Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Modul runtime Fabric nabízí bezproblémovou integraci s Azure. Poskytuje sofistikované prostředí pro projekty přípravy dat i datové vědy, které používají Apache Spark. Tento článek obsahuje přehled základních funkcí a součástí modulu Fabric Runtime 1.3.
Microsoft Fabric Runtime 1.3 je verze modulu runtime GA, která zahrnuje následující komponenty a upgrady navržené tak, aby zlepšily možnosti zpracování dat:
Apache Spark 3.5
Operační systém: Mariner 2.0 (Azure Linux 2.0)
Java: 11
Scala: 2.12.17
Python: 3.11
Delta Lake: 3.2
R: 4.4.1
Návod
Modul fabric Runtime 1.3 obsahuje podporu nativního prováděcího modulu, která může výrazně zvýšit výkon bez dalších nákladů. Pokud chcete povolit nativní prováděcí modul pro všechny úlohy a poznámkové bloky ve vašem prostředí, přejděte do nastavení prostředí, vyberte Výpočetní prostředí Sparku, přejděte na kartu Akcelerace a zkontrolujte možnost Povolit nativní prováděcí modul. Po uložení a publikování se toto nastavení použije v celém prostředí, takže všechny nové úlohy a poznámkové bloky automaticky dědí a využívají výhod vylepšených funkcí výkonu.
Integrace modulu runtime 1.3
Poznámka:
Informace o všech dostupných runtimech Fabric a jejich aktuálním stavu najdete v tématu Runtimes Apache Spark v Fabric.
Pomocí následujících pokynů integrujte modul runtime 1.3 do pracovního prostoru a použijte jeho nové funkce:
V pracovním prostoru Fabric přejděte na kartu Nastavení pracovního prostoru.
Přejděte na kartu Datoví technici/Věda a vyberte Nastavení Sparku.
Vyberte kartu Prostředí.
V částiVerze modulu runtime rozbalte rozevírací seznam.Vyberte 1.3 (Spark 3.5, Delta 3.2) a uložte změny. Tato akce nastaví verzi 1.3 jako výchozí runtime vašeho pracovního prostoru.
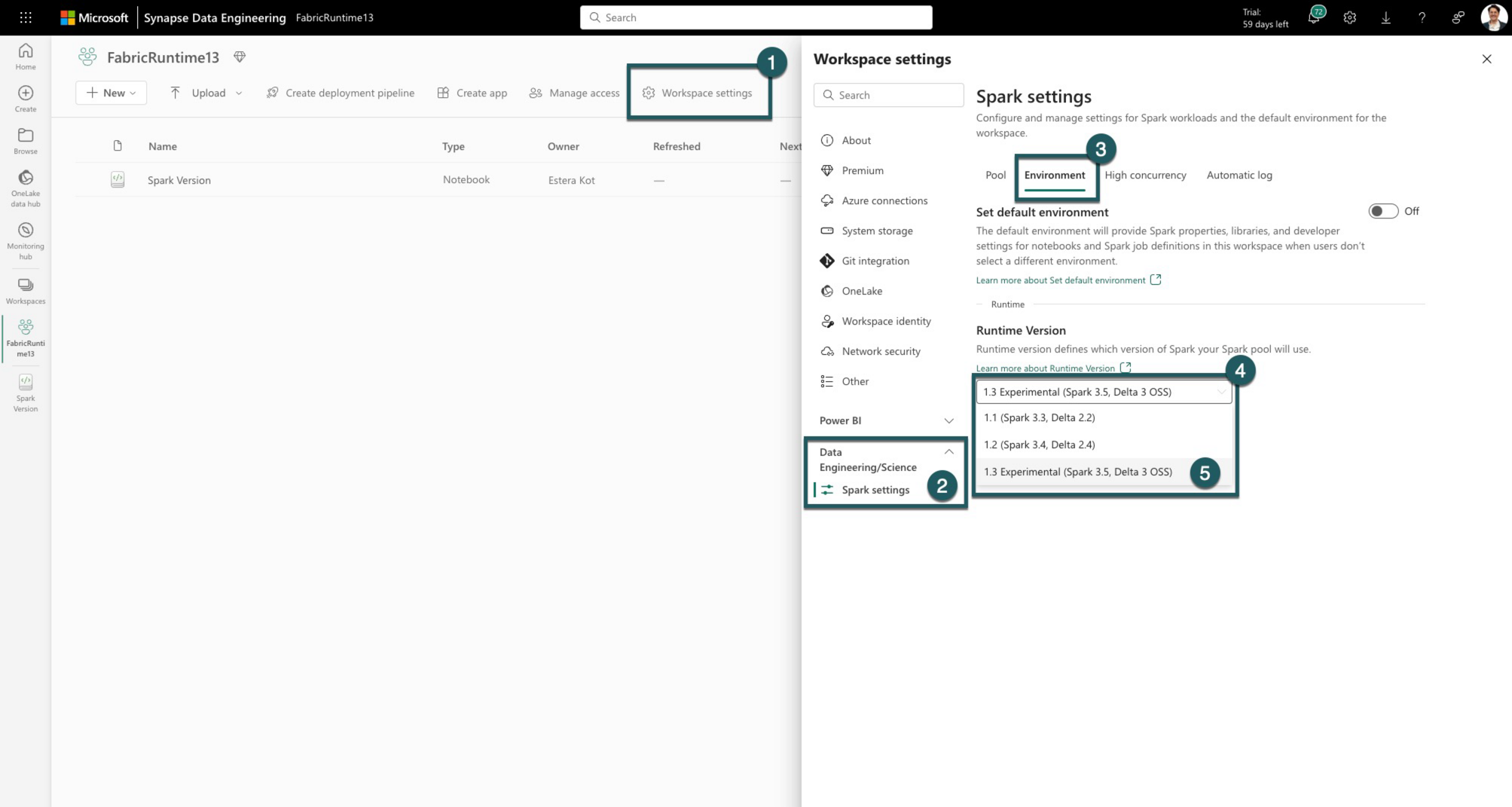

Teď můžete začít pracovat s nejnovějšími vylepšeními a funkcemi zavedenými v modulu runtime Fabric 1.3 (Spark 3.5 a Delta Lake 3.2).
Další informace o Apache Sparku 3.5
Apache Spark 3.5.0 je šestá verze řady 3.x. Tato verze je produktem rozsáhlé spolupráce v rámci opensourcové komunity, která řeší více než 1 300 problémů, jak je zaznamenáno v Jiře.
V této verzi existuje upgrade s kompatibilitou strukturovaného streamování. Kromě toho tato verze rozšiřuje funkce v rámci PySpark a SQL. Přidává funkce, jako je klauzule identifikátoru SQL, pojmenované argumenty ve volání funkce SQL a zahrnutí funkcí SQL pro přibližné agregace HyperLogLogu.
Mezi další nové funkce patří také uživatelem definované funkce tabulek Pythonu, zjednodušení distribuovaného trénování prostřednictvím DeepSpeed a nové funkce strukturovaného streamování, jako je šíření vodoznaku a operace dropDuplicatesWithinWatermark .
Úplný seznam a podrobné změny najdete tady: Verze Sparku 3.5.0.
Další informace o Delta Sparku
Delta Lake 3.2 označuje kolektivní závazek, že Delta Lake bude interoperabilní napříč formáty, bude jednodušší pracovat s a bude výkonnější. Delta Spark 3.2 je postaven na Apache Sparku™ 3.5. Artefakt Maven Delta Spark se přejmenovává z delta-core na delta-spark.
Můžete zkontrolovat úplný seznam a podrobné změny zde: https://docs.delta.io/index.html.
Komponenty a knihovny
Pro aktuální informace, podrobný seznam změn a specifické poznámky k verzím pro Fabric runtime, zkontrolujte a přihlaste se k odběru na Spark Runtimes Releases and Updates.
Poznámka:
EventHubConnector je zastaralý v modulu Fabric Runtime 1.3 (Spark 3.5) a bude odebrán z budoucích verzí modulu Fabric Runtime. Zákazníkům se doporučuje místo toho používat konektor Kafka Spark, protože služba Event Hubs je už kompatibilní se systémem Kafka. Další informace o používání konektoru Kafka Spark se službou Event Hubs najdete tady: Kurz sparku služby Event Hubs
Související obsah
- Přečtěte si o běhových prostředích Apache Spark v systému Fabric – přehled, verzování, podpora více běhových prostředí a upgrade protokolu Delta Lake
- Průvodce migrací Spark Core
- Průvodce migrací sql, datových sad a datových rámců
- Průvodce migrací strukturovaného streamování
- Průvodce migrací MLlib (Machine Learning)
- Průvodce migrací PySpark (Python ve Sparku)
- Průvodce migrací SparkR (R ve Sparku)