024);
var bytesBuffered = 0;
var bytesConsumed = 0;
while (true)
{
// Calculate the amount of bytes remaining in the buffer.
var bytesRemaining = buffer.Length - bytesBuffered;
if (bytesRemaining == 0)
{
// Double the buffer size and copy the previously buffered data into the new buffer.
var newBuffer = ArrayPool<byte>.Shared.Rent(buffer.Length * 2);
Buffer.BlockCopy(buffer, 0, newBuffer, 0, buffer.Length);
// Return the old buffer to the pool.
ArrayPool<byte>.Shared.Return(buffer);
buffer = newBuffer;
bytesRemaining = buffer.Length - bytesBuffered;
}
var bytesRead = await stream.ReadAsync(buffer, bytesBuffered, bytesRemaining);
if (bytesRead == 0)
{
// EOF
break;
}
// Keep track of the amount of buffered bytes.
bytesBuffered += bytesRead;
var linePosition = -1;
do
{
// Look for a EOL in the buffered data.
linePosition = Array.IndexOf(buffer, (byte)'\n', bytesConsumed,
bytesBuffered - bytesConsumed);
if (linePosition >= 0)
{
// Calculate the length of the line based on the offset.
var lineLength = linePosition - bytesConsumed;
// Process the line.
ProcessLine(buffer, bytesConsumed, lineLength);
// Move the bytesConsumed to skip past the line consumed (including \n).
bytesConsumed += lineLength + 1;
}
}
while (linePosition >= 0);
}
}
Předchozí kód je složitý a neřeší všechny zjištěné problémy. Vysoce výkonné sítě obvykle znamenají psaní složitého kódu pro maximalizaci výkonu.
System.IO.Pipelines byl navržen tak, aby usnadnil psaní tohoto typu kódu.
Potrubí
Třídu Pipe lze použít k vytvoření páru PipeWriter/PipeReader . Všechna data zapsaná do služby PipeWriter jsou k dispozici v :PipeReader
var pipe = new Pipe();
PipeReader reader = pipe.Reader;
PipeWriter writer = pipe.Writer;
Základní využití kanálu
async Task ProcessLinesAsync(Socket socket)
{
var pipe = new Pipe();
Task writing = FillPipeAsync(socket, pipe.Writer);
Task reading = ReadPipeAsync(pipe.Reader);
await Task.WhenAll(reading, writing);
}
async Task FillPipeAsync(Socket socket, PipeWriter writer)
{
const int minimumBufferSize = 512;
while (true)
{
// Allocate at least 512 bytes from the PipeWriter.
Memory<byte> memory = writer.GetMemory(minimumBufferSize);
try
{
int bytesRead = await socket.ReceiveAsync(memory, SocketFlags.None);
if (bytesRead == 0)
{
break;
}
// Tell the PipeWriter how much was read from the Socket.
writer.Advance(bytesRead);
}
catch (Exception ex)
{
LogError(ex);
break;
}
// Make the data available to the PipeReader.
FlushResult result = await writer.FlushAsync();
if (result.IsCompleted)
{
break;
}
}
// By completing PipeWriter, tell the PipeReader that there's no more data coming.
await writer.CompleteAsync();
}
async Task ReadPipeAsync(PipeReader reader)
{
while (true)
{
ReadResult result = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = result.Buffer;
while (TryReadLine(ref buffer, out ReadOnlySequence<byte> line))
{
// Process the line.
ProcessLine(line);
}
// Tell the PipeReader how much of the buffer has been consumed.
reader.AdvanceTo(buffer.Start, buffer.End);
// Stop reading if there's no more data coming.
if (result.IsCompleted)
{
break;
}
}
// Mark the PipeReader as complete.
await reader.CompleteAsync();
}
bool TryReadLine(ref ReadOnlySequence<byte> buffer, out ReadOnlySequence<byte> line)
{
// Look for a EOL in the buffer.
SequencePosition? position = buffer.PositionOf((byte)'\n');
if (position == null)
{
line = default;
return false;
}
// Skip the line + the \n.
line = buffer.Slice(0, position.Value);
buffer = buffer.Slice(buffer.GetPosition(1, position.Value));
return true;
}
Existují dvě smyčky:
-
FillPipeAsyncčte zSocketa zápisů doPipeWriter. -
ReadPipeAsyncčte z příchozíchPipeReaderřádků a parsuje je.
Nejsou přiděleny žádné explicitní vyrovnávací paměti. Veškerá správa vyrovnávací paměti se deleguje na PipeReader implementace a PipeWriter implementace. Delegování správy vyrovnávacích pamětí usnadňuje využívání kódu výhradně na obchodní logiku.
V první smyčce:
- PipeWriter.GetMemory(Int32) je volána pro získání paměti z podkladového zapisovače.
-
PipeWriter.Advance(Int32) je volána, aby bylo určeno,
PipeWriterkolik dat bylo zapsáno do vyrovnávací paměti. -
PipeWriter.FlushAsync je volána pro zpřístupnění dat
PipeReader.
Ve druhé smyčce PipeReader spotřebovává vyrovnávací paměti zapsané PipeWriterpomocí . Vyrovnávací paměti pocházejí ze zásuvky. Volání:PipeReader.ReadAsync
ReadResult Vrátí hodnotu, která obsahuje dva důležité informace:
- Data, která byla načtena ve formě
ReadOnlySequence<byte>. - Logická hodnota
IsCompleted, která označuje, jestli bylo dosaženo konce dat (EOF).
- Data, která byla načtena ve formě
Po nalezení oddělovače konce řádku (EOL) a parsování řádku:
- Logika zpracovává vyrovnávací paměť tak, aby přeskočí, co už bylo zpracováno.
-
PipeReader.AdvanceToje volána, aby bylo zjistitPipeReader, kolik dat bylo spotřebováno a zkoumáno.
Čtečka a zapisovač smyčky končí voláním Complete.
Complete umožňuje podkladovému kanálu uvolnit přidělenou paměť.
Zpětný tlak a řízení toku
V ideálním případě spolupracují čtení a analýza:
- Vlákno pro čtení využívá data ze sítě a vkládá je do vyrovnávacích pamětí.
- Vlákno analýzy zodpovídá za vytvoření odpovídajících datových struktur.
Analýza obvykle trvá déle než pouhé kopírování bloků dat ze sítě:
- Vlákno čtení před vláknem analýzy.
- Vlákno čtení musí zpomalit nebo přidělit více paměti pro uložení dat pro vlákno analýzy.
Pro zajištění optimálního výkonu existuje rovnováhu mezi častými pozastaveními a přidělením více paměti.
Pokud chcete vyřešit předchozí problém, Pipe má dvě nastavení pro řízení toku dat:
- PauseWriterThreshold: Určuje, kolik dat by se mělo ukládat do vyrovnávací paměti před voláním k FlushAsync pozastavení.
-
ResumeWriterThreshold: Určuje, kolik dat musí čtenář sledovat před voláním k
PipeWriter.FlushAsyncobnovení.
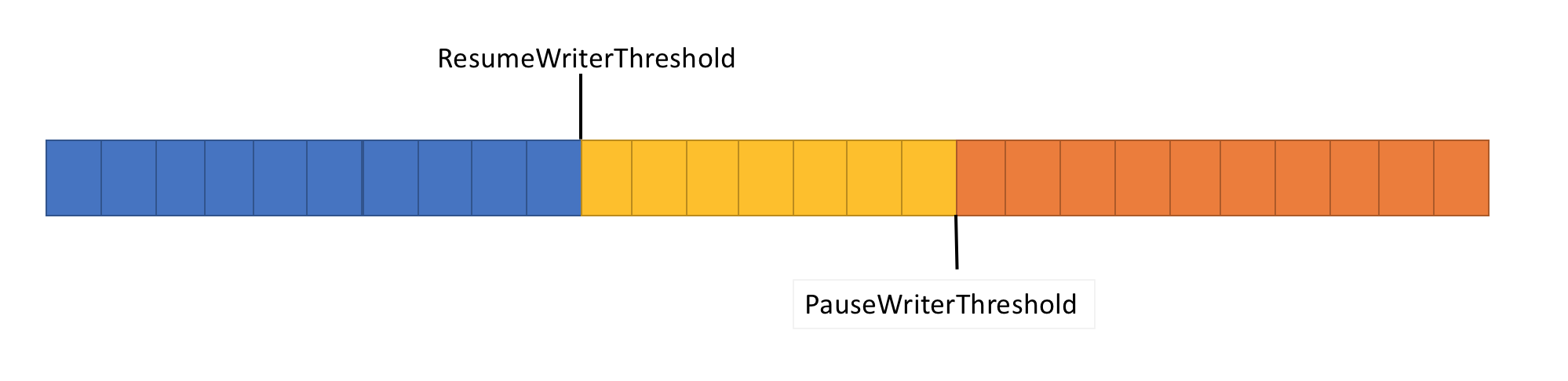
- Vrátí neúplnou
ValueTask<FlushResult>hodnotu, když množství dat vPipekřížíchPauseWriterThreshold. - Dokončí se, jakmile
ValueTask<FlushResult>bude nižší nežResumeWriterThreshold.
Dvě hodnoty se používají k prevenci rychlého cyklistiky, ke kterému může dojít, pokud se použije jedna hodnota.
Příklady
// The Pipe will start returning incomplete tasks from FlushAsync until
// the reader examines at least 5 bytes.
var options = new PipeOptions(pauseWriterThreshold: 10, resumeWriterThreshold: 5);
var pipe = new Pipe(options);
Plánovač potrubí
Obvykle při použití async a await, asynchronní kód pokračuje na nebo TaskScheduler aktuální SynchronizationContext.
Při provádění vstupně-výstupních operací je důležité mít jemně odstupňovanou kontrolu nad tím, kde se vstupně-výstupní operace provádí. Tento ovládací prvek umožňuje efektivně využívat mezipaměti procesoru. Efektivní ukládání do mezipaměti je důležité pro vysoce výkonné aplikace, jako jsou webové servery. PipeScheduler poskytuje kontrolu nad tím, kde se spouští asynchronní zpětná volání. Standardně:
- Použije se aktuální.SynchronizationContext
- Pokud neexistuje,
SynchronizationContextpoužívá fond vláken ke spouštění zpětných volání.
public static void Main(string[] args)
{
var writeScheduler = new SingleThreadPipeScheduler();
var readScheduler = new SingleThreadPipeScheduler();
// Tell the Pipe what schedulers to use and disable the SynchronizationContext.
var options = new PipeOptions(readerScheduler: readScheduler,
writerScheduler: writeScheduler,
useSynchronizationContext: false);
var pipe = new Pipe(options);
}
// This is a sample scheduler that async callbacks on a single dedicated thread.
public class SingleThreadPipeScheduler : PipeScheduler
{
private readonly BlockingCollection<(Action<object> Action, object State)> _queue =
new BlockingCollection<(Action<object> Action, object State)>();
private readonly Thread _thread;
public SingleThreadPipeScheduler()
{
_thread = new Thread(DoWork);
_thread.Start();
}
private void DoWork()
{
foreach (var item in _queue.GetConsumingEnumerable())
{
item.Action(item.State);
}
}
public override void Schedule(Action<object?> action, object? state)
{
if (state is not null)
{
_queue.Add((action, state));
}
// else log the fact that _queue.Add was not called.
}
}
PipeScheduler.ThreadPool je PipeScheduler implementace, která zařadí zpětná volání do fondu vláken.
PipeScheduler.ThreadPool je výchozí a obecně nejlepší volbou.
PipeScheduler.Inline může způsobit nezamýšlené důsledky, jako jsou zablokování.
Resetování potrubí
Často je efektivní objekt znovu použít Pipe . Pokud chcete kanál resetovat, zavolejte PipeReaderReset po PipeReader dokončení i PipeWriter po dokončení kanálu.
PipeReader
PipeReader spravuje paměť jménem volajícího.
Vždy zavolat PipeReader.AdvanceTo po volání PipeReader.ReadAsync. To informuje PipeReader o tom, kdy je volající hotový s pamětí, aby se mohl sledovat. Vrácená ReadOnlySequence<byte> hodnota PipeReader.ReadAsync je platná pouze do volání PipeReader.AdvanceTo. Je nezákonné používat ReadOnlySequence<byte> po volání PipeReader.AdvanceTo.
PipeReader.AdvanceTo přebírá dva SequencePosition argumenty:
- První argument určuje, kolik paměti bylo spotřebováno.
- Druhý argument určuje, kolik vyrovnávací paměti bylo zjištěno.
Označení dat jako spotřebovaných znamená, že kanál může vrátit paměť do základního fondu vyrovnávací paměti. Označení dat jako pozorovaných řídí, co má další volání PipeReader.ReadAsync dělat. Označení všeho, co bylo zjištěno, znamená, že další volání PipeReader.ReadAsync se nevrátí, dokud se do kanálu nezapíšou další data. Jakákoli jiná hodnota provede další volání, které se PipeReader.ReadAsync okamžitě vrátí s pozorovanými a neobsazenými daty, ale ne s daty, která už byla spotřebována.
Scénáře čtení streamovaných dat
Při pokusu o čtení streamovaných dat se objeví několik typických vzorů:
- Při použití datového proudu parste jednu zprávu.
- Vzhledem k datovému proudu analyzují všechny dostupné zprávy.
Následující příklady používají metodu TryParseLines pro analýzu zpráv z objektu .ReadOnlySequence<byte>
TryParseLines parsuje jednu zprávu a aktualizuje vstupní vyrovnávací paměť, aby ořízla analyzovanou zprávu z vyrovnávací paměti.
TryParseLines není součástí .NET, jedná se o metodu napsanou uživatelem používanou v následujících částech.
bool TryParseLines(ref ReadOnlySequence<byte> buffer, out Message message);
Čtení jedné zprávy
Následující kód přečte jednu zprávu z volajícího PipeReader a vrátí ji volajícímu.
async ValueTask<Message?> ReadSingleMessageAsync(PipeReader reader,
CancellationToken cancellationToken = default)
{
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
// In the event that no message is parsed successfully, mark consumed
// as nothing and examined as the entire buffer.
SequencePosition consumed = buffer.Start;
SequencePosition examined = buffer.End;
try
{
if (TryParseLines(ref buffer, out Message message))
{
// A single message was successfully parsed so mark the start of the
// parsed buffer as consumed. TryParseLines trims the buffer to
// point to the data after the message was parsed.
consumed = buffer.Start;
// Examined is marked the same as consumed here, so the next call
// to ReadSingleMessageAsync will process the next message if there's
// one.
examined = consumed;
return message;
}
// There's no more data to be processed.
if (result.IsCompleted)
{
if (buffer.Length > 0)
{
// The message is incomplete and there's no more data to process.
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
reader.AdvanceTo(consumed, examined);
}
}
return null;
}
Předchozí kód:
- Parsuje jednu zprávu.
- Aktualizuje spotřebovanou
SequencePositiona prověřovanouSequencePosition, aby ukazovala na začátek oříznuté vstupní vyrovnávací paměti.
Tyto dva SequencePosition argumenty jsou aktualizovány, protože TryParseLines odebere analyzovanou zprávu ze vstupní vyrovnávací paměti. Obecně platí, že při analýze jedné zprávy z vyrovnávací paměti by hodnocená pozice měla být jedna z těchto věcí:
- Konec zprávy.
- Konec přijaté vyrovnávací paměti, pokud nebyla nalezena žádná zpráva.
Jeden případ zprávy má největší potenciál pro chyby. Předání nesprávných hodnot ke zkoumání může vést k výjimce nedostatku paměti nebo nekonečné smyčce. Další informace naleznete v části Běžné problémy PipeReader v tomto článku.
Čtení více zpráv
Následující kód načte všechny zprávy z PipeReader každého z nich a volá ProcessMessageAsync je.
async Task ProcessMessagesAsync(PipeReader reader, CancellationToken cancellationToken = default)
{
try
{
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
try
{
// Process all messages from the buffer, modifying the input buffer on each
// iteration.
while (TryParseLines(ref buffer, out Message message))
{
await ProcessMessageAsync(message);
}
// There's no more data to be processed.
if (result.IsCompleted)
{
if (buffer.Length > 0)
{
// The message is incomplete and there's no more data to process.
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
// Since all messages in the buffer are being processed, you can use the
// remaining buffer's Start and End position to determine consumed and examined.
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
finally
{
await reader.CompleteAsync();
}
}
Zrušení
PipeReader.ReadAsync:
- Podporuje předávání .CancellationToken
-
OperationCanceledException Vyvolá chybu, pokud
CancellationTokenje zrušena, zatímco čeká na čtení. - Podporuje způsob, jak zrušit aktuální operaci čtení prostřednictvím PipeReader.CancelPendingRead, což zabraňuje vyvolání výjimky. Volání
PipeReader.CancelPendingReadzpůsobí, že aktuální nebo další voláníPipeReader.ReadAsyncvrátí hodnotu s ReadResult nastavenouIsCanceledtruehodnotou . To může být užitečné pro zastavení stávající smyčky čtení nedestruktivním a nevýkonným způsobem.
private PipeReader reader;
public MyConnection(PipeReader reader)
{
this.reader = reader;
}
public void Abort()
{
// Cancel the pending read so the process loop ends without an exception.
reader.CancelPendingRead();
}
public async Task ProcessMessagesAsync()
{
try
{
while (true)
{
ReadResult result = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = result.Buffer;
try
{
if (result.IsCanceled)
{
// The read was canceled. You can quit without reading the existing data.
break;
}
// Process all messages from the buffer, modifying the input buffer on each
// iteration.
while (TryParseLines(ref buffer, out Message message))
{
await ProcessMessageAsync(message);
}
// There's no more data to be processed.
if (result.IsCompleted)
{
break;
}
}
finally
{
// Since all messages in the buffer are being processed, you can use the
// remaining buffer's Start and End position to determine consumed and examined.
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
finally
{
await reader.CompleteAsync();
}
}
Běžné problémy s PipeReader
Předání nesprávných hodnot nebo
consumedmůže vést keexaminedčtení dat, která jsou už přečtená.Předání
buffer.End, které bylo zkoumáno, může mít za následek:- Pozastavená data
- Případná výjimka typu Nedostatek paměti (OOM), pokud se data nespotřebovávají. Například
PipeReader.AdvanceTo(position, buffer.End)při zpracování jedné zprávy najednou z vyrovnávací paměti.
Předání nesprávných hodnot nebo
consumedmůže vést kexaminednekonečné smyčce. PokudPipeReader.AdvanceTo(buffer.Start)se například nezměnila,buffer.Startdalší voláníPipeReader.ReadAsyncse vrátí okamžitě před příchodem nových dat.Předání nesprávných hodnot nebo
consumedmůže vést kexaminednekonečnému ukládání do vyrovnávací paměti (případný OOM).ReadOnlySequence<byte>Použití volání po voláníPipeReader.AdvanceTomůže vést k poškození paměti (použití po uvolnění).Selhání volání
PipeReader.Complete/CompleteAsyncmůže způsobit nevrácení paměti.Kontrola ReadResult.IsCompleted a ukončení logiky čtení před zpracováním vyrovnávací paměti způsobí ztrátu dat. Podmínka ukončení smyčky by měla být založena na
ReadResult.Buffer.IsEmptyaReadResult.IsCompleted. Když to uděláte nesprávně, může to vést k nekonečné smyčce.
Problematický kód
❌ Ztráta dat
Může ReadResult vrátit poslední segment dat, pokud IsCompleted je nastavena na true. Nepřečtení dat před ukončením smyčky čtení způsobí ztrátu dat.
Upozorňující
Nepoužívejte následující kód. Použití této ukázky způsobí ztrátu dat, zablokování, problémy se zabezpečením a nemělo by se kopírovat. Následující ukázka je k dispozici pro vysvětlení běžných problémů PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> dataLossBuffer = result.Buffer;
if (result.IsCompleted)
break;
Process(ref dataLossBuffer, out Message message);
reader.AdvanceTo(dataLossBuffer.Start, dataLossBuffer.End);
}
Upozorňující
Nepoužívejte předchozí kód. Použití této ukázky způsobí ztrátu dat, zablokování, problémy se zabezpečením a nemělo by se kopírovat. Předchozí ukázka je k dispozici k vysvětlení běžných problémů PipeReader.
❌ Nekonečná smyčka
Následující logika může vést k nekonečné smyčce, pokud je, Result.IsCompletedtrue ale v vyrovnávací paměti není nikdy úplná zpráva.
Upozorňující
Nepoužívejte následující kód. Použití této ukázky způsobí ztrátu dat, zablokování, problémy se zabezpečením a nemělo by se kopírovat. Následující ukázka je k dispozici pro vysvětlení běžných problémů PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> infiniteLoopBuffer = result.Buffer;
if (result.IsCompleted && infiniteLoopBuffer.IsEmpty)
break;
Process(ref infiniteLoopBuffer, out Message message);
reader.AdvanceTo(infiniteLoopBuffer.Start, infiniteLoopBuffer.End);
}
Upozorňující
Nepoužívejte předchozí kód. Použití této ukázky způsobí ztrátu dat, zablokování, problémy se zabezpečením a nemělo by se kopírovat. Předchozí ukázka je k dispozici k vysvětlení běžných problémů PipeReader.
Tady je další část kódu se stejným problémem. Před kontrolou ReadResult.IsCompletedkontroluje neprázdnou vyrovnávací paměť . Protože je ve smyčce else if, bude smyčka navždy, pokud v vyrovnávací paměti nikdy není úplná zpráva.
Upozorňující
Nepoužívejte následující kód. Použití této ukázky způsobí ztrátu dat, zablokování, problémy se zabezpečením a nemělo by se kopírovat. Následující ukázka je k dispozici pro vysvětlení běžných problémů PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> infiniteLoopBuffer = result.Buffer;
if (!infiniteLoopBuffer.IsEmpty)
Process(ref infiniteLoopBuffer, out Message message);
else if (result.IsCompleted)
break;
reader.AdvanceTo(infiniteLoopBuffer.Start, infiniteLoopBuffer.End);
}
Upozorňující
Nepoužívejte předchozí kód. Použití této ukázky způsobí ztrátu dat, zablokování, problémy se zabezpečením a nemělo by se kopírovat. Předchozí ukázka je k dispozici k vysvětlení běžných problémů PipeReader.
❌ Nereagující aplikace
Nepodmíněné volání PipeReader.AdvanceTo na buffer.Endexamined pozici může způsobit, že aplikace přestane reagovat při analýze jedné zprávy. Další volání, které PipeReader.AdvanceTo se nevrátí, dokud:
- Do kanálu se zapisuje další data.
- A nová data se ještě nezkoumala.
Upozorňující
Nepoužívejte následující kód. Použití této ukázky způsobí ztrátu dat, zablokování, problémy se zabezpečením a nemělo by se kopírovat. Následující ukázka je k dispozici pro vysvětlení běžných problémů PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> hangBuffer = result.Buffer;
Process(ref hangBuffer, out Message message);
if (result.IsCompleted)
break;
reader.AdvanceTo(hangBuffer.Start, hangBuffer.End);
if (message != null)
return message;
}
Upozorňující
Nepoužívejte předchozí kód. Použití této ukázky způsobí ztrátu dat, zablokování, problémy se zabezpečením a nemělo by se kopírovat. Předchozí ukázka je k dispozici k vysvětlení běžných problémů PipeReader.
❌ Nedostatek paměti (OOM)
S následujícími podmínkami se následující kód ukládá do vyrovnávací paměti, dokud OutOfMemoryException nedojde k:
- Neexistuje žádná maximální velikost zprávy.
- Data vrácená z této
PipeReaderzprávy neprovádí úplnou zprávu. Například se nevytvářá úplná zpráva, protože druhá strana píše velkou zprávu (například zpráva o velikosti 4 GB).
Upozorňující
Nepoužívejte následující kód. Použití této ukázky způsobí ztrátu dat, zablokování, problémy se zabezpečením a nemělo by se kopírovat. Následující ukázka je k dispozici pro vysvětlení běžných problémů PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> thisCouldOutOfMemory = result.Buffer;
Process(ref thisCouldOutOfMemory, out Message message);
if (result.IsCompleted)
break;
reader.AdvanceTo(thisCouldOutOfMemory.Start, thisCouldOutOfMemory.End);
if (message != null)
return message;
}
Upozorňující
Nepoužívejte předchozí kód. Použití této ukázky způsobí ztrátu dat, zablokování, problémy se zabezpečením a nemělo by se kopírovat. Předchozí ukázka je k dispozici k vysvětlení běžných problémů PipeReader.
❌ Poškození paměti
Při zápisu pomocných rutin, které čtou vyrovnávací paměť, by se všechny vrácené datové části měly před voláním Advancezkopírovat . Následující příklad vrátí paměť, která Pipe byla zahozena a může ji znovu použít pro další operaci (čtení/zápis).
Upozorňující
Nepoužívejte následující kód. Použití této ukázky způsobí ztrátu dat, zablokování, problémy se zabezpečením a nemělo by se kopírovat. Následující ukázka je k dispozici pro vysvětlení běžných problémů PipeReader.
public class Message
{
public ReadOnlySequence<byte> CorruptedPayload { get; set; }
}
Environment.FailFast("This code is terrible, don't use it!");
Message message = null;
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
ReadHeader(ref buffer, out int length);
if (length <= buffer.Length)
{
message = new Message
{
// Slice the payload from the existing buffer
CorruptedPayload = buffer.Slice(0, length)
};
buffer = buffer.Slice(length);
}
if (result.IsCompleted)
break;
reader.AdvanceTo(buffer.Start, buffer.End);
if (message != null)
{
// This code is broken since reader.AdvanceTo() was called with a position *after* the buffer
// was captured.
break;
}
}
return message;
}
Upozorňující
Nepoužívejte předchozí kód. Použití této ukázky způsobí ztrátu dat, zablokování, problémy se zabezpečením a nemělo by se kopírovat. Předchozí ukázka je k dispozici k vysvětlení běžných problémů PipeReader.
PipeWriter
Spravuje PipeWriter vyrovnávací paměti pro zápis jménem volajícího.
PipeWriter implementuje IBufferWriter<byte>.
IBufferWriter<byte> umožňuje získat přístup k vyrovnávacím pamětím pro provádění zápisů bez dalších kopií vyrovnávací paměti.
async Task WriteHelloAsync(PipeWriter writer, CancellationToken cancellationToken = default)
{
// Request at least 5 bytes from the PipeWriter.
Memory<byte> memory = writer.GetMemory(5);
// Write directly into the buffer.
int written = Encoding.ASCII.GetBytes("Hello".AsSpan(), memory.Span);
// Tell the writer how many bytes were written.
writer.Advance(written);
await writer.FlushAsync(cancellationToken);
}
Předchozí kód:
- Požaduje vyrovnávací paměť nejméně 5 bajtů z
PipeWriterpoužití GetMemory. - Zapíše bajty pro řetězec
"Hello"ASCII do vrácenéMemory<byte>. - Volání Advance označující, kolik bajtů bylo zapsáno do vyrovnávací paměti.
- Vyprázdní
PipeWriter, který odešle bajty do podkladového zařízení.
Předchozí metoda zápisu používá vyrovnávací paměti poskytované PipeWriter. Mohl by také použít PipeWriter.WriteAsync, což:
- Zkopíruje existující vyrovnávací paměť do
PipeWritersouboru . - Volání
GetSpan,Advancepodle potřeby a volání FlushAsync.
async Task WriteHelloAsync(PipeWriter writer, CancellationToken cancellationToken = default)
{
byte[] helloBytes = Encoding.ASCII.GetBytes("Hello");
// Write helloBytes to the writer, there's no need to call Advance here
// (Write does that).
await writer.WriteAsync(helloBytes, cancellationToken);
}
Zrušení
FlushAsyncpodporuje předávání .CancellationToken
CancellationToken Předání výsledku OperationCanceledException v případě zrušení tokenu během čekání na vyprázdnění.
PipeWriter.FlushAsync podporuje způsob, jak zrušit aktuální operaci vyprázdnění prostřednictvím PipeWriter.CancelPendingFlush bez vyvolání výjimky. Volání PipeWriter.CancelPendingFlush způsobí, že aktuální nebo další volání PipeWriter.FlushAsync nebo PipeWriter.WriteAsync vrátí s FlushResult nastavenou IsCanceled hodnotou true. To může být užitečné pro zastavení vyprázdnění nedestruktivním a nevýkonným způsobem.
PipeWriter – běžné problémy
- GetSpan a GetMemory vrátit vyrovnávací paměť s alespoň požadovanou velikostí paměti. Nepředpokládáme přesné velikosti vyrovnávací paměti.
- Není zaručeno, že následná volání vrátí stejnou vyrovnávací paměť nebo vyrovnávací paměť stejné velikosti.
- Po volání Advance musí být požadována nová vyrovnávací paměť, aby bylo možné pokračovat v zápisu dalších dat. Dříve získanou vyrovnávací paměť nelze zapisovat do.
- Volání
GetMemoryneboGetSpannekompletní hovorFlushAsyncnení bezpečný. - Volání
CompleteneboCompleteAsyncv době, kdy dojde k nechyceným datům, může dojít k poškození paměti.
Tipy pro použití PipeReader a PipeWriter
Následující tipy vám pomůžou úspěšně používat System.IO.Pipelines třídy:
- Vždy dokončete PipeReader a PipeWriter, včetně výjimky, pokud je to možné.
- Vždy zavolat PipeReader.AdvanceTo po volání PipeReader.ReadAsync.
-
awaitPipeWriter.FlushAsync Pravidelně při psaní a vždy kontrolovat FlushResult.IsCompleted. Přerušte psaní, pokudIsCompletedjetrue, protože to znamená, že čtenář je dokončen a už se nezajímá o to, co je napsané. - Po napsání něčeho, ke kterému chcete PipeWriter.FlushAsync mít přístup, zavolejte
PipeReader. - Nezavolejte
FlushAsync, pokud čtečka nemůže začít doFlushAsyncdokončení, protože to může způsobit zablokování. - Ujistěte se, že pouze jeden kontext "vlastní"
PipeReaderneboPipeWriterk nim přistupuje. Tyto typy nejsou bezpečné pro přístup z více vláken. - Nikdy nepřistupujte k ReadResult.Buffer po volání
AdvanceTonebo dokončení .PipeReader
IDuplexPipe
Jedná se IDuplexPipe o kontrakt pro typy, které podporují čtení i psaní. Například síťové připojení by reprezentovalo .IDuplexPipe
Na rozdíl od Pipe, který obsahuje PipeReader a a PipeWriter, IDuplexPipe představuje jednu stranu úplného duplexního připojení. To znamená, co je zapsáno PipeWriter do nebude čteno z PipeReader.
Streamy
Při čtení nebo zápisu dat datového proudu obvykle čtete data pomocí de-serializátoru a zapisujete data pomocí serializátoru. Většina těchto rozhraní API pro čtení a zápis streamu má Stream parametr. Pro usnadnění integrace s těmito stávajícími rozhraními PipeReader API a PipeWriter zveřejnění AsStream metody.
AsStreamvrátí implementaci, která Stream se PipeReaderPipeWriter bude pohybovat v
Příklad streamu
PipeReader a PipeWriter instance lze vytvořit pomocí statických Create metod zadaných Stream objektu a volitelných odpovídajících možností vytvoření.
Povolení StreamPipeReaderOptions kontroly nad vytvořením PipeReader instance s následujícími parametry:
-
StreamPipeReaderOptions.BufferSize je minimální velikost vyrovnávací paměti v bajtech používaná při pronájmu paměti z fondu a výchozí hodnota
4096je . -
StreamPipeReaderOptions.LeaveOpen příznak určuje, zda je podkladový datový proud po dokončení otevřen
PipeReadernebo ne, a výchozí hodnotafalseje . -
StreamPipeReaderOptions.MinimumReadSize představuje prahovou hodnotu zbývajících bajtů ve vyrovnávací paměti před přidělením nové vyrovnávací paměti a výchozí hodnota
1024je . -
StreamPipeReaderOptions.Pool
MemoryPool<byte>je použit při přidělování paměti a výchozí hodnotanull.
Povolení StreamPipeWriterOptions kontroly nad vytvořením PipeWriter instance s následujícími parametry:
-
StreamPipeWriterOptions.LeaveOpen příznak určuje, zda je podkladový datový proud po dokončení otevřen
PipeWriternebo ne, a výchozí hodnotafalseje . -
StreamPipeWriterOptions.MinimumBufferSize představuje minimální velikost vyrovnávací paměti, která se má použít při pronájmu Poolpaměti z paměti a výchozí hodnota
4096. -
StreamPipeWriterOptions.Pool
MemoryPool<byte>je použit při přidělování paměti a výchozí hodnotanull.
Důležité
Při vytváření PipeReader a PipeWriter instancí pomocí Create metod je potřeba vzít v úvahu životnost objektu Stream . Pokud potřebujete přístup ke streamu po dokončení čtení nebo zápisu, budete muset nastavit LeaveOpen příznak na true možnosti vytváření. V opačném případě se datový proud zavře.
Následující kód ukazuje vytvoření PipeReader a PipeWriter instance pomocí Create metod ze streamu.
using System.Buffers;
using System.IO.Pipelines;
using System.Text;
class Program
{
static async Task Main()
{
using var stream = File.OpenRead("lorem-ipsum.txt");
var reader = PipeReader.Create(stream);
var writer = PipeWriter.Create(
Console.OpenStandardOutput(),
new StreamPipeWriterOptions(leaveOpen: true));
WriteUserCancellationPrompt();
var processMessagesTask = ProcessMessagesAsync(reader, writer);
var userCanceled = false;
var cancelProcessingTask = Task.Run(() =>
{
while (char.ToUpperInvariant(Console.ReadKey().KeyChar) != 'C')
{
WriteUserCancellationPrompt();
}
userCanceled = true;
// No exceptions thrown
reader.CancelPendingRead();
writer.CancelPendingFlush();
});
await Task.WhenAny(cancelProcessingTask, processMessagesTask);
Console.WriteLine(
$"\n\nProcessing {(userCanceled ? "cancelled" : "completed")}.\n");
}
static void WriteUserCancellationPrompt() =>
Console.WriteLine("Press 'C' to cancel processing...\n");
static async Task ProcessMessagesAsync(
PipeReader reader,
PipeWriter writer)
{
try
{
while (true)
{
ReadResult readResult = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = readResult.Buffer;
try
{
if (readResult.IsCanceled)
{
break;
}
if (TryParseLines(ref buffer, out string message))
{
FlushResult flushResult =
await WriteMessagesAsync(writer, message);
if (flushResult.IsCanceled || flushResult.IsCompleted)
{
break;
}
}
if (readResult.IsCompleted)
{
if (!buffer.IsEmpty)
{
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
catch (Exception ex)
{
Console.Error.WriteLine(ex);
}
finally
{
await reader.CompleteAsync();
await writer.CompleteAsync();
}
}
static bool TryParseLines(
ref ReadOnlySequence<byte> buffer,
out string message)
{
SequencePosition? position;
StringBuilder outputMessage = new();
while(true)
{
position = buffer.PositionOf((byte)'\n');
if (!position.HasValue)
break;
outputMessage.Append(Encoding.ASCII.GetString(buffer.Slice(buffer.Start, position.Value)))
.AppendLine();
buffer = buffer.Slice(buffer.GetPosition(1, position.Value));
};
message = outputMessage.ToString();
return message.Length != 0;
}
static ValueTask<FlushResult> WriteMessagesAsync(
PipeWriter writer,
string message) =>
writer.WriteAsync(Encoding.ASCII.GetBytes(message));
}
Aplikace používá StreamReader ke čtení lorem-ipsum.txt souboru jako streamu a musí končit prázdným řádkem. Objekt FileStream se předá PipeReader.Create, který vytvoří instanci objektu PipeReader . Konzolová aplikace pak předá standardní výstupní datový proud k PipeWriter.Create použití Console.OpenStandardOutput(). Příklad podporuje zrušení.
Spolupracujte s námi na GitHubu
Zdroj tohoto obsahu najdete na GitHubu, kde můžete také vytvářet a kontrolovat problémy a žádosti o přijetí změn. Další informace najdete v našem průvodci pro přispěvatele.