Důležité informace o výkonu EF 4, 5 a 6
David Obando, Eric Dettinger a další
Publikováno: duben 2012
Poslední aktualizace: květen 2014
1. Úvod
Architektury mapování objektů a relačních objektů představují pohodlný způsob, jak poskytnout abstrakci pro přístup k datům v objektově orientované aplikaci. Pro aplikace .NET doporučuje Microsoft O/RM entity Framework. Díky jakékoli abstrakci se ale výkon může stát zájmem.
Tento dokument white paper byl napsán tak, aby zobrazoval aspekty výkonu při vývoji aplikací pomocí entity Framework, aby vývojářům poskytl představu o interních algoritmech Entity Framework, které můžou ovlivnit výkon, a poskytl tipy pro šetření a zlepšení výkonu ve svých aplikacích používajících Entity Framework. Na webu je již k dispozici celá řada dobrých témat a snažili jsme se na tyto prostředky odkazovat, pokud je to možné.
Výkon je složité téma. Tento dokument white paper je určený jako prostředek, který vám pomůže při rozhodování souvisejících s výkonem pro vaše aplikace, které používají Entity Framework. Zahrnuli jsme některé testovací metriky, které ukazují výkon, ale tyto metriky nejsou určené jako absolutní indikátory výkonu, které uvidíte ve vaší aplikaci.
Pro praktické účely tento dokument předpokládá, že entity Framework 4 běží v .NET 4.0 a Entity Framework 5 a 6 jsou spuštěny v rozhraní .NET 4.5. Řada vylepšení výkonu pro Entity Framework 5 se nachází v základních komponentách, které jsou součástí .NET 4.5.
Entity Framework 6 je mimo pásmo a nezávisí na komponentách Entity Framework, které jsou dodávány s .NET. Entity Framework 6 funguje na platformě .NET 4.0 i .NET 4.5 a může nabídnout velkou výhodu výkonu těm, kteří neupgradovali z .NET 4.0, ale chtějí mít v aplikaci nejnovější bity Entity Frameworku. Když tento dokument zmíní Entity Framework 6, odkazuje na nejnovější verzi dostupnou v době psaní tohoto článku: verze 6.1.0.
2. Studená vs. teplé spouštění dotazů
Při prvním vytvoření jakéhokoli dotazu na daný model provede Entity Framework spoustu práce na pozadí a načte a ověří model. Tento první dotaz často označujeme jako "studený" dotaz. Další dotazy na již načtený model se označují jako "teplé" dotazy a jsou mnohem rychlejší.
Pojďme se podívat na to, kde je čas strávený při provádění dotazu pomocí Entity Frameworku, a podívejme se, kde se v Entity Frameworku 6 vylepšují věci.
První spuštění dotazu – studený dotaz
| Zápisy uživatelů kódu | Akce | Dopad na výkon EF4 | Dopad na výkon EF5 | Dopad na výkon EF6 |
|---|---|---|---|---|
using(var db = new MyContext()) { |
Vytvoření kontextu | Medium | Medium | nízkou |
var q1 = from c in db.Customers where c.Id == id1 select c; |
Vytvoření výrazu dotazu | nízkou | nízkou | nízkou |
var c1 = q1.First(); |
Provádění dotazů LINQ | - Načítání metadat: Vysoká, ale uložená v mezipaměti - Zobrazení generace: Potenciálně velmi vysoká, ale uložená v mezipaměti - Vyhodnocení parametru: střední – Překlad dotazů: Střední - Generování materializátoru: střední, ale uložená v mezipaměti – Spouštění databázových dotazů: Potenciálně vysoké + Připojení ion. Otevřít + Command.ExecuteReader + DataReader.Read Materializace objektů: Střední – Vyhledávání identity: střední |
- Načítání metadat: Vysoká, ale uložená v mezipaměti - Zobrazení generace: Potenciálně velmi vysoká, ale uložená v mezipaměti - Vyhodnocení parametru: Nízká – Překlad dotazů: Střední, ale uložená v mezipaměti - Generování materializátoru: střední, ale uložená v mezipaměti – Spouštění databázových dotazů: Potenciálně vysoké (lepší dotazy v některých situacích) + Připojení ion. Otevřít + Command.ExecuteReader + DataReader.Read Materializace objektů: Střední – Vyhledávání identity: střední |
- Načítání metadat: Vysoká, ale uložená v mezipaměti - Zobrazení generace: střední, ale uložená v mezipaměti - Vyhodnocení parametru: Nízká – Překlad dotazů: Střední, ale uložená v mezipaměti - Generování materializátoru: střední, ale uložená v mezipaměti – Spouštění databázových dotazů: Potenciálně vysoké (lepší dotazy v některých situacích) + Připojení ion. Otevřít + Command.ExecuteReader + DataReader.Read Materializace objektů: Střední (rychlejší než EF5) – Vyhledávání identity: střední |
} |
Připojení ion. Zavřete | nízkou | nízkou | nízkou |
Druhé spuštění dotazu – teplý dotaz
| Zápisy uživatelů kódu | Akce | Dopad na výkon EF4 | Dopad na výkon EF5 | Dopad na výkon EF6 |
|---|---|---|---|---|
using(var db = new MyContext()) { |
Vytvoření kontextu | Medium | Medium | nízkou |
var q1 = from c in db.Customers where c.Id == id1 select c; |
Vytvoření výrazu dotazu | nízkou | nízkou | nízkou |
var c1 = q1.First(); |
Provádění dotazů LINQ | - Načítání metadat vyhledávání - Zobrazení - Vyhodnocení parametru: střední - Vyhledávání překladu - Vyhledávání generování – Spouštění databázových dotazů: Potenciálně vysoké + Připojení ion. Otevřít + Command.ExecuteReader + DataReader.Read Materializace objektů: Střední – Vyhledávání identity: střední |
- Načítání metadat vyhledávání - Zobrazení - Vyhodnocení parametru: Nízká – Vyhledávání překladu - Vyhledávání generování – Spouštění databázových dotazů: Potenciálně vysoké (lepší dotazy v některých situacích) + Připojení ion. Otevřít + Command.ExecuteReader + DataReader.Read Materializace objektů: Střední – Vyhledávání identity: střední |
- Načítání metadat vyhledávání - Zobrazení - Vyhodnocení parametru: Nízká – Vyhledávání překladu - Vyhledávání generování – Spouštění databázových dotazů: Potenciálně vysoké (lepší dotazy v některých situacích) + Připojení ion. Otevřít + Command.ExecuteReader + DataReader.Read Materializace objektů: Střední (rychlejší než EF5) – Vyhledávání identity: střední |
} |
Připojení ion. Zavřete | nízkou | nízkou | nízkou |
Existuje několik způsobů, jak snížit náklady na výkon studených i teplých dotazů a podíváme se na ně v následující části. Konkrétně se podíváme na snížení nákladů na načítání modelu v studených dotazech pomocí předem vygenerovaných zobrazení, která by měla pomoct zmírnit problémy s výkonem, ke kterým došlo během generování zobrazení. V případě teplých dotazů se budeme zabývat ukládáním plánů dotazů do mezipaměti, žádnými sledovacími dotazy a různými možnostmi provádění dotazů.
2.1 Co je generování zobrazení?
Abychom pochopili, co je generování zobrazení, musíme nejprve pochopit, co jsou "Zobrazení mapování". Mapování zobrazení jsou spustitelné reprezentace transformací zadaných v mapování pro každou sadu entit a přidružení. Interně tato zobrazení mapování mají tvar CQT (kanonické stromy dotazů). Existují dva typy zobrazení mapování:
- Zobrazení dotazů: Představují transformaci potřebnou k přechodu ze schématu databáze na koncepční model.
- Zobrazení aktualizací: Představují transformaci potřebnou k přechodu z konceptuálního modelu na schéma databáze.
Mějte na paměti, že koncepční model se může lišit od schématu databáze různými způsoby. Jedna tabulka může být například použita k ukládání dat pro dva různé typy entit. Dědičnost a ne triviální mapování hrají roli v složitosti zobrazení mapování.
Proces výpočtu těchto zobrazení na základě specifikace mapování je to, co nazýváme generování zobrazení. Generování zobrazení může probíhat dynamicky při načtení modelu nebo v době sestavení pomocí předem vygenerovaných zobrazení; tyto příkazy jsou serializovány ve formě příkazů Entity SQL do souboru C# nebo VB.
Při generování zobrazení se také ověří. Z hlediska výkonu je velká většina nákladů na generování zobrazení ve skutečnosti ověřením zobrazení, která zajišťují, že propojení mezi entitami mají smysl a mají správnou kardinalitu pro všechny podporované operace.
Když se provede dotaz nad sadou entit, dotaz se zkombinuje s odpovídajícím zobrazením dotazu a výsledkem tohoto složení je spuštění prostřednictvím kompilátoru plánu, který vytvoří reprezentaci dotazu, kterému backingové úložiště dokáže porozumět. Pro SQL Server bude konečným výsledkem této kompilace příkaz T-SQL SELECT. Při prvním provedení aktualizace sady entit se zobrazení aktualizace provede podobným procesem, který ho transformuje na příkazy DML pro cílovou databázi.
2.2 Faktory, které ovlivňují výkon generování zobrazení
Výkon kroku generování zobrazení nejen závisí na velikosti modelu, ale také na tom, jak je model propojený. Pokud jsou dvě entity propojené prostřednictvím řetězu dědičnosti nebo přidružení, říká se, že jsou propojené. Podobně pokud jsou dvě tabulky propojeny pomocí cizího klíče, jsou propojeny. S rostoucím počtem propojených entit a tabulek ve vašich schématech se zvýší náklady na generování zobrazení.
Algoritmus, který používáme k vygenerování a ověřování zobrazení, je v nejhorším případě exponenciální, i když k vylepšení používáme některé optimalizace. Největší faktory, které se zdají negativně ovlivnit výkon, jsou:
- Velikost modelu odkazující na počet entit a množství přidružení mezi těmito entitami.
- Složitost modelu, konkrétně dědičnost zahrnující velký počet typů
- Použití nezávislých přidružení místo přidružení cizího klíče.
U malých, jednoduchých modelů může být náklady dostatečně malé, aby neobtěžovaly použití předem vygenerovaných zobrazení. S rostoucí velikostí modelu a složitostí je k dispozici několik možností, které snižují náklady na generování a ověřování zobrazení.
2.3 Snížení doby načítání modelu pomocí předem generovaných zobrazení
Podrobné informace o tom, jak používat předem generovaná zobrazení entity Framework 6, najdete v tématu Předgenerovaná zobrazení mapování.
2.3.1 Předgenerovaná zobrazení pomocí entity Framework Power Tools Community Edition
Pomocí entity Framework 6 Power Tools Community Edition můžete vygenerovat zobrazení modelů EDMX a Code First tak, že kliknete pravým tlačítkem myši na soubor třídy modelu a pomocí nabídky Entity Framework vyberete Možnost Generovat zobrazení. Entity Framework Power Tools Community Edition funguje pouze na kontextech odvozených od DbContext.
2.3.2 Použití předgenerovaných zobrazení s modelem vytvořeným EDMGen
EDMGen je nástroj, který je dodáván s .NET a pracuje s Entity Framework 4 a 5, ale ne s Entity Framework 6. EDMGen umožňuje vygenerovat soubor modelu, vrstvu objektu a zobrazení z příkazového řádku. Jedním z výstupů bude soubor Views ve vašem jazyce podle výběru, VB nebo C#. Toto je soubor kódu obsahující fragmenty kódu entity SQL pro každou sadu entit. Pokud chcete povolit předem vygenerovaná zobrazení, stačí do projektu zahrnout soubor.
Pokud ručně upravíte soubory schématu pro model, budete muset znovu vygenerovat soubor zobrazení. Můžete to provést spuštěním EDMGen s příznakem /mode:ViewGeneration .
2.3.3 Použití předgenerovaných zobrazení se souborem EDMX
Pomocí EDMGen můžete také vygenerovat zobrazení pro soubor EDMX – dříve odkazované téma MSDN popisuje, jak k tomu přidat předem připravenou událost , ale je to složité a v některých případech to není možné. Obecně je jednodušší použít šablonu T4 k vygenerování zobrazení, když je váš model v souboru edmx.
Blog týmu ADO.NET obsahuje příspěvek, který popisuje, jak použít šablonu T4 pro generování zobrazení ( <https://learn.microsoft.com/archive/blogs/adonet/how-to-use-a-t4-template-for-view-generation>). Tento příspěvek obsahuje šablonu, kterou si můžete stáhnout a přidat do projektu. Šablona byla napsána pro první verzi entity Framework, takže není zaručeno, že budou fungovat s nejnovějšími verzemi Entity Frameworku. Můžete si ale stáhnout aktuální sadu šablon generování zobrazení pro Entity Framework 4 a 5 z galerie sady Visual Studio:
- VB.NET: <http://visualstudiogallery.msdn.microsoft.com/118b44f2-1b91-4de2-a584-7a680418941d>
- C#: <http://visualstudiogallery.msdn.microsoft.com/ae7730ce-ddab-470f-8456-1b313cd2c44d>
Pokud používáte Entity Framework 6, můžete získat šablony T4 pro zobrazení z galerie sady Visual Studio na adrese <http://visualstudiogallery.msdn.microsoft.com/18a7db90-6705-4d19-9dd1-0a6c23d0751f>.
2.4 Snížení nákladů na generování zobrazení
Použití předem vygenerovaných zobrazení přesune náklady na generování zobrazení z načítání modelu (doba běhu) do doby návrhu. I když se tím zlepší výkon při spuštění za běhu, při vývoji se stále setkáte s bolestí generování zobrazení. Existuje několik dalších triků, které můžou pomoct snížit náklady na generování zobrazení, a to jak v době kompilace, tak v době běhu.
2.4.1 Použití přidružení cizího klíče ke snížení nákladů na generování
Viděli jsme řadu případů, kdy přepnutí přidružení v modelu z nezávislých přidružení na přidružení cizího klíče výrazně zlepšilo dobu strávenou ve generování zobrazení.
Abychom toto vylepšení ukázali, vygenerovali jsme dvě verze modelu Navision pomocí EDMGen. Poznámka: Popis modelu Navision najdete v dodatku C. Model Navision je pro toto cvičení zajímavý z důvodu velkého množství entit a vztahů mezi nimi.
Jedna verze tohoto velmi velkého modelu byla generována s přidruženími cizích klíčů a druhá byla generována s nezávislými přidruženími. Potom jsme načasovali, jak dlouho trvalo generování zobrazení pro každý model. Test Entity Framework 5 použil metodu GenerateViews() z třídy EntityViewGenerator ke generování zobrazení, zatímco Entity Framework 6 test použil GenerateViews() metoda ze třídy StorageMappingItemCollection. Důvodem je restrukturalizace kódu, ke které došlo v základu kódu Entity Framework 6.
Generování modelu s cizími klíči pomocí entity Entity Framework 5 trvalo 65 minut v testovacím počítači. Není známo, jak dlouho by trvalo vygenerovat zobrazení modelu, který používal nezávislé přidružení. Test jsme nechali spuštěný po dobu více než měsíc, než se počítač restartoval v našem testovacím prostředí, aby se nainstalovaly měsíční aktualizace.
Použití Entity Framework 6, generování zobrazení pro model s cizími klíči trvalo 28 sekund ve stejném testovacím počítači. Generování zobrazení modelu, který používá nezávislé přidružení, trvalo 58 sekund. Vylepšení entity Frameworku 6 v kódu pro generování zobrazení znamenají, že mnoho projektů nebude potřebovat předem vygenerovaná zobrazení, aby bylo rychlejší spouštění.
Je důležité poznamenat, že předem generující zobrazení v sadě Entity Framework 4 a 5 je možné provádět s EDMGen nebo Nástroji Entity Framework Power Tools. Generování zobrazení Entity Framework 6 lze provádět prostřednictvím nástrojů Power Tools entity Framework nebo programově, jak je popsáno v předgenerovaných zobrazeních mapování.
2.4.1.1 Jak používat cizí klíče místo nezávislých přidružení
Při použití EDMGen nebo Návrháře entit v sadě Visual Studio získáte ve výchozím nastavení sady FK a pro přepínání mezi sadami FA a IA trvá jenom jedno zaškrtávací políčko nebo příznak příkazového řádku.
Pokud máte velký model Code First, použití nezávislých přidružení bude mít stejný vliv na generování zobrazení. Tento dopad můžete zabránit zahrnutím vlastností cizího klíče do tříd závislých objektů, i když někteří vývojáři budou považovat za znečisťující objektový model. Další informace o tomto tématu najdete v <http://blog.oneunicorn.com/2011/12/11/whats-the-deal-with-mapping-foreign-keys-using-the-entity-framework/>tématu .
| Při použití | Postup |
|---|---|
| Návrhář entit | Po přidání přidružení mezi dvě entity se ujistěte, že máte referenční omezení. Referenční omezení říkají entity Frameworku, aby místo nezávislých přidružení používala cizí klíče. Další podrobnosti najdete na adrese <https://learn.microsoft.com/archive/blogs/efdesign/foreign-keys-in-the-entity-framework>. |
| EDMGen | Při použití EDMGen k vygenerování souborů z databáze se vaše cizí klíče respektují a přidají do modelu. Další informace o různých možnostech vystavených EDMGen navštivte http://msdn.microsoft.com/library/bb387165.aspx. |
| Code First | Informace o tom, jak zahrnout vlastnosti cizího klíče na závislých objektech při použití code First, najdete v části "Konvence vztahů". |
2.4.2 Přesunutí modelu do samostatného sestavení
Pokud je váš model zahrnutý přímo do projektu vaší aplikace a vygenerujete zobrazení prostřednictvím předpřipravené události nebo šablony T4, generování a ověření zobrazení proběhne při každém opětovném vytvoření projektu, i když se model nezměnil. Pokud model přesunete do samostatného sestavení a na něj odkazujete z projektu aplikace, můžete v aplikaci provést další změny, aniž byste museli znovu sestavit projekt obsahující model.
Poznámka: Při přesouvání modelu do samostatných sestavení nezapomeňte zkopírovat připojovací řetězec modelu do konfiguračního souboru aplikace klientského projektu.
2.4.3 Zakázání ověřování modelu založeného na edmxu
Modely EDMX se ověřují v době kompilace, i když se model nezmění. Pokud už byl model ověřen, můžete potlačit ověření v době kompilace nastavením vlastnosti Ověřit při sestavení na hodnotu false v okně vlastností. Když změníte mapování nebo model, můžete dočasně znovu povolit ověření a ověřit změny.
Všimněte si, že vylepšení výkonu byla provedena v Návrháři entity Framework pro Entity Framework 6 a náklady na ověření při sestavení jsou mnohem nižší než v předchozích verzích návrháře.
3 Ukládání do mezipaměti v Entity Frameworku
Entity Framework má následující formy integrované mezipaměti:
- Ukládání objektů do mezipaměti – ObjectStateManager integrovaný do instance ObjectContext sleduje v paměti objektů, které byly načteny pomocí této instance. Označuje se také jako mezipaměť první úrovně.
- Plán dotazu Ukládání do mezipaměti – opětovné použití vygenerovaného příkazu úložiště při provádění dotazu více než jednou.
- Ukládání metadat do mezipaměti – sdílení metadat pro model napříč různými připojeními ke stejnému modelu
Kromě mezipamětí, které EF poskytuje, se dá použít také speciální druh ADO.NET zprostředkovatele dat označovaného jako zprostředkovatel obtékání, a rozšířit tak Entity Framework o mezipaměť pro výsledky načtené z databáze, označované také jako ukládání do mezipaměti druhé úrovně.
3.1 Objekt Ukládání do mezipaměti
Ve výchozím nastavení, když je entita vrácena ve výsledcích dotazu, těsně před tím, než ef materializuje, ObjectContext zkontroluje, zda entita se stejným klíčem již byla načtena do objektu ObjectStateManager. Pokud už existuje entita se stejnými klíči, ef ji zahrne do výsledků dotazu. I když EF stále vydá dotaz na databázi, toto chování může obejít většinu nákladů na materializaci entity vícekrát.
3.1.1 Získání entit z mezipaměti objektů pomocí DbContext Find
Na rozdíl od běžného dotazu provede metoda Find v DbSet (rozhraní API zahrnutá poprvé v EF 4.1) vyhledávání v paměti předtím, než dotaz odešle do databáze. Je důležité si uvědomit, že dvě různé instance ObjectContext budou mít dvě různé instance ObjectStateManager, což znamená, že mají samostatné mezipaměti objektů.
Funkce Find používá hodnotu primárního klíče k pokusu o vyhledání entity sledované kontextem. Pokud entita není v kontextu, provede se dotaz a vyhodnotí se vůči databázi a vrátí se hodnota null, pokud se entita nenajde v kontextu nebo v databázi. Funkce Find také vrací entity, které byly přidány do kontextu, ale ještě nebyly uloženy do databáze.
Při použití funkce Najít je potřeba vzít v úvahu výkon. Vyvolání této metody ve výchozím nastavení aktivuje ověření mezipaměti objektů, aby bylo možné zjistit změny, které stále čekají na potvrzení do databáze. Tento proces může být velmi nákladný, pokud je v mezipaměti objektů nebo v rozsáhlém grafu objektů přidaný do mezipaměti objektů velký počet objektů, ale může být také zakázán. V některých případech můžete při zakázání automatického zjišťování změn vnímat přes určitý rozsah rozdílu při volání metody Find. Druhý řád rozsahu je však vnímaný, když je objekt ve skutečnosti v mezipaměti a kdy se objekt musí načíst z databáze. Tady je příklad grafu s měřeními pořízenými pomocí některých z našich mikrobenchmarků vyjádřených v milisekundách s zatížením 5 000 entit:

Příklad funkce Najít se zakázanými změnami automatického zjišťování:
context.Configuration.AutoDetectChangesEnabled = false;
var product = context.Products.Find(productId);
context.Configuration.AutoDetectChangesEnabled = true;
...
Co je potřeba zvážit při použití metody Find:
- Pokud objekt není v mezipaměti, výhody Funkce Najít jsou negované, ale syntaxe je stále jednodušší než dotaz podle klíče.
- Pokud je povolená automatická detekce změn, mohou se náklady na metodu Find zvýšit o jeden řád nebo ještě více v závislosti na složitosti modelu a množství entit v mezipaměti objektů.
Mějte také na paměti, že Funkce Najít vrátí pouze entitu, kterou hledáte, a nenačte automaticky její přidružené entity, pokud ještě nejsou v mezipaměti objektů. Pokud potřebujete načíst přidružené entity, můžete použít dotaz podle klíče s dychtivým načtením. Další informace naleznete v tématu 8.1 Opožděné načítání vs. Dychtivé načítání.
3.1.2 Problémy s výkonem, když mezipaměť objektů obsahuje mnoho entit
Mezipaměť objektů pomáhá zvýšit celkovou odezvu entity Framework. Pokud ale mezipaměť objektů obsahuje velmi velké množství entit, může to mít vliv na určité operace, jako je Přidání, Odebrání, Najít, Položka, SaveChanges a další. Zejména operace, které aktivují volání DetectChanges, budou negativně ovlivněny velmi velkými mezipaměťmi objektů. Funkce DetectChanges synchronizuje graf objektů se správcem stavu objektu a jeho výkon se určí přímo podle velikosti grafu objektu. Další informace o DetectChanges naleznete v tématu Sledování změn v entitách POCO.
Při použití Entity Framework 6 mohou vývojáři volat AddRange a RemoveRange přímo na DbSet, místo iterace kolekce a volání Přidat jednou na instanci. Výhodou použití metod rozsahu je, že náklady na DetectChanges se platí pouze jednou za celou sadu entit, a nikoli jednou na každou přidanou entitu.
3.2 Ukládání do mezipaměti plánu dotazů
Při prvním spuštění dotazu prochází kompilátorem interního plánu a přeloží koncepční dotaz do příkazu úložiště (například T-SQL, který se spustí při spuštění na SQL Serveru). Pokud je povolené ukládání do mezipaměti plánu dotazů, při příštím spuštění dotazu se příkaz úložiště načte přímo z mezipaměti plánu dotazu pro spuštění a vynechá se kompilátor plánu.
Mezipaměť plánu dotazů se sdílí napříč instancemi ObjectContext ve stejné doméně AppDomain. Abyste mohli těžit z ukládání plánů dotazů do mezipaměti, nemusíte uchovávat instanci ObjectContext.
3.2.1 Některé poznámky k plánu dotazů Ukládání do mezipaměti
- Mezipaměť plánu dotazu se sdílí pro všechny typy dotazů: Entity SQL, LINQ to Entities a CompiledQuery objekty.
- Ve výchozím nastavení je ukládání plánu dotazů do mezipaměti povolené pro dotazy Entity SQL, ať už se provádí prostřednictvím EntityCommand nebo prostřednictvím ObjectQuery. Ve výchozím nastavení je povolená také pro dotazy LINQ to Entities v Entity Frameworku v rozhraní .NET 4.5 a Entity Framework 6.
- Ukládání plánů dotazů do mezipaměti lze zakázat nastavením vlastnosti EnablePlan Ukládání do mezipaměti (u EntityCommand nebo ObjectQuery) na hodnotu false. Příklad:
var query = from customer in context.Customer
where customer.CustomerId == id
select new
{
customer.CustomerId,
customer.Name
};
ObjectQuery oQuery = query as ObjectQuery;
oQuery.EnablePlanCaching = false;
- U parametrizovaných dotazů se změna hodnoty parametru stále dostane k dotazu uloženému v mezipaměti. Změna omezujících vlastností parametru (například velikost, přesnost nebo měřítko) ale dosáhne jiné položky v mezipaměti.
- Při použití Entity SQL je řetězec dotazu součástí klíče. Změna dotazu bude mít za následek různé položky mezipaměti, i když jsou dotazy funkčně ekvivalentní. To zahrnuje změny velikosti a mezer.
- Při použití LINQ se dotaz zpracuje tak, aby vygeneroval část klíče. Změna výrazu LINQ proto vygeneruje jiný klíč.
- Mohou platit další technická omezení; Další podrobnosti najdete v tématu Automatické kompilované dotazy.
3.2.2 Algoritmus vyřazení mezipaměti
Když pochopíte, jak funguje interní algoritmus, pomůže vám zjistit, kdy povolit nebo zakázat ukládání plánů dotazů do mezipaměti. Algoritmus čištění je následující:
- Jakmile mezipaměť obsahuje nastavený počet položek (800), spustíme časovač, který mezipaměť pravidelně (jednou za minutu) uklidí.
- Během úklidu mezipaměti se položky z mezipaměti odeberou z mezipaměti v LFRU (nejméně často – nedávno použité). Při rozhodování o tom, které položky se vysunou, bere tento algoritmus v úvahu jak počet hitů, tak věk.
- Na konci každého úklidu mezipaměti obsahuje mezipaměť znovu 800 položek.
Všechny položky mezipaměti se zpracovávají stejně při určování položek, které se mají vyřadit. To znamená, že příkaz úložiště pro CompiledQuery má stejnou šanci vyřazení jako příkaz úložiště pro dotaz Entity SQL.
Všimněte si, že časovač vyřazení mezipaměti se spustí v případě, že v mezipaměti je 800 entit, ale mezipaměť se po spuštění tohoto časovače zamíjí jen 60 sekund. To znamená, že po dobu až 60 sekund může vaše mezipaměť narůstat až na poměrně velkou velikost.
3.2.3 Testovací metriky demonstrující výkon plánů dotazů v ukládání do mezipaměti
Abychom ukázali účinek ukládání plánů dotazů do mezipaměti na výkon vaší aplikace, provedli jsme test, ve kterém jsme provedli řadu dotazů Entity SQL na model Navision. Popis modelu Navision a typy spuštěných dotazů najdete v dodatku. V tomto testu nejprve iterujeme seznam dotazů a spustíme je jednou, abychom je přidali do mezipaměti (pokud je ukládání do mezipaměti povolené). Tento krok není v čase. Dále přepíme hlavní vlákno po dobu více než 60 sekund, abychom umožnili uklidit mezipaměť; nakonec iterujeme seznamem 2. čas spuštění dotazů uložených v mezipaměti. Mezipaměť plánu SYSTÉMU SQL Server se navíc vyprázdní před spuštěním každé sady dotazů, aby časy, které získáme přesně, odrážely výhody poskytnuté mezipamětí plánu dotazů.
3.2.3.1 Výsledky zkoušky
| Test | EF5 – žádná mezipaměť | EF5 uložená v mezipaměti | EF6 bez mezipaměti | EF6 uložená v mezipaměti |
|---|---|---|---|---|
| Výčet všech 18723 dotazů | 124 | 125.4 | 124.3 | 125.3 |
| Vyhněte se úklidu (pouze prvních 800 dotazů bez ohledu na složitost) | 41.7 | 5.5 | 40.5 | 5.4 |
| Pouze agregační dotazysubtotals (celkem 178 – což se vyhne úklidu) | 39.5 | 4.5 | 38.1 | 4.6 |
Všechny časy v sekundách.
Morální – při provádění velkého množství jedinečných dotazů (například dynamicky vytvořených dotazů) se ukládání do mezipaměti nepomohlo a výsledné vyprázdnění mezipaměti může zachovat dotazy, které by nejvíce využívaly ukládání do mezipaměti plánu, aby je skutečně používaly.
Agregační dotazySubtotals jsou nejsložitější z dotazů, se kterými jsme testovali. Podle očekávání je čím složitější dotaz, tím větší výhodou je ukládání plánů dotazů do mezipaměti.
Vzhledem k tomu, že CompiledQuery je ve skutečnosti dotaz LINQ s jeho plánem uloženým v mezipaměti, porovnání kompilovaného dotazu a ekvivalentního dotazu Entity SQL by mělo mít podobné výsledky. Pokud má aplikace hodně dynamických dotazů Entity SQL, při vyprázdnění z mezipaměti z mezipaměti také efektivně způsobí dekompilování kompilátoruQueries. V tomto scénáři může být výkon vylepšen zakázáním ukládání do mezipaměti u dynamických dotazů, aby bylo možné určit prioritu CompiledQueries. Lepším by však bylo samozřejmě přepsat aplikaci tak, aby místo dynamických dotazů používala parametrizované dotazy.
3.3 Použití compiledQuery ke zlepšení výkonu s dotazy LINQ
Naše testy naznačují, že použití CompiledQuery může přinést výhodu 7 % oproti automaticky kompilovaným dotazům LINQ; to znamená, že provádění kódu ze zásobníku Entity Framework bude trávit méně času než 7 %. neznamená, že vaše aplikace bude o 7 % rychlejší. Obecně řečeno, náklady na psaní a údržbu kompilovaných objektůQuery v EF 5.0 nemusí být v porovnání s výhodami za problém. Vaše kilometry se můžou lišit, takže tuto možnost použijte, pokud váš projekt vyžaduje další nabízení. Všimněte si, že KompilovanéQuery jsou kompatibilní pouze s objektově odvozenými modely a nejsou kompatibilní s modely odvozenými od DbContext.
Další informace o vytváření a vyvolání CompiledQuery naleznete v tématu Kompilované dotazy (LINQ to Entities).
Při použití CompiledQuery je potřeba vzít v úvahu dva aspekty, konkrétně požadavek na použití statických instancí a problémy, které mají s kompozitovatelností. Tady najdete podrobné vysvětlení těchto dvou aspektů.
3.3.1 Použití statických instancí CompiledQuery
Vzhledem k tomu, že kompilace dotazu LINQ je časově náročný proces, nechceme to dělat pokaždé, když potřebujeme načíst data z databáze. Kompilované instanceQuery umožňují zkompilovat jednou a spustit vícekrát, ale musíte být opatrní a muset znovu použít stejnou instanci CompiledQuery pokaždé, když ji nemusíte kompilovat znovu a znovu. Použití statických členů k uložení instancí CompiledQuery je nezbytné; jinak neuvidíte žádnou výhodu.
Předpokládejme například, že vaše stránka obsahuje následující text metody pro zpracování zobrazení produktů pro vybranou kategorii:
// Warning: this is the wrong way of using CompiledQuery
using (NorthwindEntities context = new NorthwindEntities())
{
string selectedCategory = this.categoriesList.SelectedValue;
var productsForCategory = CompiledQuery.Compile<NorthwindEntities, string, IQueryable<Product>>(
(NorthwindEntities nwnd, string category) =>
nwnd.Products.Where(p => p.Category.CategoryName == category)
);
this.productsGrid.DataSource = productsForCategory.Invoke(context, selectedCategory).ToList();
this.productsGrid.DataBind();
}
this.productsGrid.Visible = true;
V tomto případě vytvoříte novou instanci CompiledQuery za běhu při každém zavolání metody. Místo zobrazení výhod výkonu načtením příkazu úložiště z mezipaměti plánu dotazů bude CompiledQuery procházet kompilátor plánu při každém vytvoření nové instance. Ve skutečnosti budete znečišťovat mezipaměť plánu dotazu novou položkou CompiledQuery při každém zavolání metody.
Místo toho chcete vytvořit statickou instanci kompilovaného dotazu, takže voláte stejný zkompilovaný dotaz pokaždé, když je volána metoda. Jedním ze způsobů, jak to udělat, je přidání instance CompiledQuery jako člena kontextu objektu. Potom můžete udělat trochu přehlednější přístup k CompiledQuery prostřednictvím pomocné metody:
public partial class NorthwindEntities : ObjectContext
{
private static readonly Func<NorthwindEntities, string, IEnumerable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
public IEnumerable<Product> GetProductsForCategory(string categoryName)
{
return productsForCategoryCQ.Invoke(this, categoryName).ToList();
}
Tato pomocná metoda by byla vyvolána následujícím způsobem:
this.productsGrid.DataSource = context.GetProductsForCategory(selectedCategory);
3.3.2 Kompilace přes CompiledQuery
Schopnost vytvářet přes jakýkoli dotaz LINQ je velmi užitečná; k tomu jednoduše vyvoláte metodu za IQueryable, jako je Skip() nebo Count(). Tím se ale v podstatě vrátí nový objekt IQueryable. I když není nic, co by vás technicky nezastavil v vytváření přes CompiledQuery, způsobí to generování nového objektu IQueryable, který vyžaduje opětovné průchod kompilátoru plánu.
Některé komponenty použijí složené objekty IQueryable k povolení pokročilých funkcí. Například Objekt GridView ASP.NET může být vázán na objekt IQueryable prostřednictvím SelectMethod vlastnost. Objekt GridView pak vytvoří přes tento objekt IQueryable, aby bylo možné řadit a stránkovat datový model. Jak vidíte, použití CompiledQuery pro GridView by nebylo dosaženo zkompilovaného dotazu, ale vygenerovalo by nový automaticky kompilovaný dotaz.
Jedním z míst, kde na to můžete narazit, je přidání progresivních filtrů do dotazu. Předpokládejme například, že jste měli stránku Zákazníci s několika rozevíracími seznamy pro volitelné filtry (například Země a OrdersCount). Tyto filtry můžete vytvořit přes výsledky IQueryable z CompiledQuery, ale výsledkem bude nový dotaz procházející kompilátorem plánu při každém spuštění.
using (NorthwindEntities context = new NorthwindEntities())
{
IQueryable<Customer> myCustomers = context.InvokeCustomersForEmployee();
if (this.orderCountFilterList.SelectedItem.Value != defaultFilterText)
{
int orderCount = int.Parse(orderCountFilterList.SelectedValue);
myCustomers = myCustomers.Where(c => c.Orders.Count > orderCount);
}
if (this.countryFilterList.SelectedItem.Value != defaultFilterText)
{
myCustomers = myCustomers.Where(c => c.Address.Country == countryFilterList.SelectedValue);
}
this.customersGrid.DataSource = myCustomers;
this.customersGrid.DataBind();
}
Abyste se vyhnuli této opětovné kompilaci, můžete přepsat CompiledQuery a vzít v úvahu možné filtry:
private static readonly Func<NorthwindEntities, int, int?, string, IQueryable<Customer>> customersForEmployeeWithFiltersCQ = CompiledQuery.Compile(
(NorthwindEntities context, int empId, int? countFilter, string countryFilter) =>
context.Customers.Where(c => c.Orders.Any(o => o.EmployeeID == empId))
.Where(c => countFilter.HasValue == false || c.Orders.Count > countFilter)
.Where(c => countryFilter == null || c.Address.Country == countryFilter)
);
To by se vyvolalo v uživatelském rozhraní takto:
using (NorthwindEntities context = new NorthwindEntities())
{
int? countFilter = (this.orderCountFilterList.SelectedIndex == 0) ?
(int?)null :
int.Parse(this.orderCountFilterList.SelectedValue);
string countryFilter = (this.countryFilterList.SelectedIndex == 0) ?
null :
this.countryFilterList.SelectedValue;
IQueryable<Customer> myCustomers = context.InvokeCustomersForEmployeeWithFilters(
countFilter, countryFilter);
this.customersGrid.DataSource = myCustomers;
this.customersGrid.DataBind();
}
Tady je kompromisem vygenerovaný příkaz úložiště, který bude mít vždy filtry s kontrolami null, ale pro databázový server by měl být poměrně jednoduchý pro optimalizaci:
...
WHERE ((0 = (CASE WHEN (@p__linq__1 IS NOT NULL) THEN cast(1 as bit) WHEN (@p__linq__1 IS NULL) THEN cast(0 as bit) END)) OR ([Project3].[C2] > @p__linq__2)) AND (@p__linq__3 IS NULL OR [Project3].[Country] = @p__linq__4)
3.4 Ukládání metadat do mezipaměti
Entity Framework také podporuje ukládání metadat do mezipaměti. To je v podstatě ukládání informací o typu do mezipaměti a informace mapování typu na databázi napříč různými připojeními ke stejnému modelu. Mezipaměť metadat je jedinečná pro každou doménu AppDomain.
3.4.1 Algoritmus Ukládání do mezipaměti metadat
Informace o metadatech pro model jsou uloženy v ItemCollection pro každou entitu Připojení ion.
- Jako poznámka na straně jsou různé ItemCollection objekty pro různé části modelu. Například StoreItemCollections obsahuje informace o databázovém modelu; ObjectItemCollection obsahuje informace o datovém modelu; EdmItemCollection obsahuje informace o konceptuálním modelu.
Pokud dvě připojení používají stejnou připojovací řetězec, budou sdílet stejnou instanci ItemCollection.
Funkčně ekvivalentní, ale textově odlišné připojovací řetězec mohou vést k různým mezipamětí metadat. Provádíme tokenizaci připojovací řetězec, takže změna pořadí tokenů by měla vést ke sdíleným metadatům. Ale dvě připojovací řetězec, které se zdají být funkčně stejné, nemusí být po tokenizaci vyhodnoceny jako identické.
ItemCollection se pravidelně kontroluje pro použití. Pokud se zjistí, že k pracovnímu prostoru se v poslední době nepřistupuje, označí se k vyčištění při dalším úklidu mezipaměti.
Pouhé vytvoření entity Připojení ion způsobí vytvoření mezipaměti metadat (i když kolekce položek v ní nebudou inicializovány, dokud se připojení neotevře). Tento pracovní prostor zůstane v paměti, dokud algoritmus ukládání do mezipaměti nezůstane "používán".
Poradní tým pro zákazníky napsal blogový příspěvek, který popisuje uchovávání odkazu na ItemCollection, aby se zabránilo "vyřazení" při použití velkých modelů: <https://learn.microsoft.com/archive/blogs/appfabriccat/holding-a-reference-to-the-ef-metadataworkspace-for-wcf-services>.
3.4.2 Vztah mezi Ukládání do mezipaměti metadat a Ukládání do mezipaměti plánu dotazů
Instance mezipaměti plánu dotazu se nachází v ItemCollection typu úložiště metadataWorkspace. To znamená, že příkazy úložiště uložené v mezipaměti se použijí pro dotazy na jakékoli kontextové instance pomocí dané instance MetadataWorkspace. To také znamená, že pokud máte dva připojovací řetězce, které se mírně liší a po tokenizaci se neshodují, budete mít různé instance mezipaměti plánu dotazů.
3.5 Výsledky ukládání do mezipaměti
Ukládání výsledků do mezipaměti (označované také jako "ukládání do mezipaměti druhé úrovně") uchovává výsledky dotazů v místní mezipaměti. Při vydávání dotazu nejprve uvidíte, jestli jsou výsledky k dispozici místně, než se dotazujete na úložiště. I když Entity Framework nepodporuje ukládání výsledků do mezipaměti přímo, je možné přidat mezipaměť druhé úrovně pomocí zprostředkovatele obtékání. Příkladem zprostředkovatele zabalení s mezipamětí druhé úrovně je mezipaměť Entity Framework Entity Framework druhé úrovně založená na NCache.
Tato implementace ukládání do mezipaměti druhé úrovně je vložená funkce, která se provádí po vyhodnocení výrazu LINQ (a funcletized) a plán provádění dotazů se vypočítá nebo načte z první úrovně mezipaměti. Mezipaměť druhé úrovně pak uloží pouze nezpracované výsledky databáze, takže kanál materializace se bude dál spouštět.
3.5.1 Další odkazy na ukládání výsledků do mezipaměti s poskytovatelem obtékání
- Julie Lerman napsala článek MSDN "Second-Level Ukládání do mezipaměti in Entity Framework a Windows Azure", který obsahuje informace o tom, jak aktualizovat poskytovatele ukázkových obtékání tak, aby používal ukládání do mezipaměti Windows Server AppFabric:https://msdn.microsoft.com/magazine/hh394143.aspx
- Pokud pracujete s Entity Framework 5, týmový blog obsahuje příspěvek, který popisuje, jak začít pracovat s poskytovatelem ukládání do mezipaměti pro Entity Framework 5: <https://learn.microsoft.com/archive/blogs/adonet/ef-caching-with-jarek-kowalskis-provider>. Obsahuje také šablonu T4, která pomáhá automatizovat přidávání mezipaměti na 2. úrovni do projektu.
4 Automaticky kompilované dotazy
Pokud je dotaz vydán pro databázi pomocí Entity Framework, musí projít řadou kroků, než skutečně materializuje výsledky; jedním z takových kroků je kompilace dotazu. Dotazy Entity SQL měly dobrý výkon, protože se automaticky ukládají do mezipaměti, takže druhý nebo třetí čas spuštění stejného dotazu může přeskočit kompilátor plánu a místo toho použít plán uložený v mezipaměti.
Entity Framework 5 zavedla také automatické ukládání do mezipaměti pro dotazy LINQ to Entities. V minulých edicích Entity Frameworku, které vytváří CompiledQuery pro zrychlení výkonu, bylo běžné, protože to by z dotazu LINQ to Entities do mezipaměti. Vzhledem k tomu, že ukládání do mezipaměti se teď provádí automaticky bez použití CompiledQuery, nazýváme tuto funkci "automaticky kompilované dotazy". Další informace o mezipaměti plánu dotazů a jeho mechanikě najdete v tématu Ukládání do mezipaměti plánu dotazů.
Entity Framework zjistí, kdy dotaz vyžaduje rekompilování, a to při vyvolání dotazu i v případě, že byl zkompilován dříve. Mezi běžné podmínky, které způsobují rekompilování dotazu, patří:
- Změna funkce MergeOption přidružená k dotazu Dotaz uložený v mezipaměti se nepoužije, místo toho se kompilátor plánu spustí znovu a nově vytvořený plán se uloží do mezipaměti.
- Změna hodnoty ContextOptions.UseCSharpNullComparisonBehavior. Zobrazí se stejný efekt jako změna funkce MergeOption.
Jiné podmínky můžou zabránit tomu, aby dotaz používal mezipaměť. Obvyklými příklady jsou:
- Použití IEnumerable<T>. Contains<>(T value).
- Použití funkcí, které vytvářejí dotazy s konstantami
- Použití vlastností nemapovaného objektu
- Propojení dotazu s jiným dotazem, který vyžaduje překompilování.
4.1 Použití IEnumerable<T>. Obsahuje<hodnotu T>(T)
Entity Framework neukládá dotazy, které vyvolávají IEnumerable<T>. Obsahuje<hodnotu T>(T) pro kolekci v paměti, protože hodnoty kolekce jsou považovány za nestálé. Následující příklad dotazu nebude uložen do mezipaměti, takže bude vždy zpracován kompilátorem plánu:
int[] ids = new int[10000];
...
using (var context = new MyContext())
{
var query = context.MyEntities
.Where(entity => ids.Contains(entity.Id));
var results = query.ToList();
...
}
Všimněte si, že velikost IEnumerable, která obsahuje je spuštěna, určuje, jak rychle nebo jak pomalé je dotaz zkompilován. Výkon může při použití velkých kolekcí, jako je například výkon uvedený v předchozím příkladu, výrazně trpět.
Entity Framework 6 obsahuje optimalizace způsobu, jakým IEnumerable<T>. Obsahuje<hodnotu T>(T) funguje při spuštění dotazů. Kód SQL, který se generuje, je mnohem rychlejší a čitelnější a ve většině případů se také provádí rychleji na serveru.
4.2 Použití funkcí, které vytvářejí dotazy s konstantami
Operátory LINQ Skip(), Take(), Contains() a DefautIfEmpty() negenerují dotazy SQL s parametry, ale místo toho hodnoty předané jako konstanty. Z tohoto důvodu dotazy, které by jinak mohly být identické, skončí znečistí mezipaměť plánu dotazů, a to jak v zásobníku EF, tak na databázovém serveru, a nebudou znovu využity, pokud se při následném spuštění dotazu nepoužijí stejné konstanty. Příklad:
var id = 10;
...
using (var context = new MyContext())
{
var query = context.MyEntities.Select(entity => entity.Id).Contains(id);
var results = query.ToList();
...
}
V tomto příkladu se při každém spuštění tohoto dotazu s jinou hodnotou ID dotazu zkompiluje do nového plánu.
Zejména věnujte pozornost použití funkce Skip a Take při stránkování. V EF6 tyto metody mají přetížení lambda, které efektivně umožňuje opakovaně použít plán dotazu v mezipaměti, protože EF může zachytit proměnné předané těmto metodám a přeložit je na SQLparameters. To také pomáhá udržovat mezipaměť čistější, protože jinak by každý dotaz s jinou konstantou pro Skip a Take získal vlastní položku mezipaměti plánu dotazů.
Vezměte v úvahu následující kód, který je neoptimální, ale má pouze exemplifikaci této třídy dotazů:
var customers = context.Customers.OrderBy(c => c.LastName);
for (var i = 0; i < count; ++i)
{
var currentCustomer = customers.Skip(i).FirstOrDefault();
ProcessCustomer(currentCustomer);
}
Rychlejší verze stejného kódu by zahrnovala volání skipu s lambda:
var customers = context.Customers.OrderBy(c => c.LastName);
for (var i = 0; i < count; ++i)
{
var currentCustomer = customers.Skip(() => i).FirstOrDefault();
ProcessCustomer(currentCustomer);
}
Druhý fragment kódu může běžet až o 11 % rychleji, protože se při každém spuštění dotazu použije stejný plán dotazu, což šetří čas procesoru a zabraňuje znečisťování mezipaměti dotazů. Vzhledem k tomu, že parametr Skip je v uzavření kódu, může teď vypadat takto:
var i = 0;
var skippyCustomers = context.Customers.OrderBy(c => c.LastName).Skip(() => i);
for (; i < count; ++i)
{
var currentCustomer = skippyCustomers.FirstOrDefault();
ProcessCustomer(currentCustomer);
}
4.3 Použití vlastností nemapovaného objektu
Pokud dotaz jako parametr používá vlastnosti nemapovaného typu objektu, dotaz se do mezipaměti nedostane. Příklad:
using (var context = new MyContext())
{
var myObject = new NonMappedType();
var query = from entity in context.MyEntities
where entity.Name.StartsWith(myObject.MyProperty)
select entity;
var results = query.ToList();
...
}
V tomto příkladu předpokládejme, že třída NonMappedType není součástí modelu Entity. Tento dotaz lze snadno změnit tak, aby nepoužít nemapovaný typ, a místo toho jako parametr dotazu použijte místní proměnnou:
using (var context = new MyContext())
{
var myObject = new NonMappedType();
var myValue = myObject.MyProperty;
var query = from entity in context.MyEntities
where entity.Name.StartsWith(myValue)
select entity;
var results = query.ToList();
...
}
V takovém případě bude dotaz moct získat mezipaměť a bude mít prospěch z mezipaměti plánu dotazů.
4.4 Propojení s dotazy, které vyžadují rekompilování
Pokud máte druhý dotaz, který závisí na dotazu, který je potřeba znovu zkompilovat, použijeme stejný příklad jako v předchozím příkladu, celý druhý dotaz se také znovu zkompiluje. Tady je příklad pro ilustraci tohoto scénáře:
int[] ids = new int[10000];
...
using (var context = new MyContext())
{
var firstQuery = from entity in context.MyEntities
where ids.Contains(entity.Id)
select entity;
var secondQuery = from entity in context.MyEntities
where firstQuery.Any(otherEntity => otherEntity.Id == entity.Id)
select entity;
var results = secondQuery.ToList();
...
}
Příklad je obecný, ale ukazuje, jak propojení s firstQuery způsobuje, že secondQuery nemůže získat mezipaměť. Pokud by firstQuery nebyl dotaz, který vyžaduje rekompilování, byl by druhýQuery uložen v mezipaměti.
5 Dotazy NoTracking
5.1 Zakázání sledování změn za účelem snížení režie na správu stavu
Pokud jste ve scénáři jen pro čtení a chcete se vyhnout režii načítání objektů do ObjectStateManager, můžete vydat dotazy Typu Bez sledování. Sledování změn je možné zakázat na úrovni dotazu.
Všimněte si, že zakázáním sledování změn efektivně vypnete mezipaměť objektů. Při dotazování na entitu nemůžeme materializaci přeskočit načtením dříve materializovaných výsledků dotazu z objectStateManageru. Pokud se opakovaně dotazujete na stejné entity ve stejném kontextu, můžete ve skutečnosti vidět výhodu výkonu při povolování sledování změn.
Při dotazování pomocí ObjectContext, ObjectQuery a ObjectSet instance si zapamatují MergeOption, jakmile je nastavena, a dotazy, které se na nich skládají, zdědí efektivní MergeOption nadřazeného dotazu. Při použití DbContext lze sledování zakázat voláním modifikátoru AsNoTracking() v DbSet.
5.1.1 Zakázání sledování změn dotazu při použití DbContext
Režim dotazu můžete přepnout na NoTracking zřetězením volání metody AsNoTracking() v dotazu. Na rozdíl od ObjectQuery nemají třídy DbSet a DbQuery v rozhraní DBContext API proměnlivou vlastnost mergeOption.
var productsForCategory = from p in context.Products.AsNoTracking()
where p.Category.CategoryName == selectedCategory
select p;
5.1.2 Zakázání sledování změn na úrovni dotazu pomocí ObjectContext
var productsForCategory = from p in context.Products
where p.Category.CategoryName == selectedCategory
select p;
((ObjectQuery)productsForCategory).MergeOption = MergeOption.NoTracking;
5.1.3 Zakázání sledování změn pro celou sadu entit pomocí ObjectContext
context.Products.MergeOption = MergeOption.NoTracking;
var productsForCategory = from p in context.Products
where p.Category.CategoryName == selectedCategory
select p;
5.2 Testovací metriky demonstrující výhody výkonu dotazů NoTracking
V tomto testu se podíváme na náklady na vyplnění ObjectStateManager porovnáním sledování s dotazy NoTracking pro model Navision. Popis modelu Navision a typy spuštěných dotazů najdete v dodatku. V tomto testu iterujeme seznam dotazů a provedeme každý z nich jednou. Spustili jsme dvě varianty testu, jednou s dotazy NoTracking a jednou s výchozí možností sloučení "AppendOnly". Každou variantu jsme spustili 3krát a vzali střední hodnotu spuštění. Mezi testy vymažeme mezipaměť dotazů na SQL Serveru a zmenšíme databázi tempdb spuštěním následujících příkazů:
- DBCC DROPCLEANBUFFERS
- DBCC FREEPROCCACHE
- DBCC SHRINKDATABASE (tempdb, 0)
Výsledky testů, medián nad 3 spuštěními:
| BEZ SLEDOVÁNÍ – PRACOVNÍ SADA | BEZ SLEDOVÁNÍ – ČAS | POUZE PŘIPOJENÍ – PRACOVNÍ SADA | POUZE PŘIPOJENÍ – ČAS | |
|---|---|---|---|---|
| Entity Framework 5 | 460361728 | 1163536 ms | 596545536 | 1273042 ms |
| Entity Framework 6 | 647127040 | 190228 ms | 832798720 | 195521 ms |
Entity Framework 5 bude mít na konci spuštění menší nároky na paměť než Entity Framework 6. Další paměť spotřebovaná rozhraním Entity Framework 6 je výsledkem dalších struktur paměti a kódu, které umožňují nové funkce a lepší výkon.
Při použití ObjectStateManageru je také jasný rozdíl v paměti. Entity Framework 5 zvýšil svou stopu o 30 % při sledování všech entit, které jsme materializovali z databáze. Entity Framework 6 při tom zvýšil svou stopu o 28 %.
Z hlediska času entity Framework 6 v tomto testu překoná Entity Framework 5 velkým okrajem. Entity Framework 6 dokončil test přibližně v 16 % času spotřebovaného entity Framework 5. Kromě toho entity Framework 5 trvá dokončení objektu ObjectStateManager 5 9 % času. Ve srovnání, Entity Framework 6 používá 3% více času při použití ObjectStateManager.
6 Možnosti spuštění dotazu
Entity Framework nabízí několik různých způsobů dotazování. Podíváme se na následující možnosti, porovnáme výhody a nevýhody jednotlivých možností a prozkoumáme jejich charakteristiky výkonu:
- LINQ to Entities.
- Žádné sledování LINQ to Entities.
- Entity SQL přes ObjectQuery
- Entity SQL přes EntityCommand.
- ExecuteStoreQuery.
- SqlQuery.
- CompiledQuery.
6.1 Dotazy LINQ to Entities
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
Výhody
- Vhodné pro operace CUD.
- Plně materializované objekty.
- Nejjednodušší psát se syntaxí integrovanou do programovacího jazyka.
- Dobrý výkon.
Nevýhody
- Určitá technická omezení, například:
- Vzory používající DefaultIfEmpty pro dotazy OUTER JOIN vedou ke složitějším dotazům než jednoduché příkazy OUTER JOIN v Entity SQL.
- Funkce LIKE se stále nedá použít s obecnými porovnávání vzorů.
6.2 Bez sledování dotazů LINQ to Entities
Když kontext odvozuje ObjectContext:
context.Products.MergeOption = MergeOption.NoTracking;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
Při odvození kontextu DbContext:
var q = context.Products.AsNoTracking()
.Where(p => p.Category.CategoryName == "Beverages");
Výhody
- Vyšší výkon oproti běžným dotazům LINQ.
- Plně materializované objekty.
- Nejjednodušší psát se syntaxí integrovanou do programovacího jazyka.
Nevýhody
- Není vhodný pro operace CUD.
- Určitá technická omezení, například:
- Vzory používající DefaultIfEmpty pro dotazy OUTER JOIN vedou ke složitějším dotazům než jednoduché příkazy OUTER JOIN v Entity SQL.
- Funkce LIKE se stále nedá použít s obecnými porovnávání vzorů.
Všimněte si, že dotazy, které skalární vlastnosti projektu nejsou sledovány, i když není zadáno NoTracking. Příklad:
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages").Select(p => new { p.ProductName });
Tento konkrétní dotaz explicitně neurčuje noTracking, ale protože ne materializuje typ, který je známý správci stavu objektu, materializovaný výsledek se nesleduje.
6.3 Entity SQL přes ObjectQuery
ObjectQuery<Product> products = context.Products.Where("it.Category.CategoryName = 'Beverages'");
Výhody
- Vhodné pro operace CUD.
- Plně materializované objekty.
- Podporuje ukládání plánů dotazů do mezipaměti.
Nevýhody
- Zahrnuje textové řetězce dotazů, které jsou náchylnější k chybě uživatele než konstrukty dotazů integrované do jazyka.
6.4 Entity SQL přes příkaz Entity
EntityCommand cmd = eConn.CreateCommand();
cmd.CommandText = "Select p From NorthwindEntities.Products As p Where p.Category.CategoryName = 'Beverages'";
using (EntityDataReader reader = cmd.ExecuteReader(CommandBehavior.SequentialAccess))
{
while (reader.Read())
{
// manually 'materialize' the product
}
}
Výhody
- Podporuje ukládání plánů dotazů do mezipaměti v .NET 4.0 (ukládání plánů do mezipaměti podporuje všechny ostatní typy dotazů v .NET 4.5).
Nevýhody
- Zahrnuje textové řetězce dotazů, které jsou náchylnější k chybě uživatele než konstrukty dotazů integrované do jazyka.
- Není vhodný pro operace CUD.
- Výsledky nejsou automaticky materializovány a musí se číst ze čtečky dat.
6.5 SqlQuery a ExecuteStoreQuery
SqlQuery v databázi:
// use this to obtain entities and not track them
var q1 = context.Database.SqlQuery<Product>("select * from products");
SqlQuery v dbSet:
// use this to obtain entities and have them tracked
var q2 = context.Products.SqlQuery("select * from products");
ExecuteStoreQuery:
var beverages = context.ExecuteStoreQuery<Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued, P.DiscontinuedDate
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
Výhody
- Obecně nejrychlejší výkon, protože kompilátor plánu je vynechána.
- Plně materializované objekty.
- Vhodné pro operace CUD při použití ze sady DbSet.
Nevýhody
- Dotaz je textový a náchylný k chybám.
- Dotaz je svázaný s konkrétním back-endem pomocí sémantiky úložiště místo konceptuální sémantiky.
- Pokud je k dispozici dědičnost, musí ručně vytvořený dotaz zohlednit podmínky mapování požadovaného typu.
6.6 CompiledQuery
private static readonly Func<NorthwindEntities, string, IQueryable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
…
var q = context.InvokeProductsForCategoryCQ("Beverages");
Výhody
- Poskytuje až 7% zlepšení výkonu oproti běžným dotazům LINQ.
- Plně materializované objekty.
- Vhodné pro operace CUD.
Nevýhody
- Větší složitost a režijní náklady na programování
- Zvýšení výkonu se ztratí při vytváření kompilovaného dotazu.
- Některé dotazy LINQ nelze zapsat jako Kompilovanýquery – například projekce anonymních typů.
6.7 Porovnání výkonu různých možností dotazů
Jednoduché mikrobenchmarky, ve kterých nebyl čas vytvoření kontextu, byly do testu vloženy. Měřili jsme dotazování 5000krát pro sadu entit, které nejsou uložené v mezipaměti v řízeném prostředí. Tato čísla se použijí s upozorněním: neodráží skutečná čísla vytvořená aplikací, ale představují velmi přesné měření toho, jak velká část rozdílu v výkonu existuje, když se různé možnosti dotazování porovnávají jablka-jablka-jablka s jablky s výjimkou nákladů na vytvoření nového kontextu.
| EF | Test | Time (ms) | Memory (Paměť) |
|---|---|---|---|
| EF5 | ObjectContext ESQL | 2414 | 38801408 |
| EF5 | Dotaz Linq ObjectContext | 2692 | 38277120 |
| EF5 | DbContext Linq Query No Tracking | 2818 | 41840640 |
| EF5 | Dotaz Linq dbContext | 2930 | 41771008 |
| EF5 | ObjectContext Linq Query No Tracking | 3013 | 38412288 |
| EF6 | ObjectContext ESQL | 2059 | 46039040 |
| EF6 | Dotaz Linq ObjectContext | 3074 | 45248512 |
| EF6 | DbContext Linq Query No Tracking | 3125 | 47575040 |
| EF6 | Dotaz Linq dbContext | 3420 | 47652864 |
| EF6 | ObjectContext Linq Query No Tracking | 3593 | 45260800 |
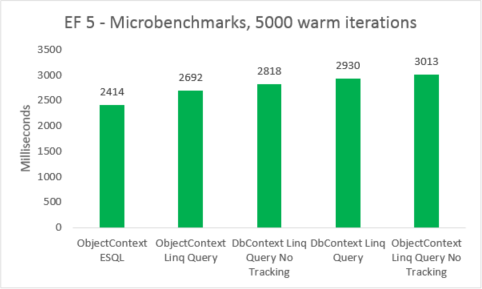
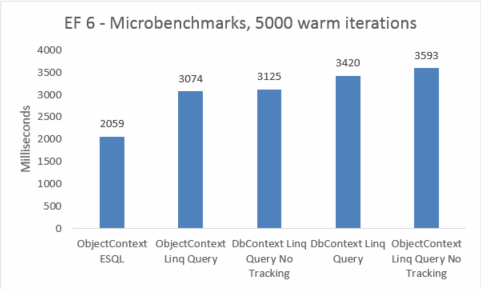
Mikrobenchmarky jsou velmi citlivé na malé změny v kódu. V tomto případě je rozdíl mezi náklady entity Framework 5 a Entity Framework 6 způsoben přidáním průsečíku a transakčních vylepšení. Tato čísla mikrobenchmarks jsou však zesílenou vizí do velmi malé části toho, co Entity Framework dělá. Reálné scénáře teplých dotazů by neměly při upgradu z Entity Framework 5 na Entity Framework 6 vidět regresi výkonu.
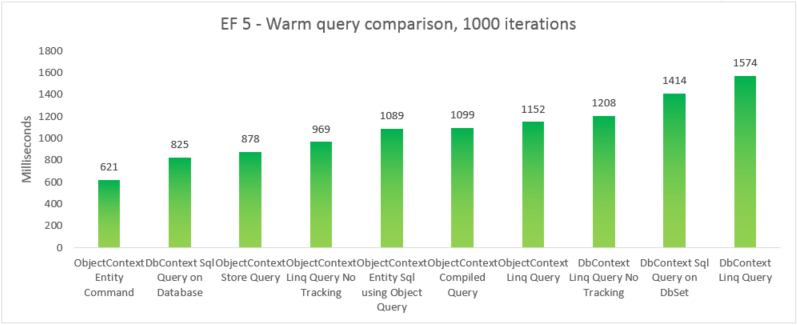
Abychom mohli porovnat skutečný výkon různých možností dotazu, vytvořili jsme 5 samostatných testovacích variant, kde pomocí jiné možnosti dotazu vybereme všechny produkty, jejichž název kategorie je "Nápoje". Každá iterace zahrnuje náklady na vytvoření kontextu a náklady na materializaci všech vrácených entit. 10 iterací se nespustí, než se vezme součet 1 000 časových iterací. Zobrazené výsledky jsou medián spuštění převzaté z 5 spuštění každého testu. Další informace naleznete v dodatku B, který obsahuje kód testu.
| EF | Test | Time (ms) | Memory (Paměť) |
|---|---|---|---|
| EF5 | ObjectContext – příkaz entity | 621 | 39350272 |
| EF5 | DbContext Sql Query v databázi | 825 | 37519360 |
| EF5 | Dotaz úložiště ObjectContext | 878 | 39460864 |
| EF5 | ObjectContext Linq Query No Tracking | 969 | 38293504 |
| EF5 | ObjectContext Entity Sql pomocí objektového dotazu | 1089 | 38981632 |
| EF5 | Kompilovaný dotaz ObjectContext | 1099 | 38682624 |
| EF5 | Dotaz Linq ObjectContext | 1152 | 38178816 |
| EF5 | DbContext Linq Query No Tracking | 1208 | 41803776 |
| EF5 | Dotaz Sql DbContext v dbSet | 1414 | 37982208 |
| EF5 | Dotaz Linq dbContext | 1574 | 41738240 |
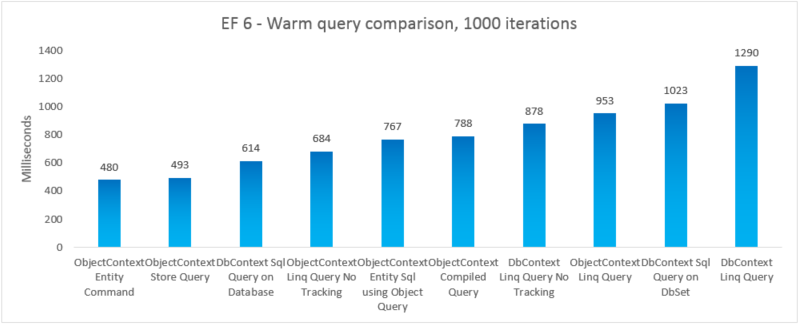
| EF6 | ObjectContext – příkaz entity | 480 | 47247360 |
| EF6 | Dotaz úložiště ObjectContext | 493 | 46739456 |
| EF6 | DbContext Sql Query v databázi | 614 | 41607168 |
| EF6 | ObjectContext Linq Query No Tracking | 684 | 46333952 |
| EF6 | ObjectContext Entity Sql pomocí objektového dotazu | 767 | 48865280 |
| EF6 | Kompilovaný dotaz ObjectContext | 788 | 48467968 |
| EF6 | DbContext Linq Query No Tracking | 878 | 47554560 |
| EF6 | Dotaz Linq ObjectContext | 953 | 47632384 |
| EF6 | Dotaz Sql DbContext v dbSet | 1023 | 41992192 |
| EF6 | Dotaz Linq dbContext | 1290 | 47529984 |
Poznámka
Pro úplnost jsme zahrnuli variantu, ve které provádíme dotaz Entity SQL na EntityCommand. Vzhledem k tomu, že výsledky nejsou pro tyto dotazy materializovány, nemusí být porovnání nutně jablka-jablka-jablka. Test zahrnuje blízkou aproximaci materializace, aby bylo porovnání spravedlivější.
V tomto koncovém případě Entity Framework 6 zpochybní Entity Framework 5 kvůli vylepšení výkonu na několika částech zásobníku, včetně mnohem lehčí inicializace DbContext a rychlejší vyhledávání MetadataCollection<T> .
7 Aspekty výkonu v době návrhu
7.1 Strategie dědičnosti
Dalším aspektem výkonu při použití entity Framework je strategie dědičnosti, kterou používáte. Entity Framework podporuje 3 základní typy dědičnosti a jejich kombinace:
- Tabulka na hierarchii (TPH) – kde se každá sada dědičnosti mapuje na tabulku s nediskriminačním sloupcem, který označuje, který konkrétní typ v hierarchii je reprezentován v řádku.
- Tabulka podle typu (TPT) – kde každý typ má v databázi svou vlastní tabulku; podřízené tabulky definují pouze sloupce, které nadřazená tabulka neobsahuje.
- Table per Class (TPC) – kde každý typ má v databázi svou vlastní úplnou tabulku; podřízené tabulky definují všechna jejich pole, včetně těch definovaných v nadřazených typech.
Pokud váš model používá dědičnost TPT, dotazy, které se vygenerují, budou složitější než dotazy vygenerované s jinými strategiemi dědičnosti, což může vést k delší době provádění v úložišti. Generování dotazů přes model TPT a materializace výsledných objektů bude obecně trvat déle.
Podívejte se na blogový příspěvek MSDN Týkající se výkonu při použití dědičnosti TPT (tabulka podle typu) v Entity Frameworku: <https://learn.microsoft.com/archive/blogs/adonet/performance-considerations-when-using-tpt-table-per-type-inheritance-in-the-entity-framework>.
7.1.1 Vyhněte se tpt v aplikacích Model First nebo Code First
Při vytváření modelu přes existující databázi, která má schéma TPT, nemáte mnoho možností. Při vytváření aplikace pomocí modelu First nebo Code First byste se ale měli vyhnout dědičnosti TPT z hlediska výkonu.
Když použijete Model First v Průvodci návrhářem entit, získáte TPT pro jakoukoli dědičnost v modelu. Pokud chcete přepnout na strategii dědičnosti TPH s modelem First, můžete použít sadu Power Pack generování databáze Návrhář entity, která je k dispozici v galerii sady Visual Studio ( <http://visualstudiogallery.msdn.microsoft.com/df3541c3-d833-4b65-b942-989e7ec74c87/>).
Při konfiguraci mapování modelu s dědičností použije EF ve výchozím nastavení TPH, a proto se všechny entity v hierarchii dědičnosti mapují na stejnou tabulku. Další podrobnosti najdete v části Mapování s rozhraním Fluent API v článku Code First in Entity Framework4.1 v msdn Magazine ( http://msdn.microsoft.com/magazine/hh126815.aspx).
7.2 Upgrade z EF4 za účelem zlepšení doby generování modelu
Vylepšení specifické pro SQL Server algoritmu, který generuje vrstvu úložiště (SSDL) modelu, je k dispozici v Entity Framework 5 a 6 a jako aktualizace Entity Framework 4 při instalaci sady Visual Studio 2010 SP1. Následující výsledky testů ukazují zlepšení při generování velmi velkého modelu, v tomto případě modelu Navision. Další podrobnosti najdete v dodatku C.
Model obsahuje 1005 sad entit a sady přidružení 4227.
| Konfigurace | Rozpis spotřebovaného času |
|---|---|
| Visual Studio 2010, Entity Framework 4 | Generace SSDL: 2 hodina 27 min Generování mapování: 1 sekunda CsDL Generation: 1 sekunda Generování ObjectLayer: 1 sekunda Zobrazení generace: 2 h 14 min |
| Visual Studio 2010 SP1, Entity Framework 4 | Generace SSDL: 1 sekunda Generování mapování: 1 sekunda CsDL Generation: 1 sekunda Generování ObjectLayer: 1 sekunda Zobrazení generace: 1 hodina 53 min |
| Visual Studio 2013, Entity Framework 5 | Generace SSDL: 1 sekunda Generování mapování: 1 sekunda CsDL Generation: 1 sekunda Generování ObjectLayer: 1 sekunda Generování zobrazení: 65 minut |
| Visual Studio 2013, Entity Framework 6 | Generace SSDL: 1 sekunda Generování mapování: 1 sekunda CsDL Generation: 1 sekunda Generování ObjectLayer: 1 sekunda Generování zobrazení: 28 sekund. |
Stojí za zmínku, že při generování SSDL je zatížení téměř zcela vynaloženo na SQL Server, zatímco klientský vývoj počítač čeká na nečinné, aby se výsledky vrátily ze serveru. DbA by si tohoto zlepšení měly zejména uvědomit. Je také vhodné poznamenat, že v podstatě celé náklady na generování modelu probíhají v zobrazení generování nyní.
7.3 Rozdělení velkých modelů pomocí databáze First a Model First
S rostoucí velikostí modelu se povrch návrháře stává nepotřebným a obtížně použitelným. Model s více než 300 entitami obvykle považujeme za příliš velký, abychom mohli návrháře efektivně používat. Následující blog příspěvek popisuje několik možností rozdělení velkých modelů: <https://learn.microsoft.com/archive/blogs/adonet/working-with-large-models-in-entity-framework-part-2>.
Příspěvek byl napsán pro první verzi Entity Frameworku, ale kroky stále platí.
7.4 Aspekty výkonu se správou zdrojů dat entity
Viděli jsme případy ve vícevláknových testech výkonu a zátěžových testů, kdy se výrazně zhoršuje výkon webové aplikace využívající ovládací prvek EntityDataSource. Základní příčinou je, že EntityDataSource opakovaně volá MetadataWorkspace.LoadFromAssembly na sestavení odkazovaná webovou aplikací za účelem zjištění typů, které se mají použít jako entity.
Řešením je nastavit ContextTypeName EntityDataSource na název typu odvozené ObjectContext třídy. Tím se vypne mechanismus, který zkontroluje všechna odkazovaná sestavení pro typy entit.
Nastavení pole ContextTypeName také brání funkčnímu problému, kdy EntityDataSource v .NET 4.0 vyvolá výjimku Reflexe ionTypeLoadException, když nemůže načíst typ ze sestavení prostřednictvím reflexe. Tento problém je opravený v .NET 4.5.
7.5 Entity POCO a proxy servery pro sledování změn
Entity Framework umožňuje používat vlastní datové třídy společně s datovým modelem, aniž byste museli provádět změny samotných datových tříd. To znamená, že s datovým modelem můžete použít "prosté staré" objekty CLR (POCO), jako jsou existující doménové objekty. Tyto datové třídy POCO (označované také jako persistence-ignorant objekty), které jsou mapovány na entity definované v datovém modelu, podporují většinu stejného dotazu, vkládání, aktualizace a odstraňování chování jako typy entit generované nástroji Entity Data Model.
Entity Framework může také vytvářet proxy třídy odvozené z vašich typů POCO, které se používají, když chcete povolit funkce, jako je opožděné načítání a automatické sledování změn u entit POCO. Vaše třídy POCO musí splňovat určité požadavky, aby entity Framework mohly používat proxy, jak je popsáno zde: http://msdn.microsoft.com/library/dd468057.aspx.
Proxy služby Chance Tracking upozorní správce stavu objektu pokaždé, když se změní některé vlastnosti entit, takže Entity Framework zná skutečný stav entit po celou dobu. To se provádí přidáním událostí oznámení do těla metod setter vašich vlastností a tím, že správce stavu objektu zpracovává takové události. Všimněte si, že vytvoření entity proxy bude obvykle dražší než vytvoření entity POCO jiného než proxy kvůli přidané sadě událostí vytvořených rozhraním Entity Framework.
Pokud entita POCO nemá proxy sledování změn, změny se najdou porovnáním obsahu entit s kopií předchozího uloženého stavu. Toto hluboké porovnání se stane zdlouhavým procesem, když máte v kontextu mnoho entit nebo když mají vaše entity velmi velké množství vlastností, i když se od posledního porovnání nezměnila žádná z nich.
Shrnutí: Při vytváření proxy sledování změn zaplatíte za dosažení výkonu, ale sledování změn vám pomůže urychlit proces detekce změn, když vaše entity mají mnoho vlastností nebo když máte v modelu mnoho entit. U entit s malým počtem vlastností, u kterých se množství entit příliš nezvětší, nemusí mít sledování změn moc výhod.
8 Načítání souvisejících entit
8.1 Opožděné načítání vs. Dychtivé načítání
Entity Framework nabízí několik různých způsobů načtení entit, které souvisejí s vaší cílovou entitou. Například při dotazování na produkty existují různé způsoby, jak se související objednávky načtou do Správce stavu objektu. Z hlediska výkonu je největší otázkou, kterou je potřeba zvážit při načítání souvisejících entit, zda použít opožděné načítání nebo načítání dychtivým načítáním.
Při použití funkce Dychtivé načítání se související entity načtou společně s cílovou sadou entit. Pomocí příkazu Include v dotazu označíte, které související entity chcete přenést.
Při použití opožděného načítání se počáteční dotaz zobrazí pouze v sadě cílových entit. Když ale přistupujete k navigační vlastnosti, vydá se vůči úložišti jiný dotaz, který načte související entitu.
Po načtení entity se všechny další dotazy na entitu načtou přímo ze Správce stavu objektu bez ohledu na to, jestli používáte opožděné načítání nebo dychtivé načítání.
8.2 Jak si vybrat mezi opožděným načítáním a dychtivým načítáním
Důležité je, že rozumíte rozdílu mezi opožděným načítáním a dychtivým načítáním, abyste mohli pro svou aplikaci zvolit správnou volbu. Pomůže vám to vyhodnotit kompromis mezi několika požadavky vůči databázi a jedním požadavkem, který může obsahovat velkou datovou část. Může být vhodné použít dychtivé načítání v některých částech aplikace a opožděné načítání v jiných částech.
Jako příklad toho, co se děje pod kapotou, předpokládejme, že chcete dotazovat zákazníky, kteří žijí ve Velké Británii, a jejich počet objednávek.
Používání dychtivých načítání
using (NorthwindEntities context = new NorthwindEntities())
{
var ukCustomers = context.Customers.Include(c => c.Orders).Where(c => c.Address.Country == "UK");
var chosenCustomer = AskUserToPickCustomer(ukCustomers);
Console.WriteLine("Customer Id: {0} has {1} orders", customer.CustomerID, customer.Orders.Count);
}
Použití opožděných načítání
using (NorthwindEntities context = new NorthwindEntities())
{
context.ContextOptions.LazyLoadingEnabled = true;
//Notice that the Include method call is missing in the query
var ukCustomers = context.Customers.Where(c => c.Address.Country == "UK");
var chosenCustomer = AskUserToPickCustomer(ukCustomers);
Console.WriteLine("Customer Id: {0} has {1} orders", customer.CustomerID, customer.Orders.Count);
}
Při použití dychtivého načítání vydáte jeden dotaz, který vrátí všechny zákazníky a všechny objednávky. Příkaz store vypadá takto:
SELECT
[Project1].[C1] AS [C1],
[Project1].[CustomerID] AS [CustomerID],
[Project1].[CompanyName] AS [CompanyName],
[Project1].[ContactName] AS [ContactName],
[Project1].[ContactTitle] AS [ContactTitle],
[Project1].[Address] AS [Address],
[Project1].[City] AS [City],
[Project1].[Region] AS [Region],
[Project1].[PostalCode] AS [PostalCode],
[Project1].[Country] AS [Country],
[Project1].[Phone] AS [Phone],
[Project1].[Fax] AS [Fax],
[Project1].[C2] AS [C2],
[Project1].[OrderID] AS [OrderID],
[Project1].[CustomerID1] AS [CustomerID1],
[Project1].[EmployeeID] AS [EmployeeID],
[Project1].[OrderDate] AS [OrderDate],
[Project1].[RequiredDate] AS [RequiredDate],
[Project1].[ShippedDate] AS [ShippedDate],
[Project1].[ShipVia] AS [ShipVia],
[Project1].[Freight] AS [Freight],
[Project1].[ShipName] AS [ShipName],
[Project1].[ShipAddress] AS [ShipAddress],
[Project1].[ShipCity] AS [ShipCity],
[Project1].[ShipRegion] AS [ShipRegion],
[Project1].[ShipPostalCode] AS [ShipPostalCode],
[Project1].[ShipCountry] AS [ShipCountry]
FROM ( SELECT
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[CompanyName] AS [CompanyName],
[Extent1].[ContactName] AS [ContactName],
[Extent1].[ContactTitle] AS [ContactTitle],
[Extent1].[Address] AS [Address],
[Extent1].[City] AS [City],
[Extent1].[Region] AS [Region],
[Extent1].[PostalCode] AS [PostalCode],
[Extent1].[Country] AS [Country],
[Extent1].[Phone] AS [Phone],
[Extent1].[Fax] AS [Fax],
1 AS [C1],
[Extent2].[OrderID] AS [OrderID],
[Extent2].[CustomerID] AS [CustomerID1],
[Extent2].[EmployeeID] AS [EmployeeID],
[Extent2].[OrderDate] AS [OrderDate],
[Extent2].[RequiredDate] AS [RequiredDate],
[Extent2].[ShippedDate] AS [ShippedDate],
[Extent2].[ShipVia] AS [ShipVia],
[Extent2].[Freight] AS [Freight],
[Extent2].[ShipName] AS [ShipName],
[Extent2].[ShipAddress] AS [ShipAddress],
[Extent2].[ShipCity] AS [ShipCity],
[Extent2].[ShipRegion] AS [ShipRegion],
[Extent2].[ShipPostalCode] AS [ShipPostalCode],
[Extent2].[ShipCountry] AS [ShipCountry],
CASE WHEN ([Extent2].[OrderID] IS NULL) THEN CAST(NULL AS int) ELSE 1 END AS [C2]
FROM [dbo].[Customers] AS [Extent1]
LEFT OUTER JOIN [dbo].[Orders] AS [Extent2] ON [Extent1].[CustomerID] = [Extent2].[CustomerID]
WHERE N'UK' = [Extent1].[Country]
) AS [Project1]
ORDER BY [Project1].[CustomerID] ASC, [Project1].[C2] ASC
Při použití opožděného načítání nejprve vydáte následující dotaz:
SELECT
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[CompanyName] AS [CompanyName],
[Extent1].[ContactName] AS [ContactName],
[Extent1].[ContactTitle] AS [ContactTitle],
[Extent1].[Address] AS [Address],
[Extent1].[City] AS [City],
[Extent1].[Region] AS [Region],
[Extent1].[PostalCode] AS [PostalCode],
[Extent1].[Country] AS [Country],
[Extent1].[Phone] AS [Phone],
[Extent1].[Fax] AS [Fax]
FROM [dbo].[Customers] AS [Extent1]
WHERE N'UK' = [Extent1].[Country]
A pokaždé, když se dostanete k navigační vlastnosti Objednávky zákazníka, vystaví se vůči úložišti jiný dotaz, například následující:
exec sp_executesql N'SELECT
[Extent1].[OrderID] AS [OrderID],
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[EmployeeID] AS [EmployeeID],
[Extent1].[OrderDate] AS [OrderDate],
[Extent1].[RequiredDate] AS [RequiredDate],
[Extent1].[ShippedDate] AS [ShippedDate],
[Extent1].[ShipVia] AS [ShipVia],
[Extent1].[Freight] AS [Freight],
[Extent1].[ShipName] AS [ShipName],
[Extent1].[ShipAddress] AS [ShipAddress],
[Extent1].[ShipCity] AS [ShipCity],
[Extent1].[ShipRegion] AS [ShipRegion],
[Extent1].[ShipPostalCode] AS [ShipPostalCode],
[Extent1].[ShipCountry] AS [ShipCountry]
FROM [dbo].[Orders] AS [Extent1]
WHERE [Extent1].[CustomerID] = @EntityKeyValue1',N'@EntityKeyValue1 nchar(5)',@EntityKeyValue1=N'AROUT'
Další informace naleznete v tématu Načítání souvisejících objektů.
8.2.1 Opožděné načítání versus dychtivé načítání tahák
Neexistuje žádná taková věc, jako je jedna velikost-hodí-all k výběru dychtivého načítání versus opožděné načítání. Nejprve se pokuste pochopit rozdíly mezi oběma strategiemi, abyste mohli provést dobře informované rozhodnutí; zvažte také, jestli váš kód zapadá do některého z následujících scénářů:
| Scenario | Náš návrh |
|---|---|
| Potřebujete získat přístup k mnoha navigačním vlastnostem z načtených entit? | Ne - Obě možnosti budou pravděpodobně dělat. Pokud ale datová část, kterou dotaz přináší, není příliš velká, můžete zaznamenat výhody výkonu díky načítání dychtivým načítáním, protože k materializaci objektů bude vyžadovat méně odezvy sítě. Ano – Pokud potřebujete získat přístup k mnoha navigačním vlastnostem z entit, měli byste to udělat pomocí více příkazů include v dotazu s dychtivým načtením. Čím více entit zahrnete, tím větší datová část dotaz vrátí. Jakmile do dotazu zahrnete tři nebo více entit, zvažte přepnutí na opožděné načítání. |
| Víte přesně, jaká data budou potřeba za běhu? | Ne - Opožděné načítání bude pro vás lepší. Jinak můžete skončit dotazováním na data, která nebudete potřebovat. Ano – Dychtivá načítání je pravděpodobně vaším nejlepším tipem. Pomůže vám rychleji načíst celé sady. Pokud váš dotaz vyžaduje načtení velmi velkého množství dat a stává se příliš pomalým, zkuste místo toho opožděné načtení. |
| Je váš kód daleko od vaší databáze? (zvýšená latence sítě) | Ne – Pokud latence sítě není problém, může použití opožděného načítání zjednodušit váš kód. Mějte na paměti, že topologie vaší aplikace se může změnit, takže nezohledněte vzdálenost databáze. Ano – Pokud je síť problém, můžete se rozhodnout, co se hodí pro váš scénář lépe. Načítání dychtivosti bude obvykle lepší, protože vyžaduje méně odezvy. |
8.2.2 Problémy s výkonem s více zahrnutími
Když slyšíme otázky týkající se výkonu, které zahrnují problémy s dobou odezvy serveru, zdroj problému se často dotazuje s více příkazy Include. I když je zahrnutí souvisejících entit do dotazu výkonné, je důležité pochopit, co se děje pod kryty.
Vytvoření příkazu úložiště trvá poměrně dlouho, než dotaz s více příkazy Include v něm projde naším interním kompilátorem plánu. Většina tohoto času se snaží optimalizovat výsledný dotaz. Vygenerovaný příkaz úložiště bude obsahovat vnější spojení nebo sjednocení pro každou zahrnutí v závislosti na vašem mapování. Podobné dotazy přinesou velké propojené grafy z vaší databáze v jedné datové části, což zvýší velikost šířky pásma, zejména v případě, že datová část obsahuje hodně redundance (například když se k procházení přidružení v směru 1:N používá více úrovní zahrnutí).
Případy, kdy dotazy vrací nadměrně velké datové části, můžete zkontrolovat tak, že k podkladovému TSQL pro dotaz přistupujete pomocí toTraceStringu a spustíte příkaz úložiště v aplikaci SQL Server Management Studio, abyste viděli velikost datové části. V takovýchpřípadechch Nebo můžete dotaz rozdělit na menší sekvenci poddotazů, například:
Před porušením dotazu:
using (NorthwindEntities context = new NorthwindEntities())
{
var customers = from c in context.Customers.Include(c => c.Orders)
where c.LastName.StartsWith(lastNameParameter)
select c;
foreach (Customer customer in customers)
{
...
}
}
Po porušení dotazu:
using (NorthwindEntities context = new NorthwindEntities())
{
var orders = from o in context.Orders
where o.Customer.LastName.StartsWith(lastNameParameter)
select o;
orders.Load();
var customers = from c in context.Customers
where c.LastName.StartsWith(lastNameParameter)
select c;
foreach (Customer customer in customers)
{
...
}
}
To bude fungovat jenom na sledovaných dotazech, protože používáme možnost, že kontext musí automaticky provádět řešení identit a oprava přidružení.
Stejně jako u opožděného načítání bude kompromis více dotazů pro menší datové části. Můžete také použít projekce jednotlivých vlastností k explicitnímu výběru jenom potřebných dat z každé entity, ale v tomto případě nebudete načítat entity a aktualizace nebudou podporovány.
8.2.3 Alternativní řešení pro získání opožděného načítání vlastností
Entity Framework v současné době nepodporuje opožděné načítání skalárních nebo složitých vlastností. V případech, kdy ale máte tabulku, která obsahuje velký objekt, jako je objekt BLOB, můžete rozdělením tabulky oddělit velké vlastnosti do samostatné entity. Předpokládejme například, že máte tabulku Product (Produkt), která obsahuje sloupec s varbinární fotografií. Pokud v dotazech často nepotřebujete přistupovat k této vlastnosti, můžete pomocí rozdělení tabulky přenést pouze části entity, které obvykle potřebujete. Entita představující fotografii produktu se načte jenom v případě, že ji explicitně potřebujete.
Dobrý zdroj, který ukazuje, jak povolit rozdělení tabulek, je Gil Fink 's "Table Splitting in Entity Framework" blogový příspěvek: <http://blogs.microsoft.co.il/blogs/gilf/archive/2009/10/13/table-splitting-in-entity-framework.aspx>.
9 Další aspekty
9.1 Uvolňování paměti serveru
Někteří uživatelé můžou zaznamenat kolize prostředků, která omezuje paralelismus, který očekávají, když systém uvolňování paměti není správně nakonfigurovaný. Vždy, když se ef používá ve scénáři s více vlákny nebo v jakékoli aplikaci, která se podobá systému na straně serveru, nezapomeňte povolit uvolňování paměti serveru. To se provádí prostřednictvím jednoduchého nastavení v konfiguračním souboru aplikace:
<?xmlversion="1.0" encoding="utf-8" ?>
<configuration>
<runtime>
<gcServer enabled="true" />
</runtime>
</configuration>
Tím by se měla snížit kolize vláken a zvýšit propustnost až o 30 % ve scénářích s nasyceným procesorem. Obecně platí, že byste měli vždy otestovat, jak se vaše aplikace chová, pomocí klasického uvolňování paměti (což je lépe vyladěné pro scénáře uživatelského rozhraní a na straně klienta) a také uvolňování paměti serveru.
9.2 AutoDetectChanges
Jak už bylo zmíněno dříve, Entity Framework může zobrazovat problémy s výkonem, když mezipaměť objektů obsahuje mnoho entit. Některé operace, jako je Přidání, Odebrání, Najít, Entry a SaveChanges, aktivují volání DetectChanges, které mohou spotřebovávat velké množství procesoru na základě toho, jak velká je mezipaměť objektů. Důvodem je, že mezipaměť objektů a správce stavu objektu se snaží zůstat co nejsynchronnější pro každou operaci provedenou v kontextu, aby vytvořená data byla zaručena správná v rámci široké škály scénářů.
Obecně je vhodné nechat automatické zjišťování změn entity Framework povolené pro celou životnost vaší aplikace. Pokud je váš scénář negativně ovlivněn vysokým využitím procesoru a vaše profily indikují, že se jedná o volání Funkce DetectChanges, zvažte dočasné vypnutí funkce AutoDetectChanges v citlivé části kódu:
try
{
context.Configuration.AutoDetectChangesEnabled = false;
var product = context.Products.Find(productId);
...
}
finally
{
context.Configuration.AutoDetectChangesEnabled = true;
}
Před vypnutím funkce AutoDetectChanges je dobré pochopit, že to může způsobit ztrátu schopnosti Entity Frameworku sledovat určité informace o změnách, které probíhají u entit. Pokud se zpracuje nesprávně, může to způsobit nekonzistence dat ve vaší aplikaci. Další informace o vypnutí funkce AutoDetectChanges naleznete v tématu <http://blog.oneunicorn.com/2012/03/12/secrets-of-detectchanges-part-3-switching-off-automatic-detectchanges/>.
9.3 Kontext na požadavek
Kontexty entity Framework se mají používat jako krátkodobé instance, aby se zajistil optimální výkon. Očekává se, že kontexty budou krátkodobé a zahozené, a proto byly implementovány tak, aby byly velmi jednoduché a znovu zužitkovaly metadata, kdykoli je to možné. Vewebových webových scénářích je důležité mít na paměti, že nemáte kontext pro více než dobu trvání jednoho požadavku. Podobně by se kontext v jiných než webových scénářích měl zahodit na základě vašeho porozumění různým úrovním ukládání do mezipaměti v entity Frameworku. Obecně řečeno, jeden by se měl vyhnout tomu, aby instance kontextu po celou dobu životnosti aplikace, stejně jako kontexty na vlákno a statické kontexty.
9.4 Sémantika null databáze
Entity Framework ve výchozím nastavení vygeneruje kód SQL, který má sémantiku porovnání null jazyka C#. Podívejte se na následující příklad dotazu:
int? categoryId = 7;
int? supplierId = 8;
decimal? unitPrice = 0;
short? unitsInStock = 100;
short? unitsOnOrder = 20;
short? reorderLevel = null;
var q = from p incontext.Products
where p.Category.CategoryName == "Beverages"
|| (p.CategoryID == categoryId
|| p.SupplierID == supplierId
|| p.UnitPrice == unitPrice
|| p.UnitsInStock == unitsInStock
|| p.UnitsOnOrder == unitsOnOrder
|| p.ReorderLevel == reorderLevel)
select p;
var r = q.ToList();
V tomto příkladu porovnáváme řadu proměnných s možnou hodnotou null proti vlastnostem s možnou hodnotou null u entity, jako jsou SupplierID a UnitPrice. Vygenerovaný jazyk SQL pro tento dotaz se zeptá, jestli je hodnota parametru stejná jako hodnota sloupce, nebo jestli parametr i hodnoty sloupce mají hodnotu null. Tím skryjete způsob, jakým databázový server zpracovává hodnoty null, a poskytne konzistentní prostředí S# null v různých dodavatelích databází. Na druhou stranu je vygenerovaný kód trochu konvolutovaný a nemusí dobře fungovat, když se množství porovnání v příkazu dotazu zvětšuje na velké číslo.
Jedním ze způsobů, jak tuto situaci vyřešit, je použití sémantiky null databáze. Všimněte si, že se to může chovat jinak než sémantiku null jazyka C#, protože teď Entity Framework vygeneruje jednodušší SQL, který zpřístupňuje způsob, jakým databázový stroj zpracovává hodnoty null. Sémantiku null databáze je možné aktivovat pro každý kontext s jedním řádkem konfigurace pro konfiguraci kontextu:
context.Configuration.UseDatabaseNullSemantics = true;
Dotazy s malou až střední velikostí nezobrazí při použití sémantiky null databáze výrazné zlepšení výkonu, ale rozdíl se u dotazů s velkým počtem potenciálních porovnání s hodnotou null zvýrazní.
V příkladovém dotazu výše byl rozdíl v výkonu menší než 2 % v mikrobenchmarku spuštěném v řízeném prostředí.
9.5 Asynchronní
Entity Framework 6 zavedl podporu asynchronních operací při spuštění v .NET 4.5 nebo novějším. Ve většině případů budou aplikace, které mají kolize související se vstupně-výstupními operacemi, využívat nejvíce asynchronních dotazů a ukládat operace. Pokud vaše aplikace netrpí kolizí vstupně-výstupních operací, použije asynchronní operace v nejlepších případech synchronně a vrátí výsledek ve stejné době jako synchronní volání nebo v nejhorším případě jednoduše odloží provádění na asynchronní úlohu a přidá k dokončení vašeho scénáře další čas.
Informace o tom, jak funguje asynchronní programování, které vám pomůžou rozhodnout, jestli asynchronní funkce zlepší výkon vaší aplikace, najdete v tématu Asynchronní programování pomocí Async a Await. Další informace o použití asynchronních operací v Entity Frameworku najdete v tématu Asynchronní dotaz a uložení.
9.6 NGEN
Entity Framework 6 není ve výchozí instalaci rozhraní .NET Framework. Sestavení Entity Framework nejsou ve výchozím nastavení NGEN, což znamená, že veškerý kód Entity Framework podléhá stejným nákladům NA JIT jako jakékoli jiné sestavení MSIL. To může snížit výkon F5 při vývoji a také studeném spuštění aplikace v produkčních prostředích. Aby se snížily náklady na procesor a paměť JIT, doporučujeme podle potřeby NGEN image Entity Frameworku. Další informace o tom, jak zlepšit výkon spouštění entity Framework 6 pomocí NGEN, naleznete v tématu Zlepšení výkonu spouštění pomocí NGen.
9.7 Code First versus EDMX
Entity Framework zdůvodní problém impedance neshody mezi objektově orientovaným programováním a relačními databázemi tím, že má reprezentaci konceptuálního modelu (objektů), schématu úložiště (databáze) a mapování mezi nimi. Tato metadata se označují jako datový model entity nebo EDM. Z tohoto EDM entity Framework odvozuje zobrazení pro zaokrouhlování dat z objektů v paměti do databáze a zpět.
Pokud se entity Framework používá se souborem EDMX, který formálně určuje koncepční model, schéma úložiště a mapování, pak fáze načítání modelu musí ověřit, že je EDM správný (například ujistěte se, že chybí žádná mapování), pak vygenerujte zobrazení, ověřte zobrazení a tato metadata jsou připravená k použití. Dotaz se pak dá spustit nebo uložit nová data do úložiště dat.
První přístup kódu je v jeho srdci sofistikovaným generátorem modelu Entity Data Model. Entity Framework musí vytvořit EDM z poskytnutého kódu; provede to tak, že analyzuje třídy zahrnuté v modelu, použije konvence a nakonfiguruje model prostřednictvím rozhraní Fluent API. Po sestavení EDM se Entity Framework v podstatě chová stejně jako soubor EDMX v projektu. Proto sestavení modelu z Code First přidává další složitost, která se v porovnání s EDMX překládá na pomalejší dobu spouštění entity Frameworku. Náklady jsou zcela závislé na velikosti a složitosti vytvořeného modelu.
Když se rozhodnete použít EDMX a Code First, je důležité vědět, že flexibilita, kterou Code First zavádí, zvyšuje náklady na vytvoření modelu poprvé. Pokud vaše aplikace dokáže odolat nákladům na toto první načtení, bude obvykle upřednostňovaným způsobem přejít code First.
10 Vyšetřování výkonu
10.1 Použití profileru sady Visual Studio
Pokud máte problémy s výkonem entity Frameworku, můžete pomocí profileru, jako je ten integrovaný do sady Visual Studio, zjistit, kde vaše aplikace tráví čas. Toto je nástroj, který jsme použili k vygenerování výsečových grafů v blogovém příspěvku "Zkoumání výkonu ADO.NET Entity Framework – část 1" ( <https://learn.microsoft.com/archive/blogs/adonet/exploring-the-performance-of-the-ado-net-entity-framework-part-1>), který ukazuje, kde Entity Framework tráví čas během studených a teplých dotazů.
Blogový příspěvek Profiling Entity Framework using the Visual Studio 2010 Profiler napsaný týmem Pro poradce pro zákazníky s modelováním ukazuje skutečný příklad použití profileru k prozkoumání problému s výkonem. <https://learn.microsoft.com/archive/blogs/dmcat/profiling-entity-framework-using-the-visual-studio-2010-profiler>. Tento příspěvek byl napsán pro aplikaci pro Windows. Pokud potřebujete profilovat webovou aplikaci, nástroje Windows Performance Recorder (WPR) a Windows Analyzátor výkonu (WPA) můžou fungovat lépe než práce ze sady Visual Studio. WPR a WPA jsou součástí sady nástrojů Windows Performance Toolkit, která je součástí sady Windows Assessment and Deployment Kit.
10.2 Profilace aplikací/databází
Nástroje, jako je profiler integrovaný do sady Visual Studio, vám říkají, kde vaše aplikace tráví čas. Další typ profileru je k dispozici, který provádí dynamickou analýzu spuštěné aplikace v produkčním prostředí nebo v předprodukčním prostředí v závislosti na potřebách a hledá běžné nástrahy a anti-vzory přístupu k databázi.
Dva komerčně dostupné profilátory jsou Entity Framework Profiler ( <http://efprof.com>) a ORMProfiler ( <http://ormprofiler.com>).
Pokud je vaše aplikace MVC pomocí code First, můžete použít MiniProfiler StackExchange. Scott Hanselman popisuje tento nástroj v jeho blogu na: <http://www.hanselman.com/blog/NuGetPackageOfTheWeek9ASPNETMiniProfilerFromStackExchangeRocksYourWorld.aspx>.
Další informace o profilaci databázové aktivity vaší aplikace naleznete v článku Julie Lermana časopisu MSDN Magazine s názvem Profiling Database Activity in the Entity Framework.
10.3 Protokolovací nástroj databáze
Pokud používáte Entity Framework 6, zvažte také použití integrované funkce protokolování. Vlastnost Database kontextu lze instruovat, aby protokolovala svou aktivitu prostřednictvím jednoduché jednořádkové konfigurace:
using (var context = newQueryComparison.DbC.NorthwindEntities())
{
context.Database.Log = Console.WriteLine;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
V tomto příkladu se aktivita databáze zaprotokoluje do konzoly, ale vlastnost Protokolu lze nakonfigurovat tak, aby volala libovolný delegát řetězce> akce<.
Pokud chcete povolit protokolování databáze bez překompilování a používáte Entity Framework 6.1 nebo novější, můžete to udělat přidáním průsečíku do souboru web.config nebo app.config vaší aplikace.
<interceptors>
<interceptor type="System.Data.Entity.Infrastructure.Interception.DatabaseLogger, EntityFramework">
<parameters>
<parameter value="C:\Path\To\My\LogOutput.txt"/>
</parameters>
</interceptor>
</interceptors>
Další informace o tom, jak přidat protokolování bez rekompilování, přejděte na <http://blog.oneunicorn.com/2014/02/09/ef-6-1-turning-on-logging-without-recompiling/>.
11 Dodatek
11.1 A. Testovací prostředí
Toto prostředí používá nastavení 2 počítačů s databází na samostatném počítači od klientské aplikace. Počítače jsou ve stejném racku, takže latence sítě je relativně nízká, ale realističtější než prostředí s jedním počítačem.
11.1.1 Aplikační server
11.1.1.1 Softwarové prostředí
- Softwarové prostředí Entity Framework 4
- Název operačního systému: Windows Server 2008 R2 Enterprise SP1.
- Visual Studio 2010 – Ultimate.
- Visual Studio 2010 SP1 (pouze pro některá porovnání)
- Entity Framework 5 a 6 Softwarové prostředí
- Název operačního systému: Windows 8.1 Enterprise
- Visual Studio 2013 – Ultimate.
11.1.1.2 Hardwarové prostředí
- Duální procesor: Procesor Intel(R) Xeon(R) CPU L5520 W3530 @ 2,27GHz, 2261 Mhz8 GHz, 4 jádra, 84 logických procesorů.
- 2412 GB RamRAM.
- 136 GB SCSI250GB SATA 7200 ot./min 3GB/s jednotka rozdělená na 4 oddíly.
11.1.2 DB server
11.1.2.1 Softwarové prostředí
- Název operačního systému: Windows Server 2008 R28.1 Enterprise SP1.
- SQL Server 2008 R22012.
11.1.2.2 Hardwarové prostředí
- Jeden procesor: Procesor Intel(R) Xeon(R) CPU L5520 @ 2,27GHz, 2261 MhzES-1620 0 @ 3,60GHz, 4 jádra, 8 logických procesorů.
- 824 GB RamRAM.
- 465 GB ATA500GB SATA 7200 ot./s jednotka rozdělená na 4 oddíly.
11.2 B. Testy porovnání výkonu dotazů
K provedení těchto testů se použil model Northwind. Vygenerovala se z databáze pomocí návrháře Entity Framework. Pak se k porovnání výkonu možností spuštění dotazu použil následující kód:
using System;
using System.Collections.Generic;
using System.Data;
using System.Data.Common;
using System.Data.Entity.Infrastructure;
using System.Data.EntityClient;
using System.Data.Objects;
using System.Linq;
namespace QueryComparison
{
public partial class NorthwindEntities : ObjectContext
{
private static readonly Func<NorthwindEntities, string, IQueryable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
public IQueryable<Product> InvokeProductsForCategoryCQ(string categoryName)
{
return productsForCategoryCQ(this, categoryName);
}
}
public class QueryTypePerfComparison
{
private static string entityConnectionStr = @"metadata=res://*/Northwind.csdl|res://*/Northwind.ssdl|res://*/Northwind.msl;provider=System.Data.SqlClient;provider connection string='data source=.;initial catalog=Northwind;integrated security=True;multipleactiveresultsets=True;App=EntityFramework'";
public void LINQIncludingContextCreation()
{
using (NorthwindEntities context = new NorthwindEntities())
{
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void LINQNoTracking()
{
using (NorthwindEntities context = new NorthwindEntities())
{
context.Products.MergeOption = MergeOption.NoTracking;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void CompiledQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
var q = context.InvokeProductsForCategoryCQ("Beverages");
q.ToList();
}
}
public void ObjectQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
ObjectQuery<Product> products = context.Products.Where("it.Category.CategoryName = 'Beverages'");
products.ToList();
}
}
public void EntityCommand()
{
using (EntityConnection eConn = new EntityConnection(entityConnectionStr))
{
eConn.Open();
EntityCommand cmd = eConn.CreateCommand();
cmd.CommandText = "Select p From NorthwindEntities.Products As p Where p.Category.CategoryName = 'Beverages'";
using (EntityDataReader reader = cmd.ExecuteReader(CommandBehavior.SequentialAccess))
{
List<Product> productsList = new List<Product>();
while (reader.Read())
{
DbDataRecord record = (DbDataRecord)reader.GetValue(0);
// 'materialize' the product by accessing each field and value. Because we are materializing products, we won't have any nested data readers or records.
int fieldCount = record.FieldCount;
// Treat all products as Product, even if they are the subtype DiscontinuedProduct.
Product product = new Product();
product.ProductID = record.GetInt32(0);
product.ProductName = record.GetString(1);
product.SupplierID = record.GetInt32(2);
product.CategoryID = record.GetInt32(3);
product.QuantityPerUnit = record.GetString(4);
product.UnitPrice = record.GetDecimal(5);
product.UnitsInStock = record.GetInt16(6);
product.UnitsOnOrder = record.GetInt16(7);
product.ReorderLevel = record.GetInt16(8);
product.Discontinued = record.GetBoolean(9);
productsList.Add(product);
}
}
}
}
public void ExecuteStoreQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
ObjectResult<Product> beverages = context.ExecuteStoreQuery<Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void ExecuteStoreQueryDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var beverages = context.Database.SqlQuery\<QueryComparison.DbC.Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void ExecuteStoreQueryDbSet()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var beverages = context.Products.SqlQuery(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void LINQIncludingContextCreationDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void LINQNoTrackingDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var q = context.Products.AsNoTracking().Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
}
}
11.3 C. Model Navision
Databáze Navision je velká databáze, která slouží k ukázce Microsoft Dynamics – NAV. Vygenerovaný koncepční model obsahuje 1005 sad entit a sady přidružení 4227. Model použitý v testu je "plochý" – do něj nebyla přidána žádná dědičnost.
11.3.1 Dotazy používané pro testy Navision
Seznam dotazů použitý s modelem Navision obsahuje 3 kategorie dotazů Entity SQL:
11.3.1.1 Vyhledávání
Jednoduchý vyhledávací dotaz bez agregací
- Počet: 16232
- Příklad:
<Query complexity="Lookup">
<CommandText>Select value distinct top(4) e.Idle_Time From NavisionFKContext.Session as e</CommandText>
</Query>
11.3.1.2 SingleAggregating
Normální dotaz BI s více agregacemi, ale bez mezisoučtů (jeden dotaz)
- Počet: 2313
- Příklad:
<Query complexity="SingleAggregating">
<CommandText>NavisionFK.MDF_SessionLogin_Time_Max()</CommandText>
</Query>
Kde MDF_SessionLogin_Time_Max() je v modelu definován jako:
<Function Name="MDF_SessionLogin_Time_Max" ReturnType="Collection(DateTime)">
<DefiningExpression>SELECT VALUE Edm.Min(E.Login_Time) FROM NavisionFKContext.Session as E</DefiningExpression>
</Function>
11.3.1.3 Agregace podsoučtů
Dotaz BI s agregacemi a mezisoučty (prostřednictvím sjednocení)
- Počet: 178
- Příklad:
<Query complexity="AggregatingSubtotals">
<CommandText>
using NavisionFK;
function AmountConsumed(entities Collection([CRONUS_International_Ltd__Zone])) as
(
Edm.Sum(select value N.Block_Movement FROM entities as E, E.CRONUS_International_Ltd__Bin as N)
)
function AmountConsumed(P1 Edm.Int32) as
(
AmountConsumed(select value e from NavisionFKContext.CRONUS_International_Ltd__Zone as e where e.Zone_Ranking = P1)
)
----------------------------------------------------------------------------------------------------------------------
(
select top(10) Zone_Ranking, Cross_Dock_Bin_Zone, AmountConsumed(GroupPartition(E))
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed
group by E.Zone_Ranking, E.Cross_Dock_Bin_Zone
)
union all
(
select top(10) Zone_Ranking, Cast(null as Edm.Byte) as P2, AmountConsumed(GroupPartition(E))
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed
group by E.Zone_Ranking
)
union all
{
Row(Cast(null as Edm.Int32) as P1, Cast(null as Edm.Byte) as P2, AmountConsumed(select value E
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed))
}</CommandText>
<Parameters>
<Parameter Name="MinAmountConsumed" DbType="Int32" Value="10000" />
</Parameters>
</Query>