Přehled úloh importu a exportu dat
Použijte pracovní prostor Správa dat k vytvoření a správě úloh importu a exportu dat v aplikaci . Ve výchozím nastavení proces importu a exportu dat vytvoří tabulky fázování pro každou entitu v cílové databázi. Tabulky fázování umožňují ověřit, vyčistit anebo převést dat předtím, než budou přesunuta.
Poznámka
V tomto článku se předpokládá, že jste obeznámeni s datovými entitami.
Proces importu a exportu dat
Import a export dat se skládá z následujících kroků.
Vytvoření úlohy importu nebo exportu, kde dokončíte následující úkoly:
- Definujte kategorii projektu.
- Identifikujte entity, které chcete importovat nebo exportovat.
- Nastavte formát dat pro úlohu.
- Seřaďte entity tak, aby se zpracovaly v logických skupin a v pořadí, které dává smysl.
- Určete, zda použít tabulky fázování.
Ověřte, zda jsou zdrojová a cílová data správně namapována.
Ověřte zabezpečení pro úlohu import nebo exportu.
Spusťte úlohu importu nebo exportu.
Ověřte, zda úloha proběhla podle očekávání tím, že zkontrolujete historii úlohy.
Vyčistěte tabulky fázování.
Zbývající části tohoto článku poskytují podrobnější informace o jednotlivých krocích postupu.
Poznámka
Chcete-li obnovit formulář Import/export dat a zobrazit poslední vývoj, použijte ikonu obnovení formuláře. Obnovení úrovně prohlížeče se nedoporučuje, protože přeruší všechny úlohy importu/exportu, které nejsou spuštěny v dávce.
Vytvoření úlohy importu nebo exportu
Úlohu importu nebo exportu dat lze spustit jednou i několikrát.
Definování kategorie projektu
Doporučujeme, abyste si dali načas s výběrem vhodné kategorie projektu pro svou úlohu importu a exportu. Kategorie projektu mohou pomoct se správou souvisejících úloh.
Identifikace entit, které chcete importovat nebo exportovat
Můžete přidat konkrétní entity do úlohy importu nebo exportu, nebo zvolit použití šablony. Šablony naplní úlohu seznamem entit. Možnost Použít šablonu je k dispozici po zadání názvu úlohy a uložení úlohy.
Nastavení formátu dat pro úlohu
Vyberete-li entitu, je nutné vybrat formát dat, která budou exportována nebo importována. Formáty definujete pomocí dlaždice Nastavení datových zdrojů. Formát zdrojových dat je kombinací typ, formát, oddělovač řádků a oddělovač sloupců. Existují další atributy, ale ty jsou klíčové pro porozumění. V následující tabulce jsou uvedeny platné kombinace.
| Formát souboru | Oddělovač řádků/sloupců | Styl XML |
|---|---|---|
| Aplikace Excel | Aplikace Excel | -/- |
| XML | -/- | XML-Element XML-Attribute |
| Oddělené, Pevná šířka | Čárka, středník, tabulátor, svislá čára, dvojtečka | -/- |
Poznámka
Je důležité vybrat správnou hodnotu pro Oddělovač řádků, Oddělovač sloupců a Textový kvalifikátor, pokud je možnost Formát souboru nastavena na Oddělené. Ujistěte se, že vaše data neobsahují znak použitý jako oddělovač nebo kvalifikátor, protože to může způsobit chyby při importu a exportu.
Poznámka
U formátů souborů založených na XML se ujistěte, že používáte pouze povolené znaky. Další informace o platných znacích najdete v článku Platné znaky v XML 1.0. XML 1.0 nepovoluje žádné řídicí znaky kromě tabulátorů a znaků CR a LF. Mezi příklady nepovolených znaků patří hranaté závorky, složené závorky a zpětná lomítka.
K importu nebo exportu dat použijte Unicode namísto specifické kódové stránky. Tak zajistíte maximálně konzistentní výsledky a eliminujete selhání úloh správy dat, protože obsahují znaky Unicode. Systémově definované formáty zdrojových dat, které používají Unicode, mají v názvu zdroje vždy řetězec Unicode. Formát Unicode se použije výběrem kódovací stránky ANSI s kódováním Unicode v poli Kódová stránka na kartě Místní nastavení. Vyberte jednu z následujících kódových stránek pro Unicode:
| Znaková stránka | Zobrazovaný název |
|---|---|
| 1200 | Znaková sada Unicode |
| 12000 | Unicode (UTF-32) |
| 12001 | Unicode (UTF-32 Big-Endian) |
| 1201 | Unicode (Big-Endian) |
| 65000 | Unicode (UTF-7) |
| 65001 | Unicode (UTF-8) |
Další informace o kódových stránkách najdete v tématu Identifikátory kódové stránky.
Seřazení entit
Entity lze seřadit v šabloně dat nebo v úloze importu a exportu. Při spuštění úlohy, která obsahuje více než jednu entitu dat, se musíte ujistit, že jsou entity správně seřazeny. Entity seřazujete především proto, abyste mohli adresovat všechny funkční závislosti mezi entitami. Pokud nemají entity žádnou funkční závislost, lze je naplánovat pro paralelní import nebo export.
Spuštění jednotek, úrovní nebo řad
Jednotka spuštění, úroveň v jednotce spuštění a řazení entity pomáhají kontrolovat pořadí, v jakém jsou data exportována nebo importována.
- V jiných jednotkách spuštění se entity zpracovávají souběžně.
- U každé jednotky spuštění se entity zpracovávají souběžně, pokud mají stejnou úroveň.
- V každé úrovni se entity zpracování podle jejich pořadového čísla v úrovni.
- po zpracování jedné úrovně se zpracuje další úroveň.
Opětovné seřazení
Může být zapotřebí opětovně seřadit vaše entity v následujících situacích:
- Pokud je použita jen jedna datová úlohu pro všechny vaše změny, můžete použít možnosti změny seřazení, abyste optimalizovali dobu provádění celé úlohy. V těchto případech můžete použít jednotku spuštění, aby představovala modul, úroveň, která představuje oblast funkce v modulu, a seřazení představující entitu. Díky tomuto přístupu je možné pracovat ve všech modulech současně, ale i nadále můžete pracovat v pořadí v jednotlivém modulu. K zajištění, aby proběhly paralelní operace úspěšně, je nutné brát ohled na všechny závislosti.
- Při použití vícero datových úloh (například jedna úloha pro každý modul) můžete použít řazení k ovlivnění úrovně a pořadí entit za účelem optimálního provedení úlohy.
- Pokud vůbec neexistují žádné závislosti, můžete seřadit entity na jiných jednotkách spuštění pro maximální optimalizaci.
Nabídka Opětovné seřazení je k dispozici při výběru více entit. Můžete opětovně provést řazení na základě jednotky spuštění, úrovně nebo možností seřazení. Můžete nastavit přírůstek pro opětovné seřazení vybraných entit. Jednotka, úroveň anebo pořadové číslo, které bylo vybráno pro každou entitu, je aktualizováno podle zadaného přírůstku.
Třídění
Použijte možnost Seřadit podle k zobrazení seznamu entit v sekvenčním pořadí.
Zkrácení
Pro projekty importu můžete zkrátit záznamy předchozích entit před importem. Zkracování je užitečné, pokud je třeba záznamy importovat do čisté sady tabulek. Toto nastavení je ve výchozím nastavení vypnuté.
Ověření, zda jsou zdrojová a cílová data správně namapována
Mapování je funkce vztahující se jak k úloze importu, tak k úloze exportu.
- V kontextu úlohy importu popisuje mapování to, jaké sloupce ve zdrojovém souboru se stanou sloupci v tabulce fázování. Systém tedy může určit, která data sloupce ze zdrojového souboru musí být zkopírována do příslušného sloupce v tabulce fázování.
- V kontextu úlohy exportu popisuje mapování to, jaké sloupce tabulky fázování (tedy zdroje) se stanou sloupci v cílovém souboru.
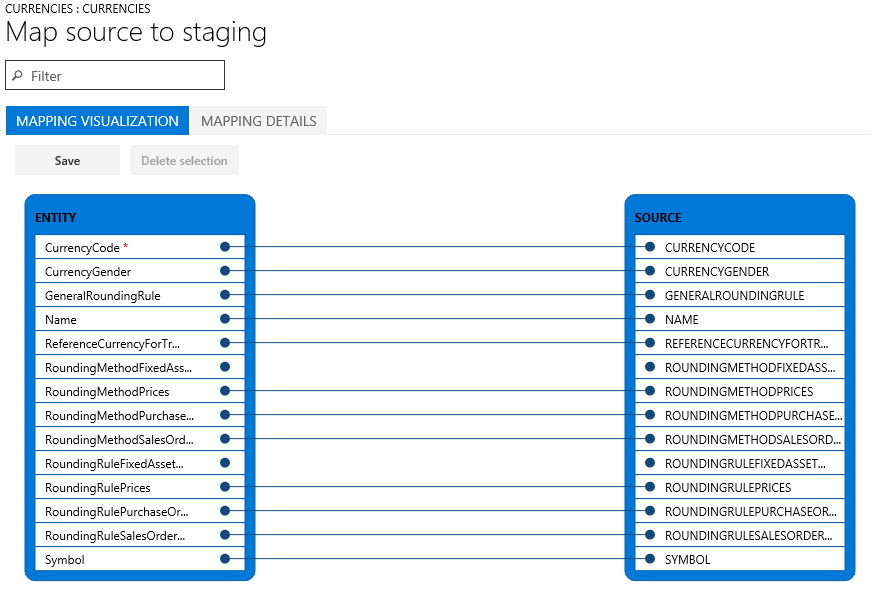
Pokud se názvy sloupců v tabulce fázování a v souboru shodují, systém automaticky vytvoří mapování na základě názvů. Avšak pokud se názvy liší, sloupce se automaticky nenamapují. V těchto případech je nutné dokončit mapování výběrem možnosti Zobrazit mapu na entitě v datové úloze.
Existují dvě zobrazení mapování: Vizualizace mapování, což je výchozí zobrazení, a Podrobnosti mapování. Červená hvězdička (*) identifikuje všechna povinná pole entity. Než začnete pracovat s entitou, musí být tato pole mapována. U dalších polí lze při práci s entitou zrušit mapování podle potřeby. Chcete-li zrušit mapování pole, vyberte pole buď ve sloupci Entita nebo sloupec Zdroj, a poté vyberte Odstranit výběr. Vyberte Uložit pro uložení změn a zavřete stránku. Tím se vrátíte do projektu. Stejný postup můžete použít k úpravě mapování pole ze zdroje do fázování po provedení importu.
Mapování na stránce můžete vygenerovat výběrem možnosti Generovat mapování zdroje. Vygenerované mapování se chová jako automatické mapování. Proto je nutné ručně namapovat všechna nenamapovaná pole.
Ověření zabezpečení pro úlohu import nebo exportu
Přístup k pracovnímu prostoru Správa dat lze omezit, tak, aby uživatelé bez oprávnění správce měli přístup pouze k určitým datovým úlohám. Přístup k úloze dat zahrnuje úplný přístup ke spuštění historie této úlohy a přístup k tabulkám fázování. Proto je třeba se ujistit, že existují příslušný ovládací prvky přístupu při vytváření datové úlohy na místě.
Zabezpečení úlohy podle role uživatelů
Použijte nabídku Použitelné role k omezení úlohy na jednu nebo více rolí zabezpečení. Pouze uživatelé v těchto rolích budou mít přístup k úloze.
Úlohu lze omezit také pro konkrétní uživatele. Pokud zabezpečíte úlohu podle uživatelů, nikoliv podle rolí, máte větší kontrolu, pokud je k jedné roli přiřazeno více uživatelů.
Zabezpečení úlohy podle právnické osoby
Datové úlohy jsou svým charakterem globální. Je-li tedy datová úloha vytvořena a použita u právnické osoby, je viditelná i u jiných právnických osob v systému. Toto výchozí chování může být upřednostňované v některých scénářích aplikace. Například organizace, která importuje faktury pomocí datových entit, může nabídnout centralizovaný tým zpracovávající faktury, který je zodpovědný za správu fakturačních chyb pro všechny divize v organizaci. V tomto případě je pro centralizovaný tým zpracovávající faktury užitečné mít přístup k úlohám importu faktur ze všech právnických osob. Výchozí chování tedy splňuje požadavek z hlediska právnické osoby.
Organizace však může potřebovat mít týmy zpracovávající faktury podle právnické osoby. V takovém případě by měl tým v právnické osobě mít přístup pouze k úloze importu faktury v rámci vlastní právnické osoby. Aby byl tento požadavek splněn, lze konfigurovat kontrolu přístupu k datovým úlohám na základě právnické osoby pomocí nabídky Použitelné právnické osoby uvnitř datové úlohy. Po dokončení konfigurace mohou uživatelé zobrazit pouze úlohy, které jsou k dispozici v právnické osobě, ke která jsou aktuálně přihlášeni. Pokud chtějí uživatelé zobrazit úlohy z jiné právnické osoby, musí přepnout na tuto právnickou osobu.
Úlohu lze zabezpečit podle rolí, uživatelů a právnické osoby současně.
Spuštění úlohy importu nebo exportu
Spustit úlohu můžete jednou výběrem tlačítka Importovat nebo Exportovat poté, co nadefinujete úlohu. Chcete-li nastavit opakovanou úlohu, zvolte Vytvořit opakovanou datovou úlohu.
Poznámka
Úlohu importu nebo exportu lze spustit výběrem tlačítka Importovat nebo Exportovat. Akce naplánuje spuštění dávkové úlohy pouze jednou. Úloha se nemusí provést okamžitě, pokud dávková služba má výpadky kvůli velkému množství požadavků. Úlohy můžete také provádět synchronně výběrem Importovat nyní nebo Exportovat nyní. Úloha se spustí ihned a je to užitečné, pokud se dávka nespustí z důvodu omezení. Úlohy lze také naplánovat tak, aby se spustila později. Toho lze dosáhnout výběrem možnosti Spustit v dávce. Zdroje dávky podléhají omezení, takže dávková úloha nemusí začít okamžitě. Použití dávky je doporučená možnost, protože také pomáhá u velkých objemů dat, která je třeba importovat nebo exportovat. Dávkové úlohy lze naplánovat tak, aby se spouštěly na určité skupině dávek, což umožňuje větší kontrolu z pohledu vyvažování zátěže.
Ověření, zda byla úloha spuštěna podle očekávání
Historie úloh je dostupná pro řešení potíží a analýzu na úlohách importu i exportu. Historie spuštění úloh je organizována podle časových rozsahů.
Spuštění každé úlohy poskytuje následující podrobnosti:
- Podrobnosti o provádění
- Protokol provádění
Podrobnosti o spuštění zobrazují stav každé datové entity, kterou úloha zpracovala. Díky tomu můžete rychle vyhledat následující informace:
- Jaké entity, které byly zpracovány.
- Kolik záznamů bylo pro danou entitu zpracováno a kolik se jich nezdařilo.
- Záznamy fázování pro každou entitu.
Můžete stáhnout data fázování do souboru pro úlohy exportu, nebo je můžete stáhnout jako balíček pro úlohy importu a exportu.
Chcete-li znát podrobnosti spuštění, můžete rovněž otevřít protokol provádění.
Souběžné importy
Chcete-li urychlit import dat, lze souběžné zpracování importu povolit, pokud entita podporuje souběžné importy. Chcete-li konfigurovat paralelní import pro entitu, je nutné provést následující kroky.
Přejděte do nabídky Správa systému > Pracovní prostory > Správa dat.
V oddílu Import/export vyberte dlaždici Parametry architektury, která otevře stránku Parametry platformy importu a exportu dat.
Na kartě Nastavení entity vyberte možnost Konfigurovat parametry spuštění entity a otevřete stránku Parametry spuštění importu entity.
Nastavte následující pole pro konfiguraci paralelního importu pro entitu:
- V poli Entita zvolte entitu. Pokud je pole entity prázdné, použije se prázdná hodnota jako výchozí nastavení pro všechny následné importy, pokud entita podporuje paralelní import.
- Do pole Počet záznamů prahové hodnoty pro import zadejte počet záznamů prahové hodnoty pro import. Určuje počet záznamů, které mají být zpracovány podprocesem. Pokud má soubor 10 000 záznamů, počet záznamů 2500 při počtu úloh čtyři znamená, že každé vlákno zpracuje 2500 záznamů.
- Do pole Počet úkolů importu zadejte počet úkolů importu. Počet nesmí přesáhnout maximální počet dávkových podprocesů přidělených pro dávkové zpracování v Správa systému >Konfigurace serveru.
Poznámka
Přidání příliš mnoha paralelních úloh způsobí, že základní infrastruktura využije kapacitu prostředků na 100 % a ovlivní výkon prostředí a další operace. Doporučujeme, abyste porozuměli kapacitě prostředků prostředí a spotřebě na základě nakonfigurovaných úloh paralelního importu a omezili počet úloh.
Vyčištění historie úloh
Ve výchozím nastavení se automaticky odstraní záznamy historie úloh a související data z tabulky etapizace, které jsou starší než 90 dní. Pomocí funkce čištění historie úloh ve správě dat lze nakonfigurovat pravidelné čištění historie provádění s nižší dobou uchovávání, než je tato výchozí hodnota. Tato funkce nahrazuje předchozí funkci Vyčištění pracovní tabulky, která je nyní zastaralá. Následující tabulky budou vyčištěny procesem vyčištění.
Všechny tabulky fází
DMFSTAGINGVALIDATIONLOG
DMFSTAGINGEXECUTIONERRORS
DMFSTAGINGLOGDETAIL
DMFSTAGINGLOG
DMFDEFINITIONGROUPEXECUTIONHISTORY
DMFEXECUTION
DMFDEFINITIONGROUPEXECUTION
Funkce Čištění historie spuštění je přístupná z cesty Správa dat > Čištění historie práce.
Parametry plánování
Při plánování procesu čištění je třeba zadat následující parametry pro definování kritérií čištění.
Počet dnů pro uchování historie – toto nastavení slouží k řízení rozsahu historie provádění, která má být zachována. Historie se udává v počtech dní. Pokud je úloha čištění naplánována jako opakovaná dávková úloha, toto nastavení bude fungovat jako neustálé přesouvání okna, takže vždy zůstala historie zadaného počtu dnů při odstranění zbývající položky. Výchozí hodnota je sedm dní.
Počet hodin pro provedení úlohy – v závislosti na množství historie, která má být vyčištěna, se může celková doba provádění úlohy čištění pohybovat v rozsahu od několika minut až po několik hodin. Tento parametr musí být nastaven na počet hodin, který bude úloha provádět. Poté, co byla úloha čištění provedena po zadaný počet hodin, úloha se ukončí a bude pokračovat v vyčištění při příštím spuštění na základě plánu opakování.
Maximální čas provedení lze určit nastavením maximálního počtu hodin, které musí úloha spustit pomocí tohoto nastavení. Logika čištění projde v čase s chronologicky uspořádaným pořadím jedno ID spuštění úlohy a nejstarší je nejprve pro vyčištění související historie spuštění. Ukončí vyzvednutí nového ID provedení vyčištění, když je zbývající doba trvání během posledních 10 % zadané doby trvání. V některých případech úloha vyčištění bude pokračovat i po uplynutí určené maximální doby. Doba trvání bude převážně záviset na počtu záznamů, které mají být odstraněny pro aktuální ID spuštění, které bylo zahájeno před dosažením prahové hodnoty 10 %. Čištění, které bylo zahájeno, musí být dokončeno, aby byla zajištěna integrita dat, což znamená, že vyčištění bude pokračovat navzdory překročení stanoveného limitu. Po dokončení operace nebudou nová ID spuštění vydána a úloha vyčištění skončí. Zbývající historie spuštění, která nebyla vyčištěna z důvodu nedostatečné doby provádění, bude vybrána při příštím plánování úlohy čištění. Výchozí a minimální hodnota pro toto nastavení je 2 hodiny.
Opakovaná dávka – úlohu čištění lze spustit jako jednorázové, ruční spuštění nebo je také možné naplánovat její opakované provedení v dávce. Dávku lze naplánovat pomocí nastavení Spustit na pozadí, což je standardní nastavení dávky.
Poznámka
Pokud není použita funkce čištění historie úloh, je historie provádění starší než 90 dní stále automaticky odstraňována. Kromě tohoto automatického odstraňování lze spustit i čištění historie úloh. Ujistěte se, že úloha čištění je naplánována tak, aby se spouštěla opakovaně. Jak bylo vysvětleno výše, při jakékoli čisté realizaci bude úloha čistit pouze tolik ID spuštění, kolik je možné v zadaných maximálních hodinách.
Čištění a archivace historie úloh
Funkce čištění a archivace historie úloh nahrazují předchozí verze funkce čištění. Tato část vysvětluje tyto nové funkce.
Jednou z hlavních změn ve funkci čištění je použití dávkové úlohy systému k vyčištění historie. Použití dávkové úlohy systému umožňuje finančním a provozním aplikacím mít automaticky naplánovanou a spouštěnou dávkovou úlohu vyčištění, jakmile je systém připraven. Dávkové úlohy již není nutné ručně plánovat. V tomto výchozím režimu provádění bude dávková úloha spuštěna každou hodinu počínaje půlnocí a zachová si historii provádění za posledních sedm dní. Vymazaná historie je archivována pro budoucí načtení. Počínaje verzí 10.0.20 je tato funkce vždy zapnutá.
Druhou změnou v procesu čištění je archivace vymazané historie provádění. Úloha vyčištění archivuje odstraněné záznamy do úložiště objektů blob, které DIXF používá pro běžné integrace. Archivovaný soubor bude ve formátu balíčku DIXF a bude k dispozici po dobu sedmi dnů v objektu blob, během kterého bude možné jej stáhnout. Výchozí životnost archivovaného souboru sedm dní lze v parametrech změnit na maximálně 90 dní.
Změna výchozího nastavení
Tato funkce je aktuálně v náhledu a musí být explicitně zapnuta povolením testovací verze úlohy DMFEnableExecutionHistoryCleanupSystemJob. Ve správě funkcí musí být také zapnuta funkce vyčištění fázování.
Chcete-li změnit výchozí nastavení životnosti archivovaného souboru, přejděte do pracovního prostoru správy dat a vyberte možnost Vyčištění historie úlohy. Nastavte Počet dnů uchování balíčku v objektu blob na hodnotu mezi 7 a 90 (včetně). Tato změna se projeví u archivů, které jsou vytvořeny po provedení této změny.
Stahování archivovaného balíčku
Tato funkce je aktuálně v náhledu a musí být explicitně zapnuta povolením testovací verze úlohy DMFEnableExecutionHistoryCleanupSystemJob. Ve správě funkcí musí být také zapnuta funkce vyčištění fázování.
Chcete-li stáhnout archivovanou historii spuštění, přejděte do pracovního prostoru správy dat a vyberte možnost Vyčištění historie úlohy. Výběrem položky Historie zálohování balíčku otevřete formulář historie. Tento formulář zobrazuje seznam všech archivovaných balíčků. Archiv lze vybrat a stáhnout výběrem možnosti Stáhnout balíček. Stažený balíček bude ve formátu balíčku DIXF a bude obsahovat následující soubory:
- Soubor tabulky fázování entit
- DMFDEFINITIONGROUPEXECUTION
- DMFDEFINITIONGROUPEXECUTIONHISTORY
- DMFEXECUTION
- DMFSTAGINGEXECUTIONERRORS
- DMFSTAGINGLOG
- DMFSTAGINGLOGDETAILS
- DMFSTAGINGVALIDATIONLOG
Řazení dat složené entity pomocí xslt
Tato funkce umožňuje exportovat složenou entitu a použít soubor xslt k seřazení dat v souboru xml.
Chcete-li seřadit data složené entity pomocí příkazu xslt, postupujte takto.
- Vytvořte soubor xslt pro seřazení dat ve formátu XML. Máte-li například soubor XSLT pro předem připravenou entitu Složené nákupní objednávky V3, můžete data formátu atributu XML seřadit podle INVOICEVENDORACCOUNTNUMBER pro PURCHPURCHASEORDERHEADERV2ENTITY a seřadit podle LINENUMBER pro PURCHPURCHASEORDERLINEV2ENTITY.
<xsl:stylesheet version='1.0' xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/*">
<xsl:copy>
<xsl:apply-templates select="@*" />
<xsl:apply-templates>
<xsl:sort select="@INVOICEVENDORACCOUNTNUMBER" data-type="text" order="ascending" />
</xsl:apply-templates>
</xsl:copy>
</xsl:template>
<xsl:template match="PURCHPURCHASEORDERHEADERV2ENTITY">
<xsl:copy>
<xsl:apply-templates select="@*"/>
<xsl:apply-templates select="*">
<xsl:sort select="@LINENUMBER" data-type="number" order="descending"/>
</xsl:apply-templates>
</xsl:copy>
</xsl:template>
<xsl:template match="@*|node()">
<xsl:copy>
<xsl:apply-templates select="@*|node()"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
- Přejděte na pracovní prostor Správa dat.
- Ze seznamu Export dat projektů vyberte projekt se zdrojem dat XML a vyberte Zobrazit mapu.
- Vyberte možnost Zobrazit mapu pro libovolnou entitu.
- Přejděte na kartu Transformace
- Vyberte Nový a nahrajte soubor xslt vytvořený v krok 1.