Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento rychlý návod vysvětluje, jak vytvořit Spark Job Definition, která obsahuje kód Python se Spark Structured Streaming pro ukládání dat do lakehousu a následně je poskytovat prostřednictvím SQL analytického koncového bodu. Po dokončení tohoto rychlého startu budete mít definici úlohy Sparku, která běží nepřetržitě a koncový bod analýzy SQL může zobrazit příchozí data.
Vytvoření skriptu Pythonu
Pomocí následujícího skriptu v Pythonu vytvořte streamovací tabulku Delta v lakehouse pomocí Apache Spark. Skript načte datový proud vygenerovaných dat (jeden řádek za sekundu) a zapíše ho v režimu připojení do tabulky Delta s názvem streamingtable. Ukládá data a informace kontrolního bodu v zadaném jezeře.
K získání dat v tabulce Lakehouse použijte následující kód Pythonu, který používá strukturované streamování Sparku.
from pyspark.sql import SparkSession if __name__ == "__main__": # Start Spark session spark = SparkSession.builder \ .appName("RateStreamToDelta") \ .getOrCreate() # Table name used for logging tableName = "streamingtable" # Define Delta Lake storage path deltaTablePath = f"Tables/{tableName}" # Create a streaming DataFrame using the rate source df = spark.readStream \ .format("rate") \ .option("rowsPerSecond", 1) \ .load() # Write the streaming data to Delta query = df.writeStream \ .format("delta") \ .outputMode("append") \ .option("path", deltaTablePath) \ .option("checkpointLocation", f"{deltaTablePath}/_checkpoint") \ .start() # Keep the stream running query.awaitTermination()Uložte skript jako soubor Pythonu (.py) do místního počítače.
Vytvořte jezerní dům
Pomocí následujících kroků vytvořte jezerní dům:
Přihlaste se k portálu Microsoft Fabric.
V případě potřeby přejděte do požadovaného pracovního prostoru nebo vytvořte nový.
Pokud chcete vytvořit lakehouse, vyberte v pracovním prostoru novou položku a pak na panelu, který se otevře, vyberte Lakehouse .
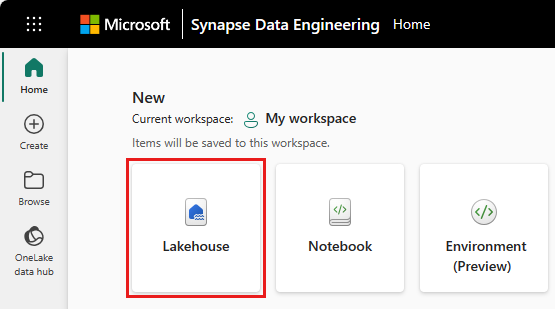
Zadejte název vašeho lakehouse a vyberte Vytvořit.

Vytvoření definice úlohy Sparku
Pomocí následujících kroků vytvořte definici úlohy Sparku:
Ve stejném pracovním prostoru, ve kterém jste vytvořili lakehouse, vyberte Nová položka.
Na panelu, který se otevře, v části Získat data vyberte Definici úlohy Sparku.
Zadejte název definice úlohy Sparku a vyberte Vytvořit.
Vyberte Nahrát a vyberte soubor Pythonu, který jste vytvořili v předchozím kroku.
V sekci Odkaz na Lakehouse zvolte lakehouse, který jste vytvořili.
Nastavení zásad opakování pro definici úlohy Sparku
Pomocí následujících kroků nastavte zásadu opakování pro definici úlohy Sparku:
V horní nabídce vyberte ikonu Nastavení .
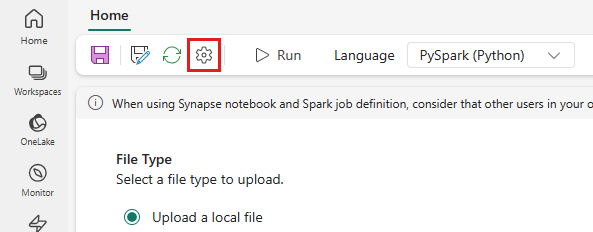
Otevřete kartu Optimalizace a nastavte trigger Zásady opakovánízapnuto.
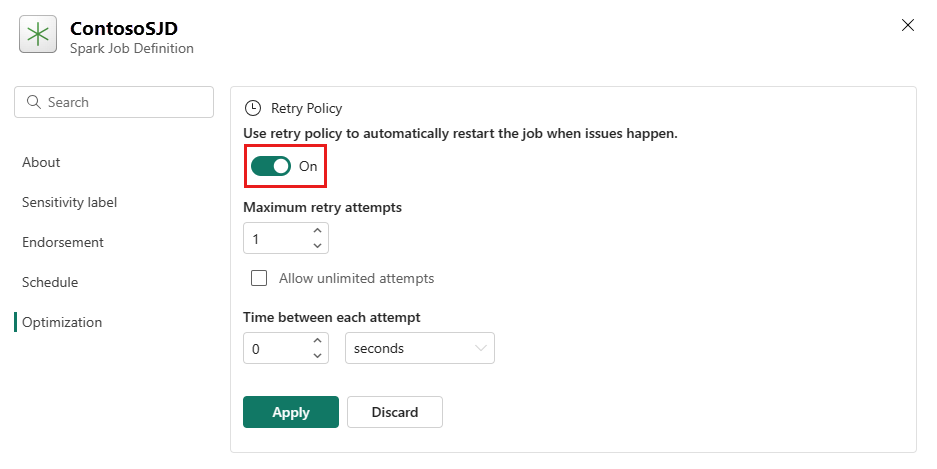
Definujte maximální počet pokusů o opakování nebo zaškrtněte políčko Povolit neomezené pokusy.
Zadejte čas mezi jednotlivými pokusy o opakování a vyberte Použít.


Note
Pro nastavení zásad opakování platí limit životnosti 90 dnů. Jakmile je zásada opakování povolená, úloha se restartuje podle zásad do 90 dnů. Po uplynutí této doby zásady opakování automaticky přestanou fungovat a úloha se ukončí. Uživatelé pak budou muset úlohu restartovat ručně, což zase znovu povolí zásadu opakování.
Spustit a sledovat definici úlohy Sparku
V horní nabídce vyberte ikonu Spustit .
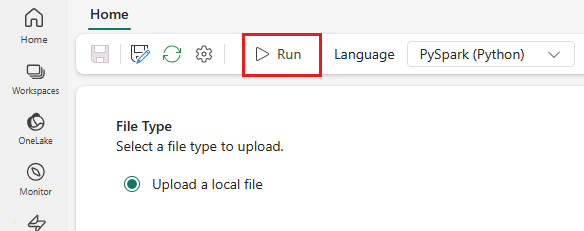
Ověřte, jestli byla definice úlohy Sparku úspěšně odeslána a spuštěna.

Zobrazení dat pomocí koncového bodu analýzy SQL
Po spuštění skriptu se v jezeře vytvoří tabulka s názvem streamingtable s časovým razítkem a sloupci hodnot . Data můžete zobrazit pomocí koncového bodu SQL Analytics:
V pracovním prostoru otevřete svůj Lakehouse.
Přepněte na koncový bod analýzy SQL v pravém horním rohu.
V levém navigačním podokně rozbalte Schémata > dbo >Tabulky, vyberte streamingtable a zobrazte náhled dat.