Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
V tomto kurzu se dozvíte, jak vytvořit definici úlohy Sparku v Microsoft Fabric.
Proces vytváření definic úloh Sparku je rychlý a jednoduchý; existuje několik způsobů, jak začít.
Definici úlohy Sparku můžete vytvořit z portálu Fabric nebo pomocí rozhraní MICROSOFT Fabric REST API. Tento článek se zaměřuje na vytvoření definice úlohy Sparku z portálu Fabric. Informace o vytvoření definice úlohy Spark pomocí rozhraní REST API najdete v tématu Rozhraní API definice úlohy Apache Spark v1 a rozhraní API definice úlohy Apache Spark v2.
Požadavky
Než začnete, budete potřebovat:
- Účet tenanta Fabric s aktivním předplatným. Vytvoření účtu zdarma
- Pracovní prostor v Microsoft Fabric. Další informace najdete v tématu Vytváření a správa pracovních prostorů v Microsoft Fabric.
- Alespoň jeden lakehouse v pracovním prostoru. Lakehouse slouží jako výchozí systém souborů pro definici úlohy Sparku. Další informace najdete v tématu Vytvoření lakehouse.
- Hlavní definiční soubor pro úlohu Sparku. Tento soubor obsahuje logiku aplikace a je povinný ke spuštění úlohy Sparku. Každá definice úlohy Sparku může mít pouze jeden hlavní definiční soubor.
Při vytváření musíte definici úlohy Sparku pojmenovat. Název musí být v aktuálním pracovním prostoru jedinečný. Nová definice úlohy Sparku se vytvoří v aktuálním pracovním prostoru.
Vytvoření definice úlohy Sparku na portálu Fabric
Pokud chcete vytvořit definici úlohy Sparku na portálu Fabric, postupujte takto:
- Přihlaste se k portálu Microsoft Fabric.
- Přejděte do požadovaného pracovního prostoru, ve kterém chcete vytvořit definici úlohy Sparku.
- Vyberte Nová položka>Definice úlohy Spark.
- V podokně Definice nové úlohy Sparku zadejte následující informace:
- Název: Zadejte jedinečný název definice úlohy Sparku.
- Umístění: Vyberte umístění pracovního prostoru.
- Vyberte Vytvořit pro vytvoření definice úlohy Sparku.
Alternativním vstupním bodem pro vytvoření definice úlohy Sparku je dlaždice Data Analytics Using a SQL... na domovské stránce Fabric. Stejnou možnost najdete tak, že vyberete dlaždici Obecné.

Když dlaždici vyberete, zobrazí se výzva k vytvoření nového pracovního prostoru nebo k výběru existujícího pracovního prostoru. Po výběru pracovního prostoru se otevře stránka pro vytvoření definice úlohy Sparku.
Přizpůsobení definice úlohy Sparku pro PySpark (Python)
Před vytvořením definice úlohy Spark pro PySpark potřebujete ukázkový soubor Parquet nahraný do jezera.
- Stáhněte si ukázkový soubor Parquet yellow_tripdata_2022-01.parquet.
- Přejděte do jezera, kam chcete soubor nahrát.
- Nahrajte ho do části "Soubory" datového skladu.
Vytvoření definice úlohy Spark pro PySpark:
V rozevíracím seznamu Jazyk vyberte PySpark (Python).
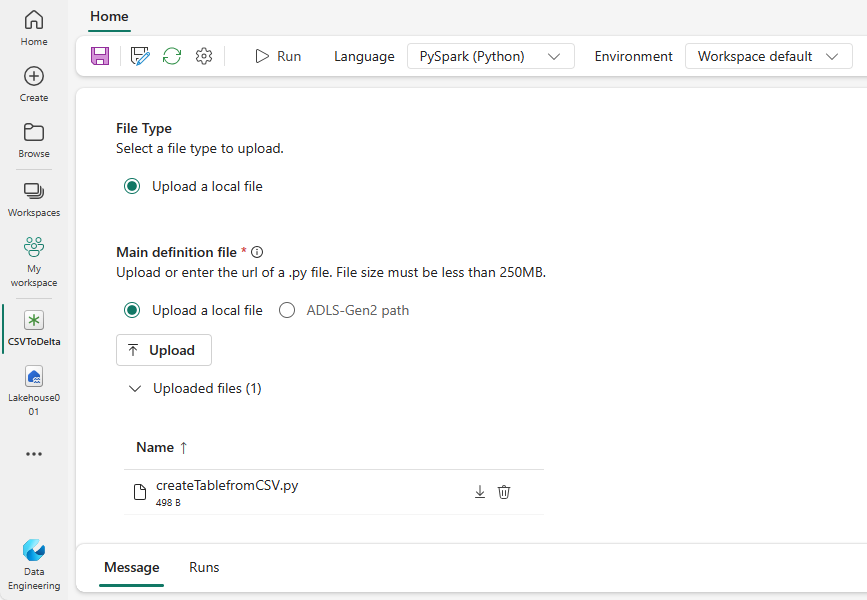
Stáhněte si ukázkový definiční soubor createTablefromParquet.py. Nahrajte ho jako hlavní definiční soubor. Hlavní definiční soubor (úloha). Main) je soubor, který obsahuje logiku aplikace a je povinný ke spuštění úlohy Spark. Pro každou definici úlohy Sparku můžete nahrát jenom jeden hlavní definiční soubor.
Poznámka:
Hlavní definiční soubor můžete nahrát z místní plochy nebo můžete nahrát z existující služby Azure Data Lake Storage (ADLS) Gen2 tak, že poskytnete úplnou cestu k souboru ABFSS. Například
abfss://your-storage-account-name.dfs.core.windows.net/your-file-path.Volitelně můžete nahrát referenční soubory jako
.pysoubory (Python). Referenční soubory jsou moduly Pythonu, které hlavní definiční soubor importuje. Stejně jako hlavní definiční soubor můžete nahrát z plochy nebo z existujícího souboru ADLS Gen2. Podporuje se více referenčních souborů.Tip
Pokud používáte cestu ADLS Gen2, ujistěte se, že je soubor přístupný. Uživatelskému účtu, který spouští úlohu, musíte udělit správné oprávnění k účtu úložiště. Oprávnění můžete udělit dvěma různými způsoby:
- Přiřaďte uživatelskému účtu roli Přispěvatel pro účet úložiště.
- Udělení oprávnění ke čtení a spuštění pro uživatelský účet souboru prostřednictvím seznamu řízení přístupu ADLS Gen2 (ACL).
Pro ruční spuštění se ke spuštění úlohy použije účet aktuálního přihlášeného uživatele.
V případě potřeby zadejte argumenty příkazového řádku pro úlohu. K oddělení argumentů použijte mezeru jako rozdělovač.
Přidejte do úlohy odkaz na lakehouse. Musíte mít k úloze přidaný alespoň jeden odkaz na lakehouse. Toto jezero je výchozím kontextem jezera pro úlohu.
Podporuje se více odkazů na lakehouse. Na stránce Nastavení Sparku vyhledejte jiný než výchozí název jezera a úplnou adresu URL OneLake.

Přizpůsobení definice úlohy Sparku pro Scala/Java
Vytvoření definice úlohy Sparku pro Scala/Java:
V rozevíracím seznamu Jazyk vyberte Spark(Scala/Java).
Nahrajte hlavní definiční soubor jako
.jarsoubor (Java). Hlavní definiční soubor je soubor, který obsahuje logiku aplikace této úlohy a je povinný ke spuštění úlohy Spark. Pro každou definici úlohy Sparku můžete nahrát jenom jeden hlavní definiční soubor. Zadejte název třídy Main.Volitelně můžete nahrát referenční soubory jako
.jarsoubory (Java). Referenční soubory jsou soubory, na které odkazuje/import hlavní definiční soubor.V případě potřeby zadejte argumenty příkazového řádku pro úlohu.
Přidejte do úlohy odkaz na lakehouse. Musíte mít k úloze přidaný alespoň jeden odkaz na lakehouse. Toto jezero je výchozím kontextem jezera pro úlohu.
Přizpůsobení definice úlohy Sparku pro R
Vytvoření definice úlohy Sparku pro SparkR(R):
V rozevíracím seznamu Jazyk vyberte SparkR(R).
Nahrajte hlavní definiční soubor jako
.rsoubor (R). Hlavní definiční soubor je soubor, který obsahuje logiku aplikace této úlohy a je povinný ke spuštění úlohy Spark. Pro každou definici úlohy Sparku můžete nahrát jenom jeden hlavní definiční soubor.Volitelně nahrajte referenční soubory jako soubory
.r(R). Referenční soubory jsou soubory, na které odkazuje nebo importuje hlavní definiční soubor.V případě potřeby zadejte argumenty příkazového řádku pro úlohu.
Přidejte do úlohy odkaz na lakehouse. Musíte mít k úloze přidaný alespoň jeden odkaz na lakehouse. Toto jezero je výchozím kontextem jezera pro úlohu.
Poznámka:
Definice úlohy Sparku se vytvoří ve vašem aktuálním pracovním prostoru.
Možnosti přizpůsobení definic úloh Sparku
Existuje několik možností, jak dále přizpůsobit spouštění definic úloh Sparku.
Spark Compute: Na kartě Spark Compute uvidíte verzi runtime systému Fabric, která se používá ke spuštění úlohy Spark. Můžete se také podívat na nastavení konfigurace Sparku, která se používají ke spuštění úlohy. Nastavení konfigurace Sparku můžete přizpůsobit výběrem tlačítka Přidat .
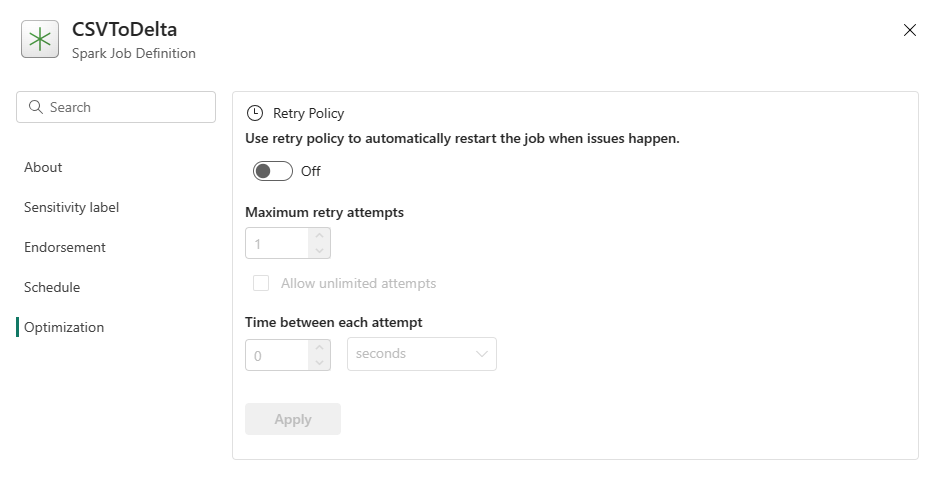
Optimalizace: Na kartě Optimalizace můžete povolit a nastavit zásady opakování pro úlohu. Pokud je tato úloha povolená, opakuje se, pokud selže. Můžete také nastavit maximální počet opakování a interval mezi opakovanými pokusy. U každého pokusu o opakování se úloha restartuje. Ujistěte se, že je úloha idempotentní.