Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Poznámka:
Tento článek předpokládá, že víte, jak používat Code First migrace v základních scénářích. Pokud tomu tak není, budete si muset před pokračováním přečíst Code First Migrations.
Vezměte si kávu, musíte si přečíst celý článek.
Problémy v týmových prostředích se většinou týkají sloučení migrací, když dva vývojáři vygenerovali migrace v místním základu kódu. I když jsou tyto kroky poměrně jednoduché, vyžadují, abyste měli solidní přehled o tom, jak migrace fungují. Nepřeskočte na konec – přečtěte si celý článek, abyste se ujistili, že jste úspěšní.
Některé obecné pokyny
Než se podíváme na to, jak spravovat slučování migrací vygenerovaných více vývojáři, zde jsou některé obecné rady, které vám pomohou připravit na úspěch.
Každý člen týmu by měl mít místní vývojovou databázi.
Tabulka __MigrationsHistory se používá k ukládání informací o tom, které migrace byly použity v databázi. Pokud máte více vývojářů, kteří generují různé migrace při pokusu o cílení na stejnou databázi (a proto sdílíte __MigrationsHistory tabulku), budou migrace velmi zmatené.
Pokud máte samozřejmě členy týmu, kteří negenerují migrace, není problém s jejich sdílením centrální vývojové databáze.
Vyhněte se automatickým migracím
Podstata je, že automatické migrace zpočátku vypadají dobře v týmových prostředích, avšak v praxi nefungují. Pokud chcete vědět proč, pokračujte ve čtení – pokud ne, můžete přeskočit na další část.
Automatické migrace umožňují aktualizovat schéma databáze tak, aby odpovídalo aktuálnímu modelu, aniž byste museli generovat soubory kódu (migrace založené na kódu). Automatické migrace by v týmovém prostředí fungovaly velmi dobře, pokud byste je někdy používali a nikdy negenerovali žádné migrace založené na kódu. Problémem je, že automatické migrace jsou omezené a nezpracují řadu operací – přejmenování vlastností nebo sloupců, přesun dat do jiné tabulky atd. Pro zpracování těchto scénářů skončíte generováním migrací založených na kódu (a úpravou vygenerovaného kódu), které jsou smíšené mezi změnami, které se zpracovávají automatickými migracemi. Je téměř nemožné sloučit změny, když dva vývojáři provedou kontrolu migrací.
Principy fungování migrací
Klíčem k úspěšnému používání migrací v týmovém prostředí je základní znalost toho, jak migrace sleduje a používá informace o modelu k detekci změn modelu.
První migrace
Když do projektu přidáte první migraci, spustíte v konzole Správce balíčků něco jako Add-Migration First. Základní kroky, které tento příkaz provede, jsou znázorněny níže.
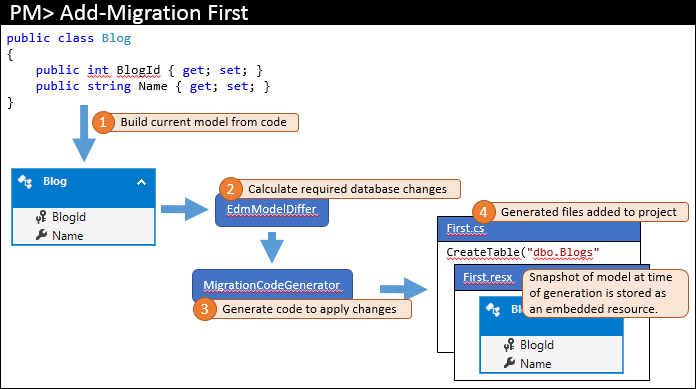
Aktuální model se vypočítá z vašeho kódu (1). Požadované databázové objekty se poté vypočítají pomocí odlišovače modelu (2) – protože se jedná o první migraci, používá odlišovač modelu pro porovnání pouze prázdný model. Požadované změny se předají generátoru kódu pro sestavení požadovaného kódu migrace (3), který se pak přidá do vašeho řešení sady Visual Studio (4).
Kromě skutečného kódu migrace, který je uložený v hlavním souboru kódu, migrace také vygenerují některé další soubory za kódem. Tyto soubory jsou metadata, která používají migrace a které nejsou něco, co byste měli upravit. Jedním z těchto souborů je soubor prostředků (.resx), který obsahuje snímek modelu v době vygenerování migrace. Uvidíte, jak se používá v dalším kroku.
V tomto okamžiku byste pravděpodobně spustili update-Database , abyste použili změny v databázi, a pak byste přešli na implementaci dalších oblastí vaší aplikace.
Následné migrace
Později se vrátíte a provedete nějaké změny modelu – v našem příkladu přidáme vlastnost Url do blogu. Pak byste vydali příkaz, například Add-Migration AddUrl, k vygenerování migrace, která použije odpovídající změny v databázi. Základní kroky, které tento příkaz provede, jsou znázorněny níže.
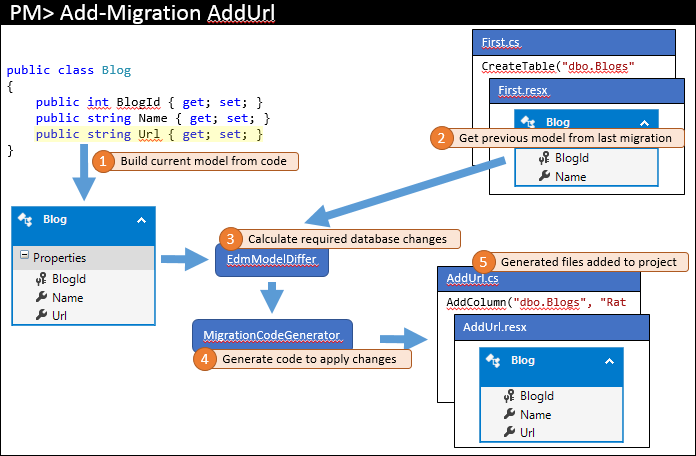
Stejně jako při posledním výpočtu aktuálního modelu z kódu (1). Tentokrát však existují migrace, takže předchozí model se načte z nejnovější migrace (2). Tyto dva modely jsou porovnávány pro zjištění požadovaných změn v databázi (3) a proces je dokončen jako dříve.
Stejný proces se používá pro všechny další migrace, které do projektu přidáte.
Proč se zabývat snímkem modelu?
Možná vás zajímá, proč si EF dělá práci se snímkem modelu – proč se prostě nepodívá na databázi. Pokud ano, přečtěte si dál. Pokud vás to nezajímá, můžete tuto část přeskočit.
Existuje řada důvodů, proč EF uchovává snímek modelu kolem:
- Umožňuje, aby se vaše databáze odchyluje od modelu EF. Tyto změny je možné provést přímo v databázi nebo můžete změnit vygenerovaný kód v migracích k provedení změn. Tady je několik příkladů v praxi:
- Do jedné nebo více tabulek chcete přidat vložený a aktualizovaný sloupec, ale nechcete tyto sloupce zahrnout do modelu EF. Pokud by se migrace podívala na databázi, neustále by se snažila tyto sloupce vypustit při každém generování migrace. Pomocí snímku modelu EF rozpozná pouze legitimní změny modelu.
- Chcete změnit tělo uložené procedury použité pro aktualizace tak, aby zahrnovalo logování. Pokud by migrace zkontrolovaly tuto uloženou proceduru z databáze, neustále by se ji snažily resetovat na definici, kterou očekává EF. Pomocí aktuální struktury modelu EF vygeneruje EF kód pro úpravu uložené procedury pouze tehdy, když změníte strukturu procedury v modelu EF.
- Stejné principy platí i pro přidání dalších indexů, včetně dalších tabulek v databázi, mapování EF na zobrazení databáze, které se nachází nad tabulkou atd.
- Model EF obsahuje více než jen tvar databáze. Mít celý model umožňuje migracím podívat se na informace o vlastnostech a třídách v modelu a o tom, jak se mapují na sloupce a tabulky. Tyto informace umožňují, aby migrace byly inteligentnější v kódu, který vygeneruje. Pokud například změníte název sloupce, který se mapuje na migrace, může přejmenování zjistit tak, že zjistíte, že se jedná o stejnou vlastnost – něco, co nejde udělat, pokud máte pouze schéma databáze.
Co způsobuje problémy v týmových prostředích
Pracovní postup popsaný v předchozí části funguje skvěle, když pracujete na aplikaci s jedním vývojářem. Funguje také dobře v týmovém prostředí, pokud jste jedinou osobou, která provádí změny modelu. V tomto scénáři můžete provádět změny modelu, generovat migrace a odesílat je do správy zdrojového kódu. Ostatní vývojáři můžou synchronizovat vaše změny a spustit Update-Database , aby se použily změny schématu.
Problémy začínají nastat, když máte více vývojářů, kteří provádí změny modelu EF a současně je odesílali do správy zdrojového kódu. Co EF chybí, je účinný způsob, jak sloučit vaše místní migrace s migracemi, které jiný vývojář odeslal do systému správy verzí od vaší poslední synchronizace.
Příklad konfliktu při sloučení
Nejprve se podíváme na konkrétní příklad takového konfliktu při slučování. Budeme pokračovat v příkladu, na který jsme se podívali dříve. Jako výchozí bod předpokládejme, že změny z předchozí části byly uloženy původním vývojářem. Při provádění změn základu kódu budeme sledovat dva vývojáře.
Model EF a migrace budeme sledovat prostřednictvím řady změn. Pro výchozí bod se oba vývojáři synchronizovali s úložištěm správy zdrojového kódu, jak je znázorněno na následujícím obrázku.
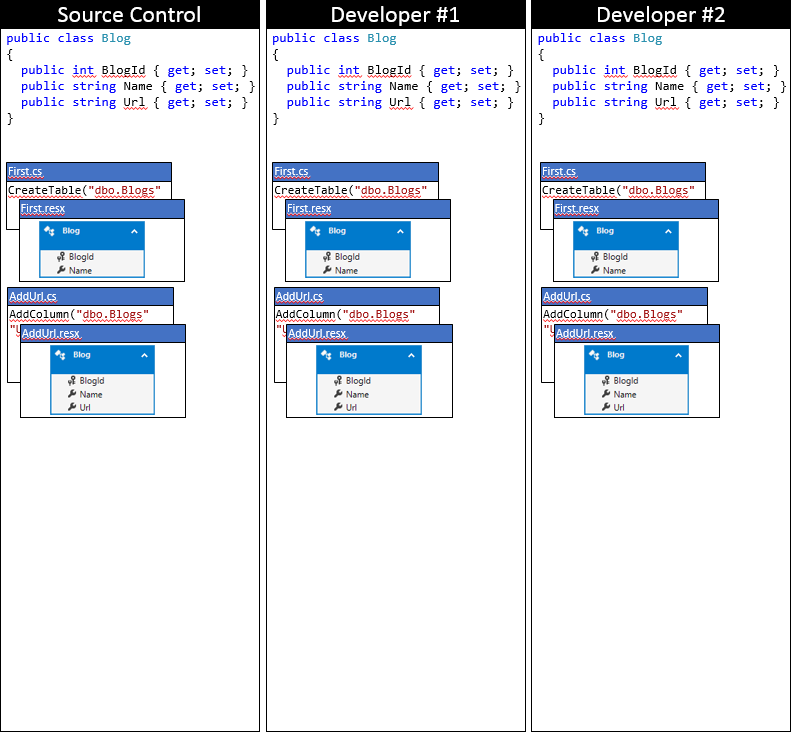
Vývojář č. 1 a vývojář č. 2 teď provedou změny v modelu EF ve své lokální kódové základně. Vývojář č. 1 přidá do blogu vlastnost Hodnocení – a vygeneruje migraci AddRating, která použije změny v databázi. Developer č. 2 přidá vlastnost Čtenáři do Blogu – a vygeneruje odpovídající migraci AddReaders. Oba vývojáři spustí Update-Database, aby mohli použít změny v místních databázích, a pak pokračovat v vývoji aplikace.
Poznámka:
Migrace mají předponu časového razítka, takže náš graf znázorňuje, že migrace AddReaders od Vývojáře č. 2 přichází po migraci AddRating od Vývojáře č. 1. Ať už vývojář č. 1 nebo #2 vygeneroval migraci jako první, nezáleží na problémech při práci v týmu nebo na proces jejich sloučení, na který se podíváme v další části.
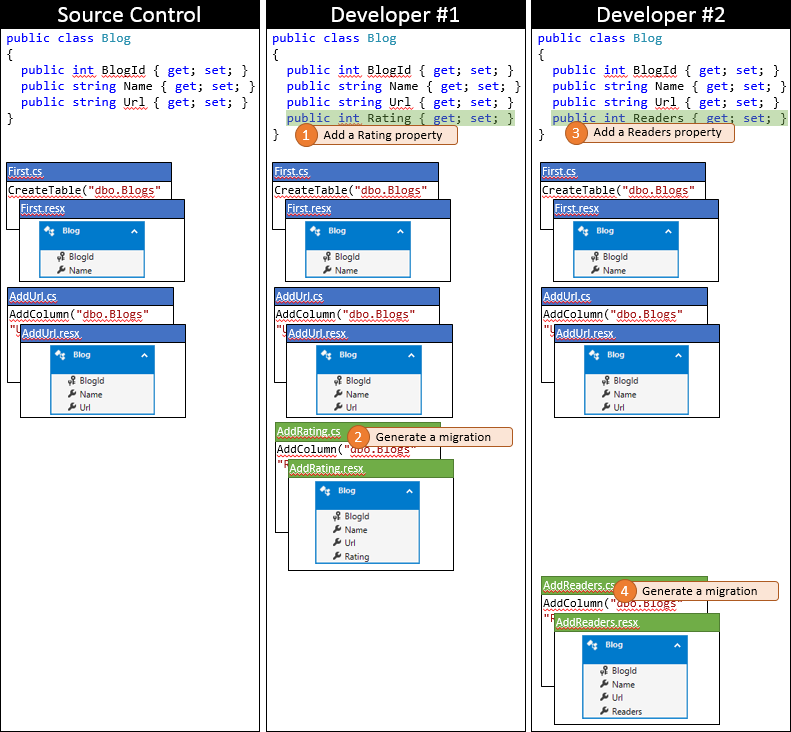
Vývojáři č. 1 mají štěstí, protože nejdřív odesílají změny. Vzhledem k tomu, že od synchronizace úložiště nikdo jiný nezkontroloval, může pouze odeslat změny bez sloučení.
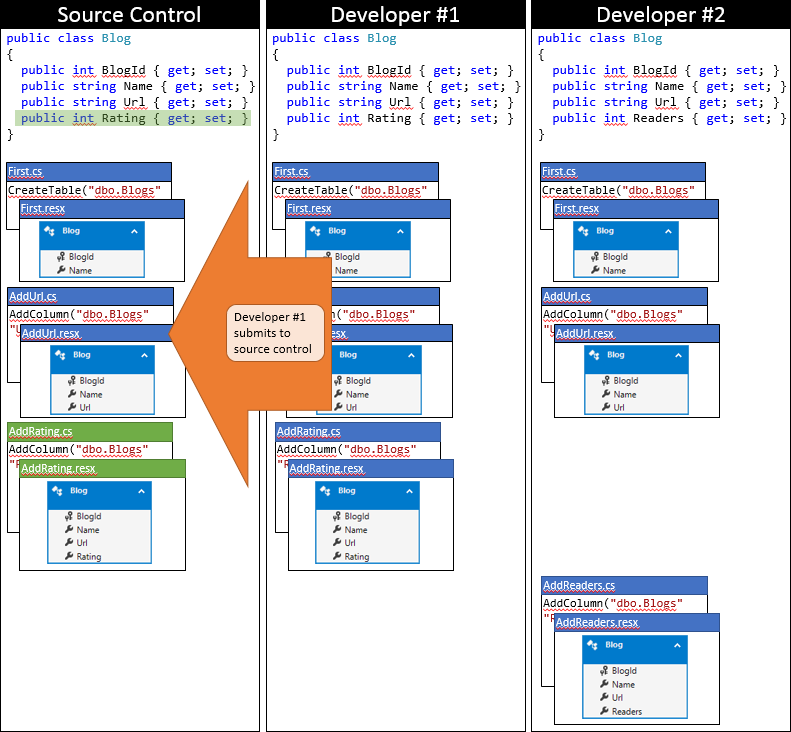
Nyní je čas, aby vývojář #2 odeslal. Nejsou tak šťastní. Protože někdo jiný od synchronizace odeslal změny, bude muset změny stáhnout a sloučit. Systém správy zdrojového kódu bude pravděpodobně moct automaticky sloučit změny na úrovni kódu, protože jsou velmi jednoduché. Stav místního úložiště Developer #2 po synchronizaci je znázorněn na následujícím obrázku.
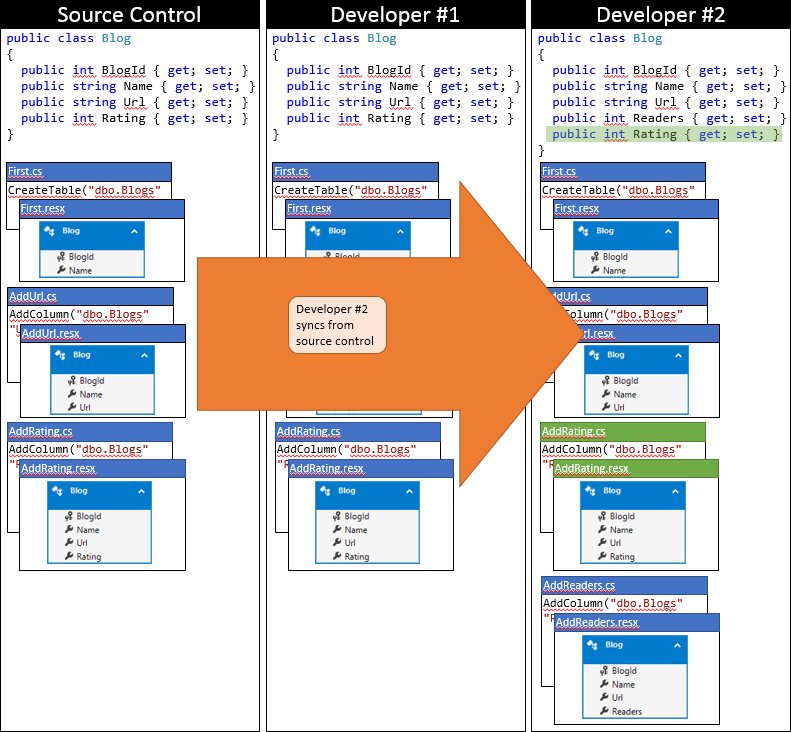
V této fázi vývojář #2 může spustit update-database , která zjistí novou migraci AddRating (která nebyla použita pro databázi vývojáře č. 2) a použije ji. Teď se sloupec Hodnocení přidá do tabulky Blogy a databáze se synchronizuje s modelem.
Existuje ale několik problémů:
- I když Update-Database použije migraci AddRating, zobrazí se také upozornění: Nelze aktualizovat databázi tak, aby odpovídala aktuálnímu modelu, protože existují nevyřízené změny a automatická migrace je zakázána... Problém je, že snímek modelu uložený v poslední migraci (AddReader) postrádá vlastnost Rating v Blogu (protože nebyla součástí modelu, když byla migrace generována). Code First zjistí, že model v poslední migraci neodpovídá aktuálnímu modelu a vyvolá upozornění.
- Spuštění aplikace způsobí výjimku InvalidOperationException, která hlásí, že se od vytvoření databáze změnil model, který zálohuje kontext BloggingContext. Zvažte použití Migrace Code First k aktualizaci databáze..." Problém je, že snímek modelu uložený v poslední migraci neodpovídá aktuálnímu modelu.
- Nakonec bychom očekávali, že spuštění doplňkové migrace teď vygeneruje prázdnou migraci (protože pro databázi se nedají použít žádné změny). Vzhledem k tomu, že migrace porovnávají aktuální model s modelem z poslední migrace (kde chybí vlastnost Hodnocení), ve skutečnosti vygeneruje další volání AddColumn, aby přidal sloupec Hodnocení. Tato migrace by samozřejmě selhala během aktualizace databáze , protože sloupec Hodnocení již existuje.
Řešení konfliktu při slučování
Dobrou zprávou je, že není příliš těžké řešit sloučení ručně – za předpokladu, že víte, jak migrace fungují. Takže pokud jste přeskočili dopředu do této části... omlouváme se, musíte se vrátit a přečíst si zbytek článku jako první!
Existují dvě možnosti, nejjednodušší je vygenerovat prázdnou migraci, která má správný aktuální model jako snímek. Druhou možností je aktualizovat snímek v poslední migraci, aby měl správný snímek modelu. Druhá možnost je o něco těžší a nedá se použít v každém scénáři, ale je také čistější, protože nezahrnuje přidání další migrace.
Možnost 1: Přidání prázdné migrace pro sloučení
V této možnosti vygenerujeme prázdnou migraci výhradně pro účely zajištění, že nejnovější migrace obsahuje správný snímek modelu uložený v ní.
Tuto možnost můžete použít bez ohledu na to, kdo vygeneroval poslední migraci. V příkladu, který sledujeme, se vývojář #2 stará o sloučení a právě on vygeneroval poslední migraci. Stejný postup ale můžete použít, pokud vývojář #1 vygeneroval poslední migraci. Tento postup platí i v případě, že se jedná o více migrací – podívali jsme se na dvě, abychom to mohli zjednodušit.
Pro tento přístup je možné použít následující proces, počínaje časem, kdy zjistíte, že máte změny, které je potřeba synchronizovat ze správy zdrojového kódu.
- Ujistěte se, že do migrace byly zapsány všechny čekající změny modelu v místním základu kódu. Tento krok zajistí, že při vygenerování prázdné migrace nezmeškáte žádné legitimní změny.
- Synchronizace se zdrojovou kontrolou
- Spusťte Update-Database, aby se použily všechny nové migrace, které provedli jiní vývojáři. Poznámka:Pokud se z příkazu Update-Database nezobrazí žádná upozornění, nebyly žádné nové migrace od jiných vývojářů a není nutné provádět žádné další sloučení.
- Spusťte Add-Migration <pick_a_name> –IgnoreChanges (například Add-Migration Merge –IgnoreChanges). Tím se vygeneruje migrace se všemi metadaty (včetně snímku aktuálního modelu), ale při porovnávání aktuálního modelu se snímkem při poslední migraci ignoruje všechny změny, které detekuje (což znamená, že získáte prázdnou metodu Nahoru a dolů ).
- Spusťte Update-Database a znovu nainstalujte nejnovější migraci s aktualizovanými metadaty.
- Pokračujte v vývoji nebo odešlete do správy zdrojového kódu (po spuštění testů jednotek samozřejmě).
Tady je stav místní úložiště kódu vývojáře č. 2 po použití tohoto přístupu.
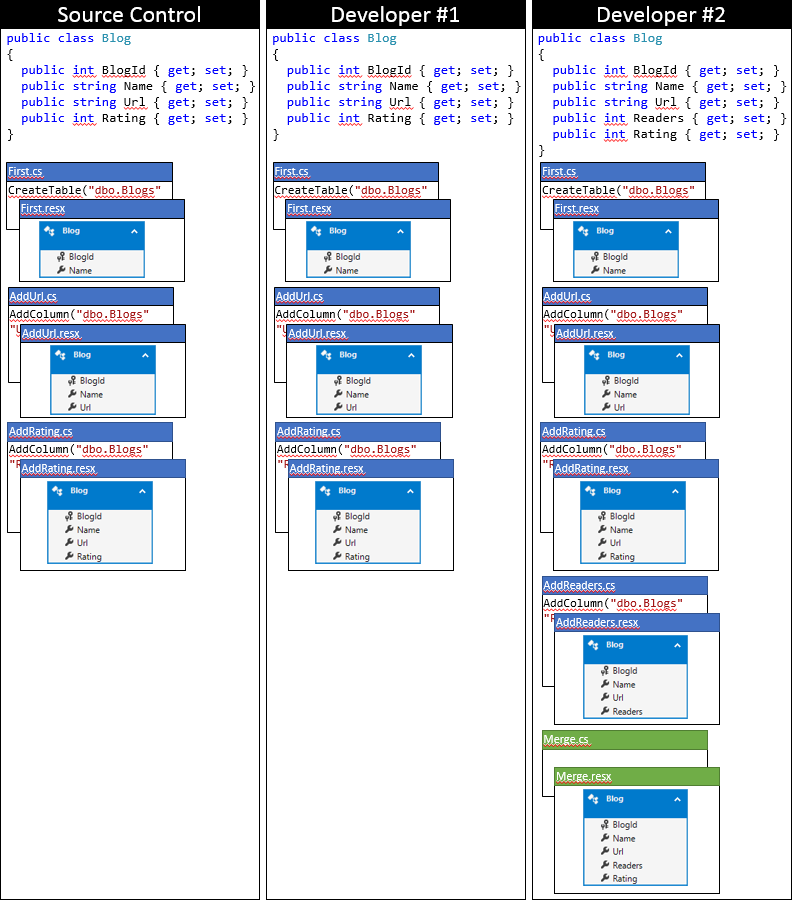
Možnost 2: Aktualizace snímku modelu v poslední migraci
Tato možnost je velmi podobná možnosti 1, ale odebere nadbytečnou prázdnou migraci – přiznejme si, kdo by chtěl ve svém řešení mít další soubory kódu navíc.
Tento přístup je proveditelný pouze v případě, že poslední migrace existuje pouze v místním základu kódu a ještě nebyla odeslána do správy zdrojového kódu (například pokud byla poslední migrace vygenerována uživatelem, který provádí sloučení). Úprava metadat migrací, které už jiní vývojáři použili u své vývojové databáze ( nebo ještě horšího použití v produkční databázi), můžou mít za následek neočekávané vedlejší účinky. Během procesu vrátíme poslední migraci v naší místní databázi a znovu ji použijeme s aktualizovanými metadaty.
I když poslední migrace musí být jenom v místní verzi kódu, neexistují žádná omezení pro počet nebo pořadí migrací, které ji následují. Existuje několik různých migrací od vývojářů a stejný postup na ně platí – pouze jsme se zaměřili na dva pro jednoduchost.
Pro tento přístup je možné použít následující proces, počínaje časem, kdy zjistíte, že máte změny, které je potřeba synchronizovat ze správy zdrojového kódu.
- Ujistěte se, že do migrace byly zapsány všechny čekající změny modelu v místním základu kódu. Tento krok zajistí, že při vygenerování prázdné migrace nezmeškáte žádné legitimní změny.
- Synchronizujte se se správou zdrojového kódu.
- Spusťte Update-Database, aby se použijí všechny nové migrace, které přihlásili jiní vývojáři. Poznámka:Pokud se z příkazu Update-Database nezobrazí žádná upozornění, nebyly žádné nové migrace od jiných vývojářů a není nutné provádět žádné další sloučení.
- Spusťte Update-Database –TargetMigration <second_last_migration> (v příkladu, který sledujeme, by to bylo Update-Database –TargetMigration AddRating). Tím se databáze vrátí zpět do stavu druhé poslední migrace – efektivně se zruší použití poslední migrace z databáze. Poznámka:Tento krok je nutný k tomu, aby bylo bezpečné upravovat metadata migrace, protože metadata jsou také uložena v __MigrationsHistoryTable databáze. Proto byste tuto možnost měli použít jenom v případě, že poslední migrace je pouze v místním základu kódu. Pokud by se použila poslední migrace jiných databází, museli byste je vrátit zpět a znovu použít poslední migraci, aby se aktualizovala metadata.
- Spusťte Add-Migration <full_name_including_timestamp_of_last_migration> (v příkladu, který sledujeme, by to bylo něco jako Add-Migration 201311062215252_AddReaders). Poznámka:Musíte zahrnout časové razítko, aby migrace věděla, že chcete stávající migraci upravit, a ne vygenerování nového. Tím se aktualizují metadata poslední migrace tak, aby odpovídala aktuálnímu modelu. Po dokončení příkazu se zobrazí následující upozornění, ale to je přesně to, co chcete. Znovu se vygeneroval pouze kód návrháře pro migraci 201311062215252_AddReaders. Pokud chcete znovu vygenerovat celou migraci, použijte parametr -Force.
- Spusťte Update-Database a znovu nainstalujte nejnovější migraci s aktualizovanými metadaty.
- Pokračujte v vývoji nebo odešlete do správy zdrojového kódu (po spuštění testů jednotek samozřejmě).
Tady je stav místního kódu vývojáře č. 2 po použití tohoto přístupu.
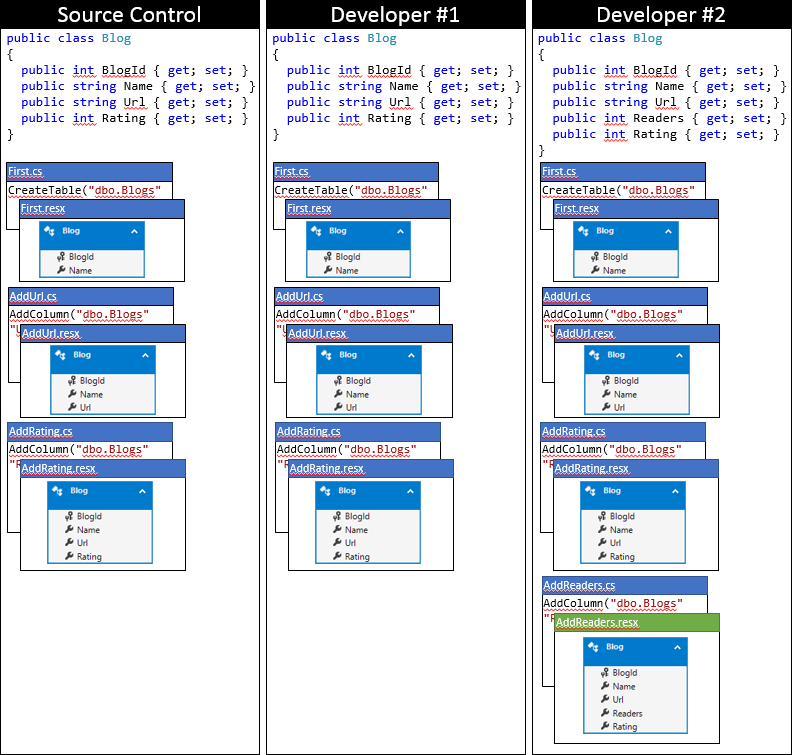
Shrnutí
Při používání Migrace Code First v týmovém prostředí dochází k určitým problémům. Základní znalosti o tom, jak migrace fungují, a několik jednoduchých přístupů k řešení konfliktů při slučování usnadňuje řešení těchto problémů.
Základním problémem jsou nesprávná metadata uložená v nejnovější migraci. To způsobí, že Code First nesprávně zjistí, že aktuální schéma modelu a databáze neodpovídá a v další migraci vygeneruje nesprávný kód. Tuto situaci lze překonat generováním prázdné migrace se správným modelem nebo aktualizací metadat v nejnovější migraci.
Spolupracujte s námi na GitHubu
Zdroj tohoto obsahu najdete na GitHubu, kde můžete také vytvářet a kontrolovat problémy a žádosti o přijetí změn. Další informace najdete v našem průvodci pro přispěvatele.