Výsledky modelů strojového učení
Tento článek pojednává o maticích zmatků, problémech s klasifikací a správnosti v modelech strojového učení (ML). Účelem je zlepšit vaše chápání správnosti ve výsledcích predikce ML. Cílové publikum zahrnuje inženýry, analytiky a manažery, kteří chtějí rozvíjet své znalosti a dovednosti v oblasti datové vědy.
Matice zmatku
Poté, co je kontrolovaný problém ML vycvičen na sadě historických dat, je testován pomocí dat, která jsou zadržena z procesu školení. Tímto způsobem můžete porovnat předpovědi z trénovaného modelu se skutečnými hodnotami. Matice zmatku poskytuje prostředky k vyhodnocení toho, jak úspěšný je problém s klasifikací a kde dělá chyby (tj. kde se stává „zmateným“).
Vaším cílem je například předpovědět, zda je domácí zvíře pes nebo kočka, na základě některých fyzických a behaviorálních atributů. Pokud máte testovací datovou sadu, která obsahuje 30 psů a 20 koček, matice zmatku může vypadat jako na následujícím obrázku.
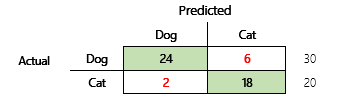
Čísla v zelených buňkách představují správné předpovědi. Jak vidíte, model správně předpovídal vyšší procento koček. Celková správnost modelu je snadno vypočitatelná. V tomto případě je to 42 ÷ 50 nebo 0,84.
Vícetřídové klasifikátory v matici zmatku
Většina diskusí o matici zmatku je zaměřena na binární klasifikátory, jako v předchozím příkladu. Tento případ je zvláštní případ, kdy lze uvažovat o dalších metrikách, jako je citlivost a úplnost.
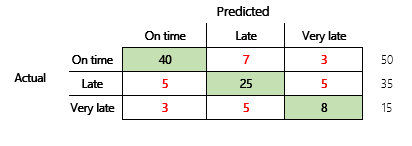
Dále zvážíme problém klasifikace pro finanční scénář, který má tři stavy. Model předpovídá, zda bude faktura od zákazníka zaplacena včas, pozdě nebo velmi pozdě. Například ze 100 testovacích faktur je 50 zaplaceno včas, 35 zaplaceno pozdě a 15 zaplaceno velmi pozdě. V tomto případě může model vytvořit matici zmatku, která se podobá následující ilustraci.
 ]
]
Matice zmatku poskytuje podstatně více informací než jednoduchá metrika správnosti. Stále je to však relativně snadné pochopit. Matice zmatku vám řekne, zda máte vyváženou datovou sadu, kde výstupní třídy mají podobné počty. Pro scénář pro více tříd vám řekne, jak mylná může být předpověď, když jsou výstupní třídy řadové, jako v předchozím příkladu o platbách zákazníků.
Správnost modelu
Výhodou kvantifikace kvality modelu jsou různé metriky správnosti.
Protože správnost je snadno pochopitelná metrika, je to dobrý výchozí bod pro vysvětlení modelu ostatním lidem, zejména uživatelům modelu, kteří nejsou datovými vědci. Pro pochopení správnosti modelu není nutné žádné porozumění statistikám. Když je k dispozici matice zmatku, poskytuje podrobnější pohled na výkon modelu.
Pro důkladnější pochopení je však třeba uvést několik problémů, které jsou spojeny se správností. Užitečnost metriky závisí na kontextu problému. Otázka, která se často objevuje v souvislosti s výkonem modelu, je: „Jak dobrý je model?“ Odpověď na tuto otázku však nemusí být přímočará. Zvažte následující matici zmatku (model 2).
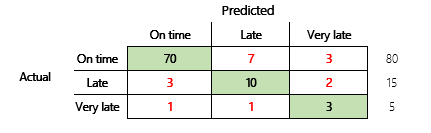
Rychlý výpočet ukazuje, že správnost tohoto modelu je (70 + 10 + 3) ÷ 100 nebo 0,83. Na povrchu se tento výsledek jeví lepší než výsledek pro předchozí model s více třídami (model 1), který má správnost 0,73. Ale je to lepší?
Chcete-li se touto otázkou začít zabývat, zvažte správnost naivního odhadu. U problému klasifikace jednoduchý odhad vždy předpovídá nejběžnější třídu. U modelu 1 bude tento odhad „včas“ a bude mít správnost 0,50. Odhad pro model 2 bude také „včas“ a bude mít správnost 0,80. Protože model 1 vylepšuje naivní odhad o 0,73 - 0,50 = 0,23, zatímco model 2 vylepšuje naivní odhad o 0,83 - 0,80 = 0,03, model 1 je lepší model, i když má nižší správnost. Výpočet ukazuje, že efektivní posouzení kvality modelu vyžaduje více kontextu než hodnotu správnosti.
Za zmínku stojí další aspekt. Zvažte scénář, kdy se ke zjištění nemoci u pacienta použije lékařský test. Tento problém je problémem binární klasifikace, kde pozitivní výsledek naznačuje, že pacient má onemocnění. V tomto scénáři musíte přemýšlet o dopadu následujících chyb:
- Falešně pozitivní, kde test říká, že pacient má nemoc, ale ve skutečnosti ji nemá.
- Falešně negativní, kde test říká, že pacient nemá nemoc, ale ve skutečnosti ji má.
Je zřejmé, že oba typy chyb jsou nežádoucí, ale která je horší? Opět to záleží na situaci. V případě život ohrožujícího onemocnění, které vyžaduje rychlou léčbu, má přednost minimalizace falešně negativních chyb (s vyhlídkou dalších testů). V jiných, méně kritických situacích mohou tvůrci modelu místo toho minimalizovat falešně pozitivní chyby. Rozumným závěrem je, že k efektivnímu určení kvality modelu musíte mít více informací, než poskytuje metrika správnosti.
Doporučení
Správnost je důležitý nástroj pro komunikaci s odborníky na danou oblast, kteří nejsou zběhlí ve statistice. Aby však byly informace užitečné, je důležité poskytnout další kontext společně s hodnotou správnosti.
Pro scénář předpovědi plateb můžete nastavit cíl pro model strojového učení, který zahrnuje faktory při různých platebních chováních. Cílem je, aby se model zlepšil v naivním odhadu snížením počtu nesprávných odpovědí alespoň o 50 procent. Jinými slovy chcete dosáhnout cílové správnosti, která půlí rozdíl mezi přesností naivního odhadu a 100 procenty.
Následující tabulka shrnuje tento princip pro matice zmatku v tomto článku.
| Model | Naivní odhad | Cíl | Správnost modelu | Je dosaženo cíle? |
|---|---|---|---|---|
| Model 1 | 0.50 | 0.75 | 0.73 | Téměř. Tento model výrazně zlepšuje odhad. |
| Model 2 | 0.80 | 0.90 | 0.83 | Č. Je nutné vylepšení. |
Správnost F1 klasifikace
Konečným hlediskem v tomto článku je pokročilejší měřítko výkonu strojového učení klasifikace, které se označuje jako správnost F1.
Před definováním správnosti F1 je třeba zavést dvě další metriky: přesnost a úplnost. Přesnost označuje, kolik z celkového počtu předpovědí, které jsou zadány jako pozitivní, je správně přiřazeno. Tato metrika je také známá jako pozitivní prediktivní hodnota. Úplnost je celkový počet skutečných pozitivních případů, které byly správně předpovězeny. Tato metrika je také známá jako citlivost.
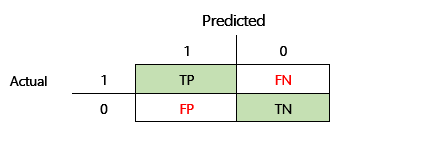
V matici zmatku na předchozím obrázku se tyto metriky počítají následujícím způsobem:
- Přesnost = TP ÷ (TP + FP)
- Úplnost = TP ÷ (TP + FN)
Míra F1 kombinuje přesnost a úplnost. Výsledkem je harmonický průměr obou hodnot. Vypočítává se následujícím způsobem:
- F1 = 2 × (přesnost × úplnost) ÷ (přesnost + úplnost)
Podívejme se na konkrétní příklad. Dříve v tomto článku byl příklad modelu, který předpovídal, zda je zvíře pes nebo kočka. Ilustrace se zde opakuje.
Zde jsou výsledky, pokud je jako pozitivní odpověď použit „pes“.
- Přesnost = 24 ÷ (24 + 2) = 0,9231
- Úplnost = 24 ÷ (24 + 6) = 0,8
- F1 = 2 × (0,9231 × 0,8) ÷ (0,9231 + 0,8) = 0,8572
Jak vidíte, hodnota F1 je mezi hodnotami pro přesnost a úplnost.
Ačkoli správnost F1 není tak snadno pochopitelná, přidává k základnímu číslu přesnosti nuanci. Může také pomoci s nevyváženými datovými sadami, jak ukáže následující diskuse.
Část Správnost modelu tohoto článku porovnala následující dvě matice zmatků. I když první model měl nižší přesnost, byl považován za užitečnější model, protože vykázal větší zlepšení než výchozí odhad včasné platby.
Podívejme se, jak se tyto dva modely porovnávají, když se použije skóre F1. Faktory skóre F1 v přesnosti a úplnosti pro každý stav a výpočet makra F1 poté zprůměruje skóre F1 napříč stavy a určí celkové skóre F1. Existují i jiné varianty F1, ale je mnohem zajímavější zvážit verzi makra, vzhledem ke stejné úvaze, která je věnována všem třem stavům.
Pro zjednodušení výpočtů byla sestrojena ukázková pole, která odpovídají skutečným a předpovězeným hodnotám. Tato pole používala k výpočtu hodnot knihovnu metrik sklearn v Pythonu. Zde je výsledek.
| Model | Naivní odhad | Přesnost | Makro F1 |
|---|---|---|---|
| Model 1 | 0.5 | 0.73 | 0.67 |
| Model 2 | 0.80 | 0.83 | 0.66 |
Další informace, jak tento výpočet funguje, najdete zde v sestavě klasifikace sklearn.metrics pro model 1. Tři stavy: „Včas“, „Pozdě“ a „Velmi pozdě“ jsou reprezentovány řádky, které jsou označeny 1, 2 a 3. Průměr makra je pouze průměr sloupce „skóre-f1“.
| přesnost | úplnost | skóre-f1 | |
|---|---|---|---|
| 1 | 0.83 | 0.80 | 0.82 |
| 2 | 0.68 | 0.71 | 0.69 |
| 3 | 0.50 | 0.50 | 0.50 |
Jak tyto výsledky ukazují, oba modely mají téměř identické skóre správnosti makra F1. V tomto a mnoha dalších případech poskytuje správnost F1 lepší indikátor schopnosti modelu. Pokud jde o přesnost, interpretace výsledků vyžaduje, abyste pochopili, co je v modelu nejdůležitější vzít v úvahu.